android 如何分析应用的内存(十八)终章——使用Perfetto查看内存与调用栈之间的泄露
android 如何分析应用的内存(十八)
在前面两篇文章中,先是介绍了如何用AS查看Android的堆内存,然后介绍了使用MAT查看
Android的堆内存。AS能够满足基本的内存分析需求,但是无法进行多个堆的综合比较,因此引入了MAT工具。它可以很好的在两个堆之间进行比较。两个工具已经能解决95%的内存问题了。
但是在一些极端情况下,如多线程带来的内存泄漏,上面两个工具可能就不太好定位问题,即泄漏点的调用栈和调用线程了。
对于Android来讲,怎样才能定位这种多线程调用带来的内存呢?下面是一些经验之谈:
- 如果能够添加代码,对于不同的线程,在泄露的对象上,添加一个字段,用于表示线程的id。此方法比较简单,就不再赘述
- 如果不能添加代码,那么就需要同时录制java的调用栈和java的堆。根据在同时间段,进行逻辑比较,得出是哪一个调用栈导致的内存泄露。如,通过比较哪个调用栈调用的次数最多,哪个调用栈分配的内存最多。甚至需要在一段时间间隔之间做差分,来获得泄露的对象和调用栈之间的关系。这些方法往往需要一定的经验进行逻辑处理。
本文将围绕不能添加代码的情况,进行分析这种极端情况。
Android Studio虽然提供了java调用栈的录制和java 堆的转储。但是他们无法同时使用,导致在时间轴上面的对比无法完成。但是Perfetto提供了类似的功能。
接下来将以Perfetto为工具,首先介绍同时录制java的调用栈和java堆,在逻辑上进行比较,得出泄漏点的调用栈。然后在一定时间间隔上,对java调用栈和java堆进行差分比较,得出泄漏点的调用栈。
Perfetto同时录制堆栈和heap dump
在android 如何分析应用的内存(十三)——perfetto一文中我们介绍了Perfetto的使用方法。接下来我们将使用常规模式,来同时录制java heap和java callstack。
adb shell perfetto \
-c - --txt \
-o /data/misc/perfetto-traces/trace \
<<EOF
buffers: {
size_kb: 63488
fill_policy: DISCARD
}
buffers: {
size_kb: 2048
fill_policy: DISCARD
}
data_sources: {
config {
name: "android.packages_list"
target_buffer: 1
}
}
data_sources: {
config {
name: "android.heapprofd"
target_buffer: 0
heapprofd_config {
sampling_interval_bytes: 4096
process_cmdline: "com.example.test_malloc"
shmem_size_bytes: 8388608
block_client: true
## 只录制com.android.art的堆
heaps: "com.android.art"
}
}
}
## 增加了第二个数据源
data_sources: {
## 数据源配置
config {
## 名字必须为"android.java_hprof"
name: "android.java_hprof"
## 指定目标buffer,关于目标buffer的含义见android 如何分析应用的内存(十三)
target_buffer: 0
## java_hprof的配置
java_hprof_config {
## dump的进程名为:"com.example.test_malloc"
process_cmdline: "com.example.test_malloc"
}
}
}
## 时间修改为60s
duration_ms: 60000
EOF
在上面的命令中,我们新增了一个data_source,并且将其指定为录制java heap。同时还有另外一个data_source即android.heapprofd。它会录制指定进程的堆内存,因为我们暂时不需要native堆,所以在heaps中设置了“com.android.art”
关于Perfetto配置文件的说明见:android 如何分析应用的内存(十三)——perfetto
分析结果
输入上面的命令,然后操作APP,60s之后,会在/data/misc/perfetto-traces/trace中形成结果文件,将其pull出来,用https://ui.perfetto.dev/打开即可。如下图
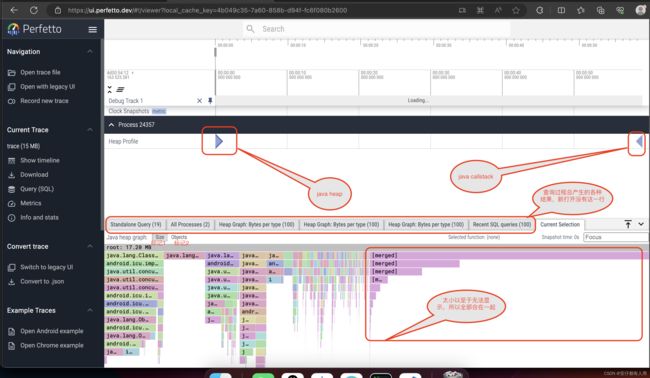
图中:
- 标记1:到GC root的这条路的retained size大小。
- 标记2:到GC root的这条路径的Retained set。
注意:某个对象的Retained size可以理解为:回收这个对象之后,会回收Retained size这么多内存。某个对象的Retained set可以理解为:回收这个对象之后,被它引用且能被回收的对象的集合。某个路径上的Retained size,即为这个路径上的对象的Retained size之和。某个路径上的Retained set,即为这个路径上的对象的Retained set之和
Retained size的计算见:
注意注意:在上面的操作中,我故意放置了一个小小的漏洞。仔细观察图中,两个菱形的位置,一个在开头,一个在结尾。为了进行泄露点的逻辑分析dump heap和callstack,这两个棱形应该越靠近越好,因此,对上面的配置,调整如下:
adb shell perfetto \
-c - --txt \
-o /data/misc/perfetto-traces/trace \
<<EOF
buffers: {
## 将buffer增大1000倍,否则出现Perfetto ui解析出错
size_kb: 63488000
fill_policy: DISCARD
}
buffers: {
size_kb: 2048
fill_policy: DISCARD
}
data_sources: {
config {
name: "android.packages_list"
target_buffer: 1
}
}
data_sources: {
config {
name: "android.heapprofd"
target_buffer: 0
heapprofd_config {
sampling_interval_bytes: 4096
process_cmdline: "com.example.test_malloc"
shmem_size_bytes: 8388608
heaps: "com.android.art"
continuous_dump_config {
## 10s之后,才开始第一次dump
dump_phase_ms: 10000
## 每隔2s,dump一次
dump_interval_ms: 10000
}
}
}
}
data_sources: {
config {
name: "android.java_hprof"
target_buffer: 0
java_hprof_config {
process_cmdline: "com.example.test_malloc"
continuous_dump_config {
## 10s后,才开始第一次dump
dump_phase_ms: 10000
## 每隔2s,dump一次
dump_interval_ms: 10000
}
}
}
}
## 总时间变成 30s
duration_ms: 30000
EOF
注意:这里dump heap时,需要先启动APP,再运行Perfetto。
得到的结果如下图:
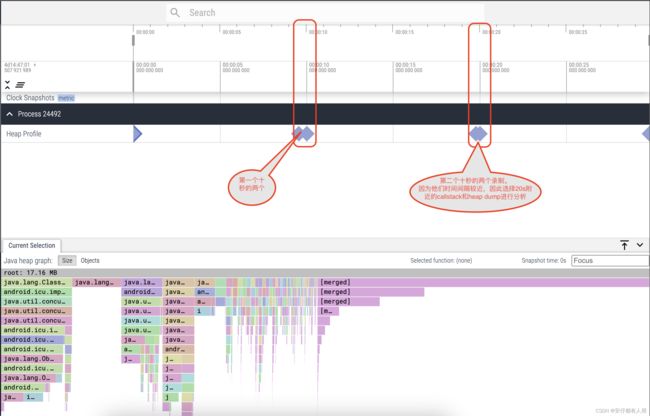
调整时间轴,将两个重合的棱形,放大一点如下图:
图中,点击第二个棱形图标,出现从GC root的火焰图。
晴天霹雳!!!发现Perfetto在我的Pixel 3上面拉取出来的java heap dump并没有正确的计算引用链。导致我的火焰图,没有正确的反应内存泄露。经过深入分析,发现问题出现在Classloader和它加载的对象之间的引用链没有正确处理,导致了一些从GC root可达的对象,变成了不可达,即已经是泄露的对象,变成了没有泄露。
我们的目标是为了同时采集callstack和heap dump进行逻辑分析。因此我们可以忽略这种影响,直接操作数据库即可。
Heap dump的数据库表
java heap dump只会涉及到3张表:
- heap_graph_reference:存储引用
- heap_graph_object:存储对象
- heap_graph_class:存储类
为了能够直观的展示这些表的结构。下面使用工具,将trace文件的数据库导出来,然后使用数据库UI工具进行查看
导出数据库
使用如下的命令进行数据库的导出。
./trace_processor /Users/biaowan/Documents/trace_single_conti -e ~/Documents/trace_to_sqlite.db
本次实验,使用了DBeaver的社区版,进行数据库的查看。打开导出的数据库:trace_to_sqlite.db.如下图:

表说明
在真正使用之前,需要对表的各个列做一个说明:
heap_graph_reference
- id 本引用唯一的id
- type 本表名字,即heap_graph_reference
- reference_set_id 引用对象集ID,如果这个引用是在某个对象中,那么在heap_graph_object中的reference_set_id和此值相等
- owned_id 被引用的对象的id,即heap_graph_object的id
- owner_id 使用这个引用的对象的id
- field_name 这个引用的字段名
- field_type_name 这个引用的字段的类型名
- deobfuscated_field_name 反混淆之后的字段名
heap_graph_object
- id 本对象的id
- type 本表的名字
- upid pid
- graph_sample_ts 采样时间,即dump这个对象的时间
- self_size 自身大小
- native_size native大小
- reference_set_id 本对象引用的其他对象的应用集id
- reachable 从根对象是否可达,如果可达,则不可回收,否则,可回收(有bug)
- type_id 本对象对应的class的id
- root_type 如果不为空,则说明是根对象
heap_graph_class
- id 本class的id
- type 本表名字
- name 本class的名字
- deobfuscated_name 本class反混淆之后的名字
- location 本class在什么地方
- classloader_id classloader的id,这个id即为heap_graph_object的id
- superclass_id 父类id,对应于本表的id
- kind 类型
有了这些表的使用说明之后,我们就可以根据自己的需要使用SQL查询语句查看堆中的对象。
接下来,我们先简单的查看,在第二个heap dump中,哪些对象占据的内存空间最大。
查看第二个堆中的内存占用情况
注意:为什么要使用第二个堆?因为在我们的采集数据中,是从Perfetto开始运行的第十秒开始采集,然后再过十秒再次采集。而第一次采集的数据,因为callstack和heap时间间隔较大,所以不采用它。
选取正确的时间戳
使用SQL语句如下:
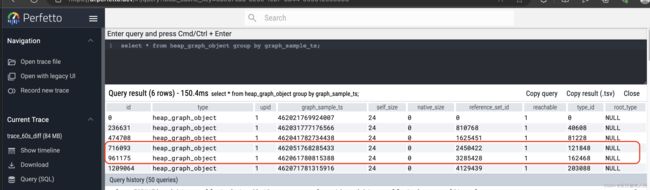
select * from heap_graph_object group by graph_sample_ts;
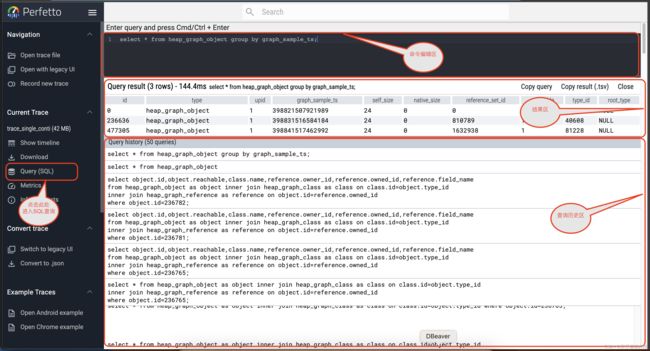
从图中,我们可以看到有三个时间段。分别对应于火焰图中的三个菱形。其余的菱形为callstack
我们要分析的就是第二个采样时间即:398831516584184
将对应时间戳的堆中对象,按照类进行分类,并统计其大小,倒序输出
select class.id,sum(object.self_size) as totalSize,class.name
from heap_graph_class as class inner join heap_graph_object as object
on class.id=object.type_id
where object.graph_sample_ts=398831516584184
group by class.id
order by totalSize desc;
结果如下

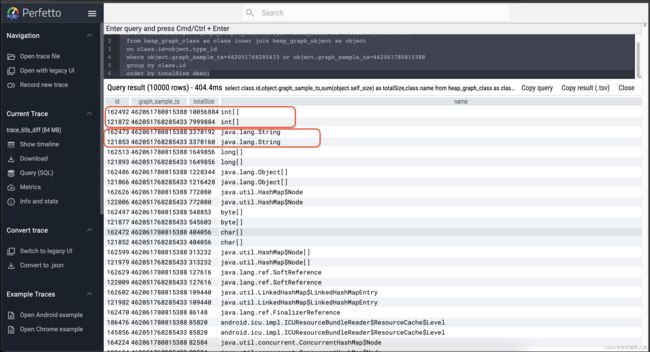
图中可以看到最大的对象类型是int[],其次为String。
注意:本次查询,即包括了能被回收的对象,也包括了不能回收的对象。因为Perfetto本身的错误,不能通过reachable字段来判断是否可回收。事实上,可以自己写一个脚本,递归处理classloader的引用关系,然后修改数据库中的reachable字段。不过我们的任务是为了找到泄漏对象和调用栈的关系。泄露对象其实已经明确了。即可以通过前面两篇的文章,来确定泄露的对象。见:
- android 如何分析应用的内存(十七)——使用MAT查看Android堆:http://t.csdn.cn/c3BfM
- android 如何分析应用的内存(十六)——使用AS查看Android堆:http://t.csdn.cn/xYGoA
如果仅仅是上面的查询结果,并不能简单的归因于内存泄露对象为int[],好在我们有AS和MAT工具可以辅助归因。随着Perfetto工具的完善(修复reachable字段的值),仅用Perfetto也可以很好的找到内存泄露点。
又因为前两篇文章和本篇文章,都是使用的一个测试APP,所以,我们已经将内存泄漏点归因于int[]了。接下来就是将这个内存泄漏点与调用栈联系起来
将泄露对象与调用栈简单的联系起来
上面小节说明了泄露对象为int[],如果同一时间在调用栈中某个调用点执行的次数最多,或者在该调用点分配的对象最大,即可简单的将其进行逻辑联系起来。认为是该调用点导致的内存泄露。
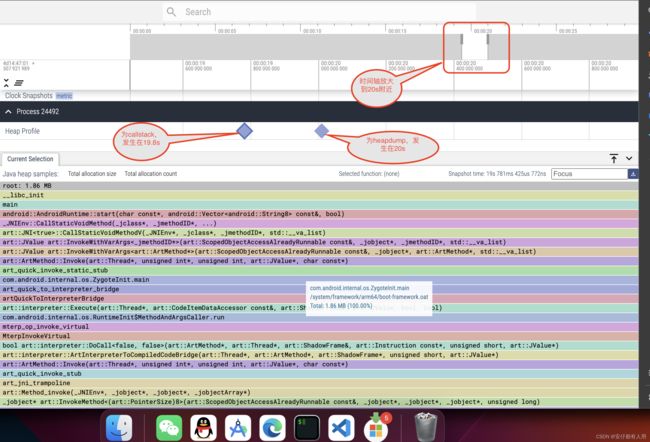
我们点击离第二个堆最近的,棱形图标,如下图:
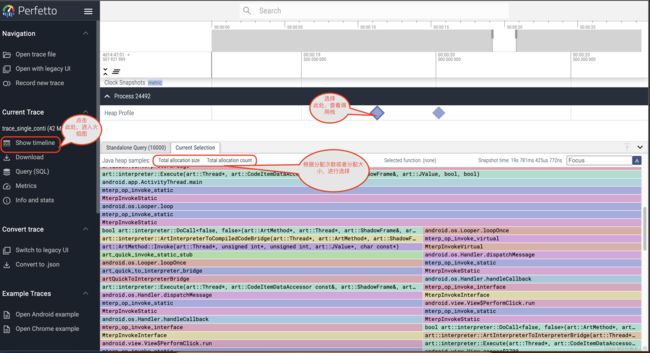
因为int[]占用了大量的空间,所以我们选择调用栈的total allocation size.如下
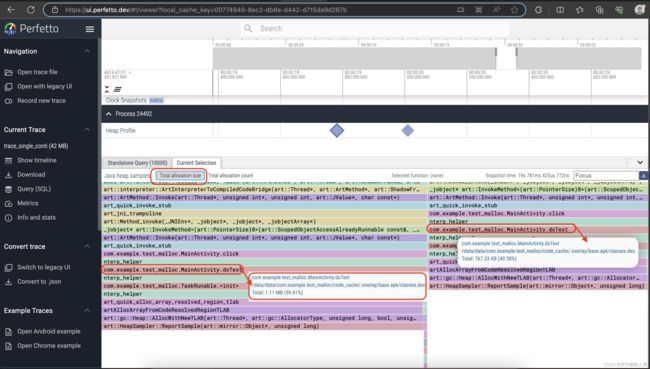
从图中,我们可以看到,doText()这个调用点,几乎占据了99%的分配大小。毫无疑问,int[]的泄露是这个doText()调用点导致的。但是这里面有两个doText(),分别占据约60%和约40%,可以肯定这两个调用点,都导致了内存的泄露。
然后查看其火焰图,可以找到整个调用栈和调用线程。
思考:一切看起来很简单,对吗?是否思考过一个问题——他们的时间点真的对的上吗?或者他们的时间点真的合理吗?
事实上:java的heap dump的数据,是从程序开始运行到dump点的堆中数据。而heapprofd中的数据(即这里的java调用栈)为Perfetto开始运行,到录制点之间的数据。画个图如下
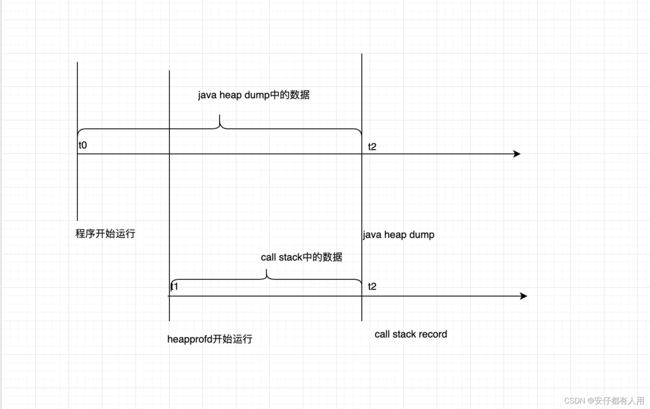
解决办法:可能读者会想到将Perfetto在app启动之前启动,这样他们开始计算的时间点都是从app启动的时候开始了。然而,根据实测,要抓取java heap,必须先app启动,所以此种方法不可取。真正要解决这种问题,我们只需要再次进行一次录制,然后分别对callstack和heap进行差分比较即可。
用差分比较解决解决剩下难以定位的问题
用差分比较,可以排除,上述时间起始点不同步带来的干扰,同时还能排除,线程过多调用栈过杂带来的干扰。接下来看看使用步骤
重新录制更长时间段的内存数据和调用栈
将上面的配置文件的总时长更改为60s。然后重新录制,得如下图所示的情况
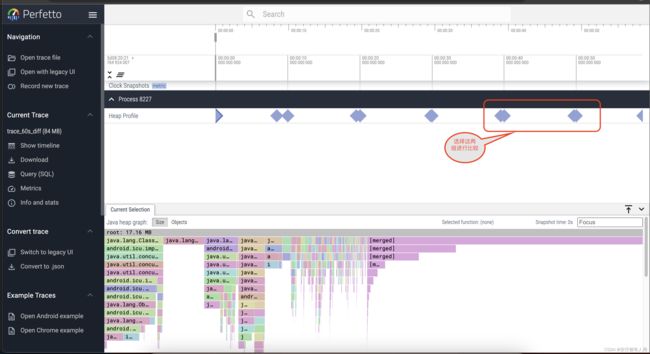
如上图我们采样了大约6组数据,现在我们选择第40s和第50s的两组进行差分比较分析。当然也可以选择其他组进行比较。
差分分析两个堆中查看增加内容最多的数据
- 先找出两者之间的时间。如下
select * from heap_graph_object group by graph_sample_ts;
根据结果我们选择上图的两个时间,分别为:462051768285433和462061780815388
- 将两个时间上的堆做减法,留下40s到50s中增加的对象。
为了对两个表有一个感性的认知,可以执行下面的指令,进行查看
select class.id,object.graph_sample_ts,
sum(object.self_size) as totalSize,class.name
from heap_graph_class as class inner join heap_graph_object as object
on class.id=object.type_id
where object.graph_sample_ts=462051768285433 or
object.graph_sample_ts=462061780815388
group by class.id
order by totalSize desc;
从图中可以看到,不同时间段上对象的大小之和。
接下来,将50s和40s之间的堆,进行相减,如下:
select t2.totalSize - COALESCE(t1.totalSize,0) as diff,t2.name
from (
select class.id,object.graph_sample_ts,
sum(object.self_size) as totalSize,class.name
from heap_graph_class as class inner join heap_graph_object as object
on class.id=object.type_id
where object.graph_sample_ts=462061780815388
group by class.id,object.graph_sample_ts
order by totalSize desc
) as t2 left join (
select class.id,object.graph_sample_ts,
sum(object.self_size) as totalSize,class.name
from heap_graph_class as class inner join heap_graph_object as object
on class.id=object.type_id
where object.graph_sample_ts=462051768285433
group by class.id,object.graph_sample_ts
order by totalSize desc
) as t1 on t2.name = t1.name
order by diff desc
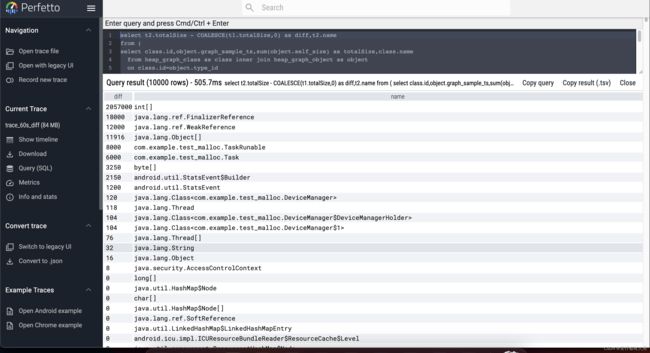
为了更好的计算它们所占的百分比,我在这里求总和之后,直接写入插入语句中,如下:
select (t2.totalSize - COALESCE(t1.totalSize,0))/2119766.0
as percentage,t2.totalSize - COALESCE(t1.totalSize,0) as diff,t2.name
from (
select class.id,object.graph_sample_ts,
sum(object.self_size) as totalSize,class.name
from heap_graph_class as class inner join heap_graph_object as object
on class.id=object.type_id
where object.graph_sample_ts=462061780815388
group by class.id,object.graph_sample_ts
order by totalSize desc
) as t2 left join (
select class.id,object.graph_sample_ts,
sum(object.self_size) as totalSize,class.name
from heap_graph_class as class inner join heap_graph_object as object
on class.id=object.type_id
where object.graph_sample_ts=462051768285433
group by class.id,object.graph_sample_ts
order by totalSize desc
) as t1 on t2.name = t1.name
order by percentage desc
如下图
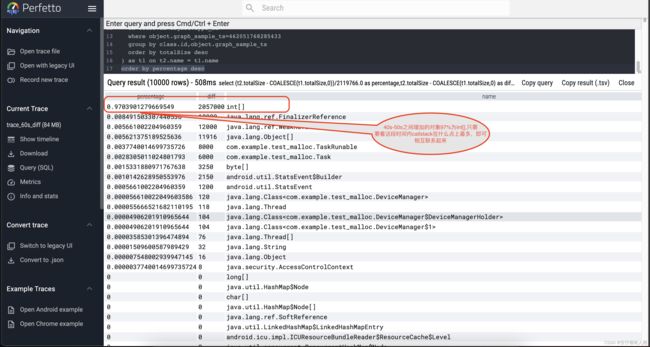
从图中我们看到了97%的对象为int[],接下来只要比较40s到50s之间,什么样的调用点被调用的次数最多,或者该调用点分配的内存最多,那么这个调用点大概率就是产生这97%的int[]的地方
差分分析同时间段的调用栈
在介绍如何查看调用栈的差分之前,我们需要知道跟调用栈相关的数据库中的表,分别有下面三张表:
- heap_profile_allocation:存储分配
- stack_profile_frame:存储栈帧名
- stack_profile_callsite:存储调用点
当然除了上面三个表以外,还有其他的表,但是对于我们的分析关系不大,故不在啰嗦,查看所有表的信息可参阅:https://perfetto.dev/docs/analysis/sql-tables
调用栈表说明
heap_profile_allocation
- id 唯一id
- type 本表名
- ts 采样时间
- upid pid
- heap_name 堆名字
- callsite_id 调用点id,即stack_profile_callsite的di
- count 分配的次数,正数就是该调用点的分配次数,负数就是该调用点的释放次数
- size 分配的大小,同样有正负之分,正数表示分配大小,负数表示释放大小
stack_profile_frame
- id 唯一id
- type 本表名
- name 函数名
- mapping 该函数映射到哪一个库,如so,.dex 即stack_profile_mapping的id
- rel_pc 相对于映射库的pc值
- symbol_set_id 该函数名对应的符号表的id,即stack_profile_symbol的id
- deobfuscated_name 反混淆之后的名字
stack_profile_callsite
- id 唯一id
- type 本表名
- depth 到调用栈顶部的距离,多一个函数,则深度加一
- parent_id 本调用点的父函数的调用点id。即stack_profile_callsite的id
- frame_id 帧id,即stack_profile_frame的id
查看各个采样时间
使用如下的命令查看。
select *,sum(count) as totalCount ,sum (size) as totalSize
from heap_profile_allocation group by ts;
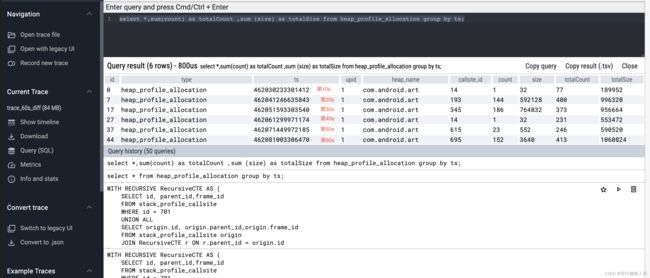
从图中可以看到,整个数据被分成了6个时间段,刚好对应于火焰图的六菱形。在火焰图中,每个棱形表示的是从开始抓取到棱形位置对应时间的所有分配。
然而数据库中的每个时间点,表示的是从上一个时间点到本次抓取的所有数据,因此查看40s到50s之间的数据,只需要看第50s的数据即可。也就是倒数第二行。
查看40s和50s的调用详细情况
为了便于理解,下面的语句,将40s和50s的两个堆都列出来分析。如下
select *
from (
select *
from heap_profile_allocation
where ts = 462061299971174
order by count desc
) as t1
union all
select *
from (
select *
from heap_profile_allocation
where ts = 462071449972185
order by count desc
) as t2
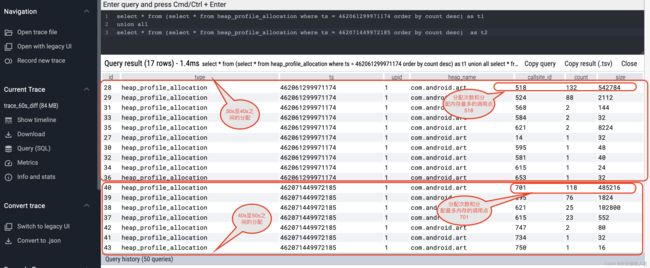
上图列出了30-40区间的情况,以及40-50区间的情况,稍微计算下各个调用点分配的内存占比,可以知道:701调用点的内存分配占据了40s到50s所有分配的82% 因此我们可以大胆的下结论——40s到50s之间的内存泄露由701分配点导致。
查看701分配点的调用栈
使用下面的递归语句,查看整个701的调用栈,如下
WITH RECURSIVE RecursiveCTE AS (
SELECT id, parent_id,frame_id
FROM stack_profile_callsite
WHERE id = 701
UNION ALL
SELECT origin.id, origin.parent_id,origin.frame_id
FROM stack_profile_callsite origin
JOIN RecursiveCTE r ON r.parent_id = origin.id
)
SELECT result.id,result.parent_id,frame.name
FROM RecursiveCTE as result inner join stack_profile_frame as frame
on frame.id=result.frame_id
order by result.id desc;
如下图
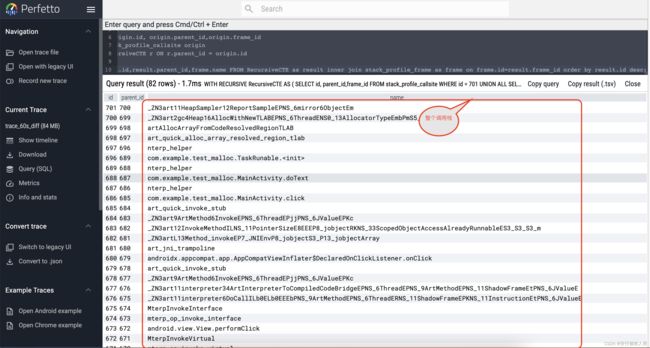
直接观察即可看到40s至50s之间泄露对象int[]由上图的调用栈产生泄露。
注意,使用同样的分析方法,查看调用点518,依然会得出相同的结论,不过他们发生在30s至40s之间。同样的操作步骤,不再继续举例
至此,使用perfetto进行内存分析,已经介绍完毕。
内存方法大总结
万事大吉,关于Android的内存分析已经介绍完毕。现在对前面的所有文章进行一个总结:
native篇
- 第零个工具xdd:只能查看任意内存
- 第一个工具gdb:它可以查看:寄存器,和任意位置的内存,分析coredump,能查看栈情况,不能查看堆情况
- 第二个工具lldb:它可以查看:寄存器,和任意位置的内存,分析coredump,能查看栈情况,不能查看堆情况
- 第三个工具自定义malloc:只能查看堆情况,且查看的范围较小,几乎只有自己编译的代码
- 第四个工具malloc hook:能查看所有的堆分配情况
- 第五个工具malloc统计和libmemunreachable:可以查看所有堆分配情况
- 第六个工具malloc debug和libc回调:能查看所有堆分配情况
- 第七个工具ASan/HWASan:只能查看linux的堆分配情况,无法查找android的分配情况,列在此处只是为了知识的完整性
- 第八个工具perfetto:只能查看堆内存分配情况
java篇
- 第零个工具jdb:查看堆帧,本地变量,锁,对象
- 第一个工具java debugger for vscode:查看堆栈,本地变量,对象
- 第二个工具Android studio:查看堆,对象引用,Retained size,调用栈
- 第三个工具MAT:查看堆,对象引用,Retained size ,还能进行堆间差分分析
- 第四个工具Perfetto:查看堆,对象引用,Retained size,调用栈,还能在堆和调用栈之间进行差分分析
本系列完。