《两日算法系列》之第四篇:隐马尔可夫模型HMM
目录
-
-
-
- 1. 定义与假设
- 2. 相关概念的表示
- 3. 三个基本问题
-
- 3.1. 概率计算问题
- 3.2. 学习问题
- 3.3. 预测问题
- 总结
-
-
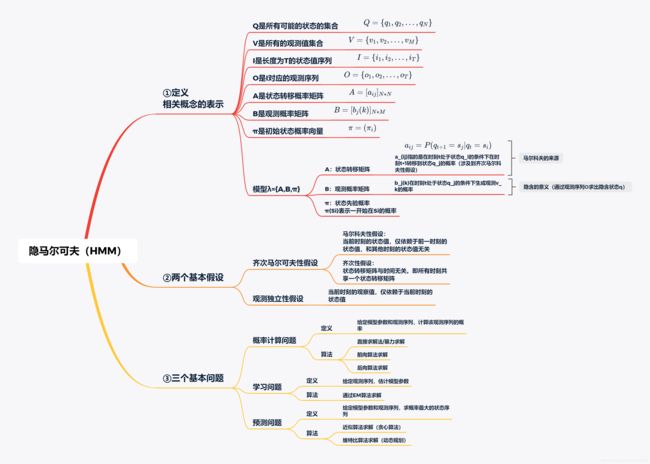
1. 定义与假设
李雷雷所在城市的天气有三种情况,分别是:晴天、阴天、雨天,而且一年四季的天气就在这三种之间变换。因为近期不便出门,所以李雷雷每天的活动只有看书和打球两种。
韩梅梅在国外上学期间,只能通过李雷雷的朋友圈观察他每天都参与了什么活动,而并不知道李雷雷所在城市的天气是什么样的
但是通过观察,韩梅梅发现李雷雷所在城市的天气是有一点点规律的,比如:前一天如果是晴天,那么后一天是晴天的概率会比较大;如果前一天是雨天,后一天是雨天的概率会比较大。
另外,通过长期的观察总结,韩梅梅发现李雷雷会根据当天的天气情况,决定进行什么样的活动。比如:今天是阴天的话,李雷雷很有可能会选择一个人去打球;而如果今天是雨天的话,李雷雷很有可能选择在家看书;而如果是晴天的话, 那就看情况而定了。
基于上面的种种条件,韩梅梅构建了一个隐马尔科夫模型,在只通过李雷雷每天朋友圈的活动猜测他所在城市的天气情况。
ok,上面的就是一个隐马尔可夫模型HMM,HMM的英文全称是Hidden Markov Model。上面的例子用HMM专业术语描述如下:
HMM的基本定义:HMM是用于描述隐藏的状态序列和显性的观测序列组合而成的双重随机过程。 在前面的例子中,李雷雷所在城市的天气是隐藏的状态序列,这个序列我们是观测不到的;而李雷雷每天的活动是观测序列,这个序列我们可以观测到。这两个序列都是随机序列。
HMM的假设一:马尔科夫性假设。当前时刻的状态值,仅依赖于前一时刻的状态值,和其他时刻的状态值无关。 每天的天气情况,会和前一天的天气有关系
HMM的假设二:齐次性假设。状态转移矩阵与时间无关。即所有时刻共享一个状态转移矩阵。 李雷雷所在城市的天气一年四季都是三种之一。
HMM的假设三:观测独立性假设。当前时刻的观察值,仅依赖于当前时刻的状态值。 李雷雷会根据当天的天气情况,决定今天进行什么样的活动。
HMM的应用目的:通过可观测到的数据,预测不可观测到的数据。 韩梅梅想通过李雷雷每天的活动,猜测他所在城市的天气情况。
2. 相关概念的表示
隐马尔可夫模型由初始概率分布、状态转移概率分布以及观测概率分布确定,其中,隐马尔可夫模型的形式定义如下:
(1)Q是所有可能的状态的集合
Q = { q 1 , q 2 , . . . , q N } Q = \lbrace q_1,q_2,...,q_N\rbrace Q={q1,q2,...,qN}
其中,N表示有N种状态值 。例如天气的状态值集合为{晴天,阴天,雨天}
(2) V是所有的观测值集合
V = { v 1 , v 2 , . . . , v M } V = \lbrace v_1,v_2,...,v_M \rbrace V={v1,v2,...,vM}
其中,M表示可能的观测数。例如李雷雷的观测值集合为{看书,打球}。
(3)I是长度为T的状态值序列
I = { i 1 , i 2 , . . . , i T } I = \lbrace i_1,i_2,...,i_T \rbrace I={i1,i2,...,iT}
状态值序列表示每天的城市天气状态值构成的序列。例如{晴,晴,阴}
(4)O是I对应的观测序列
O = { o 1 , o 2 , . . . , o T } O = \lbrace o_1,o_2,...,o_T \rbrace O={o1,o2,...,oT}
观测序列表示每天的城市天气状态值对应的李雷雷活动状态构成的序列。例如{看书,看书,打球}
(5)A是状态转移概率矩阵
A = [ a i j ] N ∗ N A =[a_{ij}]_{N * N} A=[aij]N∗N
其中:
a t j = P ( i t + 1 = q j ∣ i t = q i ) , i = 1 , 2 , . . . , N ; j = 1 , 2 , . . . , N a_{tj} = P(i_{t+1} = q_j | i_t=q_i), \ \ \ \ i=1,2,...,N;\ \ \ j=1,2,...,N atj=P(it+1=qj∣it=qi), i=1,2,...,N; j=1,2,...,N
指的是在时刻t处于状态 q i q_i qi的条件下在时刻t+1转移到状态 q j q_j qj的概率。例如今天是晴天,那么明天可能会是{晴天,阴天,雨天}中的一种,其中明天会有a1的概率是晴天,a2的概率是阴天,a3的概率是雨天,对应此时的a就是一个状态转移矩阵。
(6)B是观测概率矩阵
B = [ b j ( k ) ] N ∗ M B =[b_j(k)]_{N * M} B=[bj(k)]N∗M
其中:
b j ( k ) = P ( o t = v k ∣ i t = q j ) , k = 1 , 2 , . . . , M ; j = 1 , 2 , . . . , N b_j(k) = P(o_t=v_k | i_t=q_j), \ \ \ \ k=1,2,...,M;\ \ \ j=1,2,...,N bj(k)=P(ot=vk∣it=qj), k=1,2,...,M; j=1,2,...,N
指的是在时刻t处于状态 q j q_j qj的条件下生成观测 v k v_k vk的概率。例如今天是阴天,那么李雷雷的活动就会是{看书,打球}中的一种,其中会有b1的概率去看书,b2的概率去打球,对应此时的b就是观测概率矩阵。
(7)初始状态概率向量
π = ( π i ) \pi = (\pi_i) π=(πi)
其中
π i = P ( i 1 = q i ) , i = 1 , 2 , . . . , N \pi_i = P(i_1=q_i), \ \ \ \ i=1,2,...,N πi=P(i1=qi), i=1,2,...,N
是时刻t=1处于状态 q i q_i qi的概率。
ok,上述的后三个定义你可能看的似懂非懂,相信看了下面这个例子你应该秒懂:
状态转移概率矩阵A:
表示在时刻t处于状态 q i q_i qi的条件下在时刻t+1转移到状态 q j q_j qj的概率
| 晴天 | 阴天 | 雨天 | |
|---|---|---|---|
| 晴天 | 0.5 | 0.2 | 0.3 |
| 阴天 | 0.3 | 0.5 | 0.2 |
| 雨天 | 0.2 | 0.3 | 0.5 |
观测概率矩阵B:
表示在时刻t处于状态 q j q_j qj的条件下生成观测 v k v_k vk的概率
| 看书 | 打球 | |
|---|---|---|
| 晴天 | 0.5 | 0.5 |
| 阴天 | 0.4 | 0.6 |
| 雨天 | 0.7 | 0.3 |
初始概率状态向量π:
表示在初始时刻状态 q i q_i qi的概率
| 天气 | 初始概率 |
|---|---|
| 晴天 | 0.2 |
| 阴天 | 0.4 |
| 雨天 | 0.4 |
3. 三个基本问题
在学习HMM的过程中,需要研究三个问题,分别是:
概率计算问题: 给定模型参数和观测序列,计算该观测序列的概率。
学习训练问题: 给定观测序列,估计模型参数
解码预测问题: 给定模型参数和观测序列,求概率最大的状态序列
3.1. 概率计算问题
给定模型参数 λ = ( A , B , π ) \lambda=(A,B,\pi) λ=(A,B,π)和观测序列 O = ( o 1 , o 2 , … , o T ) O=(o_1,o_2,\dots,o_T) O=(o1,o2,…,oT),计算观测序列O出现的概率 P ( O , I ∣ λ ) P(O,I|\lambda) P(O,I∣λ)。
3.1.1. 暴力求解
思路:
-
列举所有可能的长度为T的状态序列 I I I
-
求各个状态序列 I I I与观测序列的联合概率 P ( O , I ∣ λ ) P(O,I|\lambda) P(O,I∣λ)
-
所有可能的状态序列求和 ∑ i P ( O , I ∣ λ ) \sum_iP(O,I|\lambda) ∑iP(O,I∣λ)
步骤:
- 目标是求 O O O与 I I I同时出现概率 P ( O , I ∣ λ ) = P ( O ∣ I , λ ) ⋅ P ( I ∣ λ ) P(O,I|\lambda)=P(O|I,\lambda)\cdot P(I|\lambda) P(O,I∣λ)=P(O∣I,λ)⋅P(I∣λ)
- 求解 P ( I ∣ λ ) P(I|\lambda) P(I∣λ)
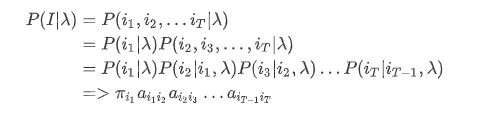
其中 P ( i 1 ∣ λ ) P(i_1|\lambda) P(i1∣λ)是初始概率 π i 1 \pi_{i_1} πi1, P ( i 2 ∣ i 1 , λ ) P(i_2|i_1,\lambda) P(i2∣i1,λ)是从状态 i 1 i1 i1转换到 i 2 i2 i2的概率
-
求解 P ( O ∣ I , λ ) P(O|I,\lambda) P(O∣I,λ)
这个的意思是在固定的状态序列 I I I,求观测序列 O O O的概率
P ( O ∣ I , λ ) = b i 1 ( o 1 ) b i 2 ( o 2 ) ⋯ b i T ( o T ) P(O|I,\lambda) = b_{i_1}(o_1)b_{i_2}(o_2)\cdots b_{i_T}(o_T) P(O∣I,λ)=bi1(o1)bi2(o2)⋯biT(oT)
-
将②和③代入①中求出 P ( O , I ∣ λ ) P(O,I| \lambda) P(O,I∣λ)
-
进行概率求和
带入计算之后,发现计算量是特别大的,大概是 O ( T N T ) O(TN^T) O(TNT)阶,可行是而可行,但是因为巨大的计算量,并不值得推广。
相应的,可以通过以下两种方式较少计算量,从而求出观测序列出现的概率
3.1.2. 前向算法
暴力求解是直接计算隐状态,相当于一传十十传百的效果
前向算法在一传十之后会重新计算,也就是计算前一项的概率分布当作当前节点的观测概率,然后继续下一步,所以前向算法的计算量为 O ( T N 2 ) O(TN^2) O(TN2),远少于直接计算法。
先来看一下前向算法的计算:
同样的,给定模型参数 λ = ( A , B , π ) \lambda=(A,B,\pi) λ=(A,B,π)和观测序列 O = ( o 1 , o 2 , … , o T ) O=(o_1,o_2,\dots,o_T) O=(o1,o2,…,oT),计算观测序列O出现的概率 P ( O , I ∣ λ ) P(O,I|\lambda) P(O,I∣λ)。
这里需要引入一个定义:
给定隐马尔可夫模型 λ \lambda λ,定义到时刻t部分观测序列为 o 1 , o 2 , . . . , o t o_1,o_2,...,o_t o1,o2,...,ot且状态为 q i q_i qi的概率为前向概率,记作:
α t ( i ) = P ( o 1 , o 2 , . . . , o t , i t = q i ∣ λ ) \alpha_t(i) = P(o_1,o_2,...,o_t, i_t=q_i|\lambda) αt(i)=P(o1,o2,...,ot,it=qi∣λ)
基于观测节点的计算公式,我们知道①通过当前观测节点的概率与状态转移矩的乘积算出下一个状态节点的概率,②通过下一个状态节点的概率与观测概率矩阵的乘积算出下一个观测节点的概率。
在前向算法中,不同的是通过计算当前时刻前向概率与下一时刻观测序列的联合概率,再通过联合概率与观测概率的乘积计算下一个前向概率
写成公式是这样的:
①初值
α 1 ( i ) = π i b i ( o 1 ) , i = 1 , 2 , . . . , N \alpha_1(i) = \pi_ib_i(o_1), \ \ i=1,2,...,N α1(i)=πibi(o1), i=1,2,...,N
②递推,对t=1,2,…,T-1,
α t + 1 ( i ) = [ ∑ j = 1 N α t ( j ) a j i ] b i ( o t + 1 ) , i = 1 , 2 , . . . , N \alpha_{t+1}(i) = \begin{bmatrix}\sum_{j=1}^N \alpha_t(j)a_{ji}\end{bmatrix} b_i(o_{t+1}), \ \ i=1,2,...,N αt+1(i)=[∑j=1Nαt(j)aji]bi(ot+1), i=1,2,...,N
③终止
P ( O ∣ λ ) = ∑ j = 1 N α T ( i ) P(O|\lambda) = \sum_{j=1}^N \alpha_T(i) P(O∣λ)=j=1∑NαT(i)
前向算法主要考虑前一个状态节点的概率(可想象成初始节点的概率),到达当前状态节点的转移概率(转移矩阵),当前状态节点和观测节点之间的关系(观测概率矩阵),将观测的各种可能路径综合起来(求和)当做当前观测节点的概率,依次类推,一步步走到终点。
3.1.3. 后向算法
同前向算法,在后向算法中定义了后向概率:
给定隐马尔可夫模型 λ \lambda λ,定义到时刻t状态为 q i q_i qi的条件下,从+1到T的部分观测序列为 o t + 1 , o t + 2 , . . . , o T o_{t+1},o_{t+2},...,o_T ot+1,ot+2,...,oT且状态为 q i q_i qi的概率为后向概率,记作:
β t ( i ) = P ( o t + 1 , o t + 2 , . . . , o T , i t = q i ∣ λ ) \beta_t(i) = P(o_{t+1},o_{t+2},...,o_T, i_t=q_i|\lambda) βt(i)=P(ot+1,ot+2,...,oT,it=qi∣λ)
用递推的方法求得后向概率 β t ( i ) \beta_t(i) βt(i)及观测序列概率P(O|λ)
前向算法是从前往后,后向算法是从后往前,一句话总计一下:
前向算法:现在这样,要得到result,往后能怎么走?(求果)
后向算法:现在这样的result,是当初怎么走造成的?(追因)
例如,在给定模型下,观测为O = ( 红,白,红 ) 的概率(其他参数在此省略)
前向算法是先计算第一个红球的概率(从1,2,3号盒子中取出),然后在此基础上计算第二个白球的概率(同样是1,2,3号盒子中取出),最后是第三个红球的概率
后向算法是先计算第三个红球的概率(从1,2,3号盒子中取出),然后在此基础上计算第二个白球的概率(同样是1,2,3号盒子中取出),最后是第一个红球的概率。
3.2. 学习问题
给定观测序列 O = ( o 1 , o 2 , … , o T ) O=(o_1,o_2,\dots,o_T) O=(o1,o2,…,oT),估计模型参数 λ = ( A , B , π ) \lambda=(A,B,\pi) λ=(A,B,π)
这个问题,有点类似前面说到的EM算法求解,同样是知道最终结果,求模型最有可能的参数。
那么根据EM算法的求解步骤,我们可以这样去解决学习问题:
-
①确定完全数据的对数似然函数
-
②EM算法的E步:求Q函数
-
③EM算法的M步:极大化Q函数,求模型参数A,B,π
具体步骤可以参考EM算法:《两日算法系列》之第三篇:EM聚类
3.3. 预测问题
给定模型参数 λ = ( A , B , π ) \lambda=(A,B,\pi) λ=(A,B,π)和观测序列 O = ( o 1 , o 2 , … , o T ) O=(o_1,o_2,\dots,o_T) O=(o1,o2,…,oT),求概率最大的状态序列 I = { i 1 , i 2 , . . . , i T } I = \lbrace i_1,i_2,...,i_T \rbrace I={i1,i2,...,iT}
**3.3.1. 近似算法 **
近似算法的思想是,在每个时刻t选择在该时刻最有可能出现的状态 i t i_t it,从而选择得到一个状态序列 I I I,将它作为预测的结果。
给定隐马尔可夫模型λ和观测序列O,在时刻t处于状态 q i q_i qi的概率 γ t ( i ) \gamma_t(i) γt(i)是:
γ t ( i ) = α t ( i ) β t ( i ) P ( O ∣ λ ) = α t ( i ) β t ( i ) ∑ j = 1 N α t ( j ) β t ( j ) \gamma_t(i) = \frac{\alpha_t(i)\beta_t(i)}{P(O|\lambda)} = \frac{\alpha_t(i)\beta_t(i)}{\sum_{j=1}^N\alpha_t(j)\beta_t(j)} γt(i)=P(O∣λ)αt(i)βt(i)=∑j=1Nαt(j)βt(j)αt(i)βt(i)
近似算法的原理有点类似于贪心算法,在每一步中选择最有可能出现的状态序列,所以会导致最终预测的状态序列并不一定是最优。
3.3.2. 维特比算法
相比起贪心算法的局部最优,动态规划可以实现全局最优解,而维特比算法正是基于动态规划思想的。我们先从最开始的例子来了解维特比算法
现在已知的模型参数有初始概率状态向量π,状态转移矩阵A,观测概率矩阵B,已知李雷雷在3天的活动序列为:{看书、打球、看书},求最有可能的天气序列情况,模型参数分别如下:
初始概率状态向量π:
表示在初始时刻状态 q i q_i qi的概率
| 天气 | 初始概率 |
|---|---|
| 晴天 | 0.2 |
| 阴天 | 0.4 |
| 雨天 | 0.4 |
状态转移概率矩阵A:
表示在时刻t处于状态 q i q_i qi的条件下在时刻t+1转移到状态 q j q_j qj的概率
| 晴天 | 阴天 | 雨天 | |
|---|---|---|---|
| 晴天 | 0.5 | 0.2 | 0.3 |
| 阴天 | 0.3 | 0.5 | 0.2 |
| 雨天 | 0.2 | 0.3 | 0.5 |
观测概率矩阵B:
表示在时刻t处于状态 q j q_j qj的条件下生成观测 v k v_k vk的概率
| 看书 | 打球 | |
|---|---|---|
| 晴天 | 0.5 | 0.5 |
| 阴天 | 0.4 | 0.6 |
| 雨天 | 0.7 | 0.3 |
维特比算法预测过程如下:
步骤①:根据模型参数,计算第一天天气的概率分布
P ( D 1 , 晴 天 , 看 书 ) = P ( D 1 , 晴 天 ) ∗ P ( 看 书 ∣ D 1 , 晴 天 ) = 0.2 ∗ 0.5 = 0.1 P(D1, 晴天,看书) = P(D1, 晴天) * P(看书 | D1,晴天) = 0.2*0.5=0.1 P(D1,晴天,看书)=P(D1,晴天)∗P(看书∣D1,晴天)=0.2∗0.5=0.1
P ( D 1 , 阴 天 , 看 书 ) = P ( D 1 , 阴 天 ) ∗ P ( 看 书 ∣ D 1 , 阴 天 ) = 0.4 ∗ 0.4 = 0.16 P(D1, 阴天,看书) = P(D1, 阴天) * P(看书 | D1,阴天) = 0.4*0.4=0.16 P(D1,阴天,看书)=P(D1,阴天)∗P(看书∣D1,阴天)=0.4∗0.4=0.16
P ( D 1 , 雨 天 , 看 书 ) = P ( D 1 , 雨 天 ) ∗ P ( 看 书 ∣ D 1 , 雨 天 ) = 0.4 ∗ 0.7 = 0.28 P(D1, 雨天,看书) = P(D1, 雨天) * P(看书 | D1,雨天) = 0.4*0.7=0.28 P(D1,雨天,看书)=P(D1,雨天)∗P(看书∣D1,雨天)=0.4∗0.7=0.28
此时我们需要保存三个序列:
- 最后时刻为晴天的最大概率序列:[晴天:0.1]
- 最后时刻为阴天的最大概率序列:[阴天:0.16]
- 最后时刻为雨天的最大概率序列:[雨天:0.28]
步骤②:根据步骤①的三个序列,模型参数A和B,计算第二天天气的概率分布
P ( D 2 , 晴 天 , 打 球 ) = m a x { P ( D 1 , 晴 天 ) ∗ P ( D 2 , 晴 天 ∣ D 1 , 晴 天 ) ∗ P ( 打 球 ∣ D 2 , 晴 天 ) P ( D 1 , 阴 天 ) ∗ P ( D 2 , 晴 天 ∣ D 1 , 阴 天 ) ∗ P ( 打 球 ∣ D 2 , 晴 天 ) P ( D 1 , 雨 天 ) ∗ P ( D 2 , 晴 天 ∣ D 1 , 雨 天 ) ∗ P ( 打 球 ∣ D 2 , 晴 天 ) P(D2, 晴天, 打球) = max \begin{cases} P(D1, 晴天) * P(D2, 晴天 | D1, 晴天) * P(打球 | D2,晴天) \\ P(D1, 阴天) * P(D2, 晴天 | D1, 阴天) * P(打球 | D2,晴天) \\ P(D1, 雨天) * P(D2, 晴天 | D1, 雨天) * P(打球 | D2,晴天) \end{cases} P(D2,晴天,打球)=max⎩⎪⎨⎪⎧P(D1,晴天)∗P(D2,晴天∣D1,晴天)∗P(打球∣D2,晴天)P(D1,阴天)∗P(D2,晴天∣D1,阴天)∗P(打球∣D2,晴天)P(D1,雨天)∗P(D2,晴天∣D1,雨天)∗P(打球∣D2,晴天)
代入数据可得:
P ( D 2 , 晴 天 , 打 球 ) = m a x ( 0.1 ∗ 0.5 ∗ 0.5 , 0.16 ∗ 0.3 ∗ 0.5 , 0.28 ∗ 0.2 ∗ 0.5 ) = m a x ( 0.025 , 0.024 , 0.028 ) = 0.028 P(D2, 晴天, 打球) = max(0.1*0.5*0.5,0.16*0.3*0.5,0.28*0.2*0.5)=max(0.025,0.024,0.028)=0.028 P(D2,晴天,打球)=max(0.1∗0.5∗0.5,0.16∗0.3∗0.5,0.28∗0.2∗0.5)=max(0.025,0.024,0.028)=0.028
同理,第二天是阴天和雨天的最大概率分别是:
P ( D 2 , 阴 天 , 打 球 ) = m a x ( 0.1 ∗ 0.2 ∗ 0.6 , 0.16 ∗ 0.5 ∗ 0.6 , 0.28 ∗ 0.3 ∗ 0.6 ) = m a x ( 0.012 , 0.048 , 0.0504 ) = 0.0504 P(D2, 阴天, 打球) = max(0.1*0.2*0.6,0.16*0.5*0.6,0.28*0.3*0.6)=max(0.012,0.048,0.0504)=0.0504 P(D2,阴天,打球)=max(0.1∗0.2∗0.6,0.16∗0.5∗0.6,0.28∗0.3∗0.6)=max(0.012,0.048,0.0504)=0.0504
P ( D 2 , 雨 天 , 打 球 ) = m a x ( 0.1 ∗ 0.3 ∗ 0.3 , 0.16 ∗ 0.3 ∗ 0.3 , 0.28 ∗ 0.5 ∗ 0.3 ) = m a x ( 0.009 , 0.0096 , 0.042 ) = 0.042 P(D2, 雨天, 打球) = max(0.1*0.3*0.3,0.16*0.3*0.3,0.28*0.5*0.3)=max(0.009,0.0096,0.042)=0.042 P(D2,雨天,打球)=max(0.1∗0.3∗0.3,0.16∗0.3∗0.3,0.28∗0.5∗0.3)=max(0.009,0.0096,0.042)=0.042
此时我们需要保存的三个序列更新为:
- 最后时刻为晴天的最大概率序列: [雨天,晴天:0.028]
- 最后时刻为阴天的最大概率序列: [雨天,阴天:0.0504]
- 最后时刻为雨天的最大概率序列: [雨天,雨天:0.042]
步骤③:根据步骤②的三个序列,模型参数A和B,计算第三天天气的概率分布
P ( D 3 , 晴 天 , 看 书 ) = m a x { P ( D 2 , 晴 天 ) ∗ P ( D 3 , 晴 天 ∣ D 2 , 晴 天 ) ∗ P ( 看 书 ∣ D 3 , 晴 天 ) P ( D 2 , 阴 天 ) ∗ P ( D 3 , 晴 天 ∣ D 2 , 阴 天 ) ∗ P ( 看 书 ∣ D 3 , 晴 天 ) P ( D 2 , 雨 天 ) ∗ P ( D 3 , 晴 天 ∣ D 2 , 雨 天 ) ∗ P ( 看 书 ∣ D 3 , 晴 天 ) P(D3, 晴天, 看书) = max \begin{cases} P(D2, 晴天) * P(D3, 晴天 | D2, 晴天) * P(看书 | D3,晴天) \\ P(D2, 阴天) * P(D3, 晴天 | D2, 阴天) * P(看书 | D3,晴天) \\ P(D2, 雨天) * P(D3, 晴天 | D2, 雨天) * P(看书 | D3,晴天) \end{cases} P(D3,晴天,看书)=max⎩⎪⎨⎪⎧P(D2,晴天)∗P(D3,晴天∣D2,晴天)∗P(看书∣D3,晴天)P(D2,阴天)∗P(D3,晴天∣D2,阴天)∗P(看书∣D3,晴天)P(D2,雨天)∗P(D3,晴天∣D2,雨天)∗P(看书∣D3,晴天)
代入数据可得:
P ( D 3 , 晴 天 , 看 书 ) = m a x ( 0.028 ∗ 0.5 ∗ 0.5 , 0.0504 ∗ 0.3 ∗ 0.5 , 0.042 ∗ 0.2 ∗ 0.5 ) = m a x ( 0.007 , 0.00756 , 0.0042 ) = 0.00756 P(D3, 晴天, 看书) = max(0.028*0.5*0.5,0.0504*0.3*0.5,0.042*0.2*0.5)=max(0.007,0.00756,0.0042)=0.00756 P(D3,晴天,看书)=max(0.028∗0.5∗0.5,0.0504∗0.3∗0.5,0.042∗0.2∗0.5)=max(0.007,0.00756,0.0042)=0.00756
同理,第三天是阴天和雨天的最大概率分别是:
P ( D 3 , 阴 天 , 看 书 ) = m a x ( 0.0028 ∗ 0.2 ∗ 0.4 , 0.0504 ∗ 0.5 ∗ 0.4 , 0.042 ∗ 0.3 ∗ 0.4 ) = m a x ( 0.00224 , 0.01008 , 0.00504 ) = 0.01008 P(D3, 阴天, 看书) = max(0.0028*0.2*0.4,0.0504*0.5*0.4,0.042*0.3*0.4)=max(0.00224,0.01008,0.00504)=0.01008 P(D3,阴天,看书)=max(0.0028∗0.2∗0.4,0.0504∗0.5∗0.4,0.042∗0.3∗0.4)=max(0.00224,0.01008,0.00504)=0.01008
P ( D 3 , 雨 天 , 看 书 ) = m a x ( 0.028 ∗ 0.3 ∗ 0.7 , 0.0504 ∗ 0.2 ∗ 0.7 , 0.042 ∗ 0.5 ∗ 0.7 ) = m a x ( 0.00588 , 0.007056 , 0.0147 ) = 0.0147 P(D3, 雨天, 看书) = max(0.028*0.3*0.7,0.0504*0.2*0.7,0.042*0.5*0.7)=max(0.00588,0.007056,0.0147)=0.0147 P(D3,雨天,看书)=max(0.028∗0.3∗0.7,0.0504∗0.2∗0.7,0.042∗0.5∗0.7)=max(0.00588,0.007056,0.0147)=0.0147
步骤④:对比步骤③的三个序列,选出概率最大的状态序列
很明显的能看到,在[0.00756, 0.01008, 0.0147]中概率最大的是0.0147,对应的状态序列为[雨天,雨天,雨天]
所以,李雷雷在3天的活动序列为:{看书、打球、看书},最有可能的天气序列为{雨天,雨天,雨天}
ok,总结一下维特比算法的思路:
①若状态值集合有N个取值,则需维护N个状态序列,以及N个状态序列对应的概率。且每个状态序列存储的是:序列最后一个时刻取值为特定状态(共N个状态)时,概率最大的状态序列
在上面的例子中,我们维护的是晴天、阴天、雨天三个状态序列,以及它们对应的概率
②从第一个时刻开始,根据状态子序列和模型参数,计算和更新N个状态序列及其概率值
在上面的例子中,对于当前时刻的晴天、阴天、雨天3个状态值,分别拼接上一时刻的状态序列和当前状态序列。例如D2晴天分别拼接D1状态序列得到:[晴天]+[晴天],[阴天]+[晴天],[雨天]+[晴天]三个新的状态序列
通过计算新状态序列的最大概率,确定最大概率对应的新状态序列为当前最有可能的状态序列,丢弃其他的新状态序列。
依次往后。
③一直迭代到最后一个时刻,对比所有状态序列的概率值 ,概率值最大的状态序列即为最大状态概率序列
总结
HMM的内容还是蛮多的,而且还不太好理解,所以在看算法的时候还是要和例子多结合,这样会容易些。
列了一下HMM的思维导图,希望对大家有用。