论文阅读:Interleaving Pre-Trained Language Models and Large LanguageModels for Zero-Shot NL2SQL Generat
摘要:
零样本NL2SQL在实现自然语言到SQL中至关重要,它能够在0注释的NL2SQL样例环境中自适应新的数据库、新的SQL语言。现有的NL2SQL研究方法要么根据带注释的数据去微调预训练模型(PLM),要么使用提示词指导大语言模型(LLM)。PLM 在模式对齐方面表现良好,但难以实现复杂推理,而 LLM 在复杂推理任务中表现出色,但无法实现精确的模式对齐。在本文中,我们提出了一个 ZeroNL2SQL 框架,它结合了 PLM 和 LLM 的互补优势,以支持零样本 NL2SQL。ZeroNL2SQL 首先使用 PLM 通过模式对齐生成 SQL 草图,然后使用 LLM 通过复杂推理来填充缺失的信息。此外,为了更好地将生成的 SQL 查询与给定数据库实例中的值对齐,我们设计了一种谓词校准方法来指导 LLM 根据数据库实例完成 SQL 草图,并通过基于执行的 SQL 查询来选择最佳 SQL 。综合实验表明,ZeroNL2SQL 可以在实际基准测试中实现最佳的零样本 NL2SQL 性能。具体来说,ZeroNL2SQL 的执行精度比最先进的基于 PLM 的方法高 3.2% 到 13%,比基于 LLM 的方法高 10% 到 20%。
引言:
自然语言到 SQL (NL2SQL),它将自然语言问题转换为 SQL 查询,允许非技术用户轻松访问和分析数据,因此对于商业智能、数据分析和其他数据驱动的应用程序非常有用。图 1 说明了如何将针对数据库D提出的问题Q转换为 SQL 查询S。
 图1 NL2SQL 翻译示例
图1 NL2SQL 翻译示例
零样本 NL2SQL。尽管现有的 NL2SQL 方法在众所周知的基准测试(例如 Spider 数据集)上表现出了令人印象深刻的性能,但它们的结果是在测试数据与训练数据相同的分布的情况下进行的。然而,在许多实际场景中,NL2SQL的测试环境可能与训练环境不同。这种差距往往会极大地降低现有方法的性能。例如,在学术数据库上训练的 NL2SQL 方法可能在金融数据库上表现不佳 ,或者当测试数据具有不同的语言现象或 SQL 结构时。
针对上述问题,本文研究了零样本NL2SQL,旨在构建适应各种测试环境的NL2SQL模型,并且测试环境所需的带注释的NL2SQL样本为零。为了实现这一目标,我们必须解决零样本 NL2SQL 中出现的以下三个挑战。
- 数据库模式对齐。在 NL2SQL 任务中,了解底层数据库的结构对于生成准确的 SQL 查询至关重要。然而,将自然语言问题与数据库模式中适当的表、列和关系正确对齐可能具有挑战性,特别是当存在多个可能与问题匹配的表时。例如,在图1中,表Course和表Student都包含一个列“course”,因此很难选择合适的表。
- 复杂的自然语言推理。 NL2SQL 任务通常涉及需要高级推理能力的复杂自然语言问题。理解问题的语义、解决歧义并执行逻辑推演对于生成精确的 SQL 查询是必要的。例如,在图 1 中,有效的 NL2SQL 模型必须能够根据“名为 timmothy ward 的学生”推断列 Given_name 和列 Last_name。当查询涉及复杂的联接、嵌套条件或聚合时,这些任务变得更具挑战性。
- 数据库实例对齐。这涉及将自然语言问题中提供的信息映射到数据库中存储的相关数据值。在 NL2SQL 任务中,模型需要理解问题的意图并识别与问题和数据库内容匹配的特定谓词。例如,在图 1 中,NL2SQL 模型需要生成一个 SQL 谓词 Give_name = ‘timmy’(而不是 ‘timmothy’),该谓词与问题一致并存在于数据库中。
最先进的模型的优点和局限性。 NL2SQL 的最先进(SOTA)解决方案主要依赖于基于 Transformer 的语言模型,该模型分为两类:预训练语言模型(PLM)和大型语言模型(LLM)。
基于 PLM 的方法(例如 RASAT、PICARD和 RESDSQL)在带注释的训练集(例如 Spider)上进行微调,以适应 NL2SQL 任务。基于 PLM 的方法通过对大量带注释的 NL2SQL 样本进行微调,有望在下游数据集上生成准确的 SQL 查询。
LLM(例如,PaLM、ChatGPT 和 GPT4)在一系列领域和任务中表现出了卓越的复杂推理能力,无需针对特定数据集进行微调;它们通常可以通过 API 调用来访问。
我们进行了深入分析,以深入了解零样本 NL2SQL 的 SOTA 解决方案的优势和局限性。我们的分析揭示了关于不同方法在解决各自困难方面的表现,如图 2 所总结的那样。
 图2 比较零样本 NL2SQL 的方法
图2 比较零样本 NL2SQL 的方法
PLM:(优点)PLM 在架构对齐子任务方面表现出卓越的熟练程度。具体来说,它们擅长确定要包含在 SELECT 子句中的适当属性以及标识要包含在 FROM 子句中的相关表。(缺点)他们不擅长零样本设置中的复杂推理。图 3 中的 S',给定“名为 timmothy ward 的学生”,它无法区分给定名称和姓氏,并且只选择了与给定名称相似的一列“命名”一词。
 图3 由 PLM 翻译的 SQL 查询 S′
图3 由 PLM 翻译的 SQL 查询 S′
LLM:(优点)LLM 在复杂的推理任务中表现出卓越的性能,特别是在处理 WHERE 子句下的谓词时。这些方法能够处理复杂的逻辑推论并解释问题的语义。 (缺点)LLM无法实现精确的模式对齐;他们倾向于选择更多的列(例如分数)和表格(例如课程)来覆盖输入内容,从而导致不正确的执行结果。图 4 中的图表,LLM 在 SELECT 和 FROM 子句中都得到了错误的列。
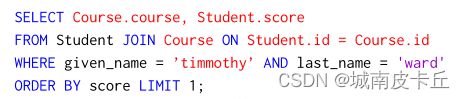 图4 由 LLM 翻译的 SQL 查询 S"
图4 由 LLM 翻译的 SQL 查询 S"
此外,PLM 和 LLM 都展示了 SQL 查询其他组件的能力,例如 ORDER BY 和 LIMIT。然而,值得注意的是,这两种方法都不擅长数据库实例对齐。例如,S' 和 S′′ 都使用值“timmothy”,但无法与数据库中存储的正确值“timmy”对齐。
我们提出的框架。我们的主要观察结果是,PLM 和 LLM 在解决零样本 NL2SQL 任务方面可以相互补充。也就是说,PLM(数据库模式对齐)的优点是 LLM 的缺点,而 LLM(复杂自然语言推理)的优点也是 PLM 的缺点。直观地说,如果我们能够智能地将 PLM 和 LLM 结合起来,从而统一两个领域的优点,零样本 NL2SQL 问题将得到更有效的解决。此外,虽然 PLM 和 LLM 都无法处理数据库实例对齐,但我们可能可以利用 LLM 的交互能力,通过使用提供的数据集校准翻译后的 SQL 查询来解决此问题。
基于上述观察,我们提出了一个ZeroNL2SQL框架,它交错可调PLM和固定LLM以实现零样本NL2SQL,有效解决零样本NL2SQL中的所有三个挑战,如图2最后一行所示。ZeroNL2SQL主要包括的两个关键步骤。首先,SQL Sketch Generation 利用可调 PLM 执行数据库模式对齐并生成 SQL sketch,其中包括 (1) SELECT 的属性、(2) FROM 中包含的表,以及 (3) 用于组合的必要关键字(例如 ORDER BY) SQL 查询。其次,SQL 查询完成利用 LLM 来填充 SQL 草图中缺失的信息,并通过与数据库中的数据值对齐来校准谓词,例如,从“timmothy”到“timmy”,这要归功于LLM复杂的自然语言推理和交互功能。
有效实现我们的 ZeroNL2SQL 框架提出了两大技术挑战。第一个挑战是如何在测试数据与训练数据不同的零样本设置中通过可调 PLM 生成准确的 SQL 草图。为了应对这一挑战,我们首先引入一个 SQL sketch 学习框架,该框架配备了自适应和数据库感知的序列化策略来生成候选 SQL sketch。接下来,由于 PLM 在搜索解码过程可能容易受到局部最优的影响而无法找到全局最佳解决方案 ,因此我们保留顶部假设进行重新评估和细化。具体来说,我们保留顶级 SQL 候选草图,而不是直接采用最好的草图,然后提出一种问题感知对齐器,根据问题的语义对 SQL 草图进行排名。第二个挑战是如何指导LLM根据数据库实例完成SQL查询并输出正确的SQL查询。为了应对这一挑战,我们设计了一种谓词校准方法来向LLM建议合适的数据库实例。此外,受我们观察到 SQL 执行结果反映其质量的启发,我们提出了一种基于执行的选择策略来选择最佳 SQL 查询。
贡献。我们的贡献总结如下:
- ZeroNL2SQL框架。在本文中,我们研究了零样本NL2SQL问题,并引入了一种新颖的框架ZeroNL2SQL,该框架首先生成SQL草图,然后完成SQL查询,以逐步解决两个内在的NL2SQL挑战。 (第 3 节)
- 优化。我们提出了新技术来解决以下问题的挑战:通过 PLM 生成 SQL 草图(第 4 节)和通过 LLM 完成 SQL 查询(第 5 节)。
- 新的 SOTA 零样本 NL2SQL 。我们在 Dr.Spider 和 KaggleDBQA 两个基准数据集上进行全面的零样本 NL2SQL 评估,总共 18 个测试集。实验结果表明,ZeroNL2SQL可以将ChatGPT在NL2SQL任务上的平均执行精度提高10%到20%,其性能超越了最先进的基于PLM的特定模型(Exp-1 & Exp-2) ),以及情境学习方法(Exp-3)。我们的代码和模型可在 Github 1 上找到。(第 6 节)
2、前言
2.1 零样本 NL2SQL
让 Q 代表自然语言查询 Q,D代表由n个表 ![]() 组成的关系型数据库D,其中
组成的关系型数据库D,其中 ![]() 表示 表
表示 表 的第 j 列。NL2SQL 的问题是根据问题 Q 和提供的数据库 D 生成正确的 SQL 查询 S。根据之前的工作,零样本NL2SQL存在的问题是推理环境
的第 j 列。NL2SQL 的问题是根据问题 Q 和提供的数据库 D 生成正确的 SQL 查询 S。根据之前的工作,零样本NL2SQL存在的问题是推理环境 ![]() ,没有出现在训练集中
,没有出现在训练集中 ![]() ,主要包括以下三种情况:
,主要包括以下三种情况:
-
在新数据库上进行测试。用于测试的数据库
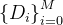 在模式和实例方面与用于训练的数据库
在模式和实例方面与用于训练的数据库 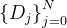 不同。例如,训练数据库包含列name,但测试数据库包含列given_name和last_name。再举一个例子,训练数据库是关于科学的,而测试数据库是关于金融的。
不同。例如,训练数据库包含列name,但测试数据库包含列given_name和last_name。再举一个例子,训练数据库是关于科学的,而测试数据库是关于金融的。 -
测试新问题。用于测试的问题
 在语言现象方面与用于训练的问题
在语言现象方面与用于训练的问题 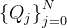 不同。例如,训练集中的问题明确提及数据库模式中的列或表名称,而测试问题中的单词未明确显示在数据库模式中或显示为同义词(例如,图 1 中的问题也可以表示为如 “What is timmothy ward’s best performing course?”)。
不同。例如,训练集中的问题明确提及数据库模式中的列或表名称,而测试问题中的单词未明确显示在数据库模式中或显示为同义词(例如,图 1 中的问题也可以表示为如 “What is timmothy ward’s best performing course?”)。 -
测试新的 SQL。用于测试的 SQL 查询
 在本地语义和复杂性方面与用于训练的 SQL 查询
在本地语义和复杂性方面与用于训练的 SQL 查询  不同。例如,训练集中只有少量 SQL 查询包含嵌套子句,而测试集中大量 SQL 查询包含嵌套子句。
不同。例如,训练集中只有少量 SQL 查询包含嵌套子句,而测试集中大量 SQL 查询包含嵌套子句。
这项工作的目标是通过交错 PLM 和 LLM 来提升 SOTA 零样本 NL2SQL 性能。
2.2 SQL Sketch
在本文中,SQL Sketch 由以下三个部分组成:
• SELECT。需要返回给用户的属性,例如图 5 中的course。
• FROM。用于获取数据的表格,例如图 5 中的Student。
• KEYWORDS。代表子句的关键字,例如 SELECT、FROM、ORDER BY、LIMIT,如图 5 所示。
 图5 ZeroNL2SQL 的图示
图5 ZeroNL2SQL 的图示
2.3 Language Models
语言模型(LM)通常基于 Transformer ,旨在理解和生成类似人类的文本。这些模型利用复杂的算法和大量的训练数据来学习语言的模式、结构和语义。从技术上讲,语言模型经过训练可以对单词序列的生成可能性进行建模,从而使它们能够根据提供的输入上下文估计后续标记的概率。事实证明,它们在自然语言处理等各种应用中具有无价的价值。
语言模型通常在大型语料库上进行预训练,并在翻译、摘要和问答等许多下游任务中表现出出色的性能。在本文中,我们区分两个特定术语:预训练语言模型(PLM)和大型语言模型(LLM)。
- PLM 是指可以由普通用户在本地托管并针对不同下游任务进行微调的模型,例如 BERT、BART和 GPT2 。
- LLM 是指只能通过Web 服务或API 调用访问的巨型语言模型,例如ChatGPT、PaLM 、GPT4 和GLam 。
尽管 PLM 和 LLM 都对大量文本数据进行预训练,但前者主要通过微调来适应下游任务,而后者通过上下文学习和指令跟踪实现零样本复杂推理,而无需改变模型参数。
2.4 Language Models for NL2SQL
最近的工作将 NL2SQL 任务制定为端到端翻译任务,并利用适当的提示来指导 LM:

因此,Prompt的设计是生成SQL查询质量的关键。现有方法仅使用任务描述(例如 “Translate the user question into an SQL query. ”)作为prompt。或在prompt添加一些手动注释的示例对(Question、SQL)。
最近的研究表明,LM 可以从给定上下文中的几个例子中学习(即上下文学习)。这些工作表明,上下文学习可以有效地使 LM 执行一系列复杂的任务。因此,考虑到NL2SQL任务的复杂性,可以采用上下文学习来指导LM更好地生成SQL查询。
3、AN OVERVIEW OF ZERONL2SQL
我们引入了一个框架 ZeroNL2SQL,它交错可调 PLM 和固定 LLM 以实现零样本 NL2SQL 生成。如图6所示,ZeroNL2SQL主要由以下两个关键步骤组成。
 图 6
图 6
ZeroNL2SQL 概述。给定用户问题 Q 和数据库模式 Dschema,(1) SQL 草图生成模块生成 SQL 草图候选列表,(2) SQL 查询完成模块完成 SQL 查询并选择最佳 SQL 查询作为最终查询结果。
(1)由 PLM 生成 SQL 草图。给定用户问题 Q 和数据库模式 Dschema,SQL Sketch 生成模块会生成 SQL 草图候选列表 Dsketch = (SELECT, FROM, keywords) 并将其传递给固定的 LLM。
(2)由 LLM 完成 SQL 查询。给定一组 SQL sketch 候选 Dsketch,由 LLM 提供支持的 SQL 查询完成模块会完成详细信息,并选择最佳 SQL 查询作为最终输出。
示例 1。图 5 说明了我们的想法,它通过两个连续步骤处理 NL2SQL。
步骤1:首先使用PLM生成SQL sketch并执行数据库模式对齐的子任务,即完成SELECT和FROM子句。
步骤2:然后使用LLM来填补缺失的信息,因为LLM擅长复杂的自然语言推理。最后,它通过与数据库中的数据值对齐来校准谓词,例如从“timmothy”到“timmy”。
为了支持上述框架,我们开发了两个关键模块,即 SQL Sketch Generation 和 SQL Query Completion,以有效地统一可调 PLM(例如 T5、Bart)和固定 LLM(例如 ChatGPT)的优势。 ,现将其介绍如下。SQL 草图生成。给定用户问题 Q 和数据库模式 Dschema,该模块会生成 SQL sketch 候选 Dsketch 的排名列表。 SQL 草图生成的一个简单实现是将其建模为序列到序列生成问题,并使用基于编码器-解码器的 PLM 来生成 SQL 草图,即
![]()
其中 ![]() 是 PLM 的编码器,用于将输入
是 PLM 的编码器,用于将输入 ![]() 转换为高维隐藏向量 x,而
转换为高维隐藏向量 x,而 ![]() 是 PLM 的解码器,用于基于 x 通过 beam search 算法 生成 SQL sketch t 。然而,训练这样的 SQL Sketch 生成模块以在测试数据与训练数据不同的零样本设置中提供准确的 SQL sketch 并非易事。为此,我们首先使用配备数据库感知序列化策略的 SQL sketch 学习框架,使模型能够在不同的测试环境中生成有效的 SQL sketch 列表。然后,我们引入一个问题感知对齐器,根据用户问题的细粒度语义进一步对 SQL 草图进行排名。 SQL Sketch 生成的更多细节将在第 4 节中讨论。
是 PLM 的解码器,用于基于 x 通过 beam search 算法 生成 SQL sketch t 。然而,训练这样的 SQL Sketch 生成模块以在测试数据与训练数据不同的零样本设置中提供准确的 SQL sketch 并非易事。为此,我们首先使用配备数据库感知序列化策略的 SQL sketch 学习框架,使模型能够在不同的测试环境中生成有效的 SQL sketch 列表。然后,我们引入一个问题感知对齐器,根据用户问题的细粒度语义进一步对 SQL 草图进行排名。 SQL Sketch 生成的更多细节将在第 4 节中讨论。
SQL 查询完成。给定 SQL 草图的排名列表,该模块利用 LLM 完成 SQL 查询并选择最佳 SQL 查询作为最终输出。该模块主要面临两个挑战:(1)如何实现数据库实例对齐,(2)如何选择最优的SQL查询。
为了解决第一个挑战,我们设计了一种谓词校准方法,为法学硕士提供适当的谓词建议,这些建议既符合原始 SQL 查询,又基于数据库。具体来说,该模块将LLM预测的谓词作为输入,表示为![]() 。我们从
。我们从![]() 开始,逐步将
开始,逐步将![]() 的匹配范围扩大到整个数据库,以获得最佳谓词
的匹配范围扩大到整个数据库,以获得最佳谓词 ![]() ,然后反馈给LLM重写SQL查询。此外,我们还根据值的类型(例如缩写或同义词)探索不同的相似度计算方法。
,然后反馈给LLM重写SQL查询。此外,我们还根据值的类型(例如缩写或同义词)探索不同的相似度计算方法。
为了解决第二个挑战,基于对SQL执行结果能够反映SQL质量的观察,我们设计了一种基于执行的选择策略来选择最优的可执行的SQL查询,可以返回高质量的数据。SQL 查询完成模块的更多细节将在第 5 节中讨论。
4、SQL SKETCH GENERATION
本节介绍 SQL Sketch Generation,它生成 SQL sketch 的排名列表,如图 7 所示。我们首先在 4.1 节中介绍配备数据库感知序列化策略的 SQL sketch 学习框架,然后在 4.2 节中开发问题感知对齐根据 NL2SQL 中问题 Q 的语义进一步对 SQL 草图进行排序。
4.1 SQL Sketch Learning
给定一个用户问题 Q 和一个数据库模式 Dschema,我们需要在 SQL 草图中生成三个部分:SELECT、FROM、KEYWORDS,为了便于表示,这些部分称为子任务。我们将此问题表述为序列到序列生成问题,并采用编码器-解码器预训练语言模型(PLM)作为主干。我们使 Encoder-Decoder PLM 通过多任务学习来学习生成这些部分,如图 7 所示。接下来,我们介绍这个 SQL Sketch Learning 组件的两个关键步骤:数据库感知序列化和参数学习。
Database-aware serialization:给定用户问题 Q 和数据库模式 Dschema,我们将它们与不同的指令结合起来,为每个子任务构建特定的输入,如下所示:
![]()
其中 INS 是每个子任务的指令,S(·)是序列化函数,用于将结构化数据库模式Dschema序列化为文本序列。图7展示了每个子任务对应的指令,延续了之前的工作,主要由任务描述组成。例如,对于FROM生成子任务,对应的指令是 “Generate the relevant tables of this question according to the database”。 我们的主要直觉是,不同的指令可以使 PLM 理解不同的子任务,以实现所需的输出。
对于数据库模式序列化,以前基于 PLM 的工作直接连接表/列名称,并要求模型输出这些名称以形成 SQL 查询。但是,PLM 有义务生成数据库中存在的有效表/列名称。当测试环境发生变化时,以前的方法不能保证这一点。示例2和图8-(1)提供了详细的解释。
示例 2(直接表/列名称序列化)。大多数现有作品使用Spider数据集作为训练集,该数据集在用户问题中具有很高的列提及百分比。我们观察到,PLM 在训练期间经常直接从问题 Q 中复制列/表名称,而不是从数据库中进行选择。我们设计了一个实验来探讨数据分布变化对 PLM 的影响。我们通过直接生成列/表名称来在 Spider 数据集上训练 T5-3B 模型。图8-(1)显示了微调后的T5-3B模型的测试结果,其中数据库中不存在 “attendance” 列。
为了解决这个问题,我们提出了一种简单而有效的数据库感知序列化策略,使 PLM 能够选择有效的数据库表或列。具体来说,我们通过训练 PLM 通过索引引用数据库中的列/表来实现这一点。具体来说,给定名为 ![]() 的
的 ![]() ,其中包含 n个表
,其中包含 n个表 ![]() 组成的关系型数据库D,其中
组成的关系型数据库D,其中 ![]() 表示 表
表示 表![]() 的第 j 列。我们对不同部分使用括号和索引来序列化数据库,如下所示:
的第 j 列。我们对不同部分使用括号和索引来序列化数据库,如下所示:
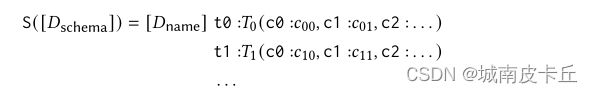
例如,在图 7 中,数据库“car_1”的序列化表示为“car_1: t0: model_list (c0: modelid, c1:maker, c2: model) t1: continents (c0: contid, c1: continent) t2:car_name(...)”。此外,对于包含外键关系的表(例如,在图7中,表“cars_data”的列“id”在表“car_names”中具有外键“makeid”),我们以“t4.c0= t2.c0”形式附加它在序列化表“cars_data”之后。
通过这种方式,我们强制 PLM 选择与用户问题最匹配的表/列索引,而不是直接从问题中复制它。最后,索引会自动转换回原始列/表名称。示例 3 和图 8-(2) 说明了我们的数据库感知序列化策略。
示例 3(数据库感知序列化)。继续示例2,我们使用Spider作为训练集。不同的是,我们要求模型学习如何使用索引来引用相应的表或列。图8-(2)展示了测试结果,模型首先输出SELECT t0.c2,然后自动翻译为数据库中的列名和表名:SELECT stadium.highest。根据比较结果,我们可以看到数据库感知的序列化策略可以使模型从数据库中选择有效的表名和列名,而不是直接从问题中复制单词。
 图 7
图 7
SQL 草图生成模块概述。 (a) PLM 用于在 SQL 草图学习后生成候选 DSELECT、DFROM 和 DKeywords 列表(第 4.1 节)。 (b) 问题感知对齐器用于根据细粒度问题语义进一步对 SELECT 和关键字候选者进行排名(第 4.2 节)。 top-1 SELECT 和关键字与 Dfrom 组合形成排序的 SQL sketch 候选集 Dsketch。