阅读笔记6*:基于半监督学习的运动想象脑机接口研究
文章目录
- 论文信息
- 笔记
-
- 1.摘要
- 2.绪论
-
- 2.1 BCI研究基础
-
- 2.1.1BCI概念与研究意义
- 2.1.2BCI系统组成与分类
- 2.1.3存在问题
- 2.2 半监督学习研究背景
-
- 2.2.1模式识别
- 2.2.2半监督学习
- 2.2.3半监督学习分类研究现状
- 2.2.4 半监督学习遇到的问题和挑战
- 3.运动想象EEG的特征提取方法研究
-
- 3.1 基于运动想象的EEG
- 3.2 EEG的预处理
-
- 3.2.1空间滤波
- 3.2.2频率滤波
- 3.3.3 EEG特征提取方法
- 4.参数选择的半监督算法研究
-
- 4.1 自训练算法
- 4.2参数选择的半监督算法
- 5.衍生 FLDA 的半监督算法研究
-
- 5.1协同训练算法
- 5.2 衍生 FLDA 的半监督算法
- 5.融合主动学习的半监督多分类研究
-
- 5.1主动学习(Active Learning)研究
- 5.2 三种分类器的样例选择策略
- 5.3多任务分类
- 5.4 融合主动学习的半监督学习
- 6.基于 SCSP 的 batch-mode 增量式顺序更新半监督算法研究
-
- 6.1增量式半监督
- 6.2 基于 SCSP 的 batch-mode 增量式顺序更新半监督算法
论文信息
- 题目:基于半监督学习的运动想象脑机接口研究
- 作者:谭学敏
- 单位:重庆大学电气工程
- 发表时间:2015.05
笔记
1.摘要
- 基于参数选择的自训练算法(STBMS),解决了运动想象 BCI 自训练中小样本无法利用交叉验证准确选择合适参数的问题。针对迭代过程噪声不断积累的问题,提出了一种置信度评估准则,去除未标记样本中易误标记的噪声样本,选择置信度高的样本添加到训练集中重新训练,提高了自训练的分类性能和信噪比
- 基于衍生FLDA(Fisher Linear Discriminant Analysis)的协同训练算法(CTBMFLDA),运用到运动想象的分类中。
- 用于运动想象 BCI 多分类的三种主动学习方法(ALNACD,ALSVMactive 和 ALEBS),探索了这三种主动学习的样例选择策略:最近平均聚类距离(Nearest Average-class Distance,NACD),SVM 主动学习(SVMactive)和信息熵(Entropy-based Sampling,EBS)
- 提出了一个新的特征提取方法:分段选择共空间模式(Segmented Common Spatial Pattern,SCSP)。利用 SCSP 作为特征提取方法,提出了基于 SCSP 的batch-mode 增量式顺序更新半监督算法(BMSUST-SCSP),不仅节省了训练时间,而且为在线 BCI 的开发和应用提供了模型和框架。
2.绪论
2.1 BCI研究基础
2.1.1BCI概念与研究意义
脑机接口 :在不依赖脑的正常输出通路(外围神经与肌肉组织)的情况下,建立起人脑与计算机或其他电子设备之间的直接通讯和控制。
BCI技术的理论意义在于:它的研究与开发过程不仅能够深入理解大脑认知模式、控制方式与信息流程,而且也能对大脑思维模式与意识的形成机制提供新的研究方法。
BCI技术主要应用于以下几个方面:
- 医疗领域
- 军事领域
- 娱乐与日常
- 可穿戴智能装备
2.1.2BCI系统组成与分类

1.信号采集
大部分都是在用EEG
2.信号预处理
信号预处理主要是对信号进行滤波和去噪,一个有效的预处理可以增强信噪比和提高 BCI 系统的性能。通常使用的预处理方法包括空间滤波、频率滤波、独立成份分析去除眼电、基线校正等。
3.信号处理
原始脑信号经过预处理以后,需要经过特征提取和信号分类将信号转换成对设备的控制命令。在 BCI 系统中,特征提取实际上也是为了提高信噪比,把需要的有用特征从噪声中突现出来,这些有用的特征是真正能够反应大脑真实意图的。提取到反应大脑意识的特征后,信号分类的主要任务是将这些特征进行分类识别。目前,用于 BCI 分类的方法很多,如线性判别分析、支持向量机、人工神经网络等。
4.输出控制
5.操作协议
根据以下三种不同的分类方式,BCI 系统可分为以下几类:
- 植入式BCI和非植入式BCI
- 自发式和诱发式
- 同步式和异步式
2.1.3存在问题
- 提高速度与精度
- 提高自适应性
- 减少训练时间与增强鲁棒性
2.2 半监督学习研究背景
2.2.1模式识别
模式识别是对感知信号的行为或物理现象进行解释和判别的过程,侧重于自动化和判读方面的研究。
模式识别过程主要包括数据的预处理、特征提取与选择、分类识别。
2.2.2半监督学习
在训练过程中,它除了使用少量的有标记样本,还利用了大量未标记样本的隐含信息。
半监督学习的基本思想是在有标记样本的帮助下建立假设模型,并使用模型预测未标记样本标签。
半监督学习基本假设
- 聚类假设
如果数据点在同一聚类中,它们很有可能具有相同的类别标记.这意味着决策边界应该位于数据较为稀疏的区域。
- 流形假设
不同于着重考虑整体特性的聚类假设,流形假
设着眼于局部特性,实际反映了决策函数的局部平滑性。在大量未标记样本的参与下,整个数据空间变得十分稠密,这有助于更加准确地刻画局部区域特性,增加了决策函数的局部平滑性
- 局部与全局一致性假设
邻近的数据很有可能属于同一类别,相同结构上的数据很有可能有相同的标签
2.2.3半监督学习分类研究现状
- 生成式模型算法
此算法利用聚类假设,在少量有标记样本周围聚类。算法使用生成式模式作为分类器,将未标记样本属于某一类别的概率作为一组缺乏的参数建模,再利用期望最大化EM(Expectation Maximization)算法进行标记和模型参数的估计。
- 基于图正则化框架的半监督算法
直接或间接地使用流形假设。该算法先利用训练样本(所有有标记和未标记样本)与某种相似度量建立一个图形,图中所对应的是所有训练样本,边表示样例间相似度,然后定义所需要优化的目标函数,最后利用正则化项(决策函数在图上的光滑性)求解最优模型参数
- 直推式向量机(Transductive Support Vector Machine,TSVM)
传统的归纳式向量机需要大量有标记的样本来训练SVM分类器。TSVM方法能够添加未标记样本中包含的特征信息到有标记的样本中,在不考虑模型泛化能力的前提下,使用拟合的分类器对测试样本进行优化,而且未标记样本对分类器进行拟合是一个渐进式递归过程
- 自训练算法
自训练算法首先利用少量有标记样本训练分类器,然后使用分类器为未标记样本分类,未标记样本中置信度高的样本与它们预测的标记一起,添加到有标记的样本中重新训练分类器,这个过程不停迭代直到满足停止条件
- 协同半训练算法
算法使用两个分类器进行协同训练,少量有标记样本训练出的分类器 1 从未标记样本中挑选置信度高的未标记样本预测其标签,并将这些样本交给分类器 2,少量有标记样本训练出的分类器2 从未标记样本中挑选置信度高的样本交给分类器 1,这个过程不断迭代直到满足停止条件。
2.2.4 半监督学习遇到的问题和挑战
- 如何去除噪声和提高信噪比
- 如何准确选择参数
- 如何在更真实条件下构建协同训练算法
- 如何融合其它机器学习方法到半监督学习中
- 如何为在线系统的开发和应用提供模型和框架
3.运动想象EEG的特征提取方法研究
3.1 基于运动想象的EEG
- 基于运动想象的生理基础:人在进行想象运动时能激活大脑的某些特定的功能区,对应的EEG会产生有规律且稳定的特征变化。当人在做实际或想象运动时大脑皮层的相关运动区域特定频率段振幅减小的这种现象称之为事件相关去同步化(Event-related Desynchronization,ERD)。当人在大脑静息或懒惰的情况下,特定频率段的振幅增加的这种现象称之为事件相关同步化(Event-related Synchronization,ERS)
- ERD 与 ERS 现象都不是单独发生的。当人在做实际或想象左手运动时,ERD 现象将会出现在大脑右侧皮层的运动区域,即对应区域的特定μ频带的μ波(8~13Hz)和 β频带的β波(18~25Hz)的振幅会减小,而在大脑的左侧皮层的运动区域,将会出现 ERS 现象。当人在做实际或想象右手运动时,那么 ERD 现象将会出现在大脑左侧皮层的运动区域,ERS 现象则出现在大脑另一侧的运动区域。
3.2 EEG的预处理
预处理的目的是一定程度的去除噪声并且提高信噪比。主要方法包括空间滤波、频率滤波、去除眼电和基线校正。
3.2.1空间滤波
EEG 的噪声来源主要包括非脑电的伪迹(如心电、肌电、眼动等)和不需要的脑电成分(如视觉皮层的 alpha 信号等)。在采集受试者 EEG 的过程中,有用信号和噪声同时被采集,各导联的 EEG 弥散到整个头皮,造成噪声与所需信号的频段重叠,使得导联信号间有非常强的关联性。文献指出相邻两个导联的相关系数达到了 60%~70%。空间滤波对提高多通道 EEG 的信噪比起着非常重要的作用。空间滤波主要包括以下四种方法:耳突参考(Ear Reference,ER)、共同平均参考法(Common Average Reference,CAR)、小拉普拉斯参考(Small Laplacian reference)和大拉普拉斯参考(Large Laplacian reference)。
3.2.2频率滤波
频率滤波是一种通用的滤波方法,它对消除干扰信号、提高信噪比很有帮助。 滤波器主要有 IIR 滤波器(无限长脉冲响应滤波器)和 FIR 滤波器(有限长脉冲响应滤波器)。
3.3.3 EEG特征提取方法
- 时频分析:将时间和频率分析结合起来能够有效地解决传统傅立叶变换全局性变化的局限性。
其主要思想是将一维时域信号映射到二维时-频平面上。 - 自回归模型(AR): AR 非常适合对具有非平稳性的 EEG 进行功率谱估计
功率谱:功率谱是功率谱密度函数的简称,它定义为单位频带内的信号功率。它表示了信号功率随着频率的变化情况,即信号功率在频域的分布状况。功率谱表示了信号功率随着频率的变化关系
- 共空间模式(CSP):是提取运动想象EEG特征最有效的算法之一。这一算法的成功主要归功于ERS/ERD的神经生理现象。
CSP 算法的目标是设计一个最优的空间滤波器来获取最佳的投影方向,使第一类方差最大化,而使另一类方差最小化,实现对两类任务协方差矩阵的同时对角化,最终使两类信号的区别最大。
- 滤波带宽共空间模式(FBCSP)
FBCSP 最主要的思想是使用切比雪夫 II 型滤波器对 EEG 经验选取的各个频带分别提取 CSP 特征,然后通过特征选择算法挑选出所有频带中信息量大的特征,这样能有效避免遗漏某个频率段的有用信息。
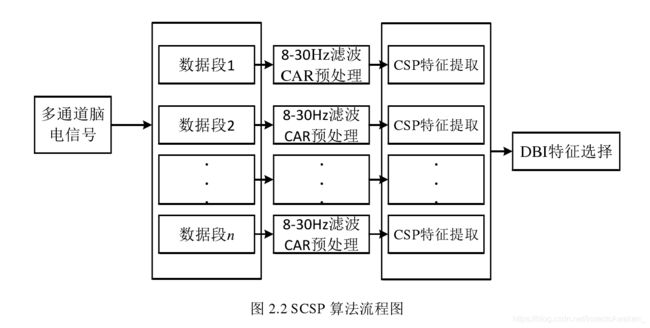
- 分段选择共空间模式(SCSP)
虽然 CSP 和 FBCSP 算法在提取运动想象 EEG 特征上取得了很好的效果,但是它们都没有充分考虑 EEG 中最有用的数据段,只是经验选取有用的数据段。如果数据段范围选择不当,很有可能加入无用信息或遗漏其它的有用信息,从而导致分类性能的急剧下降。

4.参数选择的半监督算法研究
交叉验证:在实际的训练中,训练的结果对于训练集的拟合程度通常还是挺好的(初始条件敏感),但是对于训练集之外的数据的拟合程度通常就不那么令人满意了。因此我们通常并不会把所有的数据集都拿来训练,而是分出一部分来(这一部分不参加训练)对训练集生成的参数进行测试,相对客观的判断这些参数对训练集之外的数据的符合程度。这种思想就称为交叉验证(Cross Validation)
4.1 自训练算法
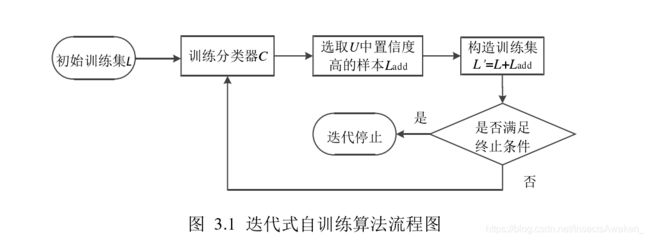
自训练(Self-training)是经常应用到半监督分类中的一种算法,它分为迭代式自训练和增量式自训练。(增量式自训练在第6节)
在执行过程中,迭代式自训练算法首先利用少量已标记训练样本集 L 训练初始分类器 C,然后将训练好的分类器 C用来预测大量未标记样本集 U 中样本的类别,并且选取出置信度高的样本 S。最后,将预测出的置信度高的带标签样本 S 添加到已标记训练样本集 L 中,更新训练样本集 L,重新训练分类器 C。通过迭代的方式,不断更新训练集直到满足停止条件。
如果在迭代过程中,我们能够从未标记的样本集中找到置信度高的样本同时剔除置信度低的样本,那么更新的训练集的质量将会得到提高,训练出的分类器将会有更好的效果。
4.2参数选择的半监督算法

5.衍生 FLDA 的半监督算法研究
第三章我们介绍了自训练算法能提高运动想象 BCI 的分类精度,在本章中,我们证明了半监督分类的另一种算法:协同训练(Co-training),能够获得比自训练算法更好的分类性能。
提出了一种基于衍生 FLDA(Fisher Linear Discriminant Analysis,FLDA)分类器的协同训练算法(CTBMFLDA),在更真实条件下构建了两个有明显差异性的分类器 FLDA1 和 FLDA2,分别为对方挑选置信度高的样本,进而提高协同训练算法对运动想象 BCI 的分类性能
5.1协同训练算法
该算法假设训练集拥有两个充分冗余的视图,这两个充分冗余视图的属性集需要同时满足以下两个条件:(1)两个数据集是相互独立的。(2)两个数据集都能够对同一问题充分描述。在执行标准协同训练的过程中,该算法首先分别在这两个充分冗余的视图上使用少量已标记训练样本集 L 训练分类器 h1和 h2,然后对大量未标记样本集 U 中的样本进行预测,并且分别从每个分类器的预测结果中选择置信度高的样本添加到另一分类器所对应的训练集中,扩大两个分类器所对应的训练集。算法的目的是两个分类器通过提供互相未知的信息给对方,同时提高两个分类器的表现。


协同训练算法的挑战:
- 难以满足充分冗余视图
- 选择分类器
- 确定评价函数
5.2 衍生 FLDA 的半监督算法
Fisher线性判别(Fisher Linear Discriminant Analysis,FLDA)
FLDA 考虑把 n 维空间的样本投影到一条直线上,即把 n 维样本压缩成一维。在一般情况下,n 维空间压缩成一维空间在数学上是容易办到的。FLDA 要解决的基本问题就是将样本尽可能地投影到某个方向,使得在这个方向的直线上分开的效果最好。即根据实际情况寻找一个判别准则函数,在这个函数的投影下使得投影后的样本在新的空间中类间离散度最大而类内离散度最小 .

我们构建 FLDA1 和 FLDA2 这两个分类器进行协同训练主要有以下原因:
- FLDA1 和 FLDA2 是由 FLDA 分类器衍生得到的。FLDA 在 BCI 中是一种很流行的分类算法并且能够取得比较好的分类结果。Ahi 等人已经证明 FLDA 甚至能够获得与 SVM 差不多的分类结果,且计算复杂度比 SVM 低
- FLDA1 和 FLDA2 分类器计算量小,实现简单,分类速度快,而且不需要使用交叉验证确定参数,进一步减少了计算的复杂程度。
- FLDA1 分类器和 FLDA2 分类器的目标分别是最大化类间散度和最小化类内离散度,因此这两个分类器的差异是明显的。在协同训练中,如果不能满足两个充分冗余视图,那么维持分类器的差异性是非常重要的,否则协同训练算法将退化成自训练算法。但是即使分类器的差异很大,随着迭代的增加,两个分类器不断地相互学习,总是为对方提供自己预测的信息,不可避免地,两个分类器也会变得越来越相似.

5.融合主动学习的半监督多分类研究
5.1主动学习(Active Learning)研究
主动学习最终的目的是用尽可能少的标记样本训练分类性能最好的分类模型,主动学习框架主要由学习引擎和搜索引擎两部分组成。
学习引擎用于建立一个基准分类器,并且使用监督算法对已标记数据进行学习来提高分类性能。搜索引擎则使用样例选择策略对未标记样本进行评价,选择出不确定性大的样本,并交给专家人工标记。之所以选择不确定性大的样本是因为我们很难区分不确定性大的样本到底属于哪类,因此,它是最有用的样本,如果添加到原标记训练集中重新训练最有可能提高分类器的性能。学习引擎和搜索引擎交替运行多次后,基准分类器的性能得到提高。当满足迭代停止条件时,主动学习过程终止。
主动学习的形式化描述为:主动学习模型的 5 个变量是(G,Q,S,L,U)。首先,使用初始标记训练集 L 训练分类器 G,然后使用查询函数 Q 从未标记的样本池 U 中搜索不确定性大的样本,专家 S 负责对选择出的样本进行人工标记真实的标签。之后,将这些人工标记的样本加入到训练集 L 中重新训练新的分类器 G。这个过程不停地迭代直到满足停止条件。其实这里的查询函数就是指样例选择策略。主动学习过程如图 5.1。

在主动学习中,分类器能主动选择未标记数据中不确定性大的数据交给专家人工标记其真实的标签,并将这些数据添加到已标注的数据中重新训练分类器,在选择尽可能少数据的情况下获得尽可能高的分类率
主动学习解决了引入错误的分类信息到训练集的问题,成功的添加了不确定性大的数据到训练集中提高分类器的性能,但是却没有充分挖掘剩余未标记数据中的隐含信息。本章考虑将主动学习与半监督学习的思想结合起来,利用主动学习来选择未标记数据中不确定性大的数据并人工标注,再利用半监督学习来挖掘剩余未标记数据中置信度高的数据并赋于其预测标签,这对提高分类器的性能有重大的意义。
在主动学习过程中,应用了最近平均聚类距离(Nearest Average-class Distance,NACD),SVM 主动学习(SVMactive)和信息熵(Entropy-based Sampling,EBS)这三种样例选择策略来选择未标记数据中不确定性大的样本。这三种策略均是基于池的主动学习。
(这一章剩下的感觉对我目前的水平来说有点对牛弹琴)
5.2 三种分类器的样例选择策略
5.3多任务分类
5.4 融合主动学习的半监督学习
6.基于 SCSP 的 batch-mode 增量式顺序更新半监督算法研究
第三章描述了迭代式的半监督学习在运动想象 BCI 中的应用,本章根据第二章提出的 SCSP 特征提取算法,提出了一种基于 SCSP 的 batch-mode 增量式顺序更新半监督算法(BMSUST-SCSP),将未知大样本池划分成若干个子集(batch),依次对各子集的未标记样本进行选择
6.1增量式半监督
自训练是一种常用的半监督分类算法,分为迭代式和增量式自训练。
增量式自训练是指在第一次迭代中,利用少量初始已标记样本集 L 训练分类器 C,然后从未标记样本集 U 中挑选置信度高的部分样本 S1并添加到 L 中更新训练集(L+S1)来重新训练分类器 C。在第二次迭代中,更新的分类器重新选择剩余未标记样本集 U-S1中置信度高的部分样本 S2并重新添加到 L+S1中更新训练集为L+S1+S2,分类器 C 再次得到更新,未标记训练集中的样本继续减少为 U-S1-S2。这个过程不断迭代直到满足停止条件。
值得注意的是,对增量式自训练来说,训练集中的样本数量随着迭代的增加而增加,而未标记训练集中的样本在不断减少。而对于 3之前介绍的迭代式的自训练来说,在第 k(k>1)次迭代后,训练集中的样本数量并没有随着迭代的增加而增加,这是因为此时训练集是由两部分组成,第一部分是固定的初始已标记样本集 L,第二部分是分类器选择的未标记样本集 U中置信度高的样本,第二部分包括的样本是随着迭代的增加不断更新替代上一次迭代选择的样本,而不是在上一次迭代的训练样本上有所增加。

6.2 基于 SCSP 的 batch-mode 增量式顺序更新半监督算法
batch-mode增量式顺序更新半监督不同于传统的增量式半监督,传统的增量式半监督把未标记的样本看作一个样本池,每次迭代从未标记池中选择部分置信度高的样本更新分类器。而batch-mode 增量式顺序更新半监督则是将这个大样本池划分成若干个子集(batch),利用初始标训练集训练出的分类器选择第一个子集中置信度高的样本,将选择的样本用来扩展初始训练集并重新训练分类器,再选择下一个子集中置信度高样本以更新分类器,直到依次使用完所有子集。
假设两个原始数据集:已标记的初始训练集 DI和未标记的扩展训练集 DF,DI包含 N1个含标签的样本,DF包含 N2个不含标签的样本。
