Linux进程调度
转载自公众号:在下小神仙
进程的分类
实时进程
实时进程代表那些需要及时响应的进程,否则用户就会感觉到延时,比如你的终端等待你的输入,你的subline等待你的输入,当你交互的时候,这些进程都需要及时的响应。
普通进程
普通进程就是指那些不需要那么及时响应的进程,比如压缩,视频的编解码。
上下文切换
CPU 寄存器和程序计数器就是 CPU 上下文,因为它们都是 CPU 在运行任何任务前,必须的依赖环境。
-
CPU 寄存器是 CPU 内置的容量小、但速度极快的内存。
-
程序计数器则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。
上下文切换就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
而这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
进程调度
调度算法
FIFO算法
先到达的先运行,后到达的后排队。
p1 20ms
P2 10ms
P3 40ms
cpu根据先来先调度依次运行 p1 p2 p3
优势:非常简单,好实现,好理解
缺点:前面的进程如果执行时间特别长,后面的进程根本拿不到cpu的执行,会挨饿。
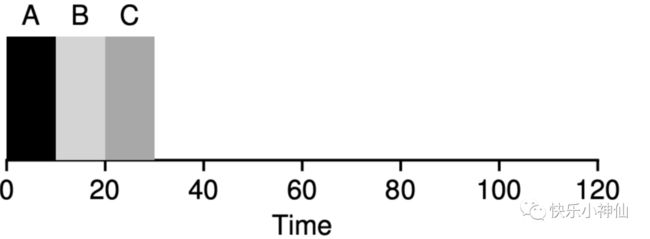
SJF算法
时间最短的进程先执行。
p1 20ms
P2 10ms
P3 40ms
假设同时达到。那么执行顺序是p2 然后p1 然后再带p3 cpu选择那个执行时间最短的来执行,看起来是比较合适的。
但是如果p3先到达呢?
那么p1,p2也还是只能等待。
优势:简单,
劣势:能解决一部分挨饿问题,但是不能解决全部。

STCF short time compelet frist
可打断式的。如果后面的进程运行的时间小于前面的,Cpu发生切换,调度时间短的进程。
优势:解决了挨饿问题,执行时间短的进程不需要等待时间长的进程结束。
缺点:响应时间长。进程时间长的占据时间还是太长了。

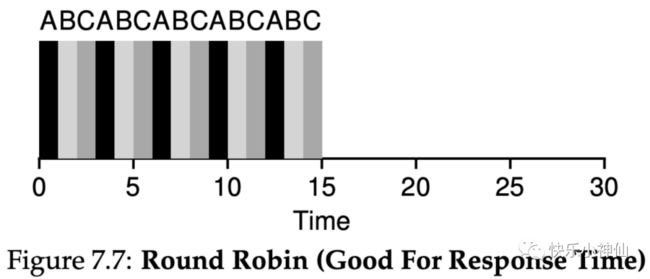
RR调度算法 轮训调度算法
讲时间分成时间片,把时间片分给每个进程,保证大家在一个时间段都被调用到。给用户一种每个进程都在被cpu调度的假象。
调度队列
思考一个问题,计算机处理这么的进程,这些进程放在哪里呢?以什么样的数据结构存储的呢?
队列的方式存储的。
全局队列
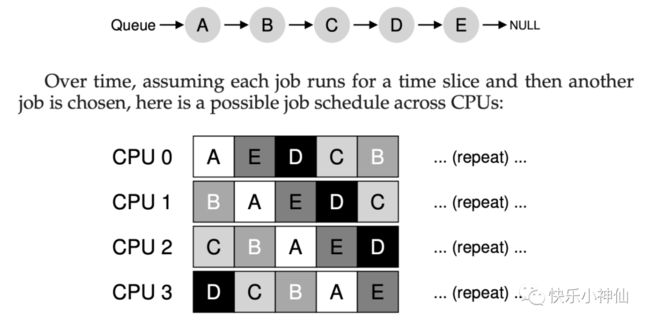
优势:实现简单
劣势:需要加锁。频繁的加锁和释放锁带来了性能的降低。
局部队列(每个cpu一个队列)

进程优先级
不是每个进程都有一样的优先级。
有些进程是实时交互的,这种进程是不能等待的。否则就会让用户感觉到时延。
如何查看进程的优先级
ps 命令查看优先级

S代表的是进程的 State 我们通过man ps来查看这些值是分别代表什么

什么是nice值
我们知道,社会上,人有善恶之分,有些人很好,有些人很不好。
不好的人一般都是通过抢别人的利益来获取更多的利益,这种人就不nice,nice值很低。
进程也是一样的,每个进程有不同的nice值。
nice越高的进程对其他进程更好,因此优先级低,获得更少的调度。
我们可以通过nice来查看当前bash 的优先级。

通过nice来设置bash的优先级
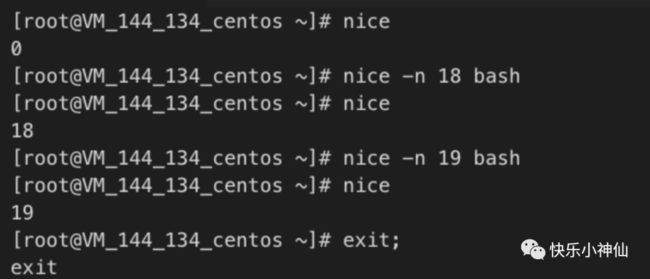
nice的取值范围是从-20到19。
nice和Pri之间的关系
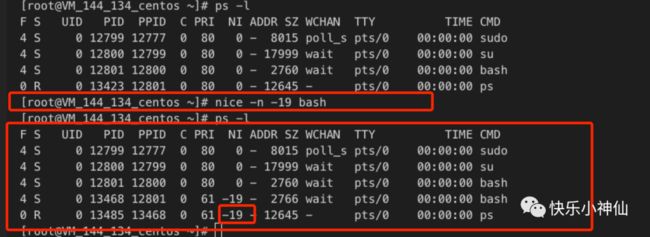
nice代表进程对别的进程礼让的程度,nice越高,那么Pri值越低,但是优先级越高。
如何修改进程的优先级
renice命令

修改bash的时候把这个bash下面的进程的优先级也一起修改了。
Priority
优先级
源代码地址
https://elixir.bootlin.com/linux/v2.6.32/source/include/linux/sched.h#L1561
sched.c
/*
* Convert user-nice values [ -20 ... 0 ... 19 ]
* to static priority [ MAX_RT_PRIO..MAX_PRIO-1 ],
* and back.
*/
#define NICE_TO_PRIO(nice) (MAX_RT_PRIO + (nice) + 20)
#define PRIO_TO_NICE(prio) ((prio) - MAX_RT_PRIO - 20)
#define TASK_NICE(p) PRIO_TO_NICE((p)->static_prio)
sched.h
#define MAX_USER_RT_PRIO 100
#define MAX_RT_PRIO MAX_USER_RT_PRIO
#define MAX_PRIO (MAX_RT_PRIO + 40)
#define DEFAULT_PRIO (MAX_RT_PRIO + 20)
实时的进程因为是特殊的进程,不能等待太久,所以实时进程的优先级在0-99直接,普通进程的优先级在100-139之前。
动态优先级是内核去调整的,因为有些进程会超时,需要被惩罚。
静态优先级是用户启动一个进程的时候可以设置的优先级,这个优先级可以通过renice来改变。
调度器
o(n)调度器
每个cpu有自己的进程队列了,也有自己的优先级了。
对于cpu而言,要去找到队列当中优先级最高的队列执行,这个耗时取决于队列的长度。
遍历操作操作时间很长
o(1)调度器
位运算是最快的,bitmap
140位的bitmap 每一个bit代表这个优先级上是否有进程,有的话位为1,没有的话位为0.
进程再按照先来后到的顺序排列在链表组成的队列上。
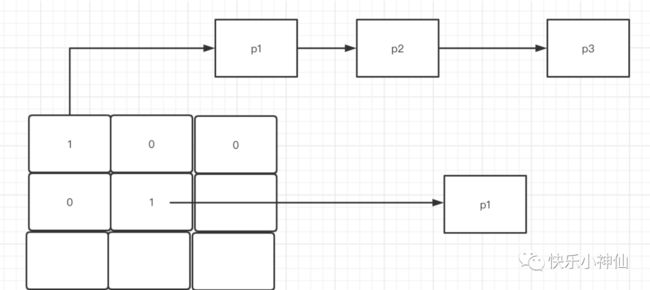
两个维护优先级的队列
一个叫active 一个叫expire
active遍历完成之后和expire交换指针。
CFS调度器
O1已经是上一代调度器了,由于其对多核、多CPU系统的支持性能并不好,并且内核功能上要加入cgroup等因素,Linux在2.6.23之后开始启用CFS作为对一般优先级(SCHED_OTHER)进程调度方法。在这个重新设计的调度器中,时间片,动态、静态优先级以及IO消耗,CPU消耗的概念都不再重要。CFS采用了一种全新的方式,对上述功能进行了比较完善的支持。
其设计的基本思路是,我们想要实现一个对所有进程完全公平的调度器。又是那个老问题:如何做到完全公平?答案跟上一篇IO调度中CFQ的思路类似:如果当前有n个进程需要调度执行,那么调度器应该在一个比较小的时间范围内,把这n个进程全都调度执行一遍,并且它们平分cpu时间,这样就可以做到所有进程的公平调度。那么这个比较小的时间就是任意一个R状态进程被调度的最大延时时间,即:任意一个R状态进程,都一定会在这个时间范围内被调度相应。这个时间也可以叫做调度周期,其英文名字叫做:sched_latency_ns。进程越多,每个进程在周期内被执行的时间就会被平分的越小。调度器只需要对所有进程维护一个累积占用CPU时间数,就可以衡量出每个进程目前占用的CPU时间总量是不是过大或者过小,这个数字记录在每个进程的vruntime中。所有待执行进程都以vruntime为key放到一个由红黑树组成的队列中,每次被调度执行的进程,都是这个红黑树的最左子树上的那个进程,即vruntime时间最少的进程,这样就保证了所有进程的相对公平。