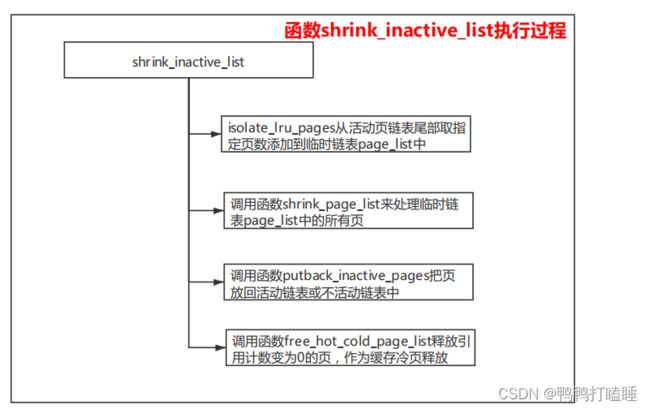
04_17页回收问题和水位线和swap交换空间和oom,内存性能微调
前言
应用程序通过 malloc 函数申请内存的时候,实际上申请的是虚拟内存,此时并不会分配物理内存。
当应用程序读写了这块虚拟内存,CPU 就会去访问这个虚拟内存, 这时会发现这个虚拟内存没有映射到物理内存, CPU 就会产生缺页中断,进程会从用户态切换到内核态,并将缺页中断交给内核的 Page Fault Handler (缺页中断函数)处理。
缺页中断处理函数会看是否有空闲的物理内存,如果有,就直接分配物理内存,并建立虚拟内存与物理内存之间的映射关系。
扯到之前的内存分配了
如果没有空闲的物理内存,那么内核就会开始进行回收内存的工作,回收的方式主要是两种:直接内存回收和后台内存回收。
同时如果有交换区,内存ram不足的时候也在交换区把不常用的匿名页 放到rom的交换区中
如果直接内存回收后,空闲的物理内存仍然无法满足此次物理内存的申请,那么内核就会放最后的大招了 ——触发 OOM (Out of Memory)机制。
水位线
内核定义了三个内存阈值(watermark,也称为水位),用来衡量当前剩余内存(pages_free)是否充裕或者紧张,分别是:
页最小阈值(pages_min);
页低阈值(pages_low);
页高阈值(pages_high);
这三个内存阈值会划分为四种内存使用情况,如下图:
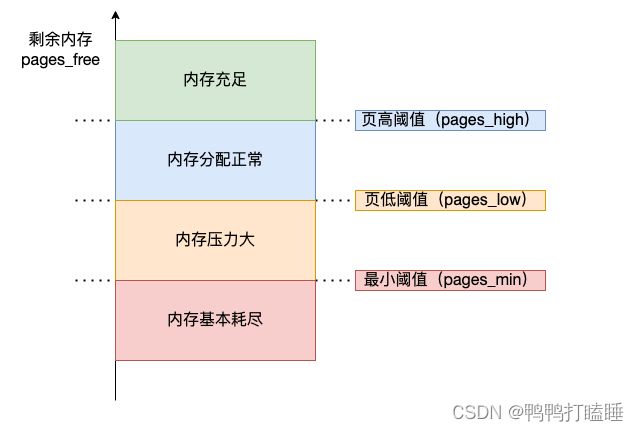
kswapd 会定期扫描内存的使用情况,根据剩余内存(pages_free)的情况来进行内存回收的工作。
图中绿色部分:如果剩余内存(pages_free)大于 页高阈值(pages_high),说明剩余内存是充足的;
图中蓝色部分:如果剩余内存(pages_free)在页高阈值(pages_high)和页低阈值(pages_low)之间,说明内存有一定压力,但还可以满足应用程序申请内存的请求;
图中橙色部分:如果剩余内存(pages_free)在页低阈值(pages_low)和页最小阈值(pages_min)之间,说明内存压力比较大,剩余内存不多了。这时 kswapd0 会执行内存回收,直到剩余内存大于高阈值(pages_high)为止。虽然会触发内存回收,但是不会阻塞应用程序,因为两者关系是异步的。
图中红色部分:如果剩余内存(pages_free)小于页最小阈值(pages_min),说明用户可用内存都耗尽了,此时就会触发直接内存回收,这时应用程序就会被阻塞,因为两者关系是同步的。
可以看到,当剩余内存页(pages_free)小于页低阈值(pages_low),就会触发 kswapd 进行后台回收,然后 kswapd 会一直回收到剩余内存页(pages_free)大于页高阈值(pages_high)
也就是说 kswapd 的活动空间只有 pages_low 与 pages_min 之间的这段区域,如果剩余内测低于了 pages_min 会触发直接内存回收,高于了 pages_high 又不会唤醒 kswapd。
LRU链表
回顾一下ram中的三级结构体 节点 Node ,区域 Zone ,页 Page ,
Linux 内核中 , 使用 pglist_data 结构体 描述内存节点 ,一个内存节点理解成一片ram就好
pglist_data 结构体里面有个链表数组 挂了5条LRU链表 存放不同的物理页
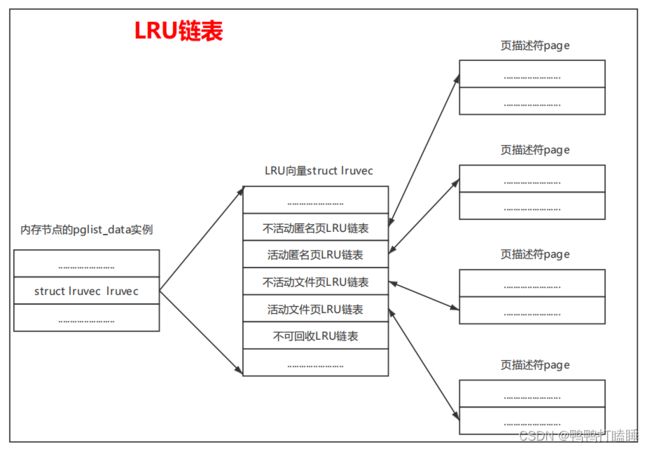
不活动匿名页LRU链表,用来链接不活动的匿名页,即最近访问频率低的匿名页;
活动匿名页LRU链表,用来链接活动的匿名页,即最近访问频率高的匿名页;
不活动文件页LRU链表,用来链接不活动的文件页,即最近访问频率低的文件页; .
活动文件页LRU链表,用来链接活动的文件页,即最近访问频率高的文件页;
不可回收LRU链表,用来链接使用mlock锁定在内存中、不允许回收的物理页。
回收方式和策略和性能
回收策略
系统内存紧张的时候,就会进行回收内测的工作,那具体哪些内存是可以被回收的呢?
下面分为两种
linux针对不同的物理页,采用不同的回收策略:交换支持的页和存储设备支持的文件页。
交换支持的页:包括匿名页 以及tempfs 就理解成匿名页就行了
存储设备支持的文件页 : 理解成文件页就好
文件页
文件页(File-backed Page):内核缓存的磁盘数据(Buffer)和内核缓存的文件数据(Cache)都叫作文件页。大部分文件页,都可以直接释放内存,以后有需要时,再从磁盘重新读取就可以了。而那些被应用程序修改过,并且暂时还没写入磁盘的数据(也就是脏页),就得先写入磁盘,然后才能进行内存释放。所以,回收干净页的方式是直接释放内存,回收脏页的方式是先写回磁盘后再释放内存。
匿名页
匿名页(Anonymous Page):应用程序通过 mmap 动态分配的堆内存叫作匿名页,这部分内存很可能还要再次被访问,所以不能直接释放内存,它们回收的方式是通过 Linux 的 Swap 机制,如果开启了 Swap 机制,Swap 会把不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。这个操作是会影响系统性能的
补充一下swap机制:
页交换(swap) 的原理:当内存不足的时候,把最近很少访问的没有存储设备支持的物理页的数据暂时保存到交换区,
释放内存空间,当交换区中存储的页被访问的时候,再把数据从交换区读到内存中。
其中交换区可以是一个磁盘分区, 也可以是存储设备上的一个文件。
流行的ROM存储设备:机械硬盘、固态硬盘及NAND闪存。
固态硬盘使用NAND内存作为存储介质,固态硬件当中的控制器支行闪存转换层固化程序,
把闪存转换成块设备,使固态硬盘对外表现为块设备。
NAND闪存特点:写入数据之前需要把擦除块擦除,每个擦除块的擦除次数有限,范围10的5次方 ~10^6,频繁地写数据
会缩短闪存的寿命。
如果设备使用固态硬盘或者是NAND闪存存储数据,不适合启用交换区;
如果设备使用机械硬盘存储数据,可以启用交换区。
回收方式
后台内存回收 : 也就是唤醒 kswapd 内核线程,这种方式是异步回收的,不会阻塞进程。
直接内存回收 : 种方式是同步回收的,会阻塞进程,这样就会造成很长时间的延迟,以及系统的 CPU 利用率会升高,最终引起系统负荷飙高。
可以看到,回收内存的操作基本都会发生磁盘 I/O 的,如果回收内存的操作很频繁,意味着磁盘 I/O 次数会很多,这个过程势必会影响系统的性能,整个系统给人的感觉就是很卡
性能优化
1.调整文件页和匿名页的回收倾向
从文件页和匿名页的回收操作来看,文件页的回收操作对系统的影响相比匿名页的回收操作会少一点,因为文件页对于干净页回收是不会发生磁盘 I/O 的,而匿名页的 Swap 换入换出这两个操作都会发生磁盘 I/O。
Linux 提供了一个 /proc/sys/vm/swappiness 选项,用来调整文件页和匿名页的回收倾向。
swappiness 的范围是 0-100,数值越大,越积极使用 Swap,也就是更倾向于回收匿名页;数值越小,越消极使用 Swap,也就是更倾向于回收文件页。
一般建议 swappiness 设置为 0(默认就是 0),这样在回收内存的时候,会更倾向于文件页的回收,但是并不代表不会回收匿名页。
2.尽早触发 kswapd 内核线程异步回收内存
如何查看系统的直接内存回收和后台内存回收的指标?
我们可以使用 sar -B 1 命令来观察:

图中红色框住的就是后台内存回收和直接内存回收的指标,它们分别表示:
pgscank/s : kswapd(后台回收线程) 每秒扫描的 page 个数。
pgscand/s: 应用程序在内存申请过程中每秒直接扫描的 page 个数。
pgsteal/s: 扫描的 page 中每秒被回收的个数(pgscank+pgscand)。
如果系统时不时发生抖动,并且在抖动的时间段里如果通过 sar -B 观察到 pgscand 数值很大,那大概率是因为「直接内存回收」导致的。
针对这个问题,解决的办法就是,可以通过尽早的触发「后台内存回收」来避免应用程序进行直接内存回收。
上面说水位线的时候说过调整水位线来触发 kswapd 的启动时间
页低阈值(pages_low)可以通过内核选项 /proc/sys/vm/min_free_kbytes (该参数代表系统所保留空闲内存的最低限)来间接设置。
min_free_kbytes 虽然设置的是页最小阈值(pages_min),但是页高阈值(pages_high)和页低阈值(pages_low)都是根据页最小阈值(pages_min)计算生成的,它们之间的计算关系如下:
pages_min = min_free_kbytes
pages_low = pages_min*5/4
pages_high = pages_min*3/2
如果系统时不时发生抖动,并且通过 sar -B 观察到 pgscand 数值很大,那大概率是因为直接内存回收导致的,这时可以增大 min_free_kbytes 这个配置选项来及早地触发后台回收,然后继续观察 pgscand 是否会降为 0。
增大了 min_free_kbytes 配置后,这会使得系统预留过多的空闲内存,从而在一定程度上降低了应用程序可使用的内存量,这在一定程度上浪费了内存。极端情况下设置 min_free_kbytes 接近实际物理内存大小时,留给应用程序的内存就会太少而可能会频繁地导致 OOM 的发生。
所以在调整 min_free_kbytes 之前,需要先思考一下,应用程序更加关注什么,如果关注延迟那就适当地增大 min_free_kbytes,如果关注内存的使用量那就适当地调小 min_free_kbytes。
3.防止你的进程被OOM杀掉
在系统空闲内存不足的情况,进程申请了一个很大的内存,如果直接内存回收都无法回收出足够大的空闲内存,那么就会触发 OOM 机制,内核就会根据算法选择一个进程杀掉。
Linux 到底是根据什么标准来选择被杀的进程呢?这就要提到一个在 Linux 内核里有一个 oom_badness() 函数,它会把系统中可以被杀掉的进程扫描一遍,并对每个进程打分,得分最高的进程就会被首先杀掉。
进程得分的结果受下面这两个方面影响:
第一,进程已经使用的物理内存页面数。
第二,每个进程的 OOM 校准值 oom_score_adj。它是可以通过 /proc/[pid]/oom_score_adj 来配置的。我们可以在设置 -1000 到 1000 之间的任意一个数值,调整进程被 OOM Kill 的几率。
函数 oom_badness() 里的最终计算方法是这样的:
// points 代表打分的结果
// process_pages 代表进程已经使用的物理内存页面数
// oom_score_adj 代表 OOM 校准值
// totalpages 代表系统总的可用页面数
points = process_pages + oom_score_adj*totalpages/1000
用「系统总的可用页面数」乘以 「OOM 校准值 oom_score_adj」再除以 1000,最后再加上进程已经使用的物理页面数,计算出来的值越大,那么这个进程被 OOM Kill 的几率也就越大。
每个进程的 oom_score_adj 默认值都为 0,所以最终得分跟进程自身消耗的内存有关,消耗的内存越大越容易被杀掉。我们可以通过调整 oom_score_adj 的数值,来改成进程的得分结果:
如果你不想某个进程被首先杀掉,那你可以调整该进程的 oom_score_adj,从而改变这个进程的得分结果,降低该进程被 OOM 杀死的概率。
如果你想某个进程无论如何都不能被杀掉,那你可以将 oom_score_adj 配置为 -1000。
我们最好将一些很重要的系统服务的 oom_score_adj 配置为 -1000,比如 sshd,因为这些系统服务一旦被杀掉,我们就很难再登陆进系统了。
但是,不建议将我们自己的业务程序的 oom_score_adj 设置为 -1000,因为业务程序一旦发生了内存泄漏,而它又不能被杀掉,这就会导致随着它的内存开销变大,OOM killer 不停地被唤醒,从而把其他进程一个个给杀掉。
细节描述
内存分配的页查找
内核中常用的分配物理内存页面的接口函数是 alloc_pages(),用于分配一个或多个连续的物理页面,分配的页面个数只能是2的整数次幂。
alloc_pages(gfp_mask, order)
alloc_pages_node(numa_node_id(), gfp_mask, order)
__alloc_pages(gfp_mask, order, node_zonelist(nid, gfp_mask));
__alloc_pages_nodemask(gfp_mask, order, zonelist, NULL);

异步内存回收
每个内存节点node有一个页回收线程kswapd, 如果内存节点的所有内存区域的空闲页数小于高水线,
页回收线程就反复尝试回收页, 调用函数shrink node以回收内存节点中的页。
直接内存回收
针对备用区域列表中符合分配条件的每个内存区域,调用函数shrink node来回收内存
区域所属的内存节点中的页。
回收页是以内存节点为单位执行的,函数shrink_ node负责回收内存节点中的页。
回收不活动页
最后一个lur链表 不活动页的回收过程