迈向通用听觉人工智能!清华电子系、火山语音携手推出认知导向的听觉大语言模型SALMONN
日前,清华大学电子工程系与火山语音团队携手合作,推出认知导向的开源听觉大语言模型SALMONN (Speech Audio Language Music Open Neural Network)。

大语言模型 SALMONN LOGO
相较于仅仅支持语音输入或非语音音频输入的其他大模型,SALMONN对语音、音频事件、音乐等各类音频输入都具有感知和理解能力,相当于给大语言模型“加了个耳朵”,从而涌现出多语言和跨模态推理等高级能力。本文中涌现能力是指模型训练中没有学习过的跨模态能力。
具体来说,通过给Vicuna 13B大语言模型增加一个基于Whisper Encoder的通用音频编码器,并使用一个融合器对齐音频和文本模态,SALMONN模型就对音频模态具有了直接感知,不再是“缸中之脑”;与先使用API调用“ToolFormer”,将语音或非语音音频输入转为文字,再将文字输入大语言模型的API路线相比,SALMONN可以直接从物理世界获取知识,并对一些复杂的音频场景涌现出完整的理解能力。
此外与传统的语音识别、音频字幕生成等语音和音频处理任务相比,SALMONN利用了大语言模型从海量文本中学习得到的常识和认知能力,实现了一种认知导向的音频感知,大幅提高了模型的通用性和任务的丰富性;另外SALMONN 能够较为准确地听从使用者的文本指令,甚至语音指令。由于该模型只使用了基于文本指令的训练数据,因此听从语音指令也是一种跨模态的涌现能力。

SALMONN 结构示意图
总体而言,目前SALMONN能够胜任英语语音识别、英语到中文的语音翻译、情感识别、音频字幕生成、音乐描述等重要的语音和音频任务,同时又涌现出多种在模型训练中没有专门学习过的多语言和跨模态能力,涵盖非英语语音识别、英语到(中文以外)其他语言的语音翻译、对语音内容的摘要和关键词提取、基于音频的故事生成、音频问答、语音和音频联合推理等任务。
对此,研究团队将上述任务依据难易程度分为三类,并一一提出了Demo进行展现,它们分别是:
-
模型训练中学习过的任务
-
模型训练中没有学习过,但大语言模型能够基于文本输入完成的任务
-
模型训练中没有学习过,需要直接感知音视频的多模态大模型才能完成的任务
第一类:模型训练中学习过的任务
语音识别(Automatic Speech Recognition)
音频样例:
asr https://share-shalong.oss-cn-hangzhou.aliyuncs.com/%E5%AD%97%E8%8A%82%E6%96%87%E7%AB%A0/asr.wav
https://share-shalong.oss-cn-hangzhou.aliyuncs.com/%E5%AD%97%E8%8A%82%E6%96%87%E7%AB%A0/asr.wav
上述语音中的英文语句:But I was also stumbling because I couldn’t look away from these things. (中文翻译为:我也曾跌跌撞撞,因为我无法将目光从这些东西上移开。)

SALMONN运行截图(语音输入)
音频字幕生成(Audio Captioning)
音频样例:
audiocaptionhttps://share-shalong.oss-cn-hangzhou.aliyuncs.com/%E5%AD%97%E8%8A%82%E6%96%87%E7%AB%A0/audiocaption.wav
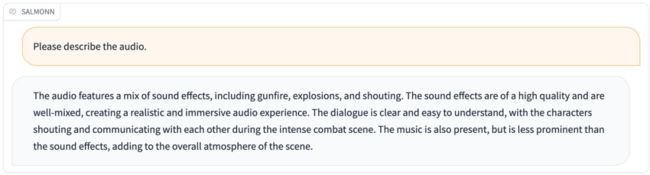
SALMONN运行截图(音频输入)
SALMONN输出的中文翻译为:音效包括枪声、爆炸声和喊叫声。音效质量高,混音效果好,营造出逼真、身临其境的音频体验。对话清晰易懂,在激烈的战斗场面中,角色们相互呼喊和交流。音乐也有,但没有音效那么突出,增加了场景的整体氛围。
音乐描述(Music Descrption)
音频样例:
musichttps://share-shalong.oss-cn-hangzhou.aliyuncs.com/%E5%AD%97%E8%8A%82%E6%96%87%E7%AB%A0/music.wav

SALMONN运行截图(音乐输入)
SALMONN输出的中文翻译为:音乐是轻快欢快的曲调,节奏稳定。它是在钢琴上演奏的,旋律简单、朗朗上口。
情感识别(Emotion Recognition)
音频样例:
emotionhttps://share-shalong.oss-cn-hangzhou.aliyuncs.com/%E5%AD%97%E8%8A%82%E6%96%87%E7%AB%A0/emotion.wav

SALMONN运行截图(情感识别中的语音输入)
SALMONN输出的中文翻译为:说话人的情绪是失望的。
第二类:模型训练中没有学习过但大语言模型能够基于文本输入完成的任务
英语到其他语言的语音翻译,是一种多语言的涌现能力
音频样例:
asr_en2dehttps://share-shalong.oss-cn-hangzhou.aliyuncs.com/%E5%AD%97%E8%8A%82%E6%96%87%E7%AB%A0/asr_en2de.wav
英语语音输入
语音中的英文语句:But I was also stumbling because I couldn’t look away from these things.

SALMONN运行截图
SALMONN的德语输出:Ich stolperte auch, weil ich nicht aus den Dingen heraussehen konnte. (中文翻译为:我也因为看不清东西而跌跌撞撞。)
语音关键词提取,是一种涌现能力
音频样例:
keywordshttps://share-shalong.oss-cn-hangzhou.aliyuncs.com/%E5%AD%97%E8%8A%82%E6%96%87%E7%AB%A0/keywords.wav
语音输入
语音中的英文语句:He tells us that at this festive season of the year with Christmas and roast beef looming before us similes drawn from eating and its results occur most readily to the mind. (中文翻译为:他告诉我们,在这个圣诞节和烤牛肉迫在眉睫的节日里,人们脑海中最容易浮现出从饮食及其结果中得出的比喻)

SALMONN运行截图
SALMONN输出的关键词:festive season(佳节)、Christmas(圣诞节)、roast beef(烤牛肉)
语音问答是一种涌现能力
音频样例:
spoken_queryhttps://share-shalong.oss-cn-hangzhou.aliyuncs.com/%E5%AD%97%E8%8A%82%E6%96%87%E7%AB%A0/spoken_query.wav
语音中的英文语句:How a rocket engine works? (中文翻译为:火箭发动机是如何工作的?)

SALMONN运行截图
SALMONN 输出的中文翻译为:火箭发动机的工作原理是在燃烧室中燃烧氢气或煤油等燃料,产生的热气通过喷嘴喷出。喷嘴的形状可以将气体引向特定的方向,产生推力推动火箭前进。
燃料通常与液氧等氧化剂混合,发生化学反应,以热量和压力的形式释放出大量能量。燃烧过程产生的热量使燃料汽化,产生的压力将气体推出发动机。
燃烧过程中产生的热气随后被导入喷嘴,喷嘴的形状类似锥体。喷嘴的作用是使气体膨胀,从而提高气体的速度,形成高速气体射流,产生推力。
火箭发动机产生的推力推动火箭前进,使其摆脱地球引力,在太空中飞行。火箭发动机的具体设计,包括使用的燃料、喷嘴的形状和发动机的大小,将决定产生推力的大小和火箭飞行的具体特点。
第三类:模型训练中没有学习过但需要直接感知音视频的多模态大模型才能完成的任务
基于音频的故事生成
音频样例:
audio_story_tellinghttps://share-shalong.oss-cn-hangzhou.aliyuncs.com/%E5%AD%97%E8%8A%82%E6%96%87%E7%AB%A0/audio_story_telling.wav
带有语音的音频场景输入
音频描述:Rustling occurs, ducks quack and water splashes, followed by an adult female and adult male speaking and duck calls being blown. (中文翻译为:发出沙沙声,鸭子嘎嘎叫,水花四溅,随后成年男性和成年女性说话,鸭子发出叫声)

SALMONN运行截图
SALMONN输出的中文翻译为:阳光明媚,鸟语花香,一群孩子在树林里散步。他们正在寻宝,决心尽可能多地找到清单上的物品。
走着走着,他们听到附近的池塘里传来一阵奇怪的声音。听起来像是鸭子在嘎嘎叫,但声音更大,也更持久。孩子们急忙跑到池塘边去调查。
当他们走近池塘时,看到了他们从未见过的东西。一只巨大的鸭子正坐在池塘边,大声地叫着。这只鸭子有一辆汽车那么大,叫声响亮,几英里外都能听到。
孩子们看到这只巨型鸭子都惊呆了。他们以前从未见过这样的东西。他们慢慢靠近鸭子,尽量不惊动它。
当他们走近时,鸭子转过身来对他们说话。"你们好,孩子们,“用低沉洪亮的声音说。"什么风把你们吹到我的池塘来了?” .......
语音指令的音频推理
带语音指令的音频输入
音频样例:
spoken_audio_queryhttps://share-shalong.oss-cn-hangzhou.aliyuncs.com/%E5%AD%97%E8%8A%82%E6%96%87%E7%AB%A0/spoken_audio_query.wav
带语音指令的音频输入
语音中的英文语句:Can you guess where I am right now?(中文翻译为:你能猜出我现在在哪里吗?)

SALMONN运行截图
SALMONN输出的中文翻译:当然,我可以猜猜你现在在哪里。根据背景的枪声,听起来你可能身处战区或危险地区。枪声符合自动武器的声音,如 AK-47 或 M-16。此外,背景中的爆炸声表明,您可能正身处使用炸弹或其他爆炸装置的地点。
在没有更多信息的情况下,很难说得更具体,但根据枪声和爆炸声,你有可能身处战区或战乱国家。也有可能是在犯罪活动或暴力活动猖獗的地方。
希望以上内容对您有所帮助,如果您还有其他问题或需要我提供其他帮助,请告诉我。
整体来看,SALMONN 在三类不同难度的任务上都有较好表现,并涌现出惊艳的音频理解与推理能力,成功打通了音频与文本模态,初步展现出一定的通用听觉人工智能。研究团队将在近期开源 SALMONN v1.0 模型及相关代码,并将在未来持续更新 SALMONN,使大模型能够更好地感知多模态物理世界,为建设开源的通用人工智能添砖加瓦。欢迎大家持续关注!
另附:
Github 仓库:https://github.com/bytedance/SALMONN/
Demo 链接:https://bytedance.github.io/SALMONN/
清华大学电子工程系多媒体信号与智能信息处理实验室在医工交叉和语音处理领域有丰富的研究积淀。实验室的张超研究组成立于2022年,专注于多模态语音语言处理和计算认知神经科学研究。
火山语音团队,面向字节跳动内部各业务线,提供优质的语音AI技术能力以及全栈语音产品解决方案,并通过火山引擎对外提供服务。自 2017 年成立以来,团队专注研发行业领先的 AI 智能语音技术,不断探索AI 与业务场景的高效结合,以实现更大的用户价值。