FPGA原理与结构——RAM IP核的使用与测试
目录
一、前言
二、RAM IP核定制
1、RAM IP核
step1 打开vivado工程,点击左侧栏中的IP Catalog
step2 在搜索栏搜索RAM,找到Block Memory Generator IP核:
2、IP核定制
step3 Baisc界面定制
step4 端口定制
step5 Other Options
step6 Summary
3、IP核例化
step7 例化
三、IP核测试
一、前言
本文介绍Block Memory Generator v8.4 IP核的具体使用与例化,在学习一个IP核的使用之前,首先需要对于IP核的具体参数和原理有一个基本的了解,具体可以参考:
FPGA原理与结构——块RAM(Block RAM,BRAM) https://blog.csdn.net/apple_53311083/article/details/132253916?spm=1001.2014.3001.5501 本文讲述了这个IP核使用的底层资源BRAM。
https://blog.csdn.net/apple_53311083/article/details/132253916?spm=1001.2014.3001.5501 本文讲述了这个IP核使用的底层资源BRAM。
FPGA原理与结构——RAM IP核原理学习https://blog.csdn.net/apple_53311083/article/details/132326228?spm=1001.2014.3001.5501 本文讲述了这个IP核的基本原理和具体参数
二、RAM IP核定制
1、RAM IP核
step1 打开vivado工程,点击左侧栏中的IP Catalog

step2 在搜索栏搜索RAM,找到Block Memory Generator IP核:

我们知道FPGA中的RAM可以分为DRAM和BRAM,今天我们要用到的时BRAM资源实现RAM,选择图中红色部分框选的IP核,双击打开。
2、IP核定制
step3 Baisc界面定制

①Component Name : IP核名字
②Interface Type : 接口类型,可选Native类型和AXI4类型,这里我们选Native类型
Memory Type : 存储器类型选择,对于RAM来说有三种可选(还有2种是ROM):单端口,简单双端口,真双端口,这里我们选择单端口RAM
③ECC Options :Error Correction Capability,纠错能力选项,单端口 RAM 不支持 ECC。
④Write Enable:字节写使能选项,勾中后可以单独将数据的某个字节写入 RAM 中,这里不使能。
⑤Algorithm Options:算法选项。可选择 Minimum Area(最小面积)、Low Power(低功耗)和 Fixed Primitives(固定原语),这里选择默认的 Minimum Area。
step4 端口定制
这里因为我们使用是单端口的RAM,所以只需要配置一个端口A就好了,如果使用的是双端口RAM,端口A和端口B需要独立进行配置。

① Memory Size
Write Width : 写位宽,这里设置为8
Read Width : 读位宽,允许和读的位宽不一致,但是要满足一定的比例要求,这里设置和写位宽一致,为8
Write Depth : 写深度,这里设置为32,这样就等于确定了我们的RAM的大小
Read Depth : 读深度,由于写位宽+写深度已经确定了RAM的大小,再结合读位宽,这里读深度已经唯一确定(写位宽*写深度/读位宽),这里就是8*32/8 = 32
② Operating Mode : RAM 读写操作模式。共分为三种模式,分别是 Write First(写优先模式)、Read First(读优先模式)和 No Change(保持模式)这里选择Write First模式。
Enable Port Type:使能端口类型。Use ENA pin(添加使能端口 A 信号);Always Enabled(取消使能信号,端口 A 一直处于使能状态),这里选择默认的 Use ENA pin。
③ Port A Optional Output Register:端口 A 输出寄存器选项。其中“Primitives Output Register”默认是选中状态,作用是打开 BRAM 内部位于输出数据总线之后的输出流水线寄存器,虽然在一般设计中为了改善时序性能会保持此选项的默认勾选状态,但是这会使得 BRAM 输出的数据延迟一拍,在这里我们只是进行一个简单的例化测试,为了使得我们的效果直观,我们不进行勾选。
④ Port A Output Reset Options:RAM 输出寄存器复位信号选项,这里不添加复位信号,保持默认即可。(注意是对输出寄存器复位,不是对RAM的复位)
⑤ READ Address Change A : 这是对于ultrascale系类的,普通的7系类不适用。
step5 Other Options

① Pipeline Stages within Mux:当使用多个BRAM资源来构成一个较大的RAM时,IP核提供了可选的0~3流水线结构来帮助优化性能,这里我们的RAM很小,一块BRAM(18Kb)就可以实现,所以不需要 。
② Memory Initialization : 内存初始化,简单说就是给RAM进行赋初值,可以有两种方式,一种是通过Coe文件写入,还有一种是直接把RAM赋同一个值,这里我们选择的就是第二种,全部赋值为0 。(也可以两种都不选)
③ :这里都是一些仿真的打印信息,我们保持默认。
step6 Summary

基本上所有的IP核设计的最后都会有一个Summary界面来帮助我们进行一个检查回顾,这里我们可以看到使用的是单端口RAM,用到了一个18Kb的BRAM资源,读延迟1个时钟周期,A端口的地址位宽为5 。
最后我们点OK,逐步完成IP核的生成。
3、IP核例化
step7 例化

对于IP核的例化来说,找到如下界面(IP Sources),图中标注了VHDL和Verilog的例化案例,我们以verilog为例
//----------- Begin Cut here for INSTANTIATION Template ---// INST_TAG
ram_v1 your_instance_name (
.clka(clka), // input wire clka
.ena(ena), // input wire ena
.wea(wea), // input wire [0 : 0] wea
.addra(addra), // input wire [4 : 0] addra
.dina(dina), // input wire [7 : 0] dina
.douta(douta) // output wire [7 : 0] douta
);
// INST_TAG_END ------ End INSTANTIATION Template ---------
// You must compile the wrapper file ram_v1.v when simulating
// the core, ram_v1. When compiling the wrapper file, be sure to
// reference the Verilog simulation library.把上述的代码赋值出来,进行模块例化就可以了。
设计的顶层代码如下:
module top(
input clk, //输入时钟
input ena, //ram使能信号
input wea, //ram读写选择
input [4:0]addra, //读写地址(共用)
input [7:0]din, //数据输入
output [7:0]dout //数据输出
);
ram_v1 ram_u1(
.clka(clk),
.ena(ena),
.wea(wea),
.addra(addra),
.dina(din),
.douta(dout)
);
endmodule
三、IP核测试
首先我们需要添加 仿真文件:
`timescale 1ns / 1ns
module tb_ram();
reg clk; //时钟
reg ena; //ram使能信号
reg wea; //ram读写选择,1写,0读
reg [4:0]addra; //ram地址
reg [7:0]din; //数据输入
wire [7:0]dout; //数据输出
initial begin
clk = 0;
ena = 0;
wea = 0;
addra = 0;
din = 0;
#30
ena = 1;
wea = 1; //写数据
repeat(30)begin
#10
addra = addra + 1;
din = din + 1;
end
wea = 0; //读数据
addra = 0;
repeat(30)begin
#10
addra = addra + 1;
end
#20
$finish;
end
always #5 clk = ~clk;
top tb_top(
.clk(clk),
.ena(ena),
.wea(wea),
.addra(addra),
.din(din),
.dout(dout)
);
endmodule
我们设计的仿真方式如下,首先向0~29地址内写入数据,随着地址每次加1,写入的数据也加1,一共写入30组数据,然后进行读操作,从地址0开始,把数据读出来
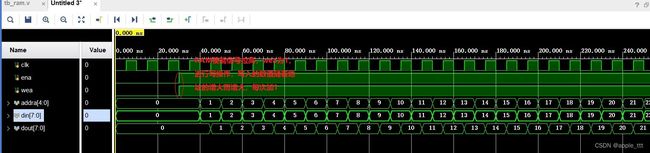
上图完成了写操作,从wea和ena同时拉高开始进行写操作,把数据依次写入RAM。
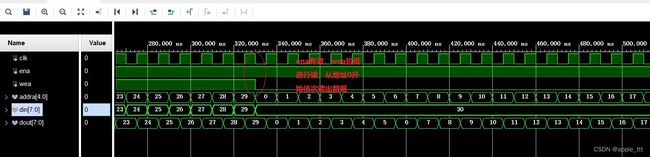
上图完成了读操作,从wea拉低开始进行读操作,从地址0开始依次读出之前写入的数据。
到这里我们就完成了IP核的测试,但是有一个小问题,在进行数据写入的时候,我们的dout已经有了输出的值,这其实是因为我们选择的是写优先模式,输入值被直接驱动到了输出端,如果我们不希望这时候dout有数据,可以设置为读优先模式,或者在写优先模式下通过wea增加一层组合逻辑的判断,这样就能实现我们的设计需求了。