Elasticsearch 常见面试题
Elasticsearch 常见面试题
- 常见面试题
-
- 1、ES 是什么?
- 2、ES 中的 集群、节点、分片、副本、索引、文档、映射、类型、字段 是什么?
- 3、倒排索引是什么?倒排索引的结构?Lucene什么?
- 4、ES 写入数据的 过程?(答下一题的 过程即可)
- 5、 ES 的底层 存储原理?
- 6、ES 读取数据(文档)的过程?
- 7、ES 删除、更改文档的过程?
- 8、ES 搜索的过程?检索文本
- 9、ES 如何选举master 节点?
- 10、ES 出现 脑裂的原因?如何解决?
-
- 脑裂 的成因:
- 脑裂问题 解决:
- 11、如何 监控 ES 的集群状态?
- 12、ES 的优化?存储设备优化?
- 13、ES JVM 调优?调整哪些参数?堆大小、GC、文件系统缓存大小?
- 14、ES 参数配置?分片数量?副本数量?
- 15、ES 参数配置?refresh时间?flush时间、translog 大小?
- 16、ES 在数据量很大的情况下(数十亿级别)如何提高查询效率啊?缓存、数据预热、冷热分离(可对于所有的数据库)
- 17、ES 分页性能优化?避免深度分页
- 18、在并发情况下,Elasticsearch 如果保证读写一致?
- 19、了解字典树吗?
- 20、拼写纠错 是如何实现的?

常见面试题
1、ES 是什么?
ElasticSearch 设计的理念就是分布式搜索引擎,底层其实还是基于 lucene 的。核心思想就是在
多台机器上启动多个 ES 进程实例,组成了一个 ES 集群。
2、ES 中的 集群、节点、分片、副本、索引、文档、映射、类型、字段 是什么?
集群:
- ElasticSearch 设计的理念就是 分布式搜索引擎,底层其实还是基于 lucene 的。核心思想就是在
多台机器上启动多个 ES进程实例,组成了一个 ES 集群。- ES集群由一个或多个Elasticsearch节点组成,每个节点配置相同的 cluster.name 即可加入集群,默认值为 “elasticsearch”。
节点:
- master 节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;
- data 节点负责数据的存储和相关的操作,例如对数据进行增、删、改、查和聚合等操作。
- 主节点和其他节点之间通过
Ping的方式互检查,主节点负责Ping所有其他节点,判断是否有节点已经挂掉。其他节点也通过Ping的方式判断主节点是否处于可用状态。分片:
- 索引可以拆分成多个 分片 ,每个 分片 存储部分数据。每个分片又可以拷贝多份,每分片有一个主分片和多个副本分片。
- 这样可以提高性能,数据分布在多个 分片,即多台服务器上,所有的操作,都会在多台机器 上并行分布式执行,提高了吞吐量和性能。
副本:
- 副本分片 就是 主分片的 备份。读数据时可在 主分片和 副本分片上读取,提高并发能力。且当主分片所在的节点宕机后,还有其他节点的分片可用。
索引:
- 索引 相当于 mysql 里的一张
表。存储着结构相近的数据。ES里是倒排索引,具有很高的搜索效率。文档:
- 文档 类比于 mysql 的一
行数据。映射:
- 映射 类比于 mysql 的
表结构定义,规定了 索引里的文档的字段名称 和 类型。字段:
- 字段 类比于 mysql 的
字段(列),是数据的标识。
3、倒排索引是什么?倒排索引的结构?Lucene什么?
倒排索引就是把原本文件ID对应到关键词的映射转换为
关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。在 ES 里面,
倒排索引主要由两部分组成:词典和倒排文件。
- 词典 就是 所有 关键词 的 集合。倒排文件 就是 记录这些关键词 对应的 文档ID 的文件。每个关键字,或说词条,都对应着一个 排序列表,记录着 这些词条出现的文档ID。
- 搜索时, 分词器会将 字符串 分解为 一些 词条。然后根据 倒排索引, 找到这些 词条对应的 文档。然后再对这些文档进行整合处理,得到最终的结果。
Lucene 是一个工具包,它不是一个完整的全文检索引擎。
- Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
- ES 就是 在Lucene 基础上开发的一个 搜索引擎。
4、ES 写入数据的 过程?(答下一题的 过程即可)
客户端发送写请求到任意一个 节点,成为
协调节点。协调节点对
文档ID进行路由计算,确定文档 属于哪个分片 ,然后选择该分片的主分片。然后将请求转发到 主分片 所在的节点上。节点 在该
主分片上 处理请求;在 ES 里, 数据是先写入内存 buffer 中的,然后。。。。(下面的过程)主分片 处理成功后,将请求
并行转发到所有 副本分片所在的节点上。所有副本分片都执行成功后,主分片所在节点向协调节点报告成功。协调节点 向 客户端 报告成功。
5、 ES 的底层 存储原理?
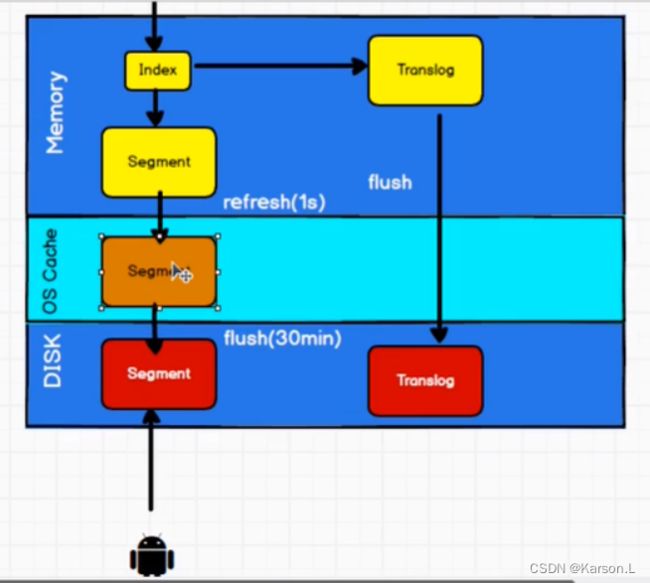
- refresh :数据先写入
内存 buffer,然后每隔一段时间,默认1s,将数据refresh到一个新的段中,
但是此时数据不是直接进入
磁盘文件,而是先进入文件系统缓存。这个过程就是refresh。
- 到了
文件系统缓存,数据就能被搜索到 (所以我们才说 es 是近实时搜索的,因为从写入到能被搜索到,中间有 1s 的延迟)。- 每隔
5s,将数据写入translog 文件(这样如果机器宕机,内存数据全没,最多会有 5s 的数据丢失)
- flush:当
translog大到一定程度(默认512MB),或者默认每隔 30mins,会出发一次flush 操作。
- 内存中的数据被
refresh到一个新的 段并 被写入到文件系统缓存中。- 然后,将一个
提交点写入磁盘文件,里面标识着这个提交点对应的所有 段 ;- 同时,
文件系统缓存中所有的数据通过fsync刷新到磁盘中。- 最后
清空现有translog日志文件并创建一个新的 translog。
补充
索引文档以段的形式存储在磁盘上,何为段?索引文件被拆分为多个子文件,则每个子文件叫作段,- 每一个
段本身都是一个倒排索引,并且段具有不变性,一旦索引的数据被写入硬盘,就不可再修改。在底层采用了分段的存储模式,使它在读写时几乎完全避免了锁的出现,大大提升了读写性能。- 段被写入到磁盘后会生成一个
提交点,提交点是一个用来记录所有提交后段信息的文件。一个段一旦拥有了提交点,就说明这个段只有读的权限,失去了写的权限。相反,当段在内存buffer中时,就只有写的权限,而不具备读数据的权限,意味着不能被检索。(在文件系统缓存中的段是可以被检索的)。- 在
refresh阶段:可以通过 es 的 restful api 或者 java api ,手动执行一次 refresh 操作,就是手动将buffer 中的数据刷入文件系统缓存中,让数据立马就可以被搜索到。只要数据被输入文件系统缓存中,buffer 就会被清空了,因为不需要保留 buffer 了,数据在translog里面已经持久化到磁盘去一份了。
6、ES 读取数据(文档)的过程?
- 客户端发送请求到任意一个 节点,成为
协调节点。 协调节点对文档ID 进行路由计算,确定文档 属于哪个分片 ,然后选择该分片的主分片或任一副本分片。- 然后将请求
转发到 选择的分片所在的节点。 具体选择主分片 还是 哪个副本分片,一般是使用round-robin 随机轮询算法,在主分片以及其所有副本分片 中随机选择一个, 让读请求负载均衡。
3… 节点 处理请求并 返回 文档 给 协调节点 。 协调节点 再将文档 返回 给客户端。
7、ES 删除、更改文档的过程?
删除和更新也都是
写操作,但是 Elasticsearch 中的文档是不可变的,因此不能被删除或者改动以展示 其变更;删除:
- 磁盘上的每个段都有一个相应的
.del 文件。当删除请求发送后,文档并没有真的被删除,而是在.del 文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。
当段合并时,在.del文件中被标记为删除的文档将不会被写入新段,这时才是真正的删除。(逻辑删除)更新:
- 在新的文档被创建时,Elasticsearch 会为该文档指定一个
版本号,当执行更新时,旧版本的文档在.del 文件中被标记为删除,新版本的文档被索引到一个新段。旧版本的文档依然能匹配查询,但是会在结果中被过滤掉。(更新 = 删除旧的,创建新的)写操作后主分片和副本分片的 一致:
- 当主分片把更改
转发到副本分片时,它不会转发更新请求。 相反,它转发完整文档的新版本。- 这些更改将会
异步转发到副本分片,并且不能保证它们以发送它们相同的顺序到达。- 如果 Elasticsearch 仅
转发更改请求,则可能以错误的顺序应用更改,导致得到损坏的文档。
8、ES 搜索的过程?检索文本
搜索被执行成一个两阶段过程,我们称之为
Query Then Fetch;
1、客户端发送请求到一个任意节点,该节点即为协调节点。
2、Query 阶段:(本地搜索之后再合并)
- 协调节点将搜索请求
转发到所有的 分片 对应的主分片 或 副本分片。- 每个分片在
本地执行搜索并构建一个匹配文档的大小为from + size的优先队列。 每个分片返回各自优先队列中所有文档的 ID和排序值给协调节点。- 协调节点
合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。3、Fetch 阶段:((按需拉取文档)
- 协调节点辨别出哪些文档
需要被取回并向相关的分片提交多个 GET 请求。 每 个分片加载并丰富文档,如果有需要的话,接着返回文档给协调节点。- 一旦
所有的文档都被取回了, 协调节点返回结果给客户端。
9、ES 如何选举master 节点?
发现机制:
- Elasticsearch 的主节点选举是
ZenDiscovery模块负责的,主要包含Ping(节点之间通过这个RPC来发现彼此) 和Unicast(单播模块包含一个主机列表以控制哪些节点需要 ping 通)这两部分。- Elasticsearch默认被配置为使用
单播发现,以防止节点无意中加入集群。只有在同一台机器上运行的节点才会自动组成集群。- 如果集群的节点运行在不同的机器上,使用单播,你可以为 Elasticsearch提供一些它应该去尝试连接的节点列表。当一个节点联系到单播列表中的成员时,它就会得到整个集群所有节点的状态,然后它会联系 master节点,并加入集群。
- 这意味着单播列表不需要包含集群中的所有节点,它只是需要足够的节点,当一个新节点联系上其中一个并且说上话就可以了。如果你使用 master候选节点作为单播列表,你只要列出三个就可以了。这个配置在 elasticsearch.yml 文件中: discovery.zen.ping.unicast.hosts: [“host1”, “host2:port”]
节点启动后先ping,如果 discovery.zen.ping.unicast.hosts 有设置,则 ping 设置中的 host ,否则尝试 ping localhost 的几个端口, Elasticsearch 支持同一个主机启动多个节点, Ping 的 response会包含该节点的基本信息以及该节点认为的 master 节点。选举过程: (参选人数达标、得票数过半、自己选了自己)
- 首先确认
参与选举的候选主节点数是否达标,即是否达到elasticsearch.yml 设置的值 discovery.zen.minimum_master_nodes;(一般是节点数/2+1,即过半)- 对所有可以成为 master的节点(node.master: true)根据
nodeId字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第0 位)节点,暂且认为它是 master 节点。- 如果对某个节点的投票数达到一定的值**(可以成为 master 节点数 n/2+1)**并且
该节点自己也选举自己, 那这个节点就是master。否则重新选举一直到满足上述条件。
10、ES 出现 脑裂的原因?如何解决?
脑裂 的成因:
- 网络问题:集群间的网络延迟导致一些节点访问不到master,认为master挂掉了从而选举出新的master,并对master上的分片和副本标红,分配新的主分片。
- 节点负载:主节点的角色既为master又为data,访问量较大时可能会导致**ES停止响应(假死状态)**造成大面积延迟,此时其他节点得不到主节点的响应认为主节点挂掉了,会重新选取主节点。
- 内存回收:主节点的角色既为master又为data,当data节点上的ES进程占用的内存较大,引发JVM的大规模内存回收,造成ES进程失去响应。
脑裂问题 解决:
适当调大响应时间,减少误判:
- 通过参数 discovery.zen.ping_timeout设置节点状态的响应时间,默认为3s,可以适当调大,如果master在该响应时间的范围内没有做出响应应答,判断该节点已经挂掉了。
调大参数(如6s, discovery.zen.ping_timeout:6),可适当减少误判。增加参与选举的候选节点数:
- 选举触发我们需要在候选集群中的节点的配置文件中设置参数 discovery.zen.munimum_master_nodes的值,这个参数表示在选举主节点时需要参与选举的候选主节点的节点数,默认值是1,官方建议取值
(master_eligibel_nodes/2)+1,即略大于候选节点数一半,其中master_eligibel_nodes为候选主节点的个数。- 这样做既能防止脑裂现象的发生,也能最大限度地提升集群的高可用性,因为只要不少于discovery.zen.munimum_master_nodes个候选节点存活,选举工作就能正常进行。当小于这个值的时候,无法触发选举行为,集群无法使用,不会造成分片混乱的情况。(
可用节点数太少,集群不工作,可防止出现分片混乱)角色分离:
- 即是上面我们提到的
候选主节点和数据节点进行角色分离,这样可以减轻主节点的负担,防止主节点的假死状态发生,减少对主节点“已死”的误判。
11、如何 监控 ES 的集群状态?
elasticsearch-head 插件
通过
Kibana监控 Elasticsearch。你可以实时查看你的集群健康状态和性能,也可以分析过去的集群、索引和节点指标。
12、ES 的优化?存储设备优化?
磁盘在现代服务器上通常都是瓶颈。Elasticsearch 重度使用磁盘,你的磁盘能处理的吞吐量越大,你的节点就越稳定。这里有一些优化磁盘 I/O 的技巧:
- 使用 SSD。就像其他地方提过的, 他们比机械磁盘优秀多了。
- 使用多块硬盘,并允许 Elasticsearch 通过多个 path.data目录配置把数据条带化分配到它们上面。
- 不要使用远程挂载的存储,比如 NFS 或者 SMB/CIFS。这个引入的延迟对性能来说完全是背道而驰的。
13、ES JVM 调优?调整哪些参数?堆大小、GC、文件系统缓存大小?
堆大小:
- 确保堆内存
最小值( Xms )与最大值( Xmx )的大小是相同的,防止程序在运行时改变堆内存大小。- Elasticsearch默认安装后设置的堆内存是 1 GB。可通过…/config/jvm.option 文件进行配置,但是最好不要超过物理内存的50% 和 超过32GB。
(建议 31G)GC:
- GC 默认采用
CMS的方式,并发但是有STW的问题,可以考虑使用G1收集器。文件系统缓存:
- ES非常依赖
文件系统缓存(Filesystem Cache),快速搜索。一般来说,应该至少确保物理上有一半的可用内存分配到文件系统缓存。
14、ES 参数配置?分片数量?副本数量?
- 分片和副本的设计为 ES 提供了支持
分布式和故障转移的特性,但并不意味着分片和 副本是可以无限分配的。- 索引的分片完成分配后由于索引的路由机制,我们是不能重新 修改分片数的。ES 默认分片数是1。 考虑一下 node数量,一般一个节点有时候就是一台物理机,如果分片数过多,大大超过了节点数, 很可能会导致一个节点上存在多个分片,一旦该节点故障,即使保持了 1 个以上的副本,同样有可能 会导致数据丢失,集群无法恢复。所以,
一般都设置分片数不超过节点数的 3 倍。- 主分片,副本和节点最大数之间数量,我们分配的时候可以参考以下关系:
节点数<=主分片数*(副本数+1)
15、ES 参数配置?refresh时间?flush时间、translog 大小?
减少 Refresh 的次数,增大refresh的时间
- Lucene 在新增数据时,采用了
延迟写入的策略,默认情况下索引的refresh_interval 为 1 秒。- Lucene 将待写入的数据先写到内存中**,超过 1 秒(默认)时就会触发一次 Refresh**, 然后 Refresh会把内存中的的数据刷新到操作系统的文件缓存系统中。
- 如果我们对搜索的实效性要求不高,可以将 Refresh 周期延长,例如 30 秒。这样还可以有效地减少段刷新次数,但这同时意味着需要消耗更多的 Heap 内存。
加大 Flush 设置,增加flush时间 或 translog大小
- Flush 的主要目的是把文件缓存系统中的段持久化到硬盘,当 Translog 的数据量达到
512MB或者30 分钟时,会触发一次 Flush。- index.translog.flush_threshold_size 参数的默认值是 512MB,我们进行修改。增大,可以较少刷盘次数。
- 增加参数值意味着文件缓存系统中可能需要存储更多的数据,所以我们需要为操作系统 的文件缓存系统留下足够的空间。
16、ES 在数据量很大的情况下(数十亿级别)如何提高查询效率啊?缓存、数据预热、冷热分离(可对于所有的数据库)
缓存
- 你往 es 里写的数据,实际上都写到磁盘文件里去了,查询的时候,操作系统会将磁盘文件里 的数据自动缓存到
filesystem cache里面去。 es 的搜索引擎严重依赖于底层的 filesystem cache ,你如果给 filesystem cache 更多的内存,尽量让内存可以容纳所有的 idx segment file 索引数据文件,那么你搜索的时候 就基本都是走内存的,性能会非常高。数据预热
- 对于那些你觉得比较热的、经常会有人访问的数据,最好做一个专门的
缓存预热子系统,就是对热数据每隔一段时间,就提前访问一下,让数据进入 filesystem cache 里面去。这样 下次别人访问的时候,性能一定会好很多。冷热分离
- es 可以做类似于 mysql 的
水平拆分,就是说将大量的访问很少、频率很低的数据,单独写一个索引,然后将访问很频繁的热数据单独写一个索引。最好是将冷数据写入一个索引中,然后热数据写入另外一个索引中,这样可以确保热数据在被预热之后,尽量都让他们留在 filesystem os cache 里,别让冷数据给冲刷掉。
17、ES 分页性能优化?避免深度分页
避免深度分页查询建议使用Scroll进行分页查询。
普通分页查询时,会创建一个from + size的空优先队列,每个分片会返回from + size 条数据,默认只包含文档id和分score给协调节点。
如果有n个分片,则协调节点再对**(from + size)× n** 条数据进行二次排序,然后选择需要被取回的文档。 当from很大时,排序过程会变得很沉重占用CPU资源严重。
18、在并发情况下,Elasticsearch 如果保证读写一致?
可以通过
版本号使用乐观并发控制,以确保新版本不会被旧版本覆盖,由应用层来处理具体的冲突;另外对于
写操作,一致性级别支持quorum/one/all,默认为quorum,即只有当大多数分片可用时才允许写操作。但即使大多数可用,也可能存在因为网络等原因导致写入副本失败,这样该副本被认为故 障,分片将会在一个不同的节点上重建。对于
读操作,可以设置replication 为 sync(默认),这使得操作在主分片和副本分片都完成后才会返回; 如果设置 replication 为async时,也可以通过设置搜索请求参数**_preference** 为 primary 来查询主分片,确保文档是最新版本。
19、了解字典树吗?
Trie 的核心思想是
空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目 的。它有 3 个基本性质:1)根节点不包含字符,除根节点外每一个节点都只包含一个字符。
2)从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
3)每个节点的所有子节点包含的字符都不相同。
- (1)可以看到,trie 树每一层的节点数是
26^i级别的。所以为了节省空间,我们还可以用动态链表,或者用数组来模拟动态。而空间的花费,不会超过单词数×单词长度。- (2)实现:对每个结点开一个字母集大小的数组,每个结点挂一个链表,使用左儿子右兄弟表示 法记录这棵树;
- (3)对于中文的字典树,每个节点的子节点用一个哈希表存储,这样就不用浪费太大的空间,而 且查询速度上可以保留哈希的复杂度 O(1)。
20、拼写纠错 是如何实现的?
拼写纠错是基于
编辑距离来实现;编辑距离是一种标准的方法,它用来表示经过插入、删除和替换操作从一个字符串转换到另外一个字符串的最小操作步数;