基于1.3.6, 仅个人理解,欢迎指正.
架构

master
启动类为org.apache.dolphinscheduler.server.master.MasterServer,通过spring注解@PostConstruct启动run方法.
master节点在启动时,主要做了以下4个事:
- 通过netty监听端口,与worker节点通信
- 在注册中心(zk)上注册自己
- 启动任务调度线程
- 启动quartz
其中quartz是一个定时任务的组件,可以通过数据库做集群.
worker
worker节点在启动时,主要做了以下:
- 监听端口,和master通信
- 通过注册中心注册
- 启动任务执行线程
- 启动任务ack和结果上报重试线程
RetryReportTaskStatusThread
master和worker节点都会监听端口,是因为双方都会作为客户端主动发送消息给对方.worker节点可查看org.apache.dolphinscheduler.server.worker.processor.TaskCallbackService#getRemoteChannel(int)代码,在原有连接不可用时会通过注册中心,找到原有的master的ip和监听端口,然后发起新的连接请求.master节点可查看NettyExecutorManager,作为客户端向worker发起请求.
logger
Logger节点目前仅仅是通过netty监听了一个端口,接受对日志文件的读取请求,主要逻辑都在org.apache.dolphinscheduler.server.log.LoggerRequestProcessor中.目前日志文件都是写到worker节点的本地文件,因此logger节点必须和worker节点一对一部署在一起.日志写到本地文件,对容器部署不是很友好,如果要持久化,势必需要通过持久化存储.个人感觉没什么必要特别的抽出这么一个节点,功能特别简单,又必须和worker节点一一部署在一起,完全可以合并入worker节点中,或许是为了后续扩展吧.
api
api节点是个web应用,提供controller接口为前端提供服务,主要就是crud.
alter
定时拉取数据库,发送告警信息,该节点应用只要部署一个就可以了.
服务注册与发现
master和worker节点在启动时都会作为服务端通过netty监听端口,只要客户端知道服务端ip和该端口,即可通过向其发起连接进行通信.
master注册
org.apache.dolphinscheduler.server.master.registry.MasterRegistry#registry
public void registry() {
// 1.获取本机地址
String address = NetUtils.getAddr(masterConfig.getListenPort());
// 2.master注册路径
String localNodePath = getMasterPath();
// 3.创建临时节点
zookeeperRegistryCenter.getRegisterOperator().persistEphemeral(localNodePath, "");
// 4.注册连接状态监听器
zookeeperRegistryCenter.getRegisterOperator().getZkClient().getConnectionStateListenable().addListener(
(client, newState) -> {
if (newState == ConnectionState.LOST) {
logger.error("master : {} connection lost from zookeeper", address);
} else if (newState == ConnectionState.RECONNECTED) {
logger.info("master : {} reconnected to zookeeper", address);
zookeeperRegistryCenter.getRegisterOperator().persistEphemeral(localNodePath, "");
} else if (newState == ConnectionState.SUSPENDED) {
logger.warn("master : {} connection SUSPENDED ", address);
zookeeperRegistryCenter.getRegisterOperator().persistEphemeral(localNodePath, "");
}
});
// 5.定时上报zk状态
int masterHeartbeatInterval = masterConfig.getMasterHeartbeatInterval();
HeartBeatTask heartBeatTask = new HeartBeatTask(startTime,
masterConfig.getMasterMaxCpuloadAvg(),
masterConfig.getMasterReservedMemory(),
Sets.newHashSet(getMasterPath()),
Constants.MASTER_TYPE,
zookeeperRegistryCenter);
this.heartBeatExecutor.scheduleAtFixedRate(heartBeatTask, masterHeartbeatInterval, masterHeartbeatInterval, TimeUnit.SECONDS);
logger.info("master node : {} registry to ZK successfully with heartBeatInterval : {}s", address, masterHeartbeatInterval);
}在状态上报完成后,zk节点状态如下图,data为本机状态等信息,用逗号隔开.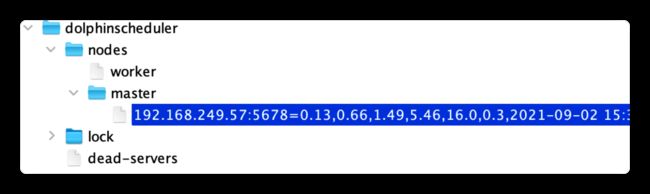
worker注册
org.apache.dolphinscheduler.server.worker.registry.WorkerRegistry#registry
public void registry() {
// 1.获取本机地址
String address = NetUtils.getAddr(workerConfig.getListenPort());
// 2. 获取zk路径,需要根据配置文件的worker group注册
Set workerZkPaths = getWorkerZkPaths();
int workerHeartbeatInterval = workerConfig.getWorkerHeartbeatInterval();
for (String workerZKPath : workerZkPaths) {
// 3.创建临时节点
zookeeperRegistryCenter.getRegisterOperator().persistEphemeral(workerZKPath, "");
// 4.注册连接状态监听器
zookeeperRegistryCenter.getRegisterOperator().getZkClient().getConnectionStateListenable().addListener(
(client,newState) -> {
if (newState == ConnectionState.LOST) {
logger.error("worker : {} connection lost from zookeeper", address);
} else if (newState == ConnectionState.RECONNECTED) {
logger.info("worker : {} reconnected to zookeeper", address);
zookeeperRegistryCenter.getRegisterOperator().persistEphemeral(workerZKPath, "");
} else if (newState == ConnectionState.SUSPENDED) {
logger.warn("worker : {} connection SUSPENDED ", address);
zookeeperRegistryCenter.getRegisterOperator().persistEphemeral(workerZKPath, "");
}
});
logger.info("worker node : {} registry to ZK {} successfully", address, workerZKPath);
}
// 5.定时上报zk状态
HeartBeatTask heartBeatTask = new HeartBeatTask(this.startTime,
this.workerConfig.getWorkerMaxCpuloadAvg(),
this.workerConfig.getWorkerReservedMemory(),
workerZkPaths,
Constants.WORKER_TYPE,
this.zookeeperRegistryCenter);
this.heartBeatExecutor.scheduleAtFixedRate(heartBeatTask, workerHeartbeatInterval, workerHeartbeatInterval, TimeUnit.SECONDS);
logger.info("worker node : {} heartbeat interval {} s", address, workerHeartbeatInterval);
} 在状态上报完成后,zk节点状态如下图: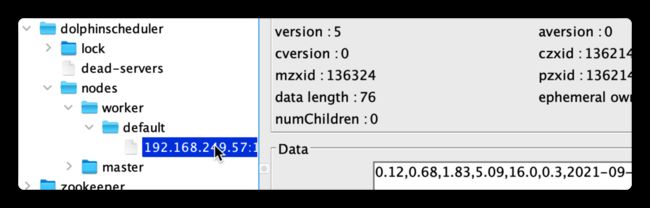
可见在default组下注册成功.
服务发现
服务注册完成之后,即可通过zk注册中心做到服务发现.通过查看ServerNodeManager代码可以得知,ds的服务发现是master负责的.其通过继承spring的InitializingBean在启动时执行以下代码
@Override
public void afterPropertiesSet() throws Exception {
/**
* 从zk中拿到master和worker节点
*/
load();
/**
* 定时同步表t_ds_worker_group的work group
*/
executorService = Executors.newSingleThreadScheduledExecutor(new NamedThreadFactory("ServerNodeManagerExecutor"));
executorService.scheduleWithFixedDelay(new WorkerNodeInfoAndGroupDbSyncTask(), 0, 10, TimeUnit.SECONDS);
/**
* 注册master节点变更监听器
*/
registryCenter.getRegisterOperator().addListener(new MasterNodeListener());
/**
* 注册worker节点变更监听器
*/
registryCenter.getRegisterOperator().addListener(new WorkerGroupNodeListener());
}查看WorkerNodeInfoAndGroupDbSyncTask代码,t_ds_worker_group表的任务组,应该不可以和配置文件的工作组重名.在有节点新增和删除时,zk回调监听器,然后同步修改本地缓存,为ExecutorDispatcher分发任务时使用.
调度流程
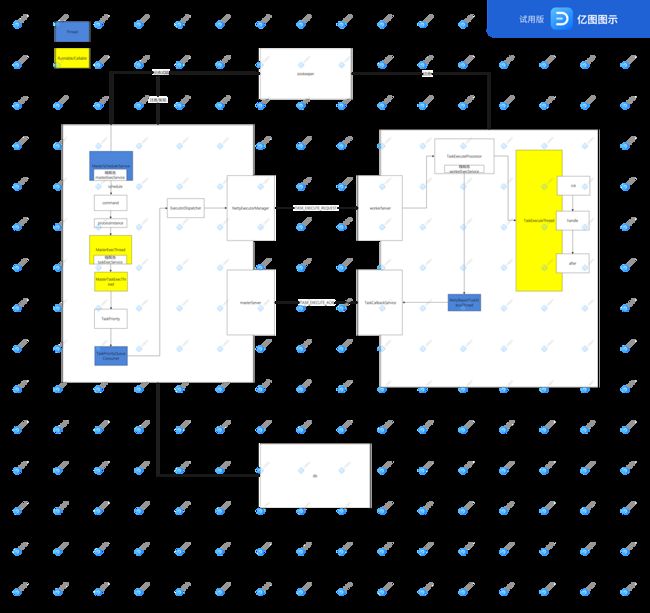
MasterSchedulerService
该线程在master节点启动时启动,循环调用scheduleProcess方法.
scheduleProcess
- 通过zk获取分布式锁
- 从t_ds_command表上拉取一条命令
处理该命令得到任务实例
- 构造任务实例
- 若任务实例为空,插入错误命令表t_ds_error_command,并删除该命令
- 若线程池数量不足,设置为等待线程状态
- 保存任务实例并删除该命令
- 线程池执行任务实例
command有很多种类型,定时触发的来源可以查看ProcessScheduleJob类,其继承Job,每次定时任务触发就会回调execute方法向command插入数据.
MasterExecThread
每个任务实例都会有一个该线程进行执行监控,普通任务调用executeProcess方法执行
prepareProcess
- 构建dag
初始化各个状态的任务节点队列
- readyToSubmitTaskQueue 准备好去提交的任务节点队列
- activeTaskNode 运行中的任务节点
- dependFailedTask 依赖节点失败
runProcess
- 提交没有依赖的任务节点到readyToSubmitTaskQueue队列
- 循环判断是否有完成的任务节点,并提交后继的任务节点
从readyToSubmitTaskQueue提交任务节点执行
endProcess
保存任务实例,如果是等待线程状态就创建一个恢复等待线程命令,最后发送告警
MasterTaskExecThread
在MasterExecThread循环中,会调用
submitStandByTask方法将readyToSubmitTaskQueue队列的任务节点提交到activeTaskNode中,提交任务节点的方法为submitTaskExec.其中普通任务创建了一个MasterTaskExecThread线程.每个任务节点都会有一个该线程来负责执行和监控状态.submit
首先提交到数据库,再通过dispatchTask方法分发任务到worker.循环提交尽量确保两者都完成
dispatchTask
构建TaskPriority对象并放入TaskPriorityQueueImpl队列,其中内部是一个线程安全的阻塞优先级队列PriorityBlockingQueue
waitTaskQuit
循环判断任务节点是否取消,暂停,完成,超时.其中取消会向worker节点发送TASK_KILL_REQUEST命令
TaskPriorityQueueConsumer
在dispatchTask方法中,任务被放入了一个任务优先级队列中,之后由TaskPriorityQueueConsumer线程来消费,该线程也是不断循环,从队列中获取任务,然后进行分发
dispatch
构建执行上下文,然后由ExecutorDispatcher分发
ExecutorDispatcherdispatch
首先获取ExecutorManager,目前只有一个NettyExecutorManager实现类.通过HostManager筛选出一个可执行的worker,默认会通过ServerNodeManager筛选出worker group下的worker节点
NettyExecutorManager
作为一个netty客户端向worker节点发送消息,其中对每个节点会重试3次,若失败则会向其他同组节点重试
任务执行的通信流程
上面貌似梳理了很多,但实际上才完成了任务开始执行时,master节点向worker节点发送的第一条消息TASK_EXECUTE_REQUEST的过程,而且过程中也省略了很多看不懂的代码.下图是任务节点执行过程中整个的master和worker的通信交互流程.
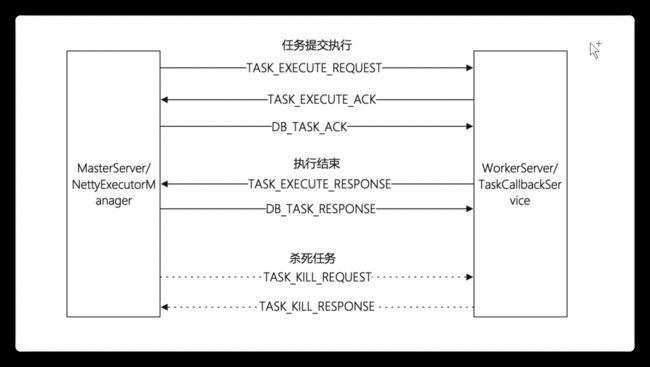
ds的netty封装
因为任务发送给worker以后,代码就执行到其他的节点上了,为了串联代码的调用流程,这里记录一下dolphinscheduler对netty的封装.
NettyRemotingServer
在构造方法中,根据入参配置,初始化了boss和work两个EventLoopGroup,然后在start方法中,设置tcp参数和ChannelPipeline,最后阻塞监听端口.其中业务逻辑都放在ChannelPipeline中.
initNettyChannel1
private void initNettyChannel(SocketChannel ch) {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast("encoder", encoder);
pipeline.addLast("decoder", new NettyDecoder());
pipeline.addLast("handler", serverHandler);
}首先添加的是编解码器,因为tcp传输的对象都是字节流,需要编解码器来负责字节流和java对象的相互转换.其中可以看到,编码器是共享的,解码器是每个管道都重新new的,这是因为在解码时由于tcp的粘包和拆包,需要缓存没有被解码的字节.
NettyServerHandler
首先先看一下userEventTriggered方法,这里处理了IdleStateEvent事件,但是刚才在initNettyChannel方法中是没有看到添加了IdleStateHandler的.在dev的最新代码上已经修复了.
processReceived
在接受并解码完成时,会回调该方法.消息体解码成Command对象之后,根据type找到通过registerProcessor方法注册的处理器NettyRequestProcessor对象和处理的线程池.耗时请求是不允许在io线程上执行的,会阻塞导致无法处理新的消息,所以这里使用线程池异步处理.
NettyRemotingClient
同样在构造方法中根据入参配置初始化boss和work两个EventLoopGroup,在start中设置tcp配置和初始化ChannelPipeline.此外多了一个responseFutureExecutor线程池处理超时的ResponseFuture.
sendAsync
异步发送消息,使用asyncSemaphore信号量控制了并发请求数量,opaque作为消息id对应请求和响应.在netty发送消息的回调中判断发送是否成功.
sendSync
同步发送消息,返回参为远程服务返回的响应.
ResponseFuture
因为worker和master之间的通信不是同步请求,因此ds设计了这个类用来异步转同步,和请求超时控制.其在构造方法中会放入全局的FUTURE_TABLE中被responseFutureExecutor线程监控是否超时.
waitResponse
阻塞等待响应,或者超时.latch在putResponse中被释放.
putResponse
放入响应,并去除全局的缓存.
NettyClientHandler
NettyRequestProcessor
这是具体业务逻辑的接口,负责处理不同的Command类型.
任务执行
在worker节点启动的时候可以看到,接收到TASK_EXECUTE_REQUEST消息时,注册的处理器是TaskExecuteProcessor
TaskExecuteProcessor
- 创建日志和执行文件夹
- 发送TASK_EXECUTE_ACK给master
交给线程池workerExecService执行
TaskExecuteThread
任务节点的执行线程
- 设置超时
- 通过TaskManager根据类型获得任务对象
- 依次调用任务对象的init,handle,after
发送TASK_EXECUTE_RESPONSE把执行结果告知master
TaskResponseService
master在接受到TASK_EXECUTE_ACK和TASK_EXECUTE_RESPONSE之后,都会把消息放到该类的eventQueue中,内部启动了一个线程负责持久化到数据库.然后发送DB_TASK_ACK和DB_TASK_RESPONSE消息到worker,让worker去除重试的缓存.
由于数据库中状态已经修改,那么MasterTaskExecThread的waitTaskQuit会退出循环.然后MasterExecThread的runProcess在遍历activeTaskNode时,future.isDone()的判断会通过,最终通过submitPostNode方法提交下面的任务节点.
容错
ZKMasterClient
dataChanged
通过zk的监听回调处理节点挂掉的容错.在该方法内根据类型分别处理master和worker节点挂掉的容错.
removeZKNodePath
通过获取zk锁防止多个节点容错.
failoverMaster
master容错.通过查表找到挂掉的master节点在处理的t_ds_process_instance.对每个ProcessInstance去除host,并创建一个容错恢复的command.最终调度线程会处理该命令.
failoverWorker
worker容错.找到所有挂掉的worker节点的host正在处理的TaskInstance,然后遍历修改状态为需要容错.对照MasterTaskExecThread线程,发现在typeIsFinished判断之后跳出循环,最终MasterExecThread线程也会感知到并重新提交给其他worker.
网络抖动
由于” 网络抖动”可能会使得节点短时间内失去和ZooKeeper的心跳,从而发生节点的remove事件。对于这种情况,我们使用最简单的方式,那就是节点一旦和ZooKeeper发生超时连接,则直接将Master或Worker服务停掉。
这段官网说明,对应代码中很多循环都会判断Stopper是否在运行.在HeartBeatTask中判断节点是否为挂掉的节点,若是调用stop.
改进
任务运行时需要很多线程配合,每个任务实例需要一个MasterExecThread线程,内部taskExecService线程池为20个线程(默认,当然不一定会启动这么多).单机可调度的数量会受到线程数量的限制.amee之前也是对每个任务都需要有一个线程来监控,后面修改为使用时间轮全局同一监控.在MasterSchedulerService中masterExecService线程池数量默认为100,说明默认情况下单机master只能同时调度100个任务实例.
很多状态是通过数据库来同步的,因此需要不断的在各处查询数据库,而全局维护的缓存此时已经失去了意义.不仅对数据库产生了压力,代码个人感觉也比较乱.有一个全局统一的模型,各处修改都对该模型进行修改或许更好.api节点对数据库的修改(例如暂停)需要通知到master.
优势
可视化,这是ds相较而言最大的优点.dag的创建,各种任务参数的设置,数据源,文件资源,运行时的状态监控等等都可以在页面上直观的看到.不过如果是二次开发成我们自己的产品,页面设置和展示肯定是自己做的.
支持水平扩展,容错,HA,非常适合于容器化部署(内部使用ip来标识,这里在k8s环境会有问题)
深度支持大数据环境的各种任务,对大数据场景来说可以做到真正意义上的开箱即用.