linux-进程
文章目录
- 1.先谈硬件
-
- 冯诺依曼体系结构
- 2.再谈软件
-
- 操作系统
-
- 什么是操作系统?
- 为什么要有操作系统?
- 如何管理?
- 系统调用
- 3.再谈进程
-
- 那么具体Linux是怎么做的?
-
- 指令 ps ajx 查看所有进程 非实时
- top 实时查看进程 相当于任务管理器
- ls /proc 内存级进程可视化.,系统中动态运行的进程信息
- 后续要学习tast_struct结构体内描述进程的各种属性
- 创建进程的方法
-
- fork()创建子进程
- 执行流
- 问题
- 问题二
- 进程状态
-
- 1.介绍操作系统学科 中 进程状态,运行,阻塞,挂起
-
- 运行态
- 阻塞状态
- 挂起
- 2.具体Linux状态如何维护的?
-
- R 运行态
- S状态 阻塞态 浅度睡眠(可被唤醒)
- D状态 深度睡眠 不响应任何请求 阻塞态
- T && t
- X(dead)
- Z(zombie)
- 孤儿进程
- linux中对应挂起状态
- Linux中tast_struct(pcb)结构体对象组织交叉
- 进程优先级
- 操作系统是如何根据优先级,开展的调度呢???
-
- 位图
- Linux内核的O(1)调度算法!
1.先谈硬件
冯诺依曼体系结构
除了Cpu和内存,其他都是外设
一个计算机能够正常运行,就必须遵守冯诺依曼体系
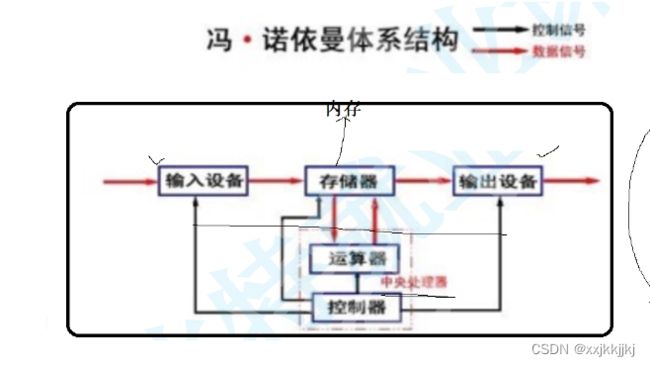
数据流向
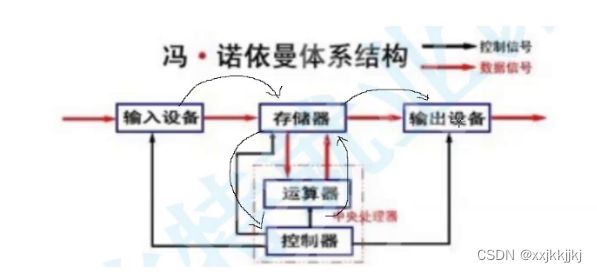
为什么不把Cpu直接怼到输入设备和输出设备中间,非要加个内存呢?
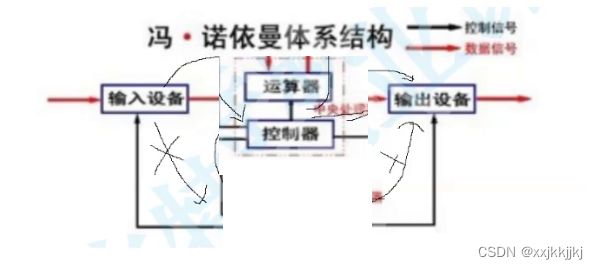
答:因为根据木桶原理,如果这样设计,导致最终效率会由外设的效率为主,而外设非常慢。
并且Cpu 的存储空间非常小,就注定了外设会拖慢cpu

那么按照冯诺依曼体系结构,这种依然串行的结构,输入设备把数据拷到内存,内存在拷到cpu,输出同理,好像也没快多少?
是的,但是可以把数据从输入设备预加载到内存之中,并且在加载过程中cpu同时处理别的事情,接下来cpu就只和内存进行交互,也就是说cpu的加载和计算可以同时进行,我们就由串行变成并行,经过这样的运行调度,所以各个硬件就可以并行跑起来,所以效率提高了。
这个调度是谁做的?操作系统
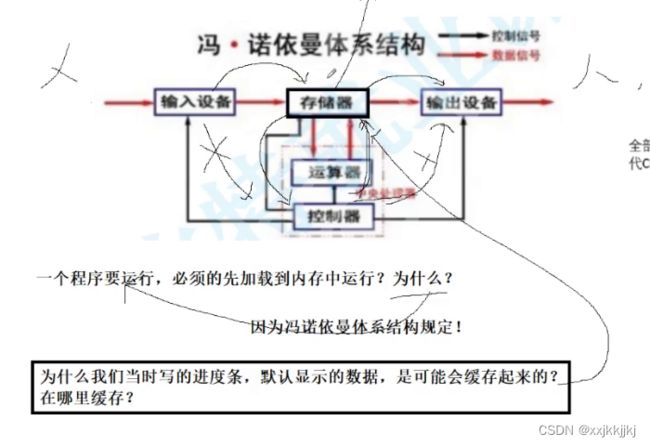
一个程序要运行,必须先加载到内存中运行?为什么?
因为冯诺依曼体系结构规定!
你的代码和数据要让cpu运行,而cpu只从内存中拿数据,而程序是在外设磁盘上,就注定要把程序先加载到内存
为什么我们当时写的进度条,默认显示的数据,是可能会缓存起来的?
在哪里缓存?
按照正常数据流向,数据换成到内存中的某个区域,只不过没有刷新它
2.再谈软件
操作系统
什么是操作系统?
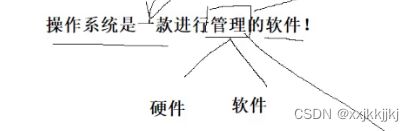
为什么要有操作系统?
对下管理好软硬件资源
对上提供良好的运行环境
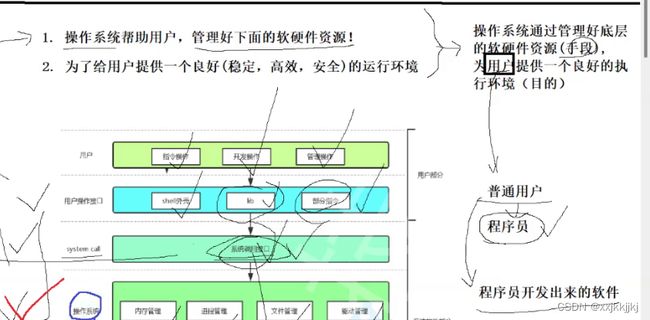
如何管理?

管理 建模
所有的计算机世界,软件,代码都遵循 先描述再组织
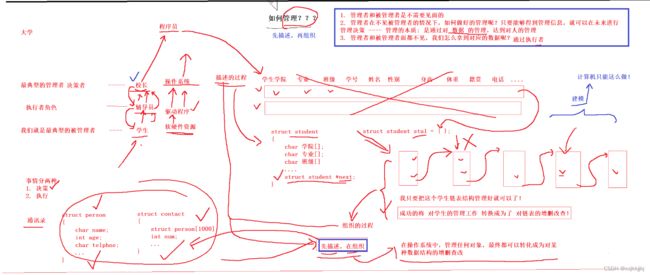
拿数据是通过执行者,也就是驱动程序,拿到软硬件相关数据
在操作系统内部要对被管理对象进行建模,形成对应的某种数据结构,所以对软硬件资源的管理转换成对某种数据结构的增删查改

之前在学习数据结构queue时,对于把头尾结点指针用结构体包起来的操作不是很懂,那现在学过先描述再组织,就很好理解了,就是用结构体来描述队列的属性(队头,队尾),再利用链表增删改查进行组织。
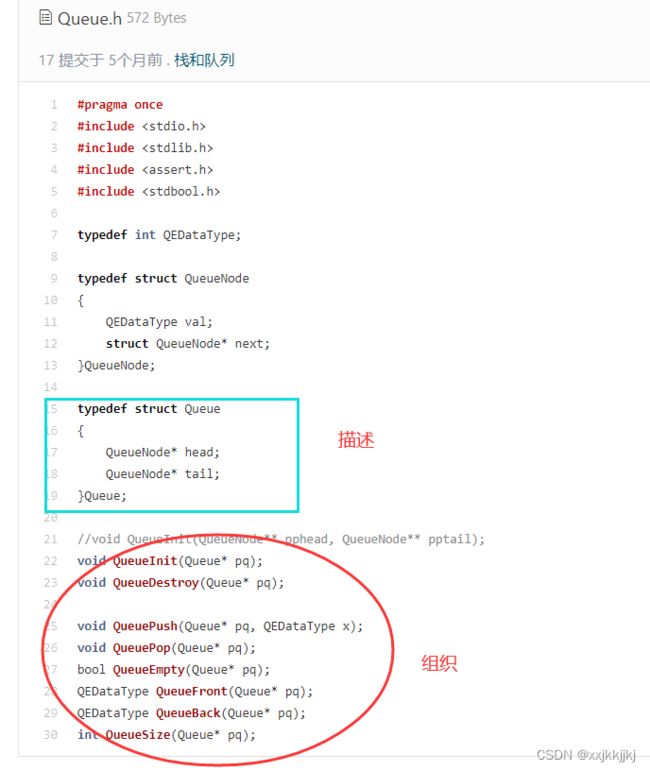
学习C/C++在告诉我们如何描述,学数据结构是为了学习如何组织。
系统调用
用户能不能绕过操作系统直接访问硬件?
答:不能,你不会,你不懂硬件
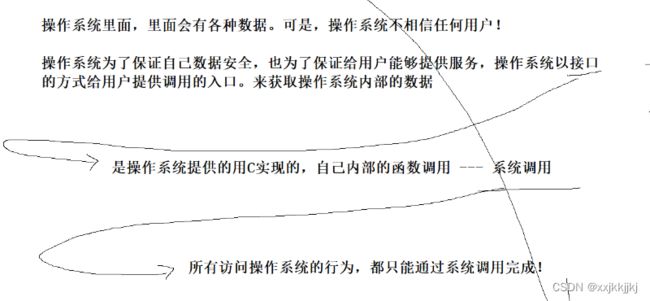

语言在变,操作系统的思想是不变的
任何语言要进行访问硬件,必须经过操作系统,他要经过操作系统就必须得系统调用
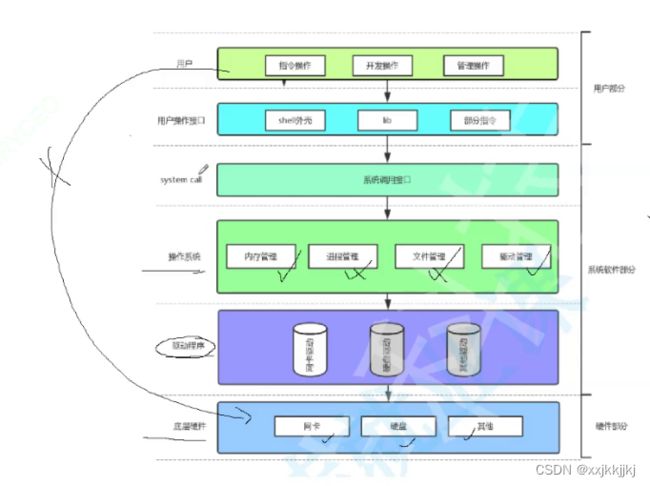
3.再谈进程
左手计算机体系层状结构系统调用的概念,右手操作系统管理的核心思路
7-28 15min:46

利用属性来构建pcb结构体对象,对象中充满了描述进程的属性
单独PCB不叫进程
因为一个程序要运行,就必须将它的代码和数据加载的内存之中
单独代码和数据也不叫进程,它就像教务系统里面没有保安的信息
pcb + 代码数据才叫进程
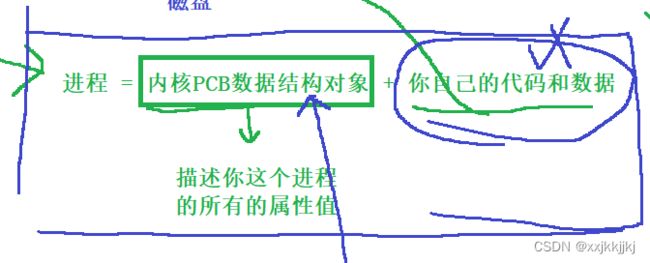
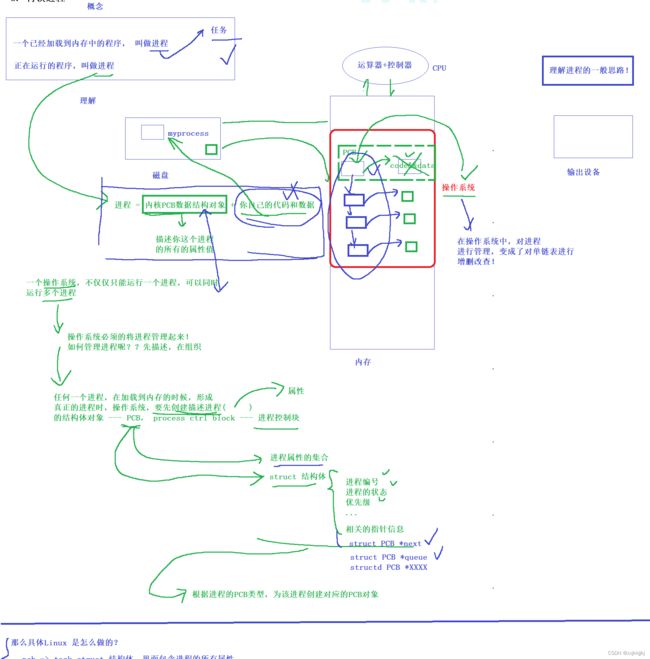
对进程进行管理,一个进程要进入运行队列或者阻塞队列是进程的PCB在排队,而不是它的代码和数据在排队
那么具体Linux是怎么做的?
pcb -> task_struct结构体,里面包含进程的所有属性
Linux中如何组织进程,Linux内核中,最基本的组织进程task_struct的方式,采用双向链表组织的
指令 ps ajx 查看所有进程 非实时
top 实时查看进程 相当于任务管理器
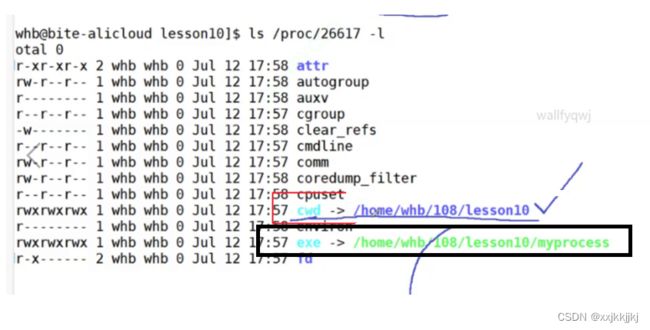
ls /proc 内存级进程可视化.,系统中动态运行的进程信息
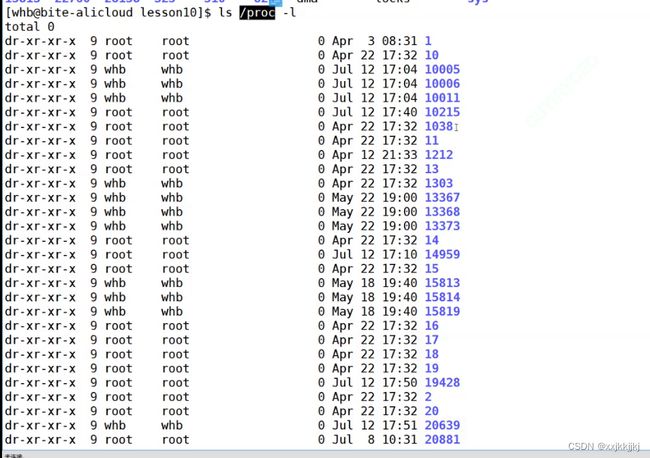
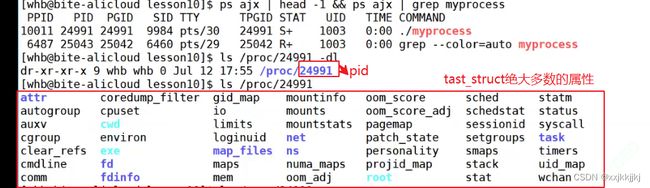
后续要学习tast_struct结构体内描述进程的各种属性

-
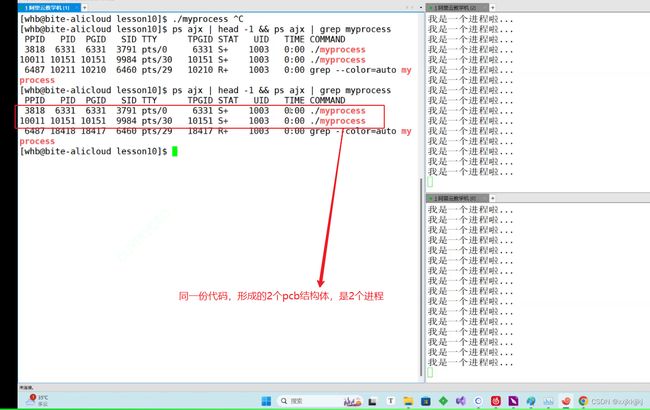
pid
唯一标识符操作系统为了管理这两个进程要创建2个不同的pcb结构体
-
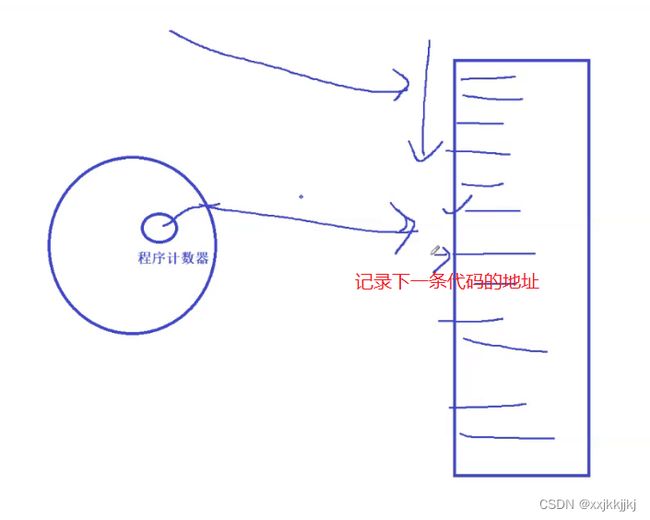
程序计数器(pc指针),eip
-
cwd 当前工作目录
为什么touch test.c 我们没给在哪里创建,当touch变成进程时,他怎么知道是在哪里创建呢?
因为touch进程启动时,有自己的当前工作目录,所以可以不用带路径

-
exe->指向的是二进制可执行程序所在目录
创建进程的方法
- ./运行我们的程序—指令级别
- fork() ----代码层面创建的子进程
fork()创建子进程
代码
#include 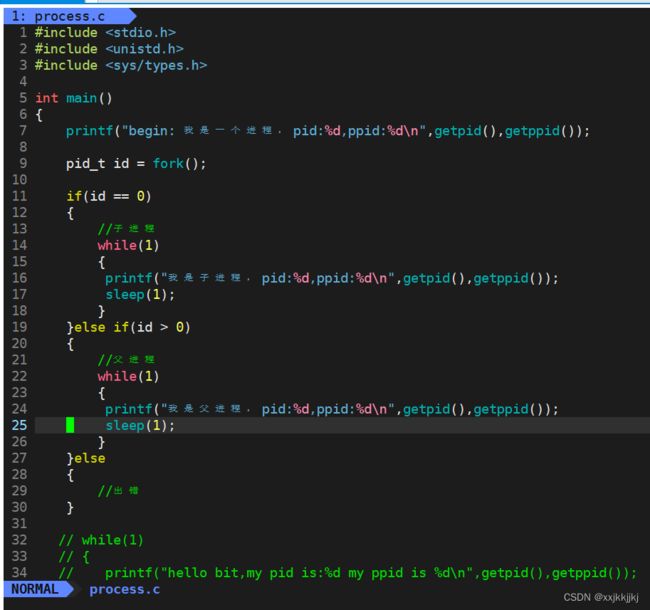

getpid,getppid是系统调用接口,其实就是C语言写的函数
用来获取pid和父进程的pid
执行流
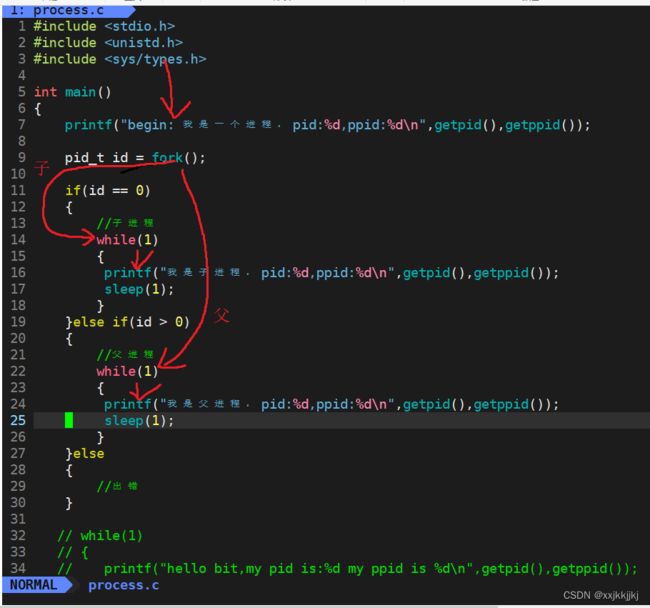
fork创建了新的子进程,变成了2个执行流
问题
1.为什么fork要给父进程返回子进程pid,给子进程返回0?

fork函数是干什么的?它做了什么?
fork()也是一个函数
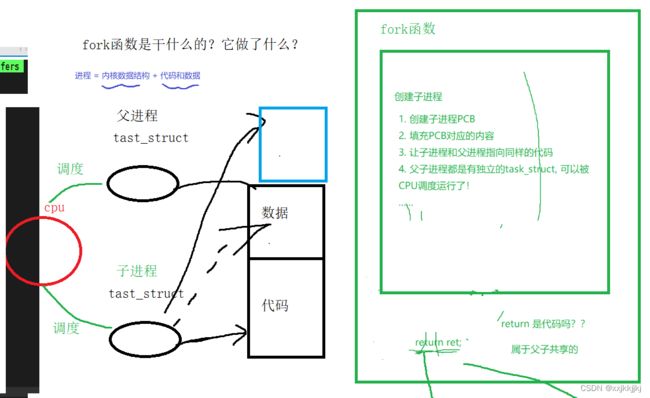
2.一个函数是如何做到返回两次的?如何理解?
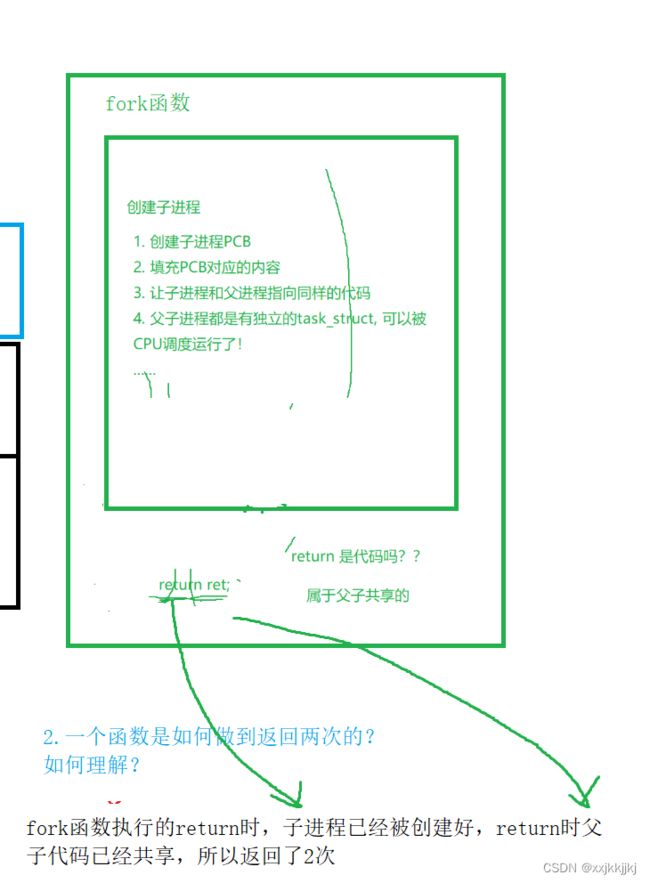
return ret是代码,父子共享,到达return时创建子进程的工作早就做完了,子进程允许被cpu调度了,所以return时就返回了2次,父进程1次,子进程1次
- 为什么id具有不同的值,既等于0,又>0?
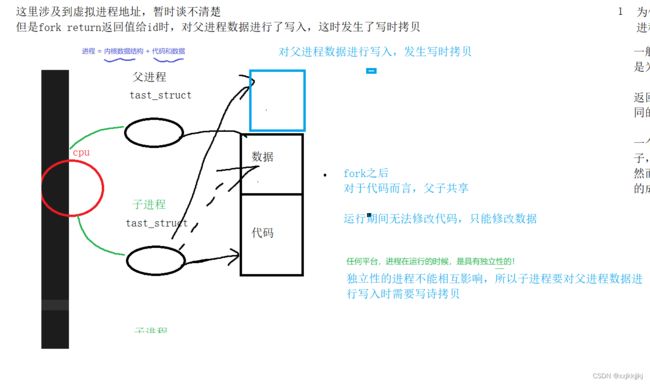
父进程是带资进组的,上来就有代码和数据,但是子进程是没有代码和数据的,所以只能子进程共享父进程的代码。
父进程有它自己的数据,子进程必须也要有数据,根据进程在运行时,具有独立性,所以绝对不能父子访问同样的数据!
父子进程对同一份代码进行读取,他们互不影响,而代码在运行时无法修改,只能修改数据。
共享代码并不影响独立性
所以子进程要把数据单独拷贝一份,而且没必要完全拷贝父进程的所有数据,子进程有可能根本不会访问父进程的任意一个数据(通篇拷贝有效率负担)。操作系统识别:当子进程尝试去修改父进程的数据时,才会拷贝一份新的数据,子进程用多少,给你申请多少,这种技术称为:数据层面的写时拷贝! 这样父子进程就不会互相影响。
id是父进程的数据,return的时候是写入
那么必定发生写时拷贝,所以子进程访问的是拷贝出来的新数据,父进程访问的是老数据
所以他们两个看起来是同一个id,但实际上访问的是不同的内存
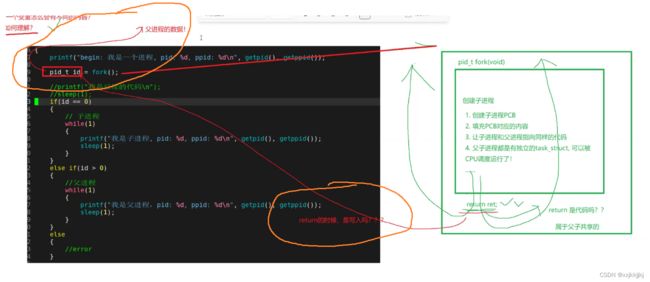
但我还是不懂为什么同一个变量名是如何做到让父子进程看到不同的内容呢?
地址空间再说
问题二

调度器尽可能做到公平调度
bash(王婆) 为了不砸自己招牌,创建了子进程,这样子进程崩了就不会影响Bash
bash如何创建子进程呢?
答:fork()

进程状态
1.介绍操作系统学科 中 进程状态,运行,阻塞,挂起
运行态
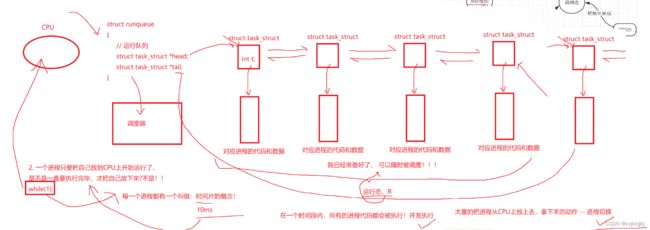
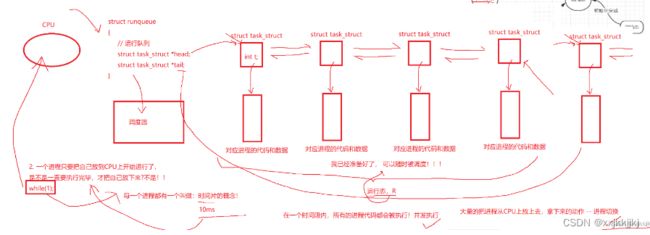
一个Cpu绑定一个运行队列,4个cpu有4个运行队列
运行队列
只要在运行队列里就叫运行态(R)
调度器(函数)把struct runqueue当作参数传入调度器,调度器就可以看到所有运行队列上的PCB
2.一个进程只要把自己放到CPU上开始运行了,是不是一直要执行完毕,才把自己放下来?
每个进程都有一个时间片概念,每个进程在cpu最多跑个10ms,就被扒下来,继续排队
在一个时间段内,所有的进程代码都会被执行! 并发执行
大量的把进程从CPU上放上去,拿下来的动作–进程切换
不要拿自己的感受来衡量cpu,cpu对运行队列的进程切换太快了!
阻塞状态
进程像访问的软硬件资源未就绪,如果进程等待键盘的资源,那么就把进程链入到键盘pcb的等待队列里。
如果进程得到了键盘的资源,那么cpu就会把进程链接到运行队列中(唤醒,把S改成R)
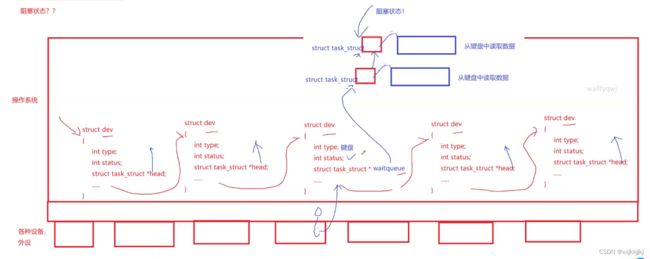
进程也有等待队列,进程也会等待进程
每一个设备都有自己的等待队列,甚至不止一个
挂起
进程的PCB和代码数据都在内存中,当操作系统内部的内存资源严重不足时,为了节省内存资源,操作系统保留PCB,把代码和数据交换到磁盘(外设)中,当资源就绪时,把进程放到运行队列时,把代码和数据重新放回内存中。

2.具体Linux状态如何维护的?
R 运行态
不要用自己的感知和CPU的速度做对比!
等待外设大概率是S状态
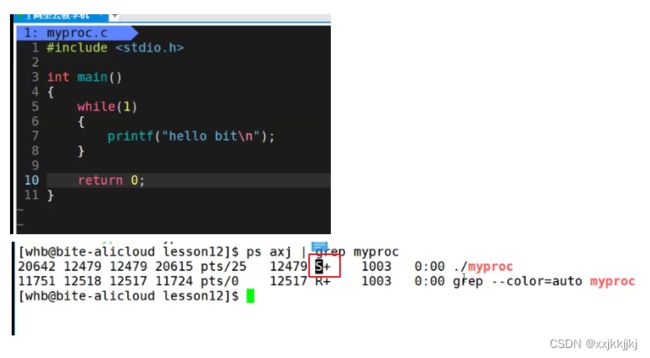
不涉及外设
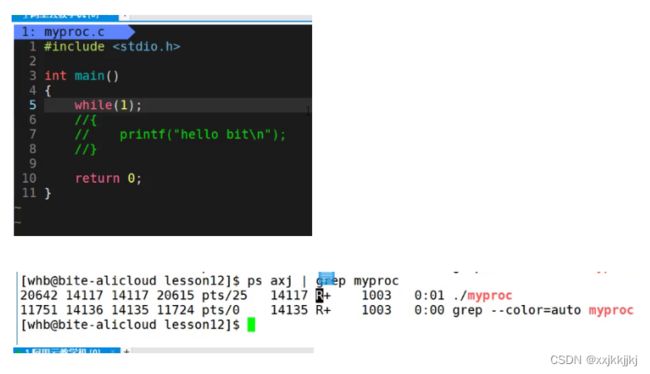
R+ 前台运行
./myproc & 后台运行 后台运行只能kill杀掉
S状态 阻塞态 浅度睡眠(可被唤醒)
情况1.等待某种资源就绪
情况2.主动sleep,99%都在等待,1%是运行打印,因为CPU太快了
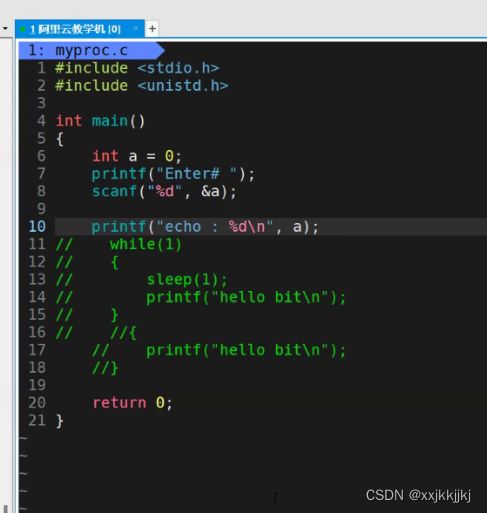
![]()
D状态 深度睡眠 不响应任何请求 阻塞态
dish sleep 磁盘 = disk
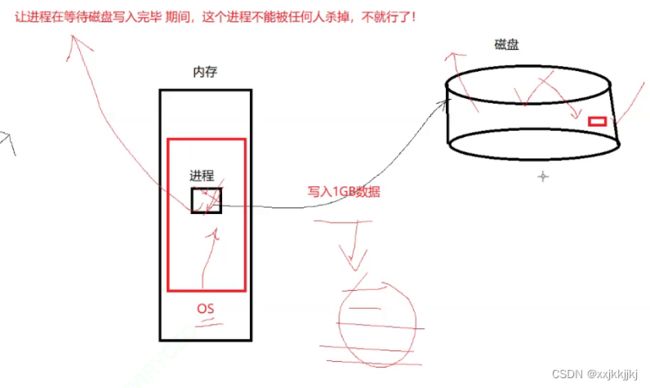
进程交给磁盘写入任务,等待外设过程中,操作系统内部内存严重不足,os把能置换的内存都置换了,此时Os会杀掉进程,导致磁盘写入完成后的数据丢失。
但是磁盘写入的数据很重要所以只要当前进程有写入任务交给了磁盘,如果磁盘没有办法立马响应的话,需要进程等待,这个进程绝对不能以浅度睡眠的状态等待,必须把自己设为D状态,任何人不能杀掉包括操作系统。
当磁盘写完数据告诉进程时,进程把自己D变成R继续运行。
操作系统中如果看到1个D状态进程,在这种内存严重不足,高IO磁盘压力很大,那么操作系统就要挂了
如果内存充裕,那么大概率是S状态
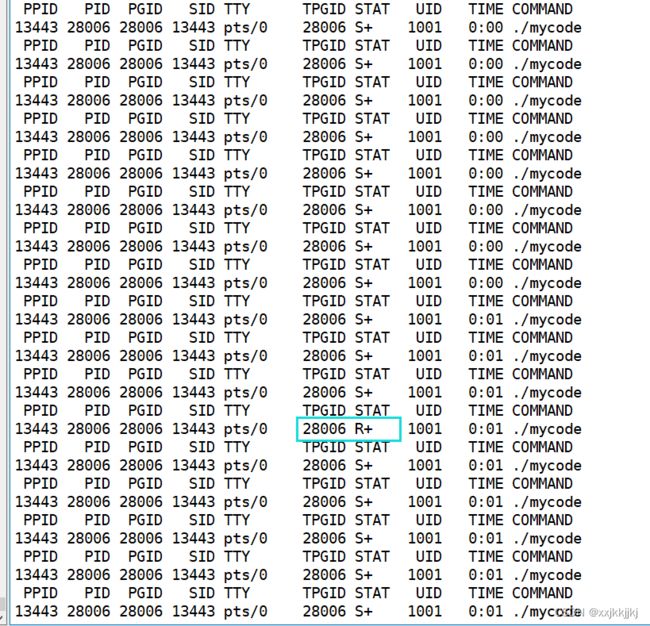
while :; do ps ajx | head -1&& ps ajx | grep mycode | grep -v grep; sleep 1;done
D和S都是阻塞态,操作系统是理论,实际有所差别
T && t
T和t已经没啥区别了
18-19号信号,对进程发送暂停继续信号
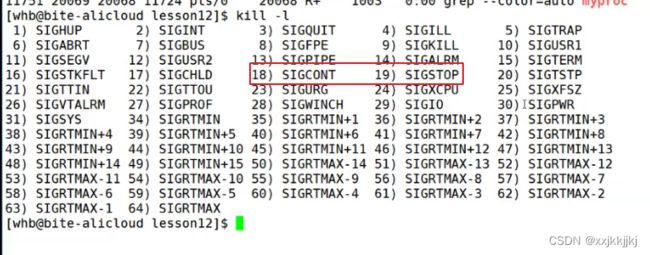
S和T状态有啥区别?
T叫做暂停,可能等待某种资源,或者就是想暂时暂停控制一下
T也可以理解为操作系统级别的阻塞状态
t应用场景
gdb打断点调试时,对进程发送暂停信号进行了暂停
X(dead)
进程死亡 回收,瞬时状态很难看到
Z(zombie)
一个进程退出(死亡)时并不会立即释放它的所有资源,它会维持一段时间,把资源交给父进程读取
僵死状态(Zombies)是一个比较特殊的状态。当进程退出并且父进程(使用wait()系统调用,后面讲)
没有读取到子进程退出的返回代码时就会产生僵死(尸)进程
僵死进程会以终止状态保持在进程表中,并且会一直在等待父进程读取退出状态代码
只要子进程退出,父进程还在运行,但父进程没有读取子进程状态,子进程进入Z状态
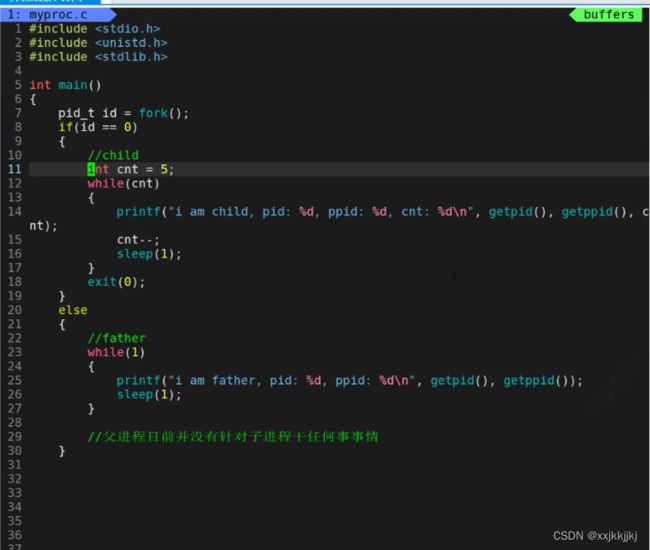

问题1 : 父进程怎么没有僵尸呢?
父进程的父进程是Bash,当程序结束时,bash直接回收父进程
问题2:子进程为什么也结束了?
操作系统systemd or init 领养了子进程
父进程未回收子进程,造成子进程一直维护PCB
并且僵尸进程会造成系统级内存泄漏
如果进程放在一个循环里,一直造成内存泄露,虽然说最后进程结束会被操作系统领养但是进程运行期间就不断的内存泄漏
孤儿进程
父子进程,父进程先退出,子进程的父进程会被改成1号进程(操作系统),

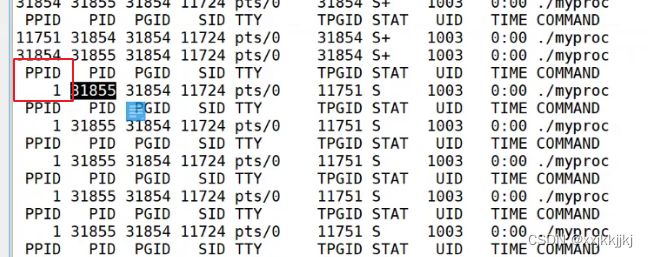
linux中对应挂起状态
挂起后用户感知不到,就像银行存钱,银行拿着钱干什么了,我们不知道,用的时候再还给你
但是一般对应的是T状态 或者 S状态
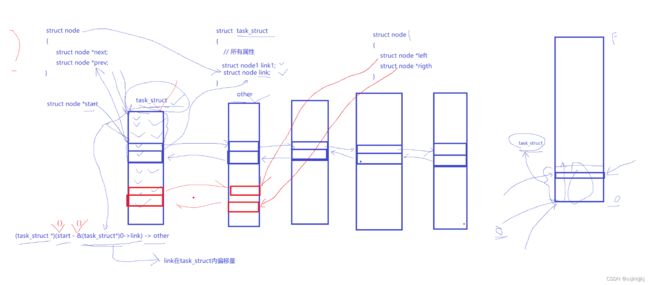
Linux中tast_struct(pcb)结构体对象组织交叉
Linux中tast_struct(pcb)结构体对象的组织是交叉在一起的,一个进程既属于某个多叉树又属于某一个双向链表,所以一个结点即可以放到多叉树又可以放到链表中。
Linux的设计是比较优雅的
Linux并没有像我们数据结构一样把数据放到strue node中,而是把node放到tast_struct里面串起来
利用0号地址结构体寻找node地址偏移量,再用start-偏移量,找到tast_struct的地址
还要注意指针-指针需要无脑转int or char*,不然指针-指针是元素个数
优雅在于不同于task_struct的结构体与other类型也可以被链表node所链接起来
并且tast_struct可以链接到不同结构的数据结构中,双向链表,二叉树,只需要在tast_struct中放入struct node
进程优先级
什么是优先级?
优先级(对于资源的访问,谁先访问,谁后访问) vS 权限(能与不能)
优先级是已经有权限了决定谁先谁后
为什么要有优先级?
因为资源是有限的,进程是多个的,注定了,进程之间是竞争关系! —竞争性
操作系统必须保证大家良性竞争,确认优先级
如果我们进程长时间得不到CPU资源,该进程的代码长时间无法得到推进—该进程的饥饿问题
怎么办?
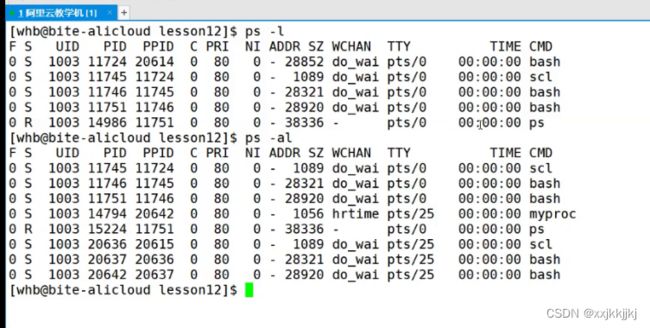
查优先级
ps -l
默认打开当前终端启的进程
ps -al
打开所有终端进程
更改优先级

方式1.nice
方式2.renice
方式1.top后按r
每次更改都会PRI都会从80开始
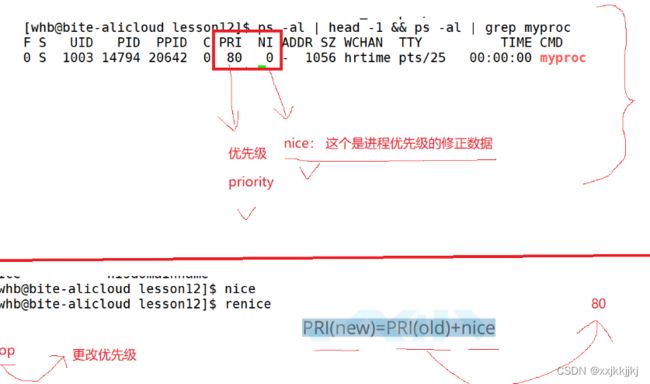
同样Linux限制了优先级的更改的范围

操作系统是如何根据优先级,开展的调度呢???
位图

为了方便理解先前运行队列没有优先级,现在有了优先级该如何确定各个进程的优先级呢?
Linux的做法非常优雅:
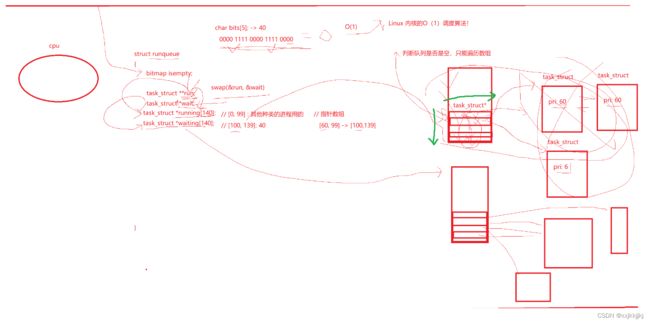
利用指针数组tast_struct* running[140]来指向task_struct,PRI是60的就放入100号下标位,同样的PRI链接到后面排队,不同的PRI就链入到对应[60,99]->数组中[100,139]这40个位置之中,数组中[0,99]是其他种类进程用的(我们大概率用不上)
当running队列调度时从左往右,从上往下,确定了优先级!
新来的或者被拔下来的进程都放到waiting数组中,当running队列运行完(空了),交换二级指针run和wait,run永远认为指向运行队列,wait永远指向空闲队列
我怎么知道我当前运行队列为空了呢?
遍历太慢了!
Linux内核的O(1)调度算法!
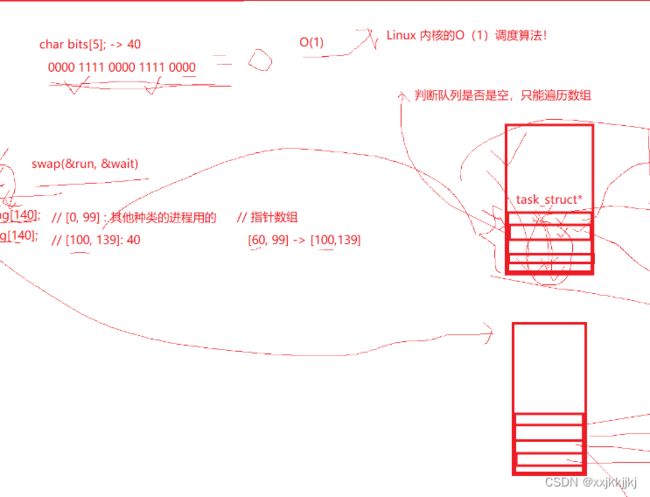
利用位图来判断,40个位置只需要5字节的bit位,所以char bits[5];
规定数组最右bit位是100号位
判断这40个bit位是不是等于0,就做到近乎O(1)