CCS2019:Log2vec论文阅读
CCS2019:《Log2vec: A Heterogeneous Graph Embedding Based Approach for Detecting Cyber Threats within Enterprise》
基于异构图嵌入的面向企业的网络空间威胁检测
2022.10.05 - 2022.10.10
论文提出了一种基于**异构图嵌入的网络威胁检测方法log2vec。log2vec ,属于开山之作。为了分析该图,论文设计了一种改进的图嵌入算法,其输出由一种实用的检测算法处理。论文实现了一个log2vec的原型,包含图构建、图嵌入、攻击检测算法三部分。评估表明,在日志级粒度方面,log2vec优于其他最先进的方法。它可以有效地检测各种场景**下的网络威胁。
文章信息:
**原文作者:**Fucheng Liu、Yu Wen∗、Dongxue Zhang等
**原文标题:**Log2vec: A Heterogeneous Graph Embedding Based Approach for Detecting Cyber Threats within Enterprise
**原文链接:**https://dl.acm.org/doi/pdf/10.1145/3319535.3363224
**发表会议:**CCS 2019
ABSTRACT
组织信息系统中现存的两种主要的威胁是:
-
传统的内部员工攻击威胁
**特点:**攻击来源于企业内部员工;获得授权从而访问企业的信息系统;严重影响系统的机密性、完整性和可用性
-
APT攻击
定义:APT攻击是指组织(特别是政府)使用先进的攻击手段对特定目标进行有组织、有目标、 隐蔽性强、破坏力大、持续性长的新型攻击和安全威胁
**特点:**攻击来源于系统外部、初始入侵来源于网络钓鱼或驱动下载、严重影响系统的机密性、完整性和可用性
然而,现存的方法关注的是威胁日志中的连续关系和用户连续的行为,却忽略了其他的关系,不可避免地导致这些方法无法适用于各类攻击场景。
在上述背景下,作者提出了 log2vec:一种基于异构图嵌入的网络空间威胁检测的模块化方法。
- 第一部分,采用启发式的方法将日志记录之间的多种关系表示为异质图
- 第二部分,采用一种**改进**的图嵌入将异质图中的日志记录表示为低维向量
- 第三部分,采用一种实际的攻击检测算法将恶意日志和良性日志聚成不同的簇,并能够检测恶意用户
实验表明,作者提出的log2vec表现得很好,优于常见的深度学习方法和HMM方法。此外,log2vec能够适用于各种各样的攻击场景。
1 INTRODUCTION
1.1 研究背景
内部员工攻击威胁和APT攻击是现代信息系统中存在的两种主要的威胁,会严重影响信息系统的机密性、完整性和可用性。如何检测这两种威胁在方法上是存在区别的:
- 内部员工攻击威胁,比如一个常见的场景是,一个恶意用户员工获取了另一个合法用户的身份,然后使用这个新的身份去偷窃保密信息(称为伪装攻击)。针对内部员工攻击威胁,现存的方法是将各种操作表示为连续序列,这可以包含日志记录之间的连续关系(第一种关系),然后使用序列处理方法(如深度学习),去学习过去的事件来预测未来的事件。从本质上讲,这些入门方法对用户的正常行为进行建模,并将其偏差标记为异常行为。但是这类方法忽略了其他关系。例如,某一用户天与天之间的逻辑关系(第二种关系)。此外,这类方法需要更多的标签数据来进行训练,然而,在真实场景中,恶意攻击行为是占少数的,所以并没有那么多带标签的数据。
- APT攻击中,攻击者通常利用内网(结合多台主机)来升级自己的特权,从而窃取机密情报。针对APT攻击,目前大部分方法关注于用户的登录操作和分析这些主机间的交互关系(第三种关系),从中抽取和分析关于用户登录的特征,来发现遭到破坏的主机,从而检测恶意用户。显然,序列化方法未考虑交互关系。因此,序列化方法不适用于检测APT攻击。同样,此类考虑主机交互关系的方法也不适用于检测内部员工攻击
1.2 提出挑战
我们面临三个挑战:
- 如何同时检测上述两种攻击场景,具体来说,要考虑到检测系统的所有三种关系(粗体)
- 如何在APT场景下进行细粒度检测,特别是深入挖掘和分析主机内日志条目之间的关系
- 训练模型在没有攻击样本的情况下如何进行检测
1.3 如何解决挑战(log2vec)
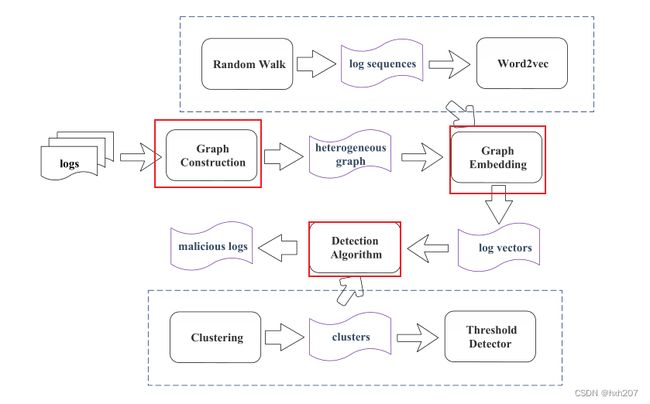
我们提出了一种能够同时检测上述两种威胁的新方法,log2vec。log2vec包含三个组成部分:
- graph construction:Log2vec构造一个异构图来集成日志条目之间的多个关系
- graph embedding (also graph representation learning):根据每个操作在图中的关系来学习它们的表示(向量)。向量化用户操作可以直接比较它们的相似性,从而发现异常
- detection algorithm:有效地将恶意操作分组到单个集群中并找出它们
**针对第一个挑战,**log2vec的第一个部分能够根据日志条目之间的三种关系来构建异构图,并且能够同时解决上述两种攻击场景。
针对第二个挑战,我们将一个日志条目分为五种属性,根据这些属性,我们能够深入考虑一个主机中日志间的关系,并采用多条规则来关系它们,这个设计使正常和异常日志条目在这样的一个图中拥有不同的拓扑结构,然后再送入检测算法中进行检测。
**针对第三个挑战,**Log2vec的图嵌入和检测算法在没有攻击样本的情况下,可以将日志条目表示并分组到不同的集群中,适用于数据不平衡的场景。
此外,图嵌入本身可以自动学习每个操作的表示(向量),而不是手动提取特定领域的特征,因此不依赖于专家的知识。我们的改进版本可以进一步从上述异构图中分别提取和表示操作之间的多个关系。
1.4 贡献(创新点)
我们的贡献如下:
- 我们提出了一种新的网络威胁检测方法log2vec,它能够通过捕获和表示用户操作之间的丰富关系来有效地检测用户的恶意行为。在各种攻击场景下,如前面提到的内部员工和APT的典型攻击,Log2vec执行日志入门级检测,而不需要训练攻击样本
- 我们提出了一种新的方法,可以将用户的日志条目转换为一个异构图,其中包含反映用户典型行为的信息并发现恶意事件,是一种通用的基于规则的图构造方法
- 我们提出了一种改进的图嵌入,它可以从上述异构图中区别提取和表示多个操作之间的关系
- 我们的评估表明,在多种攻击场景中,log2vec的性能明显优于最先进的技术,如TIRESIAS、DeepLog和HMM。同时,在内部威胁检测方面,log2vec的聚类算法在实验上优于传统的聚类算法k-means
- 我们进一步探讨了log2vec的参数对检测性能的影响。我们发现这种类型的检测需要针对每个用户设置不同的参数组合才能获得最佳性能,因为多个用户和攻击场景会产生不同的用户行为和攻击模式。在我们的实验之后,我们将log2vec的参数分为两类。一类对用户行为和攻击场景敏感,另一类则不敏感。此外,我们还就如何设置这些参数提供了建议。
2 OVERWIEW
2.1 Motivating Example
以一个例子阐述我们的问题
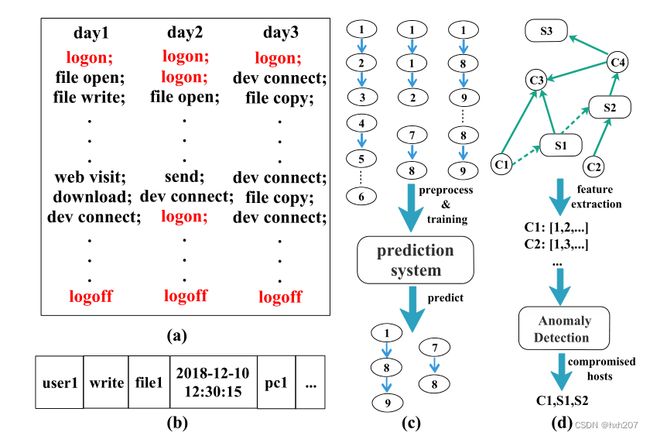
(a)表示我们需要进行检测的日志文件,它记录了用户的操作。(b)表示日志条目的属性,如主体(user id)、操作类型、客体、时间、主机。事实上,日志间的属性和关系揭露了一个用户的行为。©展示了序列化方法,它将(a)中的日志按时间顺序组成序列,然后采用深度学习方法(如LSTM)来学习过去的事件,从而预测未来的事件。显然,这种方法主要关注日志间的因果关系和连续关系。
然而,这类方法忽略了其他关系。例如,在day3,比前两天出现了更多的 dev connect和file copy操作,这可能存在数据破坏。这种差异能够通过比较用户的日常操作来发现,这种比较的前提是用户的行为在一段时间内是有规律并且相似的(天之间的逻辑关系)。上述方法并不能够比较用户的行为。同样地,它们也不能包含(d)中主机间的交互关系,也不能在APT攻击上表现得很好。此外,这类方法还需要大量的带标签数据来训练,然后,在我们的检测场景中,存在很少的攻击行为。
(d)显示了用户跨主机的行为,从(a)(红色字体)中的登录操作开始,我们可以通过分析这些主机之间的交互关系来发现异常登录。例如,管理员可能定期登录一组主机进行系统维护;而APT攻击者只能访问其能够访问的主机。这种差异可能通过登录操作的特征的不同来捕获。例如,良性(1或3个,实线)所涉及的主机数量通常与APT(2个,虚线)不同。分析这些特征后,就可以识别出受到攻击的主机。然而,这些主机包含大量的良性操作和手动提取的特定于领域的特征,这显然不能用©中的方法来解决。
2.2 Architecture
Log2vec由三个关键部分组成:图的构建、图的嵌入和检测算法
Graph construction
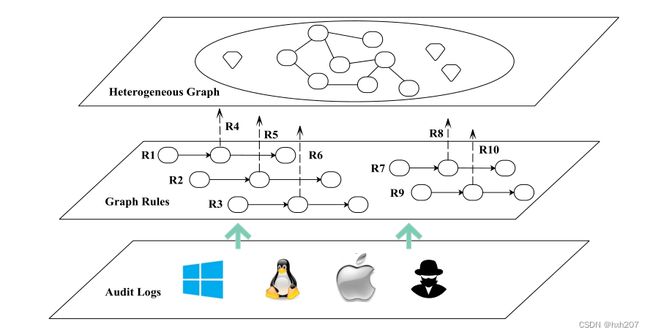
Log2vec的第一个组件是基于规则的启发式方法,用于将反映用户典型行为和揭露恶意操作的日志条目之间的关系映射到图中。log2vec主要考虑三种关系:(1)一天内的因果顺序关系;(2)天之间的逻辑关系;(3)对象之间的逻辑关系
为了深入挖掘和分析一天/主机内的日志条目之间的关系,我们将日志条目分为五个主要属性(主体、对象、操作类型、时间和主机),称为元属性(参见3.1节)。在设计关于这三种关系的规则时,我们考虑这些元属性的不同组合,以关联更少的日志条目,并将更细的日志关系映射到图中。例如,管理员登录到自己的计算机,然后远程登录到服务器,打开一个文件查看第2天的系统状态(图2a)。这个序列反映了日志条目之间的顺序关系。
ruleA:我们将同一用户的日志条目按时间顺序连接,以将这种关系映射到一个图中。在这条规则中,我们考虑了两个属性,主体和时间。
ruleB:我们将同一用户和相同操作类型的日志条目按时间顺序连接,以连接一天内的设备连接操作。在这条规则中,我们考虑了三个属性,主体、时间和操作类型。
通过对日志属性的不同组合,我们设计了涉及更少日志条目的各种行为序列,并将一天内的日志条目和一台主机之间的多个更精细的关系映射到图中。经过图嵌入和检测算法,log2vec生成小簇来揭示异常操作。在实际操作中,可疑集群涉及的日志条目数量非常少,甚至等于1。因此,log2vec更精细地挖掘了用户在上述两种攻击场景下的行为。
根据log2vec中的每条规则,我们将日志项转换为序列或子图,所有这些都构成了一个异构图。每条规则,对应于一个边类型,都是从一个特定的关系派生出来的,如上面的例子所示。由于不同的关系在不同的场景中扮演不同的角色,我们使用多个边类型而不是权重来区分它们。
Graph embedding (also Graph representation learning)
图嵌入,又称图表示学习,是一种机器学习方法,能够将异构图中的节点(日志项)转换为低维向量。具体来说,图嵌入涉及到图1中的随机游走和word2vec。前者提取每个节点的上下文并将其提供给后者,后者计算其向量。
随机游走是一种常用的图遍历算法。假设行走者驻留在图中的一个节点上,他根据每条边的权重和类型来决定下一个要访问的节点。路径,即由他生成的节点序列,被视为这些节点的上下文(见4.1节)。例如,当行走者位于第1天或第2天设备连接序列的节点(图2a)上时,由于路径权重较低(因为1和2主机数量接近,1和3主机数量相差较大),行走者很少选择第3天序列的节点(设备连接)。同样,当驻留在第3天序列的节点上时,他很少会到达第1天或第2天的序列。因此,log2vec提取包含第1天和第2天的节点的路径,或者单独提取第3天的路径。
word2vec模型用于计算每个节点及其路径(上下文)的向量。具体来说,将这些路径作为自然语言中的句子,由该模型进行处理,学习每个单词(节点)的向量(见4.2节)。这种方法保持了节点及其上下文之间的接近性],这意味着一个节点(日志条目)和它的邻居(与它有密切关系的日志条目)共享相似的嵌入(向量)。比如,在上述例子中,day1和day2相近,因此都在同一条路径上,共享相似的向量,而第3天的则拥有不同的向量。
此外,log2vec改进了现有的图嵌入。新版本能够根据攻击场景确定日志条目之间每个关系的重要性,并对它们进行分别处理。在上面的例子中,log2vec确定规则B比规则A更重要,并在随机游走中提取出更多对应规则B定义的边类型的路径。在word2vec之后,由于B规则提取的路径较多,第3天的设备连接向量趋于相似,而a规则提取的路径较少,第3天的设备连接向量与登录操作的向量都不相似。因此,log2vec偏向于提取和表示日志之间的关系。这个示例还展示了log2vec如何将一天内的登录(良性)和设备连接(恶意)分组到不同的集群中,而不是将它们视为日常序列。
Detection Algorithm
Log2vec采用一种聚类算法来分析上述向量,并将良性操作(日志条目)和恶意操作分组到不同的集群中(第5.1节)。在上面的例子中,聚类算法将第1天和第2天的设备操作分组为一个簇,第3天的设备操作分组为另一个簇。聚类完成后,我们设置一个阈值来识别恶意集群。也就是说,大小小于阈值的集群将被视为恶意集群
综上所述,良性操作(用户的典型行为)与恶意操作之间有着密切的关系。然而,它们之间很少甚至没有相关性。根据观察结果,log2vec对这些关系进行不同的提取和表示,将它们分离到不同的集群中。此外,恶意操作的数量较少,因此更小的集群往往是恶意的。(有参考文献证明)
2.3 Adversarial Model
Adversarial Model包含以下三种企业和政府常见的攻击场景:(为什么称为对抗场景)
第一,是内部员工滥用职权执行恶意操作,例如访问数据库或应用程序服务器,然后破坏系统或窃取知识产权以获取个人利益
第二,恶意内部人员通过偷窃或密钥记录器来获取其他合法用户的证书,并利用这个新的身份来获取机密信息
以上两种是典型的内部员工攻击
第三,APT参与者对系统中的一台主机进行访问,并从该主机持续访问多个主机,以升级自己的权限,窃取机密文件
3 GRAPH CONSTRUCTION
3.1 Definition
图2b中的日志记录被一个含有5个属性的元组来表示,即==
3.2 Rules of Graph Construction
关系包括三类:
- 一天内的因果关系和顺序关系
- 天之间的逻辑关系
- 对象之间的逻辑关系
对于每个类别,我们基于元属性的不同组合提出了一些规则
如图3所示,我们首先提出R1∼R3,将一天内的日志条目连接成序列,对应于关系(1)。这三条规则从不同的时间、主机和操作类型等方面对用户行为进行了建模。通过这种设计,用户在不熟悉的主机上执行的罕见操作,或属于很少执行的操作类型的操作,被孤立在图中。
然后,我们提出R4 ~R6,根据关系(2)分别桥接这些每天的日志序列。其中,恶意的日志序列将会与良性的序列分离。这六个规则将图2c中的关系映射到一个图中。它们主要将用户在多台主机上不同类型的操作关联起来。
最后,提出了4条规则(R7 ~ R10),对应于关系(3),考虑用户如何登录/访问主机并向外部发送机密数据。具体来说,就是构建用户的登录模式和网页浏览操作模式。关于登录操作的规则(R7和R8)考虑如何在内网中交互访问这些主机,例如图2d中的一个实例。关于网络操作的规则(R9和R10),关注的是用户通过互联网使用浏览器的情况。内网和Internet是主要的入侵源,如登录主机或驱动下载。此外,Internet也是机密文件泄露的主要途径。
Log2vec旨在分析每个用户的典型行为,因此它为==每个用户(子)==构建了一个异构图。
以下的规则将作为图的边类型:
3.2.1 Constructing graph within a day
在企业中,用户拥有不同的角色,进行不同的操作。因此,设计了多个规则来检测它们的行为。
首先,log2vec考虑元属性 sub和T,构建用户的日常行为序列,这是一种检测用户日常行为的常用方法。同时,这种设计也被用来减少误报。即Rule1:
**Rule1(edge1):**将一天的日志条目按时间顺序连接,权重最大为1
其次,log2vec在每台主机上构造用户的日常行为。这种设计是基于观察到其他用户(不同于管理员)通常对指定的几个主机或只对自己的主机执行操作。因此,用户以前很少或从未登录的不熟悉的主机表示异常登录。即Rule2:
**Rule2(edge2):**同一主机、同一天的日志条目按时间顺序连接,权重最大为1
有些恶意日志项与多种操作类型有关,例如,用户在他人主机上搜索机密文件(文件操作),并将机密文件发送到自己的邮箱(邮件操作)。这些连续的操作可以通过Rule2进行关联。然而,只存在针对一种类型的攻击动作。例如,用户访问一个网站并上传机密文件。将它们映射到没有其他操作类型的图中,有利于后续的精确检测。同时,它们发生在宿主主机上。因此,我们构建了一个用户在每个主机上的每种操作类型的日常行为:。即Rule3:
**Rule3(edge3):**相同操作类型、相同主机、同一天的日志按时间顺序连接,权重最大为1
通过这些规则,log2vec构建了各种日常行为序列。它们更加细粒度(有些只涉及少量日志条目),比传统的方法包含更强的逻辑关系。
3.2 Constructing graph among days
员工的日常行为在一段时间内通常是有规律的。现有的方法主要关注日常操作的数量。具体来说,一个员工通常每天都有平均工作量,远远超过这个平均值的异常很可能涉及恶意操作。
每日日志序列之间的逻辑关系反映了用户行为的这种规律性。具体而言,良性日序列的日志条目数接近平均值,因此彼此接近,而恶意日序列的日志条目数与平均值相差甚远。也就是说(Put another way),这些良性的日志行为具有相似的行为模式,与恶意的不同。
为了比较来自rule1∼rule3的用户日常行为序列,我们提出了rule4∼rule6,它由与rule1∼rule3分别对应的元属性组成。通过这些规则,log2vec在图中分别从3.2.1节提到的各种场景中分离出异常行为序列。
**Rule4(edge4):**每日的日志序列是连接的,它们的权重与它们所包含的日志条目的数量的相似度呈正相关
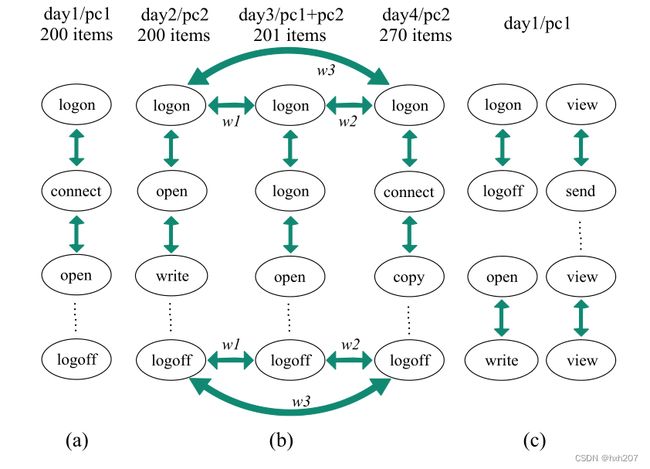
这个规则涉及sub和T。图4b显示了一个实例。连接模式是将每个序列的第一个/最后一个日志条目连接到其他序列的日志条目。如前所述,提出这三条规则(rule4 ~ rule6)的目的是紧密连接每天的日志序列,反映用户的常规行为(接近日志条目的平均值)和分离恶意行为(远远超过平均值)。因此,这个连接满足了我们的需求。异常日志序列的划分取决于边的权重,如图4b所示。两个序列中涉及的日志条目数量相似,那它们之间的权重就较高。(论文中附录A详细介绍了边权的计算方法)
进一步地,我们提出了涉及 H 的规则:
**Rule5(edge5):**同一主机的每日日志序列是相互连接的,权重与它们所包含的日志条目的数量的相似度呈正相关
最后,我们提出了包含 sub、H、A和T的规则:
**Rule6(edge6):**相同操作类型和相同主机的每日日志序列相互连接,权重与它们所包含的日志条目数量的相似度呈正相关
3.2.3 Constructing graph based on objects
Object是一个相对复杂的元属性,因为它表示不同类型的实体,如域名、文件、电子邮件。特别是,如前所述,登录操作的对象是目标主机。基于内网的攻击和来自Internet的渗透,我们设计了保持图中对象之间关系的规则。
在内网中,APT参与者对计算机进行了入侵。如果他不能获得他想要的信息或权限。他会使用该帐户寻找其他用户的凭证。例如,攻击者利用窃取的帐户从计算机登录远程服务器(obj),并注入后门来监视信息流和窃取凭证。但是,身份验证协议暴露了威胁。因此,我们通过区分每个用户的身份验证协议和主机,将正常登录和异常登录划分到不同的子图中。
**Rule7(edge7):**同一源主机使用相同的认证协议访问同一目的主机的日志按时间顺序连接,权重最大为1
**Rule8a(edge8):**不同认证协议的同一目的主机和源主机的日志序列相互连接,且权重与它们所包含的日志条目的相似度呈正相关
**Rule8b(edge8):**不同目的主机或具有相同认证协议的源主机的日志序列相互连接,权重与它们所包含的日志条目的相似度呈正相关
Internet是员工向外界泄露情报(如上传数据)的主要渠道。同时,感染内网主机的恶意软件大多来自Internet。因此,网站(或域名)是至关重要的对象。我们为每个用户提出规则:
**Rule9(edge9):**同一主机访问同一域名的日志按时间顺序连接,权重最大为1
攻击者的目标是引诱用户下载恶意代码并执行它。因此,提供软件下载的网站相对来说更危险,而不是提供新闻访问的网站。访问模式(访问,下载,上传)是一个重要的元素,我们提出了一个规则:
**Rule10(edge10):**同一主机、不同域名的日志序列相互连接,且权重与访问方式的相似性和所包含日志条目的数量呈正相关

图5b描述了一个实例。在log2vec中,访问方式优于数量。因此,权重w1应该高于w2和w3,因为域名e3没有按顺序上传和下载(意味着网站只是提供新闻),这是访问模式的差异。(论文附录B详细介绍了如何计算边权值)
4 GRAPH EMBEDDING
在4.1节中,我们提出了一种改进的随机游走,能够从上述异构图中提取每个节点的上下文(也包括日志条目)。4.2节引入了一个特定的word2vec模型来将每个节点表示成低维向量。
4.1 Random Walk with Different Sets of Edge Type
随机游走根据边类型和权重生成步行者所通过的路径。转换概率如下图所示。Log2vec的改进是控制邻居节点的数量(neigh)和提取不同比例的边类型集合(ps)的上下文,这是为了解决**数据集不平衡和各种攻击场景**的问题。
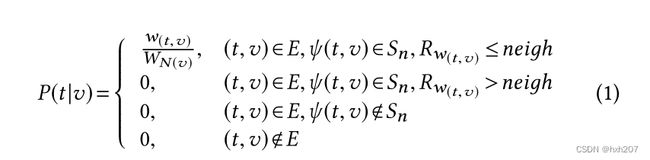
4.1.1 Transition probability
例子解释:

4.1.2 The number of neighbor nodes
每一个组都涉及两种边类型,分别关注组内(同一天/同一个对象)和组间(如天与天之间)。组内的边类型(如edge1和edge9)构造日志条目序列,并且该序列中的每个节点都有两个相邻节点。Log2vec允许步行者不重新访问他访问过的最后一个节点,因此他实际上在序列中只有一个节点要访问。组间的边类型(如edge4和edge10)对应多个日志序列。因此,序列的第一个或最后一个节点有许多相邻节点。本质上,Log2vec**调优**这些节点的邻居节点(neighs)的数量。
log2vec为neighs调优有两个原因:
第一个是内部威胁通常只包含少数恶意日志条目。如果随机游走考虑了所有的相邻节点,这些恶意日志条目就不能在向量空间中被孤立。
第二,一个企业中可能有多个员工执行攻击,这一事实会导致不同数量的恶意日志序列。因此,根据不同的用户,最佳的neighs是不同的。值得注意的是,neighs是一个超参数,是实验设定的。然而,原则上我们倾向于设置一个较低的值,例如1,以确保最相似的序列连接到给定的序列。
4.1.3 The proportion of sets of edge type
Log2vec可以根据不同的场景确定每一组边类型的重要性,并分别提取上下文信息。通常,不同的攻击场景会留下不同的检测痕迹。也就是说,在每种内部攻击中,日志条目中只有一到两个元属性变得异常。
更具体地说,log2vec最初给出的比例为1:1:1:1:1,对应于{edge1, edge4}, {edge2, edge5}, {edge3, edge6}, {edge7, edge8}和{edge9, edge10}。接下来,log2vec选择{edge3, edge6}, {edge7, edge8}和{edge9, edge10}进行调整,因为它们涵盖了与异常相关的元属性。具体来说,{edge1, edge4}, {edge2, edge5}和{edge3, edge6}属于同一类型,主要关注用户的日常行为。与其他方法相比,{edge3, edge6}涉及到更多的元属性、操作类型(A)和宿主(H),可以产生更精细的行为序列。{edge7, edge8}和{edge9, edge10}分别集中于内网的目标主机(obj)和Internet上的网站(obj)。最后,log2vec比较当前期间(例如两个月)和上一个期间的用户行为。同时,它还将他的行为与处理类似任务的同事进行了比较。例如,如果一个员工执行了大量的登录,与他以前的行为和他的同事不同,log2vec应该增加比例(ps)中的{edge7, edge8}的值。在实践中,这个值是其他集合总和的两倍,因此ps是1:1:1:8:1。(详情见论文附录C)
另外,我们设置随机游走数 r,比例的每一个值乘以r,以r=10为例。根据上述比例(1:1:1:8:1),当我们分别设置Sn为{edge7、edge8}和其他集合时,log2vec进行80次和10次随机游走。(本节伪代码见附录D)
4.2 Word2vec Model
word2vec是自然语言处理领域的经典模型,原本是将一段文本中的词映射为向量,实现文本向量化。Log2vec借用word2vec中skip-gram模型的思想,通过异构图生成的上下文(路径)将日志项映射到低维向量。它是一个目标函数,使其相邻节点的概率最大化。更准确地说,它的目标是使下列对数函数最大化:
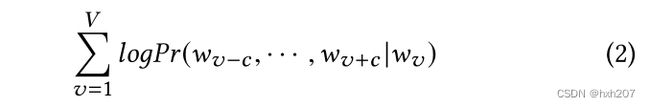

5 DETECTION ALGORITHM
第5.1节详细介绍了一种聚类算法(log2vec中用到的);第5.2节介绍阈值检测器;第5.3节演示如何在检测算法中选择参数
5.1 Clustering Algorithm
本小节提出将良性和恶意日志条目分组到不同集群的方法。然而,传统的更新聚类中心(如k-means)的思想并不适合内部威胁检测,因为它严重依赖于聚类中心和k的初始化,导致性能不理想。(解释为什么传统kmeans方法不适用)
我们采用另一种方法,擅长于进行日志条目的两两相似度比较。形式上,我们假设集群(C1,C2,…,Cn)已经获得,并且它们必须满足以下条件:

其中V是一个包含所有日志条目的集合,δ1是一个阈值。注意,C1是任意选择的使用sim来测量使用余弦距离的日志条目之间的相似性(当两个日志条目的sim为0→1时,它们变得相似)。其伪代码在论文附录E中给出。
5.2 Threshold Detector
在聚类之后,log2vec根据集群包含的日志条目的数量对集群进行排序,较小的集群往往是可疑的。

表1和表2展示了聚类算法输出的两个示例。在表1中,最小的聚类大于阈值δ2(例如80),因此被识别为合法操作。表2显示了几个小型集群(< 80),表明存在内部威胁。因此,这些集群中的日志条目被检测为恶意的。
5.3 Parameters Selection
存在δ1和δ2两个阈值可供选择。我们提出了一种更合适的选择方法,侧重于较小的集群:
(1)δ2是由log2vec生成的最大可疑聚类所涉及的日志数。由于攻击场景的不同,它是多样化的。我们设δ2 = pro * total,其中total为待检测日志的数量,pro为恶意日志条目占总数的比例。我们考虑一种情况,即所有恶意日志条目都可能被分组到一个集群中。因此,δ2应该等于它的数量,pro * total,然后log2vec将这个集群检测为恶意的。可以根据现有的工作和具体的场景设置pro。在我们的实验中,我们在所有数据集中设置pro为1%,因此δ2为1% * total
(2)**在另一种常见情况下,恶意日志条目分布在各个集群中。**通常,攻击者会执行几种不同的操作进行攻击,例如,登录主机(登录)和窃取文件(文件拷贝)。根据用户的操作类型(例如登录和文件操作),我们设置恶意集群的数量(nmal)为nbp * nt,其中nt为操作类型的数量。nbp反映每种操作类型上可疑行为模式的数量。在log2vec中,不同的行为模式被分组到不同的集群中。nbp * nt因此构成了恶意集群的数量,nmal。在实际操作中,我们根据每个操作类型的属性信息选择nbp。
(3)当δ1为0→1时,簇的数量往往更大,因为同一簇中的两个日志条目必须具有更高的相似性。我们利用最大的可疑集群中的日志数量δ2和恶意集群的数量nmal来设置δ1。当δ1为0→1时,簇的数量往往更大,因为同一簇中的两个日志条目必须具有更高的相似性。我们利用最大的可疑集群中的日志数量δ2和恶意集群的数量nmal来设置δ1。当δ1为0→1时,一个簇分裂成许多更小的簇。我们选择最大的δ1来同时覆盖以下两种情况:允许小于δ2的集群中日志条目的数量,并且这些集群的数量小于或等于nmal。
对以上方法举例理解:
以表2为例,当δ1是一个值(例如0.64)时,我们将日志条目的数量小于或等于δ2(例如80)的集群视为恶意的。同时,这些可疑聚类的数量小于或等于nmal(例如6)。然后δ1加上一个区间(例如0.01),产生一个包含9个日志条目的新聚类。因此,出现可疑集群的数量大于 nmal(6),超出了我们的设置。换句话说,当δ1设置为0.65时,可疑聚类包含良性聚类,效果不佳。因此,我们就选择0.64作为δ1。
6 EXPERIMENT
本节评估不同攻击场景下的log2vec。第6.1节介绍实验设置。第6.2节比较baseline模型。Log2vec的检测效果见6.3节。参数敏感性在6.4节中进行了评估。第6.5节和第6.6节分别展示了log2vec的边类型集和聚类算法在k-means上的有效性。
6.1 Experiment Setup
复现论文主要参考的部分。
实验环境这里就不作介绍,具体看论文,这里主要介绍数据集、参数设置
Dataset
我们使用一个合成数据集,包含两部分:CERT内部威胁测试数据集,和一个真实数据集,洛斯阿拉莫斯国家实验室(LANL)的综合网络安全事件数据集。
CERT数据集是一个综合数据集,拥有较为完整的用户行为记录和攻击场景。我们使用五个文件分别记录登录操作、可移动存储设备使用情况、文件操作、网络操作和电子邮件流量,另一个文件记录所有用户的角色及其从属关系。该数据集包括4000名用户在516天内的135,117,169次操作。有5种攻击场景,其中6个用户进行470次恶意操作,这显然是内部威胁检测中常见的**极其不平衡**的问题。五个场景包括各种内部威胁,用于检验log2vec能否根据不同场景确定每一组边类型的重要性,并对其进行分别提取和表示。
LANL数据集包括LANL公司内部计算机网络中12425名用户和17684台计算机在58天内收集的10亿多日志条目。它涉及749个恶意登录和98个受损账户,是一个典型的APT攻击数据集。我们分别使用两个文件来进行身份验证和过程检测恶意操作。该数据集用来检查log2vec是否能够检测到2.3节中提到的针对APT的攻击场景。
这两个数据集都是为了**证明log2vec对用户恶意操作的强大检测能力和覆盖各种攻击场景的能力**。
Parameter settings
参数说明:
r:每个节点随机游走的步数
l:随机游走序列的长度
d:嵌入后的向量维度
c:word2vec中的窗口大小
ps:边类型集合比例
neigh:邻居数
在CERT数据集中,我们在两个月内检测了6个恶意用户的行为,并将最后一个作为随机游走的最后一个周期。具体时间如论文附录F表5所示。在选定的两个月内,这些用户进行了37257次操作,其中恶意操作428次。此外,随机选择12个良性用户,执行71334个操作,检查FPRs。该企业的组织单位按规模由大到小依次为business_unit、functional_unit、department、team和supervisor,用前四个单位和角色(如Salesman、ITAdmin)定义随机游走中选择的同事。由于在这个数据集中没有关于身份验证登录的日志条目,我们主要使用第3节中的rule1 ~ rule6、rule9和rule10来构造图。在随机游走中,考虑{edge3, edge6}和{edge9, edge10}来确定边类型的集合比例。根据论文附录C的策略,由于显式平均,连接和网络运行数量的变化分别对应于这两个集合。6个恶意用户的具体比例由log2vec计算,见论文附录H表6的ps列。
LANL数据集包含98个恶意用户,我们随机选择其中的50个来检查log2vec的有效性。此检测到的数据集涉及701643个日志条目,其中包含495个恶意操作,占总数的66.1%。此外,我们随机选择90例良性用户,他们进行了983,421次操作,以检查FPRs。由于该数据集主要用于检测APT,且没有关于网站的信息,log2vec利用第3节中的rule1∼rule8构造图,并在随机游走中将所有用户的边类型集的比例固定为1:1:1:6。
其他参数设置见论文(主要是复现论文时需要参考)
Baseline
对CERT数据集,使用了11种Baseline方法。TIRESIAS 和 DeepLog是用于异常检测的高级日志入门方法。隐藏马尔可夫模型(markov-s和markov-c)和深度学习模型(DNN和LSTM)是该数据集中最先进的模型。STREAMSPOT是一种检测恶意信息流的高级方法。我们使用node2vec和metapath2vec来展示log2vec在随机游走方面的改进对处理异构图的效果。用log2vec- euclidean和log2vec-cos证明了log2vec的聚类在解决这一问题上优于k-means。此外,我们还介绍了一个新的log2vec版本,log2vec++,它的参数可以根据不同的用户和攻击灵活设置。
对LANL数据集,我们使用集成检测方法和TIRESIAS来与log2vec进行比较,以表现log2vec在APT攻击检测上的优越性。具体参数详见论文附录G。
6.2 Comparison with baselines

我们使用AUC来比较不同方法的性能。在表3中,log2vec优于baseline模型。TIRESIAS 和 DeepLog是最先进的日志入门级异常检测方法。在CERT数据集中,它们都只能使用一天内的因果关系和顺序关系,而没有使用另外两种关系,即天之间的逻辑关系和对象之间的逻辑关系。因此,它们不能达到令人满意的性能。
**深度学习方法(DNN和LSTM)**不同于TIRESIAS 和 DeepLog。具体来说,TIRESIAS 采用按时间排序的日志条目序列作为输入,而baseline中的LSTM则使用每天从日志条目中提取的统计特征序列。虽然DNN和LSTM在日志条目级别上不如log2vec,但由于考虑的关系更多,例如天之间的逻辑关系,所以性能优于TIRESIAS 和 DeepLog。**隐马尔可夫模型(markov-s和markov-c)**被设计用来识别恶意事件发生的可疑天数。STREAMSPOT旨在检测恶意信息流图。根据比较结果,这些方法的性能也比log2vec差。
Metapath2vec和node2vec是先进的图嵌入模型。Node2vec设计用于处理同构图,因此性能较差。Metapath2vec可以处理异构图。实际上,metapath2vec和log2vec的图嵌入的主要区别是,log2vec保留了调整边类型集合比例的能力。若比例为默认值(1:1:1:1:1),则这两种方法相同。显然,内部威胁要求不同的比例,因此log2vec实现了优越的性能。
在LANL数据集中,有足够的数据(360万日志条目)进行TIRESIAS 的训练。之所以TIRESIAS表现良好(AUC=0.85),是因为我们在数据集中设计一个指定的事件。具体来说,TIRESIAS 将出现次数少于10次的事件视为指定的事件。因此,由于有足够的样本,TIRESIAS 成功地将该事件归类为异常。但是,指定的事件涉及许多良性事件。如果TIRESIAS 学会了这些平均发生次数为2.1的各种罕见事件的模式,而不是指定的,它就不起作用(AUC为0.05)。这是因为我们场景中的数据集极度不平衡,缺乏足够的恶意样本进行训练。此外,TIRESIAS忽略了其他关系,特别是对象之间的逻辑关系。集成方法将APT的特征模式识别为统计特征,并对其进行分析,以检测受攻击的主机,而**log2vec则执行更细粒度的检测,识别恶意日志条目**。
Log2vec’s potential
log2vec++的性能明显优于Log2vec。两者的主要区别在于,log2vec++的neigh++和δ1++两个参数的设置比较灵活,如论文附录H表6所示,而log2vec的neigh为1,δ1的设置参照章节5.3。造成这种差异的原因有两个:首先,内部威胁和APT数据集通常极度不平衡。我们需要为每个用户精确地设置参数组合,以找出极少数恶意操作。其次,多个用户和攻击会产生不同的用户行为和攻击模式。Log2vec应该精确地从日志条目中提取和表示指示这些模式和行为的信息。因此,它要求对每个用户使用不同的参数组合。
6.3 Detection of Malicious Users
表4显示了log2vec的检测结果。尽管log2vec不能检测所有恶意操作,但与baseline模型相比,它在检测内部攻击(CERT)和APT (LANL)方面的性能最好(参见第6.2节)。Log2vec显示了它对多种不同攻击的通用性:1)通过可移动驱动器或数据上传窃取数据(ACM2278, CMP2946, MBG3183), 2)登录其他用户获取机密文件(CDE1846)。这两种类型的攻击属于第2.3节提到的第一个场景。3)伪装攻击。攻击者通过密钥记录器窃取其他合法用户的证书并发送报警邮件,造成恐慌(HIS1706, PLJ1771)。这是第二种情况。4)APT攻击者向一台主机访问,并从该主机持续访问多个主机(LANL数据集),属于第三种情况。
6.4 Parameter Sensitivity
我们研究了图嵌入中的6个参数如何影响log2vec在CERT数据集中检测用户CMP2946的性能。具体来说,我们使用AUC作为这六个参数的函数。当测试一个参数时,其他五个参数固定为默认值。同时,将检测算法中的δ1设为0.65,log2vec在该值下性能最佳,参考5.3章节。调整δ2计算AUC。
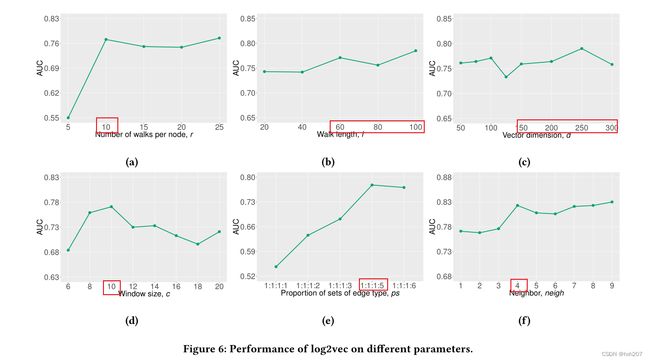
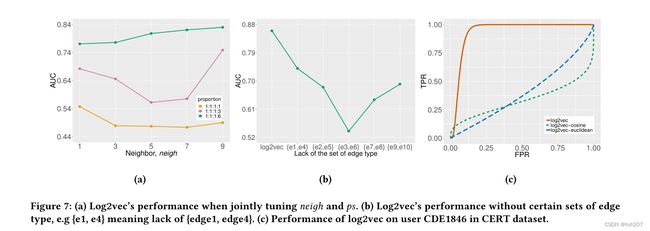
图6a描述了一条先上升后稳定的直线,这意味着每个节点®走10步足以提取每个节点的上下文(日志条目)。同样,当l和d分别达到60和100左右时,在图6b和图6c中,log2vec的性能没有显著提高。在图6d中,我们观察到AUC在c = 10时达到峰值。我们将这四个参数(r、l、d、c)归入同一类别。它们对检测到的用户和攻击都不敏感。
在图6e中,当ps为1:1:1:5时,log2vec的性能最好。在图6f中,值4、7、8和9产生了很好的性能。在图7a中,我们联合调优ps和neigh。当ps为1:1:1:6时,无论neigh如何调整,Log2vec的性能都是最好的。因此,ps是比neigh更关键的参数。与上述四个参数相比,ps和neigh对不同的用户和攻击比较敏感。在论文附录H的表6中,log2vec和log2vec++灵活地调整ps,这也是为什么log2vec优于其他方法的原因之一。此外,log2vec++还能调节neigh和δ1,从而优于log2vec。此外,δ2根据其定义可知,对攻击场景也很敏感。因此,我们将这四个参数(ps、neigh、δ1、δ2)归为一类,对检测到的用户和攻击比较敏感。
6.5 Effectiveness of Log2vec’s Sets of Edge Type
如图3所示,10个规则中有5个用于构建日志序列,例如rule1,其他5个分别用于桥接它们,例如rule4。这两类规则是相辅相成的。如果我们去掉前一种规则中的一条,例如rule1,那么后者中的相应规则,例如rule4,由于缺乏日日志序列,就无法应用于图的构建。如果我们只使用前者,例如rule3而不使用rule6,那么log2vec只构造用户的每日日志序列,而不能像2.2节中的实例那样检测异常日志序列。因此,我们计算log2vec的边类型集,由这些规则成对定义。
我们对CERT数据集中的6个攻击者和LANL数据集中随机选择的6个攻击者进行评估。具体来说,我们去掉一组边类型,并使用剩余的边类型进行检测。图7b演示了**在没有任何边类型集合的情况下性能都会下降**,特别是{edge3, edge6}和{edge7, edge8},这是4.1.3节中提到的对于各种场景最重要的两个。Log2vec在没有{edge9, edge10}的情况下,对于通过Internet发起攻击的用户,对于Rule9和Rule10的性能明显下降。没有{edge1, edge4}或{edge2, edge5}的Log2vec的性能下降主要是在边类型集合的原始比例为1:1:1:1时,这意味着这两个集合在检测这些特定的攻击者方面发挥了几乎相同的作用。
6.6 Effectiveness of Log2vec’s Clustering

我们以CERT数据集中的CDE1846用户为例,证明了**log2vec的聚类算法比k-means更适合本文的攻击场景。图7c的主要区别是分别使用了k-means余弦距离,欧几里得距离和5.1节的聚类算法**。图中k-means的auc均在0.5以下,这是因为这些方法使用集群中心对日志条目进行分组,导致严重依赖它们的初始化。然而,内部威胁数据集中恶意操作的数量非常少。因此,这些操作在初始化过程中几乎不会被选择为中心,而是倾向于被分组到它们相邻的集群中。另一个原因是k很难设定。如果k过小,恶意日志条目更容易与良性日志条目一起被收集。
7 DISCUSSION
7.1 Evasion
Log2vec根据恶意集群的大小来识别它们。如果攻击者计划逃避检测,他可能会进行足够多的恶意操作,将相应的集群扩展到良性集群中。然而,这一过程更有可能让人们注意到他的行为。例如,现有的安全信息和事件管理(SIEM)将检测这些操作。
7.2 Limitations
Graph rules
Log2vec旨在检测对抗模型中介绍的关于内部威胁和APT的三种重要场景。log2vec中使用的三个关系是从现有的方法派生而来的。这些关系包括用户行为模式、内网攻击和来自Internet的渗透。当然,我们可以考虑新的关系和设计新的规则。例如,APT的新特性还在开发中,我们可以把它们放到图中。类似地,还存在其他攻击场景。因此,我们需要将新的关系合并到图中以覆盖它们。例如,可以将电子邮件网络转换为用于检测鱼叉钓鱼的图规则。这些计划留给以后的工作去做。(展望)
False positive rate
log2vec产生的FPRs在两个数据集中分别为0.08和0.1,在生产环境中算是比较高的。为了解决这个问题,我们可以使用现有的combating
threat alert fatigue的方法来帮助分析人员减少误报。这个方向也是我们未来的工作方向。(展望)
Log2vec’s parameters
正如在log2vec’s potential(见第6.2节)中提到的,尽管log2vec优于baseline模型,但这个版本的图嵌入和检测算法仍然可以改进,就像log2vec++一样,为每个用户灵活地调优参数。这项工作可以从两个方向进行:改进现有版本的图嵌入和检测算法,如减少参数。(展望)
Graph neural network
图神经网络(GNN)是一种主流的方法,在引文网络、知识图和社会事件预测等各个领域都优于图嵌入方法。与图嵌入的word2vec模型(skip-gram)相比,GNN学习图的拓扑结构更加复杂。然而,它的大多数变体需要带标签数据进行训练。内部威胁检测和APT检测属于数据不平衡问题,异常样本数量较少。因此,GNN在这一领域的强大功能需要付出巨大的努力。
8 RELATED WORK
Insider Threat Detection and APT Detection
在各种场景下,内部威胁检测和APT检测问题得到了广泛的研究。
一种典型的方法是提取用户行为特征,通过机器学习模型对其进行处理,以发现恶意事件。
另一种典型的方法是将用户的行为转化为序列或图并对其进行分析。这种方法构建用户行为的正常模式,然后将其与新行为进行比较或预测新行为,以识别异常,而log2vec将日志条目之间的关系转换为图,并使用图嵌入来根据日志条目之间的各种关系挖掘异常。
物源跟踪系统被用来监测和分析系统的活动。log2vec和它们之间有两个区别。首先,它们大多针对攻击取证,而不是网络威胁检测。其次,这些系统利用因果图在系统调用级别跟踪进程的操作和交互。Log2vec分析记录信息系统中用户行为的日志,它主要捕获和表示反映用户典型行为的日志之间的多个关系。
HOLMES是一种检测APT攻击的先进方法。但是,它根据信息流构造高级场景图,只反映日志条目之间的因果和顺序关系。因此,这些评分图根据其组成部分的严重程度所产生的检测结果在我们的场景中不能达到令人满意的性能。
Graph Embedding
图分析已被广泛研究并应用于多个领域。在这些方法中,图嵌入受到了极大的关注。最近,深度学习被用于图嵌入可能是由于其出色的监督学习能力。
9 CONCLUSIONS
我们提出了一种基于异构图嵌入的网络威胁检测方法log2vec。据我们所知,log2vec涉及到该领域第一个复杂而有效的异构图构建方法。为了分析该图,设计了一种改进的图嵌入算法,其输出由一种实用的检测算法处理。我们实现了一个log2vec的原型。评估表明,在日志级粒度方面,log2vec优于其他最先进的方法。它可以有效地检测各种场景下的网络威胁。
个人感受
个人总结:
从宏观上来说,该篇论文是讲异构图嵌入应用在网络空间威胁检测(日志细粒度级别)这个领域,属于是开创一个新的攻击检测的思路,为以后的研究提供了指导。
从微观上来说,该论文虽然采用是经典的异构图嵌入,但很多细节做的比较到位:第一,文章在分析日志记录时,讲日志分成了5种属性,便于更深入地挖掘和分析主机内日志条目之间的关系,实现了更细粒度地攻击检测;第二,文章根据实际场景对图嵌入中的随机游走进行了改进,分析到日志间更紧密的关系;第三,文章对参数的处理也很全面,如考虑到边类型的比例,而不仅仅是有哪些边;第四检测算法的聚类算法中,充分考虑到实际场景的特点,并没有采用传统的kmeans算法,而是提出一种基于相似度比较的聚类算法,还通过两个阈值来进行检测。
个人拙见
以下两点是个人认为还可以学习(改进)得方面
检测对象方面
针对该篇论文检测的内部员工攻击和APT攻击这两类攻击来说,我先要对这两类攻击有很清晰的了解,如这两类攻击的表现形式是什么,内在模式又是什么(补充网络安全基础知识)。除此之外,该篇论文的方法不仅仅可以检测这两类攻击,也不仅仅局限于对日志项进行分析。比如,还可以检测其他常见的攻击类型,更深入的做法是在采用图构建和图嵌入之后,利用其他检测框架或系统来检测攻击(上升到ATT&CK框架)到底是哪种类型。另外,该篇论文的方法也可以应用在其他数据形式上,如进程数据。
图嵌入方面
论文中基于规则的启发式构建好以日志项为节点的异构图,“异构”主要体现在边类型的不同,但在处理该图时并未采用异构图嵌入的方法,而是把它当成同构图,采用随机游走算法和word2vec方法来进行图嵌入。所以后续可以通过采用异构图嵌入的方法来处理该异构图,比如学习metapath2vec算法(一种经典的异构图嵌入算法),将其应用在该篇论文构建的异构图中。
若之后会继续研究,可以对这两面深入分析。
英文好句
-
Nevertheless, this type of methods is generally capable of analyzing the particular relation-ship, interactive relationship among hosts, and cannot detect the previously mentioned insider threats, involving numerous other operations, such as file operations and website browses.
-
When we employ log2vec, a method of representation learning, to analyze user’s behavior for cyber threat detection, we find that this type of detection requires different combinations of parameters for each user to achieve the best performance, because multiple users and attack scenarios produce various user’s behavior and attack patterns.
-
Each rule, corresponding to an edge type, is derived from a specific relationship, as above examples
-
Put another way, these benign daily sequences share ssimilar behavioral patterns, different from the malicious ones.