可观测性最佳实践|怎样让运维和开发协同保障系统稳定性
保障系统稳定运行,这是所有数字平台的基本要求,但谁是第一责任人?假设 10 年前提出此问,绝大部分答案会说是运维。但在今天,随着微服务和云原生的进一步普及,很多情况是运维负责的 IaaS 和 PaaS 一切正常,但开发提供的程序漏洞百出,极不稳定,经常崩溃,这时谁该是第一责任人?可开发其实也有话说,既要保持应用高频迭代,又要保证稳定不出错,这是两个反方向的任务,不可能同时实现。
那就把这个问题再进一步,是保障系统稳定性重要,还是保持高频迭代快速上线重要?可能在不同的业务场景下,答案都不一样,但业务既要又要怎么办?在这个看似不可能完成的任务面前,运维和开发是否有可能紧密协同,共担责任,找到系统稳定和高频迭代的平衡点?
其实这完全可以做到,首先要实现系统全链路数据的可观测性。
可观测性对于生产环境的价值
可观测性是指在系统中收集和分析数据以了解系统的行为和状态的能力。可观测性并不是一个新生物,而是一种观念的创新。相对于传统的监控而言,可观测性是站在系统的角度去探索系统应该如何恰当地展现自己的状态,而监控则是站在局外人的角度去审视系统的运行情况。
在生产环境中,可观测性可以帮助运维人员了解系统的运行情况,及时发现问题并进行处理。同时,可观测性也可以帮助研发人员了解系统的瓶颈和性能问题,进而提高系统的可靠性和性能。因此,引入可观测性是实现生产环境运维和研发协同的一个重要步骤。
可观测性实现研发运维协同的实践
构建业务的全面可观测性平台
对于服务于生产环境的可观测性平台,必须具备完整的业务可观测性能力。从实际的业务系统出发,能够覆盖多种多样的客户端,例如 Web、小程序、Android、iOS 等。服务端支持多种语言,并尽量减少接入的门槛,对业务的影响降到最低。其次,对于中间件、系统以及各种云服务的支持,都要做到全面覆盖。只有这样的可观测性平台才能具备生产环境下运维和研发协同使用的前提。
通过观测云实现的可观测性平台,具备完整全面的可观测能力。无论业务采用任何客户端、服务端、中间件或多种多样的云服务,或者是多云能力,观测云都具备非常好的扩展接入能力。实际改造接入对业务本身造成的影响也非常小。
构建统一日志分析平台
在生产环境中,运维和开发人员都要依赖大量的日志来跟踪分析系统运行的情况,但实际上应用产生的日志,包括业务本身的日志、业务依赖中间件的日志、系统日志、安全日志等等,这些日志基本上都是散落在不同的日志平台上,当生产环境系统出现故障的时候,研发和运维需要在这些不同的日志系统中提取有用的信息,这对于快速排查故障,造成了非常大的麻烦。如果能把这些日志集中管理,并提供集中检索功能和关联分析,不仅可以提供高诊断效率,同时对系统情况能有全面的了解,可以避免事后救火的被动。
观测云提供全面的日志采集能力,通过配置日志采集,把日志数据统一上报到观测云,就可以对所采集的日志数据进行统一存储、查询、告警、分析、导出等操作。对于开发和运维人员,从一个日志平台检索所有日志内容,不管是开发还是运维都能够快速掌握各个系统运行的情况。

构建分布式追踪能力
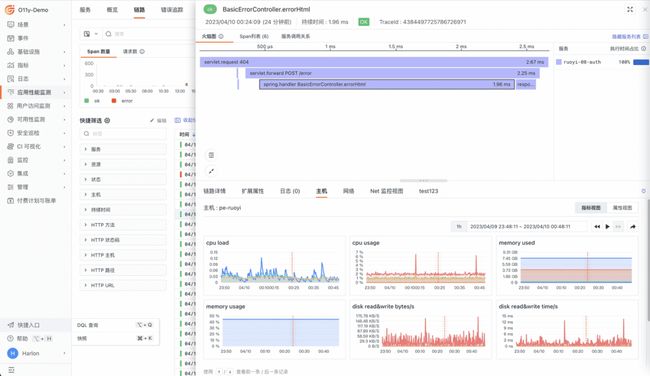
分布式跟踪能力是一种用于跟踪分布式系统请求的方法。当系统内部的服务和组件数量增加时,分布式跟踪能力变得越来越重要。通过一个 trace_id 串联前后端所有服务,分布式追踪能力能够快速了解请求在系统中的流向和时间。此外,如果系统的请求日志也能够包括请求 trace_id,您就能够具备完整的分布式追踪能力。这样,运维人员可以快速掌握系统间的依赖关系,开发人员也能够快速识别系统瓶颈及性能问题。除了跟踪请求,分布式追踪能力还可以帮助了解系统中的错误和异常。使用分布式追踪工具来监视请求的响应时间、成功率、错误率等指标,以及系统中的资源使用情况。这些指标可以帮助运维和开发识别潜在的性能问题,并提供优化系统的线索。
利用观测云,可实现完整的从前端到后端,再到基础设施端的全链路可追踪能力,通过一个 trace_id 实现用户会话访问、页面访问、后端接口、后端请求日志,以及对应主机或容器监控的串联追踪能力。运维和研发利用全链路的可追踪能力,快速识别系统问题并解决,最大程度提高系统的稳定性。
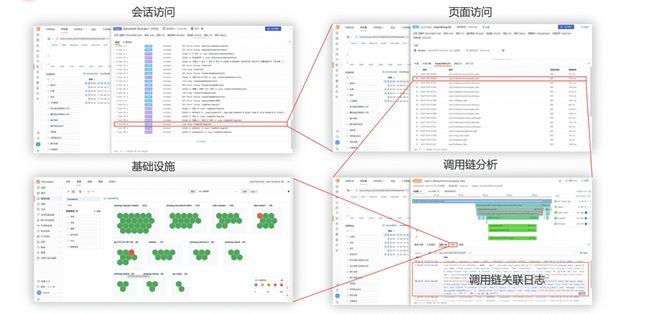
构建异常跟踪能力
在生产环境中,不管是运维还是研发,都需要实时跟踪系统产生的异常。运维人员要及时发现系统异常并进行处理,他们可以利用可观测性平台来实时跟踪系统的健康状况,一旦出现异常,他们就需要立即采取措施来解决问题。而研发人员也需要实时跟踪系统异常,他们可以利用异常数据来进行问题分析和性能优化。通过对异常数据的分析,他们可以了解系统的运行状况,找到问题的根源并进行优化,从而提高系统的性能和可靠性。
观测云具备系统运行中的错误追踪能力,并具有异常发生的完整上下文,异常时的系统日志、主机状态、依赖服务的状态,非常方便运维和开发人员定位并解决异常问题。其次,通过错误聚类可以了解系统中有哪几类的异常,通过聚类可以快速知晓系统异常种类,把精力投入到最重要的问题上。
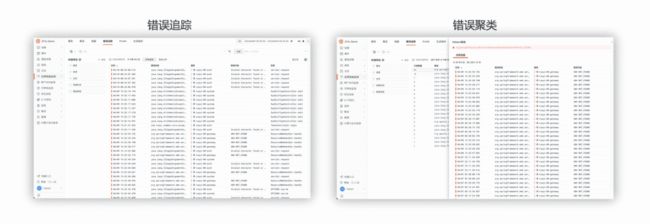
构建扁平化的基础设施监控平台
在传统模式下,基础设施平台的问题都是由运维来保障。当系统出现故障时,运维人员会去排查基础设施相关的监控数据,排除基础设施问题后再把相关问题透传给研发人员。在生产环境下的故障定位处理时效要求非常高,而研发和运维对于基础设施监控数据的都有依赖,因此需要一种更加高效的方式来解决这个问题。利用可观测平台构建扁平化的基础设施监控平台,从系统本身出发,将依赖的基础设施,如主机、容器、数据库等全部集中起来,不管是研发还是运维人员,都能第一时间知悉基础设施的健康状况,从而对故障的真实情况快速做出判断。
通过观测云构建的基础设施监控平台,不光能收集这些基础设施平台的指标、日志等监控数据,而且具备将基础设施同系统关联的能力,这种能力在复杂的生产环境下非常有价值,研发人员可以从系统应用出发查看依赖的基础设施监控数据,运维人员可以从基础设施出发,查看基础设施运行的系统应用的监控数据。
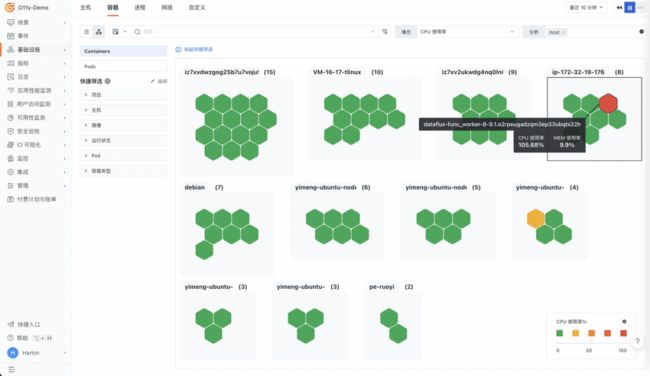
总结
在生产环境中引入可观测性对于确保系统的稳定性、可靠性和性能至关重要。通过构建业务的全面可观测性平台、统一的日志分析平台、分布式追踪能力、异常跟踪能力、扁平化的基础设施监控平台等方法,运维和研发团队可以更有效地协同工作,识别和解决问题。使用这些方法,团队可以确保其系统平稳运行,用户获得良好体验。
END
观测云
更多资讯请关注观测云官网
(guance.com),扫码小助手获取~
![]()
