【C语言】——初阶指针
这里写目录标题
- 指针
-
-
- 指针是什么
- 指针和指针类型
- 野指针
-
-
- 概念:
- 野指针成因
- 如何规避野指针
-
- 指针运算
-
-
- 指针+- 整数
- 指针-指针
- 指针的关系运算
-
- 指针和数组
- 二级指针
- 指针数组
-
指针
指针是什么
在计算机科学中,指针(Pointer)是编程语言中的一个对象,利用地址,它的值直接指向(points to)存在电脑存储器中另一个地方的值。由于通过地址能找到所需的变量单元,可以说,地址指向该变量单元。因此,将地址形象化的称为“指针”。意思是通过它能找到以它为地址的内存单元。
指针就是地址,地址就是指针。
int main()
{
int a = 10;//在内存中开辟一块空间
int* p = &a;//这里我们对变量a,取出它的地址,可以使用&操作符。
//将a的地址存放在p变量中,p就是一个之指针变量。
return 0;
}

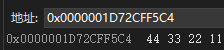
注意:在这里 p 存的是 a 的起始地址(0x0012ff40),如图。
其中 a 是 int 型变量,在内存中会占4个字节的存储空间,但指针只保存 a 的起始地址
p 是个指针变量,有空间,需要4个字节保存,地址就是内存单元的编号,有32根地址总线来组合
( 一个指针变量无论它指向的变量占几个字节,在32位机器上,它本身都只占4个字节;在64位机器上,占8个字节)
即:
# include 
可见,指针变量是和变量的类型是无关的,只和电脑本身是64位机器还是32位机器有关。
指针和指针类型
int main()
{
int a = 0x11223344;
//如果p是整形指针,解引用访问了4个字节
int* p = &a;
*p = 0;
}
我们观察内存中存储的情况:调试->窗口->内存
a = 0x11223344;
int* p = &a;
&p
![]()
p
![]()
*p = 0;
![]()
int main()
{
int a = 0x11223344;
char* p = &a;//int *
*p = 0;
}

确实把 a 的地址放在了 p 中
int a = 0x11223344;
&a
![]()
char* p = &a;
&p
![]()
p
![]()
*p = 0;
![]()
-
如果p是整形指针,解引用访问了4个字节
-
如果p是字符指针,解引用访问了1个字节
int* -- 访问 4 个字节 char* --访问 1 个字节 short* --访问 2 个字节 double* --访问 8 个字节这就是指针类型的意义。
总结:
指针的类型决定了,对指针解引用的时候有多大的权限(能操作几个字节)。 比如: char* 的指针解引用就只能访问一个字节,而 int* 的指针的解引用就能访问四个字节。
int main() {
int arr[10] = { 0 };
int* pa = arr;//数组名-首元素地址
char* pc = arr;
printf("%p\n", arr);
printf("------------------\n");
printf("%p\n", pa);
printf("%p\n", pa + 1);
printf("------------------\n");
printf("%p\n", pc);
printf("%p\n", pc + 1);
return 0;
}

总结:指针的类型决定了指针 +1 / -1,走多大距离。
利用指针对数组进行操作的实例
int main() {
int arr[10] = { 0 };
int* p = arr;
int i = 0;
for (i = 0; i < 10; i++) {
*(p + i) = i;
}
for (i = 0; i < 10; i++) {
printf("%d ", *(p + i));
}
}

int main() {
int arr[10] = { 0 };
//我希望把arr这10个整形的空间,看做40个字节的空间
//给每个字节放一个字符进去
char*pc = arr;
int i = 0;
char x = 'a';
for (i = 0; i < 40; i++)
{
*(pc + i) = x;
x++;
}
}
数组arr在内存中的存放结果

在 utf-8 中,编码 61 对应的是字符 a。

野指针
概念:
野指针就是指针指向的位置是不可知的(随机的、不正确的、没有明确限制的)
野指针成因
- 指针未初始化
int main()
{
int* p;//局部变量指针未初始化,默认为随机值
*p = 20;
printf("%d", *p);
return 0;
}
![]() 编译会报错
编译会报错
- 指针越界访问
int main()
{
int arr[10] = { 0 };//数组下标为 0~9
int* p = arr;
int i = 0;
for (i = 0; i <= 11; i++)//当i=10 时,*(p+i)会越界
{
//当指针指向的范围超出数组arr的范围时,p就是野指针 *(p + i) =i;
}
return 0;
}
- 指针指向的空间释放
int* test()
{
int a = 10;
return &a;
}
int main()
{
//野指针 -
//p得到的地址之后,地址指向的空间已经释放了,所以这个时候的p就是野指针
//
int*p = test();
printf("hehe\n");//如果没有这句,程序有可能正常运行,结果为10
printf("%d\n", *p);//并不是 10
return 0;
}
// 1
int* p;
*p = 10;
// 2
int* p = 10;
1 是经典的错误,标准的野指针(因为未初始化)
因为,1 中 p 未初始化,指向一块随机的地址,然后将该地址中的数据修改为 10,但该地址所在的内存空间 不在程序的内存空间之中(系统会为我们的程序开辟一块内存空间,但由于p未初始化,我们并不知道它指向的空间在哪,可能指向的是其他程序的空间中)
2 是正确的
当我们创建指针时,还没确定好要指向谁时,初始化为 NULL
int* q = NULL
如何规避野指针
-
指针初始化
-
小心指针越界
-
指针指向空间释放及时置为NULL
int arr[10] = {0};
int* p = arr;
//当p不再用来指向arr时
p = NULL
//及时将p置为NULL
-
指针使用之前检查有效性
错误写法:
int main() { //NULL指向的空间是不能访问的-空指针 int* p = NULL; *p = 20; return 0; }
正确写法:
int main() { //NULL指向的空间是不能访问的 int* p = NULL; if (p != NULL) { *p = 20; } return 0; }
指针运算
- 指针± 整数
- 指针-指针
- 指针的关系运算
指针± 整数
int main() {
int arr[5] = { 0 };
int* p = arr;
int i = 0;
for (i = 0; i < 5; i++) {
*(p + i) = i;
}
for (i = 0; i < 5; i++) {
printf("%d ", *(p+i));
}
}
int main() {
int arr[5] = { 0 };
int* p = arr;
int i = 0;
for (i = 0; i < 5; i++) {
//*(p + i) = i;
*p++ = i;
}
p = arr;
for (i = 0; i < 5; i++) {
printf("%d ", *(p+i));
}
}

#define N_VALUES 5
int main() {
float values[N_VALUES];
//数组包含 [0],[1],[2],[3],[4] 个数组下标
float* vp;
//指针+-整数;指针的关系运算
// vp < &values[N_VALUES] , 这里是比较地址的大小
// &values[N_VALUES],数组下标[5]是数组向后越界访问的第一个地址
for (vp = &values[0]; vp < &values[N_VALUES];)
{
*vp++ = 0;
}
}
指针-指针
int main() {
int arr[10] = { 0 };
printf("%d\n", &arr[9] - &arr[9]);
printf("%d\n", &arr[0] - &arr[9]);
// 指针 - 指针 结果的绝对值 = 指针之间元素的个数
}
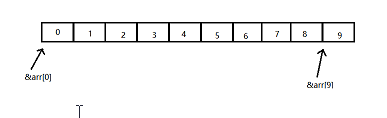
&arr[9] 指的是数组[9]的首地址,&arr[0]指的是数组[0]的首地址,在这两个首地址之间有 9 个元素。

int main() {
int arr[10] = { 0 };
char ch[5] = { 0 };
printf("%d\n", &arr[9] - &ch[3]);//error
//指针 - 指针 计算的前提条件是:两个指针指向的是同一块连续的空间
}
统计字符串个数:
int my_strlen(char* str) {
int count = 0;
while (*str != '\0') {
str++;
count++;
}
return count;
}
int main() {
char arr[] = "abcdef";
int len = my_strlen(arr);
printf("%d\n", len);
return 0;
}

//指针 - 指针版
int my_strlen(char* str) {
char* start = str;
while (*str != '\0') {
str++;
}
return str - start;
}
int main() {
char arr[] = "abcdef";
int len = my_strlen(arr);
printf("%d\n", len);
return 0;
}

指针的关系运算
#define N_VALUES 5
int main() {
float values[N_VALUES];
//数组包含 [0],[1],[2],[3],[4] 个数组下标
float* vp;
for (vp = &values[N_VALUES]; vp > &values[0];) {
*--vp = 0;
}
}

上面的代码会将数组里面的值全改为 0
将上面代码简化为下列代码
#define N_VALUES 5
int main() {
float values[N_VALUES];
//数组包含 [0],[1],[2],[3],[4] 个数组下标
float* vp;
for (vp = &values[N_VALUES - 1]; vp >= &values[0]; vp--) {
*vp = 0;
}
}

第二种写法实际在绝大部分的编译器上是可以顺利完成任务的,然而我们还是应该避免这样写,因为标准并不保证它可行。
因为,标准规定:允许指向数组元素的指针与指向数组最后一个元素后面的那个内存位置的指针比较,但是不允许与指向第一个元素之前的那个内存位置的指针进行比较。(即数组可以向后越界一次,但不能向前越界)
指针和数组
数组可以通过指针来访问。
数组名是什么?我们看一个例子:
int main() {
int arr[10] = { 1,2,3,4,5,6,7,8,9,0 };
printf("%p\n", arr);
printf("%p\n", &arr[0]);
return 0;
}
可见数组名和数组首元素的地址是一样的。
结论:数组名表示的是数组首元素的地址。
那么这样写代码是可行的:
int arr[10] = {1,2,3,4,5,6,7,8,9,0};
int* p=arr;//p存放的是数组首元素的地址
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,0 };
int* p = arr; //指针存放数组首元素的地址
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("&arr[%d] = %p <====> p+%d = %p\n", i, &arr[i], i, p + i);
}
return 0;
}
既然可以把数组名当成地址存放到一个指针中,我们使用指针来访问一个就成为可能。
例如:

二级指针
int main() {
int a = 10;
int* p = &a;
int** pp = &p;
return 0;
}

指针数组
指针数组是指针还是数组?
答案:是数组。是存放指针的数组。
数组我们已经知道整形数组,字符数组,…。
//数组
//整形数组 - 存放整形的数组
//字符数组 - 存放字符的数组
//指针数组 - 存放指针的数组
int main()
{
int arr[10] = {0};//整形数组
char ch[5] = { 'a', 'b' };//字符数组
//指针数组
int a = 10;
int b = 20;
int c = 30;
//arr就是指针数组
//存放整形指针的数组
int* arr[3] = { &a, &b, &c };//int*
//存放字符指针的数组
char* ch[5];
return 0;
}
用途:
int main() {
char* p = "abcdef";
// p 中存放的是 首元素 a 的地址
printf("%s\n", p);//从 a 开始打印
char* arr[] = { "abcdef","hello","bit" };
//arr[0],arr[1],arr[2] 存放的也是 各自首元素的地址
int i = 0;
for (i = 0; i < 3; i++) {
printf("%s\n", arr[i]);
}
return 0;
}

补充:
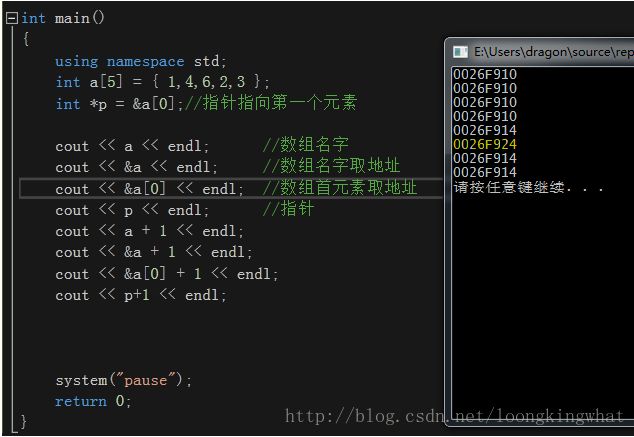
一维数组数组名 代表的是 首元素的地址
&[数组名] 代表的是 数组的地址
虽然两个地址是相同的,但 各自 ± 整数,的效果是不同的。
二维数组和一维数组有所不同,以后再讨论