ClickHouse的架构与基本概念
一、ClickHouse的定义
ClickHouse是一个完全的列式分布式数据库管理系统(DBMS),允许在运行时创建表和数据库,加载数据和运行查询,而无需重新配置和重新启动服务器,支持线性扩展,简单方便,高可靠性,容错。它在大数据领域没有走 Hadoop 生态,而是采用 Local attached storage 作为存储,这样整个 IO 可能就没有 Hadoop 那一套的局限。它的系统在生产环境中可以应用到比较大的规模,因为它的线性扩展能力和可靠性保障能够原生支持 shard + replication 这种解决方案。它还提供了一些 SQL 直接接口,有比较丰富的原生 client。
二、Clickhouse整体架构
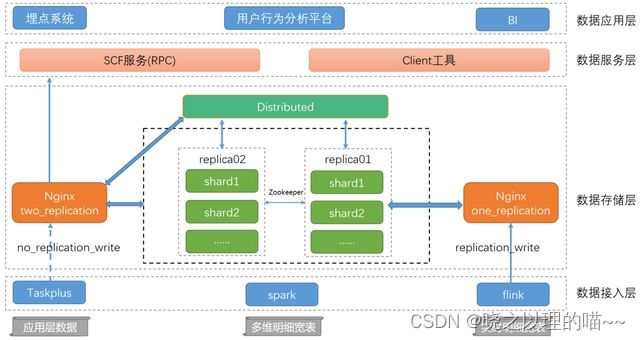
1,数据接入层
提供了数据导入相关的服务及功能,按照数据的量级和特性我们抽象出三种Clickhouse导入数据的方式。
方式一:数仓应用层小表导入这类数据量级相对较小,且分布在不同的数据源如hdfs、es、hbase等,这时我们提供基于DataX自研的TaskPlus数据流转+调度平台导入数据,单分区数据无并发写入,多分区数据小并发写入,且能和线上任务形成依赖关系,确保导入程序的可靠性。
方式二:离线多维明细宽表导入这类数据一般是汇总层的明细数据或者是用户基于Hadoop生产的大量级数据,我们基于Spark开发了一个导入工具包,用户可以根据配置直接拉取hdfs或者hive上的数据到clickhouse,同时还能基于配置sql对数据进行ETL处理,工具包会根据配置集群的节点数以及Clickhouse集群负载情况(merges、processes)对local表进行高并发的写入,达到快速导数的目的。
方式三:实时多维明细宽表导入实时数据接入场景比较固定,我们封装了通用的ClickhouseSink,将app、pc、m三端每日百亿级的数据通过Flink接入clickhouse,ClickhouseSink也提供了batchSize(单次导入数据量)及batchTime(单次导入时间间隔)供用户选择。
2,数据存储层
ClickHouse从OLAP场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序存储、主键索引、稀疏索引、数据Sharding、数据Partitioning、TTL、主备复制等丰富功能。以上功能共同为ClickHouse极速的分析性能奠定了基础。
(1)列式存储
与行存将每一行的数据连续存储不同,列存将每一列的数据连续存储。示例图如下:
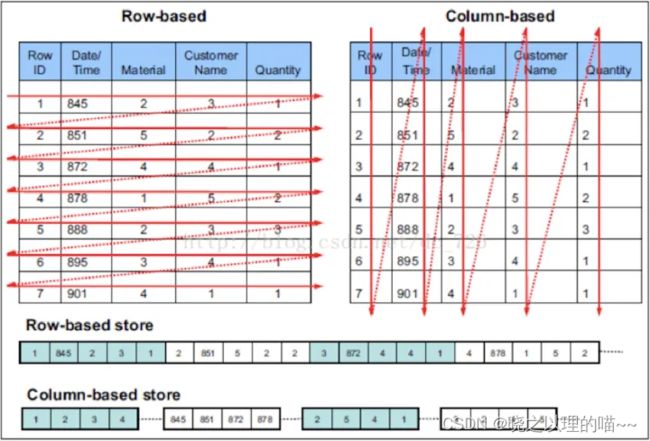
相比于行式存储,列式存储在分析场景下有着许多优良的特性。
1)如前所述,分析场景中往往需要读大量行但是少数几个列。在行存模式下,数据按行连续存储,所有列的数据都存储在一个block中,不参与计算的列在IO时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了IO cost,加速了查询。
2)同一列中的数据属于同一类型,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
3)更高的压缩比意味着更小的data size,从磁盘中读取相应数据耗时更短。
4)自由的压缩算法选择。不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同。可以针对不同列类型,选择最合适的压缩算法。
5)高压缩比,意味着同等大小的内存能够存放更多数据,系统cache效果更好。
官方数据显示,通过使用列存,在某些分析场景下,能够获得100倍甚至更高的加速效应。
(2)数据有序存储
ClickHouse支持在建表时,指定将数据按照某些列进行sort by。
排序后,保证了相同sort key的数据在磁盘上连续存储,且有序摆放。在进行等值、范围查询时,where条件命中的数据都紧密存储在一个或若干个连续的Block中,而不是分散的存储在任意多个Block, 大幅减少需要IO的block数量。另外,连续IO也能够充分利用操作系统page cache的预取能力,减少page fault。
(3)主键索引
ClickHouse支持主键索引,它将每列数据按照index granularity(默认8192行)进行划分,每个index granularity的开头第一行被称为一个mark行。主键索引存储该mark行对应的primary key的值。
对于where条件中含有primary key的查询,通过对主键索引进行二分查找,能够直接定位到对应的index granularity,避免了全表扫描从而加速查询。
但是值得注意的是:ClickHouse的主键索引与MySQL等数据库不同,它并不用于去重,即便primary key相同的行,也可以同时存在于数据库中。要想实现去重效果,需要结合具体的表引擎ReplacingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree实现,我们会在未来的文章系列中再进行详细解读。
(4)稀疏索引
ClickHouse支持对任意列创建任意数量的稀疏索引。其中被索引的value可以是任意的合法SQL Expression,并不仅仅局限于对column value本身进行索引。之所以叫稀疏索引,是因为它本质上是对一个完整index granularity(默认8192行)的统计信息,并不会具体记录每一行在文件中的位置。
目前支持的稀疏索引类型包括:
1)minmax: 以index granularity为单位,存储指定表达式计算后的min、max值;在等值和范围查询中能够帮助快速跳过不满足要求的块,减少IO。
2)set(max_rows):以index granularity为单位,存储指定表达式的distinct value集合,用于快速判断等值查询是否命中该块,减少IO。
3)ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed):将string进行ngram分词后,构建bloom filter,能够优化等值、like、in等查询条件。
4)tokenbf_v1(size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed): 与ngrambf_v1类似,区别是不使用ngram进行分词,而是通过标点符号进行词语分割。
5)bloom_filter([false_positive]):对指定列构建bloom filter,用于加速等值、like、in等查询条件的执行。
(5)数据Sharding
ClickHouse支持单机模式,也支持分布式集群模式。在分布式模式下,ClickHouse会将数据分为多个分片,并且分布到不同节点上。不同的分片策略在应对不同的SQL Pattern时,各有优势。ClickHouse提供了丰富的sharding策略,让业务可以根据实际需求选用。
1) random随机分片:写入数据会被随机分发到分布式集群中的某个节点上。
2) constant固定分片:写入数据会被分发到固定一个节点上。
3)column value分片:按照某一列的值进行hash分片。
4)自定义表达式分片:指定任意合法表达式,根据表达式被计算后的值进行hash分片。
数据分片,让ClickHouse可以充分利用整个集群的大规模并行计算能力,快速返回查询结果。
更重要的是,多样化的分片功能,为业务优化打开了想象空间。比如在hash sharding的情况下,JOIN计算能够避免数据shuffle,直接在本地进行local join; 支持自定义sharding,可以为不同业务和SQL Pattern定制最适合的分片策略;利用自定义sharding功能,通过设置合理的sharding expression可以解决分片间数据倾斜问题等。
另外,sharding机制使得ClickHouse可以横向线性拓展,构建大规模分布式集群,从而具备处理海量数据的能力。
(6)数据Partitioning
ClickHouse支持PARTITION BY子句,在建表时可以指定按照任意合法表达式进行数据分区操作,比如通过toYYYYMM()将数据按月进行分区、toMonday()将数据按照周几进行分区、对Enum类型的列直接每种取值作为一个分区等。
数据Partition在ClickHouse中主要有两方面应用:
1)在partition key上进行分区裁剪,只查询必要的数据。灵活的partition expression设置,使得可以根据SQL Pattern进行分区设置,最大化的贴合业务特点。
2)对partition进行TTL管理,淘汰过期的分区数据。
(7)数据TTL
在分析场景中,数据的价值随着时间流逝而不断降低,多数业务出于成本考虑只会保留最近几个月的数据,ClickHouse通过TTL提供了数据生命周期管理的能力。
ClickHouse支持几种不同粒度的TTL:
1) 列级别TTL:当一列中的部分数据过期后,会被替换成默认值;当全列数据都过期后,会删除该列。
2)行级别TTL:当某一行过期后,会直接删除该行。
3)分区级别TTL:当分区过期后,会直接删除该分区。
(8)高吞吐写入能力
lickHouse采用类LSM Tree的结构,数据写入后定期在后台Compaction。通过类LSM tree的结构,ClickHouse在数据导入时全部是顺序append写,写入后数据段不可更改,在后台compaction时也是多个段merge sort后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞吐能力,即便在HDD上也有着优异的写入性能。
官方公开benchmark测试显示能够达到50MB-200MB/s的写入吞吐能力,按照每行100Byte估算,大约相当于50W-200W条/s的写入速度。
(9)有限支持delete、update
在分析场景中,删除、更新操作并不是核心需求。ClickHouse没有直接支持delete、update操作,而是变相支持了mutation操作,语法为alter table delete where filter_expr,alter table update col=val where filter_expr。
目前主要限制为删除、更新操作为异步操作,需要后台compation之后才能生效。
(10)主备同步
ClickHouse通过主备复制提供了高可用能力,主备架构下支持无缝升级等运维操作。而且相比于其他系统它的实现有着自己的特色:
1)默认配置下,任何副本都处于active模式,可以对外提供查询服务;
2)可以任意配置副本个数,副本数量可以从0个到任意多个;
3)不同shard可以配置不提供副本个数,用于解决单个shard的查询热点问题。
3,ClickHouse计算层
(1)多核并行
ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity,然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。
在这种设计下,单条Query就能利用整机所有CPU。极致的并行处理能力,极大的降低了查询延时。
(2)分布式计算
除了优秀的单机并行处理能力,ClickHouse还提供了可线性拓展的分布式计算能力。ClickHouse会自动将查询拆解为多个task下发到集群中,然后进行多机并行处理,最后把结果汇聚到一起。
在存在多副本的情况下,ClickHouse提供了多种query下发策略:
1)随机下发:在多个replica中随机选择一个;
2)最近hostname原则:选择与当前下发机器最相近的hostname节点,进行query下发。在特定的网络拓扑下,可以降低网络延时。而且能够确保query下发到固定的replica机器,充分利用系统cache。
3)in order:按照特定顺序逐个尝试下发,当前一个replica不可用时,顺延到下一个replica。
4)first or random:在In Order模式下,当第一个replica不可用时,所有workload都会积压到第二个Replica,导致负载不均衡。5)first or random解决了这个问题:当第一个replica不可用时,随机选择一个其他replica,从而保证其余replica间负载均衡。另外在跨region复制场景下,通过设置第一个replica为本region内的副本,可以显著降低网络延时。
(3)向量化执行与SIMD
ClickHouse不仅将数据按列存储,而且按列进行计算。传统OLTP数据库通常采用按行计算,原因是事务处理中以点查为主,SQL计算量小,实现这些技术的收益不够明显。但是在分析场景下,单个SQL所涉及计算量可能极大,将每行作为一个基本单元进行处理会带来严重的性能损耗:
1)对每一行数据都要调用相应的函数,函数调用开销占比高;
2)存储层按列存储数据,在内存中也按列组织,但是计算层按行处理,无法充分利用CPU cache的预读能力,造成CPU Cache miss严重;
3)按行处理,无法利用高效的SIMD指令;
ClickHouse实现了向量执行引擎(Vectorized execution engine),对内存中的列式数据,一个batch调用一次SIMD指令(而非每一行调用一次),不仅减少了函数调用次数、降低了cache miss,而且可以充分发挥SIMD指令的并行能力,大幅缩短了计算耗时。向量执行引擎,通常能够带来数倍的性能提升。
(4)动态代码生成Runtime Codegen
在经典的数据库实现中,通常对表达式计算采用火山模型,也即将查询转换成一个个operator,比如HashJoin、Scan、IndexScan、Aggregation等。为了连接不同算子,operator之间采用统一的接口,比如open/next/close。在每个算子内部都实现了父类的这些虚函数,在分析场景中单条SQL要处理数据通常高达数亿行,虚函数的调用开销不再可以忽略不计。另外,在每个算子内部都要考虑多种变量,比如列类型、列的size、列的个数等,存在着大量的if-else分支判断导致CPU分支预测失效。
ClickHouse实现了Expression级别的runtime codegen,动态地根据当前SQL直接生成代码,然后编译执行。如下图例子所示,对于Expression直接生成代码,不仅消除了大量的虚函数调用(即图中多个function pointer的调用),而且由于在运行时表达式的参数类型、个数等都是已知的,也消除了不必要的if-else分支判断。
(5)近似计算
近似计算以损失一定结果精度为代价,极大地提升查询性能。在海量数据处理中,近似计算价值更加明显。
ClickHouse实现了多种近似计算功能:
1)近似估算distinct values、中位数,分位数等多种聚合函数;
2)建表DDL支持SAMPLE BY子句,支持对于数据进行抽样处理;
(6)复杂数据类型支持
ClickHouse还提供了array、json、tuple、set等复合数据类型,支持业务schema的灵活变更。
4,数据服务层
对外:将集群查询统一封装为scf服务(RPC),供外部调用。
对内:提供了客户端工具直接供分析师及开发人员使用。
5,数据应用层
埋点系统:对接实时clickhouse集群,提供秒级别的OLAP查询功能。
用户分析平台:通过标签筛选的方式,从用户访问总集合中根据特定的用户行为捕获所需用户集。
BI:提供数据应用层的可视化展示,对接单分片多副本Clickhouse集群,可横向扩展。
三、ClickHouse的优缺点
1,优点
(1)灵活的MPP架构,支持线性扩展,简单方便,高可靠性;
(2)多服务器分布式处理数据 ,完备的DBMS系统;
(3)底层数据列式存储,支持压缩,优化数据存储,优化索引数据 优化底层存储;
(4)容错跑分快:比Vertica快5倍,比Hive快279倍,比MySQL快800倍,其可处理的数据级别已达到10亿级别;
(5)功能多:支持数据统计分析各种场景,支持类SQL查询,异地复制部署;
(6)海量数据存储,分布式运算,快速闪电的性能,几乎实时的数据分析 ,友好的SQL语法,出色的函数支持。
2,缺点
(1)不支持事务,不支持真正的删除/更新 (批量);
(2)不支持高并发,官方建议qps为100,可以通过修改配置文件增加连接数,但是在服务器足够好的情况下;
(3)不支持二级索引;
(4)不擅长多表join 大宽表;
(5)元数据管理需要人为干预 ;
(6)尽量做1000条以上批量的写入,避免逐行insert或小批量的insert,update,delete操作。
四、ClickHouse核心概念
1,表引擎(Engine)
表引擎决定了数据在文件系统中的存储方式,常用的也是官方推荐的存储引擎是MergeTree系列,如果需要数据副本的话可以使用ReplicatedMergeTree系列,相当于MergeTree的副本版本。读取集群数据需要使用分布式表引擎Distribute。
2,表分区(Partition)
表中的数据可以按照指定的字段分区存储,每个分区在文件系统中都是都以目录的形式存在。常用时间字段作为分区字段,数据量大的表可以按照小时分区,数据量小的表可以在按照天分区或者月分区,查询时,使用分区字段作为Where条件,可以有效的过滤掉大量非结果集数据。
3,分片(Shard)
一个分片本身就是ClickHouse一个实例节点,分片的本质就是为了提高查询效率,将一份全量的数据分成多份(片),从而降低单节点的数据扫描数量,提高查询性能。
4, 复制集(Replication)
简单理解就是相同的数据备份,在CK中通过复制集,我们实现保障了数据可靠性外,也通过多副本的方式,增加了CK查询的并发能力。这里一般有2种方式:(1)基于ZooKeeper的表复制方式;(2)基于Cluster的复制方式。由于我们推荐的数据写入方式本地表写入,禁止分布式表写入,所以我们的复制表只考虑ZooKeeper的表复制方案。
5,集群(Cluster)
可以使用多个ClickHouse实例组成一个集群,并统一对外提供服务。
五、应用场景
1.绝大多数请求都是用于读访问的, 要求实时返回结果;
2.数据需要以大批次(大于1000行)进行更新,而不是单行更新;或者根本没有更新操作;
3.数据只是添加到数据库,没有必要修改;
4.读取数据时,会从数据库中提取出大量的行,但只用到一小部分列;
5.表很“宽”,即表中包含大量的列;
6.查询频率相对较低(通常每台服务器每秒查询数百次或更少);
7.对于简单查询,允许大约50毫秒的延迟;
8.列的值是比较小的数值和短字符串(例如,每个URL只有60个字节);
9.在处理单个查询时需要高吞吐量(每台服务器每秒高达数十亿行);
10.不需要事务;
11.数据一致性要求较低 [原子性 持久性 一致性 隔离性];
12.每次查询中只会查询一个大表。除了一个大表,其余都是小表;
13.查询结果显著小于数据源。即数据有过滤或聚合。返回结果不超过单个服务器内存大小。