知识继承概述
文章目录
- 知识继承
-
- 第一章 知识继承概述
-
- 1.背景介绍
-
- 第一页 背景
- 第二页 大模型训练成本示例
- 第三页 知识继承的动机
- 2.知识继承的主要方法
- 第二章 基于知识蒸馏的知识继承
-
-
- 预页 方法概览
- 1.知识蒸馏概述
-
- 第一页 知识蒸馏概述
- 第二页 知识蒸馏
- 第三页 什么是知识
- 第四页 知识蒸馏的核心目的
- 第五页 知识的表示与迁移
- 第六页 Hard Target & Soft Target
- 第七页 温度蒸馏T
- 第八页 不同T值的对比
- 第九页 知识蒸馏的过程
- 第十页 知识蒸馏的过程
- 第十一页 基于知识蒸馏的知识继承
- 2.知识继承
-
- 第一页 任务制定
- 第二页 研究方法
- 第三页 动态继承率
- 插页 RoBERTa
- 第四页 预训练收敛速度
- 第五页 下游任务评测
-
- 第三章 基于参数复用的知识继承
-
- 1.参数复用概述
-
- 插页 历史工作回顾--Net2Net
- 插页 Net2Net
- 插页 历史工作回顾--StackingBERT
- 插页 StackingBERT的核心算法
- 第一页 参数复用的可能性
- 2.进阶训练策略
-
- 第一页 BERT
- 第二页 BERT
- 第三页 BERT架构
- 第四页 多头注意力机制(MHA)
- 第五页 前馈网络(FFN)
- 第六页 层归一化
- 第七页 问题陈述
- 第八页 解决办法
- 第九页 横向模型增长
- 第九页 横向模型增长--Function Preserving Initialization
- 第十页 模块中的扩展
- 第十一页 横向模型增长--Advanced Knowledge Initialization
- 第十二页 模块中的扩展
- 第十三页 纵向模型增长
- 第十四页 两阶段的预训练
- 第十五页 实验结果
- 第四章 两种方法的对比与分析
-
- 1.优缺点对比
- 论文详细实验结果
-
- 第一篇 知识蒸馏
-
- Q1:知识继承如何促进大模型训练?
-
- 总体结果
- 遗传率的影响
- 使用Top-K Logits节省存储空间
- 在GPT上的实验
- Q2:知识可以代代继承吗?
- Q3:Ms的预训练设置如何影响知识继承?
-
- 模型架构的影响
- 预训练数据的影响
- Q4:知识继承如何有益于领域适应?
- 总结展望
- 第二篇 参数复用
-
- 实验设置
-
- 训练设置
- 微调设置
- 基线
- 结果和分析
-
- 在小的源模型上进行实验
- 子模型训练epoch的影响
- 在GPT上的应用
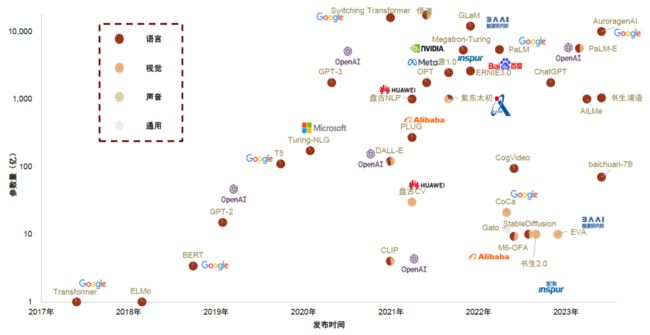
知识继承
第一章 知识继承概述
1.背景介绍
第一页 背景
尽管在探索各种预训练技术和模型架构方面做出了巨大努力,研究人员发现,简单地扩大模型容量、数据大小和训练时间可以显著提升模型性能,然而更多的模型参数也意味着更昂贵的计算资源、训练成本。

第二页 大模型训练成本示例
GPT4训练成本:
参数:大小是GPT-3十倍以上,120层中共有约1.8万亿个参数。
训练成本:据估计,在大约 25,000 个 A100 上,训练时间为 90~100 天,利用率为 32%~36%。如果在云端的成本约为每小时 1$/A100,那么运行的训练成本约为 6300 万美元。(如果使用约 8192 个 H100 GPU 进行预训练,用时将降到 55 天左右,成本为 2150 万美元,每个 H100 GPU 的计费标准为每小时 2$)
第三页 知识继承的动机
现有的PLM通常都是从零开始单独训练的,忽略了许多已训练的可用模型。
问题:如何利用已有的PLM辅助训练更大的PLM?
考虑到人类可以利用前人总结的知识来学习新任务;同样我们可以让大模型复用(继承)已有小模型中的隐式知识,从而加速大模型的训练。
2.知识继承的主要方法
- 基于知识蒸馏
- 基于参数复用
为了减少预训练计算消耗,研究者们提出知识继承框架,充分利用现有小模型消耗的算力。

第二章 基于知识蒸馏的知识继承

(NAACL 2022)
预页 方法概览
提出在大模型预训练初期,让现有小模型作为大模型的“老师”,将小模型的隐式知识“反向蒸馏”给大模型从而复用现有小模型的能力,减少大模型预训练计算消耗

1.知识蒸馏概述
第一页 知识蒸馏概述

蒸馏指的是把不纯净的水加热变成蒸汽,蒸汽冷凝之后变成冷凝水。
知识蒸馏也是把有杂质的东西,大的东西变成小的东西,纯的东西。把一个大的模型(教师模型)里面的知识给萃取蒸馏出来浓缩到一个小的学生模型上。
第二页 知识蒸馏

教师网络是一个比较大的神经网络,它把知识传递给了小的学生网络。这个过程称之为蒸馏或者叫迁移。
第三页 什么是知识
“知识”大体可以分为三种:
- 教师网络最终输出Soften Label(这里主要针对分类问题而言,相当于老师直接给答案,学生由答案反推问题的求解步骤)
- 教师网络中间层输出的Feature Maps,(相当于老师给出,她/他求解过程中的一些中间结果,以提示学生该如何求解)
- 教师网络学习或求解问题的流程(相当于老师给出问题求解时的大致求解流程,将老师求解问题前一步与后一步的求解过程教会给学生)
第四页 知识蒸馏的核心目的

在现在的人工智能社会,比如说计算机视觉,语音识别,自然语言处理,算法都是很大的。而真正落地的终端的算力都是非常有限的,比如说手机、智能手表、无人驾驶的汽车、物联网设备等等。
教师网络可能是用海量的数据,海量的能源训练出来的一个非常臃肿的模型,现在要部署到移动终端设备上,在算力非常受限的场景下,所以需要把大模型变成小模型,把模型部署到终端上。
第五页 知识的表示与迁移
假如将左边的的这匹马喂给一个图像分类的网络,可能会有很多类别,每个类别都识别一个概率。
在训练网络的时候,告诉网络是一匹马。会形成hard targets:马(1),驴(0),汽车(0)。
但是这并不科学,这样的标签等同告诉网络这是一匹马,不是驴也不是车,并且不像驴和不像车的概率是相等的。通过我们人眼可以看出来,这匹马和驴子是有一些相似性的,它更像驴子而更不像汽车。
如果把这匹马的图片喂到一个已经训练好的网络,网络可能会给出一个这样的结果——soft targets:马(0.7)、驴(0.25)、汽车(0.05)。
这个soft targets就足够的科学,它不仅告诉我们这个马的概率是最大的,那么它0.7的概率是一匹马,还有0.25的概率是一头驴,而汽车的概率只有0.05。soft targets就传递了更多的信息。
第六页 Hard Target & Soft Target

(两个2的Hard Target相同,但是Soft Target不相同)
在训练教师网络的时候可以用Hard Targets去训练,而产生出的soft targets能够传递出更多的信息,那么就可以用soft targets去训练学生网络。
由此可见,Soft Label包含了更多的“知识”和“信息”,像谁不像谁,有多像,有多不像,特别是非正确类别概率的相对大小。而在Hard Label里面非正确类别的概率一律被抹成了0.
第一个2像2也像3,第二个2像2也像7。在图中,除了3和7以外,其他的数字的概率都很小,现在需要把这些其他数字的概率放大,充分暴露出来它们的差别,需要引入一个温度蒸馏T。
第七页 温度蒸馏T
一般做多分类任务的时候都使用softmax这个激活函数。
softmax 函数一般用于多分类问题中,它是对逻辑斯蒂(logistic)回归的一种推广,也被称为多项逻辑斯蒂回归模型(multi-nominal logistic mode)。假设要实现 k 个类别的分类任务,Softmax 函数将输入数据 xi 映射到第 i个类别的概率 yi如下计算:

现在给该函数增加一个温度蒸馏T。

第八页 不同T值的对比

从图中我们可以看到当T=1的时候,曲线非常的陡峭,是马的概率是非常明显的,T=100的时候,我们几乎看不出这几种动物的分类有啥区别的,曲线非常的平缓。由此可知,我们可以增加T来使得原本比较hard的targets变得更soft。用更软的targets去训练学生网络,那些非正确类别的信息就暴露的越彻底。
第九页 知识蒸馏的过程

第一步:在温度为t的情况下,将数据喂给已经训练好的教师网络,得到soft labels;
第二步:在同样温度t下,将数据喂给没有训练过的学生网络,得到soft predictions,并与教师网络的 soft labels求损失函数。(学生模拟老师的预测结果)
第三步:学生网络自己经过一个T=1的普通的softmax,和hard label做一个损失函数。
第十页 知识蒸馏的过程
(复制上一页的图)
学生网络即要在温度为t的时候的结果跟教师网络的预测结果更接近,也要兼顾T=1的时候的预测结果和标准答案更接近。
也就是总体的损失函数为distillation loss和student loss两项的加权求和。
Loss = distillation loss + student loss
第十一页 基于知识蒸馏的知识继承
在 KI 的场景中,由于学生模型的容量更大,教师模型的表现不再是学生模型的“上限”。在NLP之外,研究人员最近证明,学生模型也可以从一个糟糕的教师的特定下游任务中受益(反向KD)。本文在前人研究的基础上,研究了反向 KD在训练前的应用。
2.知识继承
第一页 任务制定
给定一个文本输入x = {x1,…, xn},和对应的标签y∈RK,
K是特定预训练任务的类数
例如,用于掩码语言模型(MLM)的词汇量,PLM M将每个令牌xj ∈ x转换为任务特定的logits zj = [z1j,…,zKj]。使用具有温度τ的softmax函数,将zj转换为概率分布P(xj; τ)= [p1(xj; τ),…pK(xj; τ)]。
M是使用目标损失函数LSELF(x, y)=H(y, P(x;τ))预先训练好的模型。H是损失函数(如交叉熵损失函数)。
MLM-Masked Language Model,掩码/遮掩语言模型(双向的),在输入序列(一般是句子为基本单位)上随机mask掉(单词用[MASK]替换掉),然后让被改造后的序列去预测被mask掉的是哪些词;例如,假设love被mask掉,那么是p(love|I [mask] you)的概率最大化为目标,即最小化-logp(love|I [mask] you)。
在知识蒸馏中,老师模型的logits可以作为学生模型训练的软目标,而不仅仅是硬标签。这可以让学生模型学习到老师模型更丰富的信息,提高泛化能力,传递老师模型学习到的知识。
具体来说,学生模型需要逼近老师模型的logits,使两个模型在同一输入上输出尽可能接近的logits。

假设我们已经有一个经过自学习目标Lself(如MLM)训练好的小模型MS,我们的目标是利用MS的知识在语料库DL上训练更大的PLM ML。
第二页 研究方法
具体地,通过最小化MS和ML在相同输入xi ∈ DL上输出的两个概率分布之间的Kullback-Leibler(KL)散度来实现在DL上向ML赋予MS的知识,即,LKI(xi;MS)= τ2KL(P{M_S_}(xi; τ)||P{M_L_}(xi; τ)。此外,还鼓励ML通过优化LSELF(xi,yi)进行自学习。LSELF和LKI通过继承率α进行平衡:


KL 散度

τ2是在具体计算蒸馏loss时引入的,而不是在定义总loss时。第一项自监督loss不受高温度τ的影响,梯度scale保持默认,不需要额外系数调整。第二项蒸馏loss需要乘以τ2来调整梯度scale
在知识蒸馏中,使用Soft Target时对logits zi的偏导数的“magnitude”较小,而使用Hard Target时对logits zi的偏导数的“magnitude”较大。因此,为了在同时使用Soft Target和Hard Target进行知识蒸馏时平衡两者的影响,确实需要在Soft Target之前乘上τ2的系数。
具体来说,假设LSoft表示使用Soft Target时的损失函数,LHard表示使用Hard Target时的损失函数。在知识蒸馏中,模型的总体损失函数为:
Total Loss = LHard + τ2 * LSoft
其中,τ是一个超参数,通常称为温度(temperature),用于控制Soft Target的“软化”程度。通过乘上τ2的系数,Soft Target的损失对于梯度的影响将增加,从而平衡两个目标在知识蒸馏过程中的影响,确保梯度量在训练过程中更为一致。
第三页 动态继承率
当学生超过老师的时候,停止向老师“学习”。所以,需要动态的调整继承系数α。
即,当学生的能力超过老师时,应鼓励鼓励ML越来越多地自主学习知识,从超过之时,应该进行纯粹的自我学习。
对于总的训练步骤T,我们以αT/T的斜率线性衰减αt。
也就是说,学生只从老师那里继承T/αT步的知识,然后进行纯自学.

在步骤t,用于在DL上继承MS的知识的损失函数被公式化为:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Gz9vvzWQ-1692416550332)(C:\Users\24980\AppData\Roaming\Typora\typora-user-images\image-20230723123301633.png)]](http://img.e-com-net.com/image/info8/5915fd0958a14d4eac4f128d8ccaeea2.jpg)
注意,DL上的MS的logits可以预先计算并离线保存,以便我们在训练ML时不需要重新计算MS的logits.
插页 RoBERTa

从模型结构上讲,相比BERT,RoBERTa基本没有什么创新,它更像是关于BERT在预训练方面进一步的探索。上图是RoBERTa主要探索的几个方面,并将这些方面进行融合,最终训练得到的模型就是RoBERTa。
第四页 预训练收敛速度
实验证明在知识继承框架下大模型预训练的收敛速度明显提升(37.5%),表明从现有的老师模型那里继承知识比单独学习这些知识要有效得多。
如,当在40k步停止向“老师”学习后,验证 PPL 从4.60(LARGE)提升到4.28,几乎是基线 LARGE进行55k步自学习时的性能,节省了大约27.3%的计算成本。

验证PPL(Perplexity,困惑度)是用于评估语言模型性能的一种指标。在自然语言处理中,语言模型的目标是根据训练数据学习语言的概率分布,以便能够预测下一个词或字符。验证PPL通常用于衡量模型在未见过的、用于验证的数据上的表现。
在理解验证PPL之前,先来解释一下“困惑度”这个概念。在信息理论中,困惑度是一个表示平均不确定性或熵的概念。对于语言模型来说,困惑度是用来衡量模型对于给定文本序列的预测困难程度。低困惑度表示模型在验证数据上的预测表现较好,高困惑度则表示预测表现较差。
验证PPL是困惑度的一种度量方式。它通过计算在验证集上的困惑度来评估语言模型。在计算验证PPL时,模型会根据验证集中的文本序列进行预测,并用生成的概率分布来计算困惑度。具体来说,验证PPL是对模型在验证集上预测的概率进行乘积取倒数后得到的几何平均数。
数学表达式为:
PPL = exp(∑(-log P(w_i)) / N)
其中,P(w_i)是模型预测的第i个词的概率,N是验证集中词的总数。
验证PPL是一个常用的评估指标,较低的PPL通常意味着模型在验证数据上更加准确。在训练语言模型时,通常会调整模型的参数以尽量降低验证PPL,从而提高模型在生成文本时的质量和准确性。
第五页 下游任务评测
在8个GLUE任务上对比实验。
实验表明,在知识继承框架下训练的大模型在下游任务上显著超越传统方法。

GLUE: General Language Understanding Evaluation

第三章 基于参数复用的知识继承

(ACL 2022)
1.参数复用概述
插页 历史工作回顾–Net2Net
Net2Net的核心思路:用小模型初始化大模型,使得大模型不再需要从0开始训练,而是利用小模型的参数初始化,加快大模型收敛速度。

Net2Net: ACCELERATING LEARNING VIA KNOWLEDGE TRANSFER(ICLR 2016)
插页 Net2Net
当我们有一个小模型(teacher model)和一个大模型(student model)时,我们将参数矩阵进行扩展,并且保证原来的函数不变。网络中的每一层都可以视为由某个参数矩阵定义的函数,小模型到大模型对每层来说,就是将参数矩阵从m*n变成更大的M*N的过程,并且保证这个函数的输入输出不变。
如图所示,左右两侧的模型虽然中间的hidden state尺寸不一样,但是输入和输出是完全相同的,可以看成是尺寸更大的相同函数。

插页 历史工作回顾–StackingBERT
核心思路:先训练浅层的BERT,再通过堆叠的方式不断套娃,逐渐提升BERT深度。这样就不再需要直接训练一个大BERT,而是先训练浅层BERT,减小训练开销。
从图像中可以看出,低层的Attention和高层的Attention分布其实非常相似,表明不同层的注意力机制可能是非常相似的函数。

基于这个发现,作者认为我们可以将一个已经训练好的L层BERT,通过参数复制堆叠的方式,生成一个2L层的BERT。这样的好处在于,我们可以先训练一个浅层BERT,然后逐渐加深BERT的尺寸,提升训练的效率。
在每个热图中,第i行中第j个元素的颜色深度反映了从位置i到位置j的关注权重:颜色越深,位置i对位置j的关注越多。
注意力分布A帮助我们理解注意力函数:Aij反映了在生成输出时第i个键值条目相对于第j个查询的重要性
StackingBERT 通过分享顶层和底层的自注意层的权重来将浅层模型堆叠成一个深度模型,然后对所有参数进行微调。
插页 StackingBERT的核心算法
首先初始化一个浅层BERT,然后不断的进行训练、堆叠、再训练的过程,让BERT模型越来越深。


对于i ≤ L,构造的BERT的第i层和第(i + L)层具有训练的BERT的第i层的相同参数。
下标i表示循环次数,k表示总的堆叠次数。每次堆叠层数×2,所以k决定了从初始的L/2k层数逐步堆叠到最终的L层数需要的循环次数。
第一页 参数复用的可能性

研究者表明,不同大小的两个PLMs的注意力模式是相似的,意味着不同尺度的预训练模型可以共享相似的知识。
上面的是一个架构为{L=12,D=768}的BERTBASE模型的注意模式,下面的是一个架构为{L=12,D=512}的小BERT模型的注意模式。研究者发现,有大量的相似的注意模式在同一层的两个模型,表明重用参数的训练小PLM,以加快大型PLM的预训练的可能性。
2.进阶训练策略
- 深度递增
- 宽度递增
第一页 BERT

BERT整体框架包含pre-train和fine-tune两个阶段。pre-train阶段模型是在无标注的标签数据上进行训练,fine-tune阶段,BERT模型首先是被pre-train模型参数初始化,然后所有的参数会用下游的有标注的数据进行训练。
第二页 BERT

BERT是用了Transformer的encoder侧的网络,如上图的transformer的Encoder部分。
BERT模型分为24层和12层两种,其差别就是使用transformer encoder的层数的差异,BERT-base使用的是12层的Transformer Encoder结构,BERT-Large使用的是24层的Transformer Encoder结构。
第三页 BERT架构
BERT架构由一个嵌入层和多个Transformer层组成。
嵌入层(Embedding Layer):通过一个嵌入矩阵WE将句子当中的token映射到向量中。然后采用一个归一化层产生初始隐藏状态H0。
归一化定义:数据标准化(Normalization),也称为归一化,归一化就是将需要处理的数据在通过某种算法经过处理后,将其限定在需要的一定的范围内。
层归一化:通过计算在一个训练样本上某一层所有的神经元的均值和方差来对神经元进行归一化。
作用:加快网络的训练收敛速度、控制梯度爆炸和防止梯度消失
Transformer层:将隐藏状态通过多个Transformer层迭代处理:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gAsmPJRa-1692416550336)(C:\Users\24980\AppData\Roaming\Typora\typora-user-images\image-20230723161349429.png)]](http://img.e-com-net.com/image/info8/980bb3ae3a774f72967478eb0351d385.jpg)
L 是Transformer的层数,每个Transformer层包括多头注意(MHA)和前馈网络(FFN)。
第四页 多头注意力机制(MHA)
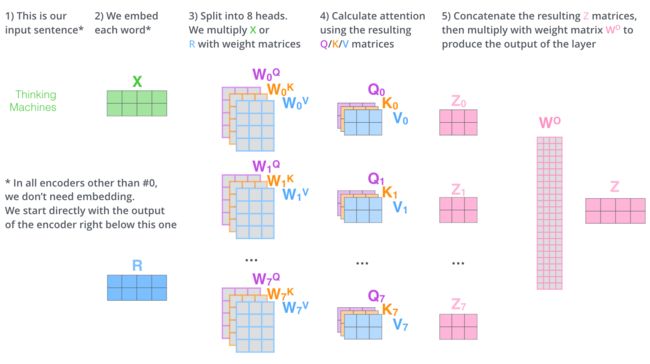
MHA由多个平行的自注意头组成。前一层的隐藏状态被馈送到每个头中,然后将所有头的输出相加以获得最终输出,如下所示:

前一层Hl-1的输出分别使用不同的权重WQl,i、WKl,i、WVl,i线性地投影到查询(Qi)、键(Ki)和值(Vi)。HHEADl,i指示通过第i个关注头部中的查询和键的缩放点积获得的上下文感知向量。a表示自注意头部的数量。dk是作为比例因子的头部尺寸。HMHAl是下一子模块FFN的输入。
第五页 前馈网络(FFN)
前馈网络由两个线性层和一个GeLU激活函数组成:

高斯误差线性单元激活函数在最近的 Transformer 模型(谷歌的 BERT 和 OpenAI 的 GPT-2)中得到了应用。GELU 的论文来自 2016 年,但直到最近才引起关注。这种激活函数的形式为:


第六页 层归一化
层归一化:通过计算在一个训练样本上某一层所有的神经元的均值和方差来对神经元进行归一化。
在MHA和FFN中都有层归一化,稳定了Transformer中的隐藏状态动态。

○表示逐元素乘法,μH和σH的统计量分别是计算出的隐藏状态H的均值和方差。
第七页 问题陈述
目标:通过转移现有预训练模型S(Ls,Ds)的知识加速目标模型T(Lt, Ds).
L表示层数,D表示隐藏层的宽度。
问题:(1)如何重用S的训练参数来对T进行有效的参数初始化
(2)如何有效地训练初始化的T,使得T具有更快的收敛速度
第八页 解决办法
通过横向模型增长+纵向模型增长,复用小模型的训练参数。
组成:(1)对于参数初始化,首先通过复制和堆叠现有较小PLM的参数扩展函数保持训练,称之为功能保留初始化(FPI)。
FPI确保初始化的大模型与小模型具有几乎相同的行为,从而使大模型为后续优化提供了一个良好的起点。
复制不同层的权重可以进一步加速大型模型的收敛,称之为高级知识初始化。(AKI)
虽然AKI的策略有些违反了函数保持的原则,但我们发现,经验上它会导致更快的收敛速度,并实现更高的训练效率。
(2)其次,使用一个两阶段的训练策略进一步加快训练过程。
第九页 横向模型增长

本质上,宽度方向的扩展可以被分解成一组矩阵(或向量)的扩展。矩阵展开通过两种操作将参数矩阵W ∈ R d w i n ∗ d w o u t R^{d^w~in*d^w~out} Rdw in∗dw out of S扩大到U ∈ R d u i n ∗ d u o u t R^{d^u~in*d^u~out} Rdu in∗du out of T:输入维度和输出维度扩展。
它先扩大输入尺寸,然后扩大输出尺寸。从神经元的角度来看,它在输入和输出中都添加了新的神经元(红色)。
第九页 横向模型增长–Function Preserving Initialization
FPI通过对小模型参数矩阵的扩展,生成适配大模型的参数矩阵。
原则:在参数矩阵扩展前后能保证原始的输出是不变的(即给定相同的输入{x1,x2},FPI确保初始化的目标模型具有与源模型相同的输出{y1,y2})。

中间这个图省略了中间过程,展现的是结果。
映射函数:

gin(i)表示U的第i列重用W的i列参数,gout(j)表示U的第j行重用W的第j行参数。
权重扩展可以表示为
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wNtJibk4-1692416550338)(C:\Users\24980\AppData\Roaming\Typora\typora-user-images\image-20230724104047416.png)]](http://img.e-com-net.com/image/info8/05b39ef61d0140f79e75913486cb4753.jpg)
输入维度扩展:

对应上一页PPT中的图进行解释,通过指示函数统计每一列的参数情况。
简单的说,对于扩展后的第一列参数,它需要按照指示函数进行统计,有两列的值相同,计数为2,那么第1列和第3列的值都变成原来的1/2。
输出维度扩展:

第一步和第二步分别根据gin映射函数和gout映射函数对参数矩阵的输入维数和输出维数进行扩展。FPI从神经元的角度出发,复制输入和输出神经元来扩展网络。在矩阵展开之后,我们可以进一步使用维数展开,以确保输出与原始输出相同。
f()代表均匀采样
第一步让输入维度din变成3,从前面两列的参数中均匀采样,比如这里采样到了第一列填到第三列。为了让下一层输出保持不变,需要把这两列的参数都设置为原来的一半。接下来需要在dout上进行扩展,这里直接复制h2一份,对应的参数矩阵把最后一行参数进行复制。经过上述操作,保证了最终模型的输出不变。
其中I(·)是指示符函数,并且Cgin(i)是gin(i)在gin的值中的计数,其用于重新缩放原始参数以保持函数保持属性。
第十页 模块中的扩展
嵌入层:

嵌入层只在输出维度进行扩展。
- 嵌入层的输入是离散的词元索引,其维度大小就是词表大小,是固定的,不需要扩展。
- FPI的目标是保持小模型和大模型的函数行为一致。嵌入层的输入不变,那么只需要确保输出向量的维度一致,模型行为就可以保持。
- 扩展输入维度不仅无法提高模型性能,反而会引入不必要的随机初始化参数,降低模型效果。
- 因此,对嵌入层权重WE采用输出维度扩展即可,既保证了函数行为的一致性,也避免引入过多随机性。
MHA:


MHA 通过宽度扩展,构建新的注意力头。
这个模块有三个限制:

1)嵌入层输出维度的扩展和MHA输入层的映射一致
2)MHA输出层扩展和WO矩阵的输入扩展的映射一致
3)MHA的输入层扩展和WO矩阵的输出扩展的映射一致
1)和2)用于维度约束,3)用于约束剩余连接
FFN:

与MHA模块相似,FFN模块也有三个限制:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CFhAV6dJ-1692416550339)(C:\Users\24980\AppData\Roaming\Typora\typora-user-images\image-20230801114917898.png)]](http://img.e-com-net.com/image/info8/a7cafcf78b04433ab93f053b2064e94b.jpg)
在层归一化中,参数扩展为:

在层归一化中,我们需要重新计算隐藏表示H的均值μ和方差σ。该参数的扩展不可避免地引起间隙,并防止目标模型严格遵循函数保持原则。然而,我们的经验发现,差距是如此之小,它几乎不会影响目标模型的初始化和收敛。因此,我们忽略这种差异。
实验结果表明,初始化的模型T实现了几乎相同的损失S,表明FPI成功地保留了小模型的知识时,执行参数扩展。
第十一页 横向模型增长–Advanced Knowledge Initialization
在进行参数扩展时不仅考虑当前层的参数,还会考虑下一层的参数。
以前的工作表明Transformer中的相邻层会学习到相同的函数,并且根据Net2Net这篇工作,打破对称性对模型收敛有一定好处。
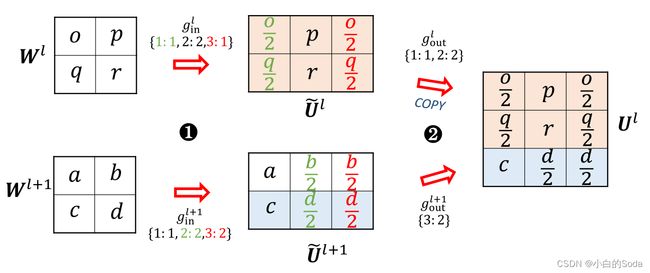
方法:在对当前层和下一层进行din扩展后,采样下一层的参数对当前层进行dout扩展。
虽然AKI方法和FPI中保证扩展前后输出不变的原则矛盾,但是作者通过实验表明AKI是可以提升收敛速度和模型效果的。
用公式表示:
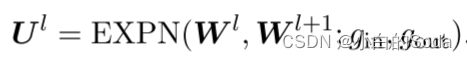
先进行输入维度扩展:

然后叠加扩展矩阵:

我们将上层信息聚合到一个新的矩阵中,用于两个直觉:(1)它打破了阻碍模型收敛的FPI对称性;(2)上层信息可以作为高层知识来指导模型更快地收敛。经验上,我们发现AKI方法优于FPI,而如果我们基于较低层(或低级知识)的矩阵构建新的矩阵,则性能更差。如何构造目标模型的最佳初始化与不同层的参数仍然是一个悬而未决的问题,我们把它作为未来的工作。
第十二页 模块中的扩展
嵌入层:只做输出扩展
MHA和FFN:通过上述公式进行扩展
第十三页 纵向模型增长
为了弥合深度差距,执行深度扩展以将模型深度增加到目标模型的深度。
采用了StackingBERT中的方法。

使用“or”,是考虑到实际使用时可以在两者中选择更合适的初始化方法,并不局限于AKI。
k ← 目标层数Lt除以源层数Ls,向下取整
Ls·t代表每次堆叠之后,Tt有多少层,堆叠一次就是T1的1倍,堆叠两次就是T1层数的两倍。
第十四页 两阶段的预训练
为了减小训练开销,本文使用两阶段的训练方法:
(1)首先以随机方式训练目标模型的子结构,以使完整模型以低成本收敛。在每个优化步骤中,随机采样一个子结构,只更新其顶部Transformer层和共享的分类头。
这些子结构由目标模型的底层Transformer层构建,并共享一个分类头。
(2)在子结构训练之后,进一步执行传统的全模型训练。
相比于直接大模型整体训练,这种方法可以降低开销,能够让每个substructure先达到一个接近收敛的状态,提升后面模型整体训练的收敛速度。

采用两阶段的预训练方法,通常称为“两阶段预训练”或“分阶段预训练”,是为了在大模型的训练过程中更好地平衡计算资源和模型性能之间的权衡。这种方法最初由OpenAI在2019年的GPT-2模型中引入,并在后续的一些大型模型中得到了广泛应用。
在传统的训练方式中,直接对整个大模型进行训练可能会面临以下问题:
- 计算资源限制:大型模型的训练通常需要大量的计算资源,包括GPU或TPU的加速,以及大量的内存和存储。这对于许多研究人员或机构来说是一个挑战。
- 易失性:训练大模型很可能需要较长的时间,可能会面临中断、故障等问题。在这种情况下,整个训练过程需要重新开始,浪费了之前已经训练的模型。
- 超参数调整困难:大型模型通常有许多超参数,对其进行优化和调整需要大量的计算资源和时间。直接对整个模型进行训练,超参数调整变得更加困难。
为了解决上述问题,采用两阶段的预训练方法可以有效地应对。具体做法如下:
- 第一阶段(子结构预训练):在这一阶段,模型的不同子结构被随机采样,只对这些子结构进行预训练。这些子结构可以是某些层、某些模块,甚至可以是单个神经元。这种子结构预训练的方式可以大大减少训练所需的计算资源和时间。
- 第二阶段(整体预训练):在第一阶段结束后,剩下的部分(通常是整个模型)会以传统的方式进行预训练。在这个阶段,可以继续调整超参数,并在更大的训练集上进行更全面的训练,以进一步提高模型性能。
通过两阶段的预训练方法,研究人员可以更容易地管理训练过程,更好地利用计算资源,并且可以在更短的时间内获得一个部分训练的模型。这种方法在大型模型的训练中被广泛使用,并且在很多情况下表现出了较好的性能。
第十五页 实验结果
在收敛速度上,bert2BERT的收敛速度要快得多。
在训练开销上,与传统的 BERTBASE 的预训练方法相比,bert2BERT的两阶段训练方法可以节省45.2%的计算资源。


使用了FLOPs(每秒浮点运算次数)作为横轴。使用FLOPs具有以下含义:
- FLOPs可以反映模型的计算量。不同模型的参数量和层数不同,计算量也不同。
- 使用FLOPs而不是其他指标(如步数),可以更客观公平地反映不同模型训练Required的实际计算量。
- 横轴使用FLOPs,可以直接比较不同训练方法在相同计算量下的效果优劣。
- 论文使用FLOPs,主要是为了比较基于知识继承的训练方法,相比正常训练,可以节省的计算量。
- 如图1所示,达到相同适应度,基于知识继承的训练FLOPs明显少于正常训练。
- 表2也显示,在相同FLOPs下,知识继承效果优于正常训练。
综上,这篇论文使用FLOPs而不是其他指标作为横轴,主要是为了更客观地比较不同训练方法对计算量的节省,以突出知识继承的优势。这也使得不同模型之间的对比更公平合理。
本文提出一种基于小模型加快大模型训练方式,虽然方法基本都是基于前人稍微改进点,目前也仅仅在Bert和GPT上进行实验,不过有一定意义,如果组合上那个使用小模型上对大模型进行调参的方法,以后都可以在小模型进行实验,最后一步再到大模型进行展示效果,会节省大量资源和时间,不过本文参数初始化和两阶段方面证明较少,虽然有效果,但应该仍有很大空间进行改进。而且函数映射的方式进行模型参数扩展过于繁琐,可扩展性差。
第四章 两种方法的对比与分析
1.优缺点对比
知识继承算法可以很好地加速模型收敛,提升模型性能
基于知识蒸馏的方法:
+ 更加灵活,对模型架构要求很低,支持多对一知识继承,不需要得到小模型的参数
- 性能提升不及参数复用
基于参数复用的方法:
+ 更好的效果
- 约束较高(需要得到模型参数),应用场景受限
论文详细实验结果
第一篇 知识蒸馏
Q1:知识继承如何促进大模型训练?
为了不失一般性,作者主要关注具有代表性的MLM任务。
选取RoBERTaBASE作为教师网络,RoBERTaLARGE作为学生网络。
作者还使用GPT对自回归语言建模进行了实验。
自回归语言建模:们通常指的是一类用于自然语言处理和生成文本的机器学习模型。它的目标是根据先前的文本序列来预测下一个词或字符。模型根据历史上看到的文本序列中的单词或字符来进行预测,因此称为“自回归”,因为它在生成序列的过程中依赖于自身的历史。
总体结果

通过上图可以看出在KI框架下模型训练收敛更快。也就是说,如果要实现相同水平的困惑度,KI 需要更少的计算消耗。
具体而言,在MS的指导下(其验证PPL为4.18),与基线(LARGE)3.58相比,BASE → LARGE在预训练结束时达到了3.41的验证PPL。BASE → LARGE在第40k步停止向老师学习后,验证PPL从4.60(LARGE)提升到4.28,几乎是基线LARGE进行55k步自学习时的性能,从而节省了大约27.3%的计算成本。

在KI下训练的ML在每个步骤的下游任务上都比基线实现了更好的性能。KI需要较少的预训练步骤,在微调后获得高分。
遗传率的影响
作者采用三种方式:
- Linear(线性衰减):逐渐鼓励 MLarge自己探索知识。
- Heviside:最初只向老师学习,到第35 k步时转变为纯自学
- Constant(常数):使用恒定比率(1:1)贯穿整个训练过程的LSELF和LKI之间的关系。
我们可以从图b中得出结论:(1)首先需要退火。Linear的验证PPL曲线收敛最快,而Heviside在ML停止从教师学习后趋于增加,这表明,由于从教师学习和自学习之间的差异,首先退火是必要的,以便性能不会在过渡点(第35k步)衰减。(2)在ML超过MS之后,来自老师的监督是多余的。尽管Constant在开始时表现良好,但其PPL逐渐变得比其他两个策略更差。这表明ML已经超过MS之后,它将受到来自MS的后续指导的阻碍。

模拟退火算法是一种优化算法,通过随机采样和接受劣质解的策略,逐渐收敛到全局最优解或接近最优解的解。这种算法可以应用于各种问题,例如组合优化、函数优化、机器学习模型参数调整等。
使用Top-K Logits节省存储空间
为KI反复加载教师MS是麻烦的,并且替代方法是预先计算并一次性离线保存MS的预测。我们表明,使用top-K logits的信息可以减少内存占用,而不会降低太多性能。具体地,我们仅保存PS(xj; τ)之后是重新归一化,而不是所有令牌上的完全分布。对于RoBERTa来说,PS(xj; τ)是由其词汇量大小决定的,大约在50,000左右。因此,我们在{10,50,100,1000}中改变K以查看其在图c中的效果,从中我们观察到:top-K logit包含绝大多数信息。选择相对小的K(例如,10)对于从老师那里继承知识来说,已经足够好了,而不会有太多的性能下降。先前的工作还表明了KD和标签平滑之间的关系,然而,我们在附录F中表明,KI的改进并不是因为受益于优化平滑目标,KI会带来正则化。
在GPT上的实验
为了证明KI是与模型无关的,我们对自回归语言建模进行实验并选择GPT架构,其具有总共{73 M,124 M,209 M,354 M,773 M,1B}参数的增长大小。详细的架构如表6所示。所有的教师模型都经过了62.5k步的预训练,批量大小为2048。如图2(a)所示,在我们的KI框架下训练较大的GPT比自学习基线收敛得更快,这表明KI对特定的预训练目标和PLM架构是无关的。

Q2:知识可以代代继承吗?
作者实验了三代RoBERTa之间的知识继承,模型大小增长了大约1.7倍:G1(BASE,125M),G2(BASE_PLUS,211M),G3 (LARGE, 355M)。
所有的模型都是在同一个语料库上从头开始训练125 k步,批量大小为2048。我们比较了(1)每一代人的自我学习(表示为G1、G2和G3),(2)两代KI(表示为G1-G2、G1-G3和G2-G3),以及(3)KI三代以上(表示为G1 → G2 → G3),其中G2首先从G1继承知识,通过额外的自我探索对其进行精炼,并将其知识传递给G3。结果绘制在图2(B)中。比较G2和G1 → G2,G3和G1 → G3,或G3和G2 → G3的性能,我们可以再次证明KI优于自我训练,如前所述。通过比较G1 → G3和G1 → G2 → G3,或G2 → G3和G1 → G2 → G3的性能,发现G3的性能得益于G1和G2的参与,这意味着知识可以通过更多代的参与来积累。

Q3:Ms的预训练设置如何影响知识继承?
现有的PLM通常在完全不同的设置下进行训练,并且不清楚这些不同的设置将如何影响KI的性能。形式上,我们有一系列训练有素的较小PLM:
![]()
每个已经在DS :

进行了优化。考虑到MS中的PLM由不同的模型架构组成,在各种规模和领域的不同语料库上以任意策略进行预训练,因此它们所掌握的知识也是多种多样的。此外,ML的预训练数据DL还可以由来自多个源的大量异构语料库组成,即,

。由于DL和DS之间的差异,MS可能需要在其预训练期间传递其关于看不见的实例的知识。理想情况下,我们希望MS教授它擅长的课程。因此,为每一个组合

选择最合适的老师是至关重要的。为此,我们进行了彻底的实验,以分析几个代表性因素的影响:模型架构、预训练数据、MS的预训练步骤(附录A.2)和批次大小(附录A.3)
模型架构的影响
大型PLM通常会更快地收敛并实现较低的PPL,从而成为更称职的教师。我们试验了两种广泛选择的架构变体,即,深度(层数)和宽度(隐藏大小),以探索MS模型架构的影响。我们选择BASE(12层,768隐藏大小)作为ML的体系结构,并选择MS的体系结构在深度或宽度上不同于ML。具体来说,对于MS,我们分别改变{4,6,8,10}中的深度和{384,480,576,672}中的宽度,并在与ML相同的设置下预训练MS。每个教师模型的PPL曲线如附录A.7所示,从中我们观察到,具有更多参数的更深/更宽的教师收敛得更快,并实现更低的PPL。之后,我们利用这些教师模型在KI下预训练ML。如图2(c)和附录A.4所示,选择更深/更宽的教师加速了ML的收敛,证明了从知识更丰富的教师那里学习的好处。由于PLM的性能与模型形状弱相关,但与模型尺寸高度相关(Li等人,2020 b),如果其他设置保持相同,选择较大的老师总是一个更好的策略。在实验中,我们还发现经验,从教师的最佳持续时间是更长的较大的教师,这意味着它需要更多的时间来学习一个更有知识的教师。

预训练数据的影响
在之前的实验中,我们假设ML在与MS相同的语料库上进行了预训练,即,DL = DS。然而,在现实世界的场景中,由于三个主要因素,ML和MS使用的预训练语料库可能会发生不匹配:(1)数据大小。当训练更大的模型时,预训练语料库通常被扩大以提高下游性能,(2)数据域。PLM在来自各种源的异构语料库(例如,新闻文章、文学作品等),也就是说,PDS != PDL。各领域所包含的知识不同,会影响PLM在下游任务中的泛化能力;(3)数据隐私。即使DS和DL的大小和域都被确保是相同的,由于隐私问题,可能难以检索MS使用的预训练语料库,在极端情况下:DL ∩ DS =φ。DS和DL之间的差距可能会阻碍MS的成功知识转移。因此,我们设计实验来分析这些因素的影响,得出以下三个结论:
- PLM可以从小到大地映射域内数据。
- 在相似域上继承可提高性能。
- 如果确保了同一个域,数据隐私就不那么重要了。
Q4:知识继承如何有益于领域适应?
作者进一步扩展了KI,并证明PLM的领域适应可以从继承现有领域专家的知识中受益。
具体地,我们不是从头开始训练大型PLM,这是之前使用的设置,而是专注于将BASEWB(已经在WB域上良好训练了125 k步)适配到两个目标域,即,来自S2 ORC的计算机科学(CS)和生物医学(BIO)论文。附录D列出了三个领域的接近度(词汇重叠)。我们假设存在两个领域专家,即,MEDIUMS和MEDIUMBIO。每个模型已经在CS / BIO域上训练了125 k步。注意,由于模型参数较少,它们的训练计算量远远小于BASEWB。因此,MEDIUMCS或MEDIUMBIO在WB域中不与BASEWB匹配,但在CS / BIO域中具有更丰富的知识。为了进行评估,我们比较了(1)目标域上的验证PPL和(2)下游任务的性能(测试F1),即ACL-ARC(Jurgens等人,2018)用于CS结构域和CHEMPROT用于BIO域。
作者比较了两种域适应策略:(1)只在目标领域进行自我学习;(2)从训练有素的领域教师那里继承知识。
- KI的训练效率更高。与自学习相比,从领域教师继承知识实现了较低的最终PPL和特定领域的下游任务中的性能提高,这表明,对于领域适应,KI是更有效的训练,使已经训练的大型PLM可以吸收更多的知识,从新的领域与相同的培训预算。
- KI数据效率更高。当可用于适应的特定领域数据较少时,KI和SL之间的PPL差距进一步扩大,这意味着KI的数据效率更高,特别是在低资源环境下,领域数据稀缺。换句话说,仅提供一小部分特定领域的数据就足以在KI下获得令人满意的自适应性能,而自学习在一定程度上表现出过拟合。
- 大型PLM可以同时吸收多个领域的知识,从而变得无所不能。从表3中,我们观察到BASEWB在由两名教师同时授课后在这两个领域都取得了改善的表现。KI显示出优于自学习的优势。然而,同时学习更容易过度拟合训练数据,并且其在任一域上的性能都无法与一次只学习一个域相匹配。
总结展望
作者提出了一个通用的知识继承(KI)的框架,利用以前训练的PLM培训更大的。我们进行了充分的实证研究,以证明其可行性。此外,我们表明,KI可以很好地支持知识转移一系列规模不断扩大的PLM。我们还综合分析了各种可能影响KI绩效的教师模型的培训前设置,结果为如何选择最适合KI的教师PLM提供了依据。最后,我们延长KI,并表明,在领域适应,已经训练的大型PLM可以受益于较小的领域教师。总的来说,我们提供了一个有希望的方向,以分享和交流不同模型学到的知识,并不断提升他们的性能。
作者接下来的目标是探索以下方向:(1)KI的效率,即,给定有限的计算预算和预训练语料库,如何更有效地从教师模型中吸收知识。潜在的解决方案包括对教师模型的预测进行降噪,并利用来自教师的更多信息。如何为KI选择最具代表性的数据点也是一个有趣的话题;(2)KI在不同环境下的有效性,即,如果教师和学生在不同的词汇、语言、预培训目标和模式上接受预培训,知识基础设施如何应用。
第二篇 参数复用
实验设置
训练设置
使用英语维基百科和多伦多图书语料库的连接我们使用英语维基百科和多伦多图书语料库的连接(Zhu et al.2015年)作为预训练数据。
预训练的设置为:峰值学习速率为1 e-4,预热步长为10 k,训练时段为E=40,批量大小为512,子模型训练时段为Eb=5,层数为lb=3。除非另有说明,所有方法包括bert 2BERT和基线都使用相同的预训练设置进行公平比较。在bert 2BERT的设置中,目标模型具有T(12,768)的BERTBASE体系结构,并且评估了源模型S(12,512)和S(6,512)的两种体系结构。
微调设置
对于评估,我们使用来自GLUE基准的任务(Wang等人,2019 a)和SQuADvl. l(Rajpurkar等人,2016年)。我们报告了SQuADv1.1的F1、CoLA的马修斯相关性(Mcc)(Warstadt等人,2019年)和其他任务的准确度(Acc)。对于GLUE微调,我们将批量大小设置为32,从{5e-6,1 e-5,2 e-5,3e-5}中选择学习率,从{4,5,10}中选择epoch。对于SQuADv1.1微调,我们将批处理大小设置为16,学习率设置为3e-5,训练epoch的数量设置为4。
在SQuAD v1.1中,F1指标(F1 score)是评估模型性能的一种方法,它由两个子指标组成:精确度(Precision)和召回率(Recall)。
- 精确度(Precision):精确度表示模型预测的答案中有多少是正确的。它是正确预测的答案数目与模型总共预测的答案数目的比值。
- 召回率(Recall):召回率表示模型能够正确找到的答案占总共正确答案的比例。它是正确预测的答案数目与实际正确答案数目的比值。
F1是精确度和召回率的调和平均数,它在评估模型性能时考虑了两者的平衡。F1计算方式如下:
F1 = 2 * (Precision * Recall) / (Precision + Recall)
“马修斯相关性”(Matthews Correlation Coefficient,简称MCC)是衡量模型在CoLA任务上性能的一种指标。
马修斯相关性是一种用于衡量二元分类问题性能的指标,它考虑了四个分类结果:真正例(True Positives,TP)、真反例(True Negatives,TN)、假正例(False Positives,FP)和假反例(False Negatives,FN)。它的计算方式如下:
MCC = (TP * TN - FP * FN) / sqrt((TP + FP) * (TP + FN) * (TN + FP) * (TN + FN))
马修斯相关性是评估模型性能的一个重要指标。较高的MCC值表示模型在判断句子的可接受性上有更好的性能,较低的MCC值则表示性能较差。
基线
首先引入一个名为DirectCopy的朴素bert2BERT基线,它直接将小模型复制到目标模型,并随机初始化未填充的参数。StackBERT(Gong等人,2019)和MSLT(Yang等人,2020年)也作为基准。两人都是以循序渐进的方式进行训练的。
按照原始设置,对于StackBERT,我们首先训练3层BERT 5个epoch,将其堆叠两次成为6层BERT,然后训练7个epoch。在最后一步中,我们将6层模型堆叠到BERTBASE中,并进一步使用28个epoch对其进行训练。
对于MSLT,我们首先执行4阶段训练。在每个阶段中,我们将已经训练好的模型的前3层添加到模型的顶部,然后通过部分更新前3层来预训练新模型。部分训练过程的每个阶段具有8个时期。最后,我们进一步执行20个全模型训练时期‡,以实现与从头开始训练的BERTBASE相同的损失。使用与bert2BERT相同的优化器、训练步骤和预热步骤来训练基线。
stackBERT 和 MSLT都是递进式训练大模型的方法
结果和分析
(1)两种渐进式训练方法都达到了10%以上的节省率,StackBERT优于MSLT;(2)DirectCopy只节省了13.8%的计算成本,这表明这种直接将源模型的训练参数复制到目标模型的幼稚方法是无效的;(3)我们提出的方法,FPI和AKI,取得了比基线更好的性能。虽然AKI不遵循函数保持性,在训练开始时的损失比FPI和DirectCopy算法大,但AKI算法利用了先进的知识,获得了更快的收敛速度;(4)通过对AKI初始化的目标模型进行两阶段预训练,可以节省45.2%的计算量。请注意,源模型的总参数是目标模型的总参数的一半(54 M与110M)。图1中bert 2BERT的损失在子模型训练阶段很高,因为它代表了所有子模型的平均损失。我们还比较了由DirectCopy,FPI和AKI初始化的目标模型的注意模式。注意力模式及其讨论见附录D。
在小的源模型上进行实验
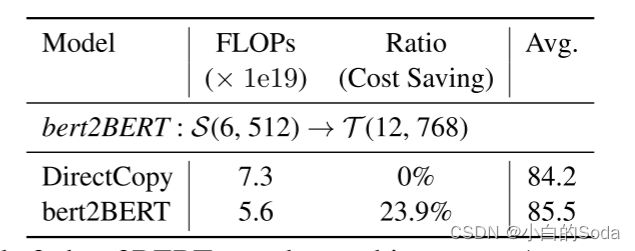
作者还在一个不同的设置上评估bert2BERT,其中源模型S(6,512)显著小于目标模型(35M vs 100M)。结果见表3,损失曲线见附录B。我们观察到DirectCopy与原始预训练相比没有实现效率提高,这表明源模型和目标模型之间的显著大小差距大大降低了DirectCopy方法的优势。与DirectCopy相比,我们提出的方法将计算成本降低了23.9%,这再次证明了bert2BERT的有效性。我们鼓励未来的工作探索源模型的大小和架构对bert2BERT的影响。
子模型训练epoch的影响
预训练包括两个阶段:子模型训练和全模型训练。在这里,我们通过在Eb={0,5,10,20}的不同设置上执行bert 2BERT来研究子模型训练时期的数量的影响。结果见表4,损失曲线见附录C。我们观察到,当epoch数设置为5时,我们的方法实现了最佳效率,而更大或更小的epoch数将带来负面影响。我们推测,少一点的子模型训练epoch可以为全模型预训练建立一个稳定的状态,以达到快速的收敛速度,但随着子模型训练epoch数的增加,从源模型获得的知识将被破坏。

在GPT上的应用
作者比较了原始的预训练方法和bert2BERT,结果如表5和图6所示。我们观察到,所提出的方法节省了47%的GPT预训练的计算成本,表现出类似的趋势BERT预训练。虽然GPT和BERT具有不同的架构(例如,LN后和LN前(Xiong等,2020)),并使用不同的任务进行预训练,bert2BERT在这两个模型上都节省了大量的训练成本,这表明所提出的方法是通用的,对不同类型的PLM都是有效的。

