2023年 Java 面试八股文(25w字)
目录
- 一.Java 基础面试题
-
- 1.Java概述
-
- Java语言有哪些特点?
- Java和C++有什么关系,它们有什么区别?
- JVM、JRE和JDK的关系是什么?
- **什么是字节码?**
- 采用字节码的好处是什么?
- Oracle JDK 和 OpenJDK 的区别是什么?
- 2.基础语法
-
- Java有哪些数据类型?
- switch 是否能作用在 byte 上,是否能作用在 long 上,是否能作用在 String 上?
- **访问修饰符public、private、protected、以及不写(默认)时的区别**?
- break ,continue ,return 的区别及作用?
- 3.关键字
-
- final、finally、finalize的区别?
- 为什么要用static关键字?
- ”static”关键字是什么意思?Java中是否可以覆盖(override)一个private或者是static的方法?
- 是否可以在static环境中访问非static变量?
- static静态方法能不能引用非静态资源?
- static静态方法里面能不能引用静态资源?
- 非静态方法里面能不能引用静态资源?
- java静态变量、代码块、和静态方法的执行顺序是什么?
- 4.面向对象
-
- 面向对象和面向过程的区别?
- 讲讲面向对象三大特性
- Java语言是如何实现多态的?
- 重载(Overload)和重写(Override)的区别是什么?
- 重载的方法能否根据返回值类型进行区分?
- 构造器(constructor)是否可被重写(override)?
- 抽象类和接口的区别是什么?
- 抽象类能使用 final 修饰吗?
- java 创建对象有哪几种方式?
- 什么是不可变对象?好处是什么?
- 能否创建一个包含可变对象的不可变对象?
- 值传递和引用传递的区别的什么?为什么说Java中只有值传递?
- 5.对象相等判断
-
- == 和 equals 区别是什么?
- **介绍下hashCode()?**
- **为什么要有 hashCode?**
- hashCode(),equals()两种方法是什么关系?
- 为什么重写 equals 方法必须重写 hashcode 方法 ?
- String,StringBuffer, StringBuilder 的区别是什么?
- String为什么要设计成不可变的?
- 6.String相关
-
- 字符型常量和字符串常量的区别?
- 什么是字符串常量池?
- String str="aaa"与 String str=new String("aaa")一样吗?`new String(“aaa”);`创建了几个字符串对象?
- String 是最基本的数据类型吗?
- String有哪些特性?
- 在使用 HashMap 的时候,用 String 做 key 有什么好处?
- 7.包装类型
-
- 包装类型是什么?基本类型和包装类型有什么区别?
- 解释一下自动装箱和自动拆箱?
- int 和 Integer 有什么区别?
- 两个new生成的Integer变量的对比
- Integer变量和int变量的对比
- 非new生成的Integer变量和new Integer()生成变量的对比
- 两个非new生成的Integer对象的对比
- 8.反射
-
- 什么是反射?
- 反射机制的优缺点有哪些?
- 如何获取反射中的Class对象?
- Java反射API有几类?
- 反射使用的步骤?
- 为什么引入反射概念?反射机制的应用有哪些?
- 反射机制的原理是什么?
- 9.泛型
-
- Java中的泛型是什么 ?
- 使用泛型的好处是什么?
- Java泛型的原理是什么 ? 什么是类型擦除 ?
- 什么是泛型中的限定通配符和非限定通配符 ?
- List和List 之间有什么区别 ?
- 可以把List`
`传递给一个接受List` - Array中可以用泛型吗?
- 判断`ArrayList
`与`ArrayList `是否相等?
- 10.序列化
-
- Java序列化与反序列化是什么?
- 为什么需要序列化与反序列化?
- 序列化实现的方式有哪些?
-
- **Serializable**接口
- **Externalizable**接口
- 两种序列化的对比
- 什么是serialVersionUID?
- 为什么还要显示指定serialVersionUID的值?
- serialVersionUID什么时候修改?
- Java 序列化中如果有些字段不想进行序列化,怎么办?
- 静态变量会被序列化吗?
- 11.异常
-
- Error 和 Exception 区别是什么?
- 非受检查异常(运行时异常)和受检查异常(一般异常)区别是什么?
- throw 和 throws 的区别是什么?
- NoClassDefFoundError 和 ClassNotFoundException 区别?
- Java常见异常有哪些?
- try-catch-finally 中哪个部分可以省略?
- try-catch-finally 中,如果 catch 中 return 了,finally 还会执行吗?
- JVM 是如何处理异常的?
- 12.IO
-
- Java的IO 流分为几种?
- 字节流如何转为字符流?
- 字符流与字节流的区别?
- BIO、NIO、AIO的区别?
- Java IO都有哪些设计模式?
- 二.集合
-
- 1. 常见的集合有哪些?
- 2. 线程安全的集合有哪些?线程不安全的呢?
- 3. Arraylist与 LinkedList 异同点?
- 4. ArrayList 与 Vector 区别?
- 5. 说一说ArrayList 的扩容机制?
- 6. Array 和 ArrayList 有什么区别?什么时候该应 Array 而不是 ArrayList 呢?
- 7. HashMap的底层数据结构是什么?
- 8. 解决hash冲突的办法有哪些?HashMap用的哪种?
- 9. 为什么在解决 hash 冲突的时候,不直接用红黑树?而选择先用链表,再转红黑树?
- 10. HashMap默认加载因子是多少?为什么是 0.75,不是 0.6 或者 0.8 ?
- 11. HashMap 中 key 的存储索引是怎么计算的?
- 12. HashMap 的put方法流程?
- 13. HashMap 的扩容方式?
- 14. 一般用什么作为HashMap的key?
- 15. HashMap为什么线程不安全?
- 16. ConcurrentHashMap 的实现原理是什么?
- 17. ConcurrentHashMap 的 put 方法执行逻辑是什么?
- 18. ConcurrentHashMap 的 get 方法是否要加锁,为什么?
- 19. get方法不需要加锁与volatile修饰的哈希桶有关吗?
- 20. ConcurrentHashMap 不支持 key 或者 value 为 null 的原因?
- 21. ConcurrentHashMap 的并发度是多少?
- 22. ConcurrentHashMap 迭代器是强一致性还是弱一致性?
- 23. JDK1.7与JDK1.8 中ConcurrentHashMap 的区别?
- 24. ConcurrentHashMap 和Hashtable的效率哪个更高?为什么?
- 25. 说一下Hashtable的锁机制 ?
- 26. 多线程下安全的操作 map还有其他方法吗?
- 27. HashSet 和 HashMap 区别?
- 28. Collection框架中实现比较要怎么做?
- 29. Iterator 和 ListIterator 有什么区别?
- 30. 讲一讲快速失败(fail-fast)和安全失败(fail-safe)
- 巨人的肩膀
- 三.MySql
-
- 基础
- 1. 数据库的三范式是什么?
- 2. MySQL 支持哪些存储引擎?
- 3. 超键、候选键、主键、外键分别是什么?
- 4. SQL 约束有哪几种?
- 5. MySQL 中的 varchar 和 char 有什么区别?
- 6. MySQL中 in 和 exists 区别
- 7. drop、delete与truncate的区别
- 8. 什么是存储过程?有哪些优缺点?
- 9. MySQL 执行查询的过程
- 事务
- 1. 什么是数据库事务?
- 2. 介绍一下事务具有的四个特征
- 3. 说一下MySQL 的四种隔离级别
- 4. 什么是脏读?幻读?不可重复读?
- 5. 事务的实现原理
- 6. MySQL事务日志介绍下?
-
- redo log
- undo log
- 7. 什么是MySQL的 binlog?
- **8. 在事务中可以混合使用存储引擎吗?**
- 9. MySQL中是如何实现事务隔离的?
- 10. 什么是 MVCC?
- 11. MVCC 的实现原理
- 锁
- 1. 为什么要加锁?
- 2. 按照锁的粒度分数据库锁有哪些?
- 3. 从锁的类别上分MySQL都有哪些锁呢?
- 4. 数据库的乐观锁和悲观锁是什么?怎么实现的?
- 5. InnoDB引擎的行锁是怎么实现的?
- 6. 什么是死锁?怎么解决?
- 7. 隔离级别与锁的关系
- 8. 优化锁方面的意见?
- 分库分表
- 1. 为什么要分库分表?
- 2. 用过哪些分库分表中间件?不同的分库分表中间件都有什么优点和缺点?
-
-
- cobar
- TDDL
- atlas
- sharding-jdbc
- mycat
-
- 3. 如何对数据库如何进行垂直拆分或水平拆分的?
- 读写分离、主从同步(复制)
- 1. 什么是MySQL主从同步?
- 2. MySQL主从同步的目的?为什么要做主从同步?
- 3. 如何实现MySQL的读写分离?
- 4. MySQL主从复制流程和原理?
- 5. MySQL主从同步延时问题如何解决?
- 优化
- 1. 如何定位及优化SQL语句的性能问题?
- 2. 大表数据查询,怎么优化
- 3. 超大分页怎么处理?
- 4. 统计过慢查询吗?对慢查询都怎么优化过?
- 5. 如何优化查询过程中的数据访问
- 6. 如何优化关联查询
- 7. 数据库结构优化
- 8. MySQL数据库cpu飙升到500%的话他怎么处理?
- 9. 大表怎么优化?
- MySql索引
- 1. 索引是什么?
- 2. 索引有哪些优缺点?
- 3. MySQL有哪几种索引类型?
- 4. 说一说索引的底层实现?
- 5. 为什么索引结构默认使用B+Tree,而不是B-Tree,Hash,二叉树,红黑树?
- 6. 讲一讲聚簇索引与非聚簇索引?
- 7. 非聚簇索引一定会回表查询吗?
- 8. 联合索引是什么?为什么需要注意联合索引中的顺序?
- 9. 讲一讲MySQL的最左前缀原则?
- 10. 讲一讲前缀索引?
- 11. 了解索引下推吗?
- 12. 怎么查看MySQL语句有没有用到索引?
- 13. 为什么官方建议使用自增长主键作为索引?
- 14. 如何创建索引?
- 15. 创建索引时需要注意什么?
- 16. 建索引的原则有哪些?
- 17. 使用索引查询一定能提高查询的性能吗?
- 18. 什么情况下不走索引(索引失效)?
-
-
-
- 1、使用!= 或者 <> 导致索引失效
- 2、类型不一致导致的索引失效
- 3、函数导致的索引失效
- 4、运算符导致的索引失效
- 5、OR引起的索引失效
-
-
- 四.Spring
-
- 1. 使用Spring框架的好处是什么?
- 2. 什么是 Spring IOC 容器?
- 3. 什么是依赖注入?可以通过多少种方式完成依赖注入?
- 4. 区分 BeanFactory 和 ApplicationContext?
- 5. 区分构造函数注入和 setter 注入
- 6. spring 提供了哪些配置方式?
- 7. Spring 中的 bean 的作用域有哪些?
- 8. 如何理解IoC和DI?
- 9. 将一个类声明为Spring的 bean 的注解有哪些?
- 10. spring 支持几种 bean scope?
- 11. Spring 中的 bean 生命周期?
-
- 创建过程:
- 销毁过程:
- 总结
- 12. 什么是 spring 的内部 bean?
- 13. 什么是 spring 装配?
- 14. 自动装配有什么局限?
- 15. Spring中出现同名bean怎么办?
- 16. Spring 怎么解决循环依赖问题?
- 17. Spring 中的单例 bean 的线程安全问题?
- 18. 什么是 AOP?
- 19. AOP 有哪些实现方式?
- 20. Spring AOP and AspectJ AOP 有什么区别?
- 21. Spring 框架中用到了哪些设计模式?
- 22. Spring 事务实现方式有哪些?
- 23. Spring框架的事务管理有哪些优点?
- 24. spring事务定义的传播规则
- 25. SpringMVC 工作原理了解吗?
- 26. 简单介绍 Spring MVC 的核心组件
- 27. @Controller 注解有什么用?
- 28. @RequestMapping 注解有什么用?
- 29. @RestController 和 @Controller 有什么区别?
- 30. @RequestMapping 和 @GetMapping 注解的不同之处在哪里?
- 31. @RequestParam 和 @PathVariable 两个注解的区别
- 32. 返回 JSON 格式使用什么注解?
- 33. 什么是springmvc拦截器以及如何使用它?
- 34. Spring MVC 和 Struts2 的异同?
- 35. REST 代表着什么?
- 36. 什么是安全的 REST 操作?
- 37. REST API 是无状态的吗?
- 38. REST安全吗? 你能做什么来保护它?
- 39. 为什么要用SpringBoot?
- 40. Spring Boot中如何实现对不同环境的属性配置文件的支持?
- 41. Spring Boot 的核心注解是哪个?它主要由哪几个注解组成的?
- 42. 你如何理解 Spring Boot 中的 Starters?
- 43. Spring Boot Starter 的工作原理是什么?
- 44. 保护 Spring Boot 应用有哪些方法?
- 45. Spring 、Spring Boot 和 Spring Cloud 的关系?
- 参考
- 五.MyBatis
-
- 1. MyBatis是什么?
- 2. Mybaits的优缺点
- 3. 为什么说Mybatis是半自动ORM映射工具?它与全自动的区别在哪里?
- 4. Hibernate 和 MyBatis 的区别
- 5. JDBC编程有哪些不足之处,MyBatis是如何解决这些问题的?
- 6. MyBatis编程步骤是什么样的?
- 7. MyBatis与Hibernate有哪些不同?
- 8. Mybaits 的优点:
- 9. MyBatis 框架的缺点:
- 10. #{}和${}的区别?
- 11. 通常一个Xml映射文件,都会写一个Dao接口与之对应,那么这个Dao接口的工作原理是什么?Dao接口里的方法、参数不同时,方法能重载吗?
- 12. 在Mapper中如何传递多个参数?
- 13. Mybatis动态sql有什么用?执行原理是什么?有哪些动态sql?
- 14. xml映射文件中,不同的xml映射文件id是否可以重复?
- 15. Mybatis实现一对一有几种方式?具体是怎么操作的?
- 16. Mybatis实现一对多有几种方式?具体是怎么操作的?
- 17. Mybatis的一级、二级缓存
- 18. 使用MyBatis的Mapper接口调用时有哪些要求?
- 19. Mybatis动态sql是做什么的?都有哪些动态sql?
- 20. Mybatis的Xml映射文件中,不同的Xml映射文件,id是否可以重复?
- 六.JVM 常考面试题
-
- 1. 什么是JVM内存结构?
- 2. 什么是JVM内存模型?
- 3. heap 和stack 有什么区别?
- 4. 什么情况下会发生栈内存溢出?
- 5. 谈谈对 OOM 的认识?如何排查 OOM 的问题?
- 6. 谈谈 JVM 中的常量池?
- 7. 如何判断一个对象是否存活?
- 8. 强引用、软引用、弱引用、虚引用是什么,有什么区别?
- 9. 被引用的对象就一定能存活吗?
- 10. Java中的垃圾回收算法有哪些?
- 11. 有哪几种垃圾回收器,各自的优缺点是什么?
- 12. 详细说一下CMS的回收过程?CMS的问题是什么?
- 13. 详细说一下G1的回收过程?
- 14. JVM中一次完整的GC是什么样子的?
- 15. Minor GC 和 Full GC 有什么不同呢?
- 16. 介绍下空间分配担保原则?
- 17. 什么是类加载?类加载的过程?
- 18. 什么是类加载器,常见的类加载器有哪些?
- 19. 什么是双亲委派模型?为什么需要双亲委派模型?
- 20. 列举一些你知道的打破双亲委派机制的例子,为什么要打破?
- 21. 说一下 JVM 调优的命令?
- 22. Java对象创建过程
- 23. JDK新特性
- 线上故障排查
- 1、硬件故障排查
- 2、报表异常 | JVM调优
- 3、大屏异常 | JUC调优
- **4、接口延迟 | SWAP调优**
- 5、**内存溢出 | Cache调优**
- 6、CPU飙高 | 死循环
- 七.RabbitMQ
-
- 为什么使用MQ?
-
- 解耦
- 异步
- 削峰
- 消息队列的缺点
- Kafka、ActiveMQ、RabbitMQ、RocketMQ 有什么优缺点?
- 1. RabbitMQ是什么?
- 2. RabbitMQ特点?
- 3. AMQP是什么?
- 4. AMQP的3层协议?
- 5. 说说Broker服务节点、Queue队列、Exchange交换器?
- 6. 如何保证消息的可靠性?
- 7. 生产者消息运转的流程?
- 8.消费者接收消息过程?
- 9. 生产者如何将消息可靠投递到RabbitMQ?
- 10. RabbitMQ如何将消息可靠投递到消费者?
- 11. 如何保证RabbitMQ消息队列的高可用?
- RocketMQ
-
- 1. RocketMQ是什么?
- 2. RocketMQ由哪些角色组成,每个角色作用和特点是什么?
- 3. RocketMQ消费模式有几种?
- 4. RocketMQ消费消息是push还是pull?
-
- 追问:为什么要主动拉取消息而不使用事件监听方式?
- 5. broker如何处理拉取请求的?
- 6. 如何让RocketMQ保证消息的顺序消费?
- 7. RocketMQ如何保证消息不丢失?
- 7. rocketMQ的消息堆积如何处理?
-
- 追问:如果Consumer和Queue不对等,上线了多台也在短时间内无法消费完堆积的消息怎么办?
- 追问:堆积时间过长消息超时了?
- 追问:堆积的消息会不会进死信队列?
- 8. RocketMQ为什么自研nameserver而不用zk?
- 八.Redis
-
- 1. Redis是什么?简述它的优缺点?
- 2. Redis为什么这么快?
- 3. Redis相比Memcached有哪些优势?
- 4. 为什么要用 Redis 做缓存?
- 5. 为什么要用 Redis 而不用 map/guava 做缓存?
- 6. Redis的常用场景有哪些?
- 7. Redis的数据类型有哪些?
- 持久化
-
- 8. Redis持久化机制?
- 9. 如何选择合适的持久化方式
- 10. Redis持久化数据和缓存怎么做扩容?
- 过期键的删除策略、淘汰策略
-
- 11. Redis过期键的删除策略
- 12. Redis key的过期时间和永久有效分别怎么设置?
- 13. Redis内存淘汰策略
- 缓存异常
-
- 14. 如何保证缓存与数据库双写时的数据一致性?
- 15. 先删除缓存,后更新数据库
-
- 答案一:延时双删
- 答案二: **更新与读取操作进行异步串行化**
- 16. 先更新数据库,后删除缓存
- 17. 什么是缓存击穿?
- 18. 什么是缓存穿透?
- 19. 什么是缓存雪崩?
- 20. 什么是缓存预热?
- 21. 什么是缓存降级?
- 线程模型
-
- 22. Redis为何选择单线程?
- 23. Redis真的是单线程?
- 24. Redis 6.0为何引入多线程?
- 25. Redis 6.0 采用多线程后,性能的提升效果如何?
- 26. 介绍下Redis的线程模型
- 27. Redis 6.0 多线程的实现机制?
- 28. Redis 6.0开启多线程后,是否会存在线程并发安全问题?
- 29. Redis 6.0 与 Memcached 多线程模型的对比
- 事务
-
- 30. Redis事务的概念
- 31. Redis事务的三个阶段
- 32. Redis事务相关命令
- 33. Redis事务支持隔离性吗?
- 34. Redis为什么不支持事务回滚?
- 35. Redis事务其他实现
- 主从、哨兵、集群
-
- 36. Redis常见使用方式有哪些?
- 37. 介绍下Redis单副本
- 38. 介绍下Redis多副本(主从)
- 39. 介绍下Redis Sentinel(哨兵)
- 40. 介绍下Redis Cluster
- 41. 介绍下Redis自研
- 42. Redis高可用方案具体怎么实施?
- 43. 了解主从复制的原理吗?
- 44. 由于主从延迟导致读取到过期数据怎么处理?
- 45. 主从复制的过程中如果因为网络原因停止复制了会怎么样?
- 46. Redis主从架构数据会丢失吗,为什么?
- 47. 如何解决主从架构数据丢失的问题?
- 48. Redis哨兵是怎么工作的?
- 49. 故障转移时会从剩下的slave选举一个新的master,被选举为master的标准是什么?
- 50. 同步配置的时候其他哨兵根据什么更新自己的配置呢?
- 51. 为什么Redis哨兵集群只有2个节点无法正常工作?
- 52. Redis cluster中是如何实现数据分布的?这种方式有什么优点?
- 53. Redis cluster节点间通信是什么机制?
- 分布式问题
-
- 54. 什么是分布式锁?为什么用分布式锁?
- 55. 常见的分布式锁有哪些解决方案?
- 56. Redis实现分布式锁
-
- 分布式锁的三个核心要素
- 上述分布式锁存在的问题
- 57. 了解RedLock吗?
- 58. RedLock的原理
- 59. Redis如何做内存优化?
- 60. 如果现在有个读超高并发的系统,用Redis来抗住大部分读请求,你会怎么设计?
一.Java 基础面试题
1.Java概述
Java语言有哪些特点?
-
面向对象(封装,继承,多态);
-
平台无关性,平台无关性的具体表现在于,Java 是“一次编写,到处运行(Write Once,Run any Where)”的语言,因此采用 Java 语言编写的程序具有很好的可移植性,而保证这一点的正是 Java 的虚拟机机制。在引入虚拟机之后,Java 语言在不同的平台上运行不需要重新编译。
-
可靠性、安全性;
-
支持多线程。C++ 语言没有内置的多线程机制,因此必须调用操作系统的多线程功能来进行多线程程序设计,而 Java 语言却提供了多线程支持;
-
支持网络编程并且很方便。Java 语言诞生本身就是为简化网络编程设计的,因此 Java 语言不仅支持网络编程而且很方便;
-
编译与解释并存;
Java和C++有什么关系,它们有什么区别?
- 都是面向对象的语言,都支持封装、继承和多态;
- C++ 支持指针,而 Java 没有指针的概念;
- C++ 支持多继承,而 Java 不支持多重继承,但允许一个类实现多个接口;
- Java 是完全面向对象的语言,并且还取消了 C/C++ 中的结构和联合,使编译程序更加简洁;
- Java 自动进行无用内存回收操作,不再需要程序员进行手动删除,而 C++ 中必须由程序释放内存资源,这就增加了程序员的负担。
- Java 不支持操作符重载,操作符重载则被认为是 C++ 的突出特征;
- Java 允许预处理,但不支持预处理器功能,所以为了实现预处理,它提供了引入语句(import),但它与 C++ 预处理器的功能类似;
- Java 不支持缺省参数函数,而 C++ 支持;
- C 和 C++ 不支持字符串变量,在 C 和 C++ 程序中使用“Null”终止符代表字符串的结束。在 Java 中字符串是用类对象(String 和 StringBuffer)来实现的;
- goto 语句是 C 和 C++ 的“遗物”,Java 不提供 goto 语句,虽然 Java 指定 goto 作为关键字,但不支持它的使用,这使程序更简洁易读;
- Java 不支持 C++ 中的自动强制类型转换,如果需要,必须由程序显式进行强制类型转换。
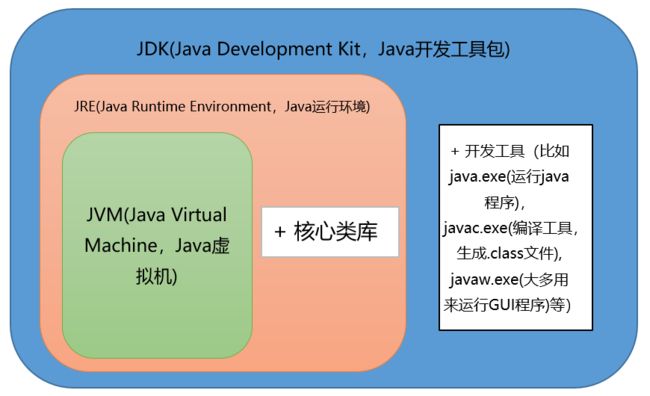
JVM、JRE和JDK的关系是什么?
JDK是(Java Development Kit)的缩写,它是功能齐全的 Java SDK。它拥有 JRE 所拥有的一切,还有编译器(javac)和工具(如 javadoc 和 jdb)。它能够创建和编译程序。
JRE是Java Runtime Environment缩写,它是运行已编译 Java 程序所需的所有内容的集合,包括 Java 虚拟机(JVM),Java 类库,java 命令和其他的一些基础构件。但是,它不能用于创建新程序。
JDK包含JRE,JRE包含JVM。
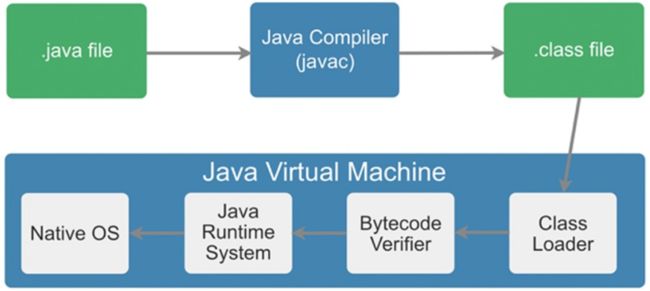
什么是字节码?
这个问题,面试官可以扩展提问,Java 是编译执行的语言,还是解释执行的语言?
Java之所以可以“一次编译,到处运行”,一是因为JVM针对各种操作系统、平台都进行了定制,二是因为无论在什么平台,都可以编译生成固定格式的字节码(.class文件)供JVM使用。因此,也可以看出字节码对于Java生态的重要性。
之所以被称之为字节码,是因为字节码文件由十六进制值组成,而JVM以两个十六进制值为一组,即以字节为单位进行读取。在Java中一般是用javac命令编译源代码为字节码文件,一个.java文件从编译到运行的示例如图所示。
采用字节码的好处是什么?
Java语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以Java程序运行时比较高效,而且,由于字节码并不专对一种特定的机器,因此,Java程序无须重新编译便可在多种不同的计算机上运行。
Oracle JDK 和 OpenJDK 的区别是什么?
可能在看这个问题之前很多人和我一样并没有接触和使用过 OpenJDK 。下面通过我通过我收集到一些资料对你解答这个被很多人忽视的问题。
- Oracle JDK 版本将每三年发布一次,而 OpenJDK 版本每三个月发布一次;
- OpenJDK 是一个参考模型并且是完全开源的,而 Oracle JDK 是OpenJDK 的一个实现,并不是完全开源的;
- Oracle JDK 比 OpenJDK 更稳定。OpenJDK 和 Oracle JDK 的代码几乎相同,但 Oracle JDK 有更多的类和一些错误修复。因此,如果您想开发企业/商业软件,建议选择 Oracle JDK,因为它经过了彻底的测试和稳定。某些情况下,有些人提到在使用 OpenJDK 可能会遇到了许多应用程序崩溃的问题,但是,只需切换到 Oracle JDK 就可以解决问题;
- 在响应性和 JVM 性能方面,Oracle JDK 与 OpenJDK 相比提供了更好的性能;
- Oracle JDK 不会为即将发布的版本提供长期支持,用户每次都必须通过更新到最新版本获得支持来获取最新版本;
- Oracle JDK 根据二进制代码许可协议获得许可,而 OpenJDK 根据 GPLv2 许可获得许可。
2.基础语法
Java有哪些数据类型?
Java 语言的数据类型分为两种:基本数据类型和引用数据类型。
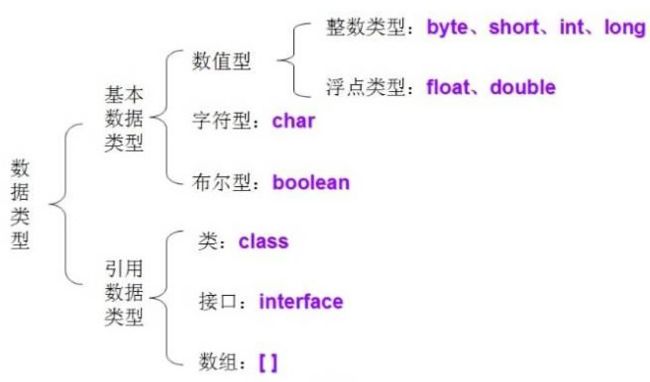
1.基本数据类型包括 boolean(布尔型)、float(单精度浮点型)、char(字符型)、byte(字节型)、short(短整型)、int(整型)、long(长整型)和 double (双精度浮点型)共 8 种,如下表所示。
| 基本类型 | 位数 | 字节 | 默认值 |
|---|---|---|---|
| int | 32 | 4 | 0 |
| short | 16 | 2 | 0 |
| long | 64 | 8 | 0L |
| byte | 8 | 1 | 0 |
| char | 16 | 2 | ‘u0000’ |
| float | 32 | 4 | 0f |
| double | 64 | 8 | 0d |
| boolean | 1 | false |
对于 boolean,官方文档未明确定义,它依赖于 JVM 厂商的具体实现。逻辑上理解是占用 1 位,但是实际中会考虑计算机高效存储因素。
Java虚拟机规范讲到:在JVM中并没有提供boolean专用的字节码指令,而boolean类型数据在经过编译后在JVM中会通过int类型来表示,此时boolean数据4字节32位,而boolean数组将会被编码成Java虚拟机的byte数组,此时每个boolean数据1字节占8bit。
注意:
- Java 里使用 long 类型的数据一定要在数值后面加上 L,否则将作为整型解析:
char a = 'h'char :单引号,String a = "hello":双引号
2.引用数据类型建立在基本数据类型的基础上,包括数组、类和接口。引用数据类型是由用户自定义,用来限制其他数据的类型。另外,Java 语言中不支持 C++中的指针类型、结构类型、联合类型和枚举类型。
switch 是否能作用在 byte 上,是否能作用在 long 上,是否能作用在 String 上?
Java5 以前 switch(expr)中,expr 只能是 byte、short、char、int。
从 Java 5 开始,Java 中引入了枚举类型, expr 也可以是 enum 类型。
从 Java 7 开始,expr还可以是字符串(String),但是长整型(long)在目前所有的版本中都是不可以的。
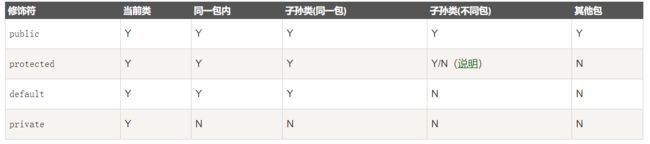
访问修饰符public、private、protected、以及不写(默认)时的区别?
Java中,可以使用访问控制符来保护对类、变量、方法和构造方法的访问。Java 支持 4 种不同的访问权限。
- default (即默认,什么也不写): 在同一包内可见,不使用任何修饰符。使用对象:类、接口、变量、方法。
- private : 在同一类内可见。使用对象:变量、方法。 注意:不能修饰类(外部类)
- public : 对所有类可见。使用对象:类、接口、变量、方法
- protected : 对同一包内的类和所有子类可见。使用对象:变量、方法。 注意:不能修饰类(外部类)。
break ,continue ,return 的区别及作用?
-
break 跳出总上一层循环,不再执行循环(结束当前的循环体)
-
continue 跳出本次循环,继续执行下次循环(结束正在执行的循环 进入下一个循环条件)
-
return 程序返回,不再执行下面的代码(结束当前的方法 直接返回)
3.关键字
final、finally、finalize的区别?
final 用于修饰变量、方法和类。
- final 变量:被修饰的变量不可变,不可变分为
引用不可变和对象不可变,final 指的是引用不可变,final 修饰的变量必须初始化,通常称被修饰的变量为常量。 - final 方法:被修饰的方法不允许任何子类重写,子类可以使用该方法。
- final 类:被修饰的类不能被继承,所有方法不能被重写。
finally 作为异常处理的一部分,它只能在 try/catch 语句中,并且附带一个语句块表示这段语句最终一定被执行(无论是否抛出异常),经常被用在需要释放资源的情况下,System.exit (0) 可以阻断 finally 执行。
finalize 是在 java.lang.Object 里定义的方法,也就是说每一个对象都有这么个方法,这个方法在 gc 启动,该对象被回收的时候被调用。
一个对象的 finalize 方法只会被调用一次,finalize 被调用不一定会立即回收该对象,所以有可能调用 finalize 后,该对象又不需要被回收了,然后到了真正要被回收的时候,因为前面调用过一次,所以不会再次调用 finalize 了,进而产生问题,因此不推荐使用 finalize 方法。
为什么要用static关键字?
通常来说,用new创建类的对象时,数据存储空间才被分配,方法才供外界调用。但有时我们只想为特定域分配单一存储空间,不考虑要创建多少对象或者说根本就不创建任何对象,再就是我们想在没有创建对象的情况下也想调用方法。在这两种情况下,static关键字,满足了我们的需求。
”static”关键字是什么意思?Java中是否可以覆盖(override)一个private或者是static的方法?
“static”关键字表明一个成员变量或者是成员方法可以在没有所属的类的实例变量的情况下被访问。
Java中static方法不能被覆盖,因为方法覆盖是基于运行时动态绑定的,而static方法是编译时静态绑定的。static方法跟类的任何实例都不相关,所以概念上不适用。
是否可以在static环境中访问非static变量?
static变量在Java中是属于类的,它在所有的实例中的值是一样的。当类被Java虚拟机载入的时候,会对static变量进行初始化。如果你的代码尝试不用实例来访问非static的变量,编译器会报错,因为这些变量还没有被创建出来,还没有跟任何实例关联上。
static静态方法能不能引用非静态资源?
不能,new的时候才会产生的东西,对于初始化后就存在的静态资源来说,根本不认识它。
static静态方法里面能不能引用静态资源?
可以,因为都是类初始化的时候加载的,大家相互都认识。
非静态方法里面能不能引用静态资源?
可以,非静态方法就是实例方法,那是new之后才产生的,那么属于类的内容它都认识。
java静态变量、代码块、和静态方法的执行顺序是什么?
基本上代码块分为三种:Static静态代码块、构造代码块、普通代码块
代码块执行顺序静态代码块——> 构造代码块 ——> 构造函数——> 普通代码块
继承中代码块执行顺序:父类静态块——>子类静态块——>父类代码块——>父类构造器——>子类代码块——>子类构造器
想要深入了解,可以参考这篇文章 :https://juejin.cn/post/6844903986475040781
4.面向对象
面向对象和面向过程的区别?
面向过程:
-
优点:性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗资源;比如单片机、嵌入式开发、Linux/Unix等一般采用面向过程开发,性能是最重要的因素。
-
缺点:没有面向对象易维护、易复用、易扩展。
面向对象:
-
优点:易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统更加灵活、更加易于维护。
-
缺点:性能比面向过程低。
讲讲面向对象三大特性
- 封装。封装最好理解了。封装是面向对象的特征之一,是对象和类概念的主要特性。封装,也就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。
- 继承。继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。通过继承创建的新类称为“子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类”。
- 多态性。它是指在父类中定义的属性和方法被子类继承之后,可以具有不同的数据类型或表现出不同的行为,这使得同一个属性或方法在父类及其各个子类中具有不同的含义。
Java语言是如何实现多态的?
本质上多态分两种:
1、编译时多态(又称静态多态)
2、运行时多态(又称动态多态)
重载(overload)就是编译时多态的一个例子,编译时多态在编译时就已经确定,运行的时候调用的是确定的方法。
**我们通常所说的多态指的都是运行时多态,也就是编译时不确定究竟调用哪个具体方法,一直延迟到运行时才能确定。**这也是为什么有时候多态方法又被称为延迟方法的原因。
Java实现多态有 3 个必要条件:继承、重写和向上转型。只有满足这 3 个条件,开发人员才能够在同一个继承结构中使用统一的逻辑实现代码处理不同的对象,从而执行不同的行为。
- 继承:在多态中必须存在有继承关系的子类和父类。
- 重写:子类对父类中某些方法进行重新定义,在调用这些方法时就会调用子类的方法。
- 向上转型:在多态中需要将子类的引用赋给父类对象,只有这样该引用才既能可以调用父类的方法,又能调用子类的方法。
Java多态的实现原理可看这篇文章:https://my.oschina.net/u/4432600/blog/4535042
重载(Overload)和重写(Override)的区别是什么?
方法的重载和重写都是实现多态的方式,区别在于前者实现的是编译时的多态性,而后者实现的是运行时的多态性。
- 重写发生在子类与父类之间, 重写方法返回值和形参都不能改变,与方法返回值和访问修饰符无关,即重载的方法不能根据返回类型进行区分。即外壳不变,核心重写!
- 重载(overloading) 是在一个类里面,方法名字相同,而参数不同。返回类型可以相同也可以不同。每个重载的方法(或者构造函数)都必须有一个独一无二的参数类型列表。最常用的地方就是构造器的重载。

重载的方法能否根据返回值类型进行区分?
不能根据返回值类型来区分重载的方法。因为调用时不指定类型信息,编译器不知道你要调用哪个函数。
float max(int a, int b);
int max(int a, int b);
当调用max(1,2);时无法确定调用的是哪个,单从这一点上来说,仅返回值类型不同的重载是不应该允许的。
构造器(constructor)是否可被重写(override)?
构造器不能被继承,因此不能被重写,但可以被重载。每一个类必须有自己的构造函数,负责构造自己这部分的构造。子类不会覆盖父类的构造函数,相反必须一开始调用父类的构造函数。
抽象类和接口的区别是什么?
语法层面上的区别:
- 抽象类可以提供成员方法的实现细节,而接口中只能存在public abstract 方法;
- 抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的;
- 接口中不能含有静态代码块以及静态方法,而抽象类可以有静态代码块和静态方法;
- 一个类只能继承一个抽象类,而一个类却可以实现多个接口。
设计层面上的区别:
- 抽象类是对一种事物的抽象,即对类抽象,而接口是对行为的抽象。抽象类是对整个类整体进行抽象,包括属性、行为,但是接口却是对类局部(行为)进行抽象。
- 设计层面不同,抽象类作为很多子类的父类,它是一种模板式设计。而接口是一种行为规范,它是一种辐射式设计。
想要深入了解,可以参考这篇文章 :https://www.cnblogs.com/dolphin0520/p/3811437.html
抽象类能使用 final 修饰吗?
不能,定义抽象类就是让其他类继承的,如果定义为 final 该类就不能被继承,这样彼此就会产生矛盾,所以 final 不能修饰抽象类
java 创建对象有哪几种方式?
java中提供了以下四种创建对象的方式:
- new创建新对象
- 通过反射机制
- 采用clone机制
- 通过序列化机制
前两者都需要显式地调用构造方法。对于clone机制,需要注意浅拷贝和深拷贝的区别,对于序列化机制需要明确其实现原理,在java中序列化可以通过实现Externalizable或者Serializable来实现。
什么是不可变对象?好处是什么?
不可变对象指对象一旦被创建,状态就不能再改变,任何修改都会创建一个新的对象,如 String、Integer及其它包装类.不可变对象最大的好处是线程安全.
能否创建一个包含可变对象的不可变对象?
当然可以,比如final Person[] persons = new Persion[]{}. persons是不可变对象的引用,但其数组中的Person实例却是可变的.这种情况下需要特别谨慎,不要共享可变对象的引用.这种情况下,如果数据需要变化时,就返回原对象的一个拷贝.
值传递和引用传递的区别的什么?为什么说Java中只有值传递?
值传递:指的是在方法调用时,传递的参数是按值的拷贝传递,传递的是值的拷贝,也就是说传递后就互不相关了。
引用传递:指的是在方法调用时,传递的参数是按引用进行传递,其实传递的是引用的地址,也就是变量所对应的内存空间的地址。传递的是值的引用,也就是说传递前和传递后都指向同一个引用(也就是同一个内存空间)。
基本类型作为参数被传递时肯定是值传递;引用类型作为参数被传递时也是值传递,只不过“值”为对应的引用。
想要深入了解,可以参考这篇文章 :http://www.itwanger.com/java/2019/11/26/java-yinyong-value.html
5.对象相等判断
== 和 equals 区别是什么?
==常用于相同的基本数据类型之间的比较,也可用于相同类型的对象之间的比较;
- 如果
==比较的是基本数据类型,那么比较的是两个基本数据类型的值是否相等; - 如果
==是比较的两个对象,那么比较的是两个对象的引用,也就是判断两个对象是否指向了同一块内存区域;
equals方法主要用于两个对象之间,检测一个对象是否等于另一个对象
看一看Object类中equals方法的源码:
public boolean equals(Object obj) {
return (this == obj);
}
它的作用也是判断两个对象是否相等,般有两种使用情况:
- 情况1,类没有覆盖equals()方法。则通过equals()比较该类的两个对象时,等价于通过“==”比较这两个对象。
- 情况2,类覆盖了equals()方法。一般,我们都覆盖equals()方法来两个对象的内容相等;若它们的内容相等,则返回true(即,认为这两个对象相等)。
java语言规范要求equals方法具有以下特性:
- 自反性。对于任意不为null的引用值x,x.equals(x)一定是true。
- 对称性)。对于任意不为null的引用值x和y,当且仅当x.equals(y)是true时,y.equals(x)也是true。
- 传递性。对于任意不为null的引用值x、y和z,如果x.equals(y)是true,同时y.equals(z)是true,那么x.equals(z)一定是true。
- 一致性。对于任意不为null的引用值x和y,如果用于equals比较的对象信息没有被修改的话,多次调用时x.equals(y)要么一致地返回true要么一致地返回false。
- 对于任意不为null的引用值x,x.equals(null)返回false。
介绍下hashCode()?
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在JDK的Object.java中,这就意味着Java中的任何类都包含有hashCode()函数。
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
为什么要有 hashCode?
以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode:
当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。
但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
hashCode(),equals()两种方法是什么关系?

要弄清楚这两种方法的关系,就需要对哈希表有一个基本的认识。其基本的结构如下:
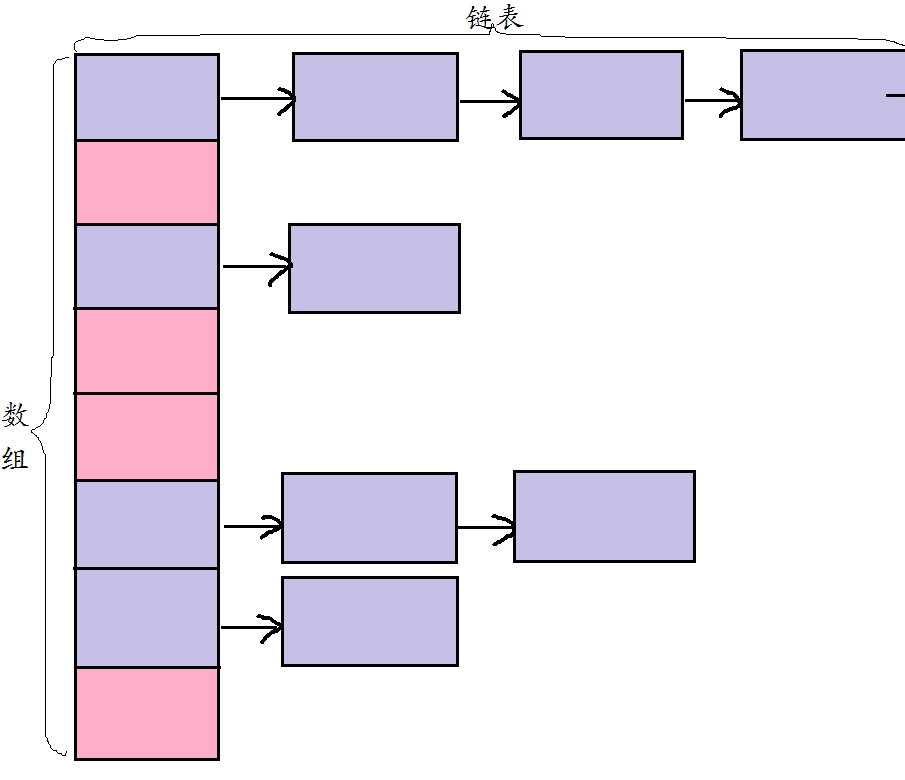
对于hashcode方法,会返回一个哈希值,哈希值对数组的长度取余后会确定一个存储的下标位置,如图中用数组括起来的第一列。
不同的哈希值取余之后的结果可能是相同的,用equals方法判断是否为相同的对象,不同则在链表中插入。
则有hashCode()与equals()的相关规定:
- 如果两个对象相等,则hashcode一定也是相同的;
- 两个对象相等,对两个对象分别调用equals方法都返回true;
- 两个对象有相同的hashcode值,它们也不一定是相等的;
为什么重写 equals 方法必须重写 hashcode 方法 ?
判断的时候先根据hashcode进行的判断,相同的情况下再根据equals()方法进行判断。如果只重写了equals方法,而不重写hashcode的方法,会造成hashcode的值不同,而equals()方法判断出来的结果为true。
在Java中的一些容器中,不允许有两个完全相同的对象,插入的时候,如果判断相同则会进行覆盖。这时候如果只重写了equals()的方法,而不重写hashcode的方法,Object中hashcode是根据对象的存储地址转换而形成的一个哈希值。这时候就有可能因为没有重写hashcode方法,造成相同的对象散列到不同的位置而造成对象的不能覆盖的问题。
String,StringBuffer, StringBuilder 的区别是什么?
1.可变与不可变。
String类中使用字符数组保存字符串,因为有“final”修饰符,所以string对象是不可变的。对于已经存在的String对象的修改都是重新创建一个新的对象,然后把新的值保存进去.
String类利用了final修饰的char类型数组存储字符,源码如下:
private final char value[];
StringBuilder与StringBuffer都继承自AbstractStringBuilder类,在AbstractStringBuilder中也是使用字符数组保存字符串,这两种对象都是可变的。
源码如下:
char[] value;
2.是否多线程安全。
String中的对象是不可变的,也就可以理解为常量,显然线程安全。
StringBuilder是非线程安全的。
StringBuffer对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。
源码如下:
@Override
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
3.性能
每次对String 类型进行改变的时候,都会生成一个新的String对象,然后将指针指向新的String 对象。StringBuffer每次都会对StringBuffer对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用StirngBuilder 相比使用StringBuffer 仅能获得10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
String为什么要设计成不可变的?
1.便于实现字符串池(String pool)
在Java中,由于会大量的使用String常量,如果每一次声明一个String都创建一个String对象,那将会造成极大的空间资源的浪费。Java提出了String pool的概念,在堆中开辟一块存储空间String pool,当初始化一个String变量时,如果该字符串已经存在了,就不会去创建一个新的字符串变量,而是会返回已经存在了的字符串的引用。
String a = "Hello world!";
String b = "Hello world!";
如果字符串是可变的,某一个字符串变量改变了其值,那么其指向的变量的值也会改变,String pool将不能够实现!
2.使多线程安全
在并发场景下,多个线程同时读一个资源,是安全的,不会引发竞争,但对资源进行写操作时是不安全的,不可变对象不能被写,所以保证了多线程的安全。
3.避免安全问题
在网络连接和数据库连接中字符串常常作为参数,例如,网络连接地址URL,文件路径path,反射机制所需要的String参数。其不可变性可以保证连接的安全性。如果字符串是可变的,黑客就有可能改变字符串指向对象的值,那么会引起很严重的安全问题。
4.加快字符串处理速度
由于String是不可变的,保证了hashcode的唯一性,于是在创建对象时其hashcode就可以放心的缓存了,不需要重新计算。这也就是Map喜欢将String作为Key的原因,处理速度要快过其它的键对象。所以HashMap中的键往往都使用String。
总体来说,String不可变的原因要包括 设计考虑,效率优化,以及安全性这三大方面。
保证了hashcode的唯一性,于是在创建对象时其hashcode就可以放心的缓存了,不需要重新计算。这也就是Map喜欢将String作为Key的原因,处理速度要快过其它的键对象。所以HashMap中的键往往都使用String。
总体来说,String不可变的原因要包括 设计考虑,效率优化,以及安全性这三大方面。
6.String相关
字符型常量和字符串常量的区别?
-
形式上: 字符常量是单引号引起的一个字符,字符串常量是双引号引起的若干个字符;
-
含义上: 字符常量相当于一个整型值( ASCII 值),可以参加表达式运算;字符串常量代表一个地址值(该字符串在内存中存放位置,相当于对象;
-
占内存大小:字符常量只占2个字节;字符串常量占若干个字节(至少一个字符结束标志) (注意: char 在Java中占两个字节)。
什么是字符串常量池?
java中常量池的概念主要有三个:全局字符串常量池,class文件常量池,运行时常量池。我们现在所说的就是全局字符串常量池,对这个想弄明白的同学可以看这篇Java中几种常量池的区分。
jvm为了提升性能和减少内存开销,避免字符的重复创建,其维护了一块特殊的内存空间,即字符串池,当需要使用字符串时,先去字符串池中查看该字符串是否已经存在,如果存在,则可以直接使用,如果不存在,初始化,并将该字符串放入字符串常量池中。
字符串常量池的位置也是随着jdk版本的不同而位置不同。在jdk6中,常量池的位置在永久代(方法区)中,此时常量池中存储的是对象。在jdk7中,常量池的位置在堆中,此时,常量池存储的就是引用了。在jdk8中,永久代(方法区)被元空间取代了。
String str="aaa"与 String str=new String(“aaa”)一样吗?new String(“aaa”);创建了几个字符串对象?
- 使用
String a = “aaa” ;,程序运行时会在常量池中查找”aaa”字符串,若没有,会将”aaa”字符串放进常量池,再将其地址赋给a;若有,将找到的”aaa”字符串的地址赋给a。 - 使用String b = new String(“aaa”);`,程序会在堆内存中开辟一片新空间存放新对象,同时会将”aaa”字符串放入常量池,相当于创建了两个对象,无论常量池中有没有”aaa”字符串,程序都会在堆内存中开辟一片新空间存放新对象。
具体分析,见以下代码:
@Test
public void test(){
String s = new String("2");
s.intern();
String s2 = "2";
System.out.println(s == s2);
String s3 = new String("3") + new String("3");
s3.intern();
String s4 = "33";
System.out.println(s3 == s4);
}
运行结果:
jdk6
false
false
jdk7
false
true
这段代码在jdk6中输出是false false,但是在jdk7中输出的是false true。我们通过图来一行行解释。
先来认识下intern()函数:
intern函数的作用是将对应的符号常量进入特殊处理,在JDK1.6以前 和 JDK1.7以后有不同的处理;
在JDK1.6中,intern的处理是 先判断字符串常量是否在字符串常量池中,如果存在直接返回该常量,如果没有找到,则将该字符串常量加入到字符串常量区,也就是在字符串常量区建立该常量;
在JDK1.7中,intern的处理是 先判断字符串常量是否在字符串常量池中,如果存在直接返回该常量,如果没有找到,说明该字符串常量在堆中,则处理是把堆区该对象的引用加入到字符串常量池中,以后别人拿到的是该字符串常量的引用,实际存在堆中
String s = new String("2");创建了两个对象,一个在堆中的StringObject对象,一个是在常量池中的“2”对象。
s.intern();在常量池中寻找与s变量内容相同的对象,发现已经存在内容相同对象“2”,返回对象2的地址。
String s2 = "2";使用字面量创建,在常量池寻找是否有相同内容的对象,发现有,返回对象"2"的地址。
System.out.println(s == s2);从上面可以分析出,s变量和s2变量地址指向的是不同的对象,所以返回false
String s3 = new String("3") + new String("3");创建了两个对象,一个在堆中的StringObject对象,一个是在常量池中的“3”对象。中间还有2个匿名的new String(“3”)我们不去讨论它们。
s3.intern();在常量池中寻找与s3变量内容相同的对象,没有发现“33”对象,在常量池中创建“33”对象,返回“33”对象的地址。
String s4 = "33";使用字面量创建,在常量池寻找是否有相同内容的对象,发现有,返回对象"33"的地址。
System.out.println(s3 == s4);从上面可以分析出,s3变量和s4变量地址指向的是不同的对象,所以返回false
JDK1.7
String s = new String("2");创建了两个对象,一个在堆中的StringObject对象,一个是在堆中的“2”对象,并在常量池中保存“2”对象的引用地址。
s.intern();在常量池中寻找与s变量内容相同的对象,发现已经存在内容相同对象“2”,返回对象“2”的引用地址。
String s2 = "2";使用字面量创建,在常量池寻找是否有相同内容的对象,发现有,返回对象“2”的引用地址。
System.out.println(s == s2);从上面可以分析出,s变量和s2变量地址指向的是不同的对象,所以返回false
String s3 = new String("3") + new String("3");创建了两个对象,一个在堆中的StringObject对象,一个是在堆中的“3”对象,并在常量池中保存“3”对象的引用地址。中间还有2个匿名的new String(“3”)我们不去讨论它们。
s3.intern();在常量池中寻找与s3变量内容相同的对象,没有发现“33”对象,将s3对应的StringObject对象的地址保存到常量池中,返回StringObject对象的地址。
String s4 = "33";使用字面量创建,在常量池寻找是否有相同内容的对象,发现有,返回其地址,也就是StringObject对象的引用地址。
System.out.println(s3 == s4);从上面可以分析出,s3变量和s4变量地址指向的是相同的对象,所以返回true。
String 是最基本的数据类型吗?
不是。Java 中的基本数据类型只有 8 个 :byte、short、int、long、float、double、char、boolean;除了基本类型(primitive type),剩下的都是引用类型(referencetype),Java 5 以后引入的枚举类型也算是一种比较特殊的引用类型。
String有哪些特性?
-
不变性:String 是只读字符串,是一个典型的 immutable 对象,对它进行任何操作,其实都是创建一个新的对象,再把引用指向该对象。不变模式的主要作用在于当一个对象需要被多线程共享并频繁访问时,可以保证数据的一致性;
-
常量池优化:String 对象创建之后,会在字符串常量池中进行缓存,如果下次创建同样的对象时,会直接返回缓存的引用;
-
final:使用 final 来定义 String 类,表示 String 类不能被继承,提高了系统的安全性。
在使用 HashMap 的时候,用 String 做 key 有什么好处?
HashMap 内部实现是通过 key 的 hashcode 来确定 value 的存储位置,因为字符串是不可变的,所以当创建字符串时,它的 hashcode 被缓存下来,不需要再次计算,所以相比于其他对象更快。
7.包装类型
包装类型是什么?基本类型和包装类型有什么区别?
Java 为每一个基本数据类型都引入了对应的包装类型(wrapper class),int 的包装类就是 Integer,从 Java 5 开始引入了自动装箱/拆箱机制,把基本类型转换成包装类型的过程叫做装箱(boxing);反之,把包装类型转换成基本类型的过程叫做拆箱(unboxing),使得二者可以相互转换。
Java 为每个原始类型提供了包装类型:
原始类型: boolean,char,byte,short,int,long,float,double
包装类型:Boolean,Character,Byte,Short,Integer,Long,Float,Double
基本类型和包装类型的区别主要有以下 几点:
-
包装类型可以为 null,而基本类型不可以。它使得包装类型可以应用于 POJO 中,而基本类型则不行。那为什么 POJO 的属性必须要用包装类型呢?《阿里巴巴 Java 开发手册》上有详细的说明, 数据库的查询结果可能是 null,如果使用基本类型的话,因为要自动拆箱(将包装类型转为基本类型,比如说把 Integer 对象转换成 int 值),就会抛出
NullPointerException的异常。 -
包装类型可用于泛型,而基本类型不可以。泛型不能使用基本类型,因为使用基本类型时会编译出错。
List<int> list = new ArrayList<>(); // 提示 Syntax error, insert "Dimensions" to complete ReferenceType List<Integer> list = new ArrayList<>();因为泛型在编译时会进行类型擦除,最后只保留原始类型,而原始类型只能是 Object 类及其子类——基本类型是个特例。
-
基本类型比包装类型更高效。基本类型在栈中直接存储的具体数值,而包装类型则存储的是堆中的引用。 很显然,相比较于基本类型而言,包装类型需要占用更多的内存空间。
解释一下自动装箱和自动拆箱?
自动装箱:将基本数据类型重新转化为对象
public class Test {
public static void main(String[] args) {
// 声明一个Integer对象,用到了自动的装箱:解析为:Integer num = Integer.valueOf(9);
Integer num = 9;
}
}
9是属于基本数据类型的,原则上它是不能直接赋值给一个对象Integer的。但jdk1.5 开始引入了自动装箱/拆箱机制,就可以进行这样的声明,自动将基本数据类型转化为对应的封装类型,成为一个对象以后就可以调用对象所声明的所有的方法。
自动拆箱:将对象重新转化为基本数据类型
public class Test {
public static void main(String[] args) {
/ /声明一个Integer对象
Integer num = 9;
// 进行计算时隐含的有自动拆箱
System.out.print(num--);
}
}
因为对象时不能直接进行运算的,而是要转化为基本数据类型后才能进行加减乘除。
int 和 Integer 有什么区别?
- Integer是int的包装类;int是基本数据类型;
- Integer变量必须实例化后才能使用;int变量不需要;
- Integer实际是对象的引用,指向此new的Integer对象;int是直接存储数据值 ;
- Integer的默认值是null;int的默认值是0。
两个new生成的Integer变量的对比
由于Integer变量实际上是对一个Integer对象的引用,所以两个通过new生成的Integer变量永远是不相等的(因为new生成的是两个对象,其内存地址不同)。
Integer i = new Integer(10000);
Integer j = new Integer(10000);
System.out.print(i == j); //false
Integer变量和int变量的对比
Integer变量和int变量比较时,只要两个变量的值是向等的,则结果为true(因为包装类Integer和基本数据类型int比较时,java会自动拆包装为int,然后进行比较,实际上就变为两个int变量的比较)
int a = 10000;
Integer b = new Integer(10000);
Integer c=10000;
System.out.println(a == b); // true
System.out.println(a == c); // true
非new生成的Integer变量和new Integer()生成变量的对比
非new生成的Integer变量和new Integer()生成的变量比较时,结果为false。(因为非new生成的Integer变量指向的是java常量池中的对象,而new Integer()生成的变量指向堆中新建的对象,两者在内存中的地址不同)
Integer b = new Integer(10000);
Integer c=10000;
System.out.println(b == c); // false
两个非new生成的Integer对象的对比
对于两个非new生成的Integer对象,进行比较时,如果两个变量的值在区间-128到127之间,则比较结果为true,如果两个变量的值不在此区间,则比较结果为false
Integer i = 100;
Integer j = 100;
System.out.print(i == j); //true
Integer i = 128;
Integer j = 128;
System.out.print(i == j); //false
当值在 -128 ~ 127之间时,java会进行自动装箱,然后会对值进行缓存,如果下次再有相同的值,会直接在缓存中取出使用。缓存是通过Integer的内部类IntegerCache来完成的。当值超出此范围,会在堆中new出一个对象来存储。
给一个Integer对象赋一个int值的时候,会调用Integer类的静态方法valueOf,源码如下:
public static Integer valueOf(String s, int radix) throws NumberFormatException {
return Integer.valueOf(parseInt(s,radix));
}
/**
* (1)在-128~127之内:静态常量池中cache数组是static final类型,cache数组对象会被存储于静态常量池中。
* cache数组里面的元素却不是static final类型,而是cache[k] = new Integer(j++),
* 那么这些元素是存储于堆中,只是cache数组对象存储的是指向了堆中的Integer对象(引用地址)
*
* (2)在-128~127 之外:新建一个 Integer对象,并返回。
*/
public static Integer valueOf(int i) {
assert IntegerCache.high >= 127;
if (i >= IntegerCache.low && i <= IntegerCache.high) {
return IntegerCache.cache[i + (-IntegerCache.low)];
}
return new Integer(i);
}
IntegerCache是Integer的内部类,源码如下:
/**
* 缓存支持自动装箱的对象标识语义 -128和127(含)。
* 缓存在第一次使用时初始化。 缓存的大小可以由-XX:AutoBoxCacheMax = 选项控制。
* 在VM初始化期间,java.lang.Integer.IntegerCache.high属性可以设置并保存在私有系统属性中
*/
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++) {
cache[k] = new Integer(j++); // 创建一个对象
}
}
private IntegerCache() {}
}
8.反射
什么是反射?
反射是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为 Java 语言的反射机制。
反射机制的优缺点有哪些?
优点:能够运行时动态获取类的实例,提高灵活性;可与动态编译结合Class.forName('com.mysql.jdbc.Driver.class');,加载MySQL的驱动类。
缺点:使用反射性能较低,需要解析字节码,将内存中的对象进行解析。其解决方案是:通过setAccessible(true)关闭JDK的安全检查来提升反射速度;多次创建一个类的实例时,有缓存会快很多;ReflflectASM工具类,通过字节码生成的方式加快反射速度。
如何获取反射中的Class对象?
-
Class.forName(“类的路径”);当你知道该类的全路径名时,你可以使用该方法获取 Class 类对象。
Class clz = Class.forName("java.lang.String"); -
类名.class。这种方法只适合在编译前就知道操作的 Class。
Class clz = String.class; -
对象名.getClass()。
String str = new String("Hello"); Class clz = str.getClass(); -
如果是基本类型的包装类,可以调用包装类的Type属性来获得该包装类的Class对象。
Java反射API有几类?
反射 API 用来生成 JVM 中的类、接口或则对象的信息。
-
Class 类:反射的核心类,可以获取类的属性,方法等信息。
-
Field 类:Java.lang.reflec 包中的类,表示类的成员变量,可以用来获取和设置类之中的属性值。
-
Method 类:Java.lang.reflec 包中的类,表示类的方法,它可以用来获取类中的方法信息或者执行方法。
-
Constructor 类:Java.lang.reflec 包中的类,表示类的构造方法。
反射使用的步骤?
-
获取想要操作的类的Class对象,这是反射的核心,通过Class对象我们可以任意调用类的方法。
-
调用 Class 类中的方法,既就是反射的使用阶段。
-
使用反射 API 来操作这些信息。
具体可以看下面的例子:
public class Apple {
private int price;
public int getPrice() {
return price;
}
public void setPrice(int price) {
this.price = price;
}
public static void main(String[] args) throws Exception{
//正常的调用
Apple apple = new Apple();
apple.setPrice(5);
System.out.println("Apple Price:" + apple.getPrice());
//使用反射调用
Class clz = Class.forName("com.chenshuyi.api.Apple");
Method setPriceMethod = clz.getMethod("setPrice", int.class);
Constructor appleConstructor = clz.getConstructor();
Object appleObj = appleConstructor.newInstance();
setPriceMethod.invoke(appleObj, 14);
Method getPriceMethod = clz.getMethod("getPrice");
System.out.println("Apple Price:" + getPriceMethod.invoke(appleObj));
}
}
从代码中可以看到我们使用反射调用了 setPrice 方法,并传递了 14 的值。之后使用反射调用了 getPrice 方法,输出其价格。上面的代码整个的输出结果是:
Apple Price:5
Apple Price:14
从这个简单的例子可以看出,一般情况下我们使用反射获取一个对象的步骤:
- 获取类的 Class 对象实例
Class clz = Class.forName("com.zhenai.api.Apple");
- 根据 Class 对象实例获取 Constructor 对象
Constructor appleConstructor = clz.getConstructor();
- 使用 Constructor 对象的 newInstance 方法获取反射类对象
Object appleObj = appleConstructor.newInstance();
而如果要调用某一个方法,则需要经过下面的步骤:
- 获取方法的 Method 对象
Method setPriceMethod = clz.getMethod("setPrice", int.class);
- 利用 invoke 方法调用方法
setPriceMethod.invoke(appleObj, 14);
为什么引入反射概念?反射机制的应用有哪些?
我们来看一下 Oracle 官方文档中对反射的描述:
从 Oracle 官方文档中可以看出,反射主要应用在以下几方面:
- 反射让开发人员可以通过外部类的全路径名创建对象,并使用这些类,实现一些扩展的功能。
- 反射让开发人员可以枚举出类的全部成员,包括构造函数、属性、方法。以帮助开发者写出正确的代码。
- 测试时可以利用反射 API 访问类的私有成员,以保证测试代码覆盖率。
也就是说,Oracle 希望开发者将反射作为一个工具,用来帮助程序员实现本不可能实现的功能。
举两个最常见使用反射的例子,来说明反射机制的强大之处:
第一种:JDBC 的数据库的连接
在JDBC 的操作中,如果要想进行数据库的连接,则必须按照以上的几步完成
- 通过Class.forName()加载数据库的驱动程序 (通过反射加载,前提是引入相关了Jar包);
- 通过 DriverManager 类进行数据库的连接,连接的时候要输入数据库的连接地址、用户名、密码;
- 通过Connection 接口接收连接。
public class ConnectionJDBC {
/**
* @param args
*/
//驱动程序就是之前在classpath中配置的JDBC的驱动程序的JAR 包中
public static final String DBDRIVER = "com.mysql.jdbc.Driver";
//连接地址是由各个数据库生产商单独提供的,所以需要单独记住
public static final String DBURL = "jdbc:mysql://localhost:3306/test";
//连接数据库的用户名
public static final String DBUSER = "root";
//连接数据库的密码
public static final String DBPASS = "";
public static void main(String[] args) throws Exception {
Connection con = null; //表示数据库的连接对象
Class.forName(DBDRIVER); //1、使用CLASS 类加载驱动程序 ,反射机制的体现
con = DriverManager.getConnection(DBURL,DBUSER,DBPASS); //2、连接数据库
System.out.println(con);
con.close(); // 3、关闭数据库
}
第二种:Spring 框架的使用,最经典的就是xml的配置模式。
Spring 通过 XML 配置模式装载 Bean 的过程:
- 将程序内所有 XML 或 Properties 配置文件加载入内存中;
- Java类里面解析xml或properties里面的内容,得到对应实体类的字节码字符串以及相关的属性信息;
- 使用反射机制,根据这个字符串获得某个类的Class实例;
- 动态配置实例的属性。
Spring这样做的好处是:
- 不用每一次都要在代码里面去new或者做其他的事情;
- 以后要改的话直接改配置文件,代码维护起来就很方便了;
- 有时为了适应某些需求,Java类里面不一定能直接调用另外的方法,可以通过反射机制来实现。
模拟 Spring 加载 XML 配置文件:
public class BeanFactory {
private Map<String, Object> beanMap = new HashMap<String, Object>();
/**
* bean工厂的初始化.
* @param xml xml配置文件
*/
public void init(String xml) {
try {
//读取指定的配置文件
SAXReader reader = new SAXReader();
ClassLoader classLoader = Thread.currentThread().getContextClassLoader();
//从class目录下获取指定的xml文件
InputStream ins = classLoader.getResourceAsStream(xml);
Document doc = reader.read(ins);
Element root = doc.getRootElement();
Element foo;
//遍历bean
for (Iterator i = root.elementIterator("bean"); i.hasNext();) {
foo = (Element) i.next();
//获取bean的属性id和class
Attribute id = foo.attribute("id");
Attribute cls = foo.attribute("class");
//利用Java反射机制,通过class的名称获取Class对象
Class bean = Class.forName(cls.getText());
//获取对应class的信息
java.beans.BeanInfo info = java.beans.Introspector.getBeanInfo(bean);
//获取其属性描述
java.beans.PropertyDescriptor pd[] = info.getPropertyDescriptors();
//设置值的方法
Method mSet = null;
//创建一个对象
Object obj = bean.newInstance();
//遍历该bean的property属性
for (Iterator ite = foo.elementIterator("property"); ite.hasNext();) {
Element foo2 = (Element) ite.next();
//获取该property的name属性
Attribute name = foo2.attribute("name");
String value = null;
//获取该property的子元素value的值
for(Iterator ite1 = foo2.elementIterator("value"); ite1.hasNext();) {
Element node = (Element) ite1.next();
value = node.getText();
break;
}
for (int k = 0; k < pd.length; k++) {
if (pd[k].getName().equalsIgnoreCase(name.getText())) {
mSet = pd[k].getWriteMethod();
//利用Java的反射极致调用对象的某个set方法,并将值设置进去
mSet.invoke(obj, value);
}
}
}
//将对象放入beanMap中,其中key为id值,value为对象
beanMap.put(id.getText(), obj);
}
} catch (Exception e) {
System.out.println(e.toString());
}
}
//other codes
}
反射机制的原理是什么?
Class actionClass=Class.forName(“MyClass”);
Object action=actionClass.newInstance();
Method method = actionClass.getMethod(“myMethod”,null);
method.invoke(action,null);
上面就是最常见的反射使用的例子,前两行实现了类的装载、链接和初始化(newInstance方法实际上也是使用反射调用了方法),后两行实现了从class对象中获取到method对象然后执行反射调用。
因反射原理较复杂,下面简要描述下流程,想要详细了解的小伙伴,可以看这篇文章:https://www.cnblogs.com/yougewe/p/10125073.html
- 反射获取类实例 Class.forName(),并没有将实现留给了java,而是交给了jvm去加载!主要是先获取 ClassLoader, 然后调用 native 方法,获取信息,加载类则是回调 java.lang.ClassLoader。最后,jvm又会回调 ClassLoader 进类加载!
- newInstance() 主要做了三件事:
- 权限检测,如果不通过直接抛出异常;
- 查找无参构造器,并将其缓存起来;
- 调用具体方法的无参构造方法,生成实例并返回。
-
获取Method对象,

上面的Class对象是在加载类时由JVM构造的,JVM为每个类管理一个独一无二的Class对象,这份Class对象里维护着该类的所有Method,Field,Constructor的cache,这份cache也可以被称作根对象。
每次getMethod获取到的Method对象都持有对根对象的引用,因为一些重量级的Method的成员变量(主要是MethodAccessor),我们不希望每次创建Method对象都要重新初始化,于是所有代表同一个方法的Method对象都共享着根对象的MethodAccessor,每一次创建都会调用根对象的copy方法复制一份:
Method copy() {
Method res = new Method(clazz, name, parameterTypes, returnType,
exceptionTypes, modifiers, slot, signature,
annotations, parameterAnnotations, annotationDefault);
res.root = this;
res.methodAccessor = methodAccessor;
return res;
}
-
调用invoke()方法。调用invoke方法的流程如下:

调用Method.invoke之后,会直接去调MethodAccessor.invoke。MethodAccessor就是上面提到的所有同名method共享的一个实例,由ReflectionFactory创建。
创建机制采用了一种名为inflation的方式(JDK1.4之后):如果该方法的累计调用次数<=15,会创建出NativeMethodAccessorImpl,它的实现就是直接调用native方法实现反射;如果该方法的累计调用次数>15,会由java代码创建出字节码组装而成的MethodAccessorImpl。(是否采用inflation和15这个数字都可以在jvm参数中调整)
以调用MyClass.myMethod(String s)为例,生成出的MethodAccessorImpl字节码翻译成Java代码大致如下:
public class GeneratedMethodAccessor1 extends MethodAccessorImpl {
public Object invoke(Object obj, Object[] args) throws Exception {
try {
MyClass target = (MyClass) obj;
String arg0 = (String) args[0];
target.myMethod(arg0);
} catch (Throwable t) {
throw new InvocationTargetException(t);
}
}
}
9.泛型
Java中的泛型是什么 ?
泛型是 JDK1.5 的一个新特性,**泛型就是将类型参数化,其在编译时才确定具体的参数。**这种参数类型可以用在类、接口和方法的创建中,分别称为泛型类、泛型接口、泛型方法。
使用泛型的好处是什么?
远在 JDK 1.4 版本的时候,那时候是没有泛型的概念的,如果使用 Object 来实现通用、不同类型的处理,有这么两个缺点:
- 每次使用时都需要强制转换成想要的类型
- 在编译时编译器并不知道类型转换是否正常,运行时才知道,不安全。
如这个例子:
List list = new ArrayList();
list.add("www.cnblogs.com");
list.add(23);
String name = (String)list.get(0);
String number = (String)list.get(1); //ClassCastException
上面的代码在运行时会发生强制类型转换异常。这是因为我们在存入的时候,第二个是一个 Integer 类型,但是取出来的时候却将其强制转换为 String 类型了。Sun 公司为了使 Java 语言更加安全,减少运行时异常的发生。于是在 JDK 1.5 之后推出了泛型的概念。
根据《Java 编程思想》中的描述,泛型出现的动机在于:有许多原因促成了泛型的出现,而最引人注意的一个原因,就是为了创建容器类。
使用泛型的好处有以下几点:
-
类型安全
- 泛型的主要目标是提高 Java 程序的类型安全
- 编译时期就可以检查出因 Java 类型不正确导致的 ClassCastException 异常
- 符合越早出错代价越小原则
-
消除强制类型转换
- 泛型的一个附带好处是,使用时直接得到目标类型,消除许多强制类型转换
- 所得即所需,这使得代码更加可读,并且减少了出错机会
-
潜在的性能收益
- 由于泛型的实现方式,支持泛型(几乎)不需要 JVM 或类文件更改
- 所有工作都在编译器中完成
- 编译器生成的代码跟不使用泛型(和强制类型转换)时所写的代码几乎一致,只是更能确保类型安全而已
Java泛型的原理是什么 ? 什么是类型擦除 ?
泛型是一种语法糖,泛型这种语法糖的基本原理是类型擦除。Java中的泛型基本上都是在编译器这个层次来实现的,也就是说:**泛型只存在于编译阶段,而不存在于运行阶段。**在编译后的 class 文件中,是没有泛型这个概念的。
类型擦除:使用泛型的时候加上的类型参数,编译器在编译的时候去掉类型参数。
例如:
public class Caculate {
private T num;
}
我们定义了一个泛型类,定义了一个属性成员,该成员的类型是一个泛型类型,这个 T 具体是什么类型,我们也不知道,它只是用于限定类型的。反编译一下这个 Caculate 类:
public class Caculate{
public Caculate(){}
private Object num;
}
发现编译器擦除 Caculate 类后面的两个尖括号,并且将 num 的类型定义为 Object 类型。
那么是不是所有的泛型类型都以 Object 进行擦除呢?大部分情况下,泛型类型都会以 Object 进行替换,而有一种情况则不是。那就是使用到了extends和super语法的有界类型,如:
public class Caculate {
private T num;
}
这种情况的泛型类型,num 会被替换为 String 而不再是 Object。这是一个类型限定的语法,它限定 T 是 String 或者 String 的子类,也就是你构建 Caculate 实例的时候只能限定 T 为 String 或者 String 的子类,所以无论你限定 T 为什么类型,String 都是父类,不会出现类型不匹配的问题,于是可以使用 String 进行类型擦除。
实际上编译器会正常的将使用泛型的地方编译并进行类型擦除,然后返回实例。但是除此之外的是,如果构建泛型实例时使用了泛型语法,那么编译器将标记该实例并关注该实例后续所有方法的调用,每次调用前都进行安全检查,非指定类型的方法都不能调用成功。
实际上编译器不仅关注一个泛型方法的调用,它还会为某些返回值为限定的泛型类型的方法进行强制类型转换,由于类型擦除,返回值为泛型类型的方法都会擦除成 Object 类型,当这些方法被调用后,编译器会额外插入一行 checkcast 指令用于强制类型转换。这一个过程就叫做『泛型翻译』。
什么是泛型中的限定通配符和非限定通配符 ?
限定通配符对类型进行了限制。有两种限定通配符,一种是它通过确保类型必须是T的子类来设定类型的上界,另一种是它通过确保类型必须是T的父类来设定类型的下界。泛型类型必须用限定内的类型来进行初始化,否则会导致编译错误。
非限定通配符 ?,可以用任意类型来替代。如List 的意思是这个集合是一个可以持有任意类型的集合,它可以是List,也可以是List,或者List等等。
List和List 之间有什么区别 ?
这两个List的声明都是限定通配符的例子,List可以接受任何继承自T的类型的List,而List可以接受任何T的父类构成的List。例如List可以接受List或List。
可以把List
不可以。真这样做的话会导致编译错误。因为List可以存储任何类型的对象包括String, Integer等等,而List却只能用来存储String。
List<Object> objectList;
List<String> stringList;
objectList = stringList; //compilation error incompatible types
Array中可以用泛型吗?
不可以。这也是为什么 Joshua Bloch 在 《Effective Java》一书中建议使用 List 来代替 Array,因为 List 可以提供编译期的类型安全保证,而 Array 却不能。
判断ArrayList与ArrayList是否相等?
ArrayList<String> a = new ArrayList<String>();
ArrayList<Integer> b = new ArrayList<Integer>();
Class c1 = a.getClass();
Class c2 = b.getClass();
System.out.println(c1 == c2);
输出的结果是 true。因为无论对于 ArrayList 还是 ArrayList,它们的 Class 类型都是一直的,都是 ArrayList.class。
那它们声明时指定的 String 和 Integer 到底体现在哪里呢?
**答案是体现在类编译的时候。**当 JVM 进行类编译时,会进行泛型检查,如果一个集合被声明为 String 类型,那么它往该集合存取数据的时候就会对数据进行判断,从而避免存入或取出错误的数据。
10.序列化
Java序列化与反序列化是什么?
Java序列化是指把Java对象转换为字节序列的过程,而Java反序列化是指把字节序列恢复为Java对象的过程:
-
**序列化:**序列化是把对象转换成有序字节流,以便在网络上传输或者保存在本地文件中。核心作用是对象状态的保存与重建。我们都知道,Java对象是保存在JVM的堆内存中的,也就是说,如果JVM堆不存在了,那么对象也就跟着消失了。
而序列化提供了一种方案,可以让你在即使JVM停机的情况下也能把对象保存下来的方案。就像我们平时用的U盘一样。把Java对象序列化成可存储或传输的形式(如二进制流),比如保存在文件中。这样,当再次需要这个对象的时候,从文件中读取出二进制流,再从二进制流中反序列化出对象。
-
**反序列化:**客户端从文件中或网络上获得序列化后的对象字节流,根据字节流中所保存的对象状态及描述信息,通过反序列化重建对象。
为什么需要序列化与反序列化?
简要描述:对内存中的对象进行持久化或网络传输, 这个时候都需要序列化和反序列化
深入描述:
- 对象序列化可以实现分布式对象。
主要应用例如:RMI(即远程调用Remote Method Invocation)要利用对象序列化运行远程主机上的服务,就像在本地机上运行对象时一样。
- java对象序列化不仅保留一个对象的数据,而且递归保存对象引用的每个对象的数据。
可以将整个对象层次写入字节流中,可以保存在文件中或在网络连接上传递。利用对象序列化可以进行对象的"深复制",即复制对象本身及引用的对象本身。序列化一个对象可能得到整个对象序列。
- 序列化可以将内存中的类写入文件或数据库中。
比如:将某个类序列化后存为文件,下次读取时只需将文件中的数据反序列化就可以将原先的类还原到内存中。也可以将类序列化为流数据进行传输。
总的来说就是将一个已经实例化的类转成文件存储,下次需要实例化的时候只要反序列化即可将类实例化到内存中并保留序列化时类中的所有变量和状态。
- 对象、文件、数据,有许多不同的格式,很难统一传输和保存。
序列化以后就都是字节流了,无论原来是什么东西,都能变成一样的东西,就可以进行通用的格式传输或保存,传输结束以后,要再次使用,就进行反序列化还原,这样对象还是对象,文件还是文件。
序列化实现的方式有哪些?
实现Serializable接口或者Externalizable接口。
Serializable接口
类通过实现 java.io.Serializable 接口以启用其序列化功能。可序列化类的所有子类型本身都是可序列化的。序列化接口没有方法或字段,仅用于标识可序列化的语义。
如以下例子:
import java.io.Serializable;
public class User implements Serializable {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "User{" +
"name='" + name +
'}';
}
}
通过下面的代码进行序列化及反序列化:
public class SerializableDemo {
public static void main(String[] args) {
//Initializes The Object
User user = new User();
user.setName("cosen");
System.out.println(user);
//Write Obj to File
try (FileOutputStream fos = new FileOutputStream("tempFile"); ObjectOutputStream oos = new ObjectOutputStream(
fos)) {
oos.writeObject(user);
} catch (IOException e) {
e.printStackTrace();
}
//Read Obj from File
File file = new File("tempFile");
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file))) {
User newUser = (User)ois.readObject();
System.out.println(newUser);
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
}
//OutPut:
//User{name='cosen'}
//User{name='cosen'}
Externalizable接口
Externalizable继承自Serializable,该接口中定义了两个抽象方法:writeExternal()与readExternal()。
当使用Externalizable接口来进行序列化与反序列化的时候需要开发人员重写writeExternal()与readExternal()方法。否则所有变量的值都会变成默认值。
public class User implements Externalizable {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public void writeExternal(ObjectOutput out) throws IOException {
out.writeObject(name);
}
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
name = (String) in.readObject();
}
@Override
public String toString() {
return "User{" +
"name='" + name +
'}';
}
}
通过下面的代码进行序列化及反序列化:
public class ExternalizableDemo1 {
public static void main(String[] args) {
//Write Obj to file
User user = new User();
user.setName("cosen");
try(ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("tempFile"))){
oos.writeObject(user);
} catch (IOException e) {
e.printStackTrace();
}
//Read Obj from file
File file = new File("tempFile");
try(ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file))){
User newInstance = (User) ois.readObject();
//output
System.out.println(newInstance);
} catch (IOException | ClassNotFoundException e ) {
e.printStackTrace();
}
}
}
//OutPut:
//User{name='cosen'}
两种序列化的对比
| 实现Serializable接口 | 实现Externalizable接口 |
|---|---|
| 系统自动存储必要的信息 | 程序员决定存储哪些信息 |
| Java内建支持,易于实现,只需要实现该接口即可,无需任何代码支持 | 必须实现接口内的两个方法 |
| 性能略差 | 性能略好 |
什么是serialVersionUID?
serialVersionUID 用来表明类的不同版本间的兼容性
Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体(类)的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。
为什么还要显示指定serialVersionUID的值?
如果不显示指定serialVersionUID, JVM在序列化时会根据属性自动生成一个serialVersionUID, 然后与属性一起序列化, 再进行持久化或网络传输. 在反序列化时, JVM会再根据属性自动生成一个新版serialVersionUID, 然后将这个新版serialVersionUID与序列化时生成的旧版serialVersionUID进行比较, 如果相同则反序列化成功, 否则报错.
如果显示指定了, JVM在序列化和反序列化时仍然都会生成一个serialVersionUID, 但值为我们显示指定的值, 这样在反序列化时新旧版本的serialVersionUID就一致了.
在实际开发中, 不显示指定serialVersionUID的情况会导致什么问题? 如果我们的类写完后不再修改, 那当然不会有问题, 但这在实际开发中是不可能的, 我们的类会不断迭代, 一旦类被修改了, 那旧对象反序列化就会报错. 所以在实际开发中, 我们都会显示指定一个serialVersionUID, 值是多少无所谓, 只要不变就行。
serialVersionUID什么时候修改?
《阿里巴巴Java开发手册》中有以下规定:

想要深入了解的小伙伴,可以看这篇文章:https://juejin.cn/post/6844903746682486791
Java 序列化中如果有些字段不想进行序列化,怎么办?
对于不想进行序列化的变量,使用 transient 关键字修饰。
transient 关键字的作用是控制变量的序列化,在变量声明前加上该关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient 变量的值被设为初始值,如 int 型的是 0,对象型的是 null。transient 只能修饰变量,不能修饰类和方法。
静态变量会被序列化吗?
不会。因为序列化是针对对象而言的, 而静态变量优先于对象存在, 随着类的加载而加载, 所以不会被序列化.
看到这个结论, 是不是有人会问, serialVersionUID也被static修饰, 为什么serialVersionUID会被序列化? 其实serialVersionUID属性并没有被序列化, JVM在序列化对象时会自动生成一个serialVersionUID, 然后将我们显示指定的serialVersionUID属性值赋给自动生成的serialVersionUID。
11.异常
Error 和 Exception 区别是什么?
Java 中,所有的异常都有一个共同的祖先 java.lang 包中的 Throwable 类。Throwable 类有两个重要的子类 Exception(异常)和 Error(错误)。
Exception 和 Error 二者都是 Java 异常处理的重要子类,各自都包含大量子类。
Exception:程序本身可以处理的异常,可以通过catch来进行捕获,通常遇到这种错误,应对其进行处理,使应用程序可以继续正常运行。Exception又可以分为运行时异常(RuntimeException, 又叫非受检查异常)和非运行时异常(又叫受检查异常) 。Error:Error属于程序无法处理的错误 ,我们没办法通过catch来进行捕获 。例如,系统崩溃,内存不足,堆栈溢出等,编译器不会对这类错误进行检测,一旦这类错误发生,通常应用程序会被终止,仅靠应用程序本身无法恢复。

非受检查异常(运行时异常)和受检查异常(一般异常)区别是什么?
非受检查异常:包括 RuntimeException 类及其子类,表示 JVM 在运行期间可能出现的异常。 Java 编译器不会检查运行时异常。例如:NullPointException(空指针)、NumberFormatException(字符串转换为数字)、IndexOutOfBoundsException(数组越界)、ClassCastException(类转换异常)、ArrayStoreException(数据存储异常,操作数组时类型不一致)等。
受检查异常:是Exception 中除 RuntimeException 及其子类之外的异常。 Java 编译器会检查受检查异常。常见的受检查异常有: IO 相关的异常、ClassNotFoundException 、SQLException等。
非受检查异常和受检查异常之间的区别:是否强制要求调用者必须处理此异常,如果强制要求调用者必须进行处理,那么就使用受检查异常,否则就选择非受检查异常。
throw 和 throws 的区别是什么?
Java 中的异常处理除了包括捕获异常和处理异常之外,还包括声明异常和拋出异常,可以通过 throws 关键字在方法上声明该方法要拋出的异常,或者在方法内部通过 throw 拋出异常对象。
throws 关键字和 throw 关键字在使用上的几点区别如下:
- throw 关键字用在方法内部,只能用于抛出一种异常,用来抛出方法或代码块中的异常,受查异常和非受查异常都可以被抛出。
- throws 关键字用在方法声明上,可以抛出多个异常,用来标识该方法可能抛出的异常列表。一个方法用 throws 标识了可能抛出的异常列表,调用该方法的方法中必须包含可处理异常的代码,否则也要在方法签名中用 throws 关键字声明相应的异常。
举例如下:
throw 关键字:
public static void main(String[] args) {
String s = "abc";
if(s.equals("abc")) {
throw new NumberFormatException();
} else {
System.out.println(s);
}
//function();
}
throws 关键字:
public static void function() throws NumberFormatException{
String s = "abc";
System.out.println(Double.parseDouble(s));
}
public static void main(String[] args) {
try {
function();
} catch (NumberFormatException e) {
System.err.println("非数据类型不能转换。");
//e.printStackTrace();
}
}
NoClassDefFoundError 和 ClassNotFoundException 区别?
NoClassDefFoundError 是一个 Error 类型的异常,是由 JVM 引起的,不应该尝试捕获这个异常。引起该异常的原因是 JVM 或 ClassLoader 尝试加载某类时在内存中找不到该类的定义,该动作发生在运行期间,即编译时该类存在,但是在运行时却找不到了,可能是编译后被删除了等原因导致。
ClassNotFoundException 是一个受检查异常,需要显式地使用 try-catch 对其进行捕获和处理,或在方法签名中用 throws 关键字进行声明。当使用 Class.forName, ClassLoader.loadClass 或 ClassLoader.findSystemClass 动态加载类到内存的时候,通过传入的类路径参数没有找到该类,就会抛出该异常;另一种抛出该异常的可能原因是某个类已经由一个类加载器加载至内存中,另一个加载器又尝试去加载它。
Java常见异常有哪些?
- java.lang.IllegalAccessError:违法访问错误。当一个应用试图访问、修改某个类的域(Field)或者调用其方法,但是又违反域或方法的可见性声明,则抛出该异常。
- java.lang.InstantiationError:实例化错误。当一个应用试图通过Java的new操作符构造一个抽象类或者接口时抛出该异常.
- java.lang.OutOfMemoryError:内存不足错误。当可用内存不足以让Java虚拟机分配给一个对象时抛出该错误。
- java.lang.StackOverflowError:堆栈溢出错误。当一个应用递归调用的层次太深而导致堆栈溢出或者陷入死循环时抛出该错误。
- java.lang.ClassCastException:类造型异常。假设有类A和B(A不是B的父类或子类),O是A的实例,那么当强制将O构造为类B的实例时抛出该异常。该异常经常被称为强制类型转换异常。
- java.lang.ClassNotFoundException:找不到类异常。当应用试图根据字符串形式的类名构造类,而在遍历CLASSPAH之后找不到对应名称的class文件时,抛出该异常。
- java.lang.ArithmeticException:算术条件异常。譬如:整数除零等。
- java.lang.ArrayIndexOutOfBoundsException:数组索引越界异常。当对数组的索引值为负数或大于等于数组大小时抛出。
- java.lang.IndexOutOfBoundsException:索引越界异常。当访问某个序列的索引值小于0或大于等于序列大小时,抛出该异常。
- java.lang.InstantiationException:实例化异常。当试图通过newInstance()方法创建某个类的实例,而该类是一个抽象类或接口时,抛出该异常。
- java.lang.NoSuchFieldException:属性不存在异常。当访问某个类的不存在的属性时抛出该异常。
- java.lang.NoSuchMethodException:方法不存在异常。当访问某个类的不存在的方法时抛出该异常。
- java.lang.NullPointerException:空指针异常。当应用试图在要求使用对象的地方使用了null时,抛出该异常。譬如:调用null对象的实例方法、访问null对象的属性、计算null对象的长度、使用throw语句抛出null等等。
- java.lang.NumberFormatException:数字格式异常。当试图将一个String转换为指定的数字类型,而该字符串确不满足数字类型要求的格式时,抛出该异常。
- java.lang.StringIndexOutOfBoundsException:字符串索引越界异常。当使用索引值访问某个字符串中的字符,而该索引值小于0或大于等于序列大小时,抛出该异常。
try-catch-finally 中哪个部分可以省略?
catch 可以省略。更为严格的说法其实是:try只适合处理运行时异常,try+catch适合处理运行时异常+普通异常。也就是说,如果你只用try去处理普通异常却不加以catch处理,编译是通不过的,因为编译器硬性规定,普通异常如果选择捕获,则必须用catch显示声明以便进一步处理。而运行时异常在编译时没有如此规定,所以catch可以省略,你加上catch编译器也觉得无可厚非。
理论上,编译器看任何代码都不顺眼,都觉得可能有潜在的问题,所以你即使对所有代码加上try,代码在运行期时也只不过是在正常运行的基础上加一层皮。但是你一旦对一段代码加上try,就等于显示地承诺编译器,对这段代码可能抛出的异常进行捕获而非向上抛出处理。如果是普通异常,编译器要求必须用catch捕获以便进一步处理;如果运行时异常,捕获然后丢弃并且+finally扫尾处理,或者加上catch捕获以便进一步处理。
至于加上finally,则是在不管有没捕获异常,都要进行的“扫尾”处理。
try-catch-finally 中,如果 catch 中 return 了,finally 还会执行吗?
会执行,在 return 前执行。
在 finally 中改变返回值的做法是不好的,因为如果存在 finally 代码块,try中的 return 语句不会立马返回调用者,而是记录下返回值待 finally 代码块执行完毕之后再向调用者返回其值,然后如果在 finally 中修改了返回值,就会返回修改后的值。显然,在 finally 中返回或者修改返回值会对程序造成很大的困扰,Java 中也可以通过提升编译器的语法检查级别来产生警告或错误。
代码示例1:
public static int getInt() {
int a = 10;
try {
System.out.println(a / 0);
a = 20;
} catch (ArithmeticException e) {
a = 30;
return a;
/*
* return a 在程序执行到这一步的时候,这里不是return a 而是 return 30;这个返回路径就形成了
* 但是呢,它发现后面还有finally,所以继续执行finally的内容,a=40
* 再次回到以前的路径,继续走return 30,形成返回路径之后,这里的a就不是a变量了,而是常量30
*/
} finally {
a = 40;
}
return a;
}
//执行结果:30
代码示例2:
public static int getInt() {
int a = 10;
try {
System.out.println(a / 0);
a = 20;
} catch (ArithmeticException e) {
a = 30;
return a;
} finally {
a = 40;
//如果这样,就又重新形成了一条返回路径,由于只能通过1个return返回,所以这里直接返回40
return a;
}
}
// 执行结果:40
JVM 是如何处理异常的?
在一个方法中如果发生异常,这个方法会创建一个异常对象,并转交给 JVM,该异常对象包含异常名称,异常描述以及异常发生时应用程序的状态。创建异常对象并转交给 JVM 的过程称为抛出异常。可能有一系列的方法调用,最终才进入抛出异常的方法,这一系列方法调用的有序列表叫做调用栈。
JVM 会顺着调用栈去查找看是否有可以处理异常的代码,如果有,则调用异常处理代码。当 JVM 发现可以处理异常的代码时,会把发生的异常传递给它。如果 JVM 没有找到可以处理该异常的代码块,JVM 就会将该异常转交给默认的异常处理器(默认处理器为 JVM 的一部分),默认异常处理器打印出异常信息并终止应用程序。
想要深入了解的小伙伴可以看这篇文章:https://www.cnblogs.com/qdhxhz/p/10765839.html
12.IO
Java的IO 流分为几种?
- 按照流的方向:输入流(inputStream)和输出流(outputStream);
- 按照实现功能分:节点流(可以从或向一个特定的地方读写数据,如 FileReader)和处理流(是对一个已存在的流的连接和封装,通过所封装的流的功能调用实现数据读写, BufferedReader);
- 按照处理数据的单位: 字节流和字符流。分别由四个抽象类来表示(每种流包括输入和输出两种所以一共四个):InputStream,OutputStream,Reader,Writer。Java中其他多种多样变化的流均是由它们派生出来的。

字节流如何转为字符流?
字节输入流转字符输入流通过 InputStreamReader 实现,该类的构造函数可以传入 InputStream 对象。
字节输出流转字符输出流通过 OutputStreamWriter 实现,该类的构造函数可以传入 OutputStream 对象。
字符流与字节流的区别?
- 读写的时候字节流是按字节读写,字符流按字符读写。
- 字节流适合所有类型文件的数据传输,因为计算机字节(Byte)是电脑中表示信息含义的最小单位。字符流只能够处理纯文本数据,其他类型数据不行,但是字符流处理文本要比字节流处理文本要方便。
- 在读写文件需要对内容按行处理,比如比较特定字符,处理某一行数据的时候一般会选择字符流。
- 只是读写文件,和文件内容无关时,一般选择字节流。
BIO、NIO、AIO的区别?
- BIO:同步并阻塞,在服务器中实现的模式为一个连接一个线程。也就是说,客户端有连接请求的时候,服务器就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然这也可以通过线程池机制改善。BIO一般适用于连接数目小且固定的架构,这种方式对于服务器资源要求比较高,而且并发局限于应用中,是JDK1.4之前的唯一选择,但好在程序直观简单,易理解。
- NIO:同步并非阻塞,在服务器中实现的模式为一个请求一个线程,也就是说,客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到有连接IO请求时才会启动一个线程进行处理。NIO一般适用于连接数目多且连接比较短(轻操作)的架构,并发局限于应用中,编程比较复杂,从JDK1.4开始支持。
- AIO:异步并非阻塞,在服务器中实现的模式为一个有效请求一个线程,也就是说,客户端的IO请求都是通过操作系统先完成之后,再通知服务器应用去启动线程进行处理。AIO一般适用于连接数目多且连接比较长(重操作)的架构,充分调用操作系统参与并发操作,编程比较复杂,从JDK1.7开始支持。
Java IO都有哪些设计模式?
使用了适配器模式和装饰器模式
适配器模式:
Reader reader = new INputStreamReader(inputStream);
把一个类的接口变换成客户端所期待的另一种接口,从而使原本因接口不匹配而无法在一起工作的两个类能够在一起工作
- 类适配器:Adapter类(适配器)继承Adaptee类(源角色)实现Target接口(目标角色)
- 对象适配器:Adapter类(适配器)持有Adaptee类(源角色)对象实例,实现Target接口(目标角色)
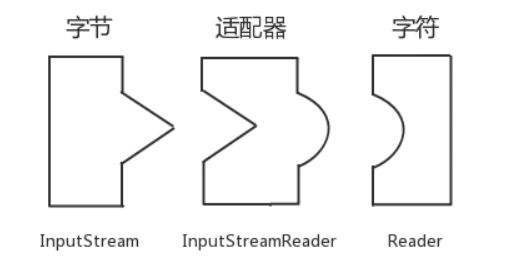
装饰器模式:
new BufferedInputStream(new FileInputStream(inputStream));
一种动态地往一个类中添加新的行为的设计模式。就功能而言,装饰器模式相比生成子类更为灵活,这样可以给某个对象而不是整个类添加一些功能。
- ConcreteComponent(具体对象)和Decorator(抽象装饰器)实现相同的Conponent(接口)并且Decorator(抽象装饰器)里面持有Conponent(接口)对象,可以传递请求。
- ConcreteComponent(具体装饰器)覆盖Decorator(抽象装饰器)的方法并用super进行调用,传递请求。

二.集合
1. 常见的集合有哪些?
Java集合类主要由两个根接口Collection和Map派生出来的,Collection派生出了三个子接口:List、Set、Queue(Java5新增的队列),因此Java集合大致也可分成List、Set、Queue、Map四种接口体系。
注意:Collection是一个接口,Collections是一个工具类,Map不是Collection的子接口。
Java集合框架图如下:


图中,List代表了有序可重复集合,可直接根据元素的索引来访问;Set代表无序不可重复集合,只能根据元素本身来访问;Queue是队列集合。
Map代表的是存储key-value对的集合,可根据元素的key来访问value。
上图中淡绿色背景覆盖的是集合体系中常用的实现类,分别是ArrayList、LinkedList、ArrayQueue、HashSet、TreeSet、HashMap、TreeMap等实现类。
2. 线程安全的集合有哪些?线程不安全的呢?
线程安全的:
- Hashtable:比HashMap多了个线程安全。
- ConcurrentHashMap:是一种高效但是线程安全的集合。
- Vector:比Arraylist多了个同步化机制。
- Stack:栈,也是线程安全的,继承于Vector。
线性不安全的:
- HashMap
- Arraylist
- LinkedList
- HashSet
- TreeSet
- TreeMap
3. Arraylist与 LinkedList 异同点?
- 是否保证线程安全: ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
- 底层数据结构: Arraylist 底层使用的是Object数组;LinkedList 底层使用的是双向循环链表数据结构;
- 插入和删除是否受元素位置的影响: ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行
add(E e)方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element))时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 LinkedList 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1)而数组为近似 O(n)。 - 是否支持快速随机访问: LinkedList 不支持高效的随机元素访问,而ArrayList 实现了RandmoAccess 接口,所以有随机访问功能。快速随机访问就是通过元素的序号快速获取元素对象(对应于
get(int index)方法)。 - 内存空间占用: ArrayList的空 间浪费主要体现在在list列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)。
4. ArrayList 与 Vector 区别?
- Vector是线程安全的,ArrayList不是线程安全的。其中,Vector在关键性的方法前面都加了synchronized关键字,来保证线程的安全性。如果有多个线程会访问到集合,那最好是使用 Vector,因为不需要我们自己再去考虑和编写线程安全的代码。
- ArrayList在底层数组不够用时在原来的基础上扩展0.5倍,Vector是扩展1倍,这样ArrayList就有利于节约内存空间。
5. 说一说ArrayList 的扩容机制?
ArrayList扩容的本质就是计算出新的扩容数组的size后实例化,并将原有数组内容复制到新数组中去。默认情况下,新的容量会是原容量的1.5倍。
以JDK1.8为例说明:
public boolean add(E e) {
//判断是否可以容纳e,若能,则直接添加在末尾;若不能,则进行扩容,然后再把e添加在末尾
ensureCapacityInternal(size + 1); // Increments modCount!!
//将e添加到数组末尾
elementData[size++] = e;
return true;
}
// 每次在add()一个元素时,arraylist都需要对这个list的容量进行一个判断。通过ensureCapacityInternal()方法确保当前ArrayList维护的数组具有存储新元素的能力,经过处理之后将元素存储在数组elementData的尾部
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
//如果传入的是个空数组则最小容量取默认容量与minCapacity之间的最大值
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// 若ArrayList已有的存储能力满足最低存储要求,则返回add直接添加元素;如果最低要求的存储能力>ArrayList已有的存储能力,这就表示ArrayList的存储能力不足,因此需要调用 grow();方法进行扩容
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// 获取elementData数组的内存空间长度
int oldCapacity = elementData.length;
// 扩容至原来的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
//校验容量是否够
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//若预设值大于默认的最大值,检查是否溢出
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 调用Arrays.copyOf方法将elementData数组指向新的内存空间
//并将elementData的数据复制到新的内存空间
elementData = Arrays.copyOf(elementData, newCapacity);
}
6. Array 和 ArrayList 有什么区别?什么时候该应 Array 而不是 ArrayList 呢?
-
Array 可以包含基本类型和对象类型,ArrayList 只能包含对象类型。
-
Array 大小是固定的,ArrayList 的大小是动态变化的。
-
ArrayList 提供了更多的方法和特性,比如:addAll(),removeAll(),iterator() 等等。
7. HashMap的底层数据结构是什么?
在JDK1.7 和JDK1.8 中有所差别:
在JDK1.7 中,由“数组+链表”组成,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的。
在JDK1.8 中,由“数组+链表+红黑树”组成。当链表过长,则会严重影响 HashMap 的性能,红黑树搜索时间复杂度是 O(logn),而链表是糟糕的 O(n)。因此,JDK1.8 对数据结构做了进一步的优化,引入了红黑树,链表和红黑树在达到一定条件会进行转换:
-
当链表超过 8 且数据总量超过 64 才会转红黑树。
-
将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树,以减少搜索时间。
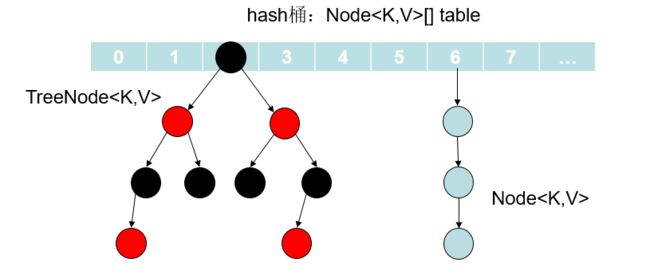
8. 解决hash冲突的办法有哪些?HashMap用的哪种?
解决Hash冲突方法有:开放定址法、再哈希法、链地址法(拉链法)、建立公共溢出区。HashMap中采用的是 链地址法 。
- 开放定址法也称为
再散列法,基本思想就是,如果p=H(key)出现冲突时,则以p为基础,再次hash,p1=H(p),如果p1再次出现冲突,则以p1为基础,以此类推,直到找到一个不冲突的哈希地址pi。 因此开放定址法所需要的hash表的长度要大于等于所需要存放的元素,而且因为存在再次hash,所以只能在删除的节点上做标记,而不能真正删除节点。 - 再哈希法(双重散列,多重散列),提供多个不同的hash函数,当
R1=H1(key1)发生冲突时,再计算R2=H2(key1),直到没有冲突为止。 这样做虽然不易产生堆集,但增加了计算的时间。 - 链地址法(拉链法),将哈希值相同的元素构成一个同义词的单链表,并将单链表的头指针存放在哈希表的第i个单元中,查找、插入和删除主要在同义词链表中进行。链表法适用于经常进行插入和删除的情况。
- 建立公共溢出区,将哈希表分为公共表和溢出表,当溢出发生时,将所有溢出数据统一放到溢出区。
9. 为什么在解决 hash 冲突的时候,不直接用红黑树?而选择先用链表,再转红黑树?
因为红黑树需要进行左旋,右旋,变色这些操作来保持平衡,而单链表不需要。当元素小于 8 个的时候,此时做查询操作,链表结构已经能保证查询性能。当元素大于 8 个的时候, 红黑树搜索时间复杂度是 O(logn),而链表是 O(n),此时需要红黑树来加快查询速度,但是新增节点的效率变慢了。
因此,如果一开始就用红黑树结构,元素太少,新增效率又比较慢,无疑这是浪费性能的。
10. HashMap默认加载因子是多少?为什么是 0.75,不是 0.6 或者 0.8 ?
回答这个问题前,我们来先看下HashMap的默认构造函数:
int threshold; // 容纳键值对的最大值
final float loadFactor; // 负载因子
int modCount;
int size;
Node[] table的初始化长度length(默认值是16),Load factor为负载因子(默认值是0.75),threshold是HashMap所能容纳键值对的最大值。threshold = length * Load factor。也就是说,在数组定义好长度之后,负载因子越大,所能容纳的键值对个数越多。
默认的loadFactor是0.75,0.75是对空间和时间效率的一个平衡选择,一般不要修改,除非在时间和空间比较特殊的情况下 :
-
如果内存空间很多而又对时间效率要求很高,可以降低负载因子Load factor的值 。
-
相反,如果内存空间紧张而对时间效率要求不高,可以增加负载因子loadFactor的值,这个值可以大于1。
我们来追溯下作者在源码中的注释(JDK1.7):
As a general rule, the default load factor (.75) offers a good tradeoff between time and space costs. Higher values decrease the space overhead but increase the lookup cost (reflected in most of the operations of the HashMap class, including get and put). The expected number of entries in the map and its load factor should be taken into account when setting its initial capacity, so as to minimize the number of rehash operations. If the initial capacity is greater than the maximum number of entries divided by the load factor, no rehash operations will ever occur.
翻译过来大概的意思是:作为一般规则,默认负载因子(0.75)在时间和空间成本上提供了很好的折衷。较高的值会降低空间开销,但提高查找成本(体现在大多数的HashMap类的操作,包括get和put)。设置初始大小时,应该考虑预计的entry数在map及其负载系数,并且尽量减少rehash操作的次数。如果初始容量大于最大条目数除以负载因子,rehash操作将不会发生。
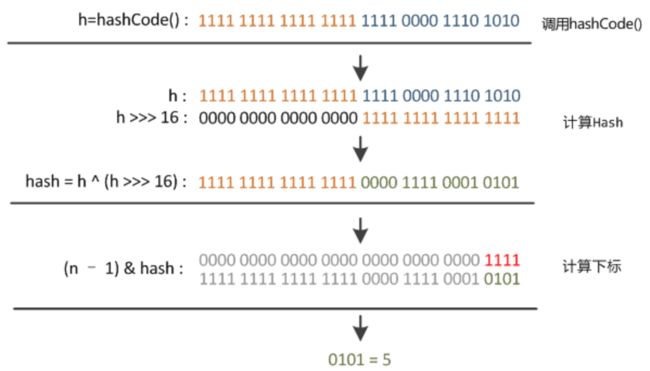
11. HashMap 中 key 的存储索引是怎么计算的?
首先根据key的值计算出hashcode的值,然后根据hashcode计算出hash值,最后通过hash&(length-1)计算得到存储的位置。看看源码的实现:
// jdk1.7
方法一:
static int hash(int h) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode(); // 为第一步:取hashCode值
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
方法二:
static int indexFor(int h, int length) { //jdk1.7的源码,jdk1.8没有这个方法,但实现原理一样
return h & (length-1); //第三步:取模运算
}
// jdk1.8
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
/*
h = key.hashCode() 为第一步:取hashCode值
h ^ (h >>> 16) 为第二步:高位参与运算
*/
}
这里的 Hash 算法本质上就是三步:取key的 hashCode 值、根据 hashcode 计算出hash值、通过取模计算下标。其中,JDK1.7和1.8的不同之处,就在于第二步。我们来看下详细过程,以JDK1.8为例,n为table的长度。
12. HashMap 的put方法流程?
简要流程如下:
-
首先根据 key 的值计算 hash 值,找到该元素在数组中存储的下标;
-
如果数组是空的,则调用 resize 进行初始化;
-
如果没有哈希冲突直接放在对应的数组下标里;
-
如果冲突了,且 key 已经存在,就覆盖掉 value;
-
如果冲突后,发现该节点是红黑树,就将这个节点挂在树上;
-
如果冲突后是链表,判断该链表是否大于 8 ,如果大于 8 并且数组容量小于 64,就进行扩容;如果链表节点大于 8 并且数组的容量大于 64,则将这个结构转换为红黑树;否则,链表插入键值对,若 key 存在,就覆盖掉 value。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gmya6HN4-1692793068255)(http://blog-img.coolsen.cn/img/hashmap之put方法.jpg)]
13. HashMap 的扩容方式?
HashMap 在容量超过负载因子所定义的容量之后,就会扩容。Java 里的数组是无法自动扩容的,方法是将 HashMap 的大小扩大为原来数组的两倍,并将原来的对象放入新的数组中。
那扩容的具体步骤是什么?让我们看看源码。
先来看下JDK1.7 的代码:
void resize(int newCapacity) { //传入新的容量
Entry[] oldTable = table; //引用扩容前的Entry数组
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) { //扩容前的数组大小如果已经达到最大(2^30)了
threshold = Integer.MAX_VALUE; //修改阈值为int的最大值(2^31-1),这样以后就不会扩容了
return;
}
Entry[] newTable = new Entry[newCapacity]; //初始化一个新的Entry数组
transfer(newTable); //!!将数据转移到新的Entry数组里
table = newTable; //HashMap的table属性引用新的Entry数组
threshold = (int)(newCapacity * loadFactor);//修改阈值
}
这里就是使用一个容量更大的数组来代替已有的容量小的数组,transfer()方法将原有Entry数组的元素拷贝到新的Entry数组里。
void transfer(Entry[] newTable) {
Entry[] src = table; //src引用了旧的Entry数组
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) { //遍历旧的Entry数组
Entry<K,V> e = src[j]; //取得旧Entry数组的每个元素
if (e != null) {
src[j] = null;//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象)
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity); //!!重新计算每个元素在数组中的位置
e.next = newTable[i]; //标记[1]
newTable[i] = e; //将元素放在数组上
e = next; //访问下一个Entry链上的元素
} while (e != null);
}
}
}
newTable[i] 的引用赋给了 e.next ,也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置;这样先放在一个索引上的元素终会被放到 Entry 链的尾部(如果发生了 hash 冲突的话)。
14. 一般用什么作为HashMap的key?
一般用Integer、String 这种不可变类当 HashMap 当 key,而且 String 最为常用。
- 因为字符串是不可变的,所以在它创建的时候 hashcode 就被缓存了,不需要重新计算。这就是 HashMap 中的键往往都使用字符串的原因。
- 因为获取对象的时候要用到 equals() 和 hashCode() 方法,那么键对象正确的重写这两个方法是非常重要的,这些类已经很规范的重写了 hashCode() 以及 equals() 方法。
15. HashMap为什么线程不安全?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fEQki3zf-1692793068255)(http://blog-img.coolsen.cn/img/HashMap为什么线程不安全.png)]
- 多线程下扩容死循环。JDK1.7中的 HashMap 使用头插法插入元素,在多线程的环境下,扩容的时候有可能导致环形链表的出现,形成死循环。因此,JDK1.8使用尾插法插入元素,在扩容时会保持链表元素原本的顺序,不会出现环形链表的问题。
- 多线程的put可能导致元素的丢失。多线程同时执行 put 操作,如果计算出来的索引位置是相同的,那会造成前一个 key 被后一个 key 覆盖,从而导致元素的丢失。此问题在JDK 1.7和 JDK 1.8 中都存在。
- put和get并发时,可能导致get为null。线程1执行put时,因为元素个数超出threshold而导致rehash,线程2此时执行get,有可能导致这个问题。此问题在JDK 1.7和 JDK 1.8 中都存在。
具体分析可见我的这篇文章:面试官:HashMap 为什么线程不安全?
16. ConcurrentHashMap 的实现原理是什么?
ConcurrentHashMap 在 JDK1.7 和 JDK1.8 的实现方式是不同的。
先来看下JDK1.7
JDK1.7中的ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成,即ConcurrentHashMap 把哈希桶切分成小数组(Segment ),每个小数组有 n 个 HashEntry 组成。
其中,Segment 继承了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色;HashEntry 用于存储键值对数据。
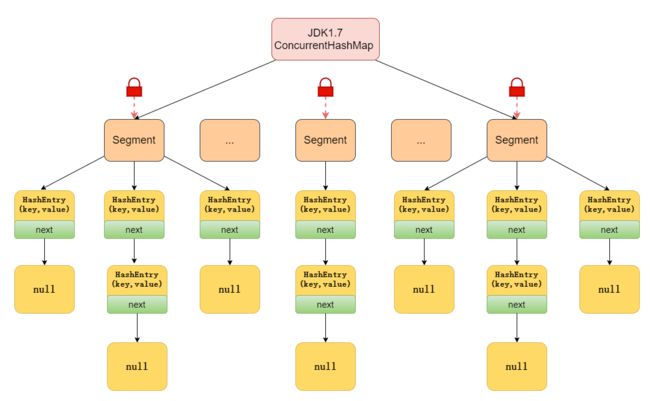
首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问,能够实现真正的并发访问。
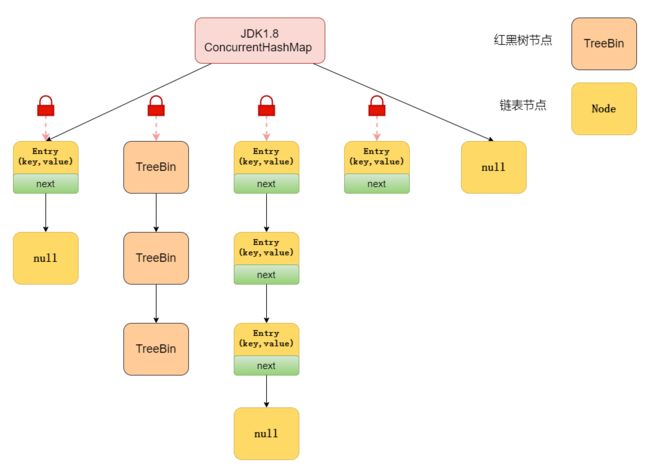
再来看下JDK1.8
在数据结构上, JDK1.8 中的ConcurrentHashMap 选择了与 HashMap 相同的数组+链表+红黑树结构;在锁的实现上,抛弃了原有的 Segment 分段锁,采用CAS + synchronized实现更加低粒度的锁。
将锁的级别控制在了更细粒度的哈希桶元素级别,也就是说只需要锁住这个链表头结点(红黑树的根节点),就不会影响其他的哈希桶元素的读写,大大提高了并发度。
17. ConcurrentHashMap 的 put 方法执行逻辑是什么?
先来看JDK1.7
首先,会尝试获取锁,如果获取失败,利用自旋获取锁;如果自旋重试的次数超过 64 次,则改为阻塞获取锁。
获取到锁后:
- 将当前 Segment 中的 table 通过 key 的 hashcode 定位到 HashEntry。
- 遍历该 HashEntry,如果不为空则判断传入的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value。
- 不为空则需要新建一个 HashEntry 并加入到 Segment 中,同时会先判断是否需要扩容。
- 释放 Segment 的锁。
再来看JDK1.8
大致可以分为以下步骤:
- 根据 key 计算出 hash值。
- 判断是否需要进行初始化。
- 定位到 Node,拿到首节点 f,判断首节点 f:
- 如果为 null ,则通过cas的方式尝试添加。
- 如果为
f.hash = MOVED = -1,说明其他线程在扩容,参与一起扩容。 - 如果都不满足 ,synchronized 锁住 f 节点,判断是链表还是红黑树,遍历插入。
- 当在链表长度达到8的时候,数组扩容或者将链表转换为红黑树。
源码分析可看这篇文章:面试 ConcurrentHashMap ,看这一篇就够了!
18. ConcurrentHashMap 的 get 方法是否要加锁,为什么?
get 方法不需要加锁。因为 Node 的元素 val 和指针 next 是用 volatile 修饰的,在多线程环境下线程A修改结点的val或者新增节点的时候是对线程B可见的。
这也是它比其他并发集合比如 Hashtable、用 Collections.synchronizedMap()包装的 HashMap 安全效率高的原因之一。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
//可以看到这些都用了volatile修饰
volatile V val;
volatile Node<K,V> next;
}
19. get方法不需要加锁与volatile修饰的哈希桶有关吗?
没有关系。哈希桶table用volatile修饰主要是保证在数组扩容的时候保证可见性。
static final class Segment<K,V> extends ReentrantLock implements Serializable {
// 存放数据的桶
transient volatile HashEntry<K,V>[] table;
20. ConcurrentHashMap 不支持 key 或者 value 为 null 的原因?
我们先来说value 为什么不能为 null ,因为ConcurrentHashMap 是用于多线程的 ,如果map.get(key)得到了 null ,无法判断,是映射的value是 null ,还是没有找到对应的key而为 null ,这就有了二义性。
而用于单线程状态的HashMap却可以用containsKey(key) 去判断到底是否包含了这个 null 。
我们用反证法来推理:
假设ConcurrentHashMap 允许存放值为 null 的value,这时有A、B两个线程,线程A调用ConcurrentHashMap .get(key)方法,返回为 null ,我们不知道这个 null 是没有映射的 null ,还是存的值就是 null 。
假设此时,返回为 null 的真实情况是没有找到对应的key。那么,我们可以用ConcurrentHashMap .containsKey(key)来验证我们的假设是否成立,我们期望的结果是返回false。
但是在我们调用ConcurrentHashMap .get(key)方法之后,containsKey方法之前,线程B执行了ConcurrentHashMap .put(key, null )的操作。那么我们调用containsKey方法返回的就是true了,这就与我们的假设的真实情况不符合了,这就有了二义性。
至于ConcurrentHashMap 中的key为什么也不能为 null 的问题,源码就是这样写的,哈哈。如果面试官不满意,就回答因为作者Doug不喜欢 null ,所以在设计之初就不允许了 null 的key存在。想要深入了解的小伙伴,可以看这篇文章这道面试题我真不知道面试官想要的回答是什么
21. ConcurrentHashMap 的并发度是多少?
在JDK1.7中,并发度默认是16,这个值可以在构造函数中设置。如果自己设置了并发度,ConcurrentHashMap 会使用大于等于该值的最小的2的幂指数作为实际并发度,也就是比如你设置的值是17,那么实际并发度是32。
22. ConcurrentHashMap 迭代器是强一致性还是弱一致性?
与HashMap迭代器是强一致性不同,ConcurrentHashMap 迭代器是弱一致性。
ConcurrentHashMap 的迭代器创建后,就会按照哈希表结构遍历每个元素,但在遍历过程中,内部元素可能会发生变化,如果变化发生在已遍历过的部分,迭代器就不会反映出来,而如果变化发生在未遍历过的部分,迭代器就会发现并反映出来,这就是弱一致性。
这样迭代器线程可以使用原来老的数据,而写线程也可以并发的完成改变,更重要的,这保证了多个线程并发执行的连续性和扩展性,是性能提升的关键。想要深入了解的小伙伴,可以看这篇文章[为什么ConcurrentHashMap 是弱一致的](http://ifeve.com/ConcurrentHashMap -weakly-consistent/)
23. JDK1.7与JDK1.8 中ConcurrentHashMap 的区别?
- 数据结构:取消了Segment分段锁的数据结构,取而代之的是数组+链表+红黑树的结构。
- 保证线程安全机制:JDK1.7采用Segment的分段锁机制实现线程安全,其中segment继承自ReentrantLock。JDK1.8 采用CAS+Synchronized保证线程安全。
- 锁的粒度:原来是对需要进行数据操作的Segment加锁,现调整为对每个数组元素加锁(Node)。
- 链表转化为红黑树:定位结点的hash算法简化会带来弊端,Hash冲突加剧,因此在链表节点数量大于8时,会将链表转化为红黑树进行存储。
- 查询时间复杂度:从原来的遍历链表O(n),变成遍历红黑树O(logN)。
24. ConcurrentHashMap 和Hashtable的效率哪个更高?为什么?
ConcurrentHashMap 的效率要高于Hashtable,因为Hashtable给整个哈希表加了一把大锁从而实现线程安全。而ConcurrentHashMap 的锁粒度更低,在JDK1.7中采用分段锁实现线程安全,在JDK1.8 中采用CAS+Synchronized实现线程安全。
25. 说一下Hashtable的锁机制 ?
Hashtable是使用Synchronized来实现线程安全的,给整个哈希表加了一把大锁,多线程访问时候,只要有一个线程访问或操作该对象,那其他线程只能阻塞等待需要的锁被释放,在竞争激烈的多线程场景中性能就会非常差!

26. 多线程下安全的操作 map还有其他方法吗?
还可以使用Collections.synchronizedMap方法,对方法进行加同步锁
private static class SynchronizedMap<K,V>
implements Map<K,V>, Serializable {
private static final long serialVersionUID = 1978198479659022715L;
private final Map<K,V> m; // Backing Map
final Object mutex; // Object on which to synchronize
SynchronizedMap(Map<K,V> m) {
this.m = Objects.requireNon null (m);
mutex = this;
}
SynchronizedMap(Map<K,V> m, Object mutex) {
this.m = m;
this.mutex = mutex;
}
// 省略部分代码
}
如果传入的是 HashMap 对象,其实也是对 HashMap 做的方法做了一层包装,里面使用对象锁来保证多线程场景下,线程安全,本质也是对 HashMap 进行全表锁。在竞争激烈的多线程环境下性能依然也非常差,不推荐使用!
27. HashSet 和 HashMap 区别?

补充HashSet的实现:HashSet的底层其实就是HashMap,只不过我们HashSet是实现了Set接口并且把数据作为K值,而V值一直使用一个相同的虚值来保存。如源码所示:
public boolean add(E e) {
return map.put(e, PRESENT)==null;// 调用HashMap的put方法,PRESENT是一个至始至终都相同的虚值
}
由于HashMap的K值本身就不允许重复,并且在HashMap中如果K/V相同时,会用新的V覆盖掉旧的V,然后返回旧的V,那么在HashSet中执行这一句话始终会返回一个false,导致插入失败,这样就保证了数据的不可重复性。
28. Collection框架中实现比较要怎么做?
第一种,实体类实现Comparable接口,并实现 compareTo(T t) 方法,称为内部比较器。
第二种,创建一个外部比较器,这个外部比较器要实现Comparator接口的 compare(T t1, T t2)方法。
29. Iterator 和 ListIterator 有什么区别?
- 遍历。使用Iterator,可以遍历所有集合,如Map,List,Set;但只能在向前方向上遍历集合中的元素。
使用ListIterator,只能遍历List实现的对象,但可以向前和向后遍历集合中的元素。
-
添加元素。Iterator无法向集合中添加元素;而,ListIteror可以向集合添加元素。
-
修改元素。Iterator无法修改集合中的元素;而,ListIterator可以使用set()修改集合中的元素。
-
索引。Iterator无法获取集合中元素的索引;而,使用ListIterator,可以获取集合中元素的索引。
30. 讲一讲快速失败(fail-fast)和安全失败(fail-safe)
快速失败(fail—fast)
-
在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception。
-
原理:迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。集合在被遍历期间如果内容发生变化,就会改变modCount的值。每当迭代器使用hashNext()/next()遍历下一个元素之前,都会检测modCount变量是否为expectedmodCount值,是的话就返回遍历;否则抛出异常,终止遍历。
-
注意:这里异常的抛出条件是检测到 modCount!=expectedmodCount 这个条件。如果集合发生变化时修改modCount值刚好又设置为了expectedmodCount值,则异常不会抛出。因此,不能依赖于这个异常是否抛出而进行并发操作的编程,这个异常只建议用于检测并发修改的bug。
-
场景:java.util包下的集合类都是快速失败的,不能在多线程下发生并发修改(迭代过程中被修改),比如HashMap、ArrayList 这些集合类。
安全失败(fail—safe)
-
采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。
-
原理:由于迭代时是对原集合的拷贝进行遍历,所以在遍历过程中对原集合所作的修改并不能被迭代器检测到,所以不会触发Concurrent Modification Exception。
-
缺点:基于拷贝内容的优点是避免了Concurrent Modification Exception,但同样地,迭代器并不能访问到修改后的内容,即:迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭代器是不知道的。
-
场景:java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使用,并发修改,比如:ConcurrentHashMap。
巨人的肩膀
https://juejin.cn/post/6844903966103306247
https://www.javazhiyin.com/71751.html
https://blog.csdn.net/qq_31780525/article/details/77431970
而是先复制原有集合内容,在拷贝的集合上进行遍历。
-
原理:由于迭代时是对原集合的拷贝进行遍历,所以在遍历过程中对原集合所作的修改并不能被迭代器检测到,所以不会触发Concurrent Modification Exception。
-
缺点:基于拷贝内容的优点是避免了Concurrent Modification Exception,但同样地,迭代器并不能访问到修改后的内容,即:迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭代器是不知道的。
-
场景:java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使用,并发修改,比如:ConcurrentHashMap。
三.MySql
基础

1. 数据库的三范式是什么?
- 第一范式:强调的是列的原子性,即数据库表的每一列都是不可分割的原子数据项。
- 第二范式:要求实体的属性完全依赖于主关键字。所谓完全 依赖是指不能存在仅依赖主关键字一部分的属性。
- 第三范式:任何非主属性不依赖于其它非主属性。
2. MySQL 支持哪些存储引擎?
MySQL 支持多种存储引擎,比如 InnoDB,MyISAM,Memory,Archive 等等.在大多数的情况下,直接选择使用 InnoDB 引擎都是最合适的,InnoDB 也是 MySQL 的默认存储引擎。
MyISAM 和 InnoDB 的区别有哪些:
- InnoDB 支持事务,MyISAM 不支持
- InnoDB 支持外键,而 MyISAM 不支持
- InnoDB 是聚集索引,数据文件是和索引绑在一起的,必须要有主键,通过主键索引效率很高;MyISAM 是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针,主键索引和辅助索引是独立的。
- Innodb 不支持全文索引,而 MyISAM 支持全文索引,查询效率上 MyISAM 要高;
- InnoDB 不保存表的具体行数,MyISAM 用一个变量保存了整个表的行数。
- MyISAM 采用表级锁(table-level locking);InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
3. 超键、候选键、主键、外键分别是什么?
- 超键:在关系中能唯一标识元组的属性集称为关系模式的超键。一个属性可以为作为一个超键,多个属性组合在一起也可以作为一个超键。超键包含候选键和主键。
- 候选键:是最小超键,即没有冗余元素的超键。
- 主键:数据库表中对储存数据对象予以唯一和完整标识的数据列或属性的组合。一个数据列只能有一个主键,且主键的取值不能缺失,即不能为空值(Null)。
- 外键:在一个表中存在的另一个表的主键称此表的外键。
4. SQL 约束有哪几种?
- NOT NULL: 用于控制字段的内容一定不能为空(NULL)。
- UNIQUE: 控件字段内容不能重复,一个表允许有多个 Unique 约束。
- PRIMARY KEY: 也是用于控件字段内容不能重复,但它在一个表只允许出现一个。
- FOREIGN KEY: 用于预防破坏表之间连接的动作,也能防止非法数据插入外键列,因为它必须是它指向的那个表中的值之一。
- CHECK: 用于控制字段的值范围。
5. MySQL 中的 varchar 和 char 有什么区别?
char 是一个定长字段,假如申请了char(10)的空间,那么无论实际存储多少内容.该字段都占用 10 个字符,而 varchar 是变长的,也就是说申请的只是最大长度,占用的空间为实际字符长度+1,最后一个字符存储使用了多长的空间.
在检索效率上来讲,char > varchar,因此在使用中,如果确定某个字段的值的长度,可以使用 char,否则应该尽量使用 varchar.例如存储用户 MD5 加密后的密码,则应该使用 char。
6. MySQL中 in 和 exists 区别
MySQL中的in语句是把外表和内表作hash 连接,而exists语句是对外表作loop循环,每次loop循环再对内表进行查询。一直大家都认为exists比in语句的效率要高,这种说法其实是不准确的。这个是要区分环境的。
如果查询的两个表大小相当,那么用in和exists差别不大。
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in。
not in 和not exists:如果查询语句使用了not in,那么内外表都进行全表扫描,没有用到索引;而not extsts的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
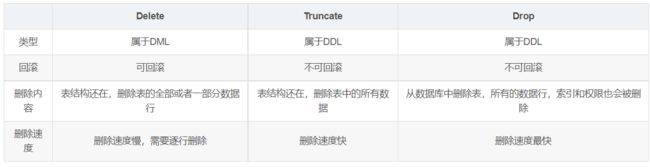
7. drop、delete与truncate的区别
三者都表示删除,但是三者有一些差别:
8. 什么是存储过程?有哪些优缺点?
存储过程是一些预编译的 SQL 语句。
1、更加直白的理解:存储过程可以说是一个记录集,它是由一些 T-SQL 语句组成的代码块,这些 T-SQL 语句代码像一个方法一样实现一些功能(对单表或多表的增删改查),然后再给这个代码块取一个名字,在用到这个功能的时候调用他就行了。
2、存储过程是一个预编译的代码块,执行效率比较高,一个存储过程替代大量 T_SQL 语句 ,可以降低网络通信量,提高通信速率,可以一定程度上确保数据安全
但是,在互联网项目中,其实是不太推荐存储过程的,比较出名的就是阿里的《Java 开发手册》中禁止使用存储过程,我个人的理解是,在互联网项目中,迭代太快,项目的生命周期也比较短,人员流动相比于传统的项目也更加频繁,在这样的情况下,存储过程的管理确实是没有那么方便,同时,复用性也没有写在服务层那么好。
9. MySQL 执行查询的过程
- 客户端通过 TCP 连接发送连接请求到 MySQL 连接器,连接器会对该请求进行权限验证及连接资源分配
- 查缓存。(当判断缓存是否命中时,MySQL 不会进行解析查询语句,而是直接使用 SQL 语句和客户端发送过来的其他原始信息。所以,任何字符上的不同,例如空格、注解等都会导致缓存的不命中。)
- 语法分析(SQL 语法是否写错了)。 如何把语句给到预处理器,检查数据表和数据列是否存在,解析别名看是否存在歧义。
- 优化。是否使用索引,生成执行计划。
- 交给执行器,将数据保存到结果集中,同时会逐步将数据缓存到查询缓存中,最终将结果集返回给客户端。

更新语句执行会复杂一点。需要检查表是否有排它锁,写 binlog,刷盘,是否执行 commit。
事务
1. 什么是数据库事务?
事务是一个不可分割的数据库操作序列,也是数据库并发控制的基本单位,其执行的结果必须使数据库从一种一致性状态变到另一种一致性状态。事务是逻辑上的一组操作,要么都执行,要么都不执行。
事务最经典也经常被拿出来说例子就是转账了。
假如小明要给小红转账1000元,这个转账会涉及到两个关键操作就是:将小明的余额减少1000元,将小红的余额增加1000元。万一在这两个操作之间突然出现错误比如银行系统崩溃,导致小明余额减少而小红的余额没有增加,这样就不对了。事务就是保证这两个关键操作要么都成功,要么都要失败。
2. 介绍一下事务具有的四个特征
事务就是一组原子性的操作,这些操作要么全部发生,要么全部不发生。事务把数据库从一种一致性状态转换成另一种一致性状态。
- 原子性。事务是数据库的逻辑工作单位,事务中包含的各操作要么都做,要么都不做
- 一致性。事 务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。因此当数据库只包含成功事务提交的结果时,就说数据库处于一致性状态。如果数据库系统 运行中发生故障,有些事务尚未完成就被迫中断,这些未完成事务对数据库所做的修改有一部分已写入物理数据库,这时数据库就处于一种不正确的状态,或者说是 不一致的状态。
- 隔离性。一个事务的执行不能其它事务干扰。即一个事务内部的//操作及使用的数据对其它并发事务是隔离的,并发执行的各个事务之间不能互相干扰。
- 持续性。也称永久性,指一个事务一旦提交,它对数据库中的数据的改变就应该是永久性的。接下来的其它操作或故障不应该对其执行结果有任何影响。
3. 说一下MySQL 的四种隔离级别
- Read Uncommitted(读取未提交内容)
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
- Read Committed(读取提交内容)
这是大多数数据库系统的默认隔离级别(但不是 MySQL 默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别 也支持所谓 的 不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的 commit,所以同一 select 可能返回不同结果。
- Repeatable Read(可重读)
这是 MySQL 的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。
- Serializable(可串行化)
通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
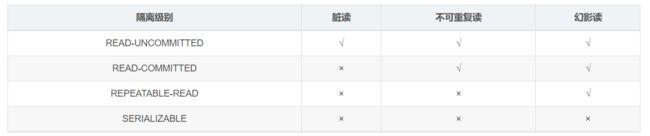
MySQL 默认采用的 REPEATABLE_READ隔离级别 Oracle 默认采用的 READ_COMMITTED隔离级别
事务隔离机制的实现基于锁机制和并发调度。其中并发调度使用的是MVVC(多版本并发控制),通过保存修改的旧版本信息来支持并发一致性读和回滚等特性。
因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是READ-COMMITTED(读取提交内容):,但是你要知道的是InnoDB 存储引擎默认使用 **REPEATABLE-READ(可重读)**并不会有任何性能损失。
InnoDB 存储引擎在 分布式事务 的情况下一般会用到**SERIALIZABLE(可串行化)**隔离级别。
4. 什么是脏读?幻读?不可重复读?
1、脏读:事务 A 读取了事务 B 更新的数据,然后 B 回滚操作,那么 A 读取到的数据是脏数据
2、不可重复读:事务 A 多次读取同一数据,事务 B 在事务 A 多次读取的过程中,对数据作了更新并提交,导致事务 A 多次读取同一数据时,结果 不一致。
3、幻读:系统管理员 A 将数据库中所有学生的成绩从具体分数改为 ABCDE 等级,但是系统管理员 B 就在这个时候插入了一条具体分数的记录,当系统管理员 A 改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
不可重复读侧重于修改,幻读侧重于新增或删除(多了或少量行),脏读是一个事务回滚影响另外一个事务。
5. 事务的实现原理
事务是基于重做日志文件(redo log)和回滚日志(undo log)实现的。
每提交一个事务必须先将该事务的所有日志写入到重做日志文件进行持久化,数据库就可以通过重做日志来保证事务的原子性和持久性。
每当有修改事务时,还会产生 undo log,如果需要回滚,则根据 undo log 的反向语句进行逻辑操作,比如 insert 一条记录就 delete 一条记录。undo log 主要实现数据库的一致性。
6. MySQL事务日志介绍下?
innodb 事务日志包括 redo log 和 undo log。
undo log 指事务开始之前,在操作任何数据之前,首先将需操作的数据备份到一个地方。redo log 指事务中操作的任何数据,将最新的数据备份到一个地方。
事务日志的目的:实例或者介质失败,事务日志文件就能派上用场。
redo log
redo log 不是随着事务的提交才写入的,而是在事务的执行过程中,便开始写入 redo 中。具体的落盘策略可以进行配置 。防止在发生故障的时间点,尚有脏页未写入磁盘,在重启 MySQL 服务的时候,根据 redo log 进行重做,从而达到事务的未入磁盘数据进行持久化这一特性。RedoLog 是为了实现事务的持久性而出现的产物。
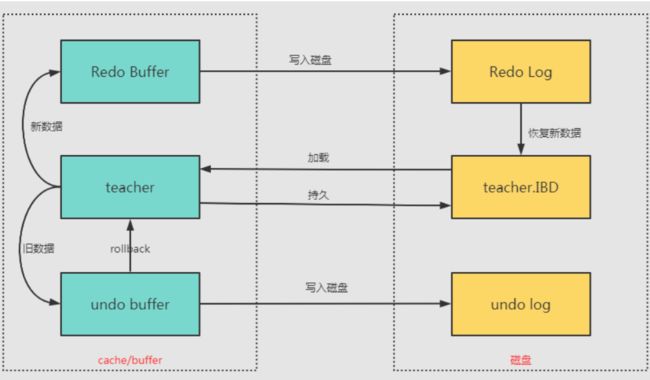
undo log
undo log 用来回滚行记录到某个版本。事务未提交之前,Undo 保存了未提交之前的版本数据,Undo 中的数据可作为数据旧版本快照供其他并发事务进行快照读。是为了实现事务的原子性而出现的产物,在 MySQL innodb 存储引擎中用来实现多版本并发控制。
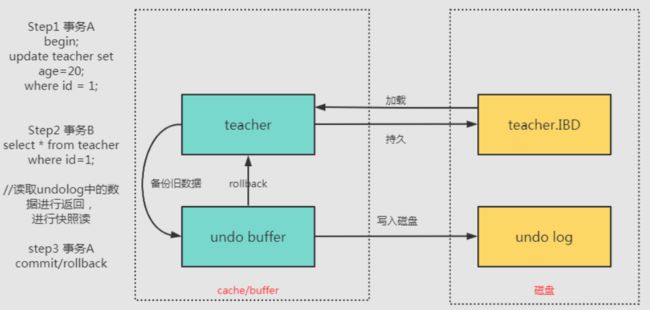
7. 什么是MySQL的 binlog?
MySQL的 binlog 是记录所有数据库表结构变更(例如 CREATE、ALTER TABLE)以及表数据修改(INSERT、UPDATE、DELETE)的二进制日志。binlog 不会记录 SELECT 和 SHOW 这类操作,因为这类操作对数据本身并没有修改,但你可以通过查询通用日志来查看 MySQL 执行过的所有语句。
MySQL binlog 以事件形式记录,还包含语句所执行的消耗的时间,MySQL 的二进制日志是事务安全型的。binlog 的主要目的是复制和恢复。
binlog 有三种格式,各有优缺点:
-
statement: 基于 SQL 语句的模式,某些语句和函数如 UUID, LOAD DATA INFILE 等在复制过程可能导致数据不一致甚至出错。
-
row: 基于行的模式,记录的是行的变化,很安全。但是 binlog 会比其他两种模式大很多,在一些大表中清除大量数据时在 binlog 中会生成很多条语句,可能导致从库延迟变大。
-
mixed: 混合模式,根据语句来选用是 statement 还是 row 模式。
8. 在事务中可以混合使用存储引擎吗?
尽量不要在同一个事务中使用多种存储引擎,MySQL服务器层不管理事务,事务是由下层的存储引擎实现的。
如果在事务中混合使用了事务型和非事务型的表(例如InnoDB和MyISAM表),在正常提交的情况下不会有什么问题。
但如果该事务需要回滚,非事务型的表上的变更就无法撤销,这会导致数据库处于不一致的状态,这种情况很难修复,事务的最终结果将无法确定。所以,为每张表选择合适的存储引擎非常重要。
9. MySQL中是如何实现事务隔离的?
读未提交和串行化基本上是不需要考虑的隔离级别,前者不加锁限制,后者相当于单线程执行,效率太差。
MySQL 在可重复读级别解决了幻读问题,是通过行锁和间隙锁的组合 Next-Key 锁实现的。
详细原理看这篇文章:https://haicoder.net/note/MySQL-interview/MySQL-interview-MySQL-trans-level.html
10. 什么是 MVCC?
MVCC, 即多版本并发控制。MVCC 的实现,是通过保存数据在某个时间点的快照来实现的。根据事务开始的时间不同,每个事务对同一张表,同一时刻看到的数据可能是不一样的。
11. MVCC 的实现原理
对于 InnoDB ,聚簇索引记录中包含 3 个隐藏的列:
- ROW ID:隐藏的自增 ID,如果表没有主键,InnoDB 会自动按 ROW ID 产生一个聚集索引树。
- 事务 ID:记录最后一次修改该记录的事务 ID。
- 回滚指针:指向这条记录的上一个版本。
我们拿上面的例子,对应解释下 MVCC 的实现原理,如下图:
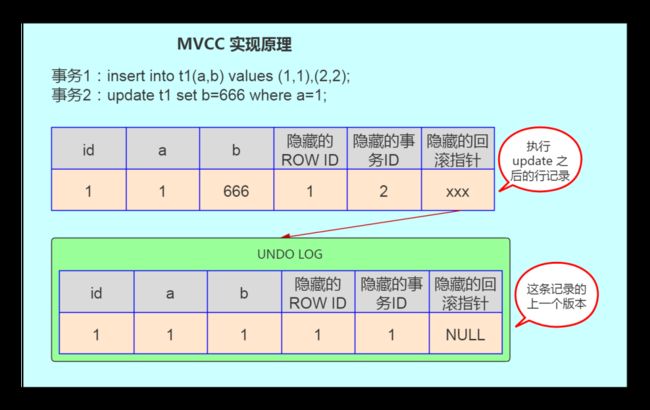
如图,首先 insert 语句向表 t1 中插入了一条数据,a 字段为 1,b 字段为 1, ROW ID 也为 1 ,事务 ID 假设为 1,回滚指针假设为 null。当执行 update t1 set b=666 where a=1 时,大致步骤如下:
- 数据库会先对满足 a=1 的行加排他锁;
- 然后将原记录复制到 undo 表空间中;
- 修改 b 字段的值为 666,修改事务 ID 为 2;
- 并通过隐藏的回滚指针指向 undo log 中的历史记录;
- 事务提交,释放前面对满足 a=1 的行所加的排他锁。
在前面实验的第 6 步中,session2 查询的结果是 session1 修改之前的记录,这个记录就是来自 undolog 中。
因此可以总结出 MVCC 实现的原理大致是:
InnoDB 每一行数据都有一个隐藏的回滚指针,用于指向该行修改前的最后一个历史版本,这个历史版本存放在 undo log 中。如果要执行更新操作,会将原记录放入 undo log 中,并通过隐藏的回滚指针指向 undo log 中的原记录。其它事务此时需要查询时,就是查询 undo log 中这行数据的最后一个历史版本。
MVCC 最大的好处是读不加锁,读写不冲突,极大地增加了 MySQL 的并发性。通过 MVCC,保证了事务 ACID 中的 I(隔离性)特性。
锁
1. 为什么要加锁?
当多个用户并发地存取数据时,在数据库中就会产生多个事务同时存取同一数据的情况。若对并发操作不加控制就可能会读取和存储不正确的数据,破坏数据库的一致性。
保证多用户环境下保证数据库完整性和一致性。
2. 按照锁的粒度分数据库锁有哪些?
在关系型数据库中,可以按照锁的粒度把数据库锁分为行级锁(INNODB引擎)、表级锁(MYISAM引擎)和页级锁(BDB引擎 )。
行级锁
- 行级锁是MySQL中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突。其加锁粒度最小,但加锁的开销也最大。行级锁分为共享锁 和 排他锁。
- 开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
表级锁
- 表级锁是MySQL中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分MySQL引擎支持。最常使用的MYISAM与INNODB都支持表级锁定。表级锁定分为表共享读锁(共享锁)与表独占写锁(排他锁)。
- 开销小,加锁快;不会出现死锁;锁定粒度大,发出锁冲突的概率最高,并发度最低。
页级锁
- 页级锁是MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。BDB支持页级锁
- 开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般
MyISAM和InnoDB存储引擎使用的锁:
- MyISAM采用表级锁(table-level locking)。
- InnoDB支持行级锁(row-level locking)和表级锁,默认为行级锁
3. 从锁的类别上分MySQL都有哪些锁呢?
从锁的类别上来讲,有共享锁和排他锁。
-
共享锁: 又叫做读锁。 当用户要进行数据的读取时,对数据加上共享锁。共享锁可以同时加上多个。
-
排他锁: 又叫做写锁。 当用户要进行数据的写入时,对数据加上排他锁。排他锁只可以加一个,他和其他的排他锁,共享锁都相斥。
用上面的例子来说就是用户的行为有两种,一种是来看房,多个用户一起看房是可以接受的。 一种是真正的入住一晚,在这期间,无论是想入住的还是想看房的都不可以。
锁的粒度取决于具体的存储引擎,InnoDB实现了行级锁,页级锁,表级锁。
他们的加锁开销从大到小,并发能力也是从大到小。
4. 数据库的乐观锁和悲观锁是什么?怎么实现的?
数据库管理系统(DBMS)中的并发控制的任务是确保在多个事务同时存取数据库中同一数据时不破坏事务的隔离性和统一性以及数据库的统一性。乐观并发控制(乐观锁)和悲观并发控制(悲观锁)是并发控制主要采用的技术手段。
-
悲观锁:假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作。在查询完数据的时候就把事务锁起来,直到提交事务。实现方式:使用数据库中的锁机制
-
乐观锁:假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性。在修改数据的时候把事务锁起来,通过version的方式来进行锁定。实现方式:乐一般会使用版本号机制或CAS算法实现。
两种锁的使用场景
从上面对两种锁的介绍,我们知道两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下(多读场景),即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。
但如果是多写的情况,一般会经常产生冲突,这就会导致上层应用会不断的进行retry,这样反倒是降低了性能,所以一般多写的场景下用悲观锁就比较合适。
5. InnoDB引擎的行锁是怎么实现的?
InnoDB是基于索引来完成行锁
例: select * from tab_with_index where id = 1 for update;
for update 可以根据条件来完成行锁锁定,并且 id 是有索引键的列,如果 id 不是索引键那么InnoDB将完成表锁,并发将无从谈起
6. 什么是死锁?怎么解决?
死锁是指两个或多个事务在同一资源上相互占用,并请求锁定对方的资源,从而导致恶性循环的现象。
常见的解决死锁的方法
1、如果不同程序会并发存取多个表,尽量约定以相同的顺序访问表,可以大大降低死锁机会。
2、在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率;
3、对于非常容易产生死锁的业务部分,可以尝试使用升级锁定颗粒度,通过表级锁定来减少死锁产生的概率;
如果业务处理不好可以用分布式事务锁或者使用乐观锁
7. 隔离级别与锁的关系
在Read Uncommitted级别下,读取数据不需要加共享锁,这样就不会跟被修改的数据上的排他锁冲突
在Read Committed级别下,读操作需要加共享锁,但是在语句执行完以后释放共享锁;
在Repeatable Read级别下,读操作需要加共享锁,但是在事务提交之前并不释放共享锁,也就是必须等待事务执行完毕以后才释放共享锁。
SERIALIZABLE 是限制性最强的隔离级别,因为该级别锁定整个范围的键,并一直持有锁,直到事务完成。
8. 优化锁方面的意见?
- 使用较低的隔离级别
- 设计索引,尽量使用索引去访问数据,加锁更加精确,从而减少锁冲突
- 选择合理的事务大小,给记录显示加锁时,最好一次性请求足够级别的锁。列如,修改数据的话,最好申请排他锁,而不是先申请共享锁,修改时在申请排他锁,这样会导致死锁
- 不同的程序访问一组表的时候,应尽量约定一个相同的顺序访问各表,对于一个表而言,尽可能的固定顺序的获取表中的行。这样大大的减少死锁的机会。
- 尽量使用相等条件访问数据,这样可以避免间隙锁对并发插入的影响
- 不要申请超过实际需要的锁级别
- 数据查询的时候不是必要,不要使用加锁。MySQL的MVCC可以实现事务中的查询不用加锁,优化事务性能:MVCC只在committed read(读提交)和 repeatable read (可重复读)两种隔离级别
- 对于特定的事务,可以使用表锁来提高处理速度活着减少死锁的可能。
分库分表
1. 为什么要分库分表?
分表
比如你单表都几千万数据了,你确定你能扛住么?绝对不行,单表数据量太大,会极大影响你的 sql执行的性能,到了后面你的 sql 可能就跑的很慢了。一般来说,就以我的经验来看,单表到几百万的时候,性能就会相对差一些了,你就得分表了。
分表就是把一个表的数据放到多个表中,然后查询的时候你就查一个表。比如按照用户 id 来分表,将一个用户的数据就放在一个表中。然后操作的时候你对一个用户就操作那个表就好了。这样可以控制每个表的数据量在可控的范围内,比如每个表就固定在 200 万以内。
分库
分库就是你一个库一般我们经验而言,最多支撑到并发 2000,一定要扩容了,而且一个健康的单库并发值你最好保持在每秒 1000 左右,不要太大。那么你可以将一个库的数据拆分到多个库中,访问的时候就访问一个库好了。
这就是所谓的分库分表。
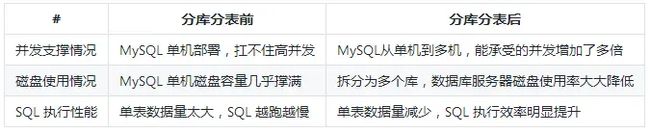
2. 用过哪些分库分表中间件?不同的分库分表中间件都有什么优点和缺点?
这个其实就是看看你了解哪些分库分表的中间件,各个中间件的优缺点是啥?然后你用过哪些分库分表的中间件。
比较常见的包括:
- cobar
- TDDL
- atlas
- sharding-jdbc
- mycat
cobar
阿里 b2b 团队开发和开源的,属于 proxy 层方案。早些年还可以用,但是最近几年都没更新了,基本没啥人用,差不多算是被抛弃的状态吧。而且不支持读写分离、存储过程、跨库 join 和分页等操作。
TDDL
淘宝团队开发的,属于 client 层方案。支持基本的 crud 语法和读写分离,但不支持 join、多表查询等语法。目前使用的也不多,因为还依赖淘宝的 diamond 配置管理系统。
atlas
360 开源的,属于 proxy 层方案,以前是有一些公司在用的,但是确实有一个很大的问题就是社区最新的维护都在 5 年前了。所以,现在用的公司基本也很少了。
sharding-jdbc
当当开源的,属于 client 层方案。确实之前用的还比较多一些,因为 SQL 语法支持也比较多,没有太多限制,而且目前推出到了 2.0 版本,支持分库分表、读写分离、分布式 id 生成、柔性事务(最大努力送达型事务、TCC 事务)。而且确实之前使用的公司会比较多一些(这个在官网有登记使用的公司,可以看到从 2017 年一直到现在,是有不少公司在用的),目前社区也还一直在开发和维护,还算是比较活跃,个人认为算是一个现在也可以选择的方案。
mycat
基于 cobar 改造的,属于 proxy 层方案,支持的功能非常完善,而且目前应该是非常火的而且不断流行的数据库中间件,社区很活跃,也有一些公司开始在用了。但是确实相比于 sharding jdbc 来说,年轻一些,经历的锤炼少一些。
3. 如何对数据库如何进行垂直拆分或水平拆分的?
水平拆分的意思,就是把一个表的数据给弄到多个库的多个表里去,但是每个库的表结构都一样,只不过每个库表放的数据是不同的,所有库表的数据加起来就是全部数据。水平拆分的意义,就是将数据均匀放更多的库里,然后用多个库来抗更高的并发,还有就是用多个库的存储容量来进行扩容。
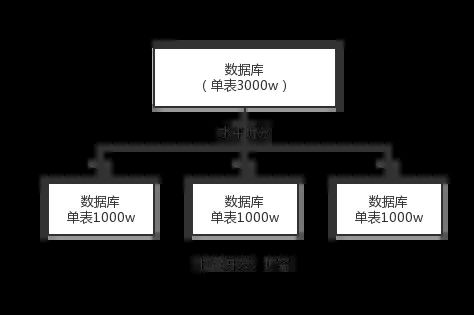
垂直拆分的意思,就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,会将较少的访问频率很高的字段放到一个表里去,然后将较多的访问频率很低的字段放到另外一个表里去。因为数据库是有缓存的,你访问频率高的行字段越少,就可以在缓存里缓存更多的行,性能就越好。这个一般在表层面做的较多一些。

两种分库分表的方式:
- 一种是按照 range 来分,就是每个库一段连续的数据,这个一般是按比如时间范围来的,但是这种一般较少用,因为很容易产生热点问题,大量的流量都打在最新的数据上了。
- 或者是按照某个字段hash一下均匀分散,这个较为常用。
range 来分,好处在于说,扩容的时候很简单,因为你只要预备好,给每个月都准备一个库就可以了,到了一个新的月份的时候,自然而然,就会写新的库了;缺点,但是大部分的请求,都是访问最新的数据。实际生产用 range,要看场景。
hash 分发,好处在于说,可以平均分配每个库的数据量和请求压力;坏处在于说扩容起来比较麻烦,会有一个数据迁移的过程,之前的数据需要重新计算 hash 值重新分配到不同的库或表
读写分离、主从同步(复制)
1. 什么是MySQL主从同步?
主从同步使得数据可以从一个数据库服务器复制到其他服务器上,在复制数据时,一个服务器充当主服务器(master),其余的服务器充当从服务器(slave)。
因为复制是异步进行的,所以从服务器不需要一直连接着主服务器,从服务器甚至可以通过拨号断断续续地连接主服务器。通过配置文件,可以指定复制所有的数据库,某个数据库,甚至是某个数据库上的某个表。
2. MySQL主从同步的目的?为什么要做主从同步?
- 通过增加从服务器来提高数据库的性能,在主服务器上执行写入和更新,在从服务器上向外提供读功能,可以动态地调整从服务器的数量,从而调整整个数据库的性能。
- 提高数据安全-因为数据已复制到从服务器,从服务器可以终止复制进程,所以,可以在从服务器上备份而不破坏主服务器相应数据
- 在主服务器上生成实时数据,而在从服务器上分析这些数据,从而提高主服务器的性能
- 数据备份。一般我们都会做数据备份,可能是写定时任务,一些特殊行业可能还需要手动备份,有些行业要求备份和原数据不能在同一个地方,所以主从就能很好的解决这个问题,不仅备份及时,而且还可以多地备份,保证数据的安全
3. 如何实现MySQL的读写分离?
其实很简单,就是基于主从复制架构,简单来说,就搞一个主库,挂多个从库,然后我们就单单只是写主库,然后主库会自动把数据给同步到从库上去。
4. MySQL主从复制流程和原理?
基本原理流程,是3个线程以及之间的关联
主:binlog线程——记录下所有改变了数据库数据的语句,放进master上的binlog中;
从:io线程——在使用start slave 之后,负责从master上拉取 binlog 内容,放进自己的relay log中;
从:sql执行线程——执行relay log中的语句;
复制过程如下:
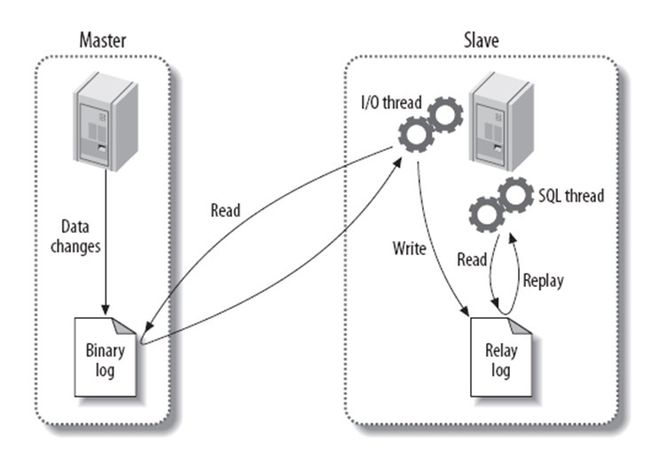
Binary log:主数据库的二进制日志
Relay log:从服务器的中继日志
第一步:master在每个事务更新数据完成之前,将该操作记录串行地写入到binlog文件中。
第二步:salve开启一个I/O Thread,该线程在master打开一个普通连接,主要工作是binlog dump process。如果读取的进度已经跟上了master,就进入睡眠状态并等待master产生新的事件。I/O线程最终的目的是将这些事件写入到中继日志中。
第三步:SQL Thread会读取中继日志,并顺序执行该日志中的SQL事件,从而与主数据库中的数据保持一致。
5. MySQL主从同步延时问题如何解决?
MySQL 实际上在有两个同步机制,一个是半同步复制,用来 解决主库数据丢失问题;一个是并行复制,用来 解决主从同步延时问题。
- 半同步复制,也叫 semi-sync 复制,指的就是主库写入 binlog 日志之后,就会将强制此时立即将数据同步到从库,从库将日志写入自己本地的 relay log 之后,接着会返回一个 ack 给主库,主库接收到至少一个从库的 ack 之后才会认为写操作完成了。
- 并行复制,指的是从库开启多个线程,并行读取 relay log 中不同库的日志,然后并行重放不同库的日志,这是库级别的并行。
优化
1. 如何定位及优化SQL语句的性能问题?
对于低性能的SQL语句的定位,最重要也是最有效的方法就是使用执行计划,MySQL提供了explain命令来查看语句的执行计划。 我们知道,不管是哪种数据库,或者是哪种数据库引擎,在对一条SQL语句进行执行的过程中都会做很多相关的优化,对于查询语句,最重要的优化方式就是使用索引。
而执行计划,就是显示数据库引擎对于SQL语句的执行的详细情况,其中包含了是否使用索引,使用什么索引,使用的索引的相关信息等。
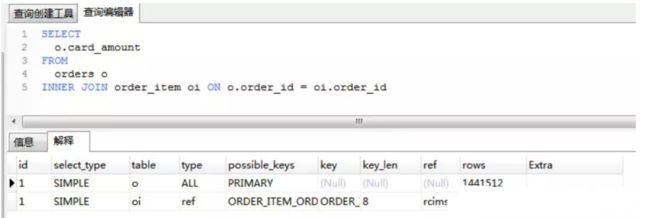
2. 大表数据查询,怎么优化
- 优化shema、sql语句+索引;
- 第二加缓存,memcached, redis;
- 主从复制,读写分离;
- 垂直拆分,根据你模块的耦合度,将一个大的系统分为多个小的系统,也就是分布式系统;
- 水平切分,针对数据量大的表,这一步最麻烦,最能考验技术水平,要选择一个合理的sharding key, 为了有好的查询效率,表结构也要改动,做一定的冗余,应用也要改,sql中尽量带sharding key,将数据定位到限定的表上去查,而不是扫描全部的表;
3. 超大分页怎么处理?
数据库层面,这也是我们主要集中关注的(虽然收效没那么大),类似于select * from table where age > 20 limit 1000000,10 这种查询其实也是有可以优化的余地的. 这条语句需要 load1000000 数据然后基本上全部丢弃,只取 10 条当然比较慢. 当时我们可以修改为select * from table where id in (select id from table where age > 20 limit 1000000,10).这样虽然也 load 了一百万的数据,但是由于索引覆盖,要查询的所有字段都在索引中,所以速度会很快。
解决超大分页,其实主要是靠缓存,可预测性的提前查到内容,缓存至redis等k-V数据库中,直接返回即可.
在阿里巴巴《Java开发手册》中,对超大分页的解决办法是类似于上面提到的第一种.
【推荐】利用延迟关联或者子查询优化超多分页场景。
说明:MySQL并不是跳过offset行,而是取offset+N行,然后返回放弃前offset行,返回N行,那当offset特别大的时候,效率就非常的低下,要么控制返回的总页数,要么对超过特定阈值的页数进行SQL改写。
正例:先快速定位需要获取的id段,然后再关联:
SELECT a.* FROM 表1 a, (select id from 表1 where 条件 LIMIT 100000,20 ) b where a.id=b.id
4. 统计过慢查询吗?对慢查询都怎么优化过?
在业务系统中,除了使用主键进行的查询,其他的我都会在测试库上测试其耗时,慢查询的统计主要由运维在做,会定期将业务中的慢查询反馈给我们。
慢查询的优化首先要搞明白慢的原因是什么? 是查询条件没有命中索引?是load了不需要的数据列?还是数据量太大?
所以优化也是针对这三个方向来的,
- 首先分析语句,看看是否load了额外的数据,可能是查询了多余的行并且抛弃掉了,可能是加载了许多结果中并不需要的列,对语句进行分析以及重写。
- 分析语句的执行计划,然后获得其使用索引的情况,之后修改语句或者修改索引,使得语句可以尽可能的命中索引。
- 如果对语句的优化已经无法进行,可以考虑表中的数据量是否太大,如果是的话可以进行横向或者纵向的分表。
5. 如何优化查询过程中的数据访问
- 访问数据太多导致查询性能下降
- 确定应用程序是否在检索大量超过需要的数据,可能是太多行或列
- 确认MySQL服务器是否在分析大量不必要的数据行
- 查询不需要的数据。解决办法:使用limit解决
- 多表关联返回全部列。解决办法:指定列名
- 总是返回全部列。解决办法:避免使用SELECT *
- 重复查询相同的数据。解决办法:可以缓存数据,下次直接读取缓存
- 是否在扫描额外的记录。解决办法:
使用explain进行分析,如果发现查询需要扫描大量的数据,但只返回少数的行,可以通过如下技巧去优化:
使用索引覆盖扫描,把所有的列都放到索引中,这样存储引擎不需要回表获取对应行就可以返回结果。 - 改变数据库和表的结构,修改数据表范式
- 重写SQL语句,让优化器可以以更优的方式执行查询。
6. 如何优化关联查询
- 确定ON或者USING子句中是否有索引。
- 确保GROUP BY和ORDER BY只有一个表中的列,这样MySQL才有可能使用索引。
7. 数据库结构优化
一个好的数据库设计方案对于数据库的性能往往会起到事半功倍的效果。
需要考虑数据冗余、查询和更新的速度、字段的数据类型是否合理等多方面的内容。
- 将字段很多的表分解成多个表
对于字段较多的表,如果有些字段的使用频率很低,可以将这些字段分离出来形成新表。
因为当一个表的数据量很大时,会由于使用频率低的字段的存在而变慢。
- 增加中间表
对于需要经常联合查询的表,可以建立中间表以提高查询效率。
通过建立中间表,将需要通过联合查询的数据插入到中间表中,然后将原来的联合查询改为对中间表的查询。
- 增加冗余字段
设计数据表时应尽量遵循范式理论的规约,尽可能的减少冗余字段,让数据库设计看起来精致、优雅。但是,合理的加入冗余字段可以提高查询速度。
表的规范化程度越高,表和表之间的关系越多,需要连接查询的情况也就越多,性能也就越差。
注意:
冗余字段的值在一个表中修改了,就要想办法在其他表中更新,否则就会导致数据不一致的问题。
8. MySQL数据库cpu飙升到500%的话他怎么处理?
当 cpu 飙升到 500%时,先用操作系统命令 top 命令观察是不是 MySQLd 占用导致的,如果不是,找出占用高的进程,并进行相关处理。
如果是 MySQLd 造成的, show processlist,看看里面跑的 session 情况,是不是有消耗资源的 sql 在运行。找出消耗高的 sql,看看执行计划是否准确, index 是否缺失,或者实在是数据量太大造成。
一般来说,肯定要 kill 掉这些线程(同时观察 cpu 使用率是否下降),等进行相应的调整(比如说加索引、改 sql、改内存参数)之后,再重新跑这些 SQL。
也有可能是每个 sql 消耗资源并不多,但是突然之间,有大量的 session 连进来导致 cpu 飙升,这种情况就需要跟应用一起来分析为何连接数会激增,再做出相应的调整,比如说限制连接数等。
9. 大表怎么优化?
类似的问题:某个表有近千万数据,CRUD比较慢,如何优化?分库分表了是怎么做的?分表分库了有什么问题?有用到中间件么?他们的原理知道么?
当MySQL单表记录数过大时,数据库的CRUD性能会明显下降,一些常见的优化措施如下:
- 限定数据的范围: 务必禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时候,我们可以控制在一个月的范围内;
- 读/写分离: 经典的数据库拆分方案,主库负责写,从库负责读;
- 缓存: 使用MySQL的缓存,另外对重量级、更新少的数据可以考虑;
- 通过分库分表的方式进行优化,主要有垂直分表和水平分表。
MySql索引
1. 索引是什么?
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。
索引是一种数据结构。数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用B树及其变种B+树。更通俗的说,索引就相当于目录。为了方便查找书中的内容,通过对内容建立索引形成目录。而且索引是一个文件,它是要占据物理空间的。
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。比如我们在查字典的时候,前面都有检索的拼音和偏旁、笔画等,然后找到对应字典页码,这样然后就打开字典的页数就可以知道我们要搜索的某一个key的全部值的信息了。
2. 索引有哪些优缺点?
索引的优点
- 可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
- 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
索引的缺点
- 时间方面:创建索引和维护索引要耗费时间,具体地,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,会降低增/改/删的执行效率;
- 空间方面:索引需要占物理空间。
3. MySQL有哪几种索引类型?
1、从存储结构上来划分:BTree索引(B-Tree或B+Tree索引),Hash索引,full-index全文索引,R-Tree索引。这里所描述的是索引存储时保存的形式,
2、从应用层次来分:普通索引,唯一索引,复合索引。
-
普通索引:即一个索引只包含单个列,一个表可以有多个单列索引
-
唯一索引:索引列的值必须唯一,但允许有空值
-
复合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并
-
聚簇索引(聚集索引):并不是一种单独的索引类型,而是一种数据存储方式。具体细节取决于不同的实现,InnoDB的聚簇索引其实就是在同一个结构中保存了B-Tree索引(技术上来说是B+Tree)和数据行。
-
非聚簇索引: 不是聚簇索引,就是非聚簇索引
3、根据中数据的物理顺序与键值的逻辑(索引)顺序关系: 聚集索引,非聚集索引。
4. 说一说索引的底层实现?
Hash索引
基于哈希表实现,只有精确匹配索引所有列的查询才有效,对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码(hash code),并且Hash索引将所有的哈希码存储在索引中,同时在索引表中保存指向每个数据行的指针。
图片来源:https://www.javazhiyin.com/40232.html

B-Tree索引(MySQL使用B+Tree)
B-Tree能加快数据的访问速度,因为存储引擎不再需要进行全表扫描来获取数据,数据分布在各个节点之中。

B+Tree索引
是B-Tree的改进版本,同时也是数据库索引索引所采用的存储结构。数据都在叶子节点上,并且增加了顺序访问指针,每个叶子节点都指向相邻的叶子节点的地址。相比B-Tree来说,进行范围查找时只需要查找两个节点,进行遍历即可。而B-Tree需要获取所有节点,相比之下B+Tree效率更高。
B+tree性质:
-
n棵子tree的节点包含n个关键字,不用来保存数据而是保存数据的索引。
-
所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
-
所有的非终端结点可以看成是索引部分,结点中仅含其子树中的最大(或最小)关键字。
-
B+ 树中,数据对象的插入和删除仅在叶节点上进行。
-
B+树有2个头指针,一个是树的根节点,一个是最小关键码的叶节点。

5. 为什么索引结构默认使用B+Tree,而不是B-Tree,Hash,二叉树,红黑树?
B-tree: 从两个方面来回答
-
B+树的磁盘读写代价更低:B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B(B-)树更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对
IO读写次数就降低了。 -
由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在
区间查询的情况,所以通常B+树用于数据库索引。
Hash:
- 虽然可以快速定位,但是没有顺序,IO复杂度高;
-
基于Hash表实现,只有Memory存储引擎显式支持哈希索引 ;
-
适合等值查询,如=、in()、<=>,不支持范围查询 ;
-
因为不是按照索引值顺序存储的,就不能像B+Tree索引一样利用索引完成排序 ;
-
Hash索引在查询等值时非常快 ;
-
因为Hash索引始终索引的所有列的全部内容,所以不支持部分索引列的匹配查找 ;
-
如果有大量重复键值得情况下,哈希索引的效率会很低,因为存在哈希碰撞问题 。
二叉树: 树的高度不均匀,不能自平衡,查找效率跟数据有关(树的高度),并且IO代价高。
红黑树: 树的高度随着数据量增加而增加,IO代价高。
6. 讲一讲聚簇索引与非聚簇索引?
在 InnoDB 里,索引B+ Tree的叶子节点存储了整行数据的是主键索引,也被称之为聚簇索引,即将数据存储与索引放到了一块,找到索引也就找到了数据。
而索引B+ Tree的叶子节点存储了主键的值的是非主键索引,也被称之为非聚簇索引、二级索引。
聚簇索引与非聚簇索引的区别:
-
非聚集索引与聚集索引的区别在于非聚集索引的叶子节点不存储表中的数据,而是存储该列对应的主键(行号)
-
对于InnoDB来说,想要查找数据我们还需要根据主键再去聚集索引中进行查找,这个再根据聚集索引查找数据的过程,我们称为回表。第一次索引一般是顺序IO,回表的操作属于随机IO。需要回表的次数越多,即随机IO次数越多,我们就越倾向于使用全表扫描 。
-
通常情况下, 主键索引(聚簇索引)查询只会查一次,而非主键索引(非聚簇索引)需要回表查询多次。当然,如果是覆盖索引的话,查一次即可
-
注意:MyISAM无论主键索引还是二级索引都是非聚簇索引,而InnoDB的主键索引是聚簇索引,二级索引是非聚簇索引。我们自己建的索引基本都是非聚簇索引。
7. 非聚簇索引一定会回表查询吗?
不一定,这涉及到查询语句所要求的字段是否全部命中了索引,如果全部命中了索引,那么就不必再进行回表查询。一个索引包含(覆盖)所有需要查询字段的值,被称之为"覆盖索引"。
举个简单的例子,假设我们在员工表的年龄上建立了索引,那么当进行select score from student where score > 90的查询时,在索引的叶子节点上,已经包含了score 信息,不会再次进行回表查询。
8. 联合索引是什么?为什么需要注意联合索引中的顺序?
MySQL可以使用多个字段同时建立一个索引,叫做联合索引。在联合索引中,如果想要命中索引,需要按照建立索引时的字段顺序挨个使用,否则无法命中索引。
具体原因为:
MySQL使用索引时需要索引有序,假设现在建立了"name,age,school"的联合索引,那么索引的排序为: 先按照name排序,如果name相同,则按照age排序,如果age的值也相等,则按照school进行排序。
当进行查询时,此时索引仅仅按照name严格有序,因此必须首先使用name字段进行等值查询,之后对于匹配到的列而言,其按照age字段严格有序,此时可以使用age字段用做索引查找,以此类推。因此在建立联合索引的时候应该注意索引列的顺序,一般情况下,将查询需求频繁或者字段选择性高的列放在前面。此外可以根据特例的查询或者表结构进行单独的调整。
9. 讲一讲MySQL的最左前缀原则?
最左前缀原则就是最左优先,在创建多列索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边。
mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式。
10. 讲一讲前缀索引?
因为可能我们索引的字段非常长,这既占内存空间,也不利于维护。所以我们就想,如果只把很长字段的前面的公共部分作为一个索引,就会产生超级加倍的效果。但是,我们需要注意,order by不支持前缀索引 。
流程是:
先计算完整列的选择性 : select count(distinct col_1)/count(1) from table_1
再计算不同前缀长度的选择性 :select count(distinct left(col_1,4))/count(1) from table_1
找到最优长度之后,创建前缀索引 : create index idx_front on table_1 (col_1(4))
11. 了解索引下推吗?
MySQL 5.6引入了索引下推优化。默认开启,使用SET optimizer_switch = ‘index_condition_pushdown=off’;可以将其关闭。
-
有了索引下推优化,可以在减少回表次数
-
在InnoDB中只针对二级索引有效
官方文档中给的例子和解释如下:
在 people_table中有一个二级索引(zipcode,lastname,address),查询是SELECT * FROM people WHERE zipcode=’95054′ AND lastname LIKE ‘%etrunia%’ AND address LIKE ‘%Main Street%’;
-
如果没有使用索引下推技术,则MySQL会通过zipcode=’95054’从存储引擎中查询对应的数据,返回到MySQL服务端,然后MySQL服务端基于lastname LIKE ‘%etrunia%’ and address LIKE ‘%Main Street%’来判断数据是否符合条件
-
如果使用了索引下推技术,则MYSQL首先会返回符合zipcode=’95054’的索引,然后根据lastname LIKE ‘%etrunia%’ and address LIKE ‘%Main Street%’来判断索引是否符合条件。如果符合条件,则根据该索引来定位对应的数据,如果不符合,则直接reject掉。
12. 怎么查看MySQL语句有没有用到索引?
通过explain,如以下例子:
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND title='Senior Engineer' AND from_date='1986-06-26';
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | filtered | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | titles | null | const | PRIMARY | PRIMARY | 59 | const,const,const | 10 | 1 |
-
id:在⼀个⼤的查询语句中每个SELECT关键字都对应⼀个唯⼀的id ,如explain select * from s1 where id = (select id from s1 where name = ‘egon1’);第一个select的id是1,第二个select的id是2。有时候会出现两个select,但是id却都是1,这是因为优化器把子查询变成了连接查询 。
-
select_type:select关键字对应的那个查询的类型,如SIMPLE,PRIMARY,SUBQUERY,DEPENDENT,SNION 。
-
table:每个查询对应的表名 。
-
type:
type字段比较重要, 它提供了判断查询是否高效的重要依据依据. 通过type字段, 我们判断此次查询是全表扫描还是索引扫描等。如const(主键索引或者唯一二级索引进行等值匹配的情况下),ref(普通的⼆级索引列与常量进⾏等值匹配),index(扫描全表索引的覆盖索引) 。通常来说, 不同的 type 类型的性能关系如下:
ALL < index < range ~ index_merge < ref < eq_ref < const < system
ALL类型因为是全表扫描, 因此在相同的查询条件下, 它是速度最慢的.
而index类型的查询虽然不是全表扫描, 但是它扫描了所有的索引, 因此比 ALL 类型的稍快. -
possible_key:查询中可能用到的索引*(可以把用不到的删掉,降低优化器的优化时间)* 。
-
key:此字段是 MySQL 在当前查询时所真正使用到的索引。
-
filtered:查询器预测满足下一次查询条件的百分比 。
-
rows 也是一个重要的字段. MySQL 查询优化器根据统计信息, 估算 SQL 要查找到结果集需要扫描读取的数据行数.
这个值非常直观显示 SQL 的效率好坏, 原则上 rows 越少越好。 -
extra:表示额外信息,如Using where,Start temporary,End temporary,Using temporary等。
13. 为什么官方建议使用自增长主键作为索引?
结合B+Tree的特点,自增主键是连续的,在插入过程中尽量减少页分裂,即使要进行页分裂,也只会分裂很少一部分。并且能减少数据的移动,每次插入都是插入到最后。总之就是减少分裂和移动的频率。
插入连续的数据:
图片来自:https://www.javazhiyin.com/40232.html

插入非连续的数据:

14. 如何创建索引?
创建索引有三种方式。
1、 在执行CREATE TABLE时创建索引
CREATE TABLE user_index2 (
id INT auto_increment PRIMARY KEY,
first_name VARCHAR (16),
last_name VARCHAR (16),
id_card VARCHAR (18),
information text,
KEY name (first_name, last_name),
FULLTEXT KEY (information),
UNIQUE KEY (id_card)
);
2、 使用ALTER TABLE命令去增加索引。
ALTER TABLE table_name ADD INDEX index_name (column_list);
ALTER TABLE用来创建普通索引、UNIQUE索引或PRIMARY KEY索引。
其中table_name是要增加索引的表名,column_list指出对哪些列进行索引,多列时各列之间用逗号分隔。
索引名index_name可自己命名,缺省时,MySQL将根据第一个索引列赋一个名称。另外,ALTER TABLE允许在单个语句中更改多个表,因此可以在同时创建多个索引。
3、 使用CREATE INDEX命令创建。
CREATE INDEX index_name ON table_name (column_list);
15. 创建索引时需要注意什么?
- 非空字段:应该指定列为NOT NULL,除非你想存储NULL。在mysql中,含有空值的列很难进行查询优化,因为它们使得索引、索引的统计信息以及比较运算更加复杂。你应该用0、一个特殊的值或者一个空串代替空值;
- 取值离散大的字段:(变量各个取值之间的差异程度)的列放到联合索引的前面,可以通过count()函数查看字段的差异值,返回值越大说明字段的唯一值越多字段的离散程度高;
- 索引字段越小越好:数据库的数据存储以页为单位一页存储的数据越多一次IO操作获取的数据越大效率越高。
16. 建索引的原则有哪些?
1、最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2、=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式。
3、尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录。
4、索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’)。
5、尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
17. 使用索引查询一定能提高查询的性能吗?
通常通过索引查询数据比全表扫描要快。但是我们也必须注意到它的代价。
索引需要空间来存储,也需要定期维护, 每当有记录在表中增减或索引列被修改时,索引本身也会被修改。 这意味着每条记录的I* NSERT,DELETE,UPDATE将为此多付出4,5 次的磁盘I/O。 因为索引需要额外的存储空间和处理,那些不必要的索引反而会使查询反应时间变慢。使用索引查询不一定能提高查询性能,索引范围查询(INDEX RANGE SCAN)适用于两种情况:
- 基于一个范围的检索,一般查询返回结果集小于表中记录数的30%。
- 基于非唯一性索引的检索。
18. 什么情况下不走索引(索引失效)?
1、使用!= 或者 <> 导致索引失效
2、类型不一致导致的索引失效
3、函数导致的索引失效
如:
SELECT * FROM `user` WHERE DATE(create_time) = '2020-09-03';
如果使用函数在索引列,这是不走索引的。
4、运算符导致的索引失效
SELECT * FROM `user` WHERE age - 1 = 20;
如果你对列进行了(+,-,*,/,!), 那么都将不会走索引。
5、OR引起的索引失效
SELECT * FROM `user` WHERE `name` = '张三' OR height = '175';
OR导致索引是在特定情况下的,并不是所有的OR都是使索引失效,如果OR连接的是同一个字段,那么索引不会失效,反之索引失效。
四.Spring
1. 使用Spring框架的好处是什么?
- **轻量:**Spring 是轻量的,基本的版本大约2MB
- **控制反转:**Spring通过控制反转实现了松散耦合,对象们给出它们的依赖,而不是创建或查找依赖的对象们
- **面向切面的编程(AOP):**Spring支持面向切面的编程,并且把应用业务逻辑和系统服务分开
- **容器:**Spring 包含并管理应用中对象的生命周期和配置
- **MVC框架:**Spring的WEB框架是个精心设计的框架,是Web框架的一个很好的替代品
- **事务管理:**Spring 提供一个持续的事务管理接口,可以扩展到上至本地事务下至全局事务(JTA)
- **异常处理:**Spring 提供方便的API把具体技术相关的异常(比如由JDBC,Hibernate or JDO抛出的)转化为一致的unchecked 异常。
2. 什么是 Spring IOC 容器?
Spring 框架的核心是 Spring 容器。容器创建对象,将它们装配在一起,配置它们并管理它们的完整生命周期。Spring 容器使用依赖注入来管理组成应用程序的组件。容器通过读取提供的配置元数据来接收对象进行实例化,配置和组装的指令。该元数据可以通过 XML,Java 注解或 Java 代码提供。
3. 什么是依赖注入?可以通过多少种方式完成依赖注入?
在依赖注入中,您不必创建对象,但必须描述如何创建它们。您不是直接在代码中将组件和服务连接在一起,而是描述配置文件中哪些组件需要哪些服务。由 IoC 容器将它们装配在一起。
通常,依赖注入可以通过三种方式完成,即:
- 构造函数注入
- setter 注入
- 接口注入
在 Spring Framework 中,仅使用构造函数和 setter 注入。
4. 区分 BeanFactory 和 ApplicationContext?
| BeanFactory | ApplicationContext |
|---|---|
| 它使用懒加载 | 它使用即时加载 |
| 它使用语法显式提供资源对象 | 它自己创建和管理资源对象 |
| 不支持国际化 | 支持国际化 |
| 不支持基于依赖的注解 | 支持基于依赖的注解 |
BeanFactory和ApplicationContext的优缺点分析:
BeanFactory的优缺点:
- 优点:应用启动的时候占用资源很少,对资源要求较高的应用,比较有优势;
- 缺点:运行速度会相对来说慢一些。而且有可能会出现空指针异常的错误,而且通过Bean工厂创建的Bean生命周期会简单一些。
ApplicationContext的优缺点:
- 优点:所有的Bean在启动的时候都进行了加载,系统运行的速度快;在系统启动的时候,可以发现系统中的配置问题。
- 缺点:把费时的操作放到系统启动中完成,所有的对象都可以预加载,缺点就是内存占用较大。
5. 区分构造函数注入和 setter 注入
| 构造函数注入 | setter 注入 |
|---|---|
| 没有部分注入 | 有部分注入 |
| 不会覆盖 setter 属性 | 会覆盖 setter 属性 |
| 任意修改都会创建一个新实例 | 任意修改不会创建一个新实例 |
| 适用于设置很多属性 | 适用于设置少量属性 |
6. spring 提供了哪些配置方式?
- 基于 xml 配置
bean 所需的依赖项和服务在 XML 格式的配置文件中指定。这些配置文件通常包含许多 bean 定义和特定于应用程序的配置选项。它们通常以 bean 标签开头。例如:
<bean id="studentbean" class="org.edureka.firstSpring.StudentBean">
<property name="name" value="Edureka">property>
bean>
- 基于注解配置
您可以通过在相关的类,方法或字段声明上使用注解,将 bean 配置为组件类本身,而不是使用 XML 来描述 bean 装配。默认情况下,Spring 容器中未打开注解装配。因此,您需要在使用它之前在 Spring 配置文件中启用它。例如:
<beans>
<context:annotation-config/>
beans>
- 基于 Java API 配置
Spring 的 Java 配置是通过使用 @Bean 和 @Configuration 来实现。
- @Bean 注解扮演与
- @Configuration 类允许通过简单地调用同一个类中的其他 @Bean 方法来定义 bean 间依赖关系。
例如:
@Configuration
public class StudentConfig {
@Bean
public StudentBean myStudent() {
return new StudentBean();
}
}
7. Spring 中的 bean 的作用域有哪些?
- singleton : 唯一 bean 实例,Spring 中的 bean 默认都是单例的。
- prototype : 每次请求都会创建一个新的 bean 实例。
- request : 每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP request内有效。
- session : :在一个HTTP Session中,一个Bean定义对应一个实例。该作用域仅在基于web的Spring ApplicationContext情形下有效。
- global-session: 全局session作用域,仅仅在基于portlet的web应用中才有意义,Spring5已经没有了。Portlet是能够生成语义代码(例如:HTML)片段的小型Java Web插件。它们基于portlet容器,可以像servlet一样处理HTTP请求。但是,与 servlet 不同,每个 portlet 都有不同的会话
8. 如何理解IoC和DI?
IOC就是控制反转,通俗的说就是我们不用自己创建实例对象,这些都交给Spring的bean工厂帮我们创建管理。这也是Spring的核心思想,通过面向接口编程的方式来是实现对业务组件的动态依赖。这就意味着IOC是Spring针对解决程序耦合而存在的。在实际应用中,Spring通过配置文件(xml或者properties)指定需要实例化的java类(类名的完整字符串),包括这些java类的一组初始化值,通过加载读取配置文件,用Spring提供的方法(getBean())就可以获取到我们想要的根据指定配置进行初始化的实例对象。
- 优点:IOC或依赖注入减少了应用程序的代码量。它使得应用程序的测试很简单,因为在单元测试中不再需要单例或JNDI查找机制。简单的实现以及较少的干扰机制使得松耦合得以实现。IOC容器支持勤性单例及延迟加载服务。
DI:DI—Dependency Injection,即“依赖注入”:组件之间依赖关系由容器在运行期决定,形象的说,即由容器动态的将某个依赖关系注入到组件之中。依赖注入的目的并非为软件系统带来更多功能,而是为了提升组件重用的频率,并为系统搭建一个灵活、可扩展的平台。通过依赖注入机制,我们只需要通过简单的配置,而无需任何代码就可指定目标需要的资源,完成自身的业务逻辑,而不需要关心具体的资源来自何处,由谁实现。
9. 将一个类声明为Spring的 bean 的注解有哪些?
我们一般使用 @Autowired 注解自动装配 bean,要想把类标识成可用于 @Autowired 注解自动装配的 bean 的类,采用以下注解可实现:
- @Component :通用的注解,可标注任意类为 Spring 组件。如果一个Bean不知道属于哪个层,可以使用@Component 注解标注。
8 @Repository : 对应持久层即 Dao 层,主要用于数据库相关操作。 - @Service : 对应服务层,主要涉及一些复杂的逻辑,需要用到 Dao层。
- @Controller : 对应 Spring MVC 控制层,主要用户接受用户请求并调用 Service 层返回数据给前端页面。
10. spring 支持几种 bean scope?
Spring bean 支持 5 种 scope:
- Singleton - 每个 Spring IoC 容器仅有一个单实例。
- Prototype - 每次请求都会产生一个新的实例。
- Request - 每一次 HTTP 请求都会产生一个新的实例,并且该 bean 仅在当前 HTTP 请求内有效。
- Session - 每一次 HTTP 请求都会产生一个新的 bean,同时该 bean 仅在当前 HTTP session 内有效。
- Global-session - 类似于标准的 HTTP Session 作用域,不过它仅仅在基于 portlet 的 web 应用中才有意义。Portlet 规范定义了全局 Session 的概念,它被所有构成某个 portlet web 应用的各种不同的 portlet 所共享。在 global session 作用域中定义的 bean 被限定于全局 portlet Session 的生命周期范围内。如果你在 web 中使用 global session 作用域来标识 bean,那么 web 会自动当成 session 类型来使用。
仅当用户使用支持 Web 的 ApplicationContext 时,最后三个才可用。
11. Spring 中的 bean 生命周期?
Bean的生命周期是由容器来管理的。主要在创建和销毁两个时期。

创建过程:
1,实例化bean对象,以及设置bean属性;
2,如果通过Aware接口声明了依赖关系,则会注入Bean对容器基础设施层面的依赖,Aware接口是为了感知到自身的一些属性。容器管理的Bean一般不需要知道容器的状态和直接使用容器。但是在某些情况下是需要在Bean中对IOC容器进行操作的。这时候需要在bean中设置对容器的感知。SpringIOC容器也提供了该功能,它是通过特定的Aware接口来完成的。
比如BeanNameAware接口,可以知道自己在容器中的名字。
如果这个Bean已经实现了BeanFactoryAware接口,可以用这个方式来获取其它Bean。
(如果Bean实现了BeanNameAware接口,调用setBeanName()方法,传入Bean的名字。
如果Bean实现了BeanClassLoaderAware接口,调用setBeanClassLoader()方法,传入ClassLoader对象的实例。
如果Bean实现了BeanFactoryAware接口,调用setBeanFactory()方法,传入BeanFactory对象的实例。)
3,紧接着会调用BeanPostProcess的前置初始化方法postProcessBeforeInitialization,主要作用是在Spring完成实例化之后,初始化之前,对Spring容器实例化的Bean添加自定义的处理逻辑。有点类似于AOP。
4,如果实现了BeanFactoryPostProcessor接口的afterPropertiesSet方法,做一些属性被设定后的自定义的事情。
5,调用Bean自身定义的init方法,去做一些初始化相关的工作。
6,调用BeanPostProcess的后置初始化方法,postProcessAfterInitialization去做一些bean初始化之后的自定义工作。
7,完成以上创建之后就可以在应用里使用这个Bean了。
销毁过程:
当Bean不再用到,便要销毁
1,若实现了DisposableBean接口,则会调用destroy方法;
2,若配置了destry-method属性,则会调用其配置的销毁方法;
总结
主要把握创建过程和销毁过程这两个大的方面;
创建过程:首先实例化Bean,并设置Bean的属性,根据其实现的Aware接口(主要是BeanFactoryAware接口,BeanFactoryAware,ApplicationContextAware)设置依赖信息,
接下来调用BeanPostProcess的postProcessBeforeInitialization方法,完成initial前的自定义逻辑;afterPropertiesSet方法做一些属性被设定后的自定义的事情;调用Bean自身定义的init方法,去做一些初始化相关的工作;然后再调用postProcessAfterInitialization去做一些bean初始化之后的自定义工作。这四个方法的调用有点类似AOP。
此时,Bean初始化完成,可以使用这个Bean了。
销毁过程:如果实现了DisposableBean的destroy方法,则调用它,如果实现了自定义的销毁方法,则调用之。
12. 什么是 spring 的内部 bean?
只有将 bean 用作另一个 bean 的属性时,才能将 bean 声明为内部 bean。为了定义 bean,Spring 的基于 XML 的配置元数据在
例如,假设我们有一个 Student 类,其中引用了 Person 类。这里我们将只创建一个 Person 类实例并在 Student 中使用它。
Student.java
public class Student {
private Person person;
//Setters and Getters
}
public class Person {
private String name;
private String address;
//Setters and Getters
}
bean.xml
<property name="person">
<bean class="com.edureka.Person">
property>
property>
bean>
property>
bean>
13. 什么是 spring 装配?
当 bean 在 Spring 容器中组合在一起时,它被称为装配或 bean 装配。 Spring 容器需要知道需要什么 bean 以及容器应该如何使用依赖注入来将 bean 绑定在一起,同时装配 bean。
Spring 容器能够自动装配 bean。也就是说,可以通过检查 BeanFactory 的内容让 Spring 自动解析 bean 的协作者。
自动装配的不同模式:
- no - 这是默认设置,表示没有自动装配。应使用显式 bean 引用进行装配。
- byName - 它根据 bean 的名称注入对象依赖项。它匹配并装配其属性与 XML 文件中由相同名称定义的 bean。
- byType - 它根据类型注入对象依赖项。如果属性的类型与 XML 文件中的一个 bean 名称匹配,则匹配并装配属性。
- 构造函数 - 它通过调用类的构造函数来注入依赖项。它有大量的参数。
- autodetect - 首先容器尝试通过构造函数使用 autowire 装配,如果不能,则尝试通过 byType 自动装配。
14. 自动装配有什么局限?
- 覆盖的可能性 - 您始终可以使用
- 基本元数据类型 - 简单属性(如原数据类型,字符串和类)无法自动装配。
- 令人困惑的性质 - 总是喜欢使用明确的装配,因为自动装配不太精确。
15. Spring中出现同名bean怎么办?
- 同一个配置文件内同名的Bean,以最上面定义的为准
- 不同配置文件中存在同名Bean,后解析的配置文件会覆盖先解析的配置文件
- 同文件中ComponentScan和@Bean出现同名Bean。同文件下@Bean的会生效,@ComponentScan扫描进来不会生效。通过@ComponentScan扫描进来的优先级是最低的,原因就是它扫描进来的Bean定义是最先被注册的~
16. Spring 怎么解决循环依赖问题?
spring对循环依赖的处理有三种情况:
①构造器的循环依赖:这种依赖spring是处理不了的,直 接抛出BeanCurrentlylnCreationException异常。
②单例模式下的setter循环依赖:通过“三级缓存”处理循环依赖。
③非单例循环依赖:无法处理。
下面分析单例模式下的setter循环依赖如何解决
Spring的单例对象的初始化主要分为三步:
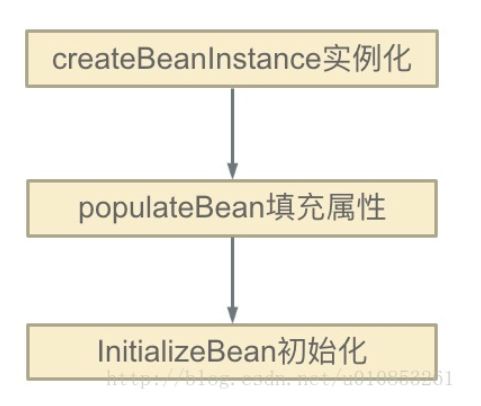
(1)createBeanInstance:实例化,其实也就是调用对象的构造方法实例化对象
(2)populateBean:填充属性,这一步主要是多bean的依赖属性进行填充
(3)initializeBean:调用spring xml中的init 方法。
从上面讲述的单例bean初始化步骤我们可以知道,循环依赖主要发生在第一、第二部。也就是构造器循环依赖和field循环依赖。

举例:A的某个field或者setter依赖了B的实例对象,同时B的某个field或者setter依赖了A的实例对象”这种循环依赖的情况。A首先完成了
初始化的第一步(createBeanINstance实例化),并且将自己提前曝光到singletonFactories中。
此时进行初始化的第二步,发现自己依赖对象B,此时就尝试去get(B),发现B还没有被create,所以走create流程,B在初始化第一步的时候发现自己依赖了对象A,于是尝试get(A),尝试一级缓存singletonObjects(肯定没有,因为A还没初始化完全),尝试二级缓存earlySingletonObjects(也没有),尝试三级缓存singletonFactories,由于A通过ObjectFactory将自己提前曝光了,所以B能够通过
ObjectFactory.getObject拿到A对象(虽然A还没有初始化完全,但是总比没有好呀),B拿到A对象后顺利完成了初始化阶段1、2、3,完全初始化之后将自己放入到一级缓存singletonObjects中。
此时返回A中,A此时能拿到B的对象顺利完成自己的初始化阶段2、3,最终A也完成了初始化,进去了一级缓存singletonObjects中,而且更加幸运的是,由于B拿到了A的对象引用,所以B现在hold住的A对象完成了初始化。
17. Spring 中的单例 bean 的线程安全问题?
当多个用户同时请求一个服务时,容器会给每一个请求分配一个线程,这时多个线程会并发执行该请求对应的业务逻辑(成员方法),此时就要注意了,如果该处理逻辑中有对单例状态的修改(体现为该单例的成员属性),则必须考虑线程同步问题。
线程安全问题都是由全局变量及静态变量引起的。
若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行写操作,一般都需要考虑线程同步,否则就可能影响线程安全.
无状态bean和有状态bean
- 有状态就是有数据存储功能。有状态对象(Stateful Bean),就是有实例变量的对象,可以保存数据,是非线程安全的。在不同方法调用间不保留任何状态。
- 无状态就是一次操作,不能保存数据。无状态对象(Stateless Bean),就是没有实例变量的对象 .不能保存数据,是不变类,是线程安全的。
在spring中无状态的Bean适合用不变模式,就是单例模式,这样可以共享实例提高性能。有状态的Bean在多线程环境下不安全,适合用Prototype原型模式。
Spring使用ThreadLocal解决线程安全问题。如果你的Bean有多种状态的话(比如 View Model 对象),就需要自行保证线程安全 。
18. 什么是 AOP?
AOP(Aspect-Oriented Programming), 即 面向切面编程, 它与 OOP( Object-Oriented Programming, 面向对象编程) 相辅相成, 提供了与 OOP 不同的抽象软件结构的视角.
在 OOP 中, 我们以类(class)作为我们的基本单元, 而 AOP 中的基本单元是 Aspect(切面)
19. AOP 有哪些实现方式?
实现 AOP 的技术,主要分为两大类:
- 静态代理 - 指使用 AOP 框架提供的命令进行编译,从而在编译阶段就可生成 AOP 代理类,因此也称为编译时增强;
- 编译时编织(特殊编译器实现)
- 类加载时编织(特殊的类加载器实现)。
- 动态代理 - 在运行时在内存中“临时”生成 AOP 动态代理类,因此也被称为运行时增强。
JDK动态代理:通过反射来接收被代理的类,并且要求被代理的类必须实现一个接口 。JDK 动态代理的核心是 InvocationHandler 接口和 Proxy 类 。CGLIB动态代理: 如果目标类没有实现接口,那么Spring AOP会选择使用CGLIB来动态代理目标类 。CGLIB( Code Generation Library ),是一个代码生成的类库,可以在运行时动态的生成某个类的子类,注意,CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为final,那么它是无法使用CGLIB做动态代理的。
20. Spring AOP and AspectJ AOP 有什么区别?
Spring AOP 基于动态代理方式实现;AspectJ 基于静态代理方式实现。
Spring AOP 仅支持方法级别的 PointCut;提供了完全的 AOP 支持,它还支持属性级别的 PointCut。
21. Spring 框架中用到了哪些设计模式?
工厂设计模式 : Spring使用工厂模式通过 BeanFactory、ApplicationContext 创建 bean 对象。
代理设计模式 : Spring AOP 功能的实现。
单例设计模式 : Spring 中的 Bean 默认都是单例的。
模板方法模式 : Spring 中 jdbcTemplate、hibernateTemplate 等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。
包装器设计模式 : 我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
观察者模式: Spring 事件驱动模型就是观察者模式很经典的一个应用。
适配器模式 :Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配Controller。
22. Spring 事务实现方式有哪些?
- 编程式事务管理:这意味着你可以通过编程的方式管理事务,这种方式带来了很大的灵活性,但很难维护。
- 声明式事务管理:这种方式意味着你可以将事务管理和业务代码分离。你只需要通过注解或者XML配置管理事务。
23. Spring框架的事务管理有哪些优点?
-
它提供了跨不同事务api(如JTA、JDBC、Hibernate、JPA和JDO)的一致编程模型。
-
它为编程事务管理提供了比JTA等许多复杂事务API更简单的API。
-
它支持声明式事务管理。
-
它很好地集成了Spring的各种数据访问抽象。
24. spring事务定义的传播规则
- PROPAGATION_REQUIRED: 支持当前事务,如果当前没有事务,就新建一个事务。这是最常见的选择。
- PROPAGATION_SUPPORTS: 支持当前事务,如果当前没有事务,就以非事务方式执行。
- PROPAGATION_MANDATORY: 支持当前事务,如果当前没有事务,就抛出异常。
- PROPAGATION_REQUIRES_NEW: 新建事务,如果当前存在事务,把当前事务挂起。
- PROPAGATION_NOT_SUPPORTED: 以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
- PROPAGATION_NEVER: 以非事务方式执行,如果当前存在事务,则抛出异常。
- PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则进行与PROPAGATION_REQUIRED类似的操作。
25. SpringMVC 工作原理了解吗?
原理如下图所示:
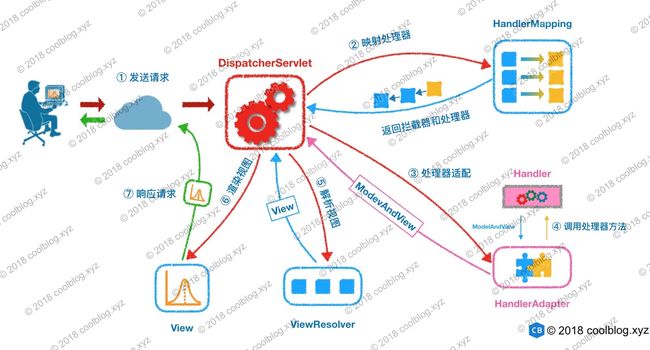
上图的一个笔误的小问题:Spring MVC 的入口函数也就是前端控制器 DispatcherServlet 的作用是接收请求,响应结果。
流程说明(重要):
- 客户端(浏览器)发送请求,直接请求到
DispatcherServlet。 DispatcherServlet根据请求信息调用HandlerMapping,解析请求对应的Handler。- 解析到对应的
Handler(也就是我们平常说的Controller控制器)后,开始由HandlerAdapter适配器处理。 HandlerAdapter会根据Handler来调用真正的处理器开处理请求,并处理相应的业务逻辑。- 处理器处理完业务后,会返回一个
ModelAndView对象,Model是返回的数据对象,View是个逻辑上的View。 ViewResolver会根据逻辑View查找实际的View。DispaterServlet把返回的Model传给View(视图渲染)。- 把
View返回给请求者(浏览器)
26. 简单介绍 Spring MVC 的核心组件
那么接下来就简单介绍一下 DispatcherServlet 和九大组件(按使用顺序排序的):
| 组件 | 说明 |
|---|---|
| DispatcherServlet | Spring MVC 的核心组件,是请求的入口,负责协调各个组件工作 |
| MultipartResolver | 内容类型( Content-Type )为 multipart/* 的请求的解析器,例如解析处理文件上传的请求,便于获取参数信息以及上传的文件 |
| HandlerMapping | 请求的处理器匹配器,负责为请求找到合适的 HandlerExecutionChain 处理器执行链,包含处理器(handler)和拦截器们(interceptors) |
| HandlerAdapter | 处理器的适配器。因为处理器 handler 的类型是 Object 类型,需要有一个调用者来实现 handler 是怎么被执行。Spring 中的处理器的实现多变,比如用户处理器可以实现 Controller 接口、HttpRequestHandler 接口,也可以用 @RequestMapping 注解将方法作为一个处理器等,这就导致 Spring MVC 无法直接执行这个处理器。所以这里需要一个处理器适配器,由它去执行处理器 |
| HandlerExceptionResolver | 处理器异常解析器,将处理器( handler )执行时发生的异常,解析( 转换 )成对应的 ModelAndView 结果 |
| RequestToViewNameTranslator | 视图名称转换器,用于解析出请求的默认视图名 |
| LocaleResolver | 本地化(国际化)解析器,提供国际化支持 |
| ThemeResolver | 主题解析器,提供可设置应用整体样式风格的支持 |
| ViewResolver | 视图解析器,根据视图名和国际化,获得最终的视图 View 对象 |
| FlashMapManager | FlashMap 管理器,负责重定向时,保存参数至临时存储(默认 Session) |
Spring MVC 对各个组件的职责划分的比较清晰。DispatcherServlet 负责协调,其他组件则各自做分内之事,互不干扰。
27. @Controller 注解有什么用?
@Controller 注解标记一个类为 Spring Web MVC 控制器 Controller。Spring MVC 会将扫描到该注解的类,然后扫描这个类下面带有 @RequestMapping 注解的方法,根据注解信息,为这个方法生成一个对应的处理器对象,在上面的 HandlerMapping 和 HandlerAdapter组件中讲到过。
当然,除了添加 @Controller 注解这种方式以外,你还可以实现 Spring MVC 提供的 Controller 或者 HttpRequestHandler 接口,对应的实现类也会被作为一个处理器对象
28. @RequestMapping 注解有什么用?
@RequestMapping 注解,在上面已经讲过了,配置处理器的 HTTP 请求方法,URI等信息,这样才能将请求和方法进行映射。这个注解可以作用于类上面,也可以作用于方法上面,在类上面一般是配置这个控制器的 URI 前缀
29. @RestController 和 @Controller 有什么区别?
@RestController 注解,在 @Controller 基础上,增加了 @ResponseBody 注解,更加适合目前前后端分离的架构下,提供 Restful API ,返回例如 JSON 数据格式。当然,返回什么样的数据格式,根据客户端的 ACCEPT 请求头来决定。
30. @RequestMapping 和 @GetMapping 注解的不同之处在哪里?
@RequestMapping:可注解在类和方法上;@GetMapping仅可注册在方法上@RequestMapping:可进行 GET、POST、PUT、DELETE 等请求方法;@GetMapping是@RequestMapping的 GET 请求方法的特例,目的是为了提高清晰度。
31. @RequestParam 和 @PathVariable 两个注解的区别
两个注解都用于方法参数,获取参数值的方式不同,@RequestParam 注解的参数从请求携带的参数中获取,而 @PathVariable 注解从请求的 URI 中获取
32. 返回 JSON 格式使用什么注解?
可以使用 @ResponseBody 注解,或者使用包含 @ResponseBody 注解的 @RestController 注解。
当然,还是需要配合相应的支持 JSON 格式化的 HttpMessageConverter 实现类。例如,Spring MVC 默认使用 MappingJackson2HttpMessageConverter。
33. 什么是springmvc拦截器以及如何使用它?
Spring的处理程序映射机制包括处理程序拦截器,当你希望将特定功能应用于某些请求时,例如,检查用户主题时,这些拦截器非常有用。拦截器必须实现org.springframework.web.servlet包的HandlerInterceptor。此接口定义了三种方法:
- preHandle:在执行实际处理程序之前调用。
- postHandle:在执行完实际程序之后调用。
- afterCompletion:在完成请求后调用。
34. Spring MVC 和 Struts2 的异同?
入口不同
- Spring MVC 的入门是一个 Servlet 控制器。
- Struts2 入门是一个 Filter 过滤器。
配置映射不同,
- Spring MVC 是基于方法开发,传递参数是通过方法形参,一般设置为单例。
- Struts2 是基于类开发,传递参数是通过类的属性,只能设计为多例。
视图不同
- Spring MVC 通过参数解析器是将 Request 对象内容进行解析成方法形参,将响应数据和页面封装成 ModelAndView 对象,最后又将模型数据通过 Request 对象传输到页面。其中,如果视图使用 JSP 时,默认使用 JSTL 。
- Struts2 采用值栈存储请求和响应的数据,通过 OGNL 存取数据。
35. REST 代表着什么?
REST 代表着抽象状态转移,它是根据 HTTP 协议从客户端发送数据到服务端,例如:服务端的一本书可以以 XML 或 JSON 格式传递到客户端
可以看看 REST API design and development ,知乎上的 《怎样用通俗的语言解释 REST,以及 RESTful?》了解。
36. 什么是安全的 REST 操作?
REST 接口是通过 HTTP 方法完成操作
- 一些 HTTP 操作是安全的,如 GET 和 HEAD ,它不能在服务端修改资源
- 换句话说,PUT、POST 和 DELETE 是不安全的,因为他们能修改服务端的资源
所以,是否安全的界限,在于是否修改服务端的资源
37. REST API 是无状态的吗?
是的,REST API 应该是无状态的,因为它是基于 HTTP 的,它也是无状态的
REST API 中的请求应该包含处理它所需的所有细节。它不应该依赖于以前或下一个请求或服务器端维护的一些数据,例如会话
REST 规范为使其无状态设置了一个约束,在设计 REST API 时,你应该记住这一点
38. REST安全吗? 你能做什么来保护它?
安全是一个宽泛的术语。它可能意味着消息的安全性,这是通过认证和授权提供的加密或访问限制提供的
REST 通常不是安全的,需要开发人员自己实现安全机制
39. 为什么要用SpringBoot?
在使用Spring框架进行开发的过程中,需要配置很多Spring框架包的依赖,如spring-core、spring-bean、spring-context等,而这些配置通常都是重复添加的,而且需要做很多框架使用及环境参数的重复配置,如开启注解、配置日志等。Spring Boot致力于弱化这些不必要的操作,提供默认配置,当然这些默认配置是可以按需修改的,快速搭建、开发和运行Spring应用。
以下是使用SpringBoot的一些好处:
- 自动配置,使用基于类路径和应用程序上下文的智能默认值,当然也可以根据需要重写它们以满足开发人员的需求。
- 创建Spring Boot Starter 项目时,可以选择选择需要的功能,Spring Boot将为你管理依赖关系。
- SpringBoot项目可以打包成jar文件。可以使用Java-jar命令从命令行将应用程序作为独立的Java应用程序运行。
- 在开发web应用程序时,springboot会配置一个嵌入式Tomcat服务器,以便它可以作为独立的应用程序运行。(Tomcat是默认的,当然你也可以配置Jetty或Undertow)
- SpringBoot包括许多有用的非功能特性(例如安全和健康检查)。
40. Spring Boot中如何实现对不同环境的属性配置文件的支持?
Spring Boot支持不同环境的属性配置文件切换,通过创建application-{profile}.properties文件,其中{profile}是具体的环境标识名称,例如:application-dev.properties用于开发环境,application-test.properties用于测试环境,application-uat.properties用于uat环境。如果要想使用application-dev.properties文件,则在application.properties文件中添加spring.profiles.active=dev。
如果要想使用application-test.properties文件,则在application.properties文件中添加spring.profiles.active=test。
41. Spring Boot 的核心注解是哪个?它主要由哪几个注解组成的?
启动类上面的注解是@SpringBootApplication,它也是 Spring Boot 的核心注解,主要组合包含了以下 3 个注解:
@SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
@EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项,如关闭数据源自动配置功能: @SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })。
@ComponentScan:Spring组件扫描。
42. 你如何理解 Spring Boot 中的 Starters?
Starters可以理解为启动器,它包含了一系列可以集成到应用里面的依赖包,你可以一站式集成 Spring 及其他技术,而不需要到处找示例代码和依赖包。如你想使用 Spring JPA 访问数据库,只要加入 spring-boot-starter-data-jpa 启动器依赖就能使用了。
Starters包含了许多项目中需要用到的依赖,它们能快速持续的运行,都是一系列得到支持的管理传递性依赖。
43. Spring Boot Starter 的工作原理是什么?
Spring Boot 在启动的时候会干这几件事情:
- Spring Boot 在启动时会去依赖的 Starter 包中寻找 resources/META-INF/spring.factories 文件,然后根据文件中配置的 Jar 包去扫描项目所依赖的 Jar 包。
- 根据 spring.factories 配置加载 AutoConfigure 类
- 根据 @Conditional 注解的条件,进行自动配置并将 Bean 注入 Spring Context
总结一下,其实就是 Spring Boot 在启动的时候,按照约定去读取 Spring Boot Starter 的配置信息,再根据配置信息对资源进行初始化,并注入到 Spring 容器中。这样 Spring Boot 启动完毕后,就已经准备好了一切资源,使用过程中直接注入对应 Bean 资源即可
44. 保护 Spring Boot 应用有哪些方法?
- 在生产中使用HTTPS
- 使用Snyk检查你的依赖关系
- 升级到最新版本
- 启用CSRF保护
- 使用内容安全策略防止XSS攻击
45. Spring 、Spring Boot 和 Spring Cloud 的关系?
Spring 最初最核心的两大核心功能 Spring Ioc 和 Spring Aop 成就了 Spring,Spring 在这两大核心的功能上不断的发展,才有了 Spring 事务、Spring Mvc 等一系列伟大的产品,最终成就了 Spring 帝国,到了后期 Spring 几乎可以解决企业开发中的所有问题。
Spring Boot 是在强大的 Spring 帝国生态基础上面发展而来,发明 Spring Boot 不是为了取代 Spring ,是为了让人们更容易的使用 Spring 。
Spring Cloud 是一系列框架的有序集合。它利用 Spring Boot 的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用 Spring Boot 的开发风格做到一键启动和部署。
Spring Cloud 是为了解决微服务架构中服务治理而提供的一系列功能的开发框架,并且 Spring Cloud 是完全基于 Spring Boot 而开发,Spring Cloud 利用 Spring Boot 特性整合了开源行业中优秀的组件,整体对外提供了一套在微服务架构中服务治理的解决方案。
用一组不太合理的包含关系来表达它们之间的关系。
Spring ioc/aop > Spring > Spring Boot > Spring Cloud
参考
https://juejin.cn/post/6844903860658503693
https://www.cnblogs.com/jingmoxukong/p/9408037.html
ring Boot 不是为了取代 Spring ,是为了让人们更容易的使用 Spring 。
Spring Cloud 是一系列框架的有序集合。它利用 Spring Boot 的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用 Spring Boot 的开发风格做到一键启动和部署。
Spring Cloud 是为了解决微服务架构中服务治理而提供的一系列功能的开发框架,并且 Spring Cloud 是完全基于 Spring Boot 而开发,Spring Cloud 利用 Spring Boot 特性整合了开源行业中优秀的组件,整体对外提供了一套在微服务架构中服务治理的解决方案。
用一组不太合理的包含关系来表达它们之间的关系。
Spring ioc/aop > Spring > Spring Boot > Spring Cloud
五.MyBatis
1. MyBatis是什么?
- Mybatis是一个半ORM(对象关系映射)框架,它内部封装了JDBC,加载驱动、创建连接、创建statement等繁杂的过程,开发者开发时只需要关注如何编写SQL语句,可以严格控制sql执行性能,灵活度高。
- 作为一个半ORM框架,MyBatis 可以使用 XML 或注解来配置和映射原生信息,将 POJO映射成数据库中的记录,避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。
- 通过xml 文件或注解的方式将要执行的各种 statement 配置起来,并通过java对象和 statement中sql的动态参数进行映射生成最终执行的sql语句,最后由mybatis框架执行sql并将结果映射为java对象并返回。(从执行sql到返回result的过程)。
- 由于MyBatis专注于SQL本身,灵活度高,所以比较适合对性能的要求很高,或者需求变化较多的项目,如互联网项目。
2. Mybaits的优缺点
优点:
- 基于SQL语句编程,相当灵活,不会对应用程序或者数据库的现有设计造成任何影响,SQL写在XML里,解除sql与程序代码的耦合,便于统一管理;提供XML标签,支持编写动态SQL语句,并可重用。
- 与JDBC相比,减少了50%以上的代码量,消除了JDBC大量冗余的代码,不需要手动开关连接;
- 很好的与各种数据库兼容(因为MyBatis使用JDBC来连接数据库,所以只要JDBC支持的数据库MyBatis都支持)。
- 能够与Spring很好的集成;
- 提供映射标签,支持对象与数据库的ORM字段关系映射;提供对象关系映射标签,支持对象关系组件维护。
缺点:
- SQL语句的编写工作量较大,尤其当字段多、关联表多时,对开发人员编写SQL语句的功底有一定要求。
- SQL语句依赖于数据库,导致数据库移植性差,不能随意更换数据库。
3. 为什么说Mybatis是半自动ORM映射工具?它与全自动的区别在哪里?
Hibernate属于全自动ORM映射工具,使用Hibernate查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全自动的。
而Mybatis在查询关联对象或关联集合对象时,需要手动编写sql来完成,所以,称之为半自动ORM映射工具。
4. Hibernate 和 MyBatis 的区别
相同点:都是对jdbc的封装,都是持久层的框架,都用于dao层的开发。
不同点
1、映射关系
MyBatis 是一个半自动映射的框架,配置Java对象与sql语句执行结果的对应关系,多表关联关系配置简单。
Hibernate 是一个全表映射的框架,配置Java对象与数据库表的对应关系,多表关联关系配置复杂。
2、 SQL优化和移植性
Hibernate 对SQL语句封装,提供了日志、缓存、级联(级联比 MyBatis 强大)等特性,此外还提供 HQL(Hibernate Query Language)操作数据库,数据库无关性支持好,但会多消耗性能。如果项目需要支持多种数据库,代码开发量少,但SQL语句优化困难。
MyBatis 需要手动编写 SQL,支持动态 SQL、处理列表、动态生成表名、支持存储过程。开发工作量相对大些。直接使用SQL语句操作数据库,不支持数据库无关性,但sql语句优化容易。
3、开发难易程度和学习成本
Hibernate 是重量级框架,学习使用门槛高,适合于需求相对稳定,中小型的项目,比如:办公自动化系统
MyBatis 是轻量级框架,学习使用门槛低,适合于需求变化频繁,大型的项目,比如:互联网电子商务系统
总结
MyBatis 是一个小巧、方便、高效、简单、直接、半自动化的持久层框架,
Hibernate 是一个强大、方便、高效、复杂、间接、全自动化的持久层框架。
5. JDBC编程有哪些不足之处,MyBatis是如何解决这些问题的?
1、数据库链接创建、释放频繁造成系统资源浪费从而影响系统性能,如果使用数据库链接池可解决此问题。
解决:在SqlMapConfig.xml中配置数据链接池,使用连接池管理数据库链接。
2、Sql语句写在代码中造成代码不易维护,实际应用sql变化的可能较大,sql变动需要改变java代码。
解决:将Sql语句配置在XXXXmapper.xml文件中与java代码分离。
3、 向sql语句传参数麻烦,因为sql语句的where条件不一定,可能多也可能少,占位符需要和参数一一对应。
解决: Mybatis自动将java对象映射至sql语句。
4、 对结果集解析麻烦,sql变化导致解析代码变化,且解析前需要遍历,如果能将数据库记录封装成pojo对象解析比较方便。
解决:Mybatis自动将sql执行结果映射至java对象。
6. MyBatis编程步骤是什么样的?
1、创建SqlSessionFactory
2、通过SqlSessionFactory创建SqlSession
3、 通过sqlsession执行数据库操作
4、 调用session.commit()提交事务
5、 调用session.close()关闭会话
7. MyBatis与Hibernate有哪些不同?
1、Mybatis 和 hibernate 不同,它不完全是一个 ORM 框架,因为 MyBatis 需要 程序员自己编写 Sql 语句。
2、Mybatis 直接编写原生态 sql,可以严格控制 sql 执行性能,灵活度高,非常 适合对关系数据模型要求不高的软件开发,因为这类软件需求变化频繁,一但需 求变化要求迅速输出成果。但是灵活的前提是 mybatis 无法做到数据库无关性, 如果需要实现支持多种数据库的软件,则需要自定义多套 sql 映射文件,工作量大。
3、Hibernate 对象/关系映射能力强,数据库无关性好,对于关系模型要求高的 软件,如果用 hibernate 开发可以节省很多代码,提高效率
8. Mybaits 的优点:
1、基于 SQL 语句编程,相当灵活,不会对应用程序或者数据库的现有设计造成任 何影响,SQL 写在 XML 里,解除 sql 与程序代码的耦合,便于统一管理;提供 XML 标签,支持编写动态 SQL 语句,并可重用。
2、与 JDBC 相比,减少了 50%以上的代码量,消除了 JDBC 大量冗余的代码,不 需要手动开关连接;
3、很好的与各种数据库兼容(因为 MyBatis 使用 JDBC 来连接数据库,所以只要 JDBC 支持的数据库 MyBatis 都支持)。
4、能够与 Spring 很好的集成; 5、提供映射标签,支持对象与数据库的 ORM 字段关系映射;提供对象关系映射 标签,支持对象关系组件维护
9. MyBatis 框架的缺点:
1、SQL 语句的编写工作量较大,尤其当字段多、关联表多时,对开发人员编写 SQL 语句的功底有一定要求。
2、SQL 语句依赖于数据库,导致数据库移植性差,不能随意更换数据库。
10. #{}和${}的区别?
- #{}是占位符,预编译处理;${}是拼接符,字符串替换,没有预编译处理。
- Mybatis在处理#{}时,#{}传入参数是以字符串传入,会将SQL中的#{}替换为?号,调用PreparedStatement的set方法来赋值。
- Mybatis在处理时 , 是 原 值 传 入 , 就 是 把 {}时,是原值传入,就是把时,是原值传入,就是把{}替换成变量的值,相当于JDBC中的Statement编译
- 变量替换后,#{} 对应的变量自动加上单引号 ‘’;变量替换后,${} 对应的变量不会加上单引号 ‘’
- #{} 可以有效的防止SQL注入,提高系统安全性;${} 不能防止SQL 注入
- #{} 的变量替换是在DBMS 中;${} 的变量替换是在 DBMS 外
11. 通常一个Xml映射文件,都会写一个Dao接口与之对应,那么这个Dao接口的工作原理是什么?Dao接口里的方法、参数不同时,方法能重载吗?
Dao接口即Mapper接口。接口的全限名就是映射文件中的namespace的值;接口的方法名,就是映射文件中Mapper的Statement的id值;接口方法内的参数,就是传递给sql的参数。Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名的拼接字符串作为key值,可唯一定位一个MapperStatement。
Dao接口里的方法,是不能重载的,因为是全限名+方法名的保存和寻找策略。
Dao接口的工作原理是JDK动态代理,Mybatis运行时会使用JDK动态代理为Dao接口生成代理proxy对象,代理对象proxy会拦截接口方法,转而执行MappedStatement所代表的sql,然后将sql执行结果返回。
12. 在Mapper中如何传递多个参数?
1、若Dao层函数有多个参数,那么其对应的xml中,#{0}代表接收的是Dao层中的第一个参数,#{1}代表Dao中的第二个参数,以此类推。
2、使用@Param注解:在Dao层的参数中前加@Param注解,注解内的参数名为传递到Mapper中的参数名。
3、多个参数封装成Map,以HashMap的形式传递到Mapper中。
13. Mybatis动态sql有什么用?执行原理是什么?有哪些动态sql?
Mybatis动态sql可以在xml映射文件内,以标签的形式编写动态sql,执行原理是根据表达式的值完成逻辑判断,并动态拼接sql的功能。
Mybatis提供了9种动态sql标签:trim、where、set、foreach、if、choose、when、otherwise、bind
14. xml映射文件中,不同的xml映射文件id是否可以重复?
不同的xml映射文件,如果配置了namespace,那么id可以重复;如果没有配置namespace,那么id不能重复;
原因是namespace+id是作为Map
15. Mybatis实现一对一有几种方式?具体是怎么操作的?
有联合查询和嵌套查询两种方式。
联合查询是几个表联合查询,通过在resultMap里面配置association节点配置一对一的类就可以完成;
嵌套查询是先查一个表,根据这个表里面的结果的外键id,再去另外一个表里面查询数据,也是通过association配置,但另外一个表的查询是通过select配置的。
16. Mybatis实现一对多有几种方式?具体是怎么操作的?
有联合查询和嵌套查询两种方式。
联合查询是几个表联合查询,只查询一次,通过在resultMap里面的collection节点配置一对多的类就可以完成;
嵌套查询是先查一个表,根据这个表里面的结果的外键id,再去另外一个表里面查询数据,也是通过collection,但另外一个表的查询是通过select配置的。
17. Mybatis的一级、二级缓存
1、 一级缓存:基于PerpetualCache的HashMap本地缓存,其存储作用域为Session,当Session flush或close之后,该Session中的所有Cache就将清空,默认打开一级缓存。
2、 二级缓存与一级缓存机制相同,默认也是采用PerpetualCache,HashMap存储,不同在于其存储作用域为Mapper(namespace),并且可自定义存储源,如Ehcache。默认打不开二级缓存,要开启二级缓存,使用二级缓存属性类需要实现Serializable序列化接口(可用来保存对象的状态),可在它的映射文件中配置。
对于缓存数据更新机制,当某一个作用域(一级缓存Session/二级缓存Namespace)进行了增/删/改操作后,默认该作用域下所有select中的缓存将被clear。
18. 使用MyBatis的Mapper接口调用时有哪些要求?
1、Mapper接口方法名和mapper.xml中定义的每个sql的id相同;
2、Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql的parameterType类型相同;
3、Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同;
4、Mapper.xml文件中的namespace即是mapper接口的类路径。
19. Mybatis动态sql是做什么的?都有哪些动态sql?
Mybatis动态sql可以让我们在Xml映射文件内,以标签的形式编写动态sql,完成逻辑判断和动态拼接sql的功能,Mybatis提供了9种动态sql标签trim|where|set|foreach|if|choose|when|otherwise|bind。
其执行原理为,使用OGNL从sql参数对象中计算表达式的值,根据表达式的值动态拼接sql,以此来完成动态sql的功能。
20. Mybatis的Xml映射文件中,不同的Xml映射文件,id是否可以重复?
不同的Xml映射文件,如果配置了namespace,那么id可以重复;如果没有配置namespace,那么id不能重复;毕竟namespace不是必须的,只是最佳实践而已。
原因就是namespace+id是作为Map
六.JVM 常考面试题
1. 什么是JVM内存结构?

jvm将虚拟机分为5大区域,程序计数器、虚拟机栈、本地方法栈、java堆、方法区;
- 程序计数器:线程私有的,是一块很小的内存空间,作为当前线程的行号指示器,用于记录当前虚拟机正在执行的线程指令地址;
- 虚拟机栈:线程私有的,每个方法执行的时候都会创建一个栈帧,用于存储局部变量表、操作数、动态链接和方法返回等信息,当线程请求的栈深度超过了虚拟机允许的最大深度时,就会抛出StackOverFlowError;
- 本地方法栈:线程私有的,保存的是native方法的信息,当一个jvm创建的线程调用native方法后,jvm不会在虚拟机栈中为该线程创建栈帧,而是简单的动态链接并直接调用该方法;
- 堆:java堆是所有线程共享的一块内存,几乎所有对象的实例和数组都要在堆上分配内存,因此该区域经常发生垃圾回收的操作;
- 方法区:存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码数据。即永久代,在jdk1.8中不存在方法区了,被元数据区替代了,原方法区被分成两部分;1:加载的类信息,2:运行时常量池;加载的类信息被保存在元数据区中,运行时常量池保存在堆中;
2. 什么是JVM内存模型?
Java 内存模型(下文简称 JMM)就是在底层处理器内存模型的基础上,定义自己的多线程语义。它明确指定了一组排序规则,来保证线程间的可见性。
这一组规则被称为 Happens-Before, JMM 规定,要想保证 B 操作能够看到 A 操作的结果(无论它们是否在同一个线程),那么 A 和 B 之间必须满足 Happens-Before 关系:
- 单线程规则:一个线程中的每个动作都 happens-before 该线程中后续的每个动作
- 监视器锁定规则:监听器的解锁动作 happens-before 后续对这个监听器的锁定动作
- volatile 变量规则:对 volatile 字段的写入动作 happens-before 后续对这个字段的每个读取动作
- 线程 start 规则:线程 start() 方法的执行 happens-before 一个启动线程内的任意动作
- 线程 join 规则:一个线程内的所有动作 happens-before 任意其他线程在该线程 join() 成功返回之前
- 传递性:如果 A happens-before B, 且 B happens-before C, 那么 A happens-before C
怎么理解 happens-before 呢?如果按字面意思,比如第二个规则,线程(不管是不是同一个)的解锁动作发生在锁定之前?这明显不对。happens-before 也是为了保证可见性,比如那个解锁和加锁的动作,可以这样理解,线程1释放锁退出同步块,线程2加锁进入同步块,那么线程2就能看见线程1对共享对象修改的结果。
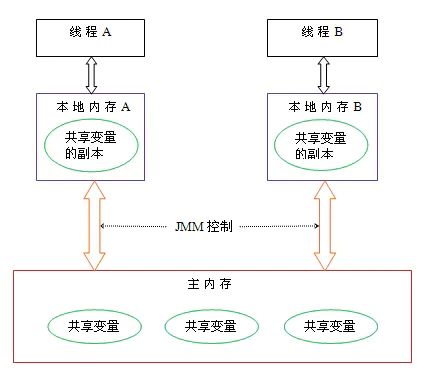
Java 提供了几种语言结构,包括 volatile, final 和 synchronized, 它们旨在帮助程序员向编译器描述程序的并发要求,其中:
- volatile - 保证可见性和有序性
- synchronized - 保证可见性和有序性; 通过**管程(Monitor)*保证一组动作的*原子性
- final - 通过禁止在构造函数初始化和给 final 字段赋值这两个动作的重排序,保证可见性(如果 this 引用逃逸就不好说可见性了)
编译器在遇到这些关键字时,会插入相应的内存屏障,保证语义的正确性。
有一点需要注意的是,synchronized 不保证同步块内的代码禁止重排序,因为它通过锁保证同一时刻只有一个线程访问同步块(或临界区),也就是说同步块的代码只需满足 as-if-serial 语义 - 只要单线程的执行结果不改变,可以进行重排序。
所以说,Java 内存模型描述的是多线程对共享内存修改后彼此之间的可见性,另外,还确保正确同步的 Java 代码可以在不同体系结构的处理器上正确运行。
3. heap 和stack 有什么区别?
(1)申请方式
stack:由系统自动分配。例如,声明在函数中一个局部变量 int b; 系统自动在栈中为 b 开辟空间
heap:需要程序员自己申请,并指明大小,在 c 中 malloc 函数,对于Java 需要手动 new Object()的形式开辟
(2)申请后系统的响应
stack:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
heap:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
(3)申请大小的限制
stack:栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在 WINDOWS 下,栈的大小是 2M(默认值也取决于虚拟内存的大小),如果申请的空间超过栈的剩余空间时,将提示 overflow。因此,能从栈获得的空间较小。
heap:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的, 自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见, 堆获得的空间比较灵活,也比较大。
(4)申请效率的比较
stack:由系统自动分配,速度较快。但程序员是无法控制的。
heap:由 new 分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便。
(5)heap和stack中的存储内容
stack:在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址, 然后是函数的各个参数,在大多数的 C 编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
heap:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
4. 什么情况下会发生栈内存溢出?
1、栈是线程私有的,栈的生命周期和线程一样,每个方法在执行的时候就会创建一个栈帧,它包含局部变量表、操作数栈、动态链接、方法出口等信息,局部变量表又包括基本数据类型和对象的引用;
2、当线程请求的栈深度超过了虚拟机允许的最大深度时,会抛出StackOverFlowError异常,方法递归调用肯可能会出现该问题;
3、调整参数-xss去调整jvm栈的大小
5. 谈谈对 OOM 的认识?如何排查 OOM 的问题?
除了程序计数器,其他内存区域都有 OOM 的风险。
- 栈一般经常会发生 StackOverflowError,比如 32 位的 windows 系统单进程限制 2G 内存,无限创建线程就会发生栈的 OOM
- Java 8 常量池移到堆中,溢出会出 java.lang.OutOfMemoryError: Java heap space,设置最大元空间大小参数无效;
- 堆内存溢出,报错同上,这种比较好理解,GC 之后无法在堆中申请内存创建对象就会报错;
- 方法区 OOM,经常会遇到的是动态生成大量的类、jsp 等;
- 直接内存 OOM,涉及到 -XX:MaxDirectMemorySize 参数和 Unsafe 对象对内存的申请。
排查 OOM 的方法:
- 增加两个参数 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/heapdump.hprof,当 OOM 发生时自动 dump 堆内存信息到指定目录;
- 同时 jstat 查看监控 JVM 的内存和 GC 情况,先观察问题大概出在什么区域;
- 使用 MAT 工具载入到 dump 文件,分析大对象的占用情况,比如 HashMap 做缓存未清理,时间长了就会内存溢出,可以把改为弱引用 。
6. 谈谈 JVM 中的常量池?
JVM常量池主要分为Class文件常量池、运行时常量池,全局字符串常量池,以及基本类型包装类对象常量池。
- Class文件常量池。class文件是一组以字节为单位的二进制数据流,在java代码的编译期间,我们编写的java文件就被编译为.class文件格式的二进制数据存放在磁盘中,其中就包括class文件常量池。
- 运行时常量池:运行时常量池相对于class常量池一大特征就是具有动态性,java规范并不要求常量只能在运行时才产生,也就是说运行时常量池的内容并不全部来自class常量池,在运行时可以通过代码生成常量并将其放入运行时常量池中,这种特性被用的最多的就是String.intern()。
- 全局字符串常量池:字符串常量池是JVM所维护的一个字符串实例的引用表,在HotSpot VM中,它是一个叫做StringTable的全局表。在字符串常量池中维护的是字符串实例的引用,底层C++实现就是一个Hashtable。这些被维护的引用所指的字符串实例,被称作”被驻留的字符串”或”interned string”或通常所说的”进入了字符串常量池的字符串”。
- 基本类型包装类对象常量池:java中基本类型的包装类的大部分都实现了常量池技术,这些类是Byte,Short,Integer,Long,Character,Boolean,另外两种浮点数类型的包装类则没有实现。另外上面这5种整型的包装类也只是在对应值小于等于127时才可使用对象池,也即对象不负责创建和管理大于127的这些类的对象。
7. 如何判断一个对象是否存活?
判断一个对象是否存活,分为两种算法1:引用计数法;2:可达性分析算法;
引用计数法:
给每一个对象设置一个引用计数器,当有一个地方引用该对象的时候,引用计数器就+1,引用失效时,引用计数器就-1;当引用计数器为0的时候,就说明这个对象没有被引用,也就是垃圾对象,等待回收;
缺点:无法解决循环引用的问题,当A引用B,B也引用A的时候,此时AB对象的引用都不为0,此时也就无法垃圾回收,所以一般主流虚拟机都不采用这个方法;
可达性分析法
从一个被称为GC Roots的对象向下搜索,如果一个对象到GC Roots没有任何引用链相连接时,说明此对象不可用,在java中可以作为GC Roots的对象有以下几种:
- 虚拟机栈中引用的对象
- 方法区类静态属性引用的变量
- 方法区常量池引用的对象
- 本地方法栈JNI引用的对象
但一个对象满足上述条件的时候,不会马上被回收,还需要进行两次标记;第一次标记:判断当前对象是否有finalize()方法并且该方法没有被执行过,若不存在则标记为垃圾对象,等待回收;若有的话,则进行第二次标记;第二次标记将当前对象放入F-Queue队列,并生成一个finalize线程去执行该方法,虚拟机不保证该方法一定会被执行,这是因为如果线程执行缓慢或进入了死锁,会导致回收系统的崩溃;如果执行了finalize方法之后仍然没有与GC Roots有直接或者间接的引用,则该对象会被回收;
8. 强引用、软引用、弱引用、虚引用是什么,有什么区别?
- 强引用,就是普通的对象引用关系,如 String s = new String(“ConstXiong”)
- 软引用,用于维护一些可有可无的对象。只有在内存不足时,系统则会回收软引用对象,如果回收了软引用对象之后仍然没有足够的内存,才会抛出内存溢出异常。SoftReference 实现
- 弱引用,相比软引用来说,要更加无用一些,它拥有更短的生命周期,当 JVM 进行垃圾回收时,无论内存是否充足,都会回收被弱引用关联的对象。WeakReference 实现
- 虚引用是一种形同虚设的引用,在现实场景中用的不是很多,它主要用来跟踪对象被垃圾回收的活动。PhantomReference 实现
9. 被引用的对象就一定能存活吗?
不一定,看 Reference 类型,弱引用在 GC 时会被回收,软引用在内存不足的时候,即 OOM 前会被回收,但如果没有在 Reference Chain 中的对象就一定会被回收。
10. Java中的垃圾回收算法有哪些?
java中有四种垃圾回收算法,分别是标记清除法、标记整理法、复制算法、分代收集算法;
标记清除法:
第一步:利用可达性去遍历内存,把存活对象和垃圾对象进行标记;
第二步:在遍历一遍,将所有标记的对象回收掉;
特点:效率不行,标记和清除的效率都不高;标记和清除后会产生大量的不连续的空间分片,可能会导致之后程序运行的时候需分配大对象而找不到连续分片而不得不触发一次GC;

标记整理法:
第一步:利用可达性去遍历内存,把存活对象和垃圾对象进行标记;
第二步:将所有的存活的对象向一段移动,将端边界以外的对象都回收掉;
特点:适用于存活对象多,垃圾少的情况;需要整理的过程,无空间碎片产生;
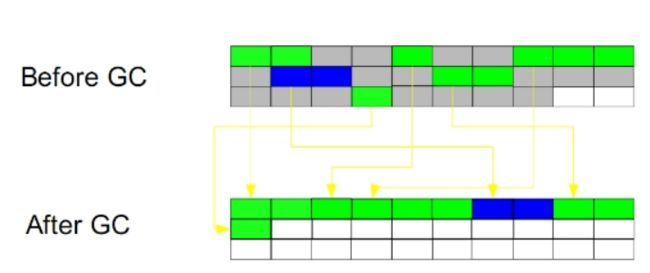
复制算法:
将内存按照容量大小分为大小相等的两块,每次只使用一块,当一块使用完了,就将还存活的对象移到另一块上,然后在把使用过的内存空间移除;
特点:不会产生空间碎片;内存使用率极低;
分代收集算法:
根据内存对象的存活周期不同,将内存划分成几块,java虚拟机一般将内存分成新生代和老生代,在新生代中,有大量对象死去和少量对象存活,所以采用复制算法,只需要付出少量存活对象的复制成本就可以完成收集;老年代中因为对象的存活率极高,没有额外的空间对他进行分配担保,所以采用标记清理或者标记整理算法进行回收;
对比
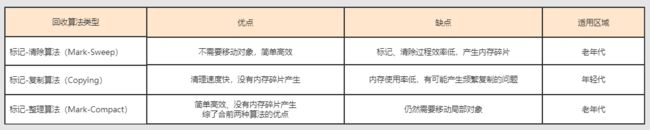
11. 有哪几种垃圾回收器,各自的优缺点是什么?
垃圾回收器主要分为以下几种:Serial、ParNew、Parallel Scavenge、Serial Old、Parallel Old、CMS、G1;
-
Serial:单线程的收集器,收集垃圾时,必须stop the world,使用复制算法。它的最大特点是在进行垃圾回收时,需要对所有正在执行的线程暂停(stop the world),对于有些应用是难以接受的,但是如果应用的实时性要求不是那么高,只要停顿的时间控制在N毫秒之内,大多数应用还是可以接受的,是client级别的默认GC方式。
-
ParNew:Serial收集器的多线程版本,也需要stop the world,复制算
-
Parallel Scavenge:新生代收集器,复制算法的收集器,并发的多线程收集器,目标是达到一个可控的吞吐量,和ParNew的最大区别是GC自动调节策略;虚拟机会根据系统的运行状态收集性能监控信息,动态设置这些参数,以提供最优停顿时间和最高的吞吐量;
-
Serial Old:Serial收集器的老年代版本,单线程收集器,使用标记整理算法。
-
Parallel Old:是Parallel Scavenge收集器的老年代版本,使用多线程,标记-整理算法。
-
CMS:是一种以获得最短回收停顿时间为目标的收集器,标记清除算法,运作过程:初始标记,并发标记,重新标记,并发清除,收集结束会产生大量空间碎片;
-
G1:标记整理算法实现,运作流程主要包括以下:初始标记,并发标记,最终标记,筛选回收。不会产生空间碎片,可以精确地控制停顿;G1将整个堆分为大小相等的多个Region(区域),G1跟踪每个区域的垃圾大小,在后台维护一个优先级列表,每次根据允许的收集时间,优先回收价值最大的区域,已达到在有限时间内获取尽可能高的回收效率;
垃圾回收器间的配合使用图:
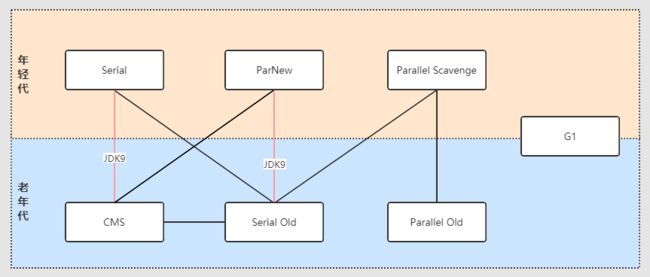
各个垃圾回收器对比:
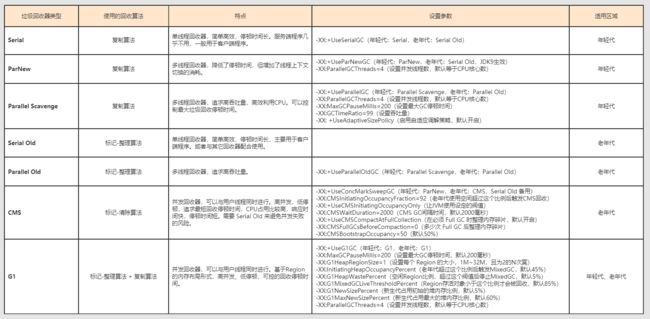
12. 详细说一下CMS的回收过程?CMS的问题是什么?
CMS(Concurrent Mark Sweep,并发标记清除) 收集器是以获取最短回收停顿时间为目标的收集器(追求低停顿),它在垃圾收集时使得用户线程和 GC 线程并发执行,因此在垃圾收集过程中用户也不会感到明显的卡顿。
从名字就可以知道,CMS是基于“标记-清除”算法实现的。CMS 回收过程分为以下四步:
-
初始标记 (CMS initial mark):主要是标记 GC Root 开始的下级(注:仅下一级)对象,这个过程会 STW,但是跟 GC Root 直接关联的下级对象不会很多,因此这个过程其实很快。
-
并发标记 (CMS concurrent mark):根据上一步的结果,继续向下标识所有关联的对象,直到这条链上的最尽头。这个过程是多线程的,虽然耗时理论上会比较长,但是其它工作线程并不会阻塞,没有 STW。
-
重新标记(CMS remark):顾名思义,就是要再标记一次。为啥还要再标记一次?因为第 2 步并没有阻塞其它工作线程,其它线程在标识过程中,很有可能会产生新的垃圾。
-
并发清除(CMS concurrent sweep):清除阶段是清理删除掉标记阶段判断的已经死亡的对象,由于不需要移动存活对象,所以这个阶段也是可以与用户线程同时并发进行的。
CMS 的问题:
1. 并发回收导致CPU资源紧张:
在并发阶段,它虽然不会导致用户线程停顿,但却会因为占用了一部分线程而导致应用程序变慢,降低程序总吞吐量。CMS默认启动的回收线程数是:(CPU核数 + 3)/ 4,当CPU核数不足四个时,CMS对用户程序的影响就可能变得很大。
2. 无法清理浮动垃圾:
在CMS的并发标记和并发清理阶段,用户线程还在继续运行,就还会伴随有新的垃圾对象不断产生,但这一部分垃圾对象是出现在标记过程结束以后,CMS无法在当次收集中处理掉它们,只好留到下一次垃圾收集时再清理掉。这一部分垃圾称为“浮动垃圾”。
3. 并发失败(Concurrent Mode Failure):
由于在垃圾回收阶段用户线程还在并发运行,那就还需要预留足够的内存空间提供给用户线程使用,因此CMS不能像其他回收器那样等到老年代几乎完全被填满了再进行回收,必须预留一部分空间供并发回收时的程序运行使用。默认情况下,当老年代使用了 92% 的空间后就会触发 CMS 垃圾回收,这个值可以通过 -XX*** CMSInitiatingOccupancyFraction 参数来设置。
这里会有一个风险:要是CMS运行期间预留的内存无法满足程序分配新对象的需要,就会出现一次“并发失败”(Concurrent Mode Failure),这时候虚拟机将不得不启动后备预案:Stop The World,临时启用 Serial Old 来重新进行老年代的垃圾回收,这样一来停顿时间就很长了。
4.内存碎片问题:
CMS是一款基于“标记-清除”算法实现的回收器,这意味着回收结束时会有内存碎片产生。内存碎片过多时,将会给大对象分配带来麻烦,往往会出现老年代还有很多剩余空间,但就是无法找到足够大的连续空间来分配当前对象,而不得不提前触发一次 Full GC 的情况。
为了解决这个问题,CMS收集器提供了一个 -XX**:+UseCMSCompactAtFullCollection 开关参数(默认开启),用于在 Full GC 时开启内存碎片的合并整理过程,由于这个内存整理必须移动存活对象,是无法并发的,这样停顿时间就会变长。还有另外一个参数 -XX*CMSFullGCsBeforeCompaction,这个参数的作用是要求CMS在执行过若干次不整理空间的 Full GC 之后,下一次进入 Full GC 前会先进行碎片整理(默认值为0,表示每次进入 Full GC 时都进行碎片整理)。
13. 详细说一下G1的回收过程?
G1(Garbage First)回收器采用面向局部收集的设计思路和基于Region的内存布局形式,是一款主要面向服务端应用的垃圾回收器。G1设计初衷就是替换 CMS,成为一种全功能收集器。G1 在JDK9 之后成为服务端模式下的默认垃圾回收器,取代了 Parallel Scavenge 加 Parallel Old 的默认组合,而 CMS 被声明为不推荐使用的垃圾回收器。G1从整体来看是基于 标记-整理 算法实现的回收器,但从局部(两个Region之间)上看又是基于 标记-复制 算法实现的。
G1 回收过程,G1 回收器的运作过程大致可分为四个步骤:
-
初始标记(会STW):仅仅只是标记一下 GC Roots 能直接关联到的对象,并且修改TAMS指针的值,让下一阶段用户线程并发运行时,能正确地在可用的Region中分配新对象。这个阶段需要停顿线程,但耗时很短,而且是借用进行Minor GC的时候同步完成的,所以G1收集器在这个阶段实际并没有额外的停顿。
-
并发标记:从 GC Roots 开始对堆中对象进行可达性分析,递归扫描整个堆里的对象图,找出要回收的对象,这阶段耗时较长,但可与用户程序并发执行。当对象图扫描完成以后,还要重新处理在并发时有引用变动的对象。
-
最终标记(会STW):对用户线程做短暂的暂停,处理并发阶段结束后仍有引用变动的对象。
-
清理阶段(会STW):更新Region的统计数据,对各个Region的回收价值和成本进行排序,根据用户所期望的停顿时间来制定回收计划,可以自由选择任意多个Region构成回收集,然后把决定回收的那一部分Region的存活对象复制到空的Region中,再清理掉整个旧Region的全部空间。这里的操作涉及存活对象的移动,必须暂停用户线程,由多条回收器线程并行完成的。
14. JVM中一次完整的GC是什么样子的?
先描述一下Java堆内存划分。
在 Java 中,堆被划分成两个不同的区域:新生代 ( Young )、老年代 ( Old ),新生代默认占总空间的 1/3,老年代默认占 2/3。
新生代有 3 个分区:Eden、To Survivor、From Survivor,它们的默认占比是 8:1:1。
新生代的垃圾回收(又称Minor GC)后只有少量对象存活,所以选用复制算法,只需要少量的复制成本就可以完成回收。
老年代的垃圾回收(又称Major GC)通常使用“标记-清理”或“标记-整理”算法。

再描述它们之间转化流程:
-
对象优先在Eden分配。当 eden 区没有足够空间进行分配时,虚拟机将发起一次 Minor GC。
- 在 Eden 区执行了第一次 GC 之后,存活的对象会被移动到其中一个 Survivor 分区;
- Eden 区再次 GC,这时会采用复制算法,将 Eden 和 from 区一起清理,存活的对象会被复制到 to 区;
- 移动一次,对象年龄加 1,对象年龄大于一定阀值会直接移动到老年代。GC年龄的阀值可以通过参数 -XX:MaxTenuringThreshold 设置,默认为 15;
- 动态对象年龄判定:Survivor 区相同年龄所有对象大小的总和 > (Survivor 区内存大小 * 这个目标使用率)时,大于或等于该年龄的对象直接进入老年代。其中这个使用率通过 -XX:TargetSurvivorRatio 指定,默认为 50%;
- Survivor 区内存不足会发生担保分配,超过指定大小的对象可以直接进入老年代。
-
大对象直接进入老年代,大对象就是需要大量连续内存空间的对象(比如:字符串、数组),为了避免为大对象分配内存时由于分配担保机制带来的复制而降低效率。
-
老年代满了而无法容纳更多的对象,Minor GC 之后通常就会进行Full GC,Full GC 清理整个内存堆 – 包括年轻代和老年代。
15. Minor GC 和 Full GC 有什么不同呢?
Minor GC:只收集新生代的GC。
Full GC: 收集整个堆,包括 新生代,老年代,永久代(在 JDK 1.8及以后,永久代被移除,换为metaspace 元空间)等所有部分的模式。
**Minor GC触发条件:**当Eden区满时,触发Minor GC。
Full GC触发条件:
- 通过Minor GC后进入老年代的平均大小大于老年代的可用内存。如果发现统计数据说之前Minor GC的平均晋升大小比目前old gen剩余的空间大,则不会触发Minor GC而是转为触发full GC。
- 老年代空间不够分配新的内存(或永久代空间不足,但只是JDK1.7有的,这也是用元空间来取代永久代的原因,可以减少Full GC的频率,减少GC负担,提升其效率)。
- 由Eden区、From Space区向To Space区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小。
- 调用System.gc时,系统建议执行Full GC,但是不必然执行。
16. 介绍下空间分配担保原则?
如果YougGC时新生代有大量对象存活下来,而 survivor 区放不下了,这时必须转移到老年代中,但这时发现老年代也放不下这些对象了,那怎么处理呢?其实JVM有一个老年代空间分配担保机制来保证对象能够进入老年代。
在执行每次 YoungGC 之前,JVM会先检查老年代最大可用连续空间是否大于新生代所有对象的总大小。因为在极端情况下,可能新生代 YoungGC 后,所有对象都存活下来了,而 survivor 区又放不下,那可能所有对象都要进入老年代了。这个时候如果老年代的可用连续空间是大于新生代所有对象的总大小的,那就可以放心进行 YoungGC。但如果老年代的内存大小是小于新生代对象总大小的,那就有可能老年代空间不够放入新生代所有存活对象,这个时候JVM就会先检查 -XX:HandlePromotionFailure 参数是否允许担保失败,如果允许,就会判断老年代最大可用连续空间是否大于历次晋升到老年代对象的平均大小,如果大于,将尝试进行一次YoungGC,尽快这次YoungGC是有风险的。如果小于,或者 -XX:HandlePromotionFailure 参数不允许担保失败,这时就会进行一次 Full GC。
在允许担保失败并尝试进行YoungGC后,可能会出现三种情况:
- ① YoungGC后,存活对象小于survivor大小,此时存活对象进入survivor区中
- ② YoungGC后,存活对象大于survivor大小,但是小于老年大可用空间大小,此时直接进入老年代。
- ③ YoungGC后,存活对象大于survivor大小,也大于老年大可用空间大小,老年代也放不下这些对象了,此时就会发生“Handle Promotion Failure”,就触发了 Full GC。如果 Full GC后,老年代还是没有足够的空间,此时就会发生OOM内存溢出了。
通过下图来了解空间分配担保原则:

17. 什么是类加载?类加载的过程?
虚拟机把描述类的数据加载到内存里面,并对数据进行校验、解析和初始化,最终变成可以被虚拟机直接使用的class对象;
类的整个生命周期包括:加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)7个阶段。其中准备、验证、解析3个部分统称为连接(Linking)。如图所示:
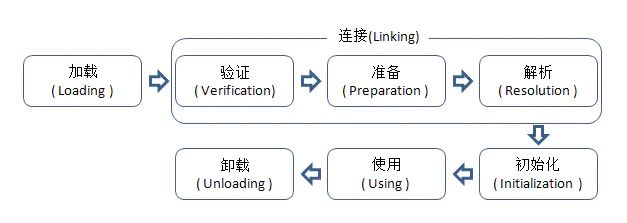
加载、验证、准备、初始化和卸载这5个阶段的顺序是确定的,类的加载过程必须按照这种顺序按部就班地开始,而解析阶段则不一定:它在某些情况下可以在初始化阶段之后再开始,这是为了支持Java语言的运行时绑定(也称为动态绑定或晚期绑定)
类加载过程如下:
-
加载,加载分为三步:
1、通过类的全限定性类名获取该类的二进制流;
2、将该二进制流的静态存储结构转为方法区的运行时数据结构;
3、在堆中为该类生成一个class对象; -
验证:验证该class文件中的字节流信息复合虚拟机的要求,不会威胁到jvm的安全;
-
准备:为class对象的静态变量分配内存,初始化其初始值;
-
解析:该阶段主要完成符号引用转化成直接引用;
-
初始化:到了初始化阶段,才开始执行类中定义的java代码;初始化阶段是调用类构造器的过程;
18. 什么是类加载器,常见的类加载器有哪些?
类加载器是指:通过一个类的全限定性类名获取该类的二进制字节流叫做类加载器;类加载器分为以下四种:
-
启动类加载器(BootStrapClassLoader):用来加载java核心类库,无法被java程序直接引用;
-
扩展类加载器(Extension ClassLoader):用来加载java的扩展库,java的虚拟机实现会提供一个扩展库目录,该类加载器在扩展库目录里面查找并加载java类;
-
系统类加载器(AppClassLoader):它根据java的类路径来加载类,一般来说,java应用的类都是通过它来加载的;
-
自定义类加载器:由java语言实现,继承自ClassLoader;

19. 什么是双亲委派模型?为什么需要双亲委派模型?
当一个类加载器收到一个类加载的请求,他首先不会尝试自己去加载,而是将这个请求委派给父类加载器去加载,只有父类加载器在自己的搜索范围类查找不到给类时,子加载器才会尝试自己去加载该类;
为了防止内存中出现多个相同的字节码;因为如果没有双亲委派的话,用户就可以自己定义一个java.lang.String类,那么就无法保证类的唯一性。
补充:那怎么打破双亲委派模型?
自定义类加载器,继承ClassLoader类,重写loadClass方法和findClass方法。
20. 列举一些你知道的打破双亲委派机制的例子,为什么要打破?
-
JNDI 通过引入线程上下文类加载器,可以在 Thread.setContextClassLoader 方法设置,默认是应用程序类加载器,来加载 SPI 的代码。有了线程上下文类加载器,就可以完成父类加载器请求子类加载器完成类加载的行为。打破的原因,是为了 JNDI 服务的类加载器是启动器类加载,为了完成高级类加载器请求子类加载器(即上文中的线程上下文加载器)加载类。
-
Tomcat,应用的类加载器优先自行加载应用目录下的 class,并不是先委派给父加载器,加载不了才委派给父加载器。
tomcat之所以造了一堆自己的classloader,大致是出于下面三类目的:
- 对于各个
webapp中的class和lib,需要相互隔离,不能出现一个应用中加载的类库会影响另一个应用的情况,而对于许多应用,需要有共享的lib以便不浪费资源。 - 与
jvm一样的安全性问题。使用单独的classloader去装载tomcat自身的类库,以免其他恶意或无意的破坏; - 热部署。
tomcat类加载器如下图:

- 对于各个
-
OSGi,实现模块化热部署,为每个模块都自定义了类加载器,需要更换模块时,模块与类加载器一起更换。其类加载的过程中,有平级的类加载器加载行为。打破的原因是为了实现模块热替换。
-
JDK 9,Extension ClassLoader 被 Platform ClassLoader 取代,当平台及应用程序类加载器收到类加载请求,在委派给父加载器加载前,要先判断该类是否能够归属到某一个系统模块中,如果可以找到这样的归属关系,就要优先委派给负责那个模块的加载器完成加载。打破的原因,是为了添加模块化的特性。
21. 说一下 JVM 调优的命令?
- jps:JVM Process Status Tool,显示指定系统内所有的HotSpot虚拟机进程。
- jstat:jstat(JVM statistics Monitoring)是用于监视虚拟机运行时状态信息的命令,它可以显示出虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据。
- jmap:jmap(JVM Memory Map)命令用于生成heap dump文件,如果不使用这个命令,还阔以使用-XX:+HeapDumpOnOutOfMemoryError参数来让虚拟机出现OOM的时候·自动生成dump文件。
jmap不仅能生成dump文件,还阔以查询finalize执行队列、Java堆和永久代的详细信息,如当前使用率、当前使用的是哪种收集器等。 - jhat:jhat(JVM Heap Analysis Tool)命令是与jmap搭配使用,用来分析jmap生成的dump,jhat内置了一个微型的HTTP/HTML服务器,生成dump的分析结果后,可以在浏览器中查看。在此要注意,一般不会直接在服务器上进行分析,因为jhat是一个耗时并且耗费硬件资源的过程,一般把服务器生成的dump文件复制到本地或其他机器上进行分析。
- jstack:jstack用于生成java虚拟机当前时刻的线程快照。jstack来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做什么事情,或者等待什么资源。 如果java程序崩溃生成core文件,jstack工具可以用来获得core文件的java stack和native stack的信息,从而可以轻松地知道java程序是如何崩溃和在程序何处发生问题。
22. Java对象创建过程
- JVM遇到一条新建对象的指令时首先去检查这个指令的参数是否能在常量池中定义到一个类的符号引用。然后加载这个类(类加载过程在后边讲)
- 为对象分配内存。一种办法“指针碰撞”、一种办法“空闲列表”,最终常用的办法“本地线程缓冲分配(TLAB)”
- 将除对象头外的对象内存空间初始化为0
- 对对象头进行必要设置
23. JDK新特性
JDK8
支持 Lamda 表达式、集合的 stream 操作、提升HashMap性能
JDK9
//Stream API中iterate方法的新重载方法,可以指定什么时候结束迭代
IntStream.iterate(1, i -> i < 100, i -> i + 1).forEach(System.out::println);
默认G1垃圾回收器
JDK10
其重点在于通过完全GC并行来改善G1最坏情况的等待时间。
JDK11
ZGC (并发回收的策略) 4TB
用于 Lambda 参数的局部变量语法
JDK12
Shenandoah GC (GC 算法)停顿时间和堆的大小没有任何关系,并行关注停顿响应时间。
JDK13
增加ZGC以将未使用的堆内存返回给操作系统,16TB
JDK14
删除cms垃圾回收器、弃用ParallelScavenge+SerialOldGC垃圾回收算法组合
将ZGC垃圾回收器应用到macOS和windows平台
线上故障排查
1、硬件故障排查
如果一个实例发生了问题,根据情况选择,要不要着急去重启。如果出现的CPU、内存飙高或者日志里出现了OOM异常
第一步是隔离,第二步是保留现场,第三步才是问题排查。
隔离
就是把你的这台机器从请求列表里摘除,比如把 nginx 相关的权重设成零。
现场保留
瞬时态和历史态
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WbEBQ5HQ-1692794776262)(https://tva1.sinaimg.cn/large/008eGmZEly1gobnwy22d2j30l10cpt9d.jpg)]
查看比如 CPU、系统内存等,通过历史状态可以体现一个趋势性问题,而这些信息的获取一般依靠监控系统的协作。
保留信息
(1)系统当前网络连接
ss -antp > $DUMP_DIR/ss.dump 2>&1
使用 ss 命令而不是 netstat 的原因,是因为 netstat 在网络连接非常多的情况下,执行非常缓慢。
后续的处理,可通过查看各种网络连接状态的梳理,来排查 TIME_WAIT 或者 CLOSE_WAIT,或者其他连接过高的问题,非常有用。
(2)网络状态统计
netstat -s > $DUMP_DIR/netstat-s.dump 2>&1
它能够按照各个协议进行统计输出,对把握当时整个网络状态,有非常大的作用。
sar -n DEV 1 2 > $DUMP_DIR/sar-traffic.dump 2>&1
在一些速度非常高的模块上,比如 Redis、Kafka,就经常发生跑满网卡的情况。表现形式就是网络通信非常缓慢。
(3)进程资源
lsof -p $PID > $DUMP_DIR/lsof-$PID.dump
通过查看进程,能看到打开了哪些文件,可以以进程的维度来查看整个资源的使用情况,包括每条网络连接、每个打开的文件句柄。同时,也可以很容易的看到连接到了哪些服务器、使用了哪些资源。这个命令在资源非常多的情况下,输出稍慢,请耐心等待。
(4)CPU 资源
mpstat > $DUMP_DIR/mpstat.dump 2>&1
vmstat 1 3 > $DUMP_DIR/vmstat.dump 2>&1
sar -p ALL > $DUMP_DIR/sar-cpu.dump 2>&1
uptime > $DUMP_DIR/uptime.dump 2>&1
主要用于输出当前系统的 CPU 和负载,便于事后排查。
(5)I/O 资源
iostat -x > $DUMP_DIR/iostat.dump 2>&1
一般,以计算为主的服务节点,I/O 资源会比较正常,但有时也会发生问题,比如日志输出过多,或者磁盘问题等。此命令可以输出每块磁盘的基本性能信息,用来排查 I/O 问题。在第 8 课时介绍的 GC 日志分磁盘问题,就可以使用这个命令去发现。
(6)内存问题
free -h > $DUMP_DIR/free.dump 2>&1
free 命令能够大体展现操作系统的内存概况,这是故障排查中一个非常重要的点,比如 SWAP 影响了 GC,SLAB 区挤占了 JVM 的内存。
(7)其他全局
ps -ef > $DUMP_DIR/ps.dump 2>&1
dmesg > $DUMP_DIR/dmesg.dump 2>&1
sysctl -a > $DUMP_DIR/sysctl.dump 2>&1
dmesg 是许多静悄悄死掉的服务留下的最后一点线索。当然,ps 作为执行频率最高的一个命令,由于内核的配置参数,会对系统和 JVM 产生影响,所以我们也输出了一份。
(8)进程快照,最后的遗言(jinfo)
${JDK_BIN}jinfo $PID > $DUMP_DIR/jinfo.dump 2>&1
此命令将输出 Java 的基本进程信息,包括环境变量和参数配置,可以查看是否因为一些错误的配置造成了 JVM 问题。
(9)dump 堆信息
${JDK_BIN}jstat -gcutil $PID > $DUMP_DIR/jstat-gcutil.dump 2>&1
${JDK_BIN}jstat -gccapacity $PID > $DUMP_DIR/jstat-gccapacity.dump 2>&1
jstat 将输出当前的 gc 信息。一般,基本能大体看出一个端倪,如果不能,可将借助 jmap 来进行分析。
(10)堆信息
${JDK_BIN}jmap $PID > $DUMP_DIR/jmap.dump 2>&1
${JDK_BIN}jmap -heap $PID > $DUMP_DIR/jmap-heap.dump 2>&1
${JDK_BIN}jmap -histo $PID > $DUMP_DIR/jmap-histo.dump 2>&1
${JDK_BIN}jmap -dump:format=b,file=$DUMP_DIR/heap.bin $PID > /dev/null 2>&1
jmap 将会得到当前 Java 进程的 dump 信息。如上所示,其实最有用的就是第 4 个命令,但是前面三个能够让你初步对系统概况进行大体判断。因为,第 4 个命令产生的文件,一般都非常的大。而且,需要下载下来,导入 MAT 这样的工具进行深入分析,才能获取结果。这是分析内存泄漏一个必经的过程。
(11)JVM 执行栈
${JDK_BIN}jstack $PID > $DUMP_DIR/jstack.dump 2>&1
jstack 将会获取当时的执行栈。一般会多次取值,我们这里取一次即可。这些信息非常有用,能够还原 Java 进程中的线程情况。
top -Hp $PID -b -n 1 -c > $DUMP_DIR/top-$PID.dump 2>&1
为了能够得到更加精细的信息,我们使用 top 命令,来获取进程中所有线程的 CPU 信息,这样,就可以看到资源到底耗费在什么地方了。
(12)高级替补
kill -3 $PID
有时候,jstack 并不能够运行,有很多原因,比如 Java 进程几乎不响应了等之类的情况。我们会尝试向进程发送 kill -3 信号,这个信号将会打印 jstack 的 trace 信息到日志文件中,是 jstack 的一个替补方案。
gcore -o $DUMP_DIR/core $PID
对于 jmap 无法执行的问题,也有替补,那就是 GDB 组件中的 gcore,将会生成一个 core 文件。我们可以使用如下的命令去生成 dump:
${JDK_BIN}jhsdb jmap --exe ${JDK}java --core $DUMP_DIR/core --binaryheap
- 内存泄漏的现象
稍微提一下 jmap 命令,它在 9 版本里被干掉了,取而代之的是 jhsdb,你可以像下面的命令一样使用。
jhsdb jmap --heap --pid 37340
jhsdb jmap --pid 37288
jhsdb jmap --histo --pid 37340
jhsdb jmap --binaryheap --pid 37340
一般内存溢出,表现形式就是 Old 区的占用持续上升,即使经过了多轮 GC 也没有明显改善。比如ThreadLocal里面的GC Roots,内存泄漏的根本就是,这些对象并没有切断和 GC Roots 的关系,可通过一些工具,能够看到它们的联系。
2、报表异常 | JVM调优
有一个报表系统,频繁发生内存溢出,在高峰期间使用时,还会频繁的发生拒绝服务,由于大多数使用者是管理员角色,所以很快就反馈到研发这里。
业务场景是由于有些结果集的字段不是太全,因此需要对结果集合进行循环,并通过 HttpClient 调用其他服务的接口进行数据填充。使用 Guava 做了 JVM 内缓存,但是响应时间依然很长。
初步排查,JVM 的资源太少。接口 A 每次进行报表计算时,都要涉及几百兆的内存,而且在内存里驻留很长时间,有些计算又非常耗 CPU,特别的“吃”资源。而我们分配给 JVM 的内存只有 3 GB,在多人访问这些接口的时候,内存就不够用了,进而发生了 OOM。在这种情况下,没办法,只有升级机器。把机器配置升级到 4C8G,给 JVM 分配 6GB 的内存,这样 OOM 问题就消失了。但随之而来的是频繁的 GC 问题和超长的 GC 时间,平均 GC 时间竟然有 5 秒多。
进一步,由于报表系统和高并发系统不太一样,它的对象,存活时长大得多,并不能仅仅通过增加年轻代来解决;而且,如果增加了年轻代,那么必然减少了老年代的大小,由于 CMS 的碎片和浮动垃圾问题,我们可用的空间就更少了。虽然服务能够满足目前的需求,但还有一些不太确定的风险。
第一,了解到程序中有很多缓存数据和静态统计数据,为了减少 MinorGC 的次数,通过分析 GC 日志打印的对象年龄分布,把 MaxTenuringThreshold 参数调整到了 3(特殊场景特殊的配置)。这个参数是让年轻代的这些对象,赶紧回到老年代去,不要老呆在年轻代里。
第二,我们的 GC 时间比较长,就一块开了参数 CMSScavengeBeforeRemark,使得在 CMS remark 前,先执行一次 Minor GC 将新生代清掉。同时配合上个参数,其效果还是比较好的,一方面,对象很快晋升到了老年代,另一方面,年轻代的对象在这种情况下是有限的,在整个 MajorGC 中占的时间也有限。
第三,由于缓存的使用,有大量的弱引用,拿一次长达 10 秒的 GC 来说。我们发现在 GC 日志里,处理 weak refs 的时间较长,达到了 4.5 秒。这里可以加入参数 ParallelRefProcEnabled 来并行处理Reference,以加快处理速度,缩短耗时。
优化之后,效果不错,但并不是特别明显。经过评估,针对高峰时期的情况进行调研,我们决定再次提升机器性能,改用 8core16g 的机器。但是,这带来另外一个问题。
高性能的机器带来了非常大的服务吞吐量,通过 jstat 进行监控,能够看到年轻代的分配速率明显提高,但随之而来的 MinorGC 时长却变的不可控,有时候会超过 1 秒。累积的请求造成了更加严重的后果。
这是由于堆空间明显加大造成的回收时间加长。为了获取较小的停顿时间,我们在堆上改用了 G1 垃圾回收器,把它的目标设定在 200ms。G1 是一款非常优秀的垃圾收集器,不仅适合堆内存大的应用,同时也简化了调优的工作。通过主要的参数初始和最大堆空间、以及最大容忍的 GC 暂停目标,就能得到不错的性能。修改之后,虽然 GC 更加频繁了一些,但是停顿时间都比较小,应用的运行较为平滑。
到目前为止,也只是勉强顶住了已有的业务,但是,这时候领导层面又发力,要求报表系统可以支持未来两年业务10到100倍的增长,并保持其可用性,但是这个“千疮百孔”的报表系统,稍微一压测,就宕机,那如何应对十倍百倍的压力呢 ? 硬件即使可以做到动态扩容,但是毕竟也有极限。
使用 MAT 分析堆快照,发现很多地方可以通过代码优化,那些占用内存特别多的对象:
1、select * 全量排查,只允许获取必须的数据
2、报表系统中cache实际的命中率并不高,将Guava 的 Cache 引用级别改成弱引用(WeakKeys)
3、限制报表导入文件大小,同时拆分用户超大范围查询导出请求。
每一步操作都使得JVM使用变得更加可用,一系列优化以后,机器相同压测数据性能提升了数倍。
3、大屏异常 | JUC调优
有些数据需要使用 HttpClient 来获取进行补全。提供数据的服务提供商有的响应时间可能会很长,也有可能会造成服务整体的阻塞。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sYWaKUez-1692794776262)(https://tva1.sinaimg.cn/large/008eGmZEly1gobr4whjzwj30l1058dfx.jpg)]
接口 A 通过 HttpClient 访问服务 2,响应 100ms 后返回;接口 B 访问服务 3,耗时 2 秒。HttpClient 本身是有一个最大连接数限制的,如果服务 3 迟迟不返回,就会造成 HttpClient 的连接数达到上限,概括来讲,就是同一服务,由于一个耗时非常长的接口,进而引起了整体的服务不可用
这个时候,通过 jstack 打印栈信息,会发现大多数竟然阻塞在了接口 A 上,而不是耗时更长的接口 B,这个现象起初十分具有迷惑性,不过经过分析后,我们猜想其实是因为接口 A 的速度比较快,在问题发生点进入了更多的请求,它们全部都阻塞住的同时被打印出来了。
为了验证这个问题,我搭建了一个demo 工程,模拟了两个使用同一个 HttpClient 的接口。fast 接口用来访问百度,很快就能返回;slow 接口访问谷歌,由于众所周知的原因,会阻塞直到超时,大约 10 s。 利用ab对两个接口进行压测,同时使用 jstack 工具 dump 堆栈。首先使用 jps 命令找到进程号,然后把结果重定向到文件(可以参考 10271.jstack 文件)。
过滤一下 nio 关键字,可以查看 tomcat 相关的线程,足足有 200 个,这和 Spring Boot 默认的 maxThreads 个数不谋而合。更要命的是,有大多数线程,都处于 BLOCKED 状态,说明线程等待资源超时。通过grep fast | wc -l 分析,确实200个中有150个都是blocked的fast的进程。
问题找到了,解决方式就顺利成章了。
1、fast和slow争抢连接资源,通过线程池限流或者熔断处理
2、有时候slow的线程也不是一直slow,所以就得加入监控
3、使用带countdownLaunch对线程的执行顺序逻辑进行控制
4、接口延迟 | SWAP调优
有一个关于服务的某个实例,经常发生服务卡顿。由于服务的并发量是比较高的,每多停顿 1 秒钟,几万用户的请求就会感到延迟。
我们统计、类比了此服务其他实例的 CPU、内存、网络、I/O 资源,区别并不是很大,所以一度怀疑是机器硬件的问题。
接下来我们对比了节点的 GC 日志,发现无论是 Minor GC,还是 Major GC,这个节点所花费的时间,都比其他实例长得多。
通过仔细观察,我们发现在 GC 发生的时候,vmstat 的 si、so 飙升的非常严重,这和其他实例有着明显的不同。
使用 free 命令再次确认,发现 SWAP 分区,使用的比例非常高,引起的具体原因是什么呢?
更详细的操作系统内存分布,从 /proc/meminfo 文件中可以看到具体的逻辑内存块大小,有多达 40 项的内存信息,这些信息都可以通过遍历 /proc 目录的一些文件获取。我们注意到 slabtop 命令显示的有一些异常,dentry(目录高速缓冲)占用非常高。
问题最终定位到是由于某个运维工程师删除日志时,定时执行了一句命令:
find / | grep “xxx.log”
他是想找一个叫做 要被删除 的日志文件,看看在哪台服务器上,结果,这些老服务器由于文件太多,扫描后这些文件信息都缓存到了 slab 区上。而服务器开了 swap,操作系统发现物理内存占满后,并没有立即释放 cache,导致每次 GC 都要和硬盘打一次交道。
解决方式就是关闭 SWAP 分区。
swap 是很多性能场景的万恶之源,建议禁用。在高并发 SWAP 绝对能让你体验到它魔鬼性的一面:进程倒是死不了了,但 GC 时间长的却让人无法忍受。
5、内存溢出 | Cache调优
有一次线上遇到故障,重新启动后,使用 jstat 命令,发现 Old 区一直在增长。我使用 jmap 命令,导出了一份线上堆栈,然后使用 MAT 进行分析,通过对 GC Roots 的分析,发现了一个非常大的 HashMap 对象,这个原本是其他同事做缓存用的,但是做了一个无界缓存,没有设置超时时间或者 LRU 策略,在使用上又没有重写key类对象的hashcode和equals方法,对象无法取出也直接造成了堆内存占用一直上升,后来,将这个缓存改成 guava 的 Cache,并设置了弱引用,故障就消失了。
关于文件处理器的应用,在读取或者写入一些文件之后,由于发生了一些异常,close 方法又没有放在 finally 块里面,造成了文件句柄的泄漏。由于文件处理十分频繁,产生了严重的内存泄漏问题。
内存溢出是一个结果,而内存泄漏是一个原因。内存溢出的原因有内存空间不足、配置错误等因素。一些错误的编程方式,不再被使用的对象、没有被回收、没有及时切断与 GC Roots 的联系,这就是内存泄漏。
举个例子,有团队使用了 HashMap 做缓存,但是并没有设置超时时间或者 LRU 策略,造成了放入 Map 对象的数据越来越多,而产生了内存泄漏。
再来看一个经常发生的内存泄漏的例子,也是由于 HashMap 产生的。代码如下,由于没有重写 Key 类的 hashCode 和 equals 方法,造成了放入 HashMap 的所有对象都无法被取出来,它们和外界失联了。所以下面的代码结果是 null。
//leak example
import java.util.HashMap;
import java.util.Map;
public class HashMapLeakDemo {
public static class Key {
String title;
public Key(String title) {
this.title = title;
}
}
public static void main(String[] args) {
Map<Key, Integer> map = new HashMap<>();
map.put(new Key("1"), 1);
map.put(new Key("2"), 2);
map.put(new Key("3"), 2);
Integer integer = map.get(new Key("2"));
System.out.println(integer);
}
}
即使提供了 equals 方法和 hashCode 方法,也要非常小心,尽量避免使用自定义的对象作为 Key。
再看一个例子,关于文件处理器的应用,在读取或者写入一些文件之后,由于发生了一些异常,close 方法又没有放在 finally 块里面,造成了文件句柄的泄漏。由于文件处理十分频繁,产生了严重的内存泄漏问题。
6、CPU飙高 | 死循环
我们有个线上应用,单节点在运行一段时间后,CPU 的使用会飙升,一旦飙升,一般怀疑某个业务逻辑的计算量太大,或者是触发了死循环(比如著名的 HashMap 高并发引起的死循环),但排查到最后其实是 GC 的问题。
(1)使用 top 命令,查找到使用 CPU 最多的某个进程,记录它的 pid。使用 Shift + P 快捷键可以按 CPU 的使用率进行排序。
top
(2)再次使用 top 命令,加 -H 参数,查看某个进程中使用 CPU 最多的某个线程,记录线程的 ID。
top -Hp $pid
(3)使用 printf 函数,将十进制的 tid 转化成十六进制。
printf %x $tid
(4)使用 jstack 命令,查看 Java 进程的线程栈。
jstack $pid >$pid.log
(5)使用 less 命令查看生成的文件,并查找刚才转化的十六进制 tid,找到发生问题的线程上下文。
less $pid.log
我们在 jstack 日志搜关键字DEAD,以及中找到了 CPU 使用最多的几个线程id。
可以看到问题发生的根源,是我们的堆已经满了,但是又没有发生 OOM,于是 GC 进程就一直在那里回收,回收的效果又非常一般,造成 CPU 升高应用假死。接下来的具体问题排查,就需要把内存 dump 一份下来,使用 MAT 等工具分析具体原因了。
七.RabbitMQ
为什么使用MQ?
使用MQ的场景很多,主要有三个:解耦、异步、削峰。
- 解耦:假设现在,日志不光要插入到数据库里,还要在硬盘中增加文件类型的日志,同时,一些关键日志还要通过邮件的方式发送给指定的人。那么,如果按照原来的逻辑,A可能就需要在原来的代码上做扩展,除了B服务,还要加上日志文件的存储和日志邮件的发送。但是,如果你使用了MQ,那么,A服务是不需要做更改的,它还是将消息放到MQ中即可,其它的服务,无论是原来的B服务还是新增的日志文件存储服务或日志邮件发送服务,都直接从MQ中获取消息并处理即可。这就是解耦,它的好处是提高系统灵活性,扩展性。
- 异步:可以将一些非核心流程,如日志,短信,邮件等,通过MQ的方式异步去处理。这样做的好处是缩短主流程的响应时间,提升用户体验。
- 削峰:MQ的本质就是业务的排队。所以,面对突然到来的高并发,MQ也可以不用慌忙,先排好队,不要着急,一个一个来。削峰的好处就是避免高并发压垮系统的关键组件,如某个核心服务或数据库等。
下面附场景解释:
解耦
场景:A 系统发送数据到 BCD 三个系统,通过接口调用发送。如果 E 系统也要这个数据呢?那如果 C 系统现在不需要了呢?A 系统负责人几乎崩溃…
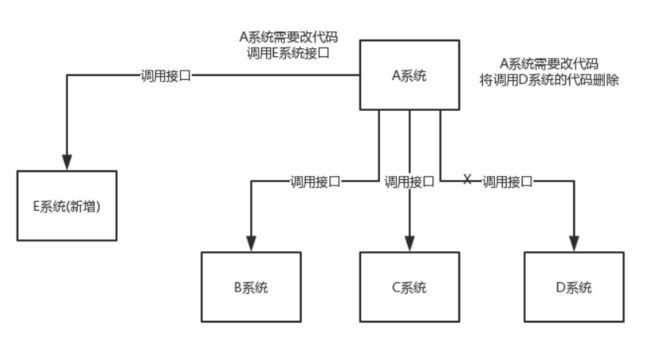
在这个场景中,A 系统跟其它各种乱七八糟的系统严重耦合,A 系统产生一条比较关键的数据,很多系统都需要 A 系统将这个数据发送过来。A 系统要时时刻刻考虑 BCDE 四个系统如果挂了该咋办?要不要重发,要不要把消息存起来?头发都白了啊!
如果使用 MQ,A 系统产生一条数据,发送到 MQ 里面去,哪个系统需要数据自己去 MQ 里面消费。如果新系统需要数据,直接从 MQ 里消费即可;如果某个系统不需要这条数据了,就取消对 MQ 消息的消费即可。这样下来,A 系统压根儿不需要去考虑要给谁发送数据,不需要维护这个代码,也不需要考虑人家是否调用成功、失败超时等情况。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Yi7Vh2wy-1692794868638)(http://blog-img.coolsen.cn/img/727602-20200108091329888-1880681145.png)]
总结:通过一个 MQ,Pub/Sub 发布订阅消息这么一个模型,A 系统就跟其它系统彻底解耦了。
异步
场景:A 系统接收一个请求,需要在自己本地写库,还需要在 BCD 三个系统写库,自己本地写库要 3ms,BCD 三个系统分别写库要 300ms、450ms、200ms。最终请求总延时是 3 + 300 + 450 + 200 = 953ms,接近 1s,用户感觉搞个什么东西,慢死了慢死了。用户通过浏览器发起请求,等待个 1s,这几乎是不可接受的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lxUOR2wK-1692794868638)(http://blog-img.coolsen.cn/img/727602-20200108091632167-740723329.png)]
一般互联网类的企业,对于用户直接的操作,一般要求是每个请求都必须在 200 ms 以内完成,对用户几乎是无感知的。
如果使用 MQ,那么 A 系统连续发送 3 条消息到 MQ 队列中,假如耗时 5ms,A 系统从接受一个请求到返回响应给用户,总时长是 3 + 5 = 8ms,对于用户而言,其实感觉上就是点个按钮,8ms 以后就直接返回了。
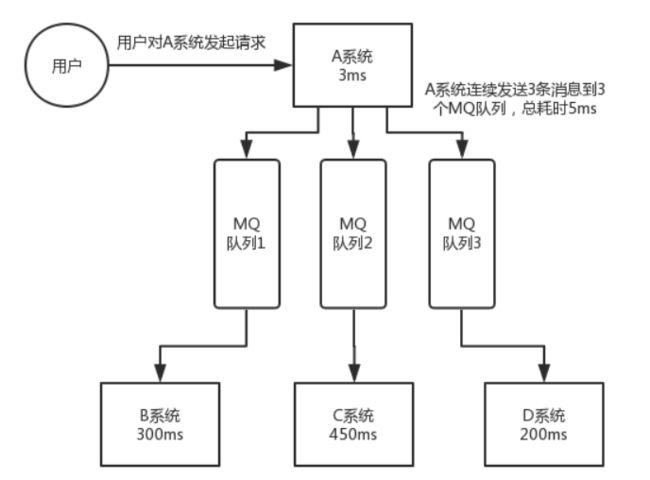
削峰
场景:每天 0:00 到 12:00,A 系统风平浪静,每秒并发请求数量就 50 个。结果每次一到 12:00 ~ 13:00 ,每秒并发请求数量突然会暴增到 5k+ 条。但是系统是直接基于 MySQL 的,大量的请求涌入 MySQL,每秒钟对 MySQL 执行约 5k 条 SQL。
使用 MQ,每秒 5k 个请求写入 MQ,A 系统每秒钟最多处理 2k 个请求,因为 MySQL 每秒钟最多处理 2k 个。A 系统从 MQ 中慢慢拉取请求,每秒钟就拉取 2k 个请求,不要超过自己每秒能处理的最大请求数量就 ok,这样下来,哪怕是高峰期的时候,A 系统也绝对不会挂掉。而 MQ 每秒钟 5k 个请求进来,就 2k 个请求出去,结果就导致在中午高峰期(1 个小时),可能有几十万甚至几百万的请求积压在 MQ 中。
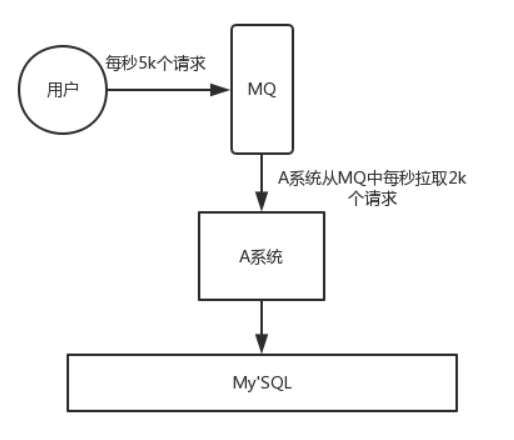
这个短暂的高峰期积压是 ok 的,因为高峰期过了之后,每秒钟就 50 个请求进 MQ,但是 A 系统依然会按照每秒 2k 个请求的速度在处理。所以说,只要高峰期一过,A 系统就会快速将积压的消息给解决掉。
消息队列的缺点
1、 系统可用性降低
系统引入的外部依赖越多,越容易挂掉。
2、 系统复杂度提高
加入了消息队列,要多考虑很多方面的问题,比如:一致性问题、如何保证消息不被重复消费、如何保证消息可靠性传输等。因此,需要考虑的东西更多,复杂性增大。
3、 一致性问题
A 系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是 BCD 三个系统那里,BD 两个系统写库成功了,结果 C 系统写库失败了,这就数据不一致了。
Kafka、ActiveMQ、RabbitMQ、RocketMQ 有什么优缺点?
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 开发语言 | java | erlang | java | scala |
| 单机吞吐量 | 万级,比 RocketMQ、Kafka 低一个数量级 | 同 ActiveMQ | 10 万级,支撑高吞吐 | 10 万级,高吞吐,一般配合大数据类的系统来进行实时数据计算、日志采集等场景 |
| topic 数量对吞吐量的影响 | topic 可以达到几百/几千的级别,吞吐量会有较小幅度的下降,这是 RocketMQ 的一大优势,在同等机器下,可以支撑大量的 topic | topic 从几十到几百个时候,吞吐量会大幅度下降,在同等机器下,Kafka 尽量保证 topic 数量不要过多,如果要支撑大规模的 topic,需要增加更多的机器资源 | ||
| 时效性 | ms 级 | 微秒级,这是 RabbitMQ 的一大特点,延迟最低 | ms 级 | 延迟在 ms 级以内 |
| 可用性 | 高,基于主从架构实现高可用 | 同 ActiveMQ | 非常高,分布式架构 | 非常高,分布式,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 消息可靠性 | 有较低的概率丢失数据 | 基本不丢 | 经过参数优化配置,可以做到 0 丢失 | 同 RocketMQ |
| 功能支持 | MQ 领域的功能极其完备 | 基于 erlang 开发,并发能力很强,性能极好,延时很低 | MQ 功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的 MQ 功能,在大数据领域的实时计算以及日志采集被大规模使用 |
| 社区活跃度 | 低 | 很高 | 一般 | 很高 |
- 中小型公司,技术实力较为一般,技术挑战不是特别高,用 RabbitMQ 是不错的选择;
- 大型公司,基础架构研发实力较强,用 RocketMQ 是很好的选择。
- 大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准的,几乎是全世界这个领域的事实性规范。
1. RabbitMQ是什么?
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)。RabbitMQ服务器是用Erlang语言编写的,而群集和故障转移是构建在开放电信平台框架上的。所有主要的编程语言均有与代理接口通讯的客户端库。
2. RabbitMQ特点?
可靠性: RabbitMQ使用一些机制来保证可靠性, 如持久化、传输确认及发布确认等。
灵活的路由 : 在消息进入队列之前,通过交换器来路由消息。对于典型的路由功能, RabbitMQ 己经提供了一些内置的交换器来实现。针对更复杂的路由功能,可以将多个 交换器绑定在一起, 也可以通过插件机制来实现自己的交换器。
扩展性: 多个RabbitMQ节点可以组成一个集群,也可以根据实际业务情况动态地扩展 集群中节点。
高可用性 : 队列可以在集群中的机器上设置镜像,使得在部分节点出现问题的情况下队 列仍然可用。
多种协议: RabbitMQ除了原生支持AMQP协议,还支持STOMP, MQTT等多种消息 中间件协议。
多语言客户端 :RabbitMQ 几乎支持所有常用语言,比如 Java、 Python、 Ruby、 PHP、 C#、 JavaScript 等。
管理界面 : RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息、集 群中的节点等。
令插件机制: RabbitMQ 提供了许多插件 , 以实现从多方面进行扩展,当然也可以编写自 己的插件。
3. AMQP是什么?
RabbitMQ就是 AMQP 协议的 Erlang 的实现(当然 RabbitMQ 还支持 STOMP2、 MQTT3 等协议 ) AMQP 的模型架构 和 RabbitMQ 的模型架构是一样的,生产者将消息发送给交换器,交换器和队列绑定 。
RabbitMQ 中的交换器、交换器类型、队列、绑定、路由键等都是遵循的 AMQP 协议中相 应的概念。目前 RabbitMQ 最新版本默认支持的是 AMQP 0-9-1。
4. AMQP的3层协议?
Module Layer:协议最高层,主要定义了一些客户端调用的命令,客户端可以用这些命令实现自己的业务逻辑。
Session Layer:中间层,主要负责客户端命令发送给服务器,再将服务端应答返回客户端,提供可靠性同步机制和错误处理。
TransportLayer:最底层,主要传输二进制数据流,提供帧的处理、信道服用、错误检测和数据表示等。
5. 说说Broker服务节点、Queue队列、Exchange交换器?
- Broker可以看做RabbitMQ的服务节点。一般请下一个Broker可以看做一个RabbitMQ服务器。
- Queue:RabbitMQ的内部对象,用于存储消息。多个消费者可以订阅同一队列,这时队列中的消息会被平摊(轮询)给多个消费者进行处理。
- Exchange:生产者将消息发送到交换器,由交换器将消息路由到一个或者多个队列中。当路由不到时,或返回给生产者或直接丢弃。
6. 如何保证消息的可靠性?
分三点:
- 生产者到RabbitMQ:事务机制和Confirm机制,注意:事务机制和 Confirm 机制是互斥的,两者不能共存,会导致 RabbitMQ 报错。
- RabbitMQ自身:持久化、集群、普通模式、镜像模式。
- RabbitMQ到消费者:basicAck机制、死信队列、消息补偿机制。
7. 生产者消息运转的流程?
-
Producer先连接到Broker,建立连接Connection,开启一个信道(Channel)。 -
Producer声明一个交换器并设置好相关属性。 -
Producer声明一个队列并设置好相关属性。 -
Producer通过路由键将交换器和队列绑定起来。 -
Producer发送消息到Broker,其中包含路由键、交换器等信息。 -
相应的交换器根据接收到的路由键查找匹配的队列。
-
如果找到,将消息存入对应的队列,如果没有找到,会根据生产者的配置丢弃或者退回给生产者。
-
关闭信道。
-
管理连接。
8.消费者接收消息过程?
-
Producer先连接到Broker,建立连接Connection,开启一个信道(Channel)。 -
向
Broker请求消费响应的队列中消息,可能会设置响应的回调函数。 -
等待
Broker回应并投递相应队列中的消息,接收消息。 -
消费者确认收到的消息,
ack。 -
RabbitMq从队列中删除已经确定的消息。 -
关闭信道。
-
关闭连接。
9. 生产者如何将消息可靠投递到RabbitMQ?
-
Client发送消息给MQ
-
MQ将消息持久化后,发送Ack消息给Client,此处有可能因为网络问题导致Ack消息无法发送到Client,那么Client在等待超时后,会重传消息;
-
Client收到Ack消息后,认为消息已经投递成功。
10. RabbitMQ如何将消息可靠投递到消费者?
-
MQ将消息push给Client(或Client来pull消息)
-
Client得到消息并做完业务逻辑
-
Client发送Ack消息给MQ,通知MQ删除该消息,此处有可能因为网络问题导致Ack失败,那么Client会重复消息,这里就引出消费幂等的问题;
-
MQ将已消费的消息删除。
11. 如何保证RabbitMQ消息队列的高可用?
RabbitMQ 有三种模式:单机模式,普通集群模式,镜像集群模式。
单机模式:就是demo级别的,一般就是你本地启动了玩玩儿的,没人生产用单机模式
普通集群模式:意思就是在多台机器上启动多个RabbitMQ实例,每个机器启动一个。
镜像集群模式:这种模式,才是所谓的RabbitMQ的高可用模式,跟普通集群模式不一样的是,你创建的queue,无论元数据(元数据指RabbitMQ的配置数据)还是queue里的消息都会存在于多个实例上,然后每次你写消息到queue的时候,都会自动把消息到多个实例的queue里进行消息同步。
RocketMQ
1. RocketMQ是什么?
RocketMQ 是阿里巴巴开源的分布式消息中间件。支持事务消息、顺序消息、批量消息、定时消息、消息回溯等。它里面有几个区别于标准消息中件间的概念,如Group、Topic、Queue等。系统组成则由Producer、Consumer、Broker、NameServer等。
RocketMQ 特点
- 是一个队列模型的消息中间件,具有高性能、高可靠、高实时、分布式等特点
- Producer、Consumer、队列都可以分布式
- Producer 向一些队列轮流发送消息,队列集合称为 Topic,Consumer 如果做广播消费,则一个 Consumer 实例消费这个 Topic 对应的所有队列,如果做集群消费,则多个 Consumer 实例平均消费这个 Topic 对应的队列集合
- 能够保证严格的消息顺序
- 支持拉(pull)和推(push)两种消息模式
- 高效的订阅者水平扩展能力
- 实时的消息订阅机制
- 亿级消息堆积能力
- 支持多种消息协议,如 JMS、OpenMessaging 等
- 较少的依赖
2. RocketMQ由哪些角色组成,每个角色作用和特点是什么?
| 角色 | 作用 |
|---|---|
| Nameserver | 无状态,动态列表;这也是和zookeeper的重要区别之一。zookeeper是有状态的。 |
| Producer | 消息生产者,负责发消息到Broker。 |
| Broker | 就是MQ本身,负责收发消息、持久化消息等。 |
| Consumer | 消息消费者,负责从Broker上拉取消息进行消费,消费完进行ack。 |
3. RocketMQ消费模式有几种?
消费模型由Consumer决定,消费维度为Topic。
1、集群消费
-
一条消息只会被同Group中的一个Consumer消费
-
多个Group同时消费一个Topic时,每个Group都会有一个Consumer消费到数据
2、广播消费
消息将对一 个Consumer Group 下的各个 Consumer 实例都消费一遍。即即使这些 Consumer 属于同一个Consumer Group ,消息也会被 Consumer Group 中的每个 Consumer 都消费一次。
4. RocketMQ消费消息是push还是pull?
RocketMQ没有真正意义的push,都是pull,虽然有push类,但实际底层实现采用的是长轮询机制,即拉取方式
broker端属性 longPollingEnable 标记是否开启长轮询。默认开启
追问:为什么要主动拉取消息而不使用事件监听方式?
事件驱动方式是建立好长连接,由事件(发送数据)的方式来实时推送。
如果broker主动推送消息的话有可能push速度快,消费速度慢的情况,那么就会造成消息在consumer端堆积过多,同时又不能被其他consumer消费的情况。而pull的方式可以根据当前自身情况来pull,不会造成过多的压力而造成瓶颈。所以采取了pull的方式。
5. broker如何处理拉取请求的?
Consumer首次请求Broker
-
Broker中是否有符合条件的消息
-
有
-
- 响应Consumer
- 等待下次Consumer的请求
-
没有
-
- DefaultMessageStore#ReputMessageService#run方法
- PullRequestHoldService 来Hold连接,每个5s执行一次检查pullRequestTable有没有消息,有的话立即推送
- 每隔1ms检查commitLog中是否有新消息,有的话写入到pullRequestTable
- 当有新消息的时候返回请求
- 挂起consumer的请求,即不断开连接,也不返回数据
- 使用consumer的offset,
6. 如何让RocketMQ保证消息的顺序消费?
首先多个queue只能保证单个queue里的顺序,queue是典型的FIFO,天然顺序。多个queue同时消费是无法绝对保证消息的有序性的。所以总结如下:
同一topic,同一个QUEUE,发消息的时候一个线程去发送消息,消费的时候 一个线程去消费一个queue里的消息。
7. RocketMQ如何保证消息不丢失?
首先在如下三个部分都可能会出现丢失消息的情况:
- Producer端
- Broker端
- Consumer端
1 、Producer端如何保证消息不丢失
-
采取send()同步发消息,发送结果是同步感知的。
-
发送失败后可以重试,设置重试次数。默认3次。
-
集群部署,比如发送失败了的原因可能是当前Broker宕机了,重试的时候会发送到其他Broker上。
2、Broker端如何保证消息不丢失
-
修改刷盘策略为同步刷盘。默认情况下是异步刷盘的。
-
集群部署,主从模式,高可用。
3、Consumer端如何保证消息不丢失
- 完全消费正常后在进行手动ack确认。
7. rocketMQ的消息堆积如何处理?
首先要找到是什么原因导致的消息堆积,是Producer太多了,Consumer太少了导致的还是说其他情况,总之先定位问题。
然后看下消息消费速度是否正常,正常的话,可以通过上线更多consumer临时解决消息堆积问题
追问:如果Consumer和Queue不对等,上线了多台也在短时间内无法消费完堆积的消息怎么办?
- 准备一个临时的topic
- queue的数量是堆积的几倍
- queue分布到多Broker中
- 上线一台Consumer做消息的搬运工,把原来Topic中的消息挪到新的Topic里,不做业务逻辑处理,只是挪过去
- 上线N台Consumer同时消费临时Topic中的数据
- 改bug
- 恢复原来的Consumer,继续消费之前的Topic
追问:堆积时间过长消息超时了?
RocketMQ中的消息只会在commitLog被删除的时候才会消失,不会超时。也就是说未被消费的消息不会存在超时删除这情况。
追问:堆积的消息会不会进死信队列?
不会,消息在消费失败后会进入重试队列(%RETRY%+ConsumerGroup),18次(默认18次,网上所有文章都说是16次,无一例外。但是我没搞懂为啥是16次,这不是18个时间吗 ?)才会进入死信队列(%DLQ%+ConsumerGroup)。
8. RocketMQ为什么自研nameserver而不用zk?
- RocketMQ只需要一个轻量级的维护元数据信息的组件,为此引入zk增加维护成本还强依赖另一个中间件了。
- RocketMQ追求的是AP,而不是CP,也就是需要高可用。
- zk是CP,因为zk节点间通过zap协议有数据共享,每个节点数据会一致,但是zk集群当挂了一半以上的节点就没法使用了。
- nameserver是AP,节点间不通信,这样会导致节点间数据信息会发生短暂的不一致,但每个broker都会定时向所有nameserver上报路由信息和心跳。当某个broker下线了,nameserver也会延时30s才知道,而且不会通知客户端(生产和消费者),只能靠客户端自己来拉,rocketMQ是靠消息重试机制解决这个问题的,所以是最终一致性。但nameserver集群只要有一个节点就可用。
八.Redis
1. Redis是什么?简述它的优缺点?
Redis本质上是一个Key-Value类型的内存数据库,很像Memcached,整个数据库加载在内存当中操作,定期通过异步操作把数据库中的数据flush到硬盘上进行保存。
因为是纯内存操作,Redis的性能非常出色,每秒可以处理超过 10万次读写操作,是已知性能最快的Key-Value 数据库。
优点:
- 读写性能极高, Redis能读的速度是110000次/s,写的速度是81000次/s。
- 支持数据持久化,支持AOF和RDB两种持久化方式。
- 支持事务, Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- 数据结构丰富,除了支持string类型的value外,还支持hash、set、zset、list等数据结构。
- 支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等特性。
缺点:
- 数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
- 主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性。
2. Redis为什么这么快?
-
内存存储:Redis是使用内存(in-memeroy)存储,没有磁盘IO上的开销。数据存在内存中,类似于 HashMap,HashMap 的优势就是查找和操作的时间复杂度都是O(1)。
-
单线程实现( Redis 6.0以前):Redis使用单个线程处理请求,避免了多个线程之间线程切换和锁资源争用的开销。注意:单线程是指的是在核心网络模型中,网络请求模块使用一个线程来处理,即一个线程处理所有网络请求。
-
非阻塞IO:Redis使用多路复用IO技术,将epoll作为I/O多路复用技术的实现,再加上Redis自身的事件处理模型将epoll中的连接、读写、关闭都转换为事件,不在网络I/O上浪费过多的时间。
-
优化的数据结构:Redis有诸多可以直接应用的优化数据结构的实现,应用层可以直接使用原生的数据结构提升性能。
-
使用底层模型不同:Redis直接自己构建了 VM (虚拟内存)机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
Redis的VM(虚拟内存)机制就是暂时把不经常访问的数据(冷数据)从内存交换到磁盘中,从而腾出宝贵的内存空间用于其它需要访问的数据(热数据)。通过VM功能可以实现冷热数据分离,使热数据仍在内存中、冷数据保存到磁盘。这样就可以避免因为内存不足而造成访问速度下降的问题。
Redis提高数据库容量的办法有两种:一种是可以将数据分割到多个RedisServer上;另一种是使用虚拟内存把那些不经常访问的数据交换到磁盘上。需要特别注意的是Redis并没有使用OS提供的Swap,而是自己实现。
3. Redis相比Memcached有哪些优势?
-
数据类型:Memcached所有的值均是简单的字符串,Redis支持更为丰富的数据类型,支持string(字符串),list(列表),Set(集合)、Sorted Set(有序集合)、Hash(哈希)等。
-
持久化:Redis支持数据落地持久化存储,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。 memcache不支持数据持久存储 。
-
集群模式:Redis提供主从同步机制,以及 Cluster集群部署能力,能够提供高可用服务。Memcached没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据
-
性能对比:Redis的速度比Memcached快很多。
-
网络IO模型:Redis使用单线程的多路 IO 复用模型,Memcached使用多线程的非阻塞IO模式。
-
Redis支持服务器端的数据操作:Redis相比Memcached来说,拥有更多的数据结构和并支持更丰富的数据操作,通常在Memcached里,你需要将数据拿到客户端来进行类似的修改再set回去。
这大大增加了网络IO的次数和数据体积。在Redis中,这些复杂的操作通常和一般的GET/SET一样高效。所以,如果需要缓存能够支持更复杂的结构和操作,那么Redis会是不错的选择。
4. 为什么要用 Redis 做缓存?
从高并发上来说:
- 直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
从高性能上来说:
- 用户第一次访问数据库中的某些数据。 因为是从硬盘上读取的所以这个过程会比较慢。将该用户访问的数据存在缓存中,下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据。
5. 为什么要用 Redis 而不用 map/guava 做缓存?
缓存分为本地缓存和分布式缓存。以java为例,使用自带的map或者guava实现的是本地缓存,最主要的特点是轻量以及快速,生命周期随着jvm的销毁而结束,并且在多实例的情况下,每个实例都需要各自保存一份缓存,缓存不具有一致性。
使用Redis或memcached之类的称为分布式缓存,在多实例的情况下,各实例共用一份缓存数据,缓存具有一致性。缺点是需要保持Redis或memcached服务的高可用,整个程序架构上较为复杂。
对比:
- Redis 可以用几十 G 内存来做缓存,Map 不行,一般 JVM 也就分几个 G 数据就够大了;
- Redis 的缓存可以持久化,Map 是内存对象,程序一重启数据就没了;
- Redis 可以实现分布式的缓存,Map 只能存在创建它的程序里;
- Redis 可以处理每秒百万级的并发,是专业的缓存服务,Map 只是一个普通的对象;
- Redis 缓存有过期机制,Map 本身无此功能;Redis 有丰富的 API,Map 就简单太多了;
- Redis可单独部署,多个项目之间可以共享,本地内存无法共享;
- Redis有专门的管理工具可以查看缓存数据。
6. Redis的常用场景有哪些?
1、缓存
缓存现在几乎是所有中大型网站都在用的必杀技,合理的利用缓存不仅能够提升网站访问速度,还能大大降低数据库的压力。Redis提供了键过期功能,也提供了灵活的键淘汰策略,所以,现在Redis用在缓存的场合非常多。
2、排行榜
很多网站都有排行榜应用的,如京东的月度销量榜单、商品按时间的上新排行榜等。Redis提供的有序集合数据类构能实现各种复杂的排行榜应用。
3、计数器
什么是计数器,如电商网站商品的浏览量、视频网站视频的播放数等。为了保证数据实时效,每次浏览都得给+1,并发量高时如果每次都请求数据库操作无疑是种挑战和压力。Redis提供的incr命令来实现计数器功能,内存操作,性能非常好,非常适用于这些计数场景。
4、分布式会话
集群模式下,在应用不多的情况下一般使用容器自带的session复制功能就能满足,当应用增多相对复杂的系统中,一般都会搭建以Redis等内存数据库为中心的session服务,session不再由容器管理,而是由session服务及内存数据库管理。
5、分布式锁
在很多互联网公司中都使用了分布式技术,分布式技术带来的技术挑战是对同一个资源的并发访问,如全局ID、减库存、秒杀等场景,并发量不大的场景可以使用数据库的悲观锁、乐观锁来实现,但在并发量高的场合中,利用数据库锁来控制资源的并发访问是不太理想的,大大影响了数据库的性能。可以利用Redis的setnx功能来编写分布式的锁,如果设置返回1说明获取锁成功,否则获取锁失败,实际应用中要考虑的细节要更多。
6、 社交网络
点赞、踩、关注/被关注、共同好友等是社交网站的基本功能,社交网站的访问量通常来说比较大,而且传统的关系数据库类型不适合存储这种类型的数据,Redis提供的哈希、集合等数据结构能很方便的的实现这些功能。如在微博中的共同好友,通过Redis的set能够很方便得出。
7、最新列表
Redis列表结构,LPUSH可以在列表头部插入一个内容ID作为关键字,LTRIM可用来限制列表的数量,这样列表永远为N个ID,无需查询最新的列表,直接根据ID去到对应的内容页即可。
8、消息系统
消息队列是大型网站必用中间件,如ActiveMQ、RabbitMQ、Kafka等流行的消息队列中间件,主要用于业务解耦、流量削峰及异步处理实时性低的业务。Redis提供了发布/订阅及阻塞队列功能,能实现一个简单的消息队列系统。另外,这个不能和专业的消息中间件相比。
7. Redis的数据类型有哪些?
有五种常用数据类型:String、Hash、Set、List、SortedSet。以及三种特殊的数据类型:Bitmap、HyperLogLog、Geospatial ,其中HyperLogLog、Bitmap的底层都是 String 数据类型,Geospatial 的底层是 Sorted Set 数据类型。
五种常用的数据类型:
1、String:String是最常用的一种数据类型,普通的key- value 存储都可以归为此类。其中Value既可以是数字也可以是字符串。使用场景:常规key-value缓存应用。常规计数: 微博数, 粉丝数。
2、Hash:Hash 是一个键值(key => value)对集合。Redishash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象,并且可以像数据库中update一个属性一样只修改某一项属性值。
3、Set:Set是一个无序的天然去重的集合,即Key-Set。此外还提供了交集、并集等一系列直接操作集合的方法,对于求共同好友、共同关注什么的功能实现特别方便。
4、List:List是一个有序可重复的集合,其遵循FIFO的原则,底层是依赖双向链表实现的,因此支持正向、反向双重查找。通过List,我们可以很方面的获得类似于最新回复这类的功能实现。
5、SortedSet:类似于java中的TreeSet,是Set的可排序版。此外还支持优先级排序,维护了一个score的参数来实现。适用于排行榜和带权重的消息队列等场景。
三种特殊的数据类型:
1、Bitmap:位图,Bitmap想象成一个以位为单位数组,数组中的每个单元只能存0或者1,数组的下标在Bitmap中叫做偏移量。使用Bitmap实现统计功能,更省空间。如果只需要统计数据的二值状态,例如商品有没有、用户在不在等,就可以使用 Bitmap,因为它只用一个 bit 位就能表示 0 或 1。
2、Hyperloglog。HyperLogLog 是一种用于统计基数的数据集合类型,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大
时,计算基数所需的空间总是固定 的、并且是很小的。每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。场景:统计网页的UV(即Unique Visitor,不重复访客,一个人访问某个网站多次,但是还是只计算为一次)。
要注意,HyperLogLog 的统计规则是基于概率完成的,所以它给出的统计结果是有一定误差的,标准误算率是 0.81%。
3、Geospatial :主要用于存储地理位置信息,并对存储的信息进行操作,适用场景如朋友的定位、附近的人、打车距离计算等。
持久化
8. Redis持久化机制?
为了能够重用Redis数据,或者防止系统故障,我们需要将Redis中的数据写入到磁盘空间中,即持久化。
Redis提供了两种不同的持久化方法可以将数据存储在磁盘中,一种叫快照RDB,另一种叫只追加文件AOF。
RDB
在指定的时间间隔内将内存中的数据集快照写入磁盘(Snapshot),它恢复时是将快照文件直接读到内存里。
优势:适合大规模的数据恢复;对数据完整性和一致性要求不高
劣势:在一定间隔时间做一次备份,所以如果Redis意外down掉的话,就会丢失最后一次快照后的所有修改。
AOF
以日志的形式来记录每个写操作,将Redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,Redis启动之初会读取该文件重新构建数据,换言之,Redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
AOF采用文件追加方式,文件会越来越大,为避免出现此种情况,新增了重写机制,当AOF文件的大小超过所设定的阈值时, Redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集.。
优势
- 每修改同步:
appendfsync always同步持久化,每次发生数据变更会被立即记录到磁盘,性能较差但数据完整性比较好 - 每秒同步:
appendfsync everysec异步操作,每秒记录,如果一秒内宕机,有数据丢失 - 不同步:
appendfsync no从不同步
劣势
- 相同数据集的数据而言
aof文件要远大于rdb文件,恢复速度慢于rdb aof运行效率要慢于rdb,每秒同步策略效率较好,不同步效率和rdb相同
9. 如何选择合适的持久化方式
- 如果是数据不那么敏感,且可以从其他地方重新生成补回的,那么可以关闭持久化。
- 如果是数据比较重要,不想再从其他地方获取,且可以承受数分钟的数据丢失,比如缓存等,那么可以只使用RDB。
- 如果是用做内存数据库,要使用Redis的持久化,建议是RDB和AOF都开启,或者定期执行bgsave做快照备份,RDB方式更适合做数据的备份,AOF可以保证数据的不丢失。
补充:Redis4.0 对于持久化机制的优化
Redis4.0相对与3.X版本其中一个比较大的变化是4.0添加了新的混合持久化方式。
简单的说:新的AOF文件前半段是RDB格式的全量数据后半段是AOF格式的增量数据,如下图:

优势:混合持久化结合了RDB持久化 和 AOF 持久化的优点, 由于绝大部分都是RDB格式,加载速度快,同时结合AOF,增量的数据以AOF方式保存了,数据更少的丢失。
劣势:兼容性差,一旦开启了混合持久化,在4.0之前版本都不识别该aof文件,同时由于前部分是RDB格式,阅读性较差。
10. Redis持久化数据和缓存怎么做扩容?
-
如果Redis被当做缓存使用,使用一致性哈希实现动态扩容缩容。
-
如果Redis被当做一个持久化存储使用,必须使用固定的keys-to-nodes映射关系,节点的数量一旦确定不能变化。否则的话(即Redis节点需要动态变化的情况),必须使用可以在运行时进行数据再平衡的一套系统,而当前只有Redis集群可以做到这样。
过期键的删除策略、淘汰策略
11. Redis过期键的删除策略
Redis的过期删除策略就是:惰性删除和定期删除两种策略配合使用。
惰性删除:惰性删除不会去主动删除数据,而是在访问数据的时候,再检查当前键值是否过期,如果过期则执行删除并返回 null 给客户端,如果没有过期则返回正常信息给客户端。它的优点是简单,不需要对过期的数据做额外的处理,只有在每次访问的时候才会检查键值是否过期,缺点是删除过期键不及时,造成了一定的空间浪费。
定期删除:Redis会周期性的随机测试一批设置了过期时间的key并进行处理。测试到的已过期的key将被删除。
附:删除key常见的三种处理方式。
1、定时删除
在设置某个key 的过期时间同时,我们创建一个定时器,让定时器在该过期时间到来时,立即执行对其进行删除的操作。
优点:定时删除对内存是最友好的,能够保存内存的key一旦过期就能立即从内存中删除。
缺点:对CPU最不友好,在过期键比较多的时候,删除过期键会占用一部分 CPU 时间,对服务器的响应时间和吞吐量造成影响。
2、惰性删除
设置该key 过期时间后,我们不去管它,当需要该key时,我们在检查其是否过期,如果过期,我们就删掉它,反之返回该key。
优点:对 CPU友好,我们只会在使用该键时才会进行过期检查,对于很多用不到的key不用浪费时间进行过期检查。
缺点:对内存不友好,如果一个键已经过期,但是一直没有使用,那么该键就会一直存在内存中,如果数据库中有很多这种使用不到的过期键,这些键便永远不会被删除,内存永远不会释放。从而造成内存泄漏。
3、定期删除
每隔一段时间,我们就对一些key进行检查,删除里面过期的key。
优点:可以通过限制删除操作执行的时长和频率来减少删除操作对 CPU 的影响。另外定期删除,也能有效释放过期键占用的内存。
缺点:难以确定删除操作执行的时长和频率。如果执行的太频繁,定期删除策略变得和定时删除策略一样,对CPU不友好。如果执行的太少,那又和惰性删除一样了,过期键占用的内存不会及时得到释放。另外最重要的是,在获取某个键时,如果某个键的过期时间已经到了,但是还没执行定期删除,那么就会返回这个键的值,这是业务不能忍受的错误。
12. Redis key的过期时间和永久有效分别怎么设置?
通过expire或pexpire命令,客户端可以以秒或毫秒的精度为数据库中的某个键设置生存时间。
与expire和pexpire命令类似,客户端可以通过expireat和pexpireat命令,以秒或毫秒精度给数据库中的某个键设置过期时间,可以理解为:让某个键在某个时间点过期。
13. Redis内存淘汰策略
Redis是不断的删除一些过期数据,但是很多没有设置过期时间的数据也会越来越多,那么Redis内存不够用的时候是怎么处理的呢?答案就是淘汰策略。此类的
当Redis的内存超过最大允许的内存之后,Redis会触发内存淘汰策略,删除一些不常用的数据,以保证Redis服务器的正常运行。
Redisv4.0前提供 6种数据淘汰策略:
- volatile-lru:利用LRU算法移除设置过过期时间的key (LRU:最近使用 Least Recently Used )
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-eviction:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
Redisv4.0后增加以下两种:
- volatile-lfu:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰(LFU(Least Frequently Used)算法,也就是最频繁被访问的数据将来最有可能被访问到)
- allkeys-lfu:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的key。
内存淘汰策略可以通过配置文件来修改,Redis.conf对应的配置项是maxmemory-policy 修改对应的值就行,默认是noeviction。
缓存异常
缓存异常有四种类型,分别是缓存和数据库的数据不一致、缓存雪崩、缓存击穿和缓存穿透。
14. 如何保证缓存与数据库双写时的数据一致性?
背景:使用到缓存,无论是本地内存做缓存还是使用 Redis 做缓存,那么就会存在数据同步的问题,因为配置信息缓存在内存中,而内存时无法感知到数据在数据库的修改。这样就会造成数据库中的数据与缓存中数据不一致的问题。
共有四种方案:
- 先更新数据库,后更新缓存
- 先更新缓存,后更新数据库
- 先删除缓存,后更新数据库
- 先更新数据库,后删除缓存
第一种和第二种方案,没有人使用的,因为第一种方案存在问题是:并发更新数据库场景下,会将脏数据刷到缓存。
第二种方案存在的问题是:如果先更新缓存成功,但是数据库更新失败,则肯定会造成数据不一致。
目前主要用第三和第四种方案。
15. 先删除缓存,后更新数据库
该方案也会出问题,此时来了两个请求,请求 A(更新操作) 和请求 B(查询操作)
- 请求A进行写操作,删除缓存
- 请求B查询发现缓存不存在
- 请求B去数据库查询得到旧值
- 请求B将旧值写入缓存
- 请求A将新值写入数据库
上述情况就会导致不一致的情形出现。而且,如果不采用给缓存设置过期时间策略,该数据永远都是脏数据。
答案一:延时双删
最简单的解决办法延时双删
使用伪代码如下:
public void write(String key,Object data){
Redis.delKey(key);
db.updateData(data);
Thread.sleep(1000);
Redis.delKey(key);
}
转化为中文描述就是
(1)先淘汰缓存
(2)再写数据库(这两步和原来一样)
(3)休眠1秒,再次淘汰缓存,这么做,可以将1秒内所造成的缓存脏数据,再次删除。确保读请求结束,写请求可以删除读请求造成的缓存脏数据。自行评估自己的项目的读数据业务逻辑的耗时,写数据的休眠时间则在读数据业务逻辑的耗时基础上,加几百ms即可。
如果使用的是 Mysql 的读写分离的架构的话,那么其实主从同步之间也会有时间差。
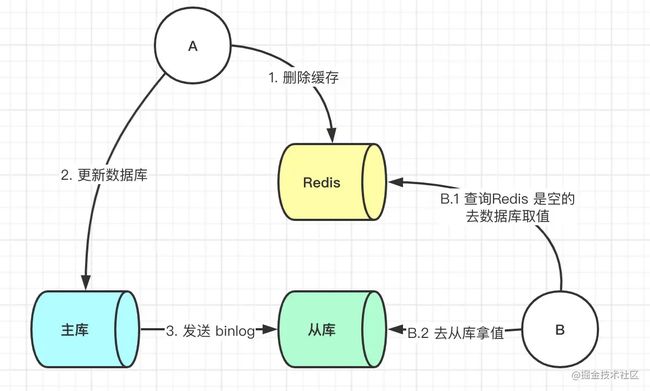
此时来了两个请求,请求 A(更新操作) 和请求 B(查询操作)
- 请求 A 更新操作,删除了 Redis
- 请求主库进行更新操作,主库与从库进行同步数据的操作
- 请 B 查询操作,发现 Redis 中没有数据
- 去从库中拿去数据
- 此时同步数据还未完成,拿到的数据是旧数据
此时的解决办法就是如果是对 Redis 进行填充数据的查询数据库操作,那么就强制将其指向主库进行查询。
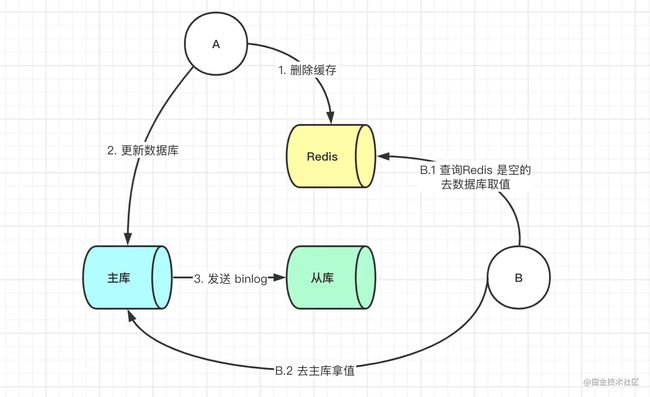
答案二: 更新与读取操作进行异步串行化
采用更新与读取操作进行异步串行化
异步串行化
我在系统内部维护n个内存队列,更新数据的时候,根据数据的唯一标识,将该操作路由之后,发送到其中一个jvm内部的内存队列中(对同一数据的请求发送到同一个队列)。读取数据的时候,如果发现数据不在缓存中,并且此时队列里有更新库存的操作,那么将重新读取数据+更新缓存的操作,根据唯一标识路由之后,也将发送到同一个jvm内部的内存队列中。然后每个队列对应一个工作线程,每个工作线程串行地拿到对应的操作,然后一条一条的执行。
这样的话,一个数据变更的操作,先执行删除缓存,然后再去更新数据库,但是还没完成更新的时候,如果此时一个读请求过来,读到了空的缓存,那么可以先将缓存更新的请求发送到队列中,此时会在队列中积压,排在刚才更新库的操作之后,然后同步等待缓存更新完成,再读库。
读操作去重
多个读库更新缓存的请求串在同一个队列中是没意义的,因此可以做过滤,如果发现队列中已经有了该数据的更新缓存的请求了,那么就不用再放进去了,直接等待前面的更新操作请求完成即可,待那个队列对应的工作线程完成了上一个操作(数据库的修改)之后,才会去执行下一个操作(读库更新缓存),此时会从数据库中读取最新的值,然后写入缓存中。
如果请求还在等待时间范围内,不断轮询发现可以取到值了,那么就直接返回;如果请求等待的时间超过一定时长,那么这一次直接从数据库中读取当前的旧值。(返回旧值不是又导致缓存和数据库不一致了么?那至少可以减少这个情况发生,因为等待超时也不是每次都是,几率很小吧。这里我想的是,如果超时了就直接读旧值,这时候仅仅是读库后返回而不放缓存)
16. 先更新数据库,后删除缓存
这一种情况也会出现问题,比如更新数据库成功了,但是在删除缓存的阶段出错了没有删除成功,那么此时再读取缓存的时候每次都是错误的数据了。
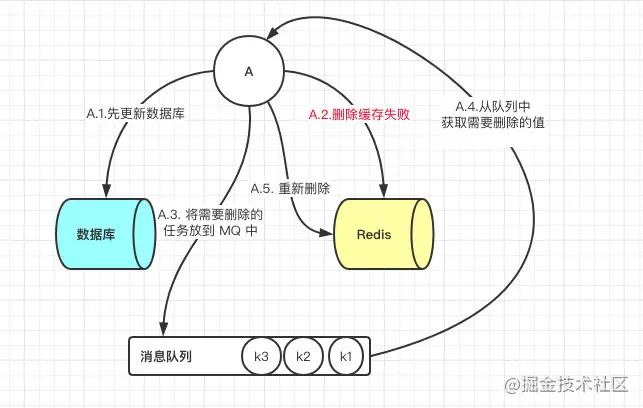
此时解决方案就是利用消息队列进行删除的补偿。具体的业务逻辑用语言描述如下:
- 请求 A 先对数据库进行更新操作
- 在对 Redis 进行删除操作的时候发现报错,删除失败
- 此时将Redis 的 key 作为消息体发送到消息队列中
- 系统接收到消息队列发送的消息后再次对 Redis 进行删除操作
但是这个方案会有一个缺点就是会对业务代码造成大量的侵入,深深的耦合在一起,所以这时会有一个优化的方案,我们知道对 Mysql 数据库更新操作后再 binlog 日志中我们都能够找到相应的操作,那么我们可以订阅 Mysql 数据库的 binlog 日志对缓存进行操作。
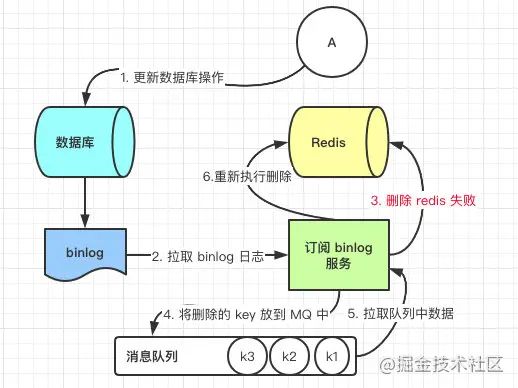
17. 什么是缓存击穿?
缓存击穿跟缓存雪崩有点类似,缓存雪崩是大规模的key失效,而缓存击穿是某个热点的key失效,大并发集中对其进行请求,就会造成大量请求读缓存没读到数据,从而导致高并发访问数据库,引起数据库压力剧增。这种现象就叫做缓存击穿。
从两个方面解决,第一是否可以考虑热点key不设置过期时间,第二是否可以考虑降低打在数据库上的请求数量。
解决方案:
-
在缓存失效后,通过互斥锁或者队列来控制读数据写缓存的线程数量,比如某个key只允许一个线程查询数据和写缓存,其他线程等待。这种方式会阻塞其他的线程,此时系统的吞吐量会下降
-
热点数据缓存永远不过期。永不过期实际包含两层意思:
- 物理不过期,针对热点key不设置过期时间
- 逻辑过期,把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建
18. 什么是缓存穿透?
缓存穿透是指用户请求的数据在缓存中不存在即没有命中,同时在数据库中也不存在,导致用户每次请求该数据都要去数据库中查询一遍。如果有恶意攻击者不断请求系统中不存在的数据,会导致短时间大量请求落在数据库上,造成数据库压力过大,甚至导致数据库承受不住而宕机崩溃。
缓存穿透的关键在于在Redis中查不到key值,它和缓存击穿的根本区别在于传进来的key在Redis中是不存在的。假如有黑客传进大量的不存在的key,那么大量的请求打在数据库上是很致命的问题,所以在日常开发中要对参数做好校验,一些非法的参数,不可能存在的key就直接返回错误提示。
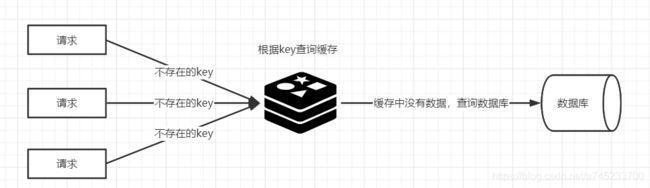
解决方法:
- 将无效的key存放进Redis中:
当出现Redis查不到数据,数据库也查不到数据的情况,我们就把这个key保存到Redis中,设置value=“null”,并设置其过期时间极短,后面再出现查询这个key的请求的时候,直接返回null,就不需要再查询数据库了。但这种处理方式是有问题的,假如传进来的这个不存在的Key值每次都是随机的,那存进Redis也没有意义。
- 使用布隆过滤器:
如果布隆过滤器判定某个 key 不存在布隆过滤器中,那么就一定不存在,如果判定某个 key 存在,那么很大可能是存在(存在一定的误判率)。于是我们可以在缓存之前再加一个布隆过滤器,将数据库中的所有key都存储在布隆过滤器中,在查询Redis前先去布隆过滤器查询 key 是否存在,如果不存在就直接返回,不让其访问数据库,从而避免了对底层存储系统的查询压力。
如何选择:针对一些恶意攻击,攻击带过来的大量key是随机,那么我们采用第一种方案就会缓存大量不存在key的数据。那么这种方案就不合适了,我们可以先对使用布隆过滤器方案进行过滤掉这些key。所以,针对这种key异常多、请求重复率比较低的数据,优先使用第二种方案直接过滤掉。而对于空数据的key有限的,重复率比较高的,则可优先采用第一种方式进行缓存。
19. 什么是缓存雪崩?
如果缓在某一个时刻出现大规模的key失效,那么就会导致大量的请求打在了数据库上面,导致数据库压力巨大,如果在高并发的情况下,可能瞬间就会导致数据库宕机。这时候如果运维马上又重启数据库,马上又会有新的流量把数据库打死。这就是缓存雪崩。
造成缓存雪崩的关键在于同一时间的大规模的key失效,主要有两种可能:第一种是Redis宕机,第二种可能就是采用了相同的过期时间。
解决方案:
1、事前:
-
均匀过期:设置不同的过期时间,让缓存失效的时间尽量均匀,避免相同的过期时间导致缓存雪崩,造成大量数据库的访问。如把每个Key的失效时间都加个随机值,
setRedis(Key,value,time + Math.random() * 10000);,保证数据不会在同一时间大面积失效。 -
分级缓存:第一级缓存失效的基础上,访问二级缓存,每一级缓存的失效时间都不同。
-
热点数据缓存永远不过期。永不过期实际包含两层意思:
- 物理不过期,针对热点key不设置过期时间
- 逻辑过期,把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建
-
保证Redis缓存的高可用,防止Redis宕机导致缓存雪崩的问题。可以使用 主从+ 哨兵,Redis集群来避免 Redis 全盘崩溃的情况。
2、事中:
-
互斥锁:在缓存失效后,通过互斥锁或者队列来控制读数据写缓存的线程数量,比如某个key只允许一个线程查询数据和写缓存,其他线程等待。这种方式会阻塞其他的线程,此时系统的吞吐量会下降
-
使用熔断机制,限流降级。当流量达到一定的阈值,直接返回“系统拥挤”之类的提示,防止过多的请求打在数据库上将数据库击垮,至少能保证一部分用户是可以正常使用,其他用户多刷新几次也能得到结果。
3、事后:
开启Redis持久化机制,尽快恢复缓存数据,一旦重启,就能从磁盘上自动加载数据恢复内存中的数据。
20. 什么是缓存预热?
缓存预热是指系统上线后,提前将相关的缓存数据加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题,用户直接查询事先被预热的缓存数据。
如果不进行预热,那么Redis初始状态数据为空,系统上线初期,对于高并发的流量,都会访问到数据库中, 对数据库造成流量的压力。
缓存预热解决方案:
-
数据量不大的时候,工程启动的时候进行加载缓存动作;
-
数据量大的时候,设置一个定时任务脚本,进行缓存的刷新;
-
数据量太大的时候,优先保证热点数据进行提前加载到缓存。
21. 什么是缓存降级?
缓存降级是指缓存失效或缓存服务器挂掉的情况下,不去访问数据库,直接返回默认数据或访问服务的内存数据。降级一般是有损的操作,所以尽量减少降级对于业务的影响程度。
在进行降级之前要对系统进行梳理,看看系统是不是可以丢卒保帅;从而梳理出哪些必须誓死保护,哪些可降级;比如可以参考日志级别设置预案:
-
一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;
-
警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警;
-
错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的最大阀值,此时可以根据情况自动降级或者人工降级;
-
严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。
线程模型
22. Redis为何选择单线程?
在Redis 6.0以前,Redis的核心网络模型选择用单线程来实现。先来看下官方的回答:
It’s not very frequent that CPU becomes your bottleneck with Redis, as usually Redisis either memory or network bound. For instance, using pipelining Redisrunning on an average Linux system can deliver even 1 million requests per second, so if your application mainly uses O(N) or O(log(N)) commands, it is hardly going to use too much CPU.
核心意思就是,对于一个 DB 来说,CPU 通常不会是瓶颈,因为大多数请求不会是 CPU 密集型的,而是 I/O 密集型。具体到 Redis的话,如果不考虑 RDB/AOF 等持久化方案,Redis是完全的纯内存操作,执行速度是非常快的,因此这部分操作通常不会是性能瓶颈,Redis真正的性能瓶颈在于网络 I/O,也就是客户端和服务端之间的网络传输延迟,因此 Redis选择了单线程的 I/O 多路复用来实现它的核心网络模型。
实际上更加具体的选择单线程的原因如下:
- 避免过多的上下文切换开销:如果是单线程则可以规避进程内频繁的线程切换开销,因为程序始终运行在进程中单个线程内,没有多线程切换的场景。
- 避免同步机制的开销:如果 Redis选择多线程模型,又因为 Redis是一个数据库,那么势必涉及到底层数据同步的问题,则必然会引入某些同步机制,比如锁,而我们知道 Redis不仅仅提供了简单的 key-value 数据结构,还有 list、set 和 hash 等等其他丰富的数据结构,而不同的数据结构对同步访问的加锁粒度又不尽相同,可能会导致在操作数据过程中带来很多加锁解锁的开销,增加程序复杂度的同时还会降低性能。
- 简单可维护:如果 Redis使用多线程模式,那么所有的底层数据结构都必须实现成线程安全的,这无疑又使得 Redis的实现变得更加复杂。
总而言之,Redis选择单线程可以说是多方博弈之后的一种权衡:在保证足够的性能表现之下,使用单线程保持代码的简单和可维护性。
23. Redis真的是单线程?
讨论 这个问题前,先看下 Redis的版本中两个重要的节点:
- Redisv4.0(引入多线程处理异步任务)
- Redis 6.0(在网络模型中实现多线程 I/O )
所以,网络上说的Redis是单线程,通常是指在Redis 6.0之前,其核心网络模型使用的是单线程。
且Redis6.0引入多线程I/O,只是用来处理网络数据的读写和协议的解析,而执行命令依旧是单线程。
Redis在 v4.0 版本的时候就已经引入了的多线程来做一些异步操作,此举主要针对的是那些非常耗时的命令,通过将这些命令的执行进行异步化,避免阻塞单线程的事件循环。
在 Redisv4.0 之后增加了一些的非阻塞命令如
UNLINK、FLUSHALL ASYNC、FLUSHDB ASYNC。
24. Redis 6.0为何引入多线程?
很简单,就是 Redis的网络 I/O 瓶颈已经越来越明显了。
随着互联网的飞速发展,互联网业务系统所要处理的线上流量越来越大,Redis的单线程模式会导致系统消耗很多 CPU 时间在网络 I/O 上从而降低吞吐量,要提升 Redis的性能有两个方向:
- 优化网络 I/O 模块
- 提高机器内存读写的速度
后者依赖于硬件的发展,暂时无解。所以只能从前者下手,网络 I/O 的优化又可以分为两个方向:
- 零拷贝技术或者 DPDK 技术
- 利用多核优势
零拷贝技术有其局限性,无法完全适配 Redis这一类复杂的网络 I/O 场景,更多网络 I/O 对 CPU 时间的消耗和 Linux 零拷贝技术。而 DPDK 技术通过旁路网卡 I/O 绕过内核协议栈的方式又太过于复杂以及需要内核甚至是硬件的支持。
总结起来,Redis支持多线程主要就是两个原因:
-
可以充分利用服务器 CPU 资源,目前主线程只能利用一个核
-
多线程任务可以分摊 Redis 同步 IO 读写负荷
25. Redis 6.0 采用多线程后,性能的提升效果如何?
Redis 作者 antirez 在 RedisConf 2019 分享时曾提到:Redis 6 引入的多线程 IO 特性对性能提升至少是一倍以上。
国内也有大牛曾使用 unstable 版本在阿里云 esc 进行过测试,GET/SET 命令在 4 线程 IO 时性能相比单线程是几乎是翻倍了。
26. 介绍下Redis的线程模型
Redis的线程模型包括Redis 6.0之前和Redis 6.0。
下面介绍的是Redis 6.0之前。
Redis 是基于 reactor 模式开发了网络事件处理器,这个处理器叫做文件事件处理器(file event handler)。由于这个文件事件处理器是单线程的,所以 Redis 才叫做单线程的模型。采用 IO 多路复用机制同时监听多个 Socket,根据 socket 上的事件来选择对应的事件处理器来处理这个事件。
IO多路复用是 IO 模型的一种,有时也称为异步阻塞 IO,是基于经典的 Reactor 设计模式设计的。多路指的是多个 Socket 连接,复用指的是复用一个线程。多路复用主要有三种技术:Select,Poll,Epoll。
Epoll 是最新的也是目前最好的多路复用技术。
模型如下图:

文件事件处理器的结构包含了四个部分:
- 多个 Socket。Socket 会产生 AE_READABLE 和 AE_WRITABLE 事件:
- 当 socket 变得可读时或者有新的可以应答的 socket 出现时,socket 就会产生一个 AE_READABLE 事件
- 当 socket 变得可写时,socket 就会产生一个 AE_WRITABLE 事件。
- IO 多路复用程序
- 文件事件分派器
- 事件处理器。事件处理器包括:连接应答处理器、命令请求处理器、命令回复处理器,每个处理器对应不同的 socket 事件:
- 如果是客户端要连接 Redis,那么会为 socket 关联连接应答处理器
- 如果是客户端要写数据到 Redis(读、写请求命令),那么会为 socket 关联命令请求处理器
- 如果是客户端要从 Redis 读数据,那么会为 socket 关联命令回复处理器
多个 socket 会产生不同的事件,不同的事件对应着不同的操作,IO 多路复用程序监听着这些 Socket,当这些 Socket 产生了事件,IO 多路复用程序会将这些事件放到一个队列中,通过这个队列,以有序、同步、每次一个事件的方式向文件时间分派器中传送。当事件处理器处理完一个事件后,IO 多路复用程序才会继续向文件分派器传送下一个事件。
下图是客户端与 Redis 通信的一次完整的流程:
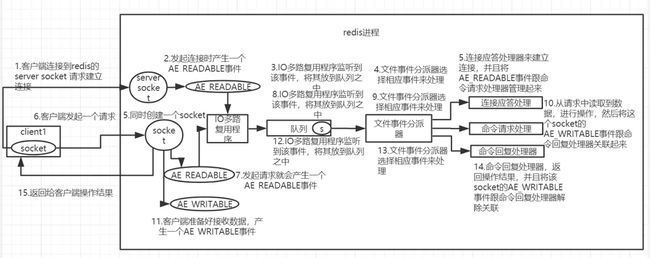
- Redis 启动初始化的时候,Redis 会将连接应答处理器与 AE_READABLE 事件关联起来。
- 如果一个客户端跟 Redis 发起连接,此时 Redis 会产生一个 AE_READABLE 事件,由于开始之初 AE_READABLE 是与连接应答处理器关联,所以由连接应答处理器来处理该事件,这时连接应答处理器会与客户端建立连接,创建客户端响应的 socket,同时将这个 socket 的 AE_READABLE 事件与命令请求处理器关联起来。
- 如果这个时间客户端向 Redis 发送一个命令(set k1 v1),这时 socket 会产生一个 AE_READABLE 事件,IO 多路复用程序会将该事件压入队列中,此时事件分派器从队列中取得该事件,由于该 socket 的 AE_READABLE 事件已经和命令请求处理器关联了,因此事件分派器会将该事件交给命令请求处理器处理,命令请求处理器读取事件中的命令并完成。操作完成后,Redis 会将该 socket 的 AE_WRITABLE 事件与命令回复处理器关联。
- 如果客户端已经准备好接受数据后,Redis 中的该 socket 会产生一个 AE_WRITABLE 事件,同样会压入队列然后被事件派发器取出交给相对应的命令回复处理器,由该命令回复处理器将准备好的响应数据写入 socket 中,供客户端读取。
- 命令回复处理器写完后,就会删除该 socket 的 AE_WRITABLE 事件与命令回复处理器的关联关系。
27. Redis 6.0 多线程的实现机制?
流程简述如下:
- 主线程负责接收建立连接请求,获取 Socket 放入全局等待读处理队列。
- 主线程处理完读事件之后,通过 RR(Round Robin)将这些连接分配给这些 IO 线程。
- 主线程阻塞等待 IO 线程读取 Socket 完毕。
- 主线程通过单线程的方式执行请求命令,请求数据读取并解析完成,但并不执行。
- 主线程阻塞等待 IO 线程将数据回写 Socket 完毕。
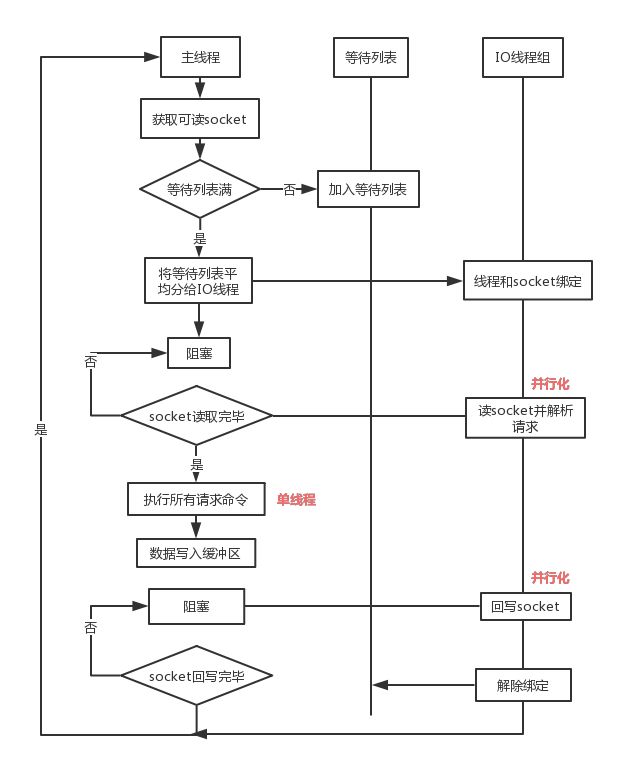
该设计有如下特点:
- IO 线程要么同时在读 Socket,要么同时在写,不会同时读或写。
- IO 线程只负责读写 Socket 解析命令,不负责命令处理。
28. Redis 6.0开启多线程后,是否会存在线程并发安全问题?
从实现机制可以看出,Redis 的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程顺序执行。
所以我们不需要去考虑控制 Key、Lua、事务,LPUSH/LPOP 等等的并发及线程安全问题。
29. Redis 6.0 与 Memcached 多线程模型的对比
-
**相同点:**都采用了 Master 线程 -Worker 线程的模型。
-
不同点:Memcached 执行主逻辑也是在 Worker 线程里,模型更加简单,实现了真正的线程隔离,符合我们对线程隔离的常规理解。
而 Redis 把处理逻辑交还给 Master 线程,虽然一定程度上增加了模型复杂度,但也解决了线程并发安全等问题。
事务
30. Redis事务的概念
Redis的事务并不是我们传统意义上理解的事务,我们都知道 单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
总结:
1. Redis事务中如果有某一条命令执行失败,之前的命令不会回滚,其后的命令仍然会被继续执行。鉴于这个原因,所以说Redis的事务严格意义上来说是不具备原子性的。
2. Redis事务中所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
3. 在事务开启之前,如果客户端与服务器之间出现通讯故障并导致网络断开,其后所有待执行的语句都将不会被服务器执行。然而如果网络中断事件是发生在客户端执行EXEC命令之后,那么该事务中的所有命令都会被服务器执行。
当使用Append-Only模式时,Redis会通过调用系统函数write将该事务内的所有写操作在本次调用中全部写入磁盘。然而如果在写入的过程中出现系统崩溃,如电源故障导致的宕机,那么此时也许只有部分数据被写入到磁盘,而另外一部分数据却已经丢失。Redis服务器会在重新启动时执行一系列必要的一致性检测,一旦发现类似问题,就会立即退出并给出相应的错误提示。此时,我们就要充分利用Redis工具包中提供的Redis-check-aof工具,该工具可以帮助我们定位到数据不一致的错误,并将已经写入的部分数据进行回滚。修复之后我们就可以再次重新启动Redis服务器了。
31. Redis事务的三个阶段
- multi 开启事务
- 大量指令入队
- exec执行事务块内命令,截止此处一个事务已经结束。
- discard 取消事务
- watch 监视一个或多个key,如果事务执行前key被改动,事务将打断。unwatch 取消监视。
事务执行过程中,如果服务端收到有EXEC、DISCARD、WATCH、MULTI之外的请求,将会把请求放入队列中排队.
32. Redis事务相关命令
Redis事务功能是通过MULTI、EXEC、DISCARD和WATCH 四个原语实现的
- WATCH 命令是一个乐观锁,可以为 Redis 事务提供 check-and-set (CAS)行为。 可以监控一个或多个键,一旦其中有一个键被修改(或删除),之后的事务就不会执行,监控一直持续到EXEC命令。
- MULTI命令用于开启一个事务,它总是返回OK。 MULTI执行之后,客户端可以继续向服务器发送任意多条命令,这些命令不会立即被执行,而是被放到一个队列中,当EXEC命令被调用时,所有队列中的命令才会被执行。
- EXEC:执行所有事务块内的命令。返回事务块内所有命令的返回值,按命令执行的先后顺序排列。 当操作被打断时,返回空值 nil 。
通过调用DISCARD,客户端可以清空事务队列,并放弃执行事务, 并且客户端会从事务状态中退出。 - UNWATCH命令可以取消watch对所有key的监控。
33. Redis事务支持隔离性吗?
Redis 是单进程程序,并且它保证在执行事务时,不会对事务进行中断,事务可以运行直到执行完所有事务队列中的命令为止。因此,Redis 的事务是总是带有隔离性的。
34. Redis为什么不支持事务回滚?
- Redis 命令只会因为错误的语法而失败,或是命令用在了错误类型的键上面,这些问题不能在入队时发现,这也就是说,从实用性的角度来说,失败的命令是由编程错误造成的,而这些错误应该在开发的过程中被发现,而不应该出现在生产环境中.
- 因为不需要对回滚进行支持,所以 Redis 的内部可以保持简单且快速。
35. Redis事务其他实现
- 基于Lua脚本,Redis可以保证脚本内的命令一次性、按顺序地执行,
其同时也不提供事务运行错误的回滚,执行过程中如果部分命令运行错误,剩下的命令还是会继续运行完。 - 基于中间标记变量,通过另外的标记变量来标识事务是否执行完成,读取数据时先读取该标记变量判断是否事务执行完成。但这样会需要额外写代码实现,比较繁琐。
主从、哨兵、集群
36. Redis常见使用方式有哪些?
Redis的几种常见使用方式包括:
- Redis单副本;
- Redis多副本(主从);
- Redis Sentinel(哨兵);
- Redis Cluster;
- Redis自研。
使用场景:
如果数据量很少,主要是承载高并发高性能的场景,比如缓存一般就几个G的话,单机足够了。
主从模式:master 节点挂掉后,需要手动指定新的 master,可用性不高,基本不用。
哨兵模式:master 节点挂掉后,哨兵进程会主动选举新的 master,可用性高,但是每个节点存储的数据是一样的,浪费内存空间。数据量不是很多,集群规模不是很大,需要自动容错容灾的时候使用。
Redis cluster 主要是针对海量数据+高并发+高可用的场景,如果是海量数据,如果你的数据量很大,那么建议就用Redis cluster,所有master的容量总和就是Redis cluster可缓存的数据容量。
37. 介绍下Redis单副本
Redis单副本,采用单个Redis节点部署架构,没有备用节点实时同步数据,不提供数据持久化和备份策略,适用于数据可靠性要求不高的纯缓存业务场景。
优点:
- 架构简单,部署方便;
- 高性价比:缓存使用时无需备用节点(单实例可用性可以用supervisor或crontab保证),当然为了满足业务的高可用性,也可以牺牲一个备用节点,但同时刻只有一个实例对外提供服务;
- 高性能。
缺点:
- 不保证数据的可靠性;
- 在缓存使用,进程重启后,数据丢失,即使有备用的节点解决高可用性,但是仍然不能解决缓存预热问题,因此不适用于数据可靠性要求高的业务;
- 高性能受限于单核CPU的处理能力(Redis是单线程机制),CPU为主要瓶颈,所以适合操作命令简单,排序、计算较少的场景。也可以考虑用Memcached替代。
38. 介绍下Redis多副本(主从)
Redis多副本,采用主从(replication)部署结构,相较于单副本而言最大的特点就是主从实例间数据实时同步,并且提供数据持久化和备份策略。主从实例部署在不同的物理服务器上,根据公司的基础环境配置,可以实现同时对外提供服务和读写分离策略。
优点:
- 高可靠性:一方面,采用双机主备架构,能够在主库出现故障时自动进行主备切换,从库提升为主库提供服务,保证服务平稳运行;另一方面,开启数据持久化功能和配置合理的备份策略,能有效的解决数据误操作和数据异常丢失的问题;
- 读写分离策略:从节点可以扩展主库节点的读能力,有效应对大并发量的读操作。
缺点:
-
故障恢复复杂,如果没有RedisHA系统(需要开发),当主库节点出现故障时,需要手动将一个从节点晋升为主节点,同时需要通知业务方变更配置,并且需要让其它从库节点去复制新主库节点,整个过程需要人为干预,比较繁琐;
-
主库的写能力受到单机的限制,可以考虑分片;
-
主库的存储能力受到单机的限制,可以考虑Pika;
-
原生复制的弊端在早期的版本中也会比较突出,如:Redis复制中断后,Slave会发起psync,此时如果同步不成功,则会进行全量同步,主库执行全量备份的同时可能会造成毫秒或秒级的卡顿;又由于COW机制,导致极端情况下的主库内存溢出,程序异常退出或宕机;主库节点生成备份文件导致服务器磁盘IO和CPU(压缩)资源消耗;发送数GB大小的备份文件导致服务器出口带宽暴增,阻塞请求,建议升级到最新版本。
39. 介绍下Redis Sentinel(哨兵)
主从模式下,当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这种方式并不推荐,实际生产中,我们优先考虑哨兵模式。这种模式下,master 宕机,哨兵会自动选举 master 并将其他的 slave 指向新的 master。
Redis Sentinel是社区版本推出的原生高可用解决方案,其部署架构主要包括两部分:Redis Sentinel集群和Redis数据集群。
其中Redis Sentinel集群是由若干Sentinel节点组成的分布式集群,可以实现故障发现、故障自动转移、配置中心和客户端通知。Redis Sentinel的节点数量要满足2n+1(n>=1)的奇数个。
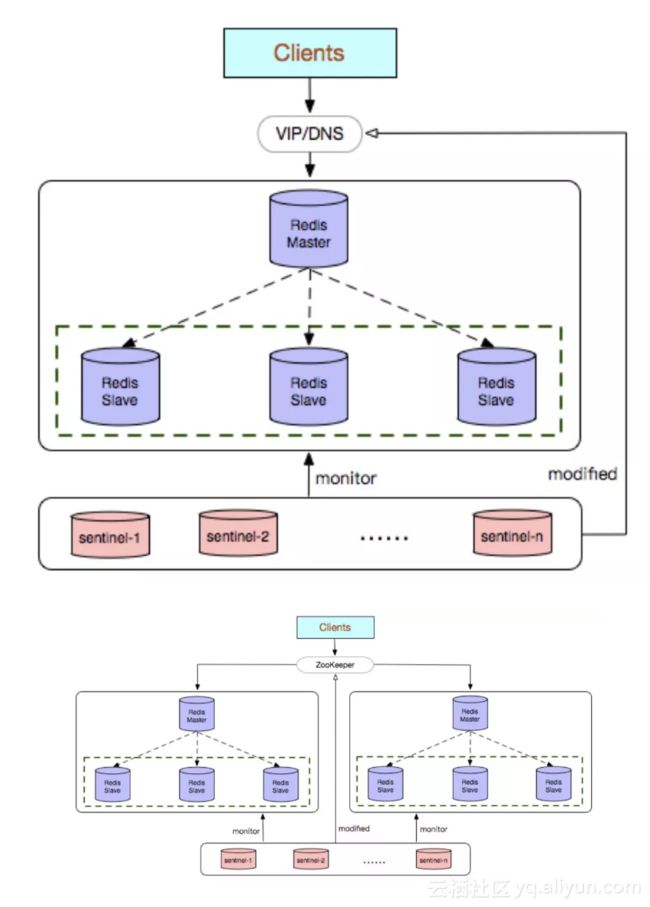
优点:
- Redis Sentinel集群部署简单;
- 能够解决Redis主从模式下的高可用切换问题;
- 很方便实现Redis数据节点的线形扩展,轻松突破Redis自身单线程瓶颈,可极大满足Redis大容量或高性能的业务需求;
- 可以实现一套Sentinel监控一组Redis数据节点或多组数据节点。
缺点:
- 部署相对Redis主从模式要复杂一些,原理理解更繁琐;
- 资源浪费,Redis数据节点中slave节点作为备份节点不提供服务;
- Redis Sentinel主要是针对Redis数据节点中的主节点的高可用切换,对Redis的数据节点做失败判定分为主观下线和客观下线两种,对于Redis的从节点有对节点做主观下线操作,并不执行故障转移。
- 不能解决读写分离问题,实现起来相对复杂。
40. 介绍下Redis Cluster
Redis 的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台 Redis 服务器都存储相同的数据,很浪费内存,所以在 Redis3.0 上加入了 Cluster 集群模式,实现了 Redis 的分布式存储,对数据进行分片,也就是说每台 Redis 节点上存储不同的内容。
Redis Cluster是社区版推出的Redis分布式集群解决方案,主要解决Redis分布式方面的需求,比如,当遇到单机内存,并发和流量等瓶颈的时候,Redis Cluster能起到很好的负载均衡的目的。
Redis Cluster集群节点最小配置6个节点以上(3主3从),其中主节点提供读写操作,从节点作为备用节点,不提供请求,只作为故障转移使用。
Redis Cluster采用虚拟槽分区,所有的键根据哈希函数映射到0~16383个整数槽内,每个节点负责维护一部分槽以及槽所印映射的键值数据。
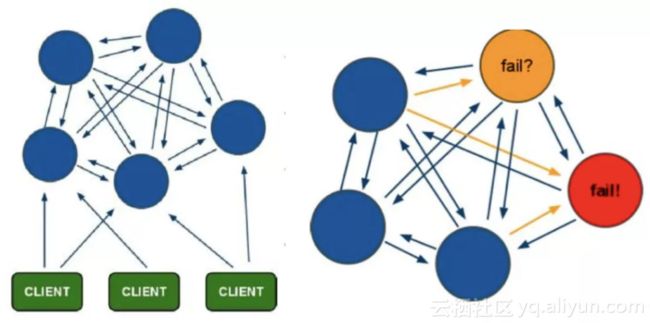
优点:
- 无中心架构;
- 数据按照slot存储分布在多个节点,节点间数据共享,可动态调整数据分布;
- 可扩展性:可线性扩展到1000多个节点,节点可动态添加或删除;
- 高可用性:部分节点不可用时,集群仍可用。通过增加Slave做standby数据副本,能够实现故障自动failover,节点之间通过gossip协议交换状态信息,用投票机制完成Slave到Master的角色提升;
- 降低运维成本,提高系统的扩展性和可用性。
缺点:
- Client实现复杂,驱动要求实现Smart Client,缓存slots mapping信息并及时更新,提高了开发难度,客户端的不成熟影响业务的稳定性。目前仅JedisCluster相对成熟,异常处理部分还不完善,比如常见的“max redirect exception”。
- 节点会因为某些原因发生阻塞(阻塞时间大于clutser-node-timeout),被判断下线,这种failover是没有必要的。
- 数据通过异步复制,不保证数据的强一致性。
- 多个业务使用同一套集群时,无法根据统计区分冷热数据,资源隔离性较差,容易出现相互影响的情况。
- Slave在集群中充当“冷备”,不能缓解读压力,当然可以通过SDK的合理设计来提高Slave资源的利用率。
- Key批量操作限制,如使用mset、mget目前只支持具有相同slot值的Key执行批量操作。对于映射为不同slot值的Key由于Keys不支持跨slot查询,所以执行mset、mget、sunion等操作支持不友好。
- Key事务操作支持有限,只支持多key在同一节点上的事务操作,当多个Key分布于不同的节点上时无法使用事务功能。
- Key作为数据分区的最小粒度,不能将一个很大的键值对象如hash、list等映射到不同的节点。
- 不支持多数据库空间,单机下的Redis可以支持到16个数据库,集群模式下只能使用1个数据库空间,即db 0。
- 复制结构只支持一层,从节点只能复制主节点,不支持嵌套树状复制结构。
- 避免产生hot-key,导致主库节点成为系统的短板。
- 避免产生big-key,导致网卡撑爆、慢查询等。
- 重试时间应该大于cluster-node-time时间。
- Redis Cluster不建议使用pipeline和multi-keys操作,减少max redirect产生的场景。
41. 介绍下Redis自研
Redis自研的高可用解决方案,主要体现在配置中心、故障探测和failover的处理机制上,通常需要根据企业业务的实际线上环境来定制化。
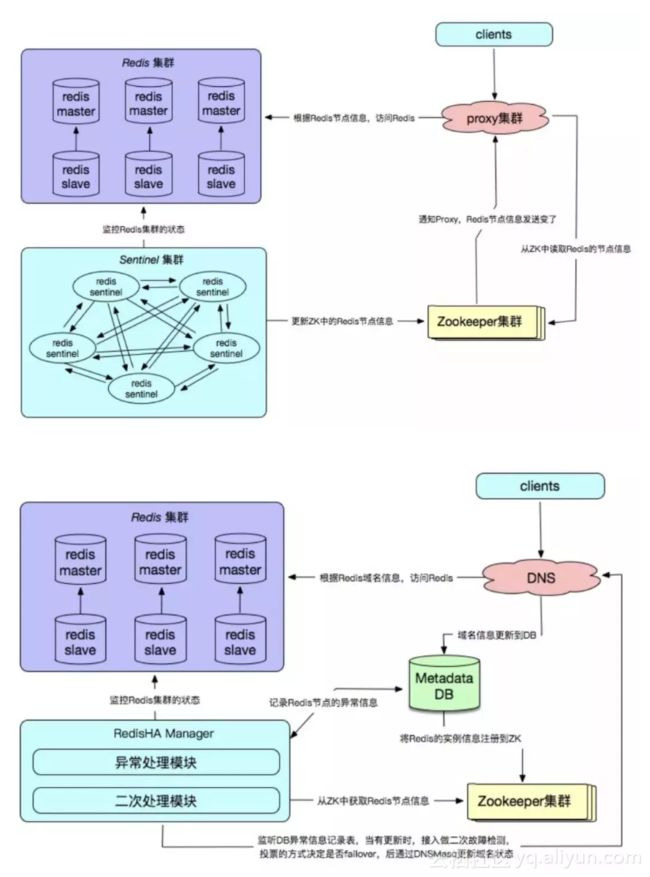
优点:
- 高可靠性、高可用性;
- 自主可控性高;
- 贴切业务实际需求,可缩性好,兼容性好。
缺点:
- 实现复杂,开发成本高;
- 需要建立配套的周边设施,如监控,域名服务,存储元数据信息的数据库等;
- 维护成本高。
42. Redis高可用方案具体怎么实施?
使用官方推荐的哨兵(sentinel)机制就能实现,当主节点出现故障时,由Sentinel自动完成故障发现和转移,并通知应用方,实现高可用性。它有四个主要功能:
- 集群监控,负责监控Redis master和slave进程是否正常工作。
- 消息通知,如果某个Redis实例有故障,那么哨兵负责发送消息作为报警通知给管理员。
- 故障转移,如果master node挂掉了,会自动转移到slave node上。
- 配置中心,如果故障转移发生了,通知client客户端新的master地址。
43. 了解主从复制的原理吗?
1、主从架构的核心原理
当启动一个slave node的时候,它会发送一个PSYNC命令给master node
如果这是slave node重新连接master node,那么master node仅仅会复制给slave部分缺少的数据; 否则如果是slave node第一次连接master node,那么会触发一次full resynchronization
开始full resynchronization的时候,master会启动一个后台线程,开始生成一份RDB快照文件,同时还会将从客户端收到的所有写命令缓存在内存中。RDB文件生成完毕之后,master会将这个RDB发送给slave,slave会先写入本地磁盘,然后再从本地磁盘加载到内存中。然后master会将内存中缓存的写命令发送给slave,slave也会同步这些数据。
slave node如果跟master node有网络故障,断开了连接,会自动重连。master如果发现有多个slave node都来重新连接,仅仅会启动一个rdb save操作,用一份数据服务所有slave node。
2、主从复制的断点续传
从Redis 2.8开始,就支持主从复制的断点续传,如果主从复制过程中,网络连接断掉了,那么可以接着上次复制的地方,继续复制下去,而不是从头开始复制一份
master node会在内存中常见一个backlog,master和slave都会保存一个replica offset还有一个master id,offset就是保存在backlog中的。如果master和slave网络连接断掉了,slave会让master从上次的replica offset开始继续复制
但是如果没有找到对应的offset,那么就会执行一次resynchronization
3、无磁盘化复制
master在内存中直接创建rdb,然后发送给slave,不会在自己本地落地磁盘了
repl-diskless-sync repl-diskless-sync-delay,等待一定时长再开始复制,因为要等更多slave重新连接过来
4、过期key处理
slave不会过期key,只会等待master过期key。如果master过期了一个key,或者通过LRU淘汰了一个key,那么会模拟一条del命令发送给slave。
44. 由于主从延迟导致读取到过期数据怎么处理?
- 通过scan命令扫库:当Redis中的key被scan的时候,相当于访问了该key,同样也会做过期检测,充分发挥Redis惰性删除的策略。这个方法能大大降低了脏数据读取的概率,但缺点也比较明显,会造成一定的数据库压力,否则影响线上业务的效率。
- Redis加入了一个新特性来解决主从不一致导致读取到过期数据问题,增加了key是否过期以及对主从库的判断,如果key已过期,当前访问的master则返回null;当前访问的是从库,且执行的是只读命令也返回null。
45. 主从复制的过程中如果因为网络原因停止复制了会怎么样?
如果出现网络故障断开连接了,会自动重连的,从Redis 2.8开始,就支持主从复制的断点续传,可以接着上次复制的地方,继续复制下去,而不是从头开始复制一份。
master如果发现有多个slave node都来重新连接,仅仅会启动一个rdb save操作,用一份数据服务所有slave node。
master node会在内存中创建一个backlog,master和slave都会保存一个replica offset,还有一个master id,offset就是保存在backlog中的。如果master和slave网络连接断掉了,slave会让master从上次的replica offset开始继续复制。
但是如果没有找到对应的offset,那么就会执行一次resynchronization全量复制。
46. Redis主从架构数据会丢失吗,为什么?
有两种数据丢失的情况:
- 异步复制导致的数据丢失:因为master -> slave的复制是异步的,所以可能有部分数据还没复制到slave,master就宕机了,此时这些部分数据就丢失了。
- 脑裂导致的数据丢失:某个master所在机器突然脱离了正常的网络,跟其他slave机器不能连接,但是实际上master还运行着,此时哨兵可能就会认为master宕机了,然后开启选举,将其他slave切换成了master。这个时候,集群里就会有两个master,也就是所谓的脑裂。此时虽然某个slave被切换成了master,但是可能client还没来得及切换到新的master,还继续写向旧master的数据可能也丢失了。因此旧master再次恢复的时候,会被作为一个slave挂到新的master上去,自己的数据会清空,重新从新的master复制数据。
47. 如何解决主从架构数据丢失的问题?
数据丢失的问题是不可避免的,但是我们可以尽量减少。
在Redis的配置文件里设置参数
min-slaves-to-write 1
min-slaves-max-lag 10
min-slaves-to-write默认情况下是0,min-slaves-max-lag默认情况下是10。
上面的配置的意思是要求至少有1个slave,数据复制和同步的延迟不能超过10秒。如果说一旦所有的slave,数据复制和同步的延迟都超过了10秒钟,那么这个时候,master就不会再接收任何请求了。
减小min-slaves-max-lag参数的值,这样就可以避免在发生故障时大量的数据丢失,一旦发现延迟超过了该值就不会往master中写入数据。
那么对于client,我们可以采取降级措施,将数据暂时写入本地缓存和磁盘中,在一段时间后重新写入master来保证数据不丢失;也可以将数据写入kafka消息队列,隔一段时间去消费kafka中的数据。
48. Redis哨兵是怎么工作的?
-
每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他 Sentinel 实例发送一个 PING 命令。
-
如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被当前 Sentinel 标记为主观下线。
-
如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。
-
当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态, 则Master会被标记为客观下线 。
-
当Master被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次 (在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有Master,Slave发送 INFO 命令 )。
-
若没有足够数量的 Sentinel 同意 Master 已经下线, Master 的客观下线状态就会变成主观下线。若 Master 重新向 Sentinel 的 PING 命令返回有效回复, Master 的主观下线状态就会被移除。
-
sentinel节点会与其他sentinel节点进行“沟通”,投票选举一个sentinel节点进行故障处理,在从节点中选取一个主节点,其他从节点挂载到新的主节点上自动复制新主节点的数据。
49. 故障转移时会从剩下的slave选举一个新的master,被选举为master的标准是什么?
如果一个master被认为odown了,而且majority哨兵都允许了主备切换,那么某个哨兵就会执行主备切换操作,此时首先要选举一个slave来,会考虑slave的一些信息。
- 跟master断开连接的时长。
如果一个slave跟master断开连接已经超过了down-after-milliseconds的10倍,外加master宕机的时长,那么slave就被认为不适合选举为master.
( down-after-milliseconds * 10) + milliseconds_since_master_is_in_SDOWN_state
-
slave优先级。
按照slave优先级进行排序,slave priority越低,优先级就越高 -
复制offset。
如果slave priority相同,那么看replica offset,哪个slave复制了越多的数据,offset越靠后,优先级就越高 -
run id
如果上面两个条件都相同,那么选择一个run id比较小的那个slave。
50. 同步配置的时候其他哨兵根据什么更新自己的配置呢?
执行切换的那个哨兵,会从要切换到的新master(salve->master)那里得到一个configuration epoch,这就是一个version号,每次切换的version号都必须是唯一的。
如果第一个选举出的哨兵切换失败了,那么其他哨兵,会等待failover-timeout时间,然后接替继续执行切换,此时会重新获取一个新的configuration epoch 作为新的version号。
这个version号就很重要了,因为各种消息都是通过一个channel去发布和监听的,所以一个哨兵完成一次新的切换之后,新的master配置是跟着新的version号的,其他的哨兵都是根据版本号的大小来更新自己的master配置的。
51. 为什么Redis哨兵集群只有2个节点无法正常工作?
哨兵集群必须部署2个以上节点。
如果两个哨兵实例,即两个Redis实例,一主一从的模式。
则Redis的配置quorum=1,表示一个哨兵认为master宕机即可认为master已宕机。
但是如果是机器1宕机了,那哨兵1和master都宕机了,虽然哨兵2知道master宕机了,但是这个时候,需要majority,也就是大多数哨兵都是运行的,2个哨兵的majority就是2(2的majority=2,3的majority=2,5的majority=3,4的majority=2),2个哨兵都运行着,就可以允许执行故障转移。
但此时哨兵1没了就只有1个哨兵了了,此时就没有majority来允许执行故障转移,所以故障转移不会执行。
52. Redis cluster中是如何实现数据分布的?这种方式有什么优点?
Redis cluster有固定的16384个hash slot(哈希槽),对每个key计算CRC16值,然后对16384取模,可以获取key对应的hash slot。
Redis cluster中每个master都会持有部分slot(槽),比如有3个master,那么可能每个master持有5000多个hash slot。
hash slot让node的增加和移除很简单,增加一个master,就将其他master的hash slot移动部分过去,减少一个master,就将它的hash slot移动到其他master上去。每次增加或减少master节点都是对16384取模,而不是根据master数量,这样原本在老的master上的数据不会因master的新增或减少而找不到。并且增加或减少master时Redis cluster移动hash slot的成本是非常低的。
53. Redis cluster节点间通信是什么机制?
Redis cluster节点间采取gossip协议进行通信,所有节点都持有一份元数据,不同的节点如果出现了元数据的变更之后U不断地i将元数据发送给其他节点让其他节点进行数据变更。
节点互相之间不断通信,保持整个集群所有节点的数据是完整的。
主要交换故障信息、节点的增加和移除、hash slot信息等。
这种机制的好处在于,元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续,打到所有节点上去更新,有一定的延时,降低了压力;
缺点,元数据更新有延时,可能导致集群的一些操作会有一些滞后。
分布式问题
54. 什么是分布式锁?为什么用分布式锁?
锁在程序中的作用就是同步工具,保证共享资源在同一时刻只能被一个线程访问,Java中的锁我们都很熟悉了,像synchronized 、Lock都是我们经常使用的,但是Java的锁只能保证单机的时候有效,分布式集群环境就无能为力了,这个时候我们就需要用到分布式锁。
分布式锁,顾名思义,就是分布式项目开发中用到的锁,可以用来控制分布式系统之间同步访问共享资源。
思路是:在整个系统提供一个全局、唯一的获取锁的“东西”,然后每个系统在需要加锁时,都去问这个“东西”拿到一把锁,这样不同的系统拿到的就可以认为是同一把锁。至于这个“东西”,可以是Redis、Zookeeper,也可以是数据库。
一般来说,分布式锁需要满足的特性有这么几点:
1、互斥性:在任何时刻,对于同一条数据,只有一台应用可以获取到分布式锁;
2、高可用性:在分布式场景下,一小部分服务器宕机不影响正常使用,这种情况就需要将提供分布式锁的服务以集群的方式部署;
3、防止锁超时:如果客户端没有主动释放锁,服务器会在一段时间之后自动释放锁,防止客户端宕机或者网络不可达时产生死锁;
4、独占性:加锁解锁必须由同一台服务器进行,也就是锁的持有者才可以释放锁,不能出现你加的锁,别人给你解锁了。
55. 常见的分布式锁有哪些解决方案?
实现分布式锁目前有三种流行方案,即基于关系型数据库、Redis、ZooKeeper 的方案
1、基于关系型数据库,如MySQL
基于关系型数据库实现分布式锁,是依赖数据库的唯一性来实现资源锁定,比如主键和唯一索引等。
缺点:
- 这把锁强依赖数据库的可用性,数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用。
- 这把锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁。
- 这把锁只能是非阻塞的,因为数据的insert操作,一旦插入失败就会直接报错。没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作。
- 这把锁是非重入的,同一个线程在没有释放锁之前无法再次获得该锁。因为数据中数据已经存在了。
2、基于Redis实现
优点:
Redis 锁实现简单,理解逻辑简单,性能好,可以支撑高并发的获取、释放锁操作。
缺点:
- Redis 容易单点故障,集群部署,并不是强一致性的,锁的不够健壮;
- key 的过期时间设置多少不明确,只能根据实际情况调整;
- 需要自己不断去尝试获取锁,比较消耗性能。
3、基于zookeeper
优点:
zookeeper 天生设计定位就是分布式协调,强一致性,锁很健壮。如果获取不到锁,只需要添加一个监听器就可以了,不用一直轮询,性能消耗较小。
缺点:
在高请求高并发下,系统疯狂的加锁释放锁,最后 zk 承受不住这么大的压力可能会存在宕机的风险。
56. Redis实现分布式锁
分布式锁的三个核心要素
1、加锁
使用setnx来加锁。key是锁的唯一标识,按业务来决定命名,value这里设置为test。
setx key test
当一个线程执行setnx返回1,说明key原本不存在,该线程成功得到了锁;当一个线程执行setnx返回0,说明key已经存在,该线程抢锁失败;
2、解锁
有加锁就得有解锁。当得到的锁的线程执行完任务,需要释放锁,以便其他线程可以进入。释放锁的最简单方式就是执行del指令。
del key
释放锁之后,其他线程就可以继续执行setnx命令来获得锁。
3、锁超时
锁超时知道的是:如果一个得到锁的线程在执行任务的过程中挂掉,来不及显式地释放锁,这块资源将会永远被锁住,别的线程北向进来。
所以,setnx的key必须设置一个超时时间,以保证即使没有被显式释放,这把锁也要在一段时间后自动释放。setnx不支持超时参数,所以需要额外指令,
expire key 30
上述分布式锁存在的问题
通过上述setnx 、del和expire实现的分布式锁还是存在着一些问题。
1、SETNX 和 EXPIRE 非原子性
假设一个场景中,某一个线程刚执行setnx,成功得到了锁。此时setnx刚执行成功,还未来得及执行expire命令,节点就挂掉了。此时这把锁就没有设置过期时间,别的线程就再也无法获得该锁。
解决措施:
由于setnx指令本身是不支持传入超时时间的,而在Redis2.6.12版本上为set指令增加了可选参数, 用法如下:
SET key value [EX seconds][PX milliseconds] [NX|XX]
- EX second: 设置键的过期时间为second秒;
- PX millisecond:设置键的过期时间为millisecond毫秒;
- NX:只在键不存在时,才对键进行设置操作;
- XX:只在键已经存在时,才对键进行设置操作;
- SET操作完成时,返回OK,否则返回nil。
2、锁误解除
如果线程 A 成功获取到了锁,并且设置了过期时间 30 秒,但线程 A 执行时间超过了 30 秒,锁过期自动释放,此时线程 B 获取到了锁;随后 A 执行完成,线程 A 使用 DEL 命令来释放锁,但此时线程 B 加的锁还没有执行完成,线程 A 实际释放的线程 B 加的锁。
解决办法:
在del释放锁之前加一个判断,验证当前的锁是不是自己加的锁。
具体在加锁的时候把当前线程的id当做value,可生成一个 UUID 标识当前线程,在删除之前验证key对应的value是不是自己线程的id。
还可以使用 lua 脚本做验证标识和解锁操作。
3、超时解锁导致并发
如果线程 A 成功获取锁并设置过期时间 30 秒,但线程 A 执行时间超过了 30 秒,锁过期自动释放,此时线程 B 获取到了锁,线程 A 和线程 B 并发执行。
A、B 两个线程发生并发显然是不被允许的,一般有两种方式解决该问题:
- 将过期时间设置足够长,确保代码逻辑在锁释放之前能够执行完成。
- 为获取锁的线程增加守护线程,为将要过期但未释放的锁增加有效时间。
4、不可重入
当线程在持有锁的情况下再次请求加锁,如果一个锁支持一个线程多次加锁,那么这个锁就是可重入的。如果一个不可重入锁被再次加锁,由于该锁已经被持有,再次加锁会失败。Redis 可通过对锁进行重入计数,加锁时加 1,解锁时减 1,当计数归 0 时释放锁。
5、无法等待锁释放
上述命令执行都是立即返回的,如果客户端可以等待锁释放就无法使用。
- 可以通过客户端轮询的方式解决该问题,当未获取到锁时,等待一段时间重新获取锁,直到成功获取锁或等待超时。这种方式比较消耗服务器资源,当并发量比较大时,会影响服务器的效率。
- 另一种方式是使用 Redis 的发布订阅功能,当获取锁失败时,订阅锁释放消息,获取锁成功后释放时,发送锁释放消息。
具体实现参考:https://xiaomi-info.github.io/2019/12/17/Redis-distributed-lock/
57. 了解RedLock吗?
Redlock是一种算法,Redlock也就是 Redis Distributed Lock,可用实现多节点Redis的分布式锁。
RedLock官方推荐,Redisson完成了对Redlock算法封装。
此种方式具有以下特性:
- 互斥访问:即永远只有一个 client 能拿到锁
- 避免死锁:最终 client 都可能拿到锁,不会出现死锁的情况,即使锁定资源的服务崩溃或者分区,仍然能释放锁。
- 容错性:只要大部分 Redis 节点存活(一半以上),就可以正常提供服务
58. RedLock的原理
假设有5个完全独立的Redis主服务器
-
获取当前时间戳
-
client尝试按照顺序使用相同的key,value获取所有Redis服务的锁,在获取锁的过程中的获取时间比锁过期时间短很多,这是为了不要过长时间等待已经关闭的Redis服务。并且试着获取下一个Redis实例。
比如:TTL为5s,设置获取锁最多用1s,所以如果一秒内无法获取锁,就放弃获取这个锁,从而尝试获取下个锁
-
client通过获取所有能获取的锁后的时间减去第一步的时间,这个时间差要小于TTL时间并且至少有3个Redis实例成功获取锁,才算真正的获取锁成功
-
如果成功获取锁,则锁的真正有效时间是 TTL减去第三步的时间差 的时间;比如:TTL 是5s,获取所有锁用了2s,则真正锁有效时间为3s(其实应该再减去时钟漂移);
-
如果客户端由于某些原因获取锁失败,便会开始解锁所有Redis实例;因为可能已经获取了小于3个锁,必须释放,否则影响其他client获取锁
算法示意图如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sRMWsYf5-1692795149431)(http://blog-img.coolsen.cn/img/image-20210829131128229.png)]
59. Redis如何做内存优化?
-
控制key的数量。当使用Redis存储大量数据时,通常会存在大量键,过多的键同样会消耗大量内存。Redis本质是一个数据结构服务器,它为我们提供多种数据结构,如hash,list,set,zset 等结构。使用Redis时不要进入一个误区,大量使用get/set这样的API,把Redis当成Memcached使用。对于存储相同的数据内容利用Redis的数据结构降低外层键的数量,也可以节省大量内存。
-
缩减键值对象,降低Redis内存使用最直接的方式就是缩减键(key)和值(value)的长度。
- key长度:如在设计键时,在完整描述业务情况下,键值越短越好。
- value长度:值对象缩减比较复杂,常见需求是把业务对象序列化成二进制数组放入Redis。首先应该在业务上精简业务对象,去掉不必要的属性避免存储无效数据。其次在序列化工具选择上,应该选择更高效的序列化工具来降低字节数组大小。
-
编码优化。Redis对外提供了string,list,hash,set,zet等类型,但是Redis内部针对不同类型存在编码的概念,所谓编码就是具体使用哪种底层数据结构来实现。编码不同将直接影响数据的内存占用和读写效率。可参考文章:https://cloud.tencent.com/developer/article/1162213
60. 如果现在有个读超高并发的系统,用Redis来抗住大部分读请求,你会怎么设计?
如果是读高并发的话,先看读并发的数量级是多少,因为Redis单机的读QPS在万级,每秒几万没问题,使用一主多从+哨兵集群的缓存架构来承载每秒10W+的读并发,主从复制,读写分离。
使用哨兵集群主要是提高缓存架构的可用性,解决单点故障问题。主库负责写,多个从库负责读,支持水平扩容,根据读请求的QPS来决定加多少个Redis从实例。如果读并发继续增加的话,只需要增加Redis从实例就行了。
如果需要缓存1T+的数据,选择Redis cluster模式,每个主节点存一部分数据,假设一个master存32G,那只需要n*32G>=1T,n个这样的master节点就可以支持1T+的海量数据的存储了。
Redis单主的瓶颈不在于读写的并发,而在于内存容量,即使是一主多从也是不能解决该问题,因为一主多从架构下,多个slave的数据和master的完全一样。假如master是10G那slave也只能存10G数据。所以数据量受单主的影响。
而这个时候又需要缓存海量数据,那就必须得有多主了,并且多个主保存的数据还不能一样。Redis官方给出的 Redis cluster 模式完美的解决了这个问题。