同态排序算法
参考文献:
-
[Batcher68] Batcher K E. Sorting networks and their applications[C]//Proceedings of the April 30–May 2, 1968, spring joint computer conference. 1968: 307-314.
-
[SV11] Smart, N.P., Vercauteren, F.: Fully homomorphic SIMD operations. IACR Cryp
tology ePrint Archive 2011, 133 (2011)
-
[CKS13] Chatterjee A, Kaushal M, Sengupta I. Accelerating sorting of fully homomorphic encrypted data[C]//Progress in Cryptology–INDOCRYPT 2013: 14th International Conference on Cryptology in India, Mumbai, India, December 7-10, 2013. Proceedings 14. Springer International Publishing, 2013: 262-273.
-
[HS14] Halevi S, Shoup V. Algorithms in HElib[C]//Advances in Cryptology–CRYPTO 2014: 34th Annual Cryptology Conference, Santa Barbara, CA, USA, August 17-21, 2014, Proceedings, Part I 34. Springer Berlin Heidelberg, 2014: 554-571.
-
[EGNS15] Emmadi N, Gauravaram P, Narumanchi H, et al. Updates on sorting of fully homomorphic encrypted data[C]//2015 International Conference on Cloud Computing Research and Innovation (ICCCRI). IEEE, 2015: 19-24.
-
[CDSS15] Çetin G S, Doröz Y, Sunar B, et al. Depth optimized efficient homomorphic sorting[C]//Progress in Cryptology–LATINCRYPT 2015: 4th International Conference on Cryptology and Information Security in Latin America, Guadalajara, Mexico, August 23-26, 2015, Proceedings 4. Springer International Publishing, 2015: 61-80.
-
[Cha&Sen17] Chatterjee A, Sengupta I. Sorting of fully homomorphic encrypted cloud data: Can partitioning be effective?[J]. IEEE Transactions on Services Computing, 2017, 13(3): 545-558.
-
[Cet&Sun17] Çetin G S, Sunar B. Homomorphic rank sort using surrogate polynomials[C]//Progress in Cryptology–LATINCRYPT 2017: 5th International Conference on Cryptology and Information Security in Latin America, Havana, Cuba, September 20–22, 2017, Revised Selected Papers 5. Springer International Publishing, 2019: 311-326.
-
[CSS20] Cetin G S, Savaş E, Sunar B. Homomorphic sorting with better scalability[J]. IEEE Transactions on Parallel and Distributed Systems, 2020, 32(4): 760-771.
-
[IZ21] Iliashenko I, Zucca V. Faster homomorphic comparison operations for BGV and BFV[J]. Proceedings on Privacy Enhancing Technologies, 2021, 2021(3): 246-264.
文章目录
- 最初方案
-
- Swap Circuit
- Lazy Sort
- Sorting Network
- 深度最优化
-
- Comparison Matrix
- Direct Sort
- Greedy Sort
- 减少乘法数量
-
- Polynomial Rank Sort
- Frobenius Maps
最初方案
Swap Circuit
[CKS13] 给出了第一个同态排序方案。它基于明文空间是 G F ( 2 ) GF(2) GF(2) 的 FHE 方案(full 版本,而非 level 版本),构建了 Swap 电路,然后用 Swap 电路搭建冒泡排序、插入排序。令 a , b a,b a,b 是带符号整数,最高位是符号位;令 β \beta β 表示 M S B ( a − b ) MSB(a-b) MSB(a−b),于是 a < b ⟺ β = 1 aa<b⟺β=1。按照从小到大顺序,交换电路为:
t m p : = β ⋅ a + ( 1 − β ) ⋅ b b : = ( 1 − β ) ⋅ a + β ⋅ b a : = t m p \begin{aligned} tmp &:= \beta \cdot a + (1-\beta) \cdot b\\ b &:= (1-\beta) \cdot a + \beta \cdot b\\ a &:= tmp \end{aligned} tmpba:=β⋅a+(1−β)⋅b:=(1−β)⋅a+β⋅b:=tmp
[CKS13] 使用 De Morgan’s law 将 MUX 电路转化为了 XOR 和 AND 门,而非算术加法和算术乘法。正确性是因为加和的两项其中之一是全零比特串,不过直接用 AND 实现算术加法不是更好么?
β ⋅ a + ( 1 − β ) ⋅ b = ( β ⋅ a ) ‾ ⋅ ( β ˉ ⋅ b ) ‾ ‾ \beta \cdot a + (1-\beta) \cdot b = \overline{\overline{(\beta \cdot a)} \cdot \overline{(\bar\beta \cdot b)}} β⋅a+(1−β)⋅b=(β⋅a)⋅(βˉ⋅b)
如图所示:
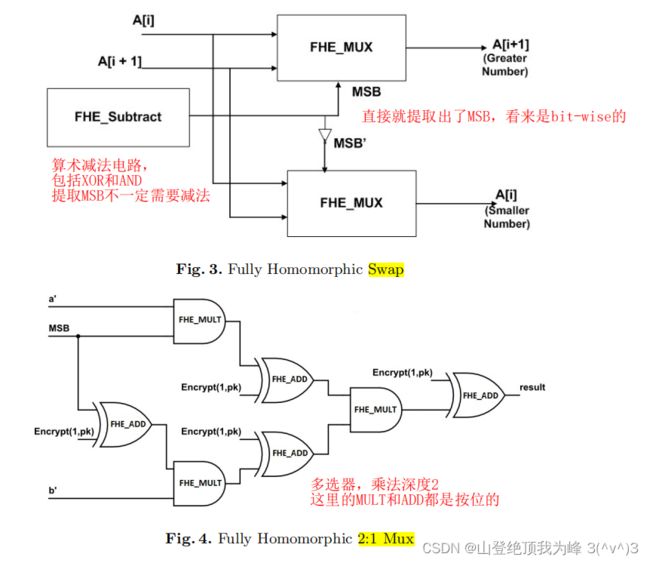
其实,计算机中有另一种交换电路,可以稍微减少的乘法门数量和乘法深度。
a : = a ⊕ b b : = ( β ˉ ⋅ a ) ⊕ b a : = a ⊕ b \begin{aligned} a &:= a \oplus b\\ b &:= (\bar\beta \cdot a) \oplus b\\ a &:= a \oplus b \end{aligned} aba:=a⊕b:=(βˉ⋅a)⊕b:=a⊕b
不过,开销占大头的还是计算 β \beta β 的电路。提取 MSB 不一定需要算术减法电路,也可以直接实现布尔比较电路。对于 l l l 比特整数乘法深度为 O ( log l ) O(\log l) O(logl),比较电路为
L T ( a , b ) : = ∑ i = 1 l ( ( a i < b i ) ∏ j = i + 1 l ( a j = b j ) ) E Q ( a , b ) : = ∏ i = 1 l ( a i = b i ) \begin{aligned} LT(a,b) &:= \sum_{i=1}^l \left((a_i
其中,单比特的比较运算可以被实现为 ( x < y ) : = y ⋅ ( x ⊕ 1 ) (x
Lazy Sort
因为 FHE 开销最大的部件是噪声控制(自举,Recrypt),所以应当删除不必要的操作,累积到一定程度的噪声之后,再执行 Recrypt 操作。另外 [CKS13] 观察到冒泡算法具有一定的容错能力(占比 30 % 30\% 30% 的错误比较结果,最终 60 % 60\% 60% 的元素位于正确的位置上),因此他们激进地删除了更多的 Recrypt 操作,得到近似有序的同态排序结果。
[CKS13] 提出将排序分为两阶段,
- 第一阶段,使用移除了适量 Recrypt 的冒泡排序,获得近似有序的排序结果
- 第二阶段,使用完全 Recrypt 的插入排序,[CKS13] 想当然地认为插排在近似有序数组上更加高效
但是!由于 FHE 最基本的 IND-CPA 安全性,我们无法区分是否发生了 Swap,因此插入排序的每一轮迭代都必须完全执行,并不会提前终止。确切的说:基于 Swap 的排序算法在同态运算下总是以最坏复杂度运行的 [EGNS15]。这包括:冒泡、插排、希尔、选择排序。
[Cha&Sen17] 讨论了基于 Partition 的排序算法,可以绕过上述限制。例如,快速排序的复杂度是依赖于分区质量的,每次递归过程的分区大小越均匀,那么平均复杂度就越接近 O ( n log n ) O(n \log n) O(nlogn),并没有根据是否发生 Swap 来决定提前终止。但是,依然受到 IND-CPA 安全性的限制,枢轴的位置我们无法确定,因此不得不对 index 也加密,导致基于 Partition 的排序算法的效率比基于 Swap 的排序算法效率更低。
同时,[Cha&Sen17] 利用窗口技术,纠正了 [CKS13] 的错误:首先执行近似的冒泡排序,然后在小窗口(例如 W = 2 W=2 W=2)中执行完全的插入排序。由于减少了自举数量,速度提升了大约一倍。
Sorting Network
[Batcher68] 提出的 Sorting Network 是一种数据独立的高并行度排序电路,其复杂度固定为 O ( n log 2 n ) O(n \log^2 n) O(nlog2n),迭代层数 O ( log 2 n ) O(\log^2 n) O(log2n),并行度 O ( n ) O(n) O(n)。[Batcher68] 提出了两种算法,我们默认长度 n n n 是二的幂次。
-
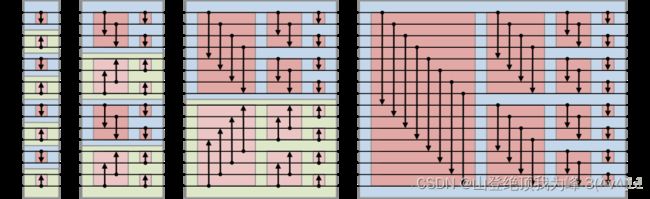
双调排序(Bitonic Sort):
-
双调序列,一个序列可以分为两个连续部分(首尾循环相接),一部分单调降(不增),另一部分单调升(不降)。
-
Batcher定理,一个长度 2 n 2n 2n 的双调序列 a 1 , ⋯ , a 2 n a_1,\cdots,a_{2n} a1,⋯,a2n,可以分为 MIN 序列 min ( a 1 , a n + 1 ) , ⋯ , min ( a n , a 2 n ) \min(a_1,a_{n+1}),\cdots,\min(a_n,a_{2n}) min(a1,an+1),⋯,min(an,a2n) 和 MAX 序列 max ( a 1 , a n + 1 ) , ⋯ , max ( a n , a 2 n ) \max(a_1,a_{n+1}),\cdots,\max(a_n,a_{2n}) max(a1,an+1),⋯,max(an,a2n),那么 MIN 序列和 MAX 序列都是双调序列,并且 MIN 序列中的最大值小于 MAX 序列中的最小值。
-
Sort 过程:输入双调序列,根据 Batcher 定理划分 MIN 序列和 MAX 序列,然后对它们分别递归执行 Sort 过程,最终将会得到一个有序数组(升序、降序)。
-
Merge 过程:输入任意序列,相邻元素两两合并,形成升调、降调交替的若干区间(相邻的区间组成了一个双调序列)。对这些双调序列调用 Sort 过程可以得到有序数组,我们仍构造出升调、降调交替的若干区间(区间大小翻倍)。迭代执行直到整个数组仅包含一个双调序列,再调用 Sort 过程得到有序数组。
-
-
奇偶归并排序(Odd-Even Merge Sort):
-
Sort 过程:输入任意序列 a 0 , ⋯ , a 2 n − 1 a_0,\cdots,a_{2n-1} a0,⋯,a2n−1,对于前半部分 a 0 , ⋯ , a n − 1 a_0,\cdots,a_{n-1} a0,⋯,an−1 和后半部分 a n , ⋯ , a 2 n − 1 a_n,\cdots,a_{2n-1} an,⋯,a2n−1 分别递归执行 Sort 过程,这得到了两个有序数组,最后调用 Merge 过程得到一个有序数组。
-
Merge 过程:输入两个有序数组 a 0 , ⋯ , a n − 1 a_0,\cdots,a_{n-1} a0,⋯,an−1 和 b 0 , ⋯ , b n − 1 b_0,\cdots,b_{n-1} b0,⋯,bn−1,如果 n = 1 n=1 n=1 则比较 a 0 < b 0 a_0 < b_0 a0<b0 获得一个长度 2 2 2 的有序数组;否则重新分组为 EVEN 序列 a 0 , a 2 , ⋯ , a n − 2 , b 0 , b 2 , ⋯ , b n − 2 a_0,a_2,\cdots,a_{n-2},b_0,b_2,\cdots,b_{n-2} a0,a2,⋯,an−2,b0,b2,⋯,bn−2 和 ODD 序列 a 1 , a 3 , ⋯ , a n − 1 , b 1 , b 3 , ⋯ , b n − 1 a_1,a_3,\cdots,a_{n-1},b_1,b_3,\cdots,b_{n-1} a1,a3,⋯,an−1,b1,b3,⋯,bn−1 ,两者的前半段和后半段也都是有序数组。对它们分别递归执行 Merge 过程,获得两个有序数组 e 0 , ⋯ , e n − 1 e_0,\cdots,e_{n-1} e0,⋯,en−1 和 o 0 , ⋯ , o n − 1 o_0,\cdots,o_{n-1} o0,⋯,on−1,然后比较 e i + 1 , o i e_{i+1},o_i ei+1,oi 并交换使得 e i + 1 > o i e_{i+1}>o_i ei+1>oi,那么序列 e 0 , o 0 , e 1 , o 1 , ⋯ , e n − 1 , o n − 1 e_0,o_0,e_1,o_1,\cdots,e_{n-1},o_{n-1} e0,o0,e1,o1,⋯,en−1,on−1 就是一个有序数组。
-
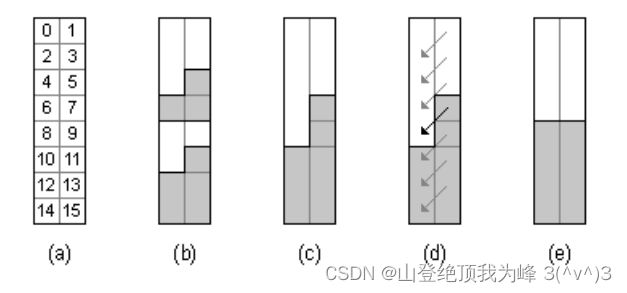
[EGNS15] 观察到基于 Swap 的同态排序算法总是以最坏复杂度运行,或者说它的效率与输入数据无关。[EGNS15] 简单地用 FHE Swap 电路搭建出了 Bitonic Sort 和 Odd-Even Merge Sort 同态排序网络,计算复杂度固定为 O ( n log 2 n ) O(n \log^2 n) O(nlog2n)。
深度最优化
Comparison Matrix
[CDSS] 使用了 LHE 而非 FHE 来实现同态排序,只要支持的 Level 级别够高,就可以完全忽略开销极高的 Recrypt 运算。由于 LHE 是以电路的形式执行的,排序算法需要先通过算术化消除条件分支,然后再通过循环展开得到无环的排序电路。但是 [EGNS15] 使用的 Sorting Network 迭代了 O ( log 2 n ) O(\log^2 n) O(log2n) 层,每一层的 Swap 输入都依赖于上一层的 Swap 结果,所以同态乘法深度较高,直接用 LHE 实例化将导致极高的参数规模。
为了降低乘法深度,最直观的思路就是只进行深度为 O ( 1 ) O(1) O(1) 的比较。输入密文 X 0 , ⋯ , X N − 1 X_0,\cdots,X_{N-1} X0,⋯,XN−1,预计算 comparison matrix,
M : = [ m 0 , 0 m 0 , 1 ⋯ m 0 , N − 1 m 1 , 0 m 1 , 1 ⋯ m 1 , N − 1 ⋮ ⋱ m N − 1 , 0 m N − 1 , 1 ⋯ m N − 1 , N − 1 ] m i j : = L T ( X i , X j ) = { E n c ( 1 ) , x i < x j E n c ( 0 ) , o t h e r w i s e M := \begin{bmatrix} m_{0,0} & m_{0,1} & \cdots & m_{0,N-1}\\ m_{1,0} & m_{1,1} & \cdots & m_{1,N-1}\\ \vdots && \ddots\\ m_{N-1,0} & m_{N-1,1} & \cdots & m_{N-1,N-1}\\ \end{bmatrix}\\ m_{ij} := LT(X_i, X_j) = \left\{\begin{aligned} Enc(1), && x_i < x_j\\ Enc(0), && otherwise\\ \end{aligned}\right. M:= m0,0m1,0⋮mN−1,0m0,1m1,1mN−1,1⋯⋯⋱⋯m0,N−1m1,N−1mN−1,N−1 mij:=LT(Xi,Xj)={Enc(1),Enc(0),xi<xjotherwise
这张表格在后续的 Sort 过程中可以被复用,消除后续的比较运算,从而降低乘法深度。对于 l l l 比特的数据,布尔电路 L T ( ⋅ ) LT(\cdot) LT(⋅) 的乘法深度为 O ( log l ) O(\log l) O(logl)
Direct Sort
矩阵 M M M 第 i i i 行的汉明重量,计数了比 X i X_i Xi 大的元素数量;矩阵 M M M 第 j j j 列的汉明重量,计数了比 X j X_j Xj 小的元素数量。于是,矩阵 M M M 第 j j j 列的汉明重量,恰好是从小到大排序时 X j X_j Xj 的正确次序!
我们利用 O ( log N ) O(\log N) O(logN) 比特的 Wallace Tree 全加器(连续 N N N 个数的加和,每三个数一组,计算出本位(XOR)和进位(AND),迭代 O ( log 3 / 2 N ) O(\log_{3/2}N) O(log3/2N) 轮)计算汉明重量
σ j = ∑ i ∈ [ N ] m i j \sigma_j = \sum_{i \in [N]} m_{ij} σj=i∈[N]∑mij
然后利用 O ( log N ) O(\log N) O(logN) 比特的 Equality Test 电路,将密文 X i X_i Xi 放置到正确的位置上
Y j : = ∑ i ∈ [ N ] ( σ i = j ) ⋅ X i Y_j := \sum_{i \in [N]} (\sigma_i=j)\cdot X_i Yj:=i∈[N]∑(σi=j)⋅Xi
不考虑预计算 M M M,Direct Sort 的乘法深度为 O ( log 3 / 2 N + log log N ) O(\log_{3/2}N + \log\log N) O(log3/2N+loglogN),乘法数量为 O ( N 2 log N + N 2 log log N ) O(N^2 \log N+N^2\log\log N) O(N2logN+N2loglogN)
Greedy Sort
算术加法电路的乘法深度总是较高的,另一种确定 X i X_i Xi 位置的思路是: X i X_i Xi 的次序是 t t t,那么恰好有 t t t 个数比它小,另外的 N − t − 1 N-t-1 N−t−1 个数都比它大(注意等号细节)
我们把排序结果写作:
Y t : = ∑ i ∈ [ N ] θ t , i X i Y_t := \sum_{i \in [N]} \theta_{t,i}X_i Yt:=i∈[N]∑θt,iXi
其中的 one-hot 系数通过穷举得到,它含有 ( N − 1 t ) {N-1 \choose t} (tN−1) 个单项,
θ t , i : = ∑ k 1 = 0 , k 1 ≠ i N − t m k 1 , i ∑ k 2 = k 1 + 1 , k 2 ≠ i N − t + 1 m k 2 , i ⋯ ∑ k t = k t − 1 + 1 , k t ≠ i N − 1 m k t , i ∏ j = 0 , j ≠ i , j ≠ k i , ⋯ , k t N − 1 m i j \theta_{t,i} := \sum_{k_1=0,k_1 \neq i}^{N-t}m_{k_1,i} \sum_{k_2=k_1+1,k_2 \neq i}^{N-t+1}m_{k_2,i} \cdots \sum_{k_t=k_{t-1}+1,k_t \neq i}^{N-1}m_{k_t,i} \prod_{j=0,j\neq i,j\neq k_i,\cdots,k_t}^{N-1} m_{ij} θt,i:=k1=0,k1=i∑N−tmk1,ik2=k1+1,k2=i∑N−t+1mk2,i⋯kt=kt−1+1,kt=i∑N−1mkt,ij=0,j=i,j=ki,⋯,kt∏N−1mij
不考虑预计算 M M M,Greedy Sort 的乘法深度仅为 O ( log N ) O(\log N) O(logN),但是乘法数量为 O ( N 2 ⋅ 2 N ) O(N^2\cdot 2^N) O(N2⋅2N)
减少乘法数量
Polynomial Rank Sort
虽然 Direct Sort 和 Greedy Sort 的乘法深度达到了最优,但是其乘法数量依然较多,尤其是 Greedy Sort 需要指数级的同态乘法。[Cet&Sun17] 把 Direct Sort 中的汉明重量的计算,从布尔算术加法电路,迁移到了多项式的幂指数上,于是待排序数据被可以自然地放置在正确位置。
输入数据 { a 0 , ⋯ , a N − 1 } \{a_0,\cdots,a_{N-1}\} {a0,⋯,aN−1},假设 a i a_i ai 的次序为 r i r_i ri,我们定义 rank polynomial ρ i ( x ) : = x r i \rho_i(x):=x^{r_i} ρi(x):=xri,那么
b ( x ) = ∑ i = 1 N − 1 a i ρ i ( x ) = ∑ i = 1 N − 1 a i x r i = ∑ i = 1 N − 1 b i x i \begin{aligned} b(x) &= \sum_{i=1}^{N-1} a_i\rho_i(x)\\ &= \sum_{i=1}^{N-1}a_i x^{r_i} = \sum_{i=1}^{N-1}b_i x^{i} \end{aligned} b(x)=i=1∑N−1aiρi(x)=i=1∑N−1aixri=i=1∑N−1bixi
那么系数向量 b 0 ≤ b 1 ≤ ⋯ ≤ b N − 1 b_0 \le b_1 \le \cdots \le b_{N-1} b0≤b1≤⋯≤bN−1 就直接是有序的 { a 0 , ⋯ , a N − 1 } \{a_0,\cdots,a_{N-1}\} {a0,⋯,aN−1} 啦!这么做对比于 Direct Sort 的好处是,不必再利用 Equality Test 去确定密文放置的位置,而是天然有序。
为了计算 ρ i ( x ) \rho_i(x) ρi(x),我们仿照 Direct Sort 的计算方式,
-
首先预计算 { a 0 , ⋯ , a N − 1 } \{a_0,\cdots,a_{N-1}\} {a0,⋯,aN−1} 两两比较的单项式(对应于比较矩阵),每一对 a i , a j , i < j a_i,a_j,i
ai,aj,i<j 计算
ρ i j ( x ) : = 1 , ρ j i ( x ) : = x ⟺ a i < a j ρ i j ( x ) : = x , ρ j i ( x ) : = 1 ⟺ a i ≥ a j \rho_{ij}(x):=1, \rho_{ji}(x):=x \iff a_i < a_j\\ \rho_{ij}(x):=x, \rho_{ji}(x):=1 \iff a_i \ge a_j\\ ρij(x):=1,ρji(x):=x⟺ai<ajρij(x):=x,ρji(x):=1⟺ai≥aj -
然后计算乘积(对应于汉明重量),
ρ i ( x ) : = ∏ i ≠ j ρ i j ( x ) = x ∑ i ≠ j ( a i ≥ a j ) = x r i \rho_i(x) := \prod_{i \neq j} \rho_{ij}(x) = x^{\sum_{i \neq j}(a_i\ge a_j)} = x^{r_i} ρi(x):=i=j∏ρij(x)=x∑i=j(ai≥aj)=xri -
最终计算出
b ( x ) = ∑ i = 1 N − 1 a i ρ i ( x ) b(x) = \sum_{i=1}^{N-1} a_i\rho_i(x) b(x)=i=1∑N−1aiρi(x)
对于密文 { A 0 , ⋯ , A N − 1 } \{A_0,\cdots,A_{N-1}\} {A0,⋯,AN−1} 下的同态计算,
P i j : = ( E n c ( 1 ) − L T ( A i , A j ) ) + L T ( A i , A j ) ⋅ E n c ( x ) ∈ { E n c ( 1 ) , E n c ( x ) } B : = ∑ i ∈ [ N ] ( A i ⋅ ∏ j ≠ i P i j ) = E n c ( ∑ i ∈ [ N ] a i x r i ) \begin{aligned} P_{ij} &:= \left(Enc(1)-LT(A_i,A_j)\right) + LT(A_i,A_j) \cdot Enc(x) \in \{Enc(1),Enc(x)\}\\ B &:= \sum_{i \in [N]} \left( A_i \cdot \prod_{j \neq i} P_{ij} \right) = Enc(\sum_{i \in [N]} a_i x^{r_i}) \end{aligned} PijB:=(Enc(1)−LT(Ai,Aj))+LT(Ai,Aj)⋅Enc(x)∈{Enc(1),Enc(x)}:=i∈[N]∑ Ai⋅j=i∏Pij =Enc(i∈[N]∑aixri)
然而,[Cet&Sun17] 的计算结果是单个多项式,其排序结果存储在了它的系数上。下面我们考虑如何提取出 N N N 个有序密文,这是我自己想的,论文中没写。
Frobenius Maps
[SV11] 提出了 RLWE-FHE 的 SIMD 技术。给定素数 p p p,分园环 G F ( p ) [ x ] / ( ϕ m ( x ) ) GF(p)[x]/(\phi_m(x)) GF(p)[x]/(ϕm(x)),次数 m m m 与 p p p 互素,令 d d d 是满足 m ∣ p d − 1 m\mid p^d-1 m∣pd−1 的最小正整数,那么分园多项式可以在 G F ( p ) GF(p) GF(p) 上分解为 l = ϕ ( m ) / d l=\phi(m)/d l=ϕ(m)/d 个不同的 d d d 次不可约多项式,
ϕ m ( x ) = ∏ i = 1 l F i ( x ) ( m o d p ) \phi_m(x) = \prod_{i=1}^{l} F_i(x) \pmod p ϕm(x)=i=1∏lFi(x)(modp)
因为域上的多项式环是主理想环,其素理想都是极大理想。根据 CRT of Ring,理想 ( F i ( x ) ) (F_i(x)) (Fi(x)) 两两互素,且 ( ϕ m ( x ) ) (\phi_m(x)) (ϕm(x)) 是它们的交理想,那么有
G F ( p ) [ x ] / ( ϕ m ( x ) ) ≅ G F ( p ) [ x ] / ( F 1 ( x ) ) × ⋯ G F ( p ) [ x ] / ( F l ( x ) ) ≅ ( G F ( p d ) ) l GF(p)[x]/(\phi_m(x)) \cong GF(p)[x]/(F_1(x)) \times \cdots GF(p)[x]/(F_l(x)) \cong (GF(p^d))^l GF(p)[x]/(ϕm(x))≅GF(p)[x]/(F1(x))×⋯GF(p)[x]/(Fl(x))≅(GF(pd))l
这包含了 l l l 个槽,空间都同构于有限域 G F ( p d ) GF(p^d) GF(pd)。对于不同的槽,它们的唯一区别就是域扩张 G F ( p d ) / G F ( p ) GF(p^d)/GF(p) GF(pd)/GF(p) 所使用的代数元不同。根据 d d d 次本原单位根之间的关系,存在 g ∈ Z m ∗ g \in \mathbb Z_m^* g∈Zm∗ 满足 o r d ( g ) = l ord(g)=l ord(g)=l,其索引的环自同构:
κ g : x ↦ x g ( m o d ϕ m ( x ) ) \kappa_g : x \mapsto x^g \pmod{\phi_m(x)} κg:x↦xg(modϕm(x))
它可以实现槽变换, κ g ( a ( x ) ) ( m o d F i ( x ) ) = a ( x ) ( m o d F j ( x ) ) \kappa_g(a(x)) \pmod{F_i(x)} = a(x) \pmod{F_j(x)} κg(a(x))(modFi(x))=a(x)(modFj(x))
令 G F ( q ) GF(q) GF(q) 是任意有限域,域扩张 G F ( q N ) / G F ( q ) GF(q^N)/GF(q) GF(qN)/GF(q) 上的 Frobenius map 定义为
σ : a ↦ a q \sigma: a \mapsto a^q σ:a↦aq
可以证明:
- σ \sigma σ 是 G F ( q N ) GF(q^N) GF(qN) 上的双射,并且 σ N = i d \sigma^N=id σN=id
- σ i \sigma^i σi 是一个 G F ( q ) GF(q) GF(q) - 域自同构
- 令 x x x 是 G F ( q N ) / G F ( q ) GF(q^N)/GF(q) GF(qN)/GF(q) 的扩张元,那么 σ i ( x ) = x q i \sigma^i(x) = x^{q^i} σi(x)=xqi 也都是扩张元
- 域扩张 G F ( q N ) / G F ( q ) GF(q^N)/GF(q) GF(qN)/GF(q) 的迹: T r ( a ) : = ∑ i = 0 N − 1 σ i ( a ) Tr(a):=\sum_{i=0}^{N-1} \sigma^i(a) Tr(a):=∑i=0N−1σi(a)
- 域扩张 G F ( q N ) / G F ( q ) GF(q^N)/GF(q) GF(qN)/GF(q) 的范数: N o r m ( a ) : = ∏ i = 0 N − 1 σ i ( a ) Norm(a):=\prod_{i=0}^{N-1} \sigma^i(a) Norm(a):=∏i=0N−1σi(a)
[HS14] 指出,同态 Frobenius map 的乘法深度为零(文中没有给出公式)。我推导了一下,假设 RLWE 密文是
c t = ( a ( x ) , a ( x ) s ( x ) + Δ m ( x ) + e ( x ) ) ∈ ( G F ( p d ) ) 2 ct = (a(x), a(x)s(x)+\Delta m(x)+e(x)) \in \left(GF(p^d)\right)^2 ct=(a(x),a(x)s(x)+Δm(x)+e(x))∈(GF(pd))2
有限扩域 G F ( p d ) GF(p^d) GF(pd) 上的 G F ( p ) GF(p) GF(p) - 域自同构 σ ( x ) : = x p \sigma(x):=x^p σ(x):=xp,因为 a , s , m , e ∈ G F ( p d ) a,s,m,e \in GF(p^d) a,s,m,e∈GF(pd) 并且 Δ ∈ G F ( p ) \Delta \in GF(p) Δ∈GF(p),
σ ( c t ) = ( σ ( a ) , σ ( a ) σ ( s ) + Δ σ ( m ) + σ ( e ) ) ∈ ( G F ( p d ) ) 2 \sigma(ct) = (\sigma(a), \sigma(a)\sigma(s)+\Delta \sigma(m)+\sigma(e)) \in \left(GF(p^d)\right)^2 σ(ct)=(σ(a),σ(a)σ(s)+Δσ(m)+σ(e))∈(GF(pd))2
所以 σ ( c t ) \sigma(ct) σ(ct) 是在私钥 σ ( s ) \sigma(s) σ(s) 下的明文 σ ( m ) \sigma(m) σ(m) 的密文,我们只需再执行 σ ( s ) → s \sigma(s) \to s σ(s)→s 的秘钥切换,就完成了同态 Frobenius map,它的代价与槽变换是相同的。
由于所有的线性映射 L : G F ( p d ) → G F ( p ) L: GF(p^d) \to GF(p) L:GF(pd)→GF(p),恰好就是所有的迹 L β ( a ) : = T r ( β a ) , β ∈ G F ( p d ) L_\beta(a):=Tr(\beta a),\beta \in GF(p^d) Lβ(a):=Tr(βa),β∈GF(pd)。所以,对于 [Cet&Sun17] 的排序结果 B = E n c ( ∑ i a i x r i ) B=Enc(\sum_i a_ix^{r_i}) B=Enc(∑iaixri),总是存在 N N N 个元素 β i \beta_i βi 索引了投影映射 T r ( β i B ) = E n c ( a i ) Tr(\beta_i B) = Enc(a_i) Tr(βiB)=Enc(ai),这就提取出了排序结果。
注意,对于 l l l 比特的数据,每个密文 A i A_i Ai 包含了 l l l 个 G F ( p d ) GF(p^d) GF(pd) 上的常数多项式(二进制分解的各个比特)。电路 L T ( ⋅ ) LT(\cdot) LT(⋅) 是布尔比较电路,输出是布尔值对应的 G F ( p d ) GF(p^d) GF(pd) 上单个常数多项式。密文 B = E n c ( ∑ i ∈ [ N ] a i x r i ) B=Enc(\sum_{i \in [N]} a_i x^{r_i}) B=Enc(∑i∈[N]aixri),为了阻止数据溢出,最基本的要求是 d ≥ N d \ge N d≥N。可以使用 SIMD 打包技术,将这些 N × l N \times l N×l 个常数多项式按位加密到 l l l 个密文中,这额外要求 ϕ ( m ) / d ≥ N \phi(m)/d \ge N ϕ(m)/d≥N。

不考虑 P i j P_{ij} Pij 的开销(这主要和 L T ( ⋅ ) LT(\cdot) LT(⋅) 的不同实现有关,[IZ21] 给出了更高效的基于插值的比较算法),Polynomial Rank Sort 的乘法深度为 O ( log N ) O(\log N) O(logN),乘法数量为 O ( N 2 ) O(N^2) O(N2),并行度为 O ( N ) O(N) O(N)。对于 l l l 比特数据,使用 SIMD 技术,先并行计算出 P i : = ∏ j ≠ i P i j P_i := \prod_{j \neq i} P_{ij} Pi:=∏j=iPij,这需要 O ( N ) O(N) O(N) 次同态乘法,乘法深度为 O ( log N ) O(\log N) O(logN);然后并行计算出 B : = ∑ i ∈ [ N ] A i P i B:=\sum_{i \in [N]} A_iP_i B:=∑i∈[N]AiPi,这需要 O ( l ) O(l) O(l) 次同态乘法,乘法深度为 O ( 1 ) O(1) O(1);最后的同态 Frobenius map 不需要同态乘法。共计 O ( N + l ) O(N+l) O(N+l) 次同态乘法,乘法深度 O ( log N ) O(\log N) O(logN)。