jetson nano部署yolov5
文章目录
-
- 系统烧录
-
-
-
- 一、烧录系统
-
- 1.1 下载OS镜像
- 1.2 格式化TF卡
- 1.3 写入镜像
- 1.4 初始化
- 二、Windows远程操控jetson nano
-
- 2.1 准备工作(换源!!!)
- 三、jetson nano 安装Yolov5 (建议用yolov5n.pt去训练)
-
- 3.1 准备工作
- 3.2安装pytorch+torchvison(#我们装的是4.6.1的jetpack)
- 3.3 安装Yolov5
- 四、jetson nano 安装TensorRTX
-
- 4.1 选择合适版本的TensorRTX
- 4.2 修改配置文件
- 4.3 编译运行
- 4.4 python接口
-
-
系统烧录
一、烧录系统
1.1 下载OS镜像
官方地址:Get Started With Jetson Nano Developer Kit | NVIDIA Developer

1.2 格式化TF卡
安装SD memory Card Formatter for Windows
地址:SD Memory Card Formatter for Windows/Mac | SD Association (sdcard.org)
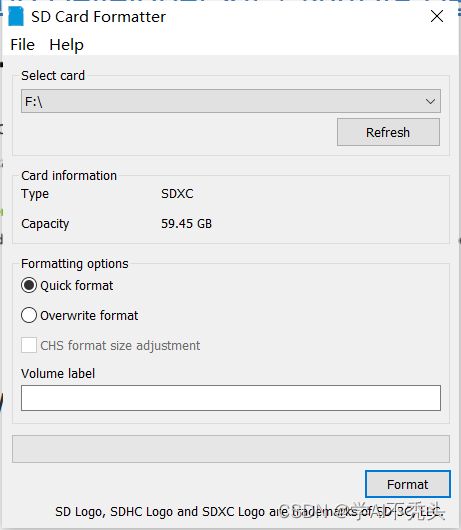
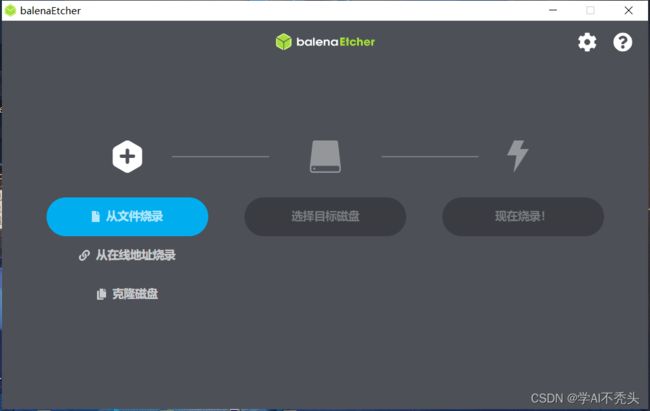
1.3 写入镜像
安装烧录软件Etcher:balenaEtcher - Flash OS images to SD cards & USB drives
选镜像–>选TF卡–>烧录
1.4 初始化
插屏幕,鼠标、键盘设置好用户名密码,密码越简单越好
二、Windows远程操控jetson nano
2.1 准备工作(换源!!!)
#首先备份好原来的source.1ist文件
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
# 修改source.list,更换清华源
sudo vim /etc/apt/sources.list
#按dG删除所有内容,复制下面内容加入
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic main multiverse restricted universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-security main multiverse restricted universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-updates main multiverse restricted universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-backports main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-security main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-updates main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-backports main multiverse restricted universe
# 保存
#更新软件列表
sudo apt-get update
#软连接python3、pip
sudo apt-get install python3-pip
#查看pip3版本
pip3 --version
#移除原来的软连接
sudo rm -rf /usr/bin/pip
#软连接
sudo ln -s /usr/bin/pip3 /usr/bin/pip
# pip换源执行以下语句
mkdir ~/.pip/
cd ~
cd .pip
sudo apt-get install vim
sudo vim pip.conf
#pip.conf写入
[global]
index-url=https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host=mirrors.aliyun.com
#保存pip.conf
#查看当前源:
pip config list
#更新pip
sudo pip install --upgrade pip
安装jtop
#升级pip3
python3 -m pip install --upgrade pip
# 安装jtop
sudo -H pip3 install -U jetson-stats
# 重启
sudo reboot
# 查看jtop,效果如下图
jtop
jetson 安装VNC
# 更新软件源
sudo apt update
sudo apt install vino
# Enable VNC 服务
sudo ln -s ../vino-server.service /usr/lib/systemd/user/graphical-session.target.wants
#配置 VNC server
gsettings set org.gnome.Vino prompt-enabled false
gsettings set org.gnome.Vino require-encryption false
#编辑 org.gnome.vino.gschema.xm]文件sudo vi /usr/share/glib-2,0/schemas/org.gnome.vino,gschema.xml
#文件最后,之前添加以下内容
sudo vim /usr/share/glib-2.0/schemas/org.gnome.Vino.gschema.xml
#
<key name='enabled' type='b'>
<summary>Enable remote access to the desktop</summary>
<description>
If true, allows remote access to the desktop via the RFB
protocol. Users on remote machines may then connect to the
desktop using a VNC viewer.
</description>
<default>false</default>
</key>
#设置为 Gnome 编译模式
sudo glib-compile-schemas /usr/share/glib-2.0/schemas
#设置 VNC '123456'自己的密码
gsettings set org.gnome.Vino authentication-methods "['vnc']"
gsettings set org.gnome.Vino vnc-password $(echo -n '123123'|base64)
#重启
sudo reboot
# windows测试VNC是否能连接
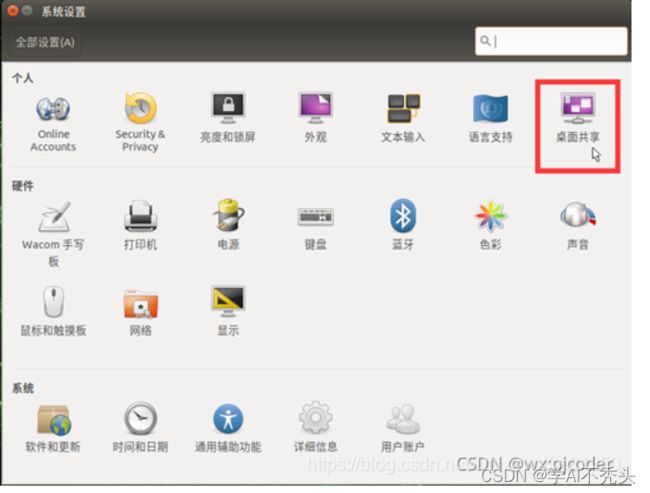
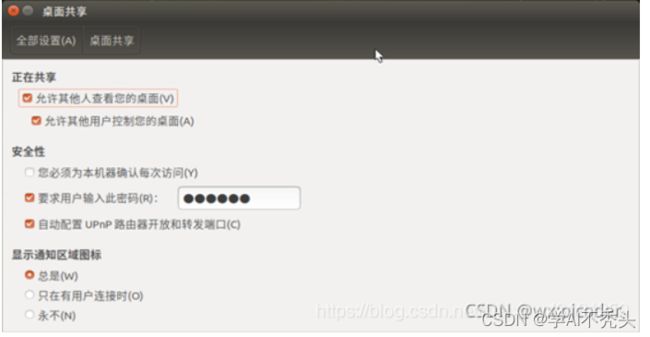
三、jetson nano 安装Yolov5 (建议用yolov5n.pt去训练)
轮子大全:Archived: Python Extension Packages for Windows - Christoph Gohlke (uci.edu)
3.1 准备工作
jtop中power model 选择maxn
jtop中打开jetson_clock
修改交换内存 swap(4G后面编译或运行不够)
#终端里输入
sudo vim /etc/systemd/nvzramconfig.sh
# 修改
mem$((("s{totalmem]"/2/"SNRDEVICES]")*1024))
#为
为mem=$((("Sftotalmem]”*2/"SNRDEVICES]")* 1024))
#重启
sudo reboot
#再进入输入jtop可以查看是否变化
3.2安装pytorch+torchvison(#我们装的是4.6.1的jetpack)
如果需要下载其他版本,请进入官网: https:/forums.developer.nvidia.com/t/pytorch-for-jetson-version-1-10-now-available/72048
torchvion:https://github.com/pytorch/vision
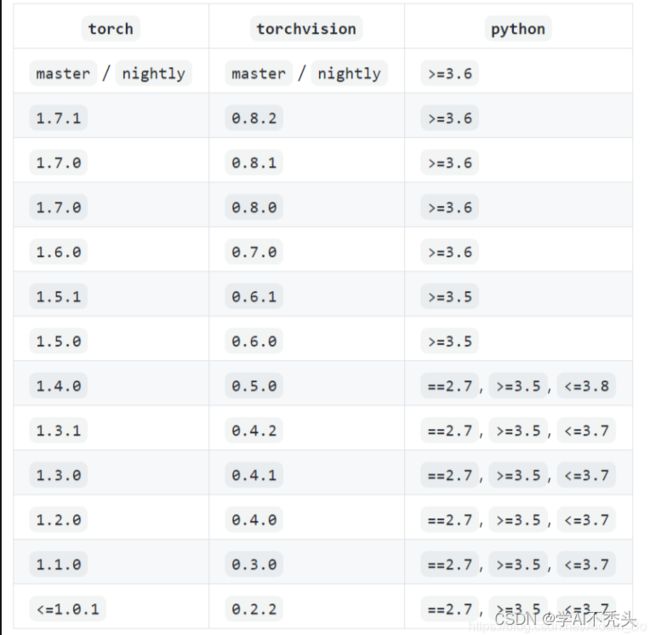
#本次使用的是: PyTorch v1.7-torchvision v0.8.1,离线安装包文件位置: jetson软件安装/3.pytorch_torchvision
# 进入离线安装包目录
# 安装PyTorch
#安装依赖库
sudo apt-get install python3-pip libopenblas-base libopenmpi-dev
pip3 install Cython
#cd到对应离线安装包目录下
pip3 install numpy torch-1.7.0-cp36-cp36m-linuxaarch64.whl
# 安装torchvision
sudo apt-get install libjpeg-dev zliblg-dev libpython3-dev libavcodec-dev libavformat-dev libswscale-dev
sudo apt-get install libffi-dev
sudo pip3 install pyzmq==17.0.0
sudo apt-get install python3-dev python3-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
pip3 install pillow==8.4.0
git clone -b v0.8.1-rc1 https://github.com/pytorch/vision.git
# 解压vision-0.8.1.zip
unzip vision-0.8.1.zip
# 重命名
mv vision-0.8.1 torchvision
# 进入目录
cd torchvision
# 安装
export BUILD_VERSION=0.8.1 # where 0.x.0 is the torchvision version
#export OPENBLAS_CORETYPE=ARMV8
#增加系统变量方法,可以进行全局修改。
#将“export OPENBLAS_CORETYPE=ARMV8”加入到“~/.bashrc”中
sudo OPENBLAS_CORETYPE=ARMV8 python3 setup.py install
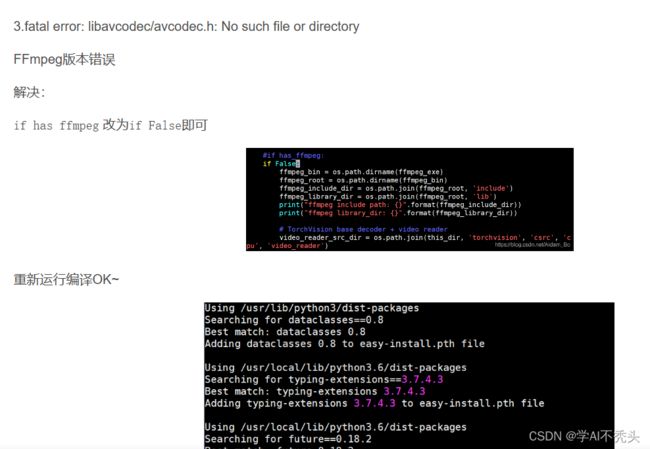
#3.fatal error: libavcodec/avcodec.h: No such file or directory
#FFmpeg版本错误
#解决:
#if has ffmpeg 改为if False即可
#验证(不要再torchvison目录下去验证,cd出去)
>>>import torch
>>> print(torch.__version__)
>>> print('CUDA available: ' + str(torch.cuda.is_available()))
>>> print('cuDNN version:' + str(torch.backends.cudnn.version()))
>>>a=torch.cuda.FloatTensor(2).zero_()
>>> print('Tensor a =' + str(a))
>>>b= torch.randn(2).cuda()
>>>print('Tensor b =' + str(b))
>>>c=a+b
>>>print('Tensor c=' + str(c))
>>>import torchvision
3.3 安装Yolov5
pip安装的opencv,模型量化时会报错。这里推荐编译安装opencv
参考我之前发的文章:https://blog.csdn.net/a1691125058/article/details/131217295?spm=1001.2014.3001.5501
# 克隆地址(v7版本的)
git clone -b v7.0 https://github.com/ultralytics/yolov5.git#如果下不了就把本地的zip拖过去
#进入目录
cd yolov5
#安装依赖
pip3 install -r requirements.txt
#可能matplotlib会安装失败(直接安本地轮子)
pip3 install matplotlib-3.3.4-cp36-cp36m-linux_aarch64.whl
#再检查一遍
pip3 install -r requirements.txt
#uilding wheels for collected packages: opencv-python, psutil
#Building wheel for opencv-python (pyproject.toml) ...
#大概率会卡在matplotlib的安装上,直接安装离线编译好的轮子
#,接着又继续pip3 install -r requirements.txt,后面又会卡在opencv的编译
#由于OpenCV体积较大,编译时间较长,导致不显示安装进度的化,前端出现假死现象,静静等待即可。!!!
#这个过程巨久。。。
#显示编译安装进程 (建议直接先用这个装吧。有个盼头)
pip3 install opencv-python-headless --verbose
pip3 install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple --verbose
pip3 install opencv-contrib-python -i https://pypi.tuna.tsinghua.edu.cn/simple --verbose
#将训练好的模型放到yolov5目录下
#用detect.py 测试一张图片试试看能不能用
# 以下指令可以用来测试
python3 detect.py --source data/images/bus.jpg--weights yolov5n.pt--img 640
#图片测试
python3 detect.py --source video.mp4--weights yolov5n.pt --img 640 #视频测试,需要自己准备视频
python3 detect.py --source 1 --weights yolov5n.pt--img 640 #摄像头测试
#可能报错
lmportError: The_imagingft C module is not installed
# 重新安装pillow
pip3 install pillow==8.4.0
四、jetson nano 安装TensorRTX
参考资料: https://github.com/wang-xinyu/tensorrtx/tree/master/yolov5
4.1 选择合适版本的TensorRTX
对照YOLOv5版本,选择合适版本的tensorRTX,具体可参考 https://github.com/wang-xinyu/tensorrtx/tree/master/yolov5
#For yolov5 v7.0, download .pt from yolov5 release v7.0,
git clone -b v7.0 https://github.com/ultralytics/yolov5.git
# and
git clone -b yolov5-v7.0 https://github.com/wang-xinyu/tensorrtx.git
4.2 修改配置文件
#在yololayer.h修改检测类别数量、输入画面大小
static constexpr int CLASS_NUM = 80;#改成自己的类别数量
static constexpr int INPUT_H= 640;#要被32整除
static constexpr int INPUT_W = 640
#在yolov5.cpp 修改数据类型、GPU、NMS、BBox confidence、Batch size
#define USE FP16 //set USE INT8 or USE FP16 or USE FP32,需要注票jetson nano GPU 不支持int8 型运算,所以这里不需要改动
#define DEVICE 0 // GPU id
#define NMS_THRESH 0.4
#define CONF_THRESH 05
#define BATCH_SIZE
#define MAX_IMAGE_INPUT_SIZE_THRESH 3000 * 3000 // ensure it exceed the maximum size in the input images!
4.3 编译运行
生成wts文件
#将tensorRT yolov5下的gen_wts.py复制到yolov5项目目录下
#进入 yolov5目录
#运行生成
python3 gen_wts.py -w{.pt模型文件名称} -o{.wts 输出文件名称}
#例如
python3 gen_wts.py -w yolov5n.pt -o yolov5n.wts
#会在当前目录生成yolov5n.wts
编译
#进入tensorrtx的yolov5目录下
#确保yololayer.h的类别已经修改好了
mkdir build
cd build
#将生成的XXXX.wts文件复制到build目录下
cp ....
#
cmake ..
make
生成engine文件
#编译完会生成 一个yolov5 可执行文件
#生成engine序列化文件 输入名称 空格n指定模型类别 不能少
#大概十分钟的等待...
sudo ./yolov5_det -s yolov5n.wts yolov5n.engine n
#测试 测试图片的路径
sudo ./yolov5_det -d yolov5n.engine ../images
4.4 python接口
pycuda安装
#安装pycuda
export CPATH=$CPATH:/usr/local/cuda-10.2/targets/aarch64-linux/include
export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/cuda-0.2/targets/aarch64-linux/lib
pip3 install pycuda --user
#或者
sudo pip3 install --global-option=build_ext --global-option="-|/usr/local/cuda/include" --global-option="-L/usr/local/cuda/lib64" pycuda
pip3 install pycuda -i https://pypi.tuna.tsinghua.edu.cn/simple --verbose
#基于tensorrtx的yolov5目录下的yolo_trt.py参考做调整
python3 yolo_trt.py
python接口需要自己修改一下代码,根据官方提供的文件自行修改就行了。