【HTML】HTML面试知识梳理
目录
- DOCTYPE(文章类型)
- head标签
- 浏览器乱码的原因及解决
- 常用的meta标签与SEO
- script标签中defer和async的区别
- src&href区别
- HTML5有哪些更新
-
- 语义化标签
- 媒体标签
- 表单
- 进度条、度量器
- DOM查询
- Web存储
- Canvas和SVG
- 拖放 (HTML5 drag API)
- WebSocket
- img的srcset属性
- 行内元素、块级元素、空元素
- Web Worker
- HTML5离线存储
- title与h1、b与strong、i与em的区别
- iframe的优缺点
- 渐进增强和优雅降级之间的区别
DOCTYPE(文章类型)
DOCTYPE html>
DOCTYPE作用:
:HTML5中一种标准通用标记语言的文档类型声明,作用是告诉浏览器(解析器)应该以什么样的文档类型定义(HTML或XHTML)来解析文档,不同的渲染模式会影响浏览器对CSS、JavaScript的解析。
浏览器渲染页面的两种模式:
浏览器渲染页面有两种模式:CSS1Compat(标准模式)与BackCompat(怪异模式)
在W3C标准出台以前,浏览器在对页面的渲染上没有统一规范,各个浏览器对页面的渲染上存在差异,甚至是同一浏览器的不同版本中,对浏览器的渲染也不同,产生了Quirks mode或Compatibility Mode。
在W3C标准推出之后,浏览器渲染页面有了统一标准(CSScompat或Strict mode、Standars mode)。但为了保证旧的网页还能继续正常渲染使用,保持浏览器渲染的兼容性,浏览器都保留了旧的渲染方法。因此浏览器的渲染产生了Quircks mode和Standars mode两种模式。
标准模式CSS1Compat: 浏览器使用W3C的标准解析渲染页面。
HTML4提供了三种DOCTYPE可选择:
DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Frameset//EN" "http://www.w3.org/TR/html4/frameset.dtd">
XHTML1.0提供了三种DOCTYPE可选择:
DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Frameset//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-frameset.dtd">
元素真正的宽度 = margin-left + border-left-width + padding-left + width + padding-right + border-right-width + margin-right;
怪异模式BackCompat: 浏览器使用自己的解析渲染引擎来解析渲染页面。
DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
或什么也不加
width则是元素的实际宽度,内容宽度 = width - (margin-left + margin-right + padding-left + padding-right + border-left-width + border-right-width);
怪异模式和标准模式
head标签
标签是 HTML 文档的一个重要部分,它通常位于文档的起始位置,在标签内部。标签中包含的元素提供了关于文档的元信息,以及引用外部资源和定义文档属性的方法。
作用:
- 文档元信息:描述文档的属性,如标题、字符编码等
- 引用外部资源:head中引用外部资源,如样式表、脚本文件、图标等,也可以定义网站图标。
- SEO搜索引擎优化:一些元信息和标签可以用于改善搜索引擎对页面内容的理解和索引。
部分有以下几标签:、、 标签,会停止解析文档,立即加载并执行指定的脚本,执行完毕之后,才会继续解析后面的标签。

2、浏览器在解析HTML文档时,如果遇到 标签时,说明该脚本的网络请求加载是异步进行的,不用等脚本加载完之后再加载页面或加载其他脚本,不会阻塞浏览器解析HTML。但是当脚本加载完毕之后,如果此时HTML还未解析完,浏览器会暂停解析HTML,先让JS引擎执行代码,执行完毕后再解析HTML。

3、浏览器在解析HTML文档时,如果遇到 标签时,说明该脚本的网络请求加载是异步进行的,不用等脚本加载完之后再加载页面或加载其他脚本,不会阻塞浏览器解析HTML。且当脚本加载完毕之后,如果此时HTML还未解析完,浏览器不会暂停解析HTML,而是等HTML解析完毕之后,再让JS引擎执行代码。

浏览器的渲染流程:
1、浏览器接收到字节数据,转成字符串,网页字符串交给HTML解析器,通过词法分析转换成token标记,然后解析器根据token构建节点,形成DOM树。
2、浏览器的加载解析过程是“自上而下”的,若在解析html时,遇到JavaScript资源URL(没有标记异步方式),则需要停止当前DOM树创建,直到JavaScript加载并被JavaScript引擎执行后才继续DOM树的创建。因为js可能会改动dom和css造成解析浪费。如果脚本是外部的则会等待脚本下载完毕再继续解析文档,脚本解析会将脚本中改变DOM和CSS的地方分别解析出来,追加到DOM树和Style表上。
3、如果节点中有其他资源,如图片、视频等,调用资源加载器去加载这些内容,但这些都是异步加载的,不会阻碍当前DOM数继续创建。css相关的请求资源会被浏览器生成相应的CSSDOM,即使DOM解析完毕,页面也不会渲染,页面渲染的条件是DOM和CSSDOM都解析完毕,进行合并生成RenderTree,进一步进行布局绘制。加载过程中遇到外部css文件,浏览器另外发出一个请求,来获取css文件。css不妨碍DOM的解析,但是会阻塞页面渲染。
重绘:
在不影响元素周围或内部的布局的情况下,只改变某个元素的外观(如修改元素的颜色、背景、阴影等),引起浏览器的repaint,重画某一部分,跳过了创建布局树和分层的阶段。
重排:
在元素的尺寸、位置或者整体布局改变时,浏览器会重新计算并更新页面的布局(如添加、删除、修改元素、改变窗口大小等),重排会影响整个页面的布局和渲染,因此代价较大。
避免重排的方式:样式集中改变、使用 absolute 或 fixed 脱离文档流。
src&href区别
<img src="" alt="">
<input type="text" src="">
<script src="">script>
<iframe src="" frameborder="0">iframe>
<a href="">a>
<link rel="stylesheet" href="style.css">
1、src(source)指向外部资源,指向的内容将会嵌入到文档中当前标签所在位置;在请求src资源时,会暂停其他资源的下载和处理,直接将其指向的资源同步加载、编译、执行到相应的文档内。这也就是为什么要把js脚本放在底部而不是头部。
-- src:img、input、style、script、iframe
2、href(Hypertext Reference)指超文本引用,指向网络资源所在位置,建立和当前元素(锚点)或当前文档(链接)之间的链接;在文档中添加href资源时,会将其指向的资源异步下载到相应的文档内,不会停止对当前文档的处理。这也就是为什么建议使用link方式来加载css,而不是@import方式。
-- href:link、a

HTML5有哪些更新
语义化标签
语义化是指根据内容的结构,选择合适的标签,即用正确的标签做正确的事情。
优点:
1、对机器友好,带有语义的文字表现力丰富,更适合搜索引擎的爬虫爬取有效信息,有利于搜索引擎优化SEO(search engine optimization)。语义类还支持读屏软件,根据文章可以自动生成目录。
2、对开发者友好,使用语义类标签增强了可读性,结构更加清晰,开发者能清晰的看出网页的结构,便于团队的开发与维护。
<header>定义文档的页眉(头部)header>
<nav>定义导航链接的部分nav>
<footer>定义文档或节的页脚(底部)footer>
<article>定义文章内容article>
<section>定义文档中的节(section、区段)section>
<aside>定义其所处内容之外的内容(侧边)aside>
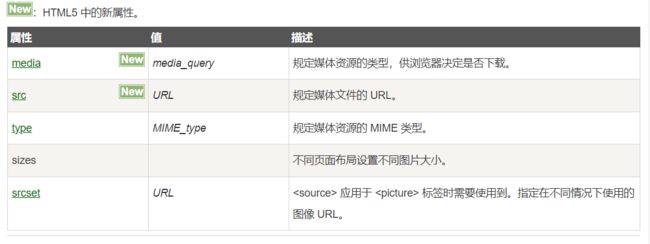
媒体标签
1、音频:

2、视频:

3、媒体资源
<video width="320" height="240" controls>
<source src="movie.mp4" type="video/mp4">
<source src="movie.ogg" type="video/ogg">
video>
表单
新增表单元素:
· email:提交表单的时候验证输入值是否满足email的格式
· tel:验证输入的是否是电话号码的格式
· url:提交表单的时候验证输入值是否满足url的格式
· number:根据你的设置提供选择数字的功能,其中min为最小值,max为最大值,value为默认值,step为点击箭头时数字的变化量,max、min、step、value均可不写,目前某些浏览器还不支持。
· range:会以一个滑块的形式表现包含一定范围内数字值的输入域,max为最大值,min为最小值,value为默认值,如果没有设置max和min,默认值是1-100
· date:选取日、月、年
· month:选取月、年
· week:选取周、年
· time:选取小时、分钟
· datetime-local:选取时间、日、月、年(本地时间)
· search:用于搜索域,若加上result="s"属性,则会在搜索框前面加一个搜索图标
· color:color类型会提供颜色拾取器,供用户选择颜色,并将用户选择的颜色填充到此元素中
新增表单属性:
· autofocus:在页面加载时,自动获得焦点。
· placeholder:提供一种提示(hint),描述输入域所期待的值。
· autocomplete :规定 form元素或者input元素拥有自动完成功能,即记录用户之前输入的值,关闭为off,默认为on。
· required:要求该输入框是必填项,当提交表单的时候会自动验证其内容是否不为空。
· pattern:利用正则表达式用于验证 元素的值。
· multiple:规定 元素中可选择多个文件或邮箱。
新增表单事件:
· oninput:监听当前指定元素内容的改变,只要内容改变(添加内容,删除内容)事件就会触发。
· oninvalid:当表单提交验证不通过时会触发该事件。
进度条、度量器
1、进度条:

2、度量器:

DOM查询

Web存储

cookie与sessionStorage和localStorage:
1、保存方式:
cookie存放在客户的浏览器上。
session都在客户端中保存,不参与服务器通讯。
2、生命周期:
cookie可设置失效时间。
localStorage除非手动清除否则可永久保存。
sessionStorage关闭当前页面或浏览器后失效。
3、存储大小
cookie 4KB左右
session 5MB
4、使用情景
cookie因每次请求都会携带在http中,可用来识别用户登录。
localStorage可用来跨页面传参。
sessionStorage可用来保留一些临时数据。
Canvas和SVG
1、Canvas:图形容器,用于图形的绘制,通过JavaScript来绘制2D图形,逐像素进行渲染,当其位置发生变化,就会重绘。
- 位图绘制: Canvas 是一个 HTML5 元素,提供了一个位图绘制的区域,你可以在上面绘制像素。绘制结果是一张位图图像。
- 像素操作: 你可以直接操作像素数据,绘制图形、图像和复杂的效果。因为是像素操作,缩放可能会导致图像失真。
- 实时绘制: Canvas 适用于需要实时更新和绘制的场景,如游戏、数据可视化等。
- 动画和交互性: Canvas 能够实现动画效果,但需要通过 JavaScript 来处理动画帧和交互事件。
- 图形复杂性: 对于绘制简单图形或需要复杂的像素级操作的情况,Canvas 是一个不错的选择。

2、SVG: 基于可扩展标记语言XML描述的2D图形的语言,每个被绘制的图形均被视为对象,如果对象的属性发生变化,那么浏览器能够自动重现图形。
- 矢量图形: SVG 是一种基于 XML 的图形描述语言,它使用矢量图形来描述图像,这意味着图像可以无限缩放而不失真。
- DOM 元素: SVG 图形被视为 DOM(文档对象模型)元素,可以像 HTML 元素一样进行操作。这使得它可以与其他 DOM 元素交互、操作和样式化。
- 分辨率无关性: 由于是矢量图形,SVG 不依赖于分辨率,所以它适合用于不同大小的显示屏和设备。
- 动画和交互性: SVG 支持内置的动画和交互功能,可以使用 CSS 和 JavaScript 来实现复杂的动态效果。
- 图形复杂性: 对于图像和图形的绘制,特别是在需要复杂路径和形状的情况下,SVG 是一个很好的选择。
- 文本支持: SVG 具有文本支持,可以嵌入文本和文字,使其成为图像和图表的好选择。

拖放 (HTML5 drag API)
拖放:拖放是一种常见的特性,即抓取对象以后拖到另一个位置。

<style>
#div1 {
width: 140px;
height: 160px;
padding: 10px;
border: 1px solid #a1a1a1;
}
#dragimg {
width: 120px;
height: 140px;
}
style>
<body>
<div id="div1" ondrop="drop(event)" ondragover="allowDrag(event)">div>
<img src="./static/123.png" draggable="true" ondragstart="drag(event)" decoding="async" loading="lazy" id="dragimg">
<script>
function allowDrag(event) {
event.preventDefault()
}
function drag(ev) {
ev.dataTransfer.setData("Text", ev.target.id);
}
function drop(ev) {
ev.preventDefault()
var data = ev.dataTransfer.getData("Text")
ev.target.appendChild(document.getElementById(data))
}
script>
body>
WebSocket
WebSocket:是 HTML5 开始提供的一种在单个 TCP 连接上进行全双工通讯的协议,实现了浏览器与服务器全双工通信,能更好的节省服务器资源和带宽并达到实时通讯的目的。
【WebSocket】前端使用WebSocket实时通信
img的srcset属性
<img src="/static/flamingo-fallback.jpg"
srcset="
/static/flamingo4x.png 4x,
/static/flamingo3x.png 3x,
/static/flamingo2x.png 2x,
/static/flamingo1x.png 1x "
sizes="(max-width: 360px) 340px, 128px" />
//在图片密度为1x时,加载/static/flamingo1x.png
//在图片密度为2x时,加载/static/flamingo2x.png
//在图片密度为3x时,加载/static/flamingo3x.png
//在图片密度为4x时,加载/static/flamingo4x.png
//sizes="[media query] [length], [media query] [length] ... "
实现响应式图片,在指定宽度或像素密度下加载对应的图片地址。
srcset指定图片的地址和对应的图片质量。sizes用来设置图片的尺寸零界点。
行内元素、块级元素、空元素
1、行内元素特点:
· 可以与其他行内元素位于同一行;
· 行内内部可以容纳其他行内元素,但不可以容纳块元素,不然会出现无法预知的效果;
常见行内元素有:span、img、input、select、strong、em、a、b。
2、块元素特点:
· 独占一行,排斥其他元素跟其位于同一行,包括块元素和行内元素;
· 块元素内部可以容纳其他块元素或行元素;
常见块元素有:h1~h6、p、div、ul、ol、li、dl、dt、dd、hr。
3、空元素特点:
· 没有内容的HTML元素
· 自闭合标签
常见的空元素有:br、hr、img、input、link、meta。
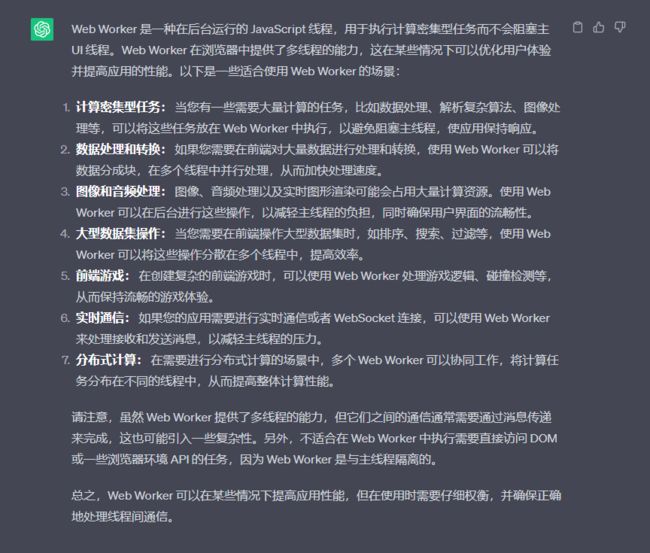
Web Worker
当在 HTML 页面中执行脚本时,页面的状态是不可响应的,直到脚本已完成。
web worker 是运行在后台的 JavaScript,独立于其他脚本,不会影响页面的性能。您可以继续做任何愿意做的事情:点击、选取内容等等,而此时 web worker 在后台运行。
JavaScript采用的是单线程,当有多个任务时,需要排队执行,而web worker的作用是为JavaScript创造多线程环境,允许主线程创建Worker线程,在主线程运行任务时,Worker线程在后台运行其他任务,互不干扰。
Web Worker 使用教程
<body>
<p>计数:<span id="result"></span></p>
<button onclick="startWorker()">开始工作</button>
<button onclick="stopWorker()">停止工作</button>
<script>
var wkr;
function startWorker() {
//检测是否存在 Worker
if (typeof (Worker) !== "undefined") {
if (typeof (wkr) == "undefined") {
wkr = new Worker("demo_workers.js") //创建Web Worker对象
}
//向 web worker 添加一个 "onmessage" 事件监听器
wkr.onmessage = function (event) {
document.getElementById("result").innerHTML = event.data
}
} else {
document.getElementById("result").innerHTML = "抱歉,您的浏览器不支持Web Workers..."
}
}
function stopWorker() {
wkr.terminate() //终止 Web Worker
wkr = undefined
}
</script>
</body>

HTML5离线存储
离线存储:通过将网页的资源(如 HTML、CSS、JavaScript、图像等)保存在用户的设备上,允许用户在没有网络连接的情况下,仍然能够访问和使用网页。在用户连接网络之后,更新用户机器上的缓存文件。

过程:
1、创建一个Cache Manifest文件,在其中列出需要在离线时缓存的资源,以及网络策略,并在需要离线存储功能的HTML文件中,通过引入该文件。
2、在线时:当用户第一次访问这个页面时,浏览器会根据页面头部manifest属性的信息,下载并解析Cache Manifest文件的内容。浏览器会根据CACHE部分列出的资源进行下载并保存到本地。当再次访问时,浏览器会使用离线资源加载页面,并且通过对比新的manifest文件与旧的manifest文件,进行下载并更新需要更新的资源。
3、离线时:浏览器会直接使用离线存储资源。
CACHE MANIFEST
# Version 1.0
CACHE:
styles.css
script.js
images/logo.png
NETWORK:
*
FALLBACK:
.manifest 文件由多个部分组成,包括 “CACHE”、“NETWORK” 和 “FALLBACK”。其中:
CACHE 部分列出了需要在离线时缓存的资源。
NETWORK 定义了在离线状态下需要从网络加载的资源。通常使用 * 表示所有资源都需要从网络加载,也就是离线时不使用本地缓存。但当CACHE和NETWORK中有一个相同的资源,那么这个资源还是会被离线存储,即CACHE的优先级更高。
FALLBACK 可以定义一些在离线时备用的资源。例如,如果某个资源在离线时不可用,你可以为它指定一个备用的资源。

title与h1、b与strong、i与em的区别
1、title与h1:
title:通常用于指定文档的标题,显示在浏览器的标题栏或标签页上,不会在网页内容上显示出来。
h1:HTML 标题元素,用于表示文档的主要标题。一个页面应该只有一个 h1 元素,表示页面的主题或主要内容。
2、b与strong:
b:表示粗体文本的标签,它在样式上使文本变粗,但没有强调的语义含义。
strong:表示强调的语义标签,它在样式上通常也会使文本变粗,但更重要的是强调文本的重要性或语义上的强调。搜索引擎和屏幕阅读器等工具可能会对 strong 元素给予更大的重视。
3、i与em:
i:表示斜体文本的标签,它在样式上使文本变斜,但没有强调的语义含义。
em:表示强调的语义标签,它在样式上通常也会使文本变斜,但更重要的是强调文本的重要性或语义上的强调。与 strong 类似,em 也可能受到搜索引擎和阅读器的特殊处理。