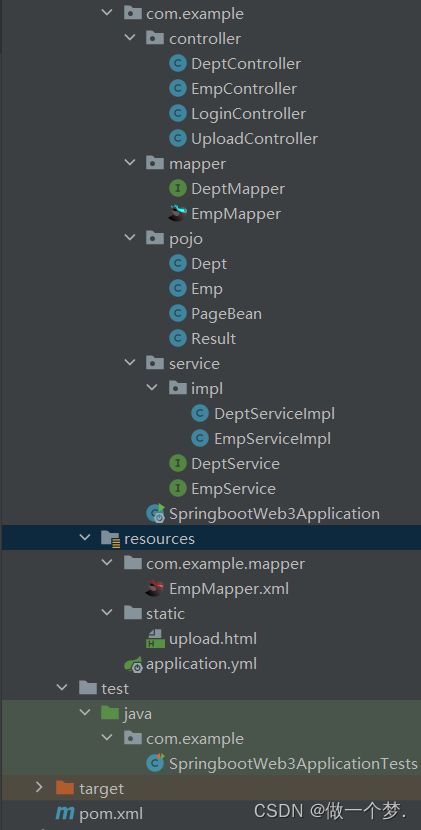
SpringBootWeb案例
SpringBootWeb案例
1. 环境搭建
- 准备数据库表(dept,emp)
- 创建spring boot工程,引入对应的起步依赖(web,mybatis,mysql驱动,lombok)
- 配置文件application.properties中引入mybatis的配置信息,准备对应的实体类
- 准备对应的Mapper,Service(接口,实现类),Controller基础结构
准备数据库表:
-- 部门管理
create table dept(
id int unsigned primary key auto_increment comment '主键ID',
name varchar(10) not null unique comment '部门名称',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间'
) comment '部门表';
-- 部门表测试数据
insert into dept (id, name, create_time, update_time) values(1,'学工部',now(),now()),(2,'教研部',now(),now()),(3,'咨询部',now(),now()), (4,'就业部',now(),now()),(5,'人事部',now(),now());
-- 员工管理(带约束)
create table emp (
id int unsigned primary key auto_increment comment 'ID',
username varchar(20) not null unique comment '用户名',
password varchar(32) default '123456' comment '密码',
name varchar(10) not null comment '姓名',
gender tinyint unsigned not null comment '性别, 说明: 1 男, 2 女',
image varchar(300) comment '图像',
job tinyint unsigned comment '职位, 说明: 1 班主任,2 讲师, 3 学工主管, 4 教研主管, 5 咨询师',
entrydate date comment '入职时间',
dept_id int unsigned comment '部门ID',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间'
) comment '员工表';
-- 员工表测试数据
INSERT INTO emp
(id, username, password, name, gender, image, job, entrydate,dept_id, create_time, update_time) VALUES
(1,'jinyong','123456','金庸',1,'1.jpg',4,'2000-01-01',2,now(),now()),
(2,'zhangwuji','123456','张无忌',1,'2.jpg',2,'2015-01-01',2,now(),now()),
(3,'yangxiao','123456','杨逍',1,'3.jpg',2,'2008-05-01',2,now(),now()),
(4,'weiyixiao','123456','韦一笑',1,'4.jpg',2,'2007-01-01',2,now(),now()),
(5,'changyuchun','123456','常遇春',1,'5.jpg',2,'2012-12-05',2,now(),now()),
(6,'xiaozhao','123456','小昭',2,'6.jpg',3,'2013-09-05',1,now(),now()),
(7,'jixiaofu','123456','纪晓芙',2,'7.jpg',1,'2005-08-01',1,now(),now()),
(8,'zhouzhiruo','123456','周芷若',2,'8.jpg',1,'2014-11-09',1,now(),now()),
(9,'dingminjun','123456','丁敏君',2,'9.jpg',1,'2011-03-11',1,now(),now()),
(10,'zhaomin','123456','赵敏',2,'10.jpg',1,'2013-09-05',1,now(),now()),
(11,'luzhangke','123456','鹿杖客',1,'11.jpg',5,'2007-02-01',3,now(),now()),
(12,'hebiweng','123456','鹤笔翁',1,'12.jpg',5,'2008-08-18',3,now(),now()),
(13,'fangdongbai','123456','方东白',1,'13.jpg',5,'2012-11-01',3,now(),now()),
(14,'zhangsanfeng','123456','张三丰',1,'14.jpg',2,'2002-08-01',2,now(),now()),
(15,'yulianzhou','123456','俞莲舟',1,'15.jpg',2,'2011-05-01',2,now(),now()),
(16,'songyuanqiao','123456','宋远桥',1,'16.jpg',2,'2007-01-01',2,now(),now()),
(17,'chenyouliang','123456','陈友谅',1,'17.jpg',NULL,'2015-03-21',NULL,now(),now());
配置文件applicat.properties:
#驱动类名称
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
#数据库连接的url
spring.datasource.url=jdbc:mysql://localhost:3306/tlias
#连接数据库的用户名
spring.datasource.username=root
#连接数据库的密码
spring.datasource.password=123456
#开启mybatis的日志输出
mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
#开启数据库表字段 到 实体类属性的驼峰映射
mybatis.configuration.map-underscore-to-camel-case=true
准备对应的Mapper,Service(接口,实现类),Controller基础结构
一个完整的请求路径,应该是类上的@RequestMapping的value属性+方法上的@RequestMapping的value属性
1.1 开发规范-统一响应结果
前后端工程在进行交互时,使用统一响应结果 Result。
package com.example.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Result {
private Integer code; //响应码,1 代表成功;0 代表失败
private String msg; //响应信息 描述字符串
private Object data; //返回的数据
//增删改 成功响应
public static Result success(){
return new Result(1,"success",null);
}
//查询 成功响应
public static Result success(Object data){
return new Result(1,"success",data);
}
//失败响应
public static Result error(String msg){
return new Result(0,msg,null);
}
}
1.2 开发流程
我们在进行功能开发时,都是根据如下流程进行:
-
查看页面原型明确需求
- 根据页面原型和需求,进行表结构设计、编写接口文档(已提供)
-
阅读接口文档
-
思路分析
-
功能接口开发
- 就是开发后台的业务功能,一个业务功能,我们称为一个接口
-
功能接口测试
- 功能开发完毕后,先通过Postman进行功能接口测试,测试通过后,再和前端进行联调测试
-
前后端联调测试
- 和前端开发人员开发好的前端工程一起测试
2. 部门管理
2.1 查询部门
部门列表查询
- 基本信息
请求路径:/depts
请求方式:GET
接口描述:该接口用于部门列表数据查询
-
请求参数
无
-
响应数据
参数格式:application/json
参数说明:
参数名 类型 是否必须 备注 code number 必须 响应码,1 代表成功,0 代表失败 msg string 非必须 提示信息 data object[ ] 非必须 返回的数据 |- id number 非必须 id |- name string 非必须 部门名称 |- createTime string 非必须 创建时间 |- updateTime string 非必须 修改时间
DeptController
//部门管理Controller
@Slf4j
@RestController
public class DeptController {
@Autowired
private DeptService deptService;
// @RequestMapping(value = "/depts",method = RequestMethod.GET) // 方式一:指定请求方式为GET
@GetMapping("/depts") // 方式二:指定请求方式为GET
public Result list(){
log.info("查询全部部门数据");
//调用service查询部门数据
List<Dept> deptList = deptService.list();
return Result.success(deptList);
}
}
DeptService(业务接口)
public interface DeptService {
List<Dept> list();
}
DeptServiceImpl(业务实现类)
@Service
public class DeptServiceImpl implements DeptService {
@Autowired
private DeptMapper deptMapper;
@Override
public List<Dept> list(){
return deptMapper.list();
}
}
DeptMapper
@Mapper
public interface DeptMapper {
/*
查询全部部门数据
*/
@Select("select * from tlias.dept")
List<Dept> list();
}
2.2 删除
删除部门
- 基本信息
请求路径:/depts/{id}
请求方式:DELETE
接口描述:该接口用于根据ID删除部门数据
DeptController
/*
* 删除部门
* @return
*/
@DeleteMapping("/{id}")
public Result delete(@PathVariable Integer id){
log.info("根据id删除部门:{}",id);
//调用service删除部门
deptService.delete(id);
return Result.success();
}
DeptService
/*
* 删除部门
* @param id
*/
void delete(Integer id);
DeptServiceImpl
@Override
public void delete(Integer id) {
deptMapper.deleteById(id);
}
DeptMapper
/*
* 根据ID删除部门
* @param id*/
@Delete("delete from tlias.dept where id = #{id}")
void deleteById(Integer id);
2.3 新增部门
添加部门
- 基本信息
请求路径:/depts
请求方式:POST
接口描述:该接口用于添加部门数据
DeptController
/*
* 新增部门
* @return
*/
@PostMapping
public Result add(@RequestBody Dept dept){
log.info("新增部门:{}",dept);
//调用service新增部门
deptService.add(dept);
return Result.success();
}
DeptService
/*
* 新增部门
* */
void add(Dept dept);
DeptServiceImpl
@Override
public void add(Dept dept) {
dept.setCreateTime(LocalDateTime.now());
dept.setUpdateTime(LocalDateTime.now());
deptMapper.insert(dept);
}
DeptMapper
/*
* 新增部门
* @param dept
*/
@Insert("insert into tlias.dept(name,create_time,update_time) values (#{name},#{createTime},#{updateTime})")
void insert(Dept dept);
3. 员工管理
3.1 分页查询
- 前端在请求服务端时,传递的参数
- 当前页码 page
- 每页显示条数 pageSize
- 后端需要响应什么数据给前端
- 所查询到的数据列表(存储到List 集合中)
- 总记录数
后台给前端返回的数据包含:List集合(数据列表)、total(总记录数)
而这两部分通常封装到PageBean对象中,并将该对象转换为json格式的数据响应回给浏览器。
package com.example.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.List;
/*
* 分页查询结果封装类
* */
@Data
@NoArgsConstructor
@AllArgsConstructor
public class PageBean {
private Long total; //总记录数
private List rows; //数据列表
}
3.1.1 员工列表查询
- 基本信息
请求路径:/emps
请求方式:GET
接口描述:该接口用于员工列表数据的条件分页查询
EmpController
package com.example.controller;
import com.example.pojo.PageBean;
import com.example.pojo.Result;
import com.example.service.EmpService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@Slf4j
@RestController
public class EmpController {
@Autowired
private EmpService empService;
@GetMapping("/emps")
public Result page(@RequestParam(defaultValue = "1") Integer page,
@RequestParam(defaultValue = "10") Integer pageSize){
log.info("分页查询,参数:{},{}",page,pageSize);
//调用service分页查询
PageBean pageBean = empService.page(page,pageSize);
return Result.success(pageBean);
}
}
@RequestParam的属性defaultValue可以来设置参数的默认值
EmpService
public interface EmpService {
PageBean page(Integer page, Integer pageSize);
}
EmpServiceImpl
@Service
public class EmpServiceImpl implements EmpService {
@Autowired
private EmpMapper empMapper;
@Override
public PageBean page(Integer page, Integer pageSize) {
//1.获取总记录数
Long count = empMapper.count();
//2.获取分页查询结果列表
Integer start = (page - 1) * pageSize;
List<Emp> empList = empMapper.page(start,pageSize);
//3.封装PageBean对象
PageBean pageBean = new PageBean(count,empList);
return pageBean;
}
}
EmpMapper
@Mapper
public interface EmpMapper {
/*
* 查询总记录数
* @return
* */
@Select("select count(*) from tlias.emp ")
public Long count();
/*
* 分页查询,获取列表数据
* @param start
* @param pageSize
* @return
* */
@Select("select * from tlias.emp limit #{start},#{pageSize}")
public List<Emp> page(Integer start,Integer pageSize);
}
3.1.1.1 功能测试
重新启动项目,通过Apipost,发起GET请求:
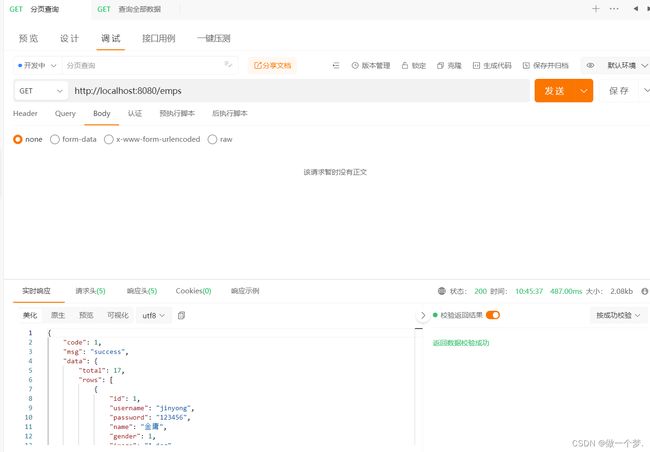
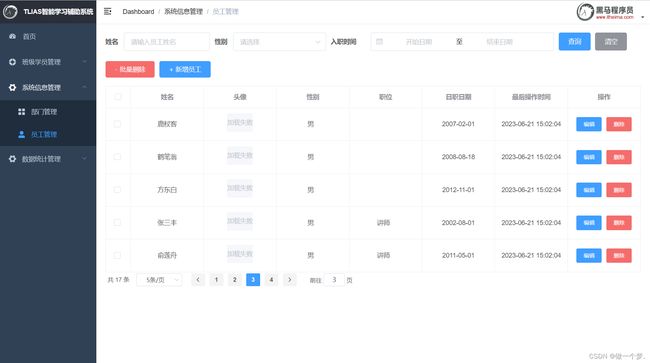
3.1.1.2 前后端联调
打开浏览器,测试后端功能接口:
3.2 分页插件PageHelper
PageHelper是Mybatis的一款功能强大、方便易用的分页插件,支持任何形式的单标、多表的分页查询。
官网:https://pagehelper.github.io/
1.在pom.xml中导入分页插件的依赖
<dependency>
<groupId>com.github.pagehelpergroupId>
<artifactId>pagehelper-spring-boot-starterartifactId>
<version>1.4.2version>
dependency>
3.3 条件分页查询
1.条件查询:动态SQL-XML映射文件
2.搜索栏的搜索条件有三个,分别是:
- 姓名:模糊匹配
- 性别:精确匹配
- 入职日期:范围匹配
3.在原有分页查询的代码基础上进行改造:
EmpController
@Slf4j
@RestController
public class EmpController {
@Autowired
private EmpService empService;
@GetMapping("/emps")
public Result page(@RequestParam(defaultValue = "1") Integer page,
@RequestParam(defaultValue = "10") Integer pageSize,
String name, Short gender,
@DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate begin,
@DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate end){
log.info("分页查询,参数:{},{},{},{},{},{}",page,pageSize,name,gender,begin,end);
//调用service分页查询
PageBean pageBean = empService.page(page,pageSize,name,gender,begin,end);
return Result.success(pageBean);
}
}
EmpService
public interface EmpService {
PageBean page(Integer page, Integer pageSize, String name, Short gender, LocalDate begin, LocalDate end);
}
EmpServiceImpl
@Override
public PageBean page(Integer page, Integer pageSize, String name, Short gender, LocalDate begin,LocalDate end) {
//1.设置分页参数
PageHelper.startPage(page,pageSize);
//2.执行查询
List<Emp> empList = empMapper.list(name,gender,begin,end);
Page<Emp> p = (Page<Emp>) empList;
//3.封装PageBean对象
PageBean pageBean = new PageBean(p.getTotal(),p.getResult());
return pageBean;
}
EmpMapper
public List<Emp> list(String name, Short gender, LocalDate begin,LocalDate end);
EmpMapper.xml
DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.mapper.EmpMapper">
<select id="list" resultType="com.example.pojo.Emp">
select *
from tlias.emp
<where>
<if test="name != null and name != '' ">
name like concat('%',#{name},'%')
if>
<if test="gender != null">
and gender = #{gender}
if>
<if test="begin != null and end != null">
and entrydate between #{begin} and #{end}
if>
where>
order by update_time desc
select>
mapper>
3.4 删除员工
-
基本信息
请求路径:/emps/{ids} 请求方式:DELETE 接口描述:该接口用于批量删除员工的数据信息
EmpController
@DeleteMapping("/emps/{ids}")
public Result delete(@PathVariable List<Integer> ids){
log.info("批量删除操作,ids:{}",ids);
empService.delete(ids);
return Result.success();
}
EmpService
public interface EmpService {
void delete(List<Integer> ids);
}
EmpServiceImpl
@Override
public void delete(List<Integer> ids) {
empMapper.delete(ids);
}
EmpMapper
/*
* 批量删除
* @param ids
*/
void delete(List<Integer> ids);
EmpMapper.xml
<delete id="delete">
delete
from tlias.emp
where id in
<foreach collection="ids" item="id" separator="," open="(" close=")">
#{id}
foreach>
delete>
3.5 新增员工
-
基本信息
请求路径:/emps 请求方式:POST 接口描述:该接口用于添加员工信息
EmpController
@PostMapping("/emps")
public Result save(@RequestBody Emp emp){
log.info("新增员工,emp:{}",emp);
empService.save(emp);
return Result.success();
}
Empservice
public interface EmpService {
void save(Emp emp);
}
EmpserviceImpl
@Override
public void save(Emp emp) {
emp.setCreateTime(LocalDateTime.now());
emp.setUpdateTime(LocalDateTime.now());
empMapper.insert(emp);
}
EmpMapper
/*
* 新增员工
* @param emp
* */
@Insert("insert into tlias.emp(username,name,gender,image,job,entrydate,dept_id,create_time,update_time)"+
"values(#{username},#{name},#{gender},#{image},#{job},#{entrydate},#{deptId},#{createTime},#{updateTime})")
void insert(Emp emp);
3.6 修改员工
-
基本信息
请求路径:/emps 请求方式:PUT 接口描述:该接口用于修改员工的数据信息
3.6.1 代码实现
EmpMapper
/*
* 修改员工信息*/
void update(Emp emp);
EmpMapper.xml
<update id="update">
update tlias.emp
<set>
<if test="username != null and username != ''">
username = #{username},
if>
<if test="password != null and password != ''">
password = #{password},
if>
<if test="name != null and name != ''">
name = #{name},
if>
<if test="gender != null">
gender = #{gender},
if>
<if test="image != null and image != ''">
image = #{image},
if>
<if test="updateTime != null">
update_time = #{updateTime},
if>
set>
where id = #{id}
update>
EmpService
void update(Emp emp);
EmpServiceImpl
@Override
public void update(Emp emp) {
emp.setUpdateTime(LocalDateTime.now());
empMapper.update(emp);
}
EmpController
@PutMapping("/emps")
public Result update(@RequestBody Emp emp){
log.info("更新员工信息:{}",emp);
empService.update(emp);
return Result.success();
}
3.6.2 ApiPost测试
发送PUT请求,进行测试:
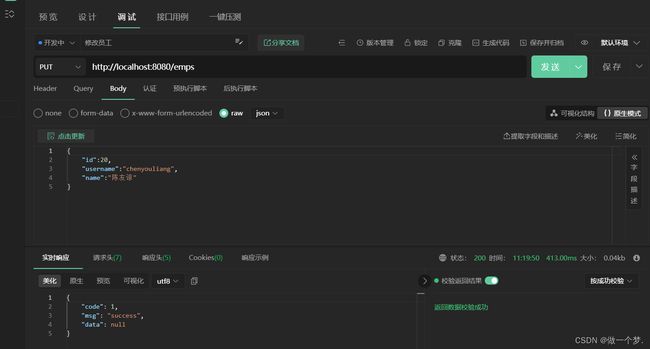
3.6.3 前后端联调
打开浏览器,测试后端功能接口:

点击编辑,能够正常修改员工信息,并且能够保存
4. 文件上传
4.1 简介
- 文件上传,是指将本地图片,视频,音频等文件上传到服务器,供其他用户浏览或下载的过程
- 文件上传在项目中应用非常广泛
- 前端页面三要素
- 表单项type=“file”
- 表单提交方式 post
- 表单的enctype属性multiparty/form-data
- 服务端接收文件
- MultipartFile
MultipartFile 常见方法:
- String getOriginalFilename(); //获取原始文件名
- void transferTo(File dest); //将接收的文件转存到磁盘文件中
- long getSize(); //获取文件的大小,单位:字节
- byte[] getBytes(); //获取文件内容的字节数组
- InputStream getInputStream(); //获取接收到的文件内容的输入流
4.2 本地存储
- 在服务端,接收到上传上来的文件之后,将文件存储在本地服务器磁盘中
代码实现:
- 在服务器本地磁盘上创建images目录,用来存储上传的文件
- 使用MultipartFile类提供的API方法,把临时文件转存到本地磁盘目录下
保证每次上传文件时文件名都唯一的(使用UUID获取随机文件名)
@Slf4j
@RestController
public class UploadController {
@PostMapping("/upload")
public Result upload(String username, Integer age, MultipartFile image) throws IOException {
log.info("文件上传:{},{},{}",username,age,image);
//获取原始文件名
String originalFilename = image.getOriginalFilename();
//构造唯一的文件名(不能重复) -uuid(通用唯一识别码)
int index = originalFilename.lastIndexOf(".");
String extname = originalFilename.substring(index);
String newFileName = UUID.randomUUID().toString()+ extname;
log.info("新的文件名:{}",newFileName);
//将文件存储在服务器的磁盘目录中 D:\JavaWeb\image
image.transferTo(new File("D:\\JavaWeb\\image\\"+ newFileName));
return Result.success();
}
}
在SpringBoot中,文件上传,默认单个文件允许最大大小为1M,如果需要上传大文件,可以在application.properties中进行如下配置:
#配置单个文件最大上传大小
spring.servlet.multipart.max-file-size=10MB
#配置单个请求最大上传大小(一次请求可以上传多个文件)
spring.servlet.multipart.max-request-size=100MB
如果直接存储在服务器的磁盘目录中,存在以下缺点:
- 不安全:磁盘如果损坏,所有的文件就会丢失
- 容量有限:如果存储大量的图片,磁盘空间有限(磁盘不可能无限制扩容)
- 无法直接访问
为了解决上述问题呢,通常有两种解决方案:
- 自己搭建存储服务器,如:fastDFS 、MinIO
- 使用现成的云服务,如:阿里云,腾讯云,华为云
4.3 阿里云OSS
-
阿里云:阿里巴巴集团旗下全球领先的云计算公司,也是国内最大的云服务提供商
-
阿里云对象存储OSS(Object Storage Service),是一款海量、安全、低成本、高可靠的云存储服务。使用OSS,可以通过网络随时存储和调用包括文本、图片、音频和视频等在内的各种文件。
5. 基础登录
5.1 需求分析
在登录界面中,我们可以输入用户的用户名以及密码,然后点击 “登录” 按钮就要请求服务器,服务端判断用户输入的用户名或者密码是否正确。如果正确,则返回成功结果,前端跳转至系统首页面。
- 基本信息
请求路径:/login
请求方式:POST
接口描述:该接口用于员工登录Tlias智能学习辅助系统
登录服务端的核心逻辑就是:接收前端请求传递的用户名和密码 ,然后再根据用户名和密码查询用户信息,如果用户信息存在,则说明用户输入的用户名和密码正确。如果查询到的用户不存在,则说明用户输入的用户名和密码错误。
5.2 代码实现
LoginController
@Slf4j
@RestController
public class LoginController {
@Autowired
private EmpService empService;
@PostMapping("/login")
public Result login(@RequestBody Emp emp){
log.info("员工登录");
Emp e = empService.login(emp);
return e != null ? Result.success():Result.error("用户名或密码错误");
}
}
EmpService
/**
* 用户登录
* @param emp
* @return
*/
Emp login(Emp emp);
EmpServiceImpl
@Override
public Emp login(Emp emp) {
Emp e = empMapper.getByUsernameAndPassword(emp);
return e;
}
EmpMapper
/*
* 根据用户名和密码查询员工
* */
@Select("select * from tlias.emp where username = #{username} and password = #{password}")
Emp getByUsernameAndPassword(Emp emp);
5.3 测试
功能开发完毕后,启动服务,打开Apipost进行测试
发起POST请求,访问:http://localhost:8080/login
6. 登录校验
6.1 会话技术
-
会话:用户打开浏览器,访问web服务器的资源,会话建立,直到有一方断开连接,会话结束,在一次会话中可以包含多次请求和响应
-
会话跟踪:一种维护浏览器状态的方法,服务器需要识别多次请求是否来自于同一浏览器,以便在同一次会话的多次请求间共享数据
-
会话跟踪方案:
- Cookie(客户端会话跟踪技术)
- 数据存储在客户端浏览器当中
- Session(服务端会话跟踪技术)
- 数据存储在储在服务端
- 令牌技术
- Cookie(客户端会话跟踪技术)
为什么要共享数据呢?
由于HTTP是无状态协议,在后面请求中怎么拿到前一次请求生成的数据呢?此时就需要在一次会话的多次请求之间进行数据共享
6.2 会话跟踪方案对比
6.2.1 方案一:Cookie
cookie 是客户端会话跟踪技术,它是存储在客户端浏览器的,我们使用 cookie 来跟踪会话,我们就可以在浏览器第一次发起请求来请求服务器的时候,我们在服务器端来设置一个cookie。
比如第一次请求了登录接口,登录接口执行完成之后,我们就可以设置一个cookie,在 cookie 当中我们就可以来存储用户相关的一些数据信息。比如我可以在 cookie 当中来存储当前登录用户的用户名,用户的ID。
服务器端在给客户端在响应数据的时候,会自动的将 cookie 响应给浏览器,浏览器接收到响应回来的 cookie 之后,会自动的将 cookie 的值存储在浏览器本地。接下来在后续的每一次请求当中,都会将浏览器本地所存储的 cookie 自动地携带到服务端。
接下来在服务端我们就可以获取到 cookie 的值。我们可以去判断一下这个 cookie 的值是否存在,如果不存在这个cookie,就说明客户端之前是没有访问登录接口的;如果存在 cookie 的值,就说明客户端之前已经登录完成了。这样我们就可以基于 cookie 在同一次会话的不同请求之间来共享数据。
-
服务器会 自动 的将 cookie 响应给浏览器。
-
浏览器接收到响应回来的数据之后,会 自动 的将 cookie 存储在浏览器本地。
-
在后续的请求当中,浏览器会 自动 的将 cookie 携带到服务器端。
为什么这一切都是自动化进行的?
是因为 cookie 它是 HTP 协议当中所支持的技术,而各大浏览器厂商都支持了这一标准。在 HTTP 协议官方给我们提供了一个响应头和请求头:
- 响应头 Set-Cookie :设置Cookie数据的
- 请求头 Cookie:携带Cookie数据的
Cookie:
- 优点:HTTP协议中支持的技术
- 缺点:
- 移动端APP无法使用Cookie
- 不安全,用户可以自己禁用Cookie
- Cookie不能跨域
跨域
- 跨域区分三个维度:协议,IP/域名,端口
- 任何一个维度不同即为跨域
6.2.2 方案二:Session
Session,它是服务器端会话跟踪技术,所以它是存储在服务器端的。而 Session 的底层其实就是基于Cookie 来实现的。
-
获取Session
如果现在要基于 Session 来进行会话跟踪,浏览器在第一次请求服务器的时候,就可以直接在服务器当中来获取到会话对象Session。如果是第一次请求Session ,会话对象是不存在的,这个时候服务器会自动的创建一个会话对象Session 。而每一个会话对象Session ,它都有一个ID(示意图中Session后面括号中的1,就表示ID),称之为 Session 的ID。
-
响应Cookie (JSESSIONID)
接下来,服务器端在给浏览器响应数据的时候,它会将 Session 的 ID 通过 Cookie 响应给浏览器。其实在响应头当中增加了一个 Set-Cookie 响应头。这个 Set-Cookie 响应头对应的值是不是cookie? cookie 的名字是固定的 JSESSIONID 代表的服务器端会话对象 Session 的 ID。浏览器会自动识别这个响应头,然后自动将Cookie存储在浏览器本地。
-
查找Session
在后续的每一次请求当中,都会将 Cookie 的数据获取出来,并且携带到服务端。接下来服务器拿到JSESSIONID这个 Cookie 的值,也就是 Session 的ID。拿到 ID 之后,就会从众多的 Session 当中来找到当前请求对应的会话对象Session。
这样就可以通过 Session 会话对象在同一次会话的多次请求之间来共享数据了
Session:
- 优点:Session是存储在服务端的,安全
- 缺点:
- 服务器集群环境下无法直接使用Session
- 移动端APP(Android、IOS)中无法使用Cookie
- 用户可以自己禁用Cookie
- Cookie不能跨域
Session 底层是基于Cookie实现的会话跟踪,如果Cookie不可用,则该方案,也就失效了
6.2.3 方案三:令牌技术
令牌,是一个用户身份的标识,本质是一个字符串
如果通过令牌技术来跟踪会话,就可以在浏览器发起请求。在请求登录接口的时候,如果登录成功,可以生成一个令牌,令牌就是用户的合法身份凭证。接下来在响应数据的时候,可以直接将令牌响应给前端。
接下来在前端程序当中接收到令牌之后,就需要将这个令牌存储起来。这个存储可以存储在 cookie 当中,也可以存储在其他的存储空间(比如:localStorage)当中。
在后续的每一次请求当中,都需要将令牌携带到服务端。携带到服务端之后,需要来校验令牌的有效性。如果令牌是有效的,就说明用户已经执行了登录操作,如果令牌是无效的,就说明用户之前并未执行登录操作。
此时,如果是在同一次会话的多次请求之间,想要共享数据,将共享的数据存储在令牌当中即可。
令牌技术:
- 优点:
- 支持PC端、移动端
- 解决集群环境下的认证问题
- 减轻服务器的存储压力(无需在服务器端存储)
- 缺点:需要自己实现(包括令牌的生成、令牌的传递、令牌的校验)
6.3 JWT令牌
-
JSON Web Token(https://jwt.io/)
-
定义了一种简洁的,自包含的格式,用于在通信双方以json数据格式安全的传输信息,由于数字签名的存在,这些信息是可靠的。
-
组成:
- 第一部分:Header(头),记录令牌类类型,签名算法等
- 第二部分:Payload(有效载荷),携带一些自定义信息,默认信息等
- 第三部分:Signature(签名),防止Token被纂改,确保安全性,将header,payload,并加入指定密钥,通过指定签名算法计算而来。
Base64:是基于64个可打印字符(A-Z a-z 0-9 + /)来表示二进制数据的编码方式
6.3.1 JWT生成
想要使用JWT令牌,需要先引入JWT的依赖:
<dependency>
<groupId>io.jsonwebtokengroupId>
<artifactId>jjwtartifactId>
<version>0.9.1version>
dependency>
在引入完JWT来赖后,就可以调用工具包中提供的API来完成JWT令牌的生成和校验
工具类:Jwts
生成JWT代码实现:
/*
* 生成JWT
* */
@Test
public void testGenJWT(){
Map<String,Object> claims = new HashMap<>();
claims.put("id",1);
claims.put("name","tom");
String jwt = Jwts.builder()
.signWith(SignatureAlgorithm.HS256,"example")//签名算法
.setClaims(claims) //自定义内容(载荷)
.setExpiration(new Date(System.currentTimeMillis() + 3600 * 1000))//设置有效期为1h
.compact();
System.out.println(jwt);
}
执行完上述代码后,会获得一个JWT令牌:eyJhbGciOiJIUzI1NiJ9.eyJuYW1lIjoidG9tIiwiaWQiOjEsImV4cCI6MTY4NzU3NzcwN30.jVDOfBv-RtRediMKqu6cMADzwmqS97g4QO4WV_CexYo
解析JWT代码实现:
/*
* 解析JWT
* */
@Test
public void testParseJWT(){
Claims claims = Jwts.parser()
.setSigningKey("example")
.parseClaimsJws("eyJhbGciOiJIUzI1NiJ9.eyJuYW1lIjoidG9tIiwiaWQiOjEsImV4cCI6MTY4NzU3NzcwN30.jVDOfBv-RtRediMKqu6cMADzwmqS97g4QO4WV_CexYo")
.getBody();
System.out.println(claims);
}
解析后可得到:
{name=tom, id=1, exp=1687577707}
- JWT校验时使用的签名密钥,必须和生成JWT令牌时使用的密钥时配套的
- 如果JWT令牌解析校验时报错,则说明JWT令牌被纂改 或 失效了,令牌非法
6.3.2 登录下发令牌
- 生成令牌
- 在登录成功之后来生成一个JWT令牌,并且把这个令牌直接返回给前端
- 校验令牌
- 拦截前端请求,从请求中获取到令牌,对令牌进行解析校验
JWT工具类
import io.jsonwebtoken.Claims;
import io.jsonwebtoken.Jwts;
import io.jsonwebtoken.SignatureAlgorithm;
import java.util.Date;
import java.util.Map;
public class JwtUtils {
private static String signKey = "itheima";
private static Long expire = 43200000L;
/**
* 生成JWT令牌
* @param claims JWT第二部分负载 payload 中存储的内容
* @return
*/
public static String generateJwt(Map<String, Object> claims){
String jwt = Jwts.builder()
.addClaims(claims)
.signWith(SignatureAlgorithm.HS256, signKey)
.setExpiration(new Date(System.currentTimeMillis() + expire))
.compact();
return jwt;
}
/**
* 解析JWT令牌
* @param jwt JWT令牌
* @return JWT第二部分负载 payload 中存储的内容
*/
public static Claims parseJWT(String jwt){
Claims claims = Jwts.parser()
.setSigningKey(signKey)
.parseClaimsJws(jwt)
.getBody();
return claims;
}
}
登录成功,生成JWT令牌并返回
@Slf4j
@RestController
public class LoginController {
@Autowired
private EmpService empService;
@PostMapping("/login")
public Result login(@RequestBody Emp emp){
log.info("员工登录:{}",emp);
Emp e = empService.login(emp);
//登陆成功,生成令牌,下发令牌
if (e != null){
Map<String, Object> claims = new HashMap<>();
claims.put("id",e.getId());
claims.put("name",e.getName());
claims.put("username",e.getUsername());
String jwt = JwtUtils.generateJwt(claims);//jwt包含了当前登陆的员工信息
return Result.success(jwt);
}
//登录失败 返回错误信息
return Result.error("用户名或密码错误");
}
}
6.4 过滤器(Filter)
- Filter过滤器,是JavaWeb三大组件(Servlet Filter Listener)之一
- 过滤器可以把对资源的请求拦截下来,从而实现一些特殊的功能
- 使用了过滤器之后,要想访问web服务器上的资源,必须先经过滤器,过滤器处理完毕之后,才可以访问对应的资源。
- 过滤器一般完成一些通用的操作,比如:登录校验,统一编码处理,敏感字符处理等
- **执行流程:**请求–>放行前逻辑–>放行–>资源–>放行后逻辑
Filter可以根据需求,配置不同的拦截资源路径:
@WebFilter(urlPatterns = "/*")
public class DomeFilter implements Filter{
}
| 拦截路径 | urlPatterns值 | 含义 |
|---|---|---|
| 拦截具体路径 | /login | 只有访问/login路径时,才会被拦截 |
| 目录拦截 | /emps/* | 访问/emps下的所有资源,都会被拦截 |
| 拦截所有 | /* | 访问所有的资源,都会被拦截 |
6.4.1 过滤器的基本使用
- 第1步,定义过滤器 :1.定义一个类,实现 Filter 接口,并重写其所有方法。
- 第2步,配置过滤器:Filter类上加 @WebFilter 注解,配置拦截资源的路径。引导类上加 @ServletComponentScan 开启Servlet组件支持。
定义过滤器:
//定义一个类,实现一个标准的Filter过滤器的接口
public class DemoFilter implements Filter {
@Override //初始化方法, 只调用一次
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("init 初始化方法执行了");
}
@Override //拦截到请求之后调用, 调用多次
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
System.out.println("Demo 拦截到了请求...放行前逻辑");
//放行
chain.doFilter(request,response);
}
@Override //销毁方法, 只调用一次
public void destroy() {
System.out.println("destroy 销毁方法执行了");
}
}
init方法:过滤器的初始化方法。在web服务器启动的时候会自动的创建Filter过滤器对象,在创建过滤器对象的时候会自动调用init初始化方法,这个方法只会被调用一次。
doFilter方法:这个方法是在每一次拦截到请求之后都会被调用,所以这个方法是会被调用多次的,每拦截到一次请求就会调用一次doFilter()方法。
destroy方法: 是销毁的方法。当我们关闭服务器的时候,它会自动的调用销毁方法destroy,而这个销毁方法也只会被调用一次。
在定义完Filter之后,Filter其实并不会生效,还需要完成Filter的配置,Filter的配置非常简单,只需要在Filter类上添加一个注解:@WebFilter,并指定属性urlPatterns,通过这个属性指定过滤器要拦截哪些请求
@WebFilter(urlPatterns = "/*") //配置过滤器要拦截的请求路径( /* 表示拦截浏览器的所有请求 )
public class DemoFilter implements Filter {
@Override //初始化方法, 只调用一次
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("init 初始化方法执行了");
}
@Override //拦截到请求之后调用, 调用多次
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
System.out.println("Demo 拦截到了请求...放行前逻辑");
//放行
chain.doFilter(request,response);
}
@Override //销毁方法, 只调用一次
public void destroy() {
System.out.println("destroy 销毁方法执行了");
}
}
在Filter类上面加了@WebFilter注解之后,还需要在启动类上面加上一个注解@ServletComponentScan,通过这个@ServletComponentScan注解来开启SpringBoot项目对于Servlet组件的支持。
@ServletComponentScan
@SpringBootApplication
public class TliasWebManagementApplication {
public static void main(String[] args) {
SpringApplication.run(TliasWebManagementApplication.class, args);
}
}
在过滤器Filter中,如果不执行放行操作,将无法访问后面的资源。 放行操作:chain.doFilter(request, response)
6.4.2 过滤器链
-
一个web应用中,可以配置多个过滤器,多个过滤器就形成了一个过滤器链
-
顺序:注解配置的Filter,优先级是按照过滤器类名(字符串)的自然排序
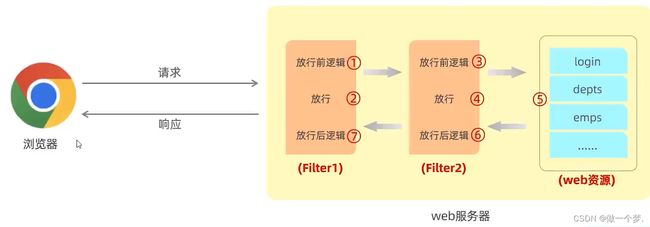
如果在web服务器当中,定义了两个过滤器,这两个过滤器就形成了一个过滤器链。
而这个链上的过滤器在执行的时候会一个一个的执行,会先执行第一个Filter,放行之后再来执行第二个Filter,如果执行到了最后一个过滤器放行之后,才会访问对应的web资源。
访问完web资源之后,按照刚才所介绍的过滤器的执行流程,还会回到过滤器当中来执行过滤器放行后的逻辑,而在执行放行后的逻辑的时候,顺序是反着的。
先要执行过滤器2放行之后的逻辑,再来执行过滤器1放行之后的逻辑,最后在给浏览器响应数据。
具体顺序如下图所示:
6.4.3 登录校验-Filter
具体实现流程:
- 获取请求url
- 判断请求url中是否包含login,如果包含,说明是登录操作,放行
- 获取请求头中的令牌(token)
- 判断令牌是否存在,如果不存在,返回错误结果(未登录)
- 解析token,如果解析失败,返回错误结果(未登录)
- 放行
代码实现过程:LoginCheckFilter
@Slf4j
@WebFilter(urlPatterns = "/*")
public class LoginCheckFilter implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
HttpServletRequest req = (HttpServletRequest) request;
HttpServletResponse resp = (HttpServletResponse) response;
//1.获取请求url
String url = req.getRequestURI().toString();
log.info("请求中的url:{}",url);
//2.判断请求url中是否包含login,如果包含,说明是登录操作,放行
if (url.contains("login")){
chain.doFilter(request,response);
return;
}
//3.获取请求头中的令牌(token)
String jwt = req.getHeader("token");
//4.判断令牌是否存在,如果不存在,返回错误结果(未登录)
if (!StringUtils.isEmpty(jwt)){
log.info("请求头token为空,返回未登录的信息");
Result error = Result.error("NOT_LOGIN");
//手动转换 对象--json ----->阿里巴巴fastJSON
String notLogin = JSONObject.toJSONString(error);
resp.getWriter().write(notLogin);
return;
}
}
}
在上述过程中,使用到了一个第三方json处理的工具包fastjson,需要导入依赖:
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.76version>
dependency>
6.5 拦截器(Interceptor)
- 拦截器是一种动态拦截方法调用的机制,类似于过滤器,Spring框架中提供的,用来动态拦截控制器方法的执行
- 作用:拦截请求,在指定的方法调用前后,根据业务需要执行预先设定的代码
拦截路径设置:
| 拦截路径 | 含义 | 举例 |
|---|---|---|
| /* | 一级路径 | 能匹配/depts,/emps,/login,不能匹配 /depts/1 |
| /** | 任意级路径 | 能匹配/depts,/depts/1,/depts/1/2 |
| /depts/* | /depts下的一级路径 | 能匹配/depts/1,不能匹配/depts/1/2,/depts |
| /depts/** | /depts下的任意级路径 | 能匹配/depts,/depts/1,/depts/1/2,不能匹配/emps/1 |
6.5.1 拦截流程
-
当打开浏览器来访问部署在web服务器当中的web应用时,此时所定义的过滤器会拦截到这次请求。拦截到这次请求之后,它会先执行放行前的逻辑,然后再执行放行操作。而由于当前是基于springboot开发的,所以放行之后是进入到了spring的环境当中,也就是要来访问所定义的controller当中的接口方法。
-
Tomcat并不识别所编写的Controller程序,但是它识别Servlet程序,所以在Spring的Web环境中提供了一个非常核心的Servlet:DispatcherServlet(前端控制器),所有请求都会先进行到DispatcherServlet,再将请求转给Controller。
-
当定义了拦截器后,会在执行Controller的方法之前,请求被拦截器拦截住。执行
preHandle()方法,这个方法执行完成后需要返回一个布尔类型的值,如果返回true,就表示放行本次操作,才会继续访问controller中的方法;如果返回false,则不会放行(controller中的方法也不会执行)。 -
在controller当中的方法执行完毕之后,再回过来执行
postHandle()这个方法以及afterCompletion()方法,然后再返回给DispatcherServlet,最终再来执行过滤器当中放行后的这一部分逻辑的逻辑。执行完毕之后,最终给浏览器响应数据。
拦截器和过滤器区别:
- 接口规范不同:过滤器需要实现Filter接口,而拦截器需要实现HandlerInterceptor接口
- 拦截范围不同:过滤器Filter会拦截所有的资源,而Interceptor只会拦截Spring环境中的资源
7. 异常处理
出现异常,解决方案:
- 方案一:在所有Controller的所有方法中进行try…catch处理
- 缺点:代码臃肿(不推荐)
- 方案二:全局异常处理器
- 好处:简单、优雅(推荐)
7.1 全局异常处理器
- 定义全局异常处理器,就是定义一个类,在类上加上一个注解@RestControllerAdvice,加上这个注解就代表定义了一个全局异常处理器。
- 在全局异常处理器当中,需要定义一个方法来捕获异常,在这个方法上需要加上注解@ExceptionHandler。通过@ExceptionHandler注解当中的value属性来指定要捕获的是哪一类型的异常。
@RestControllerAdvice = @ControllerAdvice + @ResponseBody
处理异常的方法返回值会转换为json后再响应给前端
- @RestControllerAdvice //表示当前类为全局异常处理器
- @ExceptionHandler //指定可以捕获哪种类型的异常进行处理