SQL 数据库
安装配置
【1】 MySQL安装配置教程(超级详细、保姆级)
【2】 MySQL+Navicat安装配置教程(超级详细、保姆级)
学习资料
【戴师兄】SQL入门免费教程
刷题链接:https://share.mubu.com/doc/4BHMMbbvIMb
学习笔记:https://share.mubu.com/doc/uf3vg8s5ar
【1】 零基础入门SQL - 知乎
学习笔记: https://mubu.com/doc/6M8yHBsz9lY
语法手册: 自学SQL网-金老师手册-打死也要记住法则
刷题链接:【入门】自学SQL网 / 菜鸟教程- 【进阶】牛客网 - 【参考手册】w3school
刷题答案(自学SQL网):【1】【2】
B站视频:【光头Mosh】
学习笔记:【1】
用法



最全版本
SELECT DISTINCT cxx, AGG_FUNC(cxx), AS xx
FROM xx AS xx
JOIN another_table
ON mytable.id = another_table.matching_id
WHERE xx is not null
GROUP BY cxx
HAVING group_exx
# UNION (+ 另一个SELECT语句)
ORDER BY cxx ASC/DESC
LIMIT vxx OFFSET vxx;
# cxx:列名column
# vxx:数值number
# exx:条件表达式constraint_expression
函数
distinct:去重,删除的逻辑(而不是合并)。指定某个或某些属性列唯一返回。紧跟在SELECT之后写:SELECT DISTINCT columngroup by:分组,合并。也会返回唯一的行,不过可以对具有相同的 属性值的行做一些统计计算,比如:求和、计数。HAVING:对分组之后的数据再做SELECT筛选order bycolumnASC/DESC:排序,让结果按一个或多个属性列做 ASC升序 或 DESC 降序.LIMITxxxOFFSETxxx:通常和ORDER BY 语句一起使用,对整个结果集排序之后,LIMIT指定只返回多少行结果,OFFSET指定从哪一行之后(不含)开始返回(limit 2 offset 2:3-4名)。(执行顺序靠最后)- JOINs:
(INNER) JOIN,LEFT (OUTER) JOIN,RIGHT (OUTER) JOIN,FULL (OUTER) JOIN,cross join UNION运算符用于将两个或多个 SELECT 语句 的结果集合并成一个结果集,包括属于所有查询的所有行。记住:UNION 中的每个 SELECT 语句必须具有相同的列数;列还必须具有相似的数据类型;每个 SELECT 语句中的列的顺序也必须相同。
SELECT column1, column2, column3
FROM table1
UNION
SELECT column1, column2, column3
FROM table2;
AS:给 表 / 属性列 / 表达式 取一个别名,可以省略不写COUNTMINMAXAVGSUM
# 用INNER/LEFT/RIGHT/FULL JOINs 做多表查询
SELECT column1, column2, …
FROM mytable
INNER/LEFT/RIGHT/FULL JOIN another_table
ON mytable.id = another_table.matching_id
WHERE condition(s)
ORDER BY column1, … ASC/DESC
LIMIT num_limit OFFSET num_offset;
CASE WHEN … then … else … end
SELECT role,
case when building is not null
THEN "1" else "0" end
as Wheater,
count(name)
FROM employees
WHERE 1
GROUP BY role,Wheater;
NVL:空值转换
实现空值的转换。NVL(表达式A,表达式B)
如果表达式A为空值,NVL返回值为表达式B的值,否则返回表达式A的值。
DECODE:判断翻译 If / case when
【1】
sql 中 decode(…)函数的用法 —— 相当于 if 语句
将查询结果翻译成其他值(即以其他形式表现出来)。
Select decode(columnname,值1,翻译值1,值2,翻译值2,…值n,翻译值n,缺省值)
DECODE(value,if1,then1,if2,then2,if3,then3,…,else)
含义为
IF 条件=值1 THEN
RETURN(value 1)
ELSIF 条件=值2 THEN
RETURN(value 2)
…
ELSIF 条件=值n THEN
RETURN(value 3)
ELSE
RETURN(default)
END IF
## decode函数比较1个参数时:
SELECT ID,
DECODE(inParam,'byComparedParam','值1' ,'值2') name
FROM test_table;
#如果第一个参数 inParam == 'byComparedParam',
#则 select 得到的 name 显示为值1,
#如果第一个参数 inParam != 'byComparedParam',
#则 select 得到的 name 显示为值2
REPLACE:字符串替换
【1】
1、直接替换字符串中的部分字符:
select REPLACE('abcdefghabc','abc','xxx')
输入的字符串为:abcdefghabc
结果为:xxxdefghxxx
2、替换一个字段中所有的部分字符:
select city_name,REPLACE(city_name,'市','') as city from tmp_city
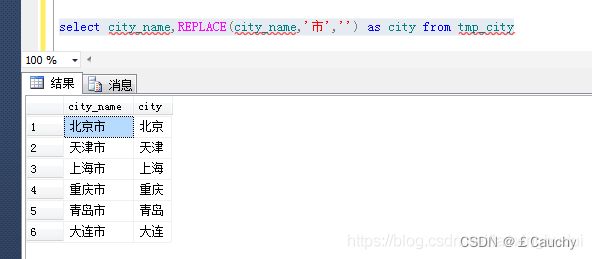
SUBSTR:字符串截取
【1】
SUBSTR(str,pos,len): 从pos开始的位置,截取len个字符
SUBSTR(str,pos): pos开始的位置,一直截取到最后。
pos要抽取的子串的起始下标,如果是负数,-1 指字符串中最后一个字符,-2 指倒数第二个字符,以此类推。
CAST:数据类型的显式转换
【1】CAST函数用于将某种数据类型的表达式显式转换为另一种数据类型。CAST()函数的参数是一个表达式,它包括用AS关键字分隔的源值和目标数据类型。
函数参数::CAST (expression AS data_type)
参数意义:expression:任何有效的SQLServer表达式。AS:用于分隔两个参数,在AS之前的是要处理的数据,在AS之后是要转换的数据类型。data_type:目标系统所提供的数据类型,包括bigint和sql_variant,不能使用用户定义的数据类型。
LPAD、RPAD:填充某个字段的查询结果
【1】,【2】
函数参数:lpad(string1, padded_length, [pad_string])和rpad(string1, padded_length, [pad_string])
参数意义: string1表示源字符串,padding_length表示最后字符串的长度,[pad_string]表示填充的内容
连接
cross join 交叉连接
A cross join B A中每一行都与B中每一行进行连接
当left join 后不加on时,也能同样起到交叉连接的效果
select title, maxt.max_s-(Domestic_sales+International_sales)
from(SELECT *
FROM Movies m
left join Boxoffice b on m.Id = b.Movie_id)as mb
cross join
(SELECT Domestic_sales+International_sales as max_s
FROM Movies m
left join Boxoffice b on m.Id = b.Movie_id
order by Domestic_sales+International_sales DESC
limit 1)as maxt
select title, max1-each1
from(SELECT title, Domestic_sales+International_sales as each1
FROM Movies m
left join Boxoffice b on m.Id = b.Movie_id) as mb
cross join
(SELECT max(b.domestic_sales+b.international_sales)as max1
FROM movies m
left join boxoffice b ON m.id = b.movie_id)as maxt
区别
【DISTINCT】 - 【GROUP BY】
【HAVING】 - 【WHERE】
HAVING 和 WHERE 语法一样,只不过作用的结果集不一样. 在我们例子数据表数据量小的情况下可能感觉 HAVING没有什么用,但当你的数据量成千上万属性又很多时也许能帮上大忙 .
【JOIN】 - 【UNION】
【TRUNCATE】 - 【DELETE】
truncate等价于不带where的delete,删除所有表数据,速度比较快。Delete可以触发器(Trigger)并可以回滚(rollback),truncate则不可以。
其他
关于NULLs
- 查找空元素:
where column1 IS NULL - 查找非空元素:
where column1 IS NOT NULL或者where column1
错题集
- 排序忘记指定 升序 / 降序
概念
事务 & 锁 & 隔离级别
事务是数据库管理系统(DBMS)执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。
事务包含四大特性,即ACID。
- A:Atomicity 原子性。事务代码块是一个整体,要么都执行成功提交,要么全部失败回滚。
C:Consistency 一致性。数据库开始的全部状态与事务执行之后的状态保持一致。
I:Isolation 隔离性。一事务与二事务互不影响。
D:Durability 持久性。事务的操作数据库造成持久化的影响。
Mysql隔离级别有以下四种(级别由低到高):
| 隔离级别 | 效果 |
|---|---|
| 读未提交(RU) | 一个事务还没提交时,它做的变更就能被别的事务看到。(别的事务指同一时间进行的增删改查操作) |
| 读已提交(RC) | 一个事务提交(commit)之后,它做的变更才会被其他事务看到。 |
| 可重复读(RR) | 一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的。 |
| 串行化(S) | 正如物理书上写的,串行是单线路,顾名思义在MySQL中同一时刻只允许单个事务执行,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。 |

- 脏写(Dirty Write) 脏写是指一个事务修改了其它事务未提交的数据。
- 脏读(Dirty Read) 脏读是指一个事务读到了其它事务未提交的数据。
- 不可重复读(Non-Repeatable Read) 不可重复读指的是在一个事务执行过程中,读取到其它事务已提交的数据,导致两次读取的结果不一致。
- 幻读(Phantom) 幻读是指的是在一个事务执行过程中,读取到了其他事务新插入数据,导致两次读取的结果不一致。
事务并发访问同一数据资源的情况主要就分为读-读、写-写和读-写三种。
- 读-读 即并发事务同时访问同一行数据记录。由于两个事务都进行只读操作,不会对记录造成任何影响,因此并发读完全允许。
- 写-写 即并发事务同时修改同一行数据记录。这种情况下可能导致脏写问题,这是任何情况下都不允许发生的,因此只能通过加锁实现,也就是当一个事务需要对某行记录进行修改时,首先会先给这条记录加锁,如果加锁成功则继续执行,否则就排队等待,事务执行完成或回滚会自动释放锁。
- 读-写 即一个事务进行读取操作,另一个进行写入操作。这种情况下可能会产生脏读、不可重复读、幻读。最好的方案是读操作利用多版本并发控制(MVCC),写操作进行加锁。
锁的粒度
按锁作用的数据范围进行分类的话,锁可以分为行级锁和表级锁。
- 行级锁:作用在数据行上,锁的粒度比较小。
- 表级锁:作用在整张数据表上,锁的粒度比较大。
锁的分类
为了实现读-读之间不受影响,并且写-写、读-写之间能够相互阻塞,Mysql使用了读写锁的思路进行实现,具体来说就是分为了共享锁和排它锁:
- 共享锁(Shared Locks):简称S锁,在事务要读取一条记录时,需要先获取该记录的S锁。S锁可以在同一时刻被多个事务同时持有。我们可以用select … lock in share mode;的方式手工加上一把S锁。
- 排他锁(Exclusive Locks):简称X锁,在事务要改动一条记录时,需要先获取该记录的X锁。X锁在同一时刻最多只能被一个事务持有。X锁的加锁方式有两种,第一种是自动加锁,在对数据进行增删改的时候,都会默认加上一个X锁。还有一种是手工加锁,我们用一个FOR UPDATE给一行数据加上一个X锁。
还需要注意的一点是,如果一个事务已经持有了某行记录的S锁,另一个事务是无法为这行记录加上X锁的,反之亦然。
除了共享锁(Shared Locks)和排他锁(Exclusive Locks),Mysql还有意向锁(Intention Locks)。意向锁是由数据库自己维护的,一般来说,当我们给一行数据加上共享锁之前,数据库会自动在这张表上面加一个意向共享锁(IS锁);当我们给一行数据加上排他锁之前,数据库会自动在这张表上面加一个意向排他锁(IX锁)。意向锁可以认为是S锁和X锁在数据表上的标识,通过意向锁可以快速判断表中是否有记录被上锁,从而避免通过遍历的方式来查看表中有没有记录被上锁,提升加锁效率。例如,我们要加表级别的X锁,这时候数据表里面如果存在行级别的X锁或者S锁的,加锁就会失败,此时直接根据意向锁就能知道这张表是否有行级别的X锁或者S锁。
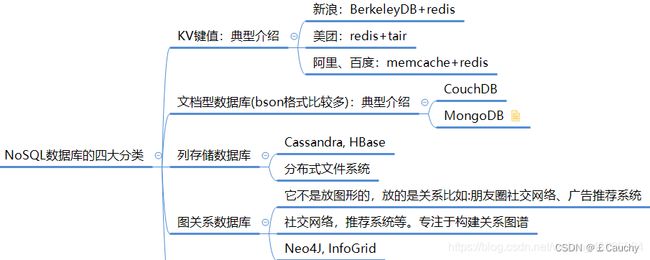
关系型 & 非关系型 数据库
Q:区别?
A:
| 关系型 | 非关系型 | |
|---|---|---|
| 举例 | Mysql、Oracle 数据库 (甲骨文) Sql Server、Access 数据库 (微软) DB2数据库 (IBM) OceanBase数据库(阿里巴巴) |
键值存储数据库:Redis、Memcached 文档存储数据库:MongoDB、CouchDB 列存储数据库:HBase 图数据库:Neo4j |
| 特性 | 1、采用了关系模型来组织数据; 2、最大特点是事务的一致性; 3、简单来说,关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。 |
1、使用键值对存储数据; 2、分布式; 3、一般不支持ACID特性; 4、非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合。 |
| 优点 | 1、容易理解:二维表结构是非常贴近逻辑世界一个概念,关系模型相对网状、层次等其他模型来说更容易理解; 2、使用方便:通用的SQL语言使得操作关系型数据库非常方便; 3、易于维护:丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大减低了数据冗余和数据不一致的概率; 4、支持SQL,可用于复杂的查询。 |
1、无需经过sql层的解析,读写性能很高; 2、基于键值对,数据没有耦合性,容易扩展; 3、存储数据的格式:nosql的存储格式是key - value形式、文档形式、图片形式等等,文档形式、图片形式等等,而关系型数据库则只支持基础类型。 |
| 缺点 | 1、为了维护一致性所付出的巨大代价就是其读写性能比较差; 2、固定的表结构; 3、高并发读写需求; 4、海量数据的高效率读写; |
1、不提供sql支持,学习和使用成本较高; 2、无事务处理,附加功能bi和报表等支持也不好; |
| 应用 | 适合存储结构化数据,比如:用户的账号、地址: (1)这些数据通常需要做结构化查询,比如说Join,这个时候,关系型数据库就要胜出一筹。 (2)这些数据的规模、增长的速度通常是可以预期的。 (3)事务性、一致性,适合存储比较复杂的数据。 |
适合存储非结构化数据,比如:文章、评论: (1)这些数据通常用于模糊处理,例如全文搜索、机器学习,适合存储较为简单的数据。 (2)这些数据是海量的,并且增长的速度是难以预期的。 (3)按照key获取数据效率很高,但是对于join或其他结构化查询的支持就比较差。 |
触发器(事前触发 / 事后触发、语句级触发 / 行级触发)
触发器是一种特殊类型的存储过程,它由事件触发,而不是程序调用或手工启动。使用触发器可以用来保证数据的有效性和完整性。
事前触发发生在事件发生之前,用于验证一些条件或进行一些准备工作;事后触发发生在事件发生之后,做收尾工作。事前触发可以获得之前和新的字段值,而事后触发可以保证事务的完整性。
语句级触发可以在语句执行之前或之后执行,而行级触发在触发器所影响的每一行触发一次。
分库 & 分表
【1】 分库分表面试题及答案
存储引擎 innob myisam
数据库中的数据量不一定是可控的,在未进行分库分表的情况下,随着时间和业务的发展,库中的表会越来越多,表中的数据量也会越来越大,相应地,数据操作,增删改查的开销也会越来越大;另外,由于无法进行分布式式部署,而一台服务器的资源(CPU、磁盘、内存、IO等)是有限的。
分表是啥意思?就是把一个表的数据放到多个表中,然后查询的时候你就查一个表。比如按照用户 id 来分表,将一个用户的数据就放在一个表中。然后操作的时候你对一个用户就操作那个表就好了。
分库是啥意思?就是你一个库一般我们经验而言,最多支撑到并发 2000,一定要扩容了,而且一个健康的单库并发值你最好保持在每秒 1000 左右,不要太大。那么你可以将一个库的数据拆分到多个库中,访问的时候就访问一个库好了
两种分库分表的方式:
(1)按照 range 来分,就是每个库一段连续的数据,这个一般是按比如时间范围来的,但是这种一般较少用,因为很容易产生热点问题,大量的流量都打在最新的数据上了。
(2)按照某个字段 hash 一下均匀分散,这个较为常用。
范式
- 第一范式: 列不可再分
- 第二范式: 行可以唯一区分,主键约束
- 第三范式: 表的非主属性不能依赖其他表的非主属性外键约束
Redis
- 5种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及 zset (sorted set:有序集合)
- 3种集群方式:主从复制,哨兵模式、集群
- 【1】 十分钟彻底掌握缓存击穿、缓存穿透、缓存雪崩
缓存雪崩
缓存击穿
缓存穿透
Spark
Map操作
在Spark中,map操作是一种数据转换函数,它将一个RDD(弹性分布式数据集)中的每个元素应用到一个给定的函数上,返回一个新的RDD。通俗的说,可以把map操作看作是对RDD中的每个元素都执行同样的操作,这个操作是由用户自定义的函数来完成的。
举个例子,假设有一个包含数字的RDD,现在我们想要将每个数字都平方,并得到一个新的RDD。那么我们就可以使用map操作来实现:
# 创建一个原始的RDD
data = [1, 2, 3, 4, 5]
rdd = sc.parallelize(data)
# 使用map操作将每个数字都平方
squared_rdd = rdd.map(lambda x: x ** 2)
# 打印新的RDD中的元素
print(squared_rdd.collect())
输出结果为:[1, 4, 9, 16, 25],表示每个数字都被平方了。
在这个例子中,我们使用了Python中的lambda函数来定义每个数字如何被平方。当调用map()方法时,Spark会将这个函数应用到RDD的每个元素上,最后返回一个新的RDD。这个新的RDD中每个元素都是原始RDD中的元素经过用户自定义函数计算后得到的结果。
RDD
RDD (Resilient Distributed Dataset, 弹性分布式数据集) 是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
- 它是一组分区,分区是spark中数据集的最小单位。也就是说spark当中数据是以分区为单位存储的,不同的分区被存储在不同的节点上。这也是分布式计算的基础。
- 一个应用在各个分区上的计算任务。在spark当中数据和执行的操作是分开的,并且spark基于懒计算的机制,也就是在真正触发计算的行动操作出现之前,spark会存储起来对哪些数据执行哪些计算。数据和计算之间的映射关系就存储在RDD中。
- RDD之间的依赖关系,RDD之间存在转化关系,一个RDD可以通过转化操作转化成其他RDD,这些转化操作都会被记录下来。当部分数据丢失的时候,spark可以通过记录的依赖关系重新计算丢失部分的数据,而不是重新计算所有数据。
- 一个分区的方法,也就是计算分区的函数。spark当中支持基于hash的hash分区方法和基于范围的range分区方法。
- 一个列表,存储的是存储每个分区的优先存储的位置。
通过以上五点,我们可以看出spark一个重要的理念。即移动数据不如移动计算,也就是说在spark运行调度的时候,会倾向于将计算分发到节点,而不是将节点的数据搜集起来计算。RDD正是基于这一理念而生的,它做的也正是这样的事情
- Narrow / Wide Transformations 指的是一种对RDD进行转换的方法。
Narrow Transformations只涉及到一个父RDD和一个子RDD之间的转换,可以处理相对较小的数据集。
Wide Transformations 则通常涉及多个父RDD的操作,在处理大数据集时更有价值。 - Narrow Transformations比Wide Transformations更高效,并且在处理较小数据集时具有优势。因为 使用Narrow Transformations时,子RDD只需要从其父RDD获取数据即可完成计算,因此不需要重新分区或混洗数据。
- 以下是几种常用的Narrow Transformations:
map(): 对每个元素应用函数并返回新的RDD
filter(): 返回一个只包含通过条件测试的元素的RDD
union(): 将两个RDD组合成一个RDD
intersection(): 返回同时存在于两个RDD中的元素的RDD
distinct(): 返回一个仅包含不同元素的新RDD
groupByKey(): 将具有相同键的元素分组到一起
reduceByKey(): 根据键将每个值减少到单个值
存储过程
Oracle存储过程包含三部分:过程声明,执行过程部分,存储过程异常
面试题目
SQL
【Q】:E-R图三要素?
【A】:实体(表),属性(表中的字段),联系(表与表之间的关系)
【Q】:企业里面的数据库设计一般需要满足哪一范式?
【A】:第一范式 —— 列不可再分
Q1:SQL的执行顺序
【1】 一文讲懂SQL语法顺序与执行顺序
书写顺序:SELECT (distinct) -> FROM -> JOIN -> ON -> WHERE -> GROUP BY -> HAVING -> UNION -> ORDER BY ->LIMIT
执行顺序:FROM -> ON -> JOIN -> WHERE -> GROUP BY -> HAVING -> SELECT(distinct) -> UNION -> ORDER BY ->LIMIT
Q2:数据库的索引类型,使用索引存在的缺点
- 单列索引 / 组合索引 普通索引:仅加速查询 唯一索引:加速查询 + 列值唯一(可以有null) 主键索引:加速查询 + 列值唯一(不可以有null)+ 表中只有一个组合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并
全文索引:对文本的内容进行分词,进行搜索- Mysql 索引类型:FULLTEXT,HASH,BTREE,RTREE
- 索引的优点:提高查询速度
- 索引的缺点:降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。建立索引会占用磁盘空间的索引文件。
Q3:左连接、内连接

Q4:窗口函数 求连续三天登录
- 窗口函数,也叫OLAP函数(Online Anallytical Processing,联机分析处理),可以对数据库数据进行实时分析处理。
- 1) 专用窗口函数,包括后面要讲到的rank, dense_rank, row_number等专用窗口函数。
2) 聚合函数,如sum. avg, count, max, min等- 窗口函数有以下功能:
1)同时具有分组和排序的功能
2)不减少原表的行数
Q5:MySQL & Oracle 的区别
A5:详见【1】 【2】。两者都是关系型数据库,mysql开源免费的,而oracle则是收费的,并且价格非常高。mysql属于轻量型数据库;oracle属于重量型数据库。
- 管理机制不同 —— Oracle通过表空间来管理磁盘空间的分配和释放,而MySQL则使用文件系统管理数据库中的对象数据,它们有不同的机制来处理磁盘空间的分配问题。与Oracle相比,MySQL没有表空间,角色管理,快照,同义词和包以及自动存储管理。
- 库函数不同 —— 数学函数(Oracle则有专门提供针对分数和小数运算的函数)、字符串函数(MySQL还具有一些其他的高级字符串函数,如FIELD、REPLACE、SUBSTRING_INDEX)、时间和日期函数(Oracle可能具有更强大和灵活的日期功能,比如时区转换)、其他:MySQL有几个非常特殊且是该数据库所独有的函数,例如SLEEP函数(在指定的秒数后停止执行)和UUID函数(生成唯一性标识符)。Oracle则有更高级的分析函数和带有设备输入输出等 I / O 操作的特殊处理函数。
- SQL语句不同 —— 字符串连接(MySQL使用“CONCAT”函数;Oracle使用横杠 || 操作符)、子查询(MySQL中,一个SELECT语句可以用于子查询;Oracle允许包含多个SELECT语句的子查询。)
- 分页查询不同 —— MySQL是直接在SQL语句中写"select… from …where…limit x, y",有limit就可以实现分页;Oracle则是需要用到伪列ROWNUM和嵌套查询
Q6:sql 行列转换
法一:case…when
法二:pivot函数


# 行转列 (pivot),列转行 (Unpivot)
SELECT *
FROM EvaluationTable
PIVOT (SUM(Score)
FOR Attribute IN ([Attrib A], [Attrib B], [Attrib C])
) AS PivotTable;
Q7:sql 两个表 产品表和收益表,输出总收益最大的产品id
Q8:MySQL 中NULL和空值的区别
空值(’’)的长度是0,不占空间;而的NULL长度是NULL,是占用空间的。Link
Q9:某属性的值唯一的方法?
设置主键;
unique约束;
unique索引;
设置外键。
Q10:
Q11:SQL题(讲思路即可):数据表重构,举了银行每个月的贷款表的例子,然后重构成13列,银行名称加上1-12个月贷款值的列,类似1179. 重新格式化部门表(用case when巴拉巴拉)
Q12:Distinct和Group by的区别?
Q13:从数据库中随机选择100条记录?
select * from (select * from example order by dbms_random.random) where rownum <= 100;
Select * From TABLE Order By Rand() Limit 100
Select top 100 * from table order by newid() # 提高效率
大数据
spark任务提交流程
hive数据倾斜怎么解决
综合 / 笔试
【1】 平安银行校招 - 笔试真题及答案解析
【2】 还是银行面试舒服些…
其他
【1】NL2SQL:将人类的自然语言问句转化为结构化查询语句