【seaweedfs】3、f4: Facebook’s Warm BLOB Storage System 分布式对象存储的冷热数据

论文地址
Facebook的照片、视频和其他需要可靠存储和快速访问的二进制大型对象(BLOB)的语料库非常庞大,而且还在继续增长。随着BLOB占用空间的增加,将它们存储在我们传统的存储系统-- Haystack 中变得越来越低效。为了提高我们的存储效率(以Blob的有效复制系数衡量),我们检查了Blob的底层访问模式,并确定了包括频繁访问的热Blob和访问频率低得多的热Blob的温度区域。我们的整体BLOB存储系统旨在隔离暖BLOB,并使我们能够使用专门的温BLOB存储系统f4。F4是一种新系统,它降低了warm的有效复制因子,同时保持了容错并能够支持较低的吞吐量需求。
F4目前存储超过65PB的逻辑Blob,并将其有效复制系数从3.6降至2.8或2.1。F4提供低延迟;对磁盘、主机、机架和数据中心故障具有恢复能力;并为热BLOB提供足够的吞吐量。
一、Introduction
随着Facebook的发展,每个用户共享的数据量也在增长,有效地存储数据变得越来越重要。Facebook存储的一类重要数据是二进制大对象(BLOB),它们是不可变的二进制数据。Blob只创建一次,读取多次,从不修改,有时还会被删除。Facebook的BLOB类型包括照片、视频、文档、跟踪、堆转储和源代码。BLOB的存储占用空间很大。截至2014年2月,Facebook存储了超过4000亿张照片。
Facebook最初的BLOB存储系统Hystack[5]已经投入生产超过7年,专为IO绑定的工作负载而设计。它将读取BLOB的磁盘寻道次数减少到几乎总是一次和三次复制数据,以实现容错和支持高请求率。然而,随着Facebook的发展壮大,BLOB存储工作负载也发生了变化。存储的Blob的类型有所增加。在大小和创建、读取和删除速率方面的多样性增加了。而且,最重要的是,现在有大量且不断增加的低请求率BLOB。对于这些BLOB,从吞吐量的角度来看,三重复制会导致过度调配。然而,三重复制也提供了重要的容错保证。
我们较新的f4 BLOB存储系统提供了与HayStack相同的容错保证,但有效复制系数更低。F4简单、模块化、可扩展和容错;它处理我们存储的Blob的请求率;它以足够低的延迟响应请求;它可以容忍磁盘、主机、机架和数据中心故障;它以较低的有效复制系数提供所有这些功能。
我们将f4描述为 warm blob storage,因为对其内容的请求率低于对HayStack中的内容的请求率,因此不是那么“热”。热存储系统也与冷存储系统形成对比,冷存储系统可靠地存储数据,但可能需要几天或几个小时来检索数据,这对于面向用户的请求来说是不可接受的长。我们还使用温度来描述blob,其中热blob接收许多请求,而暖blob接收很少的请求
正如我们将演示的那样,一个blob的年龄和它的温度之间有很强的相关性。请求新创建的BLOB的速度比请求较旧BLOB的速度高得多。例如,对于九种检查类型中的八种,对一周前的Blob的请求率比对不到一天的旧内容的请求率低一个数量级。此外,年龄和缺失率之间存在很强的相关性。我们使用这些发现来指导我们的设计:温暖blob的较低请求率使我们能够为f4调配比干草堆栈更低的最大吞吐量,并且温暖blob的低删除率使我们能够通过不需要在删除后快速物理回收空间来简化f4。我们还利用我们的发现,通过年龄和温度之间的相关性来识别温暖的成分。
Facebook的整体BLOB存储架构旨在实现热存储。它包括一个缓存堆栈,它显著减少了存储系统的负载,并使它们能够针对更少的每个BLOB请求进行配置;一个转换器层,它处理计算密集型BLOB转换,并且可以独立于存储进行扩展;一个路由器层,它抽象底层存储系统并实现它们之间的无缝迁移;以及热存储系统HayStack,它将新创建的BLOB聚合到卷中并存储它们,直到它们的请求和删除率冷却到足以迁移到f4为止。
f4 stores volumes of warm BLOBs in cells that use distributed erasure coding,这种编码比三次复制使用更少的物理字节。它使用Reed-Solomon(10,4)[46]编码,并在不同的机架上布置块,以确保在单个数据中心内对磁盘、机器和机架故障的恢复能力。IS在广域中使用XOR编码,以确保对数据中心故障的恢复能力。F4已经在Facebook投入生产超过19个月了。F4目前存储超过65PB的逻辑数据,节省超过53PB的存储。
我们在这篇论文中的贡献包括:
- 一个关于 warm storage 的案例,它为未来对它的研究提供了信息,并证明了我们的努力。
- 我们支持 warm storage 的整体 BLOB 存储体系结构的设计。
- f4的设计,这是一款简单、高效且容错的热存储解决方案,可将我们的 effectivereplication-factor(有效复制因子)从3.6降至2.8,然后降至2.1。
- 对f4进行产量评估。
本文在第二节继续介绍背景知识,第三节介绍 warm storage 的案例。第4节介绍了支持热存储的整体BLOB存储体系结构的设计。第5节介绍了F4。第6节介绍了对F4的成果评估,第7节介绍了所学到的经验教训,第8节介绍了相关工作,第9节结束了。
二、Background
本节解释 BLOB 存储在Facebook的完整架构中的位置。它还描述了我们存储的不同类型的blob及其大小分布。
2.1 Where BLOB Storage Fits
图1显示了BLOB存储如何适应Facebook的整体架构。
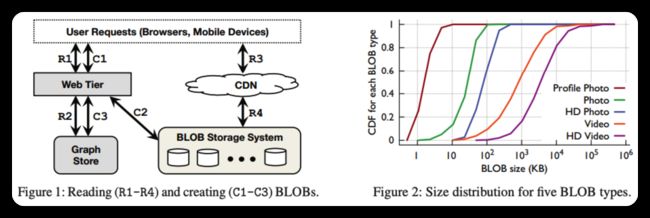
Blob Create–例如,视频上传–起源于网络层(C1)。Web层将数据写入BLOB存储系统(C2),然后将该数据的句柄存储到我们的图形存储(C3)中,即TAO[9]。该句柄可用于检索或删除blob。TAO将句柄与图形的其他元素相关联,例如,视频的所有者。
BLOB读取–例如观看视频–也源自Web层(R1)。Web层访问Graph Store(R2)以查找必要的句柄,并构造可用于获取BLOB的URL。当浏览器稍后发送对BLOB(R3)的请求时,该请求首先去往高速缓存通常访问的BLOB的内容分发网络(CDN)[2,34]。如果CDN没有所请求的blob,则它向blob存储系统发送请求(R4),高速缓存该blob,并将其返回给用户。CDN保护存储系统不受对频繁访问数据的大量请求的影响,我们将在4.1节回到它的重要性。
2.2 BLOBs Explained
BLOB是不变的二进制数据。它们只创建一次,可能会多次读取,并且只能删除,不能修改。这涵盖了Facebook的许多类型的内容。大多数BLOB类型都是面向用户的,例如照片、视频和文档。其他BLOB类型是内部的,如跟踪、堆转储和源代码。面向用户的BLOB更加流行,因此我们在本文的其余部分将重点放在它们上,并将其简称为BLOB。
图2显示了五种类型blob的大小分布。blob的大小有很大的多样性,这对我们的设计有影响,如第5.6节中所讨论的那样。
三、The Case for Warm Storage
这一部分旨在鼓励在Facebook创建一个温暖的存储系统。它证明了 tempeature zone 的存在,age is a good proxy for temperature, and that warm content is large and growing.
3.1 方法
本节提供的数据来自两周的跟踪、现有系统的基准和汇总统计数据的每日快照。跟踪包括随机的0.1%的读取、10%的创建和10%的删除。
提供了九种面向用户的BLOB类型的数据。由于日志信息不完整,我们从一些分析中排除了一些数据类型。
这九种斑点类型包括个人资料照片、照片、高清照片、移动同步照片[17]、高清移动同步照片、群组附件[16]、视频、高清视频和消息(聊天)附件。组附件和邮件附件对于我们的存储系统来说是不透明的BLOB,它们可以是文本、pdf、演示文稿等。
3.2 Temperature Zones Exist
为了说明热存储的情况,我们首先说明存在温度区域,即内容一开始是热的,接收了许多请求,然后随着时间的推移冷却,接收的请求越来越少。
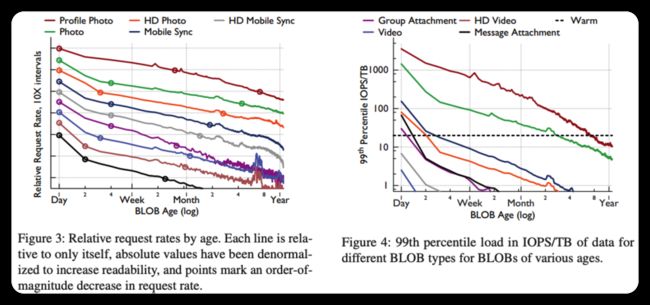
图3显示了给定年龄的内容的相对请求率,即每对象每小时请求数。两周的0.1%阅读量的跟踪被用来创建这个数字。每个正在读取的对象的年龄都会被记录下来,并以1天为间隔进行存储。然后,我们计算跟踪中每个小时对每日存储桶的请求数,并报告平均值–中位数相似,但噪音更大。绝对值被反规格化以增加可读性,因此每一行都只与其自身相关。分数标志着数量级的下降。
随着时间的推移,申请率不断下降的趋势清楚地表明了温区的存在。对于所有九种类型的内容,不到一天的内容收到的请求率是一年前内容的100多倍。其中八种类型的请求率在不到一周的时间内下降了一个数量级,六种类型的请求率在不到60天的时间内下降了100倍。
3.3 Differentiating Temperature Zones
考虑到温度区域的存在,接下来要回答的问题是如何区分热内容和热内容,以及何时将内容移动到热存储是安全的。
我们定义温暖的温度区域,包括不变的内容和低请求率。Blob不会修改,因此唯一的更改是删除。因此,区分热内容和热内容取决于请求率和删除率。
首先,我们检查请求率。为了确定热存储和热存储之间的界限,我们考虑了接近最坏情况的请求率,因为我们的内部服务级别对象在一天中最繁忙的时段需要较低的接近最坏情况的延迟。
在我们一天中最忙的时候。图4显示了按年龄分组的各种类型BLOB的第99个百分位数或接近最差情况的请求负载。两周的0.1%阅读量的跟踪被用来创建这个数字。记录读取的每个对象的时间,并将这些时间间隔存储到与创建该BLOB类型的1TB所需的时间相等的间隔中。例如,如果每3600秒创建一种类型的1TB,则第一个存储桶用于0-3599秒的年龄,第二个存储桶用于3600-7200秒的时间,依此类推。1然后,我们通过查看1000秒的窗口来补偿0.1%的采样率。我们报告这些窗口的第99个百分位数请求率,即,我们报告每个年龄段的两周跟踪中1000秒窗口内的第99个请求百分位计数。F4中使用的4TB磁盘最多可提供每秒80次输入/输出操作(IOPS),同时将每次请求的延迟保持在可接受的低水平。该图显示了20 IOPS/TB的最高热存储吞吐量。
对于九种类型中的七种,在不到一周的时间内,接近最差情况的吞吐量将低于热存储系统的容量。对于照片,需要大约3个月的时间才能达到热存储容量,而对于个人资料照片,需要一年的时间。
我们还检查了斑点类型随时间的删失率,但没有严格量化。总体趋势是,大多数删除是针对年轻斑点的,并且一旦对斑点的请求率降至热存储阈值以下,删除率也很低。
将删除分析与请求率分析相结合,将一个月作为除两个斑点类型之外的所有斑点类型的热内容和热内容之间的安全分隔符。其中一种类型是个人资料照片,不会被移到热存储中。另一种是Photos,它使用三个月的门槛。
3.4 Warm Content is Large and Growing
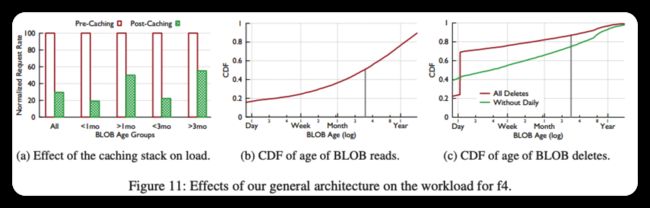
我们通过展示温暖内容的百分比很大并且持续增长来结束对热存储的讨论。图5给出了六种BLOB类型在三个月间隔内为热的内容的百分比。
我们使用上述分析来确定每种类型的温暖截止时间,即大多数类型的温暖截止时间为一个月。此图报告了从9-6个月前、6-3个月前和3个月前到现在的三个月间隔内每种类型的热内容的中位数百分比。
该图显示,热内容在所有对象中占很大比例:在最早的时间间隔中,超过80%的对象对于所有类型都是热的。它还表明,热的比例正在增加:在最近的时间间隔内,超过89%的物体对所有类型都是热的。
这一部分显示了温度区域的存在,大多数类型在一个月内就可以安全地划分Facebook现有类型的热内容和暖内容之间的分界线,并且暖内容在整个BLOB内容中所占的比例很大,而且比例还在不断增长。接下来,我们将描述Facebook的整体BLOB存储架构如何实现热存储。
四、BLOB Storage Design
我们的BLOB存储设计遵循的原则是保持组件简单、集中且与其工作很好地匹配。在本部分中,我们将介绍卷,描述我们的BLOB存储系统的完整设计,并说明它如何使用f4实现集中且简单的热存储。
4.0 Volumes
我们将BLOB聚合在一起形成逻辑卷。卷聚合文件系统元数据,使我们的存储系统几乎不会浪费IOPS,正如我们在下面进一步讨论的那样。我们将逻辑卷分为两类。卷最初是解锁的,并支持读取、创建(附加)和删除。一旦卷已满,大小约为100 GB,它们将转换为锁定状态,不再允许创建。锁定的卷仅允许读取和删除。
每个卷由三个文件组成:数据文件、索引文件和日志文件。数据文件和索引文件与《干草堆》的出版版本相同[5],而日记文件则是新的。数据文件保存每个BLOB以及相关的元数据,如键、大小和校验和。索引文件是存储机的内存中查找结构的快照。它的主要目的是允许重新启动的机器快速重建其内存中的索引。日志文件跟踪已删除的BLOB;而在HayStack的原始版本中,删除是通过直接更新数据和索引文件来处理的。对于锁定的卷,数据和索引文件为只读,而日志文件为读写。对于解锁的卷,所有三个文件都是可读写的。
4.1 Overall Storage System
完整的BLOB存储体系结构如图6所示。创建在路由器层(C1)进入系统,并被定向到热存储系统(C2)中的适当主机。删除操作在路由器层(D1)进入系统,并定向到相应存储系统(D2)中的相应主机。读取在缓存堆栈(R1)进入系统,如果在那里不满足要求,则遍历转换器层(R2)到路由器层(R3),路由器层将它们定向到适当存储系统(R4)中的适当主机。
4.1.1 Controller
Controller 确保整个系统的平稳运行。它有助于配置新的存储计算机、维护解锁的卷池、确保所有逻辑卷都有足够的物理卷支持它们、在必要时创建新的物理卷以及执行定期维护任务,如压缩和垃圾收集。
4.1.2 Router
Router Tier(路由层)是BLOB存储的接口;它隐藏了存储的实施,并允许添加新的子系统,如f4。它的客户端、Web层或缓存堆栈将逻辑Blob上的操作发送给它。
路由器层机器是相同的,它们执行相同的逻辑,并且都具有逻辑卷到物理卷映射的软状态副本,该副本规范地存储在单独的数据库中。路由器层通过添加更多机器进行扩展,其大小独立于整个系统的其他部分。
- 对于读取,路由器从BLOB ID中提取逻辑卷ID,并找到该卷的物理映射。它从可用物理卷中选择一个–通常是最近计算机上的卷–并向其发送请求。如果出现故障,则会触发超时,并将请求定向到下一个物理卷。
- 对于创建,路由器选择具有可用空间的逻辑卷,并将BLOB发送到该逻辑卷的所有物理卷。如果出现任何错误,任何部分写入的数据都将被忽略,以便稍后进行垃圾收集,并选择一个新的逻辑卷进行创建。
- 对于删除,路由器向Blob的所有物理副本发出删除命令。响应被异步处理,并且不断地重试删除,直到在失败的情况下完全删除BLOB。
路由器层通过对其客户端隐藏存储实施来实现热存储。当卷从热存储系统迁移到热存储系统时,它临时驻留在两者中,同时更新规范映射,然后将客户端操作透明地定向到新存储系统。
4.1.3 Transformer
Transformer Tier(转换器层)处理检索到的BLOB上的一组转换。例如,这些转换包括调整照片大小和裁剪照片。在Facebook的旧系统中,这些计算密集型转换是在存储机器上执行的。
通过将存储系统释放出来,使存储系统只专注于提供存储,转换器层实现了热存储。将计算划分到自己的层允许我们独立地横向扩展存储层和转换器层。反过来,这使我们能够将存储层的大小精确地匹配到我们的需求。此外,它使我们能够为这些任务中的每一项选择更优化的硬件。特别是,存储节点可以设计为只使用单个CPU和相对较少的RAM来容纳大量磁盘。
4.1.4 Caching Stack
高速缓存堆栈,BLOB读取最初被定向到高速缓存堆栈[2,34],并且如果BLOB驻留在高速缓存之一中,则直接返回该BLOB,从而避免在存储系统中读取。这会吸收常用Blob的读取,并降低存储系统的请求率。缓存堆栈通过降低其请求速率来实现热存储。
4.1.5 Hot Storage with Haystack
Facebook的热存储系统HayStack设计为仅使用充分利用的IOPS。它通过处理所有BLOB创建、处理大多数删除以及处理更高的读取率来实现热存储。Haystack is designed to fully utilize disk IOPS by:
- Grouping Blobs:它只创建少量(~100)文件,其中BLOB按顺序排列在这些文件中。结果是一个简单的BLOB存储系统,它使用少量文件,并绕过底层文件系统进行大多数元数据访问。
- 紧凑型元数据管理:它标识定位每个BLOB所需的最小元数据集,并仔细布局这些元数据,使其适合机器上的可用内存。这允许系统将极少的IOPS浪费在元数据获取上。
BLOB分组到逻辑卷中。为了实现容错和性能,每个逻辑卷映射到不同地理区域的不同主机上的多个物理卷或副本:逻辑卷的所有物理卷存储相同的BLOB集。每个物理卷完全驻留在一个 Haystack 主机上。每个逻辑卷通常有3个物理卷。每个卷最多可容纳数百万个不变的Blob,大小可增加到约100 GB。
当主机接收到读操作时,它会在内存哈希表中查找相关的元数据–数据文件中的偏移量、数据记录的大小以及它是否已被删除。然后,它对数据文件执行单个I/O请求以读取整个数据记录。
当主机收到CREATE时,它会同步地将一条记录附加到其物理卷中,更新内存中的哈希表,并同步更新索引和日志文件。
当主机收到删除操作时,它会更新内存中的哈希表和日志文件。BLOB的内容仍然存在于数据文件中。我们定期压缩卷,这会完全删除BLOB并回收其空间。
4.1.6 Fault tolenrance
Hystack通过数据文件和硬件RAID-6(1.2倍复制)的三重复制,对磁盘、主机、机架和数据中心故障具有容错能力。每个卷的两个副本位于主数据中心但在不同的机架上,因此主机和磁盘。这提供了对磁盘、主机和机架故障的恢复能力。针对磁盘故障,RAID-6提供了额外的保护。第三个副本位于另一个数据中心,可提供对数据中心故障的恢复能力。
该方案提供了良好的容错性和高吞吐量,但有效复制因子为3 BLOB 1.2=3.6。这是HayStack的主要限制:它针对IOPS进行了优化,但没有针对存储效率进行优化。正如热存储的情况所表明的那样,这会导致大量Blob的过度复制
4.1.7 Expiry-Driven Content
到期驱动的内容某些BLOB类型的内容有到期时间。例如,上传的视频在被转码为我们的存储格式时,会以其原始格式临时存储。我们避免将这种过期驱动的内容移动到f4,并将其保留在HayStack中。热存储系统通过频繁运行压缩来回收当前可用的空间来应对高删除率。
五、f4 Design
本节介绍我们的热存储设计目标,然后介绍我们的热存储系统f4。
5.1 Design goals
从高层次上讲,我们希望我们的热存储系统能够提高存储效率并提供容错功能,这样我们就不会丢失数据或对用户不可用。
存储效率:我们新系统的主要目标之一是提高存储效率,即在保持高度可靠性和性能的同时降低有效复制系数。有效复制系数描述数据的实际物理大小与存储的逻辑大小的比率。在维护3个副本并在每个具有12个磁盘的节点上使用RAID6编码的系统中,有效复制系数为3.6。
容错性:我们的存储系统的另一个重要目标是对故障层次结构的容错,以确保我们不会丢失数据,并且存储始终可用于客户端请求。我们明确考虑了四种类型的故障:
- 驱动器故障,年增长率为低个位数。
- 定期发生主机故障。
- 机架故障,每年多次。
- 数据中心故障,极其罕见,通常是暂时的,但潜在的灾难性更大。
5.2 f4 Overview
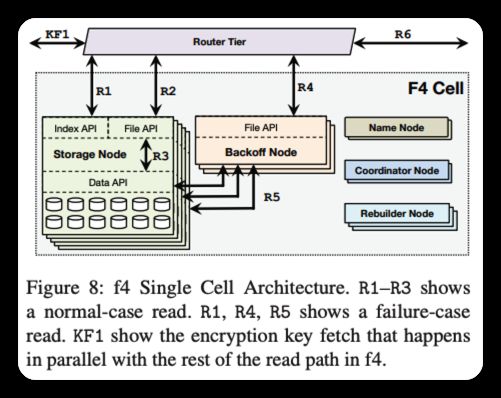
F4是我们的热数据存储子系统。它由多个单元组成,其中每个单元完全位于一个数据中心内,并由同构硬件组成。当前的单元使用14个机架,每台主机有30个4TB驱动器,每台主机有15台主机[42]。我们将蜂窝视为获取的单元,以及部署和推出的单元。
单元负责可靠地存储一组锁定的卷,并使用Reed-Solomon编码以较低的存储开销存储这些卷。Distributed erasure coding achieves reliability 以比复制更低的存储开销实现了可靠性,同时权衡了在故障情况下增加的重建和恢复时间以及更低的最大读取吞吐量。Reed-Solomon编码[46]是最流行的擦除编码技术之一,并且已经在许多不同的系统中使用。Reed-Solomon(n,k)码用k个额外的奇偶校验位对n位数据进行编码,并且可以容忍k个故障,总存储大小为n+k。此方案可防止磁盘、主机和机架故障。
我们使用单独的XOR编码方案来容忍数据中心或地理区域故障。我们将每个卷/条带/数据块与不同地理区域中的伙伴卷/条带/数据块配对。我们将伙伴的XOR存储在第三个区域中。该方案可防止三个区域中的一个发生故障。我们将在第5.5节中讨论容错
5.3 Individual f4 Cell
单个f4单元对磁盘、主机和机架故障具有恢复能力,是它们存储的BLOB的主要位置和接口。每个f4单元仅处理锁定的卷,即它只需要支持对该卷的读取和删除操作。数据和索引文件是只读的。跟踪删除的干草堆日志文件在f4中不存在。相反,所有BLOB都使用存储在外部数据库中的密钥进行加密。删除f4中BLOB的加密密钥会使其不可读,从而在逻辑上将其删除。
索引文件在一个单元格内使用三重复制。这些文件非常小,因此对它们进行编码所获得的存储收益太小,不值得增加复杂性。
具有实际斑点数据的数据文件通过里德-所罗门(n,k)码被编码和存储。最近的f4 cell使用n=10和k=4。文件在逻辑上被划分为n个块的连续序列,每个大小为b。对于每个这样的n个块序列,生成k个奇偶校验块,从而形成大小为n+k的逻辑条带。对于条带中的给定块,该条带中的其他块被视为其同伴块。如果文件不是n个块的整数倍,则对下一个倍数进行零填充。在正常操作中,BLOB直接从其数据块中读取。如果块不可用,则可以通过对其任意n个同伴块和奇偶校验块进行解码来恢复该块。对应于BLOB的块的子集也可以仅从其同伴块和奇偶校验块的任何N个的等价子集中解码。图7显示了BLOB、数据块、条带和卷之间的关系。
选择用于编码的块大小较大–通常为1 GB–有两个原因。首先,它减少了跨多个数据块的BLOB数量,因此需要多个I/O操作才能读取。其次,它减少了f4需要维护的每个数据块的元数据量。我们避免了较大的块大小,因为重建块会产生较大的开销。图8显示了一个f4单元格。其组件包括存储节点、名称节点、回退节点、重建器节点和协调器节点。
5.3.1 Name Node
The name node maintains the mapping between data blocks and parity blocks and the storage nodes that hold the actual blocks. The mapping is distributed to storage nodes via standard techniques [3, 18]. Name nodes are made fault tolerant with a standard primarybackup setup.
5.3.2 Storage Nodes
The storage nodes are the main component of a cell and handle all normal-case reads and deletes. Storage nodes expose two APIs:
- an Index API that provides existence and location information for volumes
- and a File API that provides access to data
Each node is responsible for the existence and location information of a subset of the volumes in a cell and exposes this through its Index API. It stores the index—BLOB to data file, offset, and length—file on disk and loads them into custom data structures in memory. It also loads the location-map for each volume that maps offsets in data files to the physically-stored data blocks. Index files and location maps are pinned in memory to avoid disk seeks.
用每个斑点加密密钥对f4中的每个斑点进行加密。通过删除存储在单独的密钥存储(通常是数据库)中的BLOB的加密密钥,在f4之外处理删除。这使得斑点不可读,并有效地删除了它,而不需要在f4中使用压缩。它还使f4能够消除HayStack用来跟踪关键存在和删除信息的日志文件。
通过验证BLOB是否存在,然后将调用方重定向到具有包含指定BLOB的数据块的存储节点来处理读取(R1)。数据API提供对节点存储的数据和奇偶校验块的数据访问。正常情况下的读取被重定向到相应的存储节点(R2),然后该存储节点直接从其封闭的数据块(R3)读取BLOB。故障情况读取使用数据API读取在回退节点上重建BLOB所需的伴随块和奇偶校验块。路由器层与读路径的其余部分(即,R1-R3或R1、R4、R5)并行地获取每二进制大对象加密密钥。然后在路由器层对BLOB进行解密。解密的计算代价很高,在路由器层上执行解密使f4能够专注于高效存储,并允许独立于存储扩展解密。
5.3.3 Backoff Nodes
当单元中出现故障时,一些数据块将变得不可用,并且为其持有的BLOB提供读取服务将需要从伴随数据块和奇偶校验块在线重建它们。回退节点是占用大量CPU的无存储节点,用于处理请求Blob的在线重建。
每个回退节点公开一个文件API,该API在正常情况下读取失败后从路由器层接收读取(R4)。主卷服务器已将读请求映射到数据文件、偏移量和长度。回退卷服务器从不可用数据块(R5)的所有n个−1伴随数据块和k个奇偶校验数据块的等效偏移量发送该长度的读取。一旦它接收到n个响应,它就对它们进行解码以重建所请求的BLOB。
此在线重建仅重建请求的BLOB,而不重建整个块。因为斑点的大小通常比块大小小得多–例如,40KB而不是1 GB–重建斑点比重建块要快得多,重量也轻得多。完整数据块重建由重建器节点离线处理。
5.3.4 Rebuilder Nodes
在大规模情况下,磁盘和节点故障是不可避免的。发生这种情况时,需要重建存储在故障组件上的块。重建器节点是占用大量CPU的存储较少的节点,用于处理数据块的故障检测和后台重建。每个重建器节点通过探测来检测故障,并将故障报告给协调器节点。它通过从故障数据块的条带中取出n个伴生或奇偶数据块并对其进行解码来重建数据块。重建是一个重量级过程,会对存储节点施加巨大的I/O和网络负载。重建器节点自行节流以避免对在线用户请求产生不利影响。调度重建以最大限度地减少数据丢失的可能性是协调器节点的责任。
5.3.5 Coordinator Nodes
一个单元需要许多维护任务,如调度块重建和确保当前数据布局将数据不可用的可能性降至最低。协调器节点是处理这些计算单元范围任务的存储较少、占用大量CPU的节点。
如前所述,条带中的数据块分布在不同的故障域中,以最大限度地提高可靠性。但是,在初始放置以及故障、重建和替换之后,如果条带的数据块位于同一故障域中,则可能会出现违规。协调器运行放置平衡器进程,该进程验证单元中的块布局,并根据需要重新平衡块。重新平衡操作(如重建操作)会在存储节点上产生巨大的磁盘和网络负载,并且还会受到限制,从而对用户请求产生不利影响。
5.6 Additional Design Points
为清楚起见,本小节简要介绍了我们在基本f4设计中排除的其他设计要点。
5.6.1 混合年龄和类型
我们的BLOB存储系统同时为每个BLOB类型填充多个卷。这将在一个体积内混合斑点的年龄,并使它们的温度变得平滑。体积中最新的斑点的温度可能高于我们对f4的目标温度。但是,如果体积中较老的斑点将其整体温度降低到我们的目标以下,则体积仍可能迁移到f4。
不同的斑点类型在f4细胞中的宿主上混合在一起,以实现类似的效果。如果将高温类型与低温类型混合在一起,可以更快地迁移到f4,从而平滑每个磁盘上的整体负载。
5.6.2 Index Size Consideration
f4(和HayStack)的内存需求主要由索引的内存占用量驱动。F4前面的多个缓存层消除了在存储机器上使用大容量缓存的需要。
除了个人资料照片,索引的内存大小适合我们定制硬件的内存。对于个人资料照片,我们目前将它们从f4中排除,并将它们保留在HayStack中。个人资料照片的索引大小对于HayStack主机来说仍然是个问题,即使它们存储的Blob比f4主机少。为了保持合理的索引大小,我们充分利用了HayStack主机上的存储。这使我们能够使HayStack保持简单,并且不会显著影响整个系统的效率,因为每个用户只有一张个人资料照片,而且照片非常小。
七、经验
在设计、构建、部署和改进f4的过程中,我们学到了很多教训。其中,简单性对操作稳定性的重要性、为用例的效率衡量底层软件的重要性以及硬件异构性以降低相关故障的可能性的需求尤为突出。
在Facebook的许多系统中,设计简单的系统以保持其部署的稳定性的重要性突显出来[41],我们使用f4的经验也加强了这一点。F4的早期版本使用日记文件来跟踪删除,方法与HayStack相同。这个单一的读写文件与只读的f4设计的其余部分不一致。我们实施的核心分布式文件系统(HDFS)最多只能有一个编写器的要求、大型分布式系统中故障的必然性,以及很少写入日志文件,这些都不能很好地结合在一起。这是f4生产问题的首要来源。我们后来的设计删除了这个读写日志文件,将删除跟踪推送到另一个设计为读写的系统。这一更改简化了f4,使其成为完全只读的,并修复了生产问题。
测量和理解构建在f4之上的底层软件有助于提高f4的效率。F4的实现构建在Hadoop文件系统(HDFS)之上。HDFS中的读取通常由群集中的任何服务器处理,然后由该服务器代理到具有所请求数据的服务器。通过测量,我们发现由于HDFS调度IO线程的方式,这种代理读取具有比预期更低的吞吐量和更高的延迟。特别是,HDFS为每个并行网络IO请求使用一个线程,而Java的多线程不能很好地扩展到大量并行请求,这导致网络IO请求的积压不断增加。我们通过第5.3节描述的两部分读取解决了这个问题,避免了通过HDFS代理读取。此解决方法导致了f4的预期吞吐量和延迟。
最近,当一批磁盘开始以高于正常速度的速度出现故障时,我们了解到底层硬件中的异构性对于f4的重要性。此外,我们的一个地区经历了高于平均温度的情况,这加剧了坏盘的故障率。坏磁盘和高温的组合导致在几周内从正常的~1%的AFR增加到超过60%的AFR。幸运的是,高故障率磁盘被限制在单个单元中,没有数据丢失,因为伙伴和XOR块位于其他温度较低的单元中,不受影响。在未来,我们计划使用硬件异构性来降低发生此类相关故障的可能性。