【React】React进阶(源码及实现原理)
React进阶(源码及实现原理)
-
- 一 基础篇
-
- JSX是React.createElement的语法糖。
- 虚拟DOM
- diff和调和
- React15的diff过程
- 组件化
- 生命周期的本质
- 二 进阶篇
-
- React16生命周期
- Fiber
- ReactDOM.render
-
- 1.初始化init阶段
- 2.render阶段
- 3.commit阶段
- 双缓冲模式。
- React事件的实现
一 基础篇
JSX是React.createElement的语法糖。
React.createElement将会返回一个叫做“ReactElement”的JS对象
createElement 参数:
createElement(type,config,children)
type,用于标识节点的类型
config,以对象形式转入,组件所有的属性都会以键值对的形式存储在config对象中
children,以对象形式传入,它记录的是组件标签之间的嵌套内容
React.createElement函数体拆解
首先 二次处理key,ref,self,source四个属性值,再遍历config,筛选出可以给到props里的属性,接着提取子元素,给到childArray也就是props.children数组,最后格式化defaultProps ,结合上面处理完的数据作为入参,发起ReactElement调用。
ReactDom.render(element,container,[callback])
虚拟DOM
本质上是JS和DOM之间的一个映射缓存,在形态上表现为一个能够描述DOM结构及其属性信息的JS对象。
虚拟DOM的生成又分为组件创建和组件更新两个阶段
组件创建时React结合JSX描述构建出DOM树,ReactDOM。render实现生成虚拟DOM,实现虚拟与真实DOM之间的映射,接着触发渲染的线程。
组件更新时,页面变化首先作用于虚拟DOM,调用render方法去生成新的虚拟DOM,接着通过diff算法定位出两个虚拟DOM的不同,再讲这些改变作用于真实DOM。
虚拟DOM的劣势主要在于JS计算的耗时,DOM操作的能耗比JS计算的能耗要高很多。
虚拟DOM的价值不仅仅在于性能,同时提升了开发者的体验和效率,从之前的直接操作真实DOM到了通过书写JS编写虚拟DOM,符合数据驱动视图这一点,同时也解决了跨平台的问题,批量更新时,在虚拟DOM库里由batch函数处理,batch的作用是缓冲每次生成的补丁集。
diff和调和
指的是对比出两颗虚拟DOM树之间差异的过程,不同框架不同版本可能都有着不同的实现思路。
调和和diff,调和 虚拟DOM是一种编程概念,UI以一种虚拟的表现形式保存在内存中,并通过ReactDOM等类库使之与真实DOM同步,这个过程叫做协调或调和。
调和和diff并不是一个概念,调和是使一致的过程,而diff则是负责找不同的过程。
React可以大致的分为三个部分:
Core、Reconciler和Renderer。
而Reconciler也就是调和器是React较为重要的一部分。
调和器负责组件的挂载,卸载,更新等过程,但在面试或者技术交流中,一般认为调和就指的diff,因为diff是调和过程中最具代表性的一环。
diff的设计思想:
1.若两个组件属于同一个类型,它们将拥有相同的DOM树形结构。
2.处于同一层级的一组子节点,可用通过设置key作为唯一标识从而维持各个节点在不同渲染过程中的稳定性。
逻辑拆分:
diff算法性能突破的关键点在于分层比较,类型一致的节点才会继续diff,设置key属性,尽可能的重用一个层级内的节点。
总结以下几点:
1.diff过程只针对于相同层级的节点作比较
2.diff过程只对比相同类型的组件。
3.key属性维护节点的稳定性,用来帮助React识别哪些内容被修改,如果key值改变就会重新渲染UI。
React15的diff过程
批量更新:树递归。
setState时,调和器会把它塞到一个队列中,等执行完这个队列时,仅对最新的state执行一次更新流程,这时体现出来的setState就是异步的,但把setState放到settimeout中,setState又是同步的。
那么setState到底是同步还是异步的呢,让我们直接进入setState的工作流。
在setState后,首先调用的是enqueueSetState这个方法,再去调用enqueueUpState方法,最后通过isBatchingUpdates去判断是入队列还是直接执行。
setState:
ReactComponent.prototype.setState = function(partialState, callback) {
this.updater.enqueueSetState(this, partialState);
if (callback){
this.updater.enqueueCallback(this, callback, 'setState');
}
}
enqueueSetState:
function enqueueSetState(publiclnstance, partialState) {
var queue = internalInstance._pendingStateQueue | l(internallnstance._pendingStateQueue = D); queue.push(partialState);
enqueueUpdate(internalInstance)
}
enqueueUpState://组件实例
function enqueueUpdate(component) {
ensurelnjected();
if(!batchingStrategy.isBatchingUpdates){
//立即执行
batchingStrategy.batchedUpdates(enqueueUpdate, component); return;
}
//等待
dirtyComponents.push(component);
if (component._updateBatchNumber == null) {
component._updateBatchNumber = updateBatchNumber + 1;
}
}
isBatchingUpdates:
//全局锁
var ReactDefaultBatchingStrategy = {
isBatchingUpdates: false,
batchedUpdates: function(callback, a, b, c, d, e) {}
}
判断是否立即执行:
var alreadyBatchingStrategy = ReactDefaultBatchingStrategy.isBatchingUpdates
ReactDefaultBatchingStrategy.isBatchingUpdates = true
if (alreadyBatchingStrategy) {
callback(a, b, c, d, e)
} else {
transaction.perform(callback, null, a, b, c, d, e)
}
setState本质上是由React事务机制和批量更新机制来控制的,是通过isBatchingUpdates这个变量来控制是否是异步更新。
在源码中体现为Transaction这样一个核心类,是一个可以封装任何方法的盒子。
事件监听部分源码:
function(topLevelType, nativeEvent) {
...
try {
ReactUpdates.batchedUpdates(handleTopLevellmpl, bookKeeping);
} finally {
TopLevelCallbackBookKeeping.release(bookKeeping);
}
}
组件化
工程化思想在框架中的实现,既有能提现封闭的地方,也有能提现出开放的地方
针对于渲染工作流来说是封闭的,在组件自身的渲染工作流中,每个组件都只处理它内部的渲染逻辑。
针对于组件间的通讯来说是开放的,react允许开发者基于单向数据流的原则,完成组件间的通讯。
生命周期的本质
渲染工作流:指的是从组件数据改变到组件实际更新发生的过程。
render在执行过程中并不会去操作真实DOM,它的职能是把需要渲染的内容返回出来。
componentDidMount方法在渲染结束后被触发,可以操作真实DOM。
父组件导致组件重新渲染,即使props没有更改,也会调用componentReceiveProps。
二 进阶篇
React16生命周期
为什么在高阶中写这个,因为在项目开发中,还是有很多有经验的React开发者们习惯的用componentWillReceiveProps这个旧的生命周期,因为render阶段是可以被打断的,使用这个生命周期有导致很多不可预测的风险出现,所以大家以后开发时尽可能的不要使用componentWillReceiveProps这个生命周期,转而使用getDerivedStateFromProps和componentDidUpdate。
getDerivedStateFromProps只能用来通过props来更新或生成state。
getDerivedStateFromProps是一个静态方法,就代表着在方法体里不可以使用this,并且需要通过static声明这个方法。
该方法接收两个参数,第一个是props,第二个是state,而第一个参数是接受到的最新的props,第二参数是之前的state,所以在方法的形参中,我们可以使它更语义化一点,第一个形参命名为nextProps,第二个形参命名为prevState。
该方法需要返回一个对象格式的返回值,返回值为更新的state,对state的更新并非全量更新,而是增量更新,只针对于某个属性定向更新。
Fiber
浏览器是多线程的,JS是单线程的,渲染线程和JS线程同时执行的话会导致不可预测的结果,所以它们运行流程必须是互斥的。
当JS线程占用主线程太长时间时,渲染层面的更新长时间地等待,界面不更新,带给用户就是卡顿的感觉,同时事件线程也在等待JS,就导致触发的事件也是不会被相应的,而在16之前的版本使用的Stack Reconciler也就是React16之前的调和器又是同步的递归的过程,它会重复的调用父组件调用子组件的过程知道最深的节点更新完毕,才会向上返回,导致一个长时间占用线程的事件无法被打断,所以的事件都必须等待他执行完成。React 16.x版本后的调和器Fiber Reconciler的作用之一就是同步的渲染过程变成异步的,而且这个异步渲染模式是可以被打断的,将一个大的任务拆解为多个小任务,这样就很好的解决了这个问题,但这只是其中的一种作用。
Fiber架构的核心有以下几点:可中断,可恢复,优先级。
fiber是比线程还要纤细的一个过程,意在对渲染过程实现更加精细的控制,fiber节点保存了组件需要更新的状态和副作用,同时实现了增量渲染,这样就可以实现任务的可中断,可恢复并且给不同任务赋予优先级,以此达到我们需要的效果。
那么Fiber对生命周期有什么影响呢。
React 16之前在render阶段和commit阶段之间的同步递归计算,在React 16 中被划分为了一个个的工作单元也就是fiber这个数据结构,他们是可以根据优先级来进行异步,可中断可恢复的。
ReactDOM.render
接下来将深入渲染挂载到页面上时React究竟做了哪些事情。
ReactDOM.render会经历三个阶段。
1.初始化init阶段
完成基本实体的创建
初始化时调用legacyCreateRootFromDOMContainer创建container.reactRootContainer对象并赋值给root,其次将root上的_inernalRott属性赋值给fiberRoot,再者将fiberRoot与方法入参一起,传入updateContainer方法中,形成回调,最后将updateContainer回调作为参数传入,调用unbatchedUpdates,
fiberRoot:
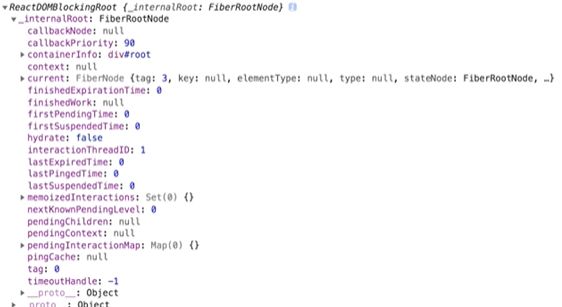
fiber节点:

fiberRoot对象实例化为rootFiber也就是FiberNode实例。
unbatchUpdates阶段时会请求当前fiber节点的优先级lane,结合lane创建当前fiber节点的update对象,并将其入队调度当前节点rootFiber。
performSyncWorkOnRoot是render阶段的起点,render阶段的任务就是完成Fiber树的构建,它是整个渲染链路中最核心的一环。
在int阶段后,React就要开始启动了,而现在存在三种React启动方式。
legacy模式:ReactDOM.render(,rootNode)
blocking模式:ReactDOM.createBlockingRoot(rootNode).render()
concurrent模式:ReactDOM.createRoot(rootNode).render()
Legacy可能不支持新功能
blocking是过渡模式
默认为concurrent,最新,目前在v18.0.0-alpha,和experiment版本中发布. 这个模式开启了所有的新功能。
如果需要异步渲染,则需要调用ReactDOM.createRoot方法来启动应用。
mode属性的差异会导致Lane是SyncLane时,进行异步渲染。
既然Fiber解决了异步渲染的问题,那Fiber架构一定是异步渲染吗。
从设计层面来看Fiber架构确实是为了Concurrent也就是异步渲染模式而设计的,但Fiber架构在React中并不能和异步渲染完全相等,它兼容了同步与异步渲染。
2.render阶段
是整个渲染链路中最为核心的一环,找不同也就是更新的过程就是在render阶段发生的。
React15下的调和过程是递归的形式,在ReactDOM.render触发的同步模式下,它是一个深度优先搜索的过程,在这个过程中,beginWork将创建新的Fiber节点,而completeWork则负责将Fiber节点映射为DOM节点。
workInProgress节点的创建:
//current是现有树结构中的rootFiber对象
function createWorklnProgress(current, pendingProps) {
//current的alternate将反过来指向workInProgress
var workInProgress = current.alternate;
if (worklnProgress === null) {
//后面createWorklnProgress调用createFiber
workInProgress = createFiber(current.tag, pendingProps, current.key, current.mode);
worklnProgress.elementType = current.elementType;
workInProgress.type = current.type;
workInProgress.stateNode = current.stateNode;
//workInProgress的alternate将指向current
workInProgress.alternate = current;
current.alternate = workInProgress;
} else {
//workInprogress是createFiber方法的返回值
...
return workInProgress
}
}
createFiber:
var createFiber = function(tag,pendingProps,key,mode){
return new FiberNode(tage,pendingProps,key,mode)
}
workInProgress = createFiber(current.tag,pendingProps,current.key,current.mode)
workInProgress节点本质上是current节点也就是rootFiber的复制节点
新Fiber节点的创建:
function workLoopSync(){
//判断workInProgress 是否为空
while(workInProgress!==null){
//触发beginWork,创建Fiber节点
performUnitOfWork(workInProgress)
}
}
从一开始说的current树,到现在的workInProgress树,好像是没有区别的,那么到底为什么要搞出两颗一样的树出来呢?这里是极大限度地实现Fiber节点的复用,涉及到双缓冲模式,后面详细探讨一下。
beginWork开启Fiber节点的创建,入参为current节点,workInProgress节点。
beginWork的核心逻辑是根据workInProgress的tag属性的不同调用不同的节点创建函数
function reconcileChildren(current, workInProgress, nextChildren, renderLanes) {
if (current === null) {
workInProgress.child = mountChildFibers(workInProgress, null, nextChildren, renderLanes);
} else {
workInProgress.child = reconcileChildFibers(workInProgress, current.child, nextChildren, renderLanes);
}
}
var reconcileChildFibers = ChildReconciler(true)
var mountChildFibers = ChildReconciler(false);
ChildReconciler的返回值是一个名为reconcileChildFibers的函数,这个函数起到逻辑分发的作用,它根据入参不容,执行相应的Fiber节点操作,最终会返回不同的Fiber节点。
mountChildFibers和reconcileChildFibers不同在于入参不同,所以产生的副作用也不同,导致返回的Fiber节点也不同
用来标记创建DOM节点的函数:
function placeSingleChild(newFiber){
if(shouldTrackSideEffects&&newFiber.alternate===null){
newFiber.flags=Placement
}
return newFiber
}
更新渲染时 placeSingleChild 会把新创建的 fiber 节点标记为 Placement, 待到提交阶段处理。
之前的版本中叫做effectTag,flags或者effectTag的意义就是标记这个fiber节点需要新建DOM节点,effectTag或flags标记的是副作用的类型。
接下来会进入这段代码来判断他的类型:
const isObject = typeof newChild === 'object' && newChild !== null;
if (isObject) {
switch (newChild.$$typeof) {
case REACT_ELEMENT_TYPE:
return placeSingleChild(
reconcileSingleElement( returnFiber,currentFirstChild,
newChild,
expirationTime,
),
);
case REACT_PORTAL_TYPE:
return placeSingleChild(
reconcileSinglePortal(
returnFiber,
currentFirstChild,
newChild,
expirationTime,
),
);
}
}
if (typeof newChild === 'string' || typeof newChild === 'number') {
return placeSingleChild(
reconcileSingleTextNode(
returnFiber,
currentFirstChild,
'' + newChild,
expirationTime,
),
);
}
if (isArray(newChild)) {
return reconcileChildrenArray(
returnFiber,
currentFirstChild,
newChild,
expirationTime,
);
}
if (getIteratorFn(newChild)) {
return reconcileChildrenIterator(
returnFiber,
currentFirstChild,
newChild,
expirationTime,
);
}
然后FiberNode就会被赋予标记的类型,如下图。
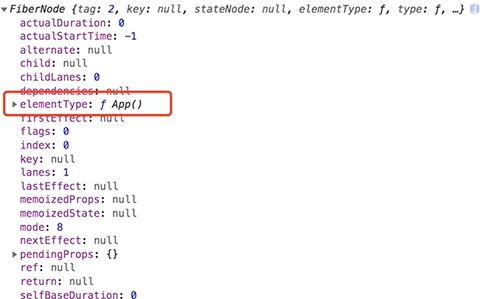
新建立的Fiber节点作为root Fiber的child属性建立起与workInprogress Fiber树的关联:
function workLoopSync(){
while(workInProgress!==null){
performUnitOfWork(workInProgress)
}
}
新建Fiber节点:
next=beginWork$1(current,unitOfWork,subtreeRenderLanes)
if(next===null){
completeUnitOfWork(unitOfWork)
}else{
workInProgress=next
}
没有新建的节点后就会完成此次创建节点的过程。
循环创建Fiber节点。
那么Fiber节点是怎么建立关联的呢,是通过节点的三个属性,分别是child,return,sibling。child,return是用来记录父子节点关系的,sibling节点用来记录兄弟节点关系。
总结一下创建Fiber节点的流程。
beginWork=>处理rootFiber节点=>调用reconcileChildren创建子节点=>Current不为null时,会进入reconcileChildFibers,reconcileChildFibers是ChildReconciler(true)的返回值,副作用将会被追踪=>reconcileChildFibers将子节点创建逻辑分发给reconcileSingleElement得到返回值App FiberNode=>调用placeSingleChild会把新创建的 fiber 节点标记为 Placement=>新创建的 fiber 节点作为root Fiber的child属性,与现有的workInprogress Fiber树建立关联。
completeWork
什么情况会调用completeWork呢,当前Fiber节点结束了递归的过程也就是next===null了。之前提到过得beginWork负责创建Fiber节点,而completeWork负责将Fiber节点映射到DOM节点。
completeWork会做三件事。
1.创建DOM节点
2.将DOM节点插入DOM树中
3.设置DOM节点的属性
创建好的DOM节点会被赋值给workInProgress节点的stateNode属性
创建好DOM节点之后的操作是什么呢?是通过appendAllChildren函数来完成将DOM节点插入到DOM树中。
此时就遇到了一个问题,这个DOM节点应该如果添加到DOM树中,之前提到过节点的三个关系,其中这里就是通过父级的DOM节点添加到的DOM树中的,但如果没有父级的DOM,例如是第一个节点,要怎么添加到DOM树中,如果没有父级DOM节点就会作为Fiber节点的stateNode属性存在,然后进入到completeUnitOfWork针对传入的当前节点调用completeWork,并将当前节点的副作用插入到父节点的副作用链中,最后以此节点作为起点,去循环遍历其兄弟节点以及其父节点。
在确认没有待处理的兄弟节点后,才会处理父节点,因为completeWork执行是严格的自底向上的过程。
总结一下render阶段。
1.通过completeWork自底向上执行,找出需要更新的地方,workInProgress递归完毕,所有更新地方被找出。
2.节点创建effectList时并不是为了自己创建的而是为了父节点创建,因为completeWork是严格的自底向上执行的,进入创建effectList的逻辑时,当firstEffect与lastEffect指向同一个节点时,该节点就会成为effectList中的唯一的FiberNode。将所有需要更新的节点,通过链的方式连接起来,最后生成一条副作用链,就是整个render阶段的成果,这条副作用链中记录着所有需要更新的节点,节点等待挂载。。。render阶段结束。
3.commit阶段
commit节点一定是同步的。
commit的第一个阶段,before mutation,这个阶段还没有将DOM节点渲染到界面上去,该阶段遍历完整个effectList就结束了,遍历时对每个effect都进行了commitBeforeMutationEffects方法的调用
commit的第二个阶段,mutation,这个阶段负责DOM节点的渲染.
startCommitHostEffectsTimer();
nextEffect = firstEffect;
do {
try {
// renderPriorityLevel为优先级
commitMutationEffects(renderPriorityLevel);
} catch (error) {
invariant(nextEffect !== null, 'Should be working on an effect.');
captureCommitPhaseError(nextEffect, error);
nextEffect = nextEffect.nextEffect;
}
} while (nextEffect !== null);
stopCommitHostEffectsTimer();
function commitMutationEffects(renderPriorityLevel) {
while (nextEffect !== null) {
const effectTag = nextEffect.effectTag;
if (effectTag & ContentReset) {
// 清除文本节点内容及其子节点变为 ‘’
commitResetTextContent(nextEffect);
}
// 将 ref 的指向置为 null
if (effectTag & Ref) {
const current = nextEffect.alternate;
if (current !== null) {
commitDetachRef(current);
}
}
// The following switch statement is only concerned about placement,
// updates, and deletions. To avoid needing to add a case for every possible
// bitmap value, we remove the secondary effects from the effect tag and
// switch on that value.
// effect类型
let primaryEffectTag = effectTag & (Placement | Update | Deletion);
// 类型区分
switch (primaryEffectTag) {
case Placement: {
commitPlacement(nextEffect);
// Clear the "placement" from effect tag so that we know that this is
// inserted, before any life-cycles like componentDidMount gets called.
// TODO: findDOMNode doesn't rely on this any more but isMounted does
// and isMounted is deprecated anyway so we should be able to kill this.
// 执行完成后去掉 Placement 标记
nextEffect.effectTag &= ~Placement;
break;
}
case PlacementAndUpdate: {
// Placement
commitPlacement(nextEffect);
// Clear the "placement" from effect tag so that we know that this is
// inserted, before any life-cycles like componentDidMount gets called.
nextEffect.effectTag &= ~Placement;
// Update
const current = nextEffect.alternate;
commitWork(current, nextEffect);
break;
}
case Update: {
const current = nextEffect.alternate;
commitWork(current, nextEffect);
break;
}
case Deletion: {
commitDeletion(nextEffect, renderPriorityLevel);
break;
}
}
// TODO: Only record a mutation effect if primaryEffectTag is non-zero.
recordEffect();
nextEffect = nextEffect.nextEffect;
}
}
其中要注意的是
1.commitResetTextContent,这个方法是判断如果原来是文本节点变为不是文本节点了,就要使用DOM textContent 属性的值去掉原来的节点的值。

以上图片转自
2.commitDetachRef 方法将当前 fiber 上的 ref 设置为 null,也就是解除了 ref 的关系
3.commitPlacement ,对新增节点的处理。通过原生的appendChild和insertBefore方法 。当插入的节点为类式组件时,首先会遍历这个组件,遍历方式和之前创建fiber节点的workLoopSync方法差不多,先根据 child 属性找到第一个原生节点,有兄弟节点就转到兄弟节点,兄弟节点有子节点就继续遍历子节点,没有就返回上级节点,一直到返回目标节点。
第三个阶段 layout,这个阶段处理DOM渲染完毕之后的逻辑,例如将之前解绑的current指针指向workInProgress Fiber树。
双缓冲模式。
双缓冲模式是不同的缓冲数据交替被读取后的结果,能较大限度的实现Fiber节点的复用,从而减少性能方面的开销。
current树与workInProgress树就是双缓冲模式下的两套缓冲数据,当current树呈现在用户眼前时,所有的更新都会由workInProgress树来承接。
接下来再看看异步渲染是怎么实现的。
这里要提到两个东西:
1.时间切片
2.优先级
同步渲染模式下的render阶段是一个同步,深度优先搜索的过程
1.时间切片:在异步渲染模式下,这个循环由workLoopConcurrent开启。
function workLoopConcurrent(){
while(workInProgress !== null && !shouldYield() ){
performUnitOfWork(workInProgress)
}
}
当shouldYield返回为true时就说明需要结束循环将空间给主线程了。
exports.unstable_shouldYield = function(){
return exports.unstable_now() >= deadline
}
deadline = currentTime + yieldInterval
2.优先级:通过调用unstable_scheduleCallback来发起调度的,结合任务的优先级信息为其执行不同的调度逻辑。
function unstable_scheduleCallback(priorityLevel,callback,options){
var currentTime = exports.unstable_now();
var startTime
}
if(typeof options === 'object' && options !== null ){
var delay = options.delay
}
if( typeof delay === 'number' && delay>0 ){
startTime = currentTime + delay;
}else{
startTime = currentTime;
}
else{
startTime = currentTime
}
var timeout
//优先级实现
switch(priorityLevel){
case ImmediatePriority:
timeout = IMMEDIATE_PRIORITY_TIMEOUT
break;
......
}
var expirationTime = startTime + timeout ;
var newTask = {
id : taskIdCounter++ ,
callback : callback ,
priorityLevel : priorityLevel ,
startTime : startTime ,
expirationTime : expirationTime ,
sortIndex : -1
}
if( startTime > currentTime ){
newTask.sortIndex = startTime ;
.....
}
if(peek(taskQueue) === null && newTask === peek(timer))
通过源码,可以得出优先级调度的实现方法:创建newTask对象;
通过startTIme和currentTime判断当前任务是否是过期任务,是过期任务则假如taskQueue堆中,再有requestHostCallback(flushwork)派发为及时任务。
不是过期任务则加入timerQueue堆或在哪个,再判断taskQueue是否为空,不为空则将当前的newTask返回,为空则判断newTask是否是timerQueue堆的最新的任务,是则调用requestHostTimeout派发延时的任务,不是则返回当前的newTask。
React事件的实现
W3C标准约定了一个事件的传播过程要经历一下三个阶段:
事件捕获阶段
目标阶段
事件冒泡阶段
DOM事件的性能优化思路:事件委托。
把多个子元素同一类型的监听事件放到父元素的监听事件中。
React事件系统是如何工作的。
当事件在具体的DOM节点上被触发后,最终都会冒泡到document上,document上所绑定的统一事件处理程序会将事件分发到具体的组件实例。
React合成事件,提供给了开发者统一的事件接口,但最终还是引用的原生DOM事件。
React合成事件会经历两个步骤,第一事件绑定,第二事件触发。
React的事件绑定是在completeWork中完成的,
completeWork有三个关键性的操作
1.创建DOM节点。
2.为DOM节点插入到DOM树中。
3.为DOM节点设置属性。
completeWork首先通过createInstance创建DOM节点,接着通过appendAllChildren将DOM节点插入DOM树中,然后通过finalizeInittialChildren设置DOM节点的属性,在finalizeInittialChildren之后会调用setInitialProperties去处理传入的props,然后调用setInitialDOMProperties方法去设置DOM节点的初始化属性,接着进入到事件监听的注册流程经过调用ensureListeningTo方法,到了分发事件监听的注册逻辑通过legacyListenToLevelEvent实现,再会进入到一段判断逻辑,判断事件是捕获还是冒泡,分别进入不同的处理逻辑后,都会回归到addTrappedEventListener上将事件注册到document上。
多次调用了对同一事件的监听,也只会在document上注册一次,因为React最终注册到document上的并不是一个节点的具体逻辑,而是一个事件分发函数,这个分发函数就是dispatchEvent。
那么React事件是如何触发的呢,本质是通过调用分发函数dispatchEvent,事件触发时会冒泡至document,紧接着会执行dispatchEvent,在创建完事件对应的合成事件对象syntheticEvent后,将收集event在捕获阶段的回调函数和对应的DOM节点实例,收集事件在冒泡阶段的回调函数和对应的DOM节点实例,将前两步收集来的回调按顺序执行。
function traverseTwoPhase(inst , fn , arg ){
var path = [] ;
while(inst){
path.push(inst);
inst = getParent(inst);
}
var i ;
for( i = 0 ; i < path.length ; i++ ){
fn( path[i] , 'bubbled' , arg );
}
}
以上源码循环收集符合条件的父节点,存入到path中,tag === HostComponent的父节点中,并将这些节点按顺序收集进path数组中。
HostComponent是DOM元素对应Fiber节点类型,也就是只收集DOM元素对应的Fiber节点。
那么在原生事件中的冒泡与捕获在React事件中是如何实现的呢?
path数组中子节点在前,祖先节点在后,也就是父节点向下遍历子节点,直到遍历到目标节点,顺序和捕获阶段的传播顺序是一致的。traverseTwoPhase会从后向前遍历path数组模拟事件的冒泡事件,会收集事件在捕获阶段对应的回调与实例,他们唯一的区别是对path数组的倒叙遍历变成了正序遍历。
那么,为什么React要费这么大的精力去搞一套自己的事件接口呢,他的作用在于在开发层面统一了不同浏览器事情的差异,提供统一,稳定的事件接口,而且还有一个最重要的作用,帮助React实现对所有事件的集中管控。
以上源码循环收集符合条件的父节点,存入到path中,tag === HostComponent的父节点中,并将这些节点按顺序收集进path数组中。
HostComponent是DOM元素对应Fiber节点类型,也就是只收集DOM元素对应的Fiber节点。
那么在原生事件中的冒泡与捕获在React事件中是如何实现的呢?
path数组中子节点在前,祖先节点在后,也就是父节点向下遍历子节点,直到遍历到目标节点,顺序和捕获阶段的传播顺序是一致的。traverseTwoPhase会从后向前遍历path数组模拟事件的冒泡事件,会收集事件在捕获阶段对应的回调与实例,他们唯一的区别是对path数组的倒叙遍历变成了正序遍历。
那么,为什么React要费这么大的精力去搞一套自己的事件接口呢,他的作用在于在开发层面统一了不同浏览器事情的差异,提供统一,稳定的事件接口,而且还有一个最重要的作用,帮助React实现对所有事件的集中管控。