【【Verilog典型电路设计之CORDIC算法的Verilog HDL 实现】】
Verilog典型电路设计之CORDIC算法的Verilog HDL 实现
典型电路设计之CORDIC算法的Verilog HDL 实现
坐标旋转数字计算机CORDIC(Coordinate Rotation Digital Computer)算法,通过移位和加减运算,能递归计算常用函数值,如sin,cos,sinh,cosh等函数,最早用于导航系统,使得矢量的旋转和定向运算不需要做查三角函数表、乘法、开方及反三角函数等复杂运算。J.Walther在1971年用它研究了一种能计算出多种超越函数的统一算法。引入参数m将CORDIC实现的三种迭代模式:三角运算、双曲运算和线性运算统一于同一个表达式下。形成目前所用的CORDIC算法的最基本的数学基础。该算法的基本思想是通过一系列固定的、与运算基数相关的角度不断偏摆以逼近所需的旋转角度。可用下列等式进行描述。




迭代结构
简单地将CORDIC算法的公式复制到硬件描述上,就可以实现迭代的cORDIC算法,其结构如下图所示。
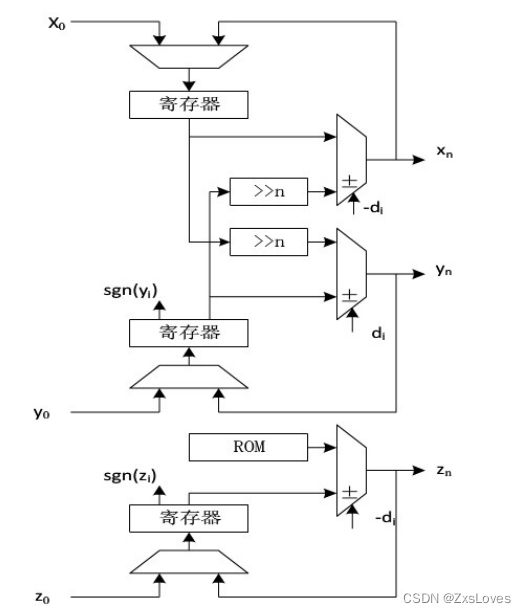
流水线结构
流水线结构虽然比迭代结构占用的资源多,但是它大大的提高了数据的吞吐率。流水线结构是将迭代结构展开,因此n个处理单元中的每一个都可以同时并行处理一个相同的迭代运算。其结构如下图所示。

例:用Verilog HDL设计基于7级流水结构求正余弦的CORDIC算法在CORDIC算法中有一个初始的X、Y值。输入变量Z是角度变量,首先将X、Y输入到固定移位次数的移位寄存器进行移
位,然后将结果输入到加/减就完成了一次迭代,符庥次进行下去,当达到果加减操作,这样就完成了一次迭代,将此次迭代运算进行下去,当达到所需要的迭代次数(本例为((次) 的的恢付石联的加/减法器阵列。。所以整个CORDIC处理器就是一个内部互联的加/减法器阵列。

module sincos(clk,rst_n,ena,phase_in,sin_out,cos_out,eps);
parameter DATA_WIDTH=8;
parameter PIPELINE=8;
input clk;
input rst_n;
input ena;
input [DATA_WIDTH-1:0] phase_in;
output [DATA_WIDTH-1:0] sin_out;
output [DATA_WIDTH-1:0] cos_out;
output [DATA_WIDTH-1:0] eps;
reg [DATA_WIDTH-1:0] sin_out;
reg [DATA_WIDTH-1:0] cos_out;
reg [DATA_WIDTH-1:0] eps;
reg [DATA_WIDTH-1:0] phase_in_reg;
reg [DATA_WIDTH-1:0] x0,y0,z0;
wire [DATA_WIDTH-1:0]x1,y1,z1;
wire [DATA_WIDTH-1:0]x2,y2,z2;
wire [DATA_WIDTH-1:0]x3,y3,z3;
wire [DATA_WIDTH-1:0]x4,y4,z4;
wire [DATA_WIDTH-1:0]x5,y5,z5;
wire [DATA_WIDTH-1:0]x6,y6,z6;
wire [DATA_WIDTH-1:0]x7,y7,z7;
reg [1:0] quadrant[PIPELINE:0];
integer i;
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
phase_in_reg<=8'b0000_0000;
else
if(ena)
begin
case(phase_in[7:6])
2'b00:phase_in_reg<=phase_in;
2'b01:phase_in_reg<=phase_in-8'h40; 2'b10:phase_in_reg<=phase_in-8'h80;
2'b11:phase_in_reg<=phase_in-8'hc0;
default:;
endcase
end
end
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
x0<=8'b0000_0000;
y0<=8'b0000_0000;
z0<=8'b0000_0000;
end
else
if(ena)
begin
x0<=8'h4D;
y0<=8'h00;
z0<=phase_in_reg;
end
end
lteration #(8,0,8'h20)u1(.clk(clk),.rst_n(rst_n),.ena(ena),.xO(xO),.y0(y0),.z0(zO),.x1(x1),.y1(y1),.z1(z1));
lteration #(8,1,8'h12)u2(.clk(clk),.rst_n(rst_n),.ena(ena),
.xO(×1),.yo(y1),.z0(z1),.x1(×2),.y1(y2),.z1(z2));
lteration #(8,2,8'h09)u3(.clk(clk),.rst_n(rst_n),.ena(ena),
.xO(x2),.y0(y2),.z0(z2),.x1(×3),.y1(y3),.z1(z3));
lteration#(8,3,8'h04)u4(.clk(clk),.rst_n(rst_n),.ena(ena),
.xO(x3)..yo(y3),.z0(z3),.x1(x4),.y1(y4),.Z1(z4));
lteration #(8,4,8'h02)u5(.clk(clk),..rst_n(rst_n),.ena(ena),
.x0(x4),.yo(y4),.z0(z4),.x1(×5),.y1(y5),.Z1(z5));
lteration #(8,5,8'ho1)u6(.clk(clk),.rst_n(rst_n),.ena(ena),
.x0(x5),.y0(y5),.z0(z5),.x1(x6),.y1(y6),.z1(z6));
lteration #(8,6,8'ho0)u7(.clk(clk),.rst_n(rst_n),.ena(ena),
.x0(×6),.yo(y6),.z0(z6),.x1(×7),.y1(y7),.z1(z7));
always@(posedge clk or negedge rst_n)begin
if(!rst_n)
for(i=0;i<=PIPELINE;i=i+1)
quadrant[i]<=2'b00;
else
if(ena)
begin
for(i=0;i<=PIPELINE;i=i+1)
quadrant[i+1]<=quadrant[i];
quadrant[0]<=phase_in[7:6];
end
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
sin_out<=8'b0000_0000;
cos_out<=8'b0000_0000;
eps<=8'b0000_0000;
end
else
if(ena)
case(quadrant[7])
2'b00:begin
sin_out<=y6;
cos_out<=x6;
eps<=z6;
end
2'b01:begin
sin_out<=x6;
cos_out<=~(y6)+1'b1;
eps<=z6;
end
2'b10:begin
sin_out<=~(y6)+1'b1;
cos_out<=~(x6)+1'b1;
eps<=z6;
end
2'b11:begin
sin_out<=~(x6)+1'b1;
cos_out<=y6;
eps<=z6;
end
endcase
end
endmodule
//迭代模块:
module lteration(clk,rst_n,ena,x0,y0,z0,x1,y1,z1);
parameter DATA_WIDTH=8;
parameter shift=0;
parameter constant=8'h20;
input clk,rst_n,ena;
input [DATA_WIDTH-1:0]x0,y0,z0;
output[DATA_WIDTH-1:0]x1,y1,z1;
reg [DATA_WIDTH-1:0]x1,y1,z1;
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
x1<=8'b0000_0000;
y1<=8'b0000_0000;
z1<=8'b0000_0000;
end
else
if(ena)
if(z0[7]==1'b0)
begin
x1<=x0-{{shift{yO[DATA_WIDTH-1]1},y0[DATA_WIDTH-1:shift]};
y1<=y0+{[shift{xO[DATA_WIDTH-1]),x0[DATA_WiDTH-1:shift]};
z1<=z0-constant;
end
else
begin
x1<=x0+{fshift{yO[DATA_WIDTH-1],y0[DATA_WIDTH-1:shift]};
y1<=y0-f{shift{xO[DATA_WIDTH-1])}.x0[DATA_WIDTH-1:shift]};
z1<=z0+constant;
end
end
endmodule
下面是testbench
module sincos_tb;
reg clk,rst_n,ena;
reg [7:0]phase_in;
wire [7:0]sin_out,cos_out,eps;
sincos U1(.clk(clk),.rst_n(rst_n),.ena(ena),.phase_in(phase_in),.sin_out(sin_out),.cos_out(cos_out),.eps(eps));
initial
begin
clk=0;
rst_n=0;
ena=1;
phase_in=8'b0000_0000;
#3 rst_n=1;
end
always #5 clk=~clk;
always #10
phase_in=phase_in+1;
endmodule