Linux

Linux笔记
第1章 Linux 入门
1.1 概述

1.2 Linux 和 Windows 区别

1.3 CentOS 下载地址
阿里云:http://mirrors.aliyun.com/centos/7.9.2009/isos/x86_64/
网易:http://mirrors.163.com/centos/7.9.2009/isos/x86_64/
清华大学:http://mirrors.tuna.tsinghua.edu.cn/centos/7.9.2009/isos/x86_64/
第 2 章VM 与Linux的安装
第 3 章Linux 文件与目录结构
3.1 Linux 文件
Linux 系统中一切皆文件。
3.2 Linux 目录结构

系统启动必须:
- /boot:存放的启动Linux 时使用的内核文件,包括连接文件以及镜像文件。
- /etc:存放所有的系统需要的配置文件和子目录列表,更改目录下的文件可能会导致系统不能启动。
- /lib:存放基本代码库(比如c++库),其作用类似于Windows里的DLL文件。几乎所有的应用程序都需要用到这些共享库。
- /sys: 这是linux2.6内核的一个很大的变化。该目录下安装了2.6内核中新出现的一个文件系统 sysfs 。sysfs文件系统集成了下面3种文件系统的信息:针对进程信息的proc文件系统、针对设备的devfs文件系统以及针对伪终端的devpts文件系统。该文件系统是内核设备树的一个直观反映。当一个内核对象被创建的时候,对应的文件和目录也在内核对象子系统中
指令集合:
- /bin:存放着最常用的程序和指令
- /sbin:只有系统管理员能使用的程序和指令。
外部文件管理:
- /dev :Device(设备)的缩写, 存放的是Linux的外部设备。注意:在Linux中访问设备和访问文件的方式是相同的。
- /media:类windows的其他设备,例如U盘、光驱等等,识别后linux会把设备放到这个目录下。
- /mnt:临时挂载别的文件系统的,我们可以将光驱挂载在/mnt/上,然后进入该目录就可以查看光驱里的内容了。
临时文件:
- /run:是一个临时文件系统,存储系统启动以来的信息。当系统重启时,这个目录下的文件应该被删掉或清除。如果你的系统上有 /var/run 目录,应该让它指向 run。
- /lost+found:一般情况下为空的,系统非法关机后,这里就存放一些文件。
- /tmp:这个目录是用来存放一些临时文件的。
账户:
- /root:系统管理员的用户主目录。
- /home:用户的主目录,以用户的账号命名的。
- /usr:用户的很多应用程序和文件都放在这个目录下,类似于windows下的program files目录。
- /usr/bin:系统用户使用的应用程序与指令。
- /usr/sbin:超级用户使用的比较高级的管理程序和系统守护程序。
- /usr/src:内核源代码默认的放置目录。
运行过程中要用:
- /var:存放经常修改的数据,比如程序运行的日志文件(/var/log 目录下)。
- /proc:管理内存空间!虚拟的目录,是系统内存的映射,我们可以直接访问这个目录来,获取系统信息。这个目录的内容不在硬盘上而是在内存里,我们也可以直接修改里面的某些文件来做修改。
扩展用的:
- /opt:默认是空的,我们安装额外软件可以放在这个里面。
- /srv:存放服务启动后需要提取的数据(不用服务器就是空)。
第 4 章 VI/VIM编辑器(重要)
4.1VI/VIM 是什么
VI 是 Unix 操作系统和类 Unix 操作系统中最通用的文本编辑器。
VIM 编辑器是从 VI 发展出来的一个性能更强大的文本编辑器。可以主动的以字体颜
色辨别语法的正确性,方便程序设计。VIM 与 VI 编辑器完全兼容。
4.2 测试数据准备
1)拷贝/etc/profile数据到/root 目录下
4.3 一般模式
以 vi 打开一个档案就直接进入一般模式了(这是默认的模式)。在这个模式中, 你可
以使用『上下左右』按键来移动光标,你可以使用『删除字符』或『删除整行』来处理档
案内容, 也可以使用『复制、粘贴』来处理你的文件数据。
| 语法 | 功能描述 |
|---|---|
| yy | 复制光标当前一行 |
| y 数字 y或 (n) yy | 复制一段(从第几行到第几行) |
| y + shift+4($) | 复制当前光标位置到行末位置的内容 |
| p | 箭头移动到目的行粘贴 |
| (n)p | 箭头移动到目的行粘贴n行 |
| u | 撤销上一步 |
| dd | 删除光标当前行 |
| d 数字 d | 删除光标(含)后多少行 |
| x | 剪切一个字母,相当于 del |
| X | 剪切一个字母,相当于 Backspace |
| r | 修改当前光标位置处的字母 |
| R | 修改当前光标所在行的内容 |
| w | 切换词后移(光标在词头) |
| e | 切换词后移(光标在词尾) |
| b | 切换词前移 |
| yw | 复制一个词 |
| dw | 删除一个词 |
| shift+6(^) | 移动到行头 |
| shift+4 ($) | 移动到行尾 |
| gg 或 shift+h | 跳转到行头 |
| 1+shift+g(G) | 移动到页头,数字 |
| shift+g(G) | 移动到页尾 |
| 数字+shift+g(G) | 移动到目标行 |
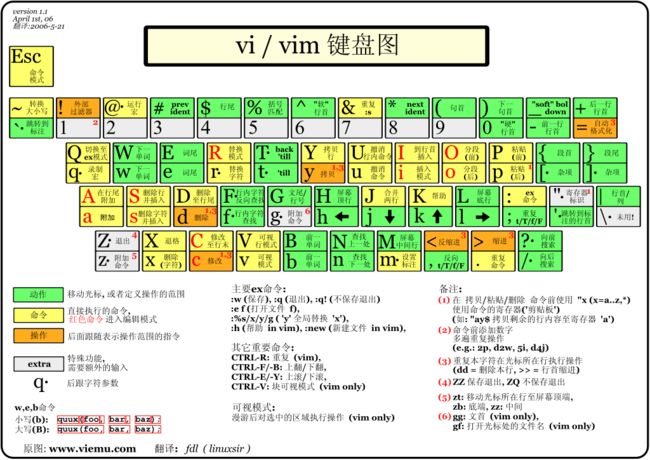
vi/vim 键盘图
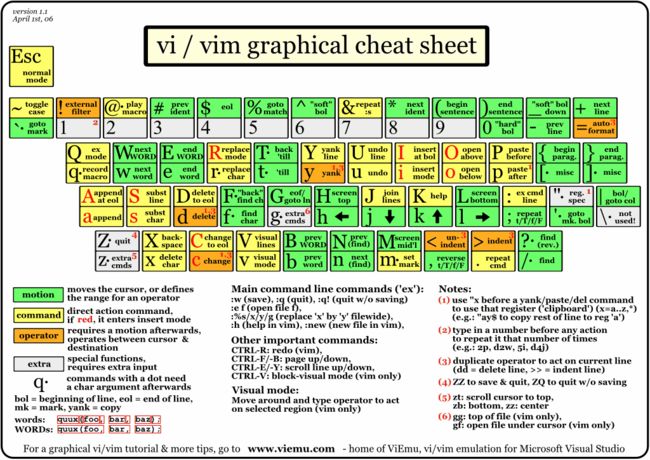
简体中文版
4.4 编辑模式
在一般模式中可以进行删除、复制、粘贴等的动作,但是却无法编辑文件内容的!
要等到你按下 加粗样式i, I, o, O, a, A 等任何一个字母之后才会进入编辑模式。
注意了!通常在Linux中,按下这些按键时,在画面的左下方会出现 INSERT或 REPLACE 的字样,此时才可以进行编辑。而如果要回到一般模式时, 则必须要按下 Esc这个按键即可退出编辑模式
①进入编辑模式
| 按键 | 功能 |
|---|---|
| i | 当前光标前 |
| a | 当前光标后 |
| o | 当前光标行的下一行 |
| I | 光标所在行最前 |
| A | 光标所在行最后 |
| O | 当前光标行的上一行 |
②退出编辑模式
按 Esc 键 退出编辑模式,之后所在的模式为一般模式
4.5 指令模式
在一般模式当中,输入『 : / ?』3个中的任何一个按钮,就可以将光标移动到最底下那
一行。
在这个模式当中, 可以提供你『搜寻资料』的动作,而读取、存盘、大量取代字符、
离开 vi 、显示行号等动作是在此模式中达成的!
(1)基本语法
| 命令 | 功能 |
|---|---|
| :w | 保存 |
| :q | 退出 |
| :! | 强制执行 |
| /要查找的词 | n 查找下一个,N 往上查找 |
| :noh | 取消高亮显示 |
| :set nu | 显示行号 |
| :set nonu | 关闭行号 |
| : s/old/new | 替换当前行匹配到的第一个old为new |
| : s/old/new/g | 替换当前行匹配到的所有old为new |
| :%s/old/new | 替换文档中行匹配到的第一个old为new |
| :%s/old/new/g | 替换文档中匹配到的所有old为new |
(2)实例操作
| :wq! | 强制保存退出 |
|---|
4.6 模式间的转换

第5章 网络配置和系统管理操作
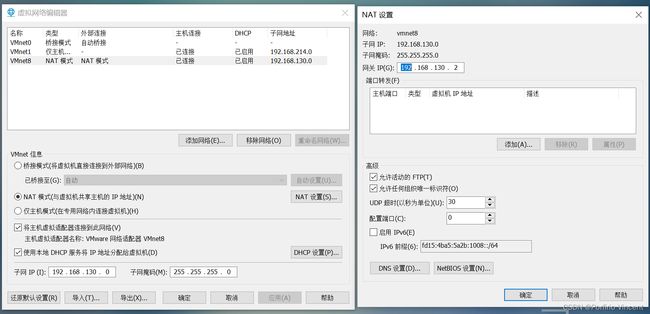
5.1 查看网络 IP 和 网关
①查看虚拟网络编辑器

②查看网关
5.2 配置网络ip地址
5.2.1 ifconfig 配置网络接口
查看当前网络ip :
[root@hadoop100 ~]# ifconfig
5.2.2 ping 测试主机之间网络连通性
测试当前服务器是否可以连接bing
[root@hadoop100 ~]# ping cn.bing.com
5.2.3 修改 IP 地址
① 查看 IP 配置文件
[root@hadoop100 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
②执行 service network restart 重启网络
[root@hadoop100 ~]# service network restart
5.3配置主机名
5.3.1 修改主机名称
①基本语法
hostname (功能描述:查看当前服务器的主机名称)
②案例实操
(1)查看当前服务器主机名称
[root@hadoop100 ~]# hostname
(2)如果感觉此主机名不合适,我们可以进行修改。通过编辑/etc/hostname 文件
[root@hadoop100 ~]# vi /etc/hostname
修改完成后重启生效。
5.3.2 修改 hosts 映射文件
修改 linux 的主机映射文件(hosts 文件)
后续在 hadoop 阶段,虚拟机会比较多,配置时通常会采用主机名的方式配置,
比较简单方便。 不用刻意记 ip 地址。
(1)打开/etc/hosts
[root@hadoop100 ~]# vim /etc/hosts

第6章系统管理
6.1 Linux中的进程和服务
计算机中,一个正在执行的程序或命令,被叫做“进程”(process)。
启动之后一只存在、常驻内存的进程,一般被称作“服务”(service)。
6.2 service 服务管理(CentOS 6 版本-了解)
1) 基本语法
service 服务名 start | stop |· restart | status
2) 经验技巧
查看服务的方法:/etc/init.d/服务名 ,发现只有两个服务保留在 service
3) 案例实操
(1)查看网络服务的状态
[root@hadoop100 桌面]#service network status
(2)停止网络服务
[root@hadoop100 桌面]#service network stop
(3)启动网络服务
[root@hadoop100 桌面]#service network start
(4)重启网络服务
[root@hadoop100 桌面]#service network restart
6.3 chkconfig 设置后台服务的自启配置(CentOS 6 版本)
1) 基本语法
chkconfig (功能描述:查看所有服务器自启配置)
chkconfig 服务名 off (功能描述:关掉指定服务的自动启动)
chkconfig 服务名 on (功能描述:开启指定服务的自动启动)
chkconfig 服务名 --list (功能描述:查看服务开机启动状态)
2) 案例实操
(1)开启/关闭 network(网络)服务的自动启动
[root@hadoop100 桌面]#chkconfig network on
[root@hadoop100 桌面]#chkconfig network off
(2)开启/关闭 network 服务指定级别的自动启动
[root@hadoop100 桌面]#chkconfig --level 指定级别 network on
[root@hadoop100 桌面]#chkconfig --level 指定级别 network off
6.4 systemctl (CentOS 7版本-重点掌握)
1) 基本语法
systemctl start | stop | restart | status 服务名
2) 经验技巧
查看服务的方法:/usr/lib/systemd/system
[root@hadoop100 ~]# pwd
/root
[root@hadoop100 ~]# /user/lib/systemd/system
-bash: /user/lib/systemd/system: 没有那个文件或目录
[root@hadoop100 ~]# ls -al
总用量 64
dr-xr-x---. 15 root root 4096 6月 22 08:50 .
dr-xr-xr-x. 17 root root 224 6月 20 15:43 ..
-rw-------. 1 root root 1889 6月 20 15:43 anaconda-ks.cfg
-rw-------. 1 root root 677 6月 22 08:50 .bash_history
-rw-r--r--. 1 root root 18 12月 29 2013 .bash_logout
-rw-r--r--. 1 root root 176 12月 29 2013 .bash_profile
-rw-r--r--. 1 root root 176 12月 29 2013 .bashrc
drwx------. 18 root root 4096 6月 20 21:34 .cache
drwxr-xr-x. 16 root root 4096 6月 20 16:59 .config
-rw-r--r--. 1 root root 100 12月 29 2013 .cshrc
drwx------. 3 root root 25 6月 20 15:51 .dbus
-rw-------. 1 root root 16 6月 20 16:51 .esd_auth
-rw-------. 1 root root 314 6月 20 16:51 .ICEauthority
-rw-r--r--. 1 root root 1920 6月 20 15:52 initial-setup-ks.cfg
drwx------. 3 root root 19 6月 20 16:51 .local
drwx------. 5 root root 66 6月 20 16:59 .mozilla
-rw-r--r--. 1 root root 129 12月 29 2013 .tcshrc
-rw-------. 1 root root 5999 6月 21 21:08 .viminfo
-rw-------. 1 root root 275 6月 22 08:50 .Xauthority
drwxr-xr-x. 2 root root 6 6月 20 16:51 公共
drwxr-xr-x. 2 root root 6 6月 20 16:51 模板
drwxr-xr-x. 2 root root 6 6月 20 16:51 视频
drwxr-xr-x. 2 root root 6 6月 20 16:51 图片
drwxr-xr-x. 2 root root 6 6月 20 16:51 文档
drwxr-xr-x. 2 root root 6 6月 20 16:51 下载
drwxr-xr-x. 2 root root 6 6月 20 16:51 音乐
drwxr-xr-x. 2 root root 100 6月 20 22:43 桌面
3)案例实操
(1)查看防火墙服务的状态
[root@hadoop100 桌面]# systemctl status firewalld
(2)停止防火墙服务
[root@hadoop100 桌面]# systemctl stop firewalld
(3)启动防火墙服务
[root@hadoop100 桌面]# systemctl start firewalld
(4)重启防火墙服务
[root@hadoop100 桌面]# systemctl restart firewalld
6.5 systemctl 设置后台服务的自启配置
1)基本语法
systemctl list-unit-files (功能描述:查看服务开机启动状态)
systemctl disable service_name (功能描述:关掉指定服务的自动启动)
systemctl enable service_name (功能描述:开启指定服务的自动启动)
2)案例实操
(1)开启/关闭 iptables(防火墙)服务的自动启动
[root@hadoop100 桌面]# systemctl enable firewalld.service
[root@hadoop100 桌面]# systemctl disable firewalld.service
6.6系统运行级别
1)Linux运行级别[CentOS 6]

2)CentOS7的运行级别简化为:
multi-user.target 等价于原运行级别 3(多用户有网,无图形界面)[Ctrl+Alt+F2]
graphical.target 等价于原运行级别 5(多用户有网,有图形界面) [Ctrl+Alt+F1]
3)查看当前运行级别:
systemctl get-default
4)修改当前运行级别
systemctl set-default TARGET.target (这里 TARGET 取 multi-user 或者 graphical)
6.7 关闭防火墙
1) 临时关闭防火墙
(1)查看防火墙状态
[root@hadoop100 桌面]# systemctl status firewalld
(2)临时关闭防火墙
[root@hadoop100 桌面]# systemctl stop firewalld
2)开机启动时关闭防火墙
(1)查看防火墙开机启动状态
[root@hadoop100 桌面]# systemctl enable firewalld.service
(2)设置开机时关闭防火墙
[root@hadoop100 桌面]# systemctl disable firewalld.service
6.8 关机重启
在 linux 领域内大多用在服务器上,很少遇到关机的操作。毕竟服务器上跑一个服务是永无止境的,除非特殊情况下,不得已才会关机。
1)基本语法
(1)sync (功能描述:将数据由内存同步到硬盘中)
(2)halt (功能描述:停机,关闭系统,但不断电)
(3)poweroff (功能描述:关机,断电)
(3)reboot (功能描述:就是重启,等同于 shutdown -r now)
(4)shutdown [选项] 时间
| 选项 | 功能 |
|---|---|
| -H | 相当于–halt,停机 |
| -h 或 -P | 关机 |
| -r | -r=reboot 重启 |
| 参数 | 功能 |
|---|---|
| now | 立刻关机 |
| 时间 | 等待多久后关机(时间单位是分钟) |
2) 经验技巧
Linux 系统中为了提高磁盘的读写效率,对磁盘采取了 “预读迟写”操作方式。当用户保存文件时,Linux 核心并不一定立即将保存数据写入物理磁盘中,而是将数据保存在缓冲区中,等缓冲区满时再写入磁盘,这种方式可以极大的提高磁盘写入数据的效率。但是, 也带来了安全隐患,如果数据还未写入磁盘时,系统掉电或者其他严重问题出现,则将导致数据丢失。使用 sync 指令可以立即将缓冲区的数据写入磁盘。
3)案例实操
(1)将数据由内存同步到硬盘中
[root@hadoop100 桌面]#sync
(2)重启
[root@hadoop100 桌面]# reboot
(3)停机(不断电)
[root@hadoop100 桌面]#halt
(4)计算机将在 1 分钟后关机,并且会显示在登录用户的当前屏幕中
[root@hadoop100 桌面]#shutdown -h 1 ‘This server will shutdown after 1 mins’
(5)立刻关机(等同于 poweroff)
[root@hadoop100 桌面]# shutdown -h now
(6)系统立刻重启(等同于 reboot)
[root@hadoop100 桌面]# shutdown -r now
第 7 章 常用基本命令(重要)
Shell 可以看作是一个命令解释器,为我们提供了交互式的文本控制台界面。我们可以通过终端控制台来输入命令,由 shell 进行解释并最终交给内核执行。
常用的基本 shell 命令。
7.1 帮助命令
7.1.1 man 获得帮助信息
1)基本语法
man [命令或配置文件] (功能描述:获得帮助信息)
2)显示说明
| 信息 | 功能 |
|---|---|
| NAME | 命令的名称和单行描述 |
| SYNOPSIS | 怎样使用命令 |
| DESCRIPTION | 命令功能的深入讨论 |
| EXAMPLES | 怎样使用命令的例子 |
| SEE ALSO | 相关主题(通常是手册页) |
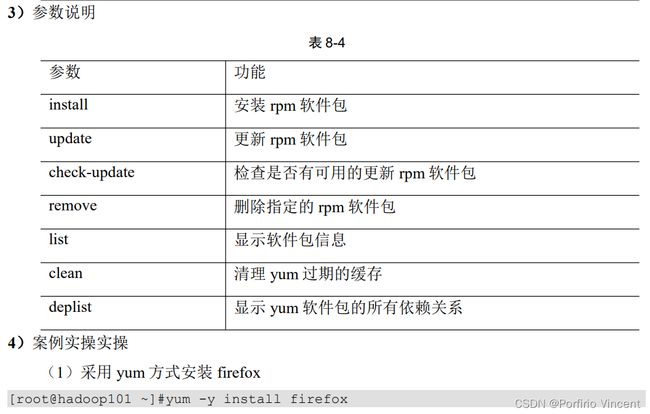
3)案例实操
(1)查看 ls 命令的帮助信息
[root@hadoop101 ~]# man ls
7.1.2 help 获得 shell 内置命令的帮助信息
一部分基础功能的系统命令是直接内嵌在 shell 中的,系统加载启动之后会随着 shell 一起加载,常驻系统内存中。这部分命令被称为“内置(built-in)命令”;相应的其它命令 被称为“外部命令”。
使用 type 可以判断当前命令是内置命令还是外部命令
使用方法: type 命令
[root@hadoop100 ~]# type ls
ls 是 `ls --color=auto' 的别名
[root@hadoop100 ~]# type history
history 是 shell 内嵌
1)基本语法
help 命令(功能描述:获得 shell 内置命令的帮助信息)
2)案例实操
(1)查看 cd 命令的帮助信息
[root@hadoop101 ~]# help cd
7.1.3 常用快捷键
| 常用快捷键 | 功能 |
|---|---|
| ctrl + c | 停止进程 |
| ctrl+l | 清屏,等同于 clear;彻底清屏是:reset |
| 善于用 tab 键 | 提示(更重要的是可以防止敲错) |
| 上下键 | 查找执行过的命令 |
xshell中清屏的快捷键:
清屏:Ctrl+Shift+I (相当于翻页,历史日志保留)
滚动缓冲区清除:Ctrl+Shift+b (只保留当前显示的日志,在滚动条上方的历史被清除)
屏幕和滚动区清除:Ctrl+Shift+a (日志全部清空,且当前页面显示空白)
7.2 文件目录类
7.2.1 pwd 显示当前工作目录的绝对路径
pwd : print working directory 打印工作目录
1)基本语法
pwd (功能描述:显示当前工作目录的绝对路径)
2)案例实操
(1)显示当前工作目录的绝对路径
[root@hadoop100 ~]# pwd
/root
7.2.2 ls 列出目录的内容
ls : list 列出目录内容
1)基本语法
ls [选项] [目录或是文件]
2)选项说明
| 选项 | 功能 |
|---|---|
| -a | 全部的文件,连同隐藏档( 开头为 . 的文件) 一起列出来(常用) |
| -l | 长数据串列出,包含文件的属性与权限等等数据;(常用)等价于“ll” |
3)显示说明
每行列出的信息依次是: 文件类型与权限 链接数 文件属主 文件属组 文件大小用byte
来表示 建立或最近修改的时间 名字
4)案例实操
(1)查看当前目录的所有内容信息
[atguigu@hadoop101 ~]$ ls -al
7.2.3 cd 切换目录
cd : Change Directory 切换路径
1)基本语法
cd [参数]
2)参数说明
| 参数 | 功能 |
|---|---|
| cd 绝对路径 | 切换路径 |
| cd 相对路径 | 切换路径 |
| cd ~或者 cd | 回到自己的家目录 |
| cd - | 回到上一次所在目录 |
| cd … | 回到当前目录的上一级目录 |
| cd -P | 跳转到实际物理路径,而非快捷方式路径 |
3)案例实操
(1)使用绝对路径切换到 root 目录
[root@hadoop101 ~]# cd /root/
(2)使用相对路径切换到“公共的”目录
[root@hadoop101 ~]# cd 公共的/
(3)表示回到自己的家目录,亦即是 /root 这个目录
[root@hadoop101 公共的]# cd ~
(4)cd- 回到上一次所在目录
[root@hadoop101 ~]# cd -
(5)表示回到当前目录的上一级目录,亦即是 “/root/公共的”的上一级目录的意思;
[root@hadoop101 公共的]# cd ..
7.2.4 mkdir 创建一个新的目录
mkdir: Make directory 建立目录
1)基本语法
mkdir [选项] 要创建的目录
2)选项说明
| 选项 | 功能 |
|---|---|
| -p | 创建多层目录 |
3)案例实操
(1)创建一个目录
[root@hadoop101 ~]# mkdir xiyou
[root@hadoop101 ~]# mkdir xiyou/mingjie
(2)创建一个多级目录
[root@hadoop101 ~]# mkdir -p xiyou/dssz/meihouwang
7.2.5 rmdir 删除一个空的目录
rmdir: Remove directory 移除目录
1)基本语法
rmdir 要删除的空目录
2)案例实操
(1)删除一个空的文件夹
[root@hadoop101 ~]# rmdir xiyou/dssz/meihouwang
7.2.6 touch 创建空文件
1)基本语法
touch 文件名称
2)案例实操
[root@hadoop101 ~]# touch xiyou/dssz/sunwukong.txt
7.2.7 cp 复制文件或目录
1)基本语法
cp [选项] source dest (功能描述:复制source文件到dest)
2)选项说明
| 选项 | 功能 |
|---|---|
| -r | 递归复制整个文件夹 |
3)参数说明
| 参数 | 功能 |
|---|---|
| source | 源文件 |
| dest | 目标文件 |
4)经验技巧
强制覆盖不提示的方法:\cp
[root@hadoop100 ~]# \cp initial-setup-ks.cfg user/document/my.txt
5)案例实操
(1)复制文件
[root@hadoop100 ~]# cp initial-setup-ks.cfg user/document/my.txt
cp:是否覆盖"user/document/my.txt"? y
(2)递归复制整个文件夹
[root@hadoop101 ~]# cp -r xiyou/dssz/ ./
7.2.8 rm 删除文件或目录
1)基本语法
rm [选项] deleteFile (功能描述:递归删除目录中所有内容)
2)选项说明
| 选项 | 功能 |
|---|---|
| -r | 递归删除目录中所有内容 |
| -f | 强制执行删除操作,而不提示用于进行确认。 |
| -v | 显示指令的详细执行过程 |
3)案例实操
(1)删除目录中的内容
[root@hadoop101 ~]# rm xiyou/mingjie/sunwukong.txt
[root@hadoop100 ~]# rm user/document/initial-setup-ks.cfg
rm:是否删除普通文件 "user/document/initial-setup-ks.cfg"?y
(2)递归删除目录中所有内容
[root@hadoop101 ~]# rm -rf dssz/
[root@hadoop100 ~]# \rm -r a
7.2.9 mv 移动文件与目录或重命名
1)基本语法
(1) mv oldNameFile newNameFile
(功能描述:重命名)
(2) mv /temp/movefile /targetFolder
(功能描述:移动文件,移动后就没有了)
[root@hadoop100 ~]# mv yang.py user/document/
2)案例实操
(1)重命名
[root@hadoop101 ~]# mv xiyou/dssz/suwukong.txt xiyou/dssz/houge.txt
(2)移动文件
[root@hadoop101 ~]# mv xiyou/dssz/houge.txt ./
7.2.10 cat 查看文件内容
查看文件内容,从第一行开始显示。
1)基本语法
cat [选项] 要查看的文件
2)选项说明
| 选项 | 功能描述 |
|---|---|
| -n | 显示所有行的行号,包括空行。 |
3)经验技巧
一般查看比较小的文件,一屏幕能显示全的。
4)案例实操
(1)查看文件内容并显示行号
[atguigu@hadoop101 ~]$ cat -n houge.txt
7.2.11 more 文件内容分屏查看器
more 指令是一个基于 VI 编辑器的文本过滤器,它以全屏幕的方式按页显示文本文件
的内容。more 指令中内置了若干快捷键,详见操作说明。
1)基本语法
more 要查看的文件
2)操作说明
| 操作 | 功能说明 |
|---|---|
| 空白键 (space) | 代表向下翻一页 |
| Enter | 代表向下翻『一行』 |
| q | 代表立刻离开 more ,不再显示该文件内容 |
| Ctrl+F | 向下滚动一屏 |
| Ctrl+B | 返回上一屏 |
| = | 输出当前行的行号 |
| :f | 输出文件名和当前行的行号 |
3)案例实操
(1)采用more查看文件
[root@hadoop101 ~]# more smartd.conf
7.2.12 less 分屏显示文件内容
less 指令用来分屏查看文件内容,它的功能与 more 指令类似,但是比 more 指令更加
强大,支持各种显示终端。less 指令在显示文件内容时,并不是一次将整个文件加载之后 才显示,而是根据显示需要加载内容,对于显示大型文件具有较高的效率。
1)基本语法
less 要查看的文件
2)操作说明
| 操作 | 功能说明 |
|---|---|
| 空白键 | 向下翻动一页 |
| [pagedown] | 向下翻动一页 |
| [pageup] | 向上翻动一页 |
| /字串 | 向下搜寻『字串』的功能;n:向下查找;N:向上查找 |
| ?字串 | 向上搜寻『字串』的功能;n:向上查找;N:向下查找 |
| q | 离开 less 这个程序 |
3)经验技巧
用SecureCRT时[pagedown]和[pageup]可能会出现无法识别的问题。
4)案例实操
(1)采用less查看文件
[root@hadoop101 ~]# less smartd.conf
7.2.13 echo
echo 输出内容到控制台
1)基本语法
echo [选项] [输出内容]
选项: -e: 支持反斜线控制的字符转换
| 控制字符 | 作用 |
|---|---|
| \ | 输出\本身 |
| \n | 换行符 |
| \t | 制表符,也就是 Tab 键 |
2)案例实操
[root@hadoop100 ~]$ echo “hello\tworld”
hello\tworld
[root@hadoop100 ~]$ echo -e “hello\tworld”
hello world
7.2.14 head 显示文件头部内容
head 用于显示文件的开头部分内容,默认情况下 head 指令显示文件的前 10 行内容。
1)基本语法
head 文件 (功能描述:查看文件头10行内容)
head -n 5 文件 (功能描述:查看文件头5行内容,5可以是任意行数)
2)选项说明
| 选项 | 功能 |
|---|---|
| -n<行数> | -n<行数> |
3)案例实操
(1)查看文件的头2行
[root@hadoop101 ~]# head -n 2 smartd.conf
7.2.15 tail 输出文件尾部内容
tail 用于输出文件中尾部的内容,默认情况下 tail 指令显示文件的后 10 行内容。
1) 基本语法
(1)tail 文件
(功能描述:查看文件尾部10行内容)
(2)tail -n 5 文件
(功能描述:查看文件尾部5行内容,5可以是任意行数)
(3)tail -f 文件 (常用)
(功能描述:实时追踪该文档的所有更新) Ctrl+S(暂停监控)Ctrl+Q(开启监控)Ctrl+C(退出监控)
2) 选项说明
| 选项 | 功能 |
|---|---|
| -n<行数> | 输出文件尾部 n 行内容 |
| -f | 显示文件最新追加的内容,监视文件变化 |
3)案例实操
(1)查看文件尾 1 行内容
[root@hadoop101 ~]# tail -n 1 smartd.conf
(2)实时追踪该档的所有更新
[root@hadoop101 ~]# tail -f houge.txt
7.2.16 > 输出重定向和 >> 追加
1)基本语法
(1)ls -l > 文件
(功能描述:列表的内容写入文件 a.txt 中(覆盖写))
(2)ls -al >> 文件
(功能描述:列表的内容追加到文件 aa.txt 的末尾)
(3)cat 文件 1 > 文件 2
(功能描述:将文件 1 的内容覆盖到文件 2)
(4)echo “内容” >> 文件
2)案例实操
(1)将 ls 查看信息写入到文件中
[root@hadoop100 ~]# ls -l>houge.txt
(2)将 ls 查看信息追加到文件中
[root@hadoop100 ~]# ls -l>>houge.txt
(3)采用 echo 将 hello 单词追加到文件中
[root@hadoop100 ~]# echo hello>>houge.txt
[root@hadoop100 ~] #echo $ (显示所有的目录)
7.2.17 ln 软链接
软链接也称为符号链接,类似于 windows 里的快捷方式,有自己的数据块,主要存放了链接其他文件的路径。
1)基本语法
ln -s [原文件或目录] [软链接名] (功能描述:给原文件创建一个软链接)
2)经验技巧
删除软链接: rm -rf 软链接名,而不是 rm -rf 软链接名/
如果使用 rm -rf 软链接名/ 删除,会把软链接对应的真实目录下内容删掉
查询:通过 ll 就可以查看,列表属性第 1 位是 l,尾部会有位置指向。
3)案例实操
(1)创建软连接
[root@hadoop100 ~]# ls
anaconda-ks.cfg Info initial-setup-ks.cfg miss user y.py 公共 模板 视频 图片 文档 下载 音乐 桌面
[root@hadoop100 ~]# vim Info
[root@hadoop100 ~]# cd user/document/
[root@hadoop100 document]# ln -s /root/Info myInfo
[root@hadoop100 document]# ls
hello.txt myInfo my.txt myu.txt

[root@hadoop101 ~]# mv houge.txt xiyou/dssz/
[root@hadoop101 ~]# ln -s xiyou/dssz/houge.txt ./houzi
[root@hadoop101 ~]# ll
(2)删除软连接(注意不要写最后的/)
[root@hadoop101 ~]# rm -rf houzi
[root@hadoop100 ~]# \rm Info
[root@hadoop100 ~]# ls
anaconda-ks.cfg initial-setup-ks.cfg miss user y.py 公共 模板 视频 图片 文档 下载 音乐 桌面
(3)进入软连接实际物理路径
[root@hadoop101 ~]# ln -s xiyou/dssz/ ./dssz
[root@hadoop101 ~]# cd -P dssz/
软链接
| 序 号 | 命令 | 作用 |
|---|---|---|
| 01 | ln -s 被链接的源文件 链接文件 | 建立文件的软链接,用通俗的方式讲类似于 Windows 下的快捷方式 |
注意:
- 没有 -s 选项建立的是一个 硬链接文件两个文件占用相同大小的硬盘空间,工作中几乎不会建立文件的硬链接
- 源文件要使用绝对路径,不能使用相对路径,这样可以方便移动链接文件后,仍然能够正常使用
演练目标
- 将桌面目录下的 01.py 移动到 demo/b/c 目录下
- 在桌面目录下新建 01.py 的 软链接 FirstPython分别使用 相对路径 和 绝对路径 建立 FirstPython 的软链接
- 将 FirstPython 移动到 demo 目录下,对比使用 相对路径 和 绝对路径 的区别
硬链接简介(知道)
在使用 ln 创建链接时,如果没有 -s 选项,会创建一个 硬链接,而不是软链接
- 在 ~/Desktop/demo 目录下建立 ~/Desktop/demo/b/c/01.py 的硬链接 01_hard
- 使用 ls -l 查看文件的硬链接数(硬链接——有多少种方式可以访问文件或者目录)
- 删除 ~/Desktop/demo/b/c/01.py ,并且使用 tree 来确认 demo 目录下的三个链接文件文件软硬链接的示意图
- 文件软硬链接示意图
硬链接演练
- 在 ~/Desktop/demo 目录下建立 ~/Desktop/demo/b/c/01.py 的硬链接 01_hard
- 使用 ls -l 查看文件的硬链接数(硬链接——有多少种方式可以访问文件或者目录)
- 删除 ~/Desktop/demo/b/c/01.py ,并且使用 tree 来确认 demo 目录下的三个链接文件文件软硬链接的示意图
文件软硬链接示意图

在 Linux 中,文件名 和 文件的数据 是分开存储的
提示:
在 Linux 中,只有文件的 硬链接数 == 0 才会被删除
使用 ls -l 可以查看一个文件的硬链接的数量
在日常工作中,几乎不会建立文件的硬链接,知道即可
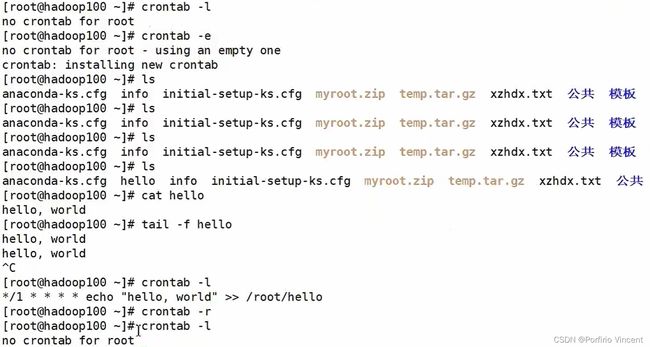
7.2.18 history 查看已经执行过历史命令
1)基本语法
history (功能描述:查看已经执行过历史命令)
2)案例实操
(1)查看已经执行过的历史命令
[root@hadoop100 ~]# history
7.3 时间日期类
1)基本语法
date [OPTION]… [+FORMAT]
2)选项说明
| 选项 | 功能 |
|---|---|
| -d<时间字符串> | 显示指定的“时间字符串”表示的时间,而非当前时间 |
| -s<日期时间> | 设置系统日期时间 |
3)参数说明
| 参数 | 功能 |
|---|---|
| <+日期时间格式> | 指定显示时使用的日期时间格式 |
7.3.1 date 显示当前时间
1)基本语法
(1)date
(功能描述:显示当前时间)
[root@hadoop100 ~]# date
2022年 06月 23日 星期四 19:43:48 CST
(2)date +%Y
(功能描述:显示当前年份)
[root@hadoop100 ~]# date +%Y
2022
(3)date +%m
(功能描述:显示当前月份)
(4)date +%d
(功能描述:显示当前是哪一天)
(5)date “+%Y-%m-%d %H:%M:%S”
(功能描述:显示年月日时分秒)
2)案例实操
(1)显示当前时间信息
[root@hadoop101 ~]# date
2022 年 06 月 19 日 星期日 20:53:30 CST
(2)显示当前时间年月日
[root@hadoop101 ~]# date +%Y%m%d
20220619
(3)显示当前时间年月日时分秒
[root@hadoop101 ~]# date "+%Y-%m-%d %H:%M:%S"
2022-06-19 20:54:58
(4)显示当前时间对应的时间戳
[root@hadoop100 ~]# date +%s
1655984979
7.3.2 date 显示非当前时间
1)基本语法
(1)date -d ‘1 days ago’
(功能描述:显示前一天时间)
(2)date -d ‘-1 days ago’
(功能描述:显示明天时间)
2)案例实操
(1)显示前一天
[root@hadoop101 ~]# date -d '1 days ago'
2022 年 06 月 18 日 星期六 21:07:22 CST
(2)显示明天时间
[root@hadoop101 ~]#date -d '-1 days ago'
2022 年 06 月 20 日 星期六 21:07:22 CST
7.3.3 date 设置系统时间
1)基本语法
date -s 字符串时间
2)案例实操
(1)设置系统当前时间
[root@hadoop101 ~]# date -s "2022-06-19 20:52:18"
7.3.4 cal 查看日历
1)基本语法
cal [选项] (功能描述:不加选项,显示本月日历)
2)选项说明
| 选项 | 功能 |
|---|---|
| 具体某一年 | 显示这一年的日历 |
3)案例实操
(1)查看当前月的日历
[root@hadoop100 ~]# cal
(2)查看 2022 年的日历
[root@hadoop100 ~]# cal 2022
(3)查看当前年份的全部日历
[root@hadoop100 ~]# cal -y
7.4 用户管理命令
7.4.1 useradd 添加新用户
1)基本语法
useradd 用户名 (功能描述:添加新用户)
useradd -g 组名 用户名 (功能描述:添加新用户到某个组)
2)案例实操
(1)添加一个用户
[root@hadoop100 ~]# useradd yfa
[root@hadoop100 ~]#ll /home/
7.4.2 passwd 设置用户密码
1)基本语法
passwd 用户名 (功能描述:设置用户密码)
2)案例实操
(1)设置用户的密码
[root@hadoop100 ~]# passwd yfa
7.4.3 id 查看用户是否存在
1)基本语法
id 用户名
2)案例实操
(1)查看用户是否存在
[root@hadoop101 ~]#id yfa
7.4.4 cat /etc/passwd 查看创建了哪些用户
1)案例实操
[root@hadoop101 ~]# cat /etc/passwd
7.4.5 su 切换用户
su: swith user 切换用户
1)基本语法
su 用户名称 (功能描述:切换用户,只能获得用户的执行权限,不能获得环境变量)
su - 用户名称 (功能描述:切换到用户并获得该用户的环境变量及执行权限)
2)案例实操
(1)切换用户
[root@hadoop101 ~]#su yfa
[root@hadoop101 ~]#echo $PATH
/usr/lib64/qt3.3/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
[root@hadoop101 ~]#exit
[root@hadoop101 ~]#su - yfa
[root@hadoop101 ~]#echo $PATH
/usr/lib64/qt3.3/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/yfa/bin
7.4.6 userdel 删除用户
1)基本语法
(1)userdel 用户名 (功能描述:删除用户但保存用户主目录)
(2)userdel -r 用户名 (功能描述:用户和用户主目录,都删除)
2)选项说明
| 选项 | 功能 |
|---|---|
| -r | 删除用户的同时,删除与用户相关的所有文件。 |
3)案例实操
(1)删除用户但保存用户主目录
[root@hadoop101 ~]#userdel yfa
[root@hadoop101 ~]#ll /home/
(2)删除用户和用户主目录,都删除
[root@hadoop101 ~]#useradd zhubajie
[root@hadoop101 ~]#ll /home/
[root@hadoop101 ~]#userdel -r zhubajie
[root@hadoop101 ~]#ll /home/
7.4.7 who 查看登录用户信息
1)基本语法
(1)whoami (功能描述:显示自身用户名称)
(2)who am i (功能描述:显示登录用户的用户名以及登陆时间)
2)案例实操
(1)显示自身用户名称
[yfa@hadoop100 ~]# whoami
yfa
(2)显示登录用户的用户名
[yfa@hadoop100 ~]# who am i
root pts/1 2022-06-22 22:38 (192.168.130.1)
7.4.8 sudo 设置普通用户具有 root 权限
1)添加 atguigu 用户,并对其设置密码。
[root@hadoop101 ~]#useradd atguigu
[root@hadoop101 ~]#passwd atguigu
2)修改配置文件
[root@hadoop101 ~]#vi /etc/sudoers
修改 /etc/sudoers 文件,找到下面一行(91 行),在 root 下面添加一行,如下所示:
## Allow root to run any commands anywhere
root
ALL=(ALL)
ALL
atguigu
ALL=(ALL)
ALL
或者配置成采用 sudo 命令时,不需要输入密码
## Allow root to run any commands anywhere
root
ALL=(ALL)
ALL
atguigu
ALL=(ALL)
NOPASSWD:ALL
修改完毕,现在可以用 atguigu 帐号登录,然后用命令 sudo ,即可获得 root 权限进行
操作。
3)案例实操
(1)用普通用户在/opt 目录下创建一个文件夹
[atguigu@hadoop101 opt]$ sudo mkdir module
[root@hadoop101 opt]# chown atguigu:atguigu module/
7.4.9 usermod 修改用户
1)基本语法
usermod -g 用户组 用户名
2)选项说明
| 选项 | 功能 |
|---|---|
| -g | 修改用户的初始登录组,给定的组必须存在。默认组 id 是 1。 |
3)案例实操
(1)将用户加入到用户组
[root@hadoop101 opt]# usermod -g root zhubajie
7.5 用户组管理命令
每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理。不同 Linux 系统对用户组的规定有所不同, 如Linux下的用户属于与它同名的用户组,这个用户组在创建用户时同时创建。 用户组的管理涉及用户组的添加、删除和修改。组的增加、删除和修改实际上就是对 /etc/group文件的更新。
7.5.1 groupadd 新增组
1)基本语法
groupadd 组名
2)案例实操
(1)添加一个xitianqujing组
[root@hadoop101 opt]#groupadd xitianqujing
7.5.2 groupdel 删除组
1)基本语法
groupdel 组名
2)案例实操
(1)删除xitianqujing组
[root@hadoop101 opt]# groupdel xitianqujing
7.5.3 groupmod 修改组
1)基本语法
groupmod -n 新组名 老组名
2)选项说明
| 选项 | 功能描述 |
|---|---|
| -n<新组名> | 指定工作组的新组名 |
3)案例实操
(1)修改atguigu组名称为atguigu1
[root@hadoop101 ~]#groupadd xitianqujing
7.5.4 cat /etc/group 查看创建了哪些组
1)基本操作
[root@hadoop101 atguigu]# cat /etc/group
7.6 文件权限相关命令
7.6.1组管理
提示:创建组 / 删除组 的终端命令都需要通过 sudo 执行
| 序号 | 命令 | 作用 |
|---|---|---|
| 01 | groupadd 组名 | 添加组 |
| 02 | groupdel 组名 | 删除组 |
| 03 | cat /etc/group | 确认组信息 |
| 04 | chgrp -R 组名 文件/目录名 | 递归修改文件/目录的所属组 |
提示:
组信息保存在 /etc/group 文件中
/etc 目录是专门用来保存 系统配置信息 的目录
7.6.2用户管理
提示:创建用户 / 删除用户 / 修改其他用户密码 的终端命令都需要通过 sudo 执行
创建用户/设置密码/删除用户

提示:
- 创建用户时,如果忘记添加 -m 选项指定新用户的家目录 —— 最简单的方法就是删除用户,重新创建
- 创建用户时,默认会创建一个和用户名同名的组名
- 用户信息保存在 /etc/passwd 文件中
7.6.3查看用户信息
| 序号 | 命令 | 作用 |
|---|---|---|
| 01 | id [用户名] | 查看用户 UID 和 GID 信息 |
| 02 | who | 查看当前所有登录的用户列表 |
| 03 | whoami | 查看当前登录用户的账户名 |
7.6.4which(重要)
提示
- /etc/passwd 是用于保存用户信息的文件
- /usr/bin/passwd 是用于修改用户密码的程序
which 命令可以查看执行命令所在位置,例如:
which ls
# 输出
# /bin/ls
which useradd
# 输出
# /usr/sbin/useradd
7.6.5bin 和 sbin
- 在 Linux 中,绝大多数可执行文件都是保存在 /bin 、 /sbin 、 /usr/bin 、 /usr/sbin
- /bin ( binary )是二进制执行文件目录,主要用于具体应用
- /sbin ( system binary )是系统管理员专用的二进制代码存放目录,主要用于系统管理
- /usr/bin ( user commands for applications )后期安装的一些软件
- /usr/sbin ( super user commands for applications )超级用户的一些管理程序
提示:
cd 这个终端命令是内置在系统内核中的,没有独立的文件,因此用 which 无法找到 cd命令的位置
7.6.6切换用户
| 序 号 | 命令 | 作用 | 说明 |
|---|---|---|---|
| 01 | su - 用户名 | 切换用户,并且切换目录 | - 可以切换到用户家目录,否则保持位置不变 |
| 02 | exit | 退出当前登录账户 |
su 不接用户名,可以切换到 root ,但是不推荐使用,因为不安全
exit 示意图如下:
7.6.7文件属性
Linux系统是一种典型的多用户系统,不同的用户处于不同的地位,拥有不同的权限。 为了保护系统的安全性,Linux系统对不同的用户访问同一文件(包括目录文件)的权限做 了不同的规定。在Linux中我们可以使用ll或者ls -l命令来显示一个文件的属性以及文件所属 的用户和组。
1)从左到右的 10 个字符表示

如果没有权限,就会出现减号[ - ]而已。从左至右用0-9这些数字来表示:
(1)0 首位表示类型
在Linux中第一个字符代表这个文件是目录、文件或链接文件等等
- 代表文件
- d 代表目录
- l 链接文档(link file);
(2)第1-3位确定属主(该文件的所有者)拥有该文件的权限。—User
(3)第4-6位确定属组(所有者的同组用户)拥有该文件的权限,—Group
(4)第7-9位确定其他用户拥有该文件的权限 —Other
2)rwx 作用文件和目录的不同解释
(1)作用到文件:
[ r ]代表可读(read): 可以读取,查看
[ w ]代表可写(write): 可以修改,但是不代表可以删除该文件,删除一个文件的前 提条件是对该文件所在的目录有写权限,才能删除该文件
[ x ]代表可执行(execute):可以被系统执行
(2)作用到目录:
[ r ]代表可读(read): 可以读取,ls查看目录内容
[ w ]代表可写(write): 可以修改,目录内创建+删除+重命名目录
[ x ]代表可执行(execute):可以进入该目录
find命令:
find命令用来精细查找文件或目录。基本语法格式如下:
find [查找范围] [查找条件表达式]
find常用的查找条件如下:
- -name:按名称查找;根据目标文件的名称进行查找,允许使用“*”及“?”通配符;
- -size:按文件大小查找;一般使用“+”、“-”号设置超过或小于指定的大小作为查找条件。常用的容量单位包括kB(注意k是小写)、MB、GB;
- -user:按文件属主查找;
- -type:按文件类型查找;类型指的是普通文件(f)、目录(d)、块设备文件(b)、字符设备文件(c)等。
同时使用多个查找条件时,各表达式之间可以使用逻辑运算符“-a”、“-o”,分别表示而且(and)、或者(or)。
7.6.8修改文件权限
| 序号 | 命令 | 作用 |
|---|---|---|
| 01 | chown | 修改拥有者 |
| 02 | chgrp | 修改组 |
| 03 | chmod | 修改权限 |
命令格式如下:
# 修改文件|目录的拥有者
chown 用户名 文件名|目录名
# 递归修改文件|目录的组
chgrp -R 组名 文件名|目录名
# 递归修改文件权限
chmod -R 755 文件名|目录名
1、chmod 改变权限
1)基本语法

第一种方式变更权限
chmod [{ugoa}{±=}{rwx}] 文件或目录
第二种方式变更权限
chmod [mode=421 ] [文件或目录]
2)经验技巧
u:所有者 g:所有组 o:其他人 a:所有人(u、g、o 的总和)
r=4 w=2 x=1 rwx=4+2+1=7
3)案例实操
(1)修改文件使其所属主用户具有执行权限
[root@hadoop101 ~]# cp xiyou/dssz/houge.txt ./
[root@hadoop101 ~]# chmod u+x houge.txt
(2)修改文件使其所属组用户具有执行权限
[root@hadoop101 ~]# chmod g+x houge.txt
(3)修改文件所属主用户执行权限,并使其他用户具有执行权限
[root@hadoop101 ~]# chmod u-x,o+x houge.txt
(4)采用数字的方式,设置文件所有者、所属组、其他用户都具有可读可写可执行权 限。
[root@hadoop101 ~]# chmod 777 houge.txt
(5)修改整个文件夹里面的所有文件的所有者、所属组、其他用户都具有可读可写可 执行权限。
[root@hadoop101 ~]# chmod -R 777 xiyou
2、chown 改变所有者(修改第3、4列内容)
1)基本语法
chown [选项] [最终用户] [文件或目录] (功能描述:改变文件或者目录的所有 者)
2)选项说明
-R 递归操作
3)案例实操
(1)修改文件所有者
[root@hadoop101 ~]# chown root:root houge.txt
[root@hadoop101 ~]# chown yfa houge.txt
[root@hadoop101 ~]# ls -al -rwxrwxrwx. 1 atguigu root 551 5 月 23 13:02 houge.txt
(2)递归改变文件所有者和所有组
[root@hadoop101 xiyou]# ll drwxrwxrwx. 2 root root 4096 9 月 3 21:20 xiyou
[root@hadoop101 xiyou]# chown -R atguigu:atguigu xiyou/
[root@hadoop101 xiyou]# ll drwxrwxrwx. 2 atguigu atguigu 4096 9 月 3 21:20 xiyou
3、chgrp 改变所属组
1)基本语法
chgrp [最终用户组] [文件或目录] (功能描述:改变文件或者目录的所属组)
2)案例实操
(1)修改文件的所属组
[root@hadoop101 ~]# chgrp root houge.txt
[root@hadoop101 ~]# ls -al -rwxrwxrwx. 1 atguigu root 551 5 月 23 13:02 houge.
7.6.8综合应用
(1)创建组,并创建分配组内人员
[root@hadoop100 ~]# groupadd bigdata
[root@hadoop100 ~]# groupadd testing
[root@hadoop100 ~]# useradd -g bigdata tom
[root@hadoop100 ~]# id tom
uid=1001(tom) gid=1001(bigdata) 组=1001(bigdata)
[root@hadoop100 ~]# useradd -g bigdata jack
[root@hadoop100 ~]# id jack
uid=1002(jack) gid=1001(bigdata) 组=1001(bigdata)
[root@hadoop100 ~]# useradd -g testing jersey
[root@hadoop100 ~]# id jersey
uid=1003(jersey) gid=1002(testing) 组=1002(testing)
[root@hadoop100 ~]# useradd -g testing mark
[root@hadoop100 ~]# id mark
uid=1004(mark) gid=1002(testing) 组=1002(testing)
(2)组内人员创建一个放在个人主目录下的文件(组内人员和其他人员都只能读)
[root@hadoop100 home]# cd /home/
[root@hadoop100 home]# ls
jack jersey mark tom yfa
[root@hadoop100 home]# su tom
[tom@hadoop100 home]$ cd ~
[tom@hadoop100 ~]$ pwd
/home/tom
[tom@hadoop100 ~]$ vim bigdata
[tom@hadoop100 ~]$ ll
总用量 4
-rw-r--r--. 1 tom bigdata 30 6月 24 08:58 bigdata
(3)修改创建文件用户的主目录权限
①组内其他人员没有权限访问文件创始者的主目录
[jack@hadoop100 home]$ cd tom/
bash: cd: tom/: 权限不够
②tom的主目录的组内人员没有读和执行的权限
[root@hadoop100 home]# ll
总用量 0
drwx------. 5 jack bigdata 128 6月 24 09:09 jack
drwx------. 3 jersey testing 78 6月 24 08:53 jersey
drwx------. 3 mark testing 78 6月 24 08:53 mark
drwx------. 5 tom bigdata 159 6月 24 09:05 tom
drwx------. 5 yfa yfa 167 6月 23 23:35 yfa
③为tom的主目录的组内人员加上可以读和执行的权限
[root@hadoop100 home]# chmod g+rx tom/
[root@hadoop100 home]# ll
总用量 0
drwx------. 5 jack bigdata 128 6月 24 09:09 jack
drwx------. 3 jersey testing 78 6月 24 08:53 jersey
drwx------. 3 mark testing 78 6月 24 08:53 mark
drwxr-x---. 5 tom bigdata 159 6月 24 09:05 tom
drwx------. 5 yfa yfa 167 6月 23 23:35 yfa
④组内人员可以进入tom的主目录下,查看主目录下的文件(不能写入文件)
[jack@hadoop100 home]$ cd tom/
[jack@hadoop100 tom]$ cat bigdata
Welcome to our bigdata group!
(4)修改文件的权限
①修改文件的权限,使得组内用户可以进行写入
[jack@hadoop100 tom]$ exit
[root@hadoop100 home]# su tom
[tom@hadoop100 home]$ cd ~
[tom@hadoop100 ~]$ chmod g+w bigdata
[tom@hadoop100 ~]$ ll
总用量 4
-rw-rw-r--. 1 tom bigdata 30 6月 24 08:58 bigdata
②进入试验
[jack@hadoop100 home]$ cd tom/
[jack@hadoop100 tom]$ vim bigdata
③打开bigtata 文件
Welcome to our bigdata group!
Hello ,I'm jack!
~
-- 插入 --
④验证jack用户现在有读写权限
[jack@hadoop100 tom]$ cat bigdata
Welcome to our bigdata group!
Hello,I'm jack!
(5)给人员换组后,试验有没有同组的权限(可见是有的)
[root@hadoop100 ~]# id jersey
uid=1003(jersey) gid=1002(testing) 组=1002(testing)
[root@hadoop100 home]# usermod -g bigdata jersey
[root@hadoop100 home]# id jersey
uid=1003(jersey) gid=1001(bigdata) 组=1001(bigdata)
[root@hadoop100 home]# su jersey
[jersey@hadoop100 home]$ cd tom/
[jersey@hadoop100 tom]$ cat bigdata
Welcome to our bigdata group!
Hello,I'm jack!
[jersey@hadoop100 tom]$ vim bigdata
[jersey@hadoop100 tom]$ cat bigdata
Welcome to our bigdata group!
Hello,I'm jack!
Hello,I'm jersey!I'm new coming here!
7.8.3 tar
7.9.3 lsblk 查看设备挂载情况
1)基本语法
lsblk (功能描述:查看设备挂载情况)
[root@hadoop100 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 50G 0 disk
├─sda1 8:1 0 1G 0 part /boot
├─sda2 8:2 0 4G 0 part [SWAP]
└─sda3 8:3 0 45G 0 part /
sr0 11:0 1 1024M 0 rom
2)选项说明
| 选项 | 功能 |
|---|---|
| -f | 查看详细的设备挂载情况,显示文件系统信息 |
7.9.5 mount/umount 挂载/卸载
对于Linux用户来讲,不论有几个分区,分别分给哪一个目录使用,它总归就是一个根目录、一个独立且唯一的文件结构。
Linux中每个分区都是用来组成整个文件系统的一部分,它在用一种叫做“挂载”的处理方法,它整个文件系统中包含了一整套的文件和目录,并将一个分区和一个目录联系起来, 要载入的那个分区将使它的存储空间在这个目录下获得。
1)挂载前准备(必须要有光盘或者已经连接镜像文件)
2)基本语法
mount [-t vfstype] [-o options] device dir (功能描述:挂载设备)
umount 设备文件名或挂载点 (功能描述:卸载设备)
3)参数说明
4)案例实操
(1)挂载光盘镜像文件
挂载前:
[root@hadoop100 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 50G 0 disk
├─sda1 8:1 0 1G 0 part /boot
├─sda2 8:2 0 4G 0 part [SWAP]
└─sda3 8:3 0 45G 0 part /
sr0 11:0 1 1024M 0 rom
挂载:
[root@hadoop100 ~]# mkdir /mnt/cdrom
[root@hadoop100 ~]# mount /dev/cdrom /mnt/cdrom
mount: /dev/sr0 写保护,将以只读方式挂载
挂载后:
[root@hadoop100 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 50G 0 disk
├─sda1 8:1 0 1G 0 part /boot
├─sda2 8:2 0 4G 0 part [SWAP]
└─sda3 8:3 0 45G 0 part /
sr0 11:0 1 4.4G 0 rom /mnt/cdrom
(2)卸载光盘镜像文件
[root@hadoop100 ~]# umount /mnt/cdrom
卸载挂载后:
[root@hadoop100 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 50G 0 disk
├─sda1 8:1 0 1G 0 part /boot
├─sda2 8:2 0 4G 0 part [SWAP]
└─sda3 8:3 0 45G 0 part /
sr0 11:0 1 4.4G 0 rom
5)设置开机自动挂载
[root@hadoop100 ~]# vi /etc/fstab


7.10 进程管理类
进程是正在执行的一个程序或命令,每一个进程都是一个运行的实体,都有自己的地 址空间,并占用一定的系统资源。
7.10.1 ps 查看当前系统进程状态 ps:process status 进程状态
1)基本语法
ps aux | grep xxx (功能描述:查看系统中所有进程)
ps -ef | grep xxx (功能描述:可以查看子父进程之间的关系)
2)选项说明
| 选项 | 功能 |
|---|---|
| a | 列出带有终端的所有用户的进程 |
| x | 列出当前用户的所有进程,包括没有终端的进程 |
| u | 面向用户友好的显示风格 |
| -e | 列出所有进程 |
| -u | 列出某个用户关联的所有进程 |
| -f | 显示完整格式的进程列表 |
3)功能说明
(1)ps aux 显示信息说明
USER:该进程是由哪个用户产生的
PID:进程的 ID 号
%CPU:该进程占用 CPU 资源的百分比,占用越高,进程越耗费资源;
%MEM:该进程占用物理内存的百分比,占用越高,进程越耗费资源;
VSZ:该进程占用虚拟内存的大小,单位 KB;
RSS:该进程占用实际物理内存的大小,单位 KB;
TTY:该进程是在哪个终端中运行的。对于 CentOS 来说,tty1 是图形化终端;
tty2-tty6 是本地的字符界面终端。pts/0-255 代表虚拟终端。
STAT:进程状态。
常见的状态有:
R:运行状态、S:睡眠状态、T:暂停状态、 Z:僵尸状态、
s:包含子进程、l:多线程、+:前台显示 、 START:该进程的启动时间
TIME:该进程占用 CPU 的运算时间,注意不是系统时间
COMMAND:产生此进程的命令名
(2)ps -ef 显示信息说明
UID:用户 ID
PID:进程 ID
PPID:父进程 ID
C:CPU 用于计算执行优先级的因子。
数值越大,表明进程是 CPU 密集型运算, 执行优先级会降低;数值越小,表明进 程是 I/O 密集型运算,执行优先级会提高
STIME:进程启动的时间
TTY:完整的终端名称
TIME:CPU 时间
CMD:启动进程所用的命令和参数
4)经验技巧
如果想查看进程的 CPU 占用率和内存占用率,可以使用 aux;
如果想查看进程的父进程 ID 可以使用 ef;
5)案例实操
[root@hadoop100 ~]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 194080 7148 ? Ss 6月22 0:15 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
root 2 0.0 0.0 0 0 ? S 6月22 0:00 [kthreadd]
root 4 0.0 0.0 0 0 ? S< 6月22 0:00 [kworker/0:0H]
root 6 0.0 0.0 0 0 ? S 6月22 0:02 [ksoftirqd/0]
root 7 0.0 0.0 0 0 ? S 6月22 0:00 [migration/0]
root 8 0.0 0.0 0 0 ? S 6月22 0:00 [rcu_bh]
root 9 0.0 0.0 0 0 ? S 6月22 1:01 [rcu_sched]
root 10 0.0 0.0 0 0 ? S< 6月22 0:00 [lru-add-drain]
root 11 0.0 0.0 0 0 ? S 6月22 0:20 [watchdog/0]
………………
7.10.2 kill 终止进程
1)基本语法
kill [选项] 进程号 (功能描述:通过进程号杀死进程)
killall 进程名称 (功能描述:通过进程名称杀死进程,也支持通配符,这在系统因负载过大而变得很慢时很有用)
2)选项说明
| 选项 | 功能 |
|---|---|
| -9 | 表示强迫进程立即停止 |
3)案例实操
(1)杀死浏览器进程
[root@hadoop101 桌面]# kill -9 5102
(2)通过进程名称杀死进程
[root@hadoop101 桌面]# killall firefox
7.10.3 pstree 查看进程树
1)基本语法
pstree [选项]
2)选项说明
| 选项 | 功能 |
|---|---|
| -p | 显示进程的 PID |
| -u | 显示进程的所属用户 |
3)案例实操
(1)显示进程 pid
[root@hadoop101 datas]# pstree -p
(2)显示进程所属用户
[root@hadoop101 datas]# pstree -u
7.10.4 top 实时监控系统进程状态
1)基本命令
top [选项]
2)选项说明
| 选项 | 功能 |
|---|---|
| -d | 秒数 指定 top 命令每隔几秒更新。默认是 3 秒在 top 命令的交互模式当 中可以执行的命令 |
| -i | 使 top 不显示任何闲置或者僵 |
| -p | 通过指定监控进程 ID 来仅仅监控某个进程的状态。 |









复制虚拟机
[root@hadoop100 ~]# ifconfig
ens33: flags=4163 mtu 1500
inet 192.168.130.100 netmask 255.255.255.0 broadcast 192.168.130.255
inet6 fe80::1fa7:9ff0:2147:60a0 prefixlen 64 scopeid 0x20
ether 00:0c:29:b9:5f:4f txqueuelen 1000 (Ethernet)
RX packets 101 bytes 18099 (17.6 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 98 bytes 11197 (10.9 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73 mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10
loop txqueuelen 1000 (Local Loopback)
RX packets 32 bytes 2592 (2.5 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 32 bytes 2592 (2.5 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
virbr0: flags=4099 mtu 1500
inet 192.168.122.1 netmask 255.255.255.0 broadcast 192.168.122.255
ether 52:54:00:7f:77:8b txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@hadoop100 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
[root@hadoop100 ~]# systemctl status network
● network.service - LSB: Bring up/down networking
Loaded: loaded (/etc/rc.d/init.d/network; bad; vendor preset: disabled)
Active: active (exited) since 五 2022-06-24 16:42:12 CST; 6min ago
Docs: man:systemd-sysv-generator(8)
Process: 930 ExecStart=/etc/rc.d/init.d/network start (code=exited, status=0/SUCCESS)
Tasks: 0
6月 24 16:42:11 hadoop100 systemd[1]: Starting LSB: Bring up/down networking...
6月 24 16:42:12 hadoop100 network[930]: 正在打开环回接口: [ 确定 ]
6月 24 16:42:12 hadoop100 network[930]: 正在打开接口 ens33: [ 确定 ]
6月 24 16:42:12 hadoop100 systemd[1]: Started LSB: Bring up/down networking.
[root@hadoop100 ~]# systemctl status NetworkManager
● NetworkManager.service - Network Manager
Loaded: loaded (/usr/lib/systemd/system/NetworkManager.service; enabled; vendor preset: enabled)
Active: active (running) since 五 2022-06-24 16:42:10 CST; 7min ago
Docs: man:NetworkManager(8)
Main PID: 799 (NetworkManager)
Tasks: 3
CGroup: /system.slice/NetworkManager.service
└─799 /usr/sbin/NetworkManager --no-daemon
6月 24 16:42:13 hadoop100 NetworkManager[799]: [1656060133.2695] device (virbr0-nic): state change: ip-config -...nal')
6月 24 16:42:13 hadoop100 NetworkManager[799]: [1656060133.2702] device (virbr0): state change: secondaries -> ...nal')
6月 24 16:42:13 hadoop100 NetworkManager[799]: [1656060133.2718] device (virbr0): Activation: successful, devic...ated.
6月 24 16:42:13 hadoop100 NetworkManager[799]: [1656060133.2728] device (virbr0-nic): state change: ip-check ->...nal')
6月 24 16:42:13 hadoop100 NetworkManager[799]: [1656060133.2731] device (virbr0-nic): state change: secondaries...nal')
6月 24 16:42:13 hadoop100 NetworkManager[799]: [1656060133.2747] device (virbr0-nic): Activation: successful, d...ated.
6月 24 16:42:13 hadoop100 NetworkManager[799]: [1656060133.3301] device (virbr0-nic): state change: activated -...nal')
6月 24 16:42:13 hadoop100 NetworkManager[799]: [1656060133.3322] device (virbr0): bridge port virbr0-nic was detached
6月 24 16:42:13 hadoop100 NetworkManager[799]: [1656060133.3323] device (virbr0-nic): released from master devi...irbr0
6月 24 16:42:37 hadoop100 NetworkManager[799]: [1656060157.4710] agent-manager: req[0x5585b7e7f190, :1.66/org.g...tered
Hint: Some lines were ellipsized, use -l to show in full.
[root@hadoop100 ~]# systemctl stop network
[root@hadoop100 ~]# systemctl stop NetworkManager
[root@hadoop100 ~]# ifconfig
ens33: flags=4163 mtu 1500
ether 00:0c:29:b9:5f:4f txqueuelen 1000 (Ethernet)
RX packets 203 bytes 24912 (24.3 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 127 bytes 13660 (13.3 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
virbr0: flags=4099 mtu 1500
inet 192.168.122.1 netmask 255.255.255.0 broadcast 192.168.122.255
ether 52:54:00:7f:77:8b txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@hadoop100 ~]# systemctl restart NetworkManager
[root@hadoop100 ~]# ifconfig
ens33: flags=4163 mtu 1500
inet 192.168.130.101 netmask 255.255.255.0 broadcast 192.168.130.255
inet6 fe80::1fa7:9ff0:2147:60a0 prefixlen 64 scopeid 0x20
ether 00:0c:29:b9:5f:4f txqueuelen 1000 (Ethernet)
RX packets 245 bytes 27552 (26.9 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 154 bytes 17759 (17.3 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73 mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10
loop txqueuelen 1000 (Local Loopback)
RX packets 32 bytes 2592 (2.5 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 32 bytes 2592 (2.5 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
virbr0: flags=4099 mtu 1500
inet 192.168.122.1 netmask 255.255.255.0 broadcast 192.168.122.255
ether 52:54:00:7f:77:8b txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@hadoop100 ~]# ping 192.168.1.102
PING 192.168.1.102 (192.168.1.102) 56(84) bytes of data.
64 bytes from 192.168.1.102: icmp_seq=1 ttl=128 time=0.757 ms
64 bytes from 192.168.1.102: icmp_seq=2 ttl=128 time=0.791 ms
64 bytes from 192.168.1.102: icmp_seq=3 ttl=128 time=0.709 ms
64 bytes from 192.168.1.102: icmp_seq=4 ttl=128 time=0.805 ms
64 bytes from 192.168.1.102: icmp_seq=5 ttl=128 time=0.580 ms
^C
--- 192.168.1.102 ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4005ms
rtt min/avg/max/mdev = 0.580/0.728/0.805/0.084 ms
[root@hadoop100 ~]# ping cn.bing.com
PING china.bing123.com (202.89.233.101) 56(84) bytes of data.
64 bytes from 202.89.233.101 (202.89.233.101): icmp_seq=1 ttl=128 time=38.0 ms
64 bytes from 202.89.233.101 (202.89.233.101): icmp_seq=2 ttl=128 time=35.6 ms
64 bytes from 202.89.233.101 (202.89.233.101): icmp_seq=3 ttl=128 time=35.4 ms
64 bytes from 202.89.233.101 (202.89.233.101): icmp_seq=4 ttl=128 time=36.1 ms
^C
--- china.bing123.com ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3006ms
rtt min/avg/max/mdev = 35.431/36.312/38.021/1.019 ms
[root@hadoop100 ~]# cat /etc/hostname
hadoop100
[root@hadoop100 ~]# hostnamectl set-hostname hadoop101
[root@hadoop100 ~]# cat /etc/hostname
hadoop101
[root@hadoop100 ~]#