Spring Cloud Alibaba-Sentinel--服务容错
1 高并发带来的问题
在微服务架构中,我们将业务拆分成一个个的服务,服务与服务之间可以相互调用,但是由于网络
原因或者自身的原因,服务并不能保证服务的100%可用,如果单个服务出现问题,调用这个服务就会出现网络延迟,此时若有大量的网络涌入,会形成任务堆积,最终导致服务瘫痪。
接下来,我们来模拟一个高并发的场景
1 编写java代码
@RestController
@Slf4j
public class OrderController2 {
@Autowired
private OrderService orderService;
@Autowired
private ProductService productService;
@RequestMapping("/order/prod/{pid}")
public Order order(@PathVariable("pid") Integer pid) {
log.info("接收到{}号商品的下单请求,接下来调用商品微服务查询此商品信息", pid);
//调用商品微服务,查询商品信息
Product product = productService.findByPid(pid);
log.info("查询到{}号商品的信息,内容是:{}", pid, JSON.toJSONString(product));
//模拟一次网络延时
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
//下单(创建订单)
Order order = new Order();
order.setUid(1);
order.setUsername("测试用户");
order.setPid(pid);
order.setPname(product.getPname());
order.setPprice(product.getPprice());
order.setNumber(1);
//为了不产生太多垃圾数据,暂时不做订单保存
//orderService.createOrder(order);
log.info("创建订单成功,订单信息为{}", JSON.toJSONString(order));
return order;
}
@RequestMapping("/order/message")
public String message() {
return "高并发下的问题测试";
}
}2 修改配置文件中tomcat的并发数
server:
port: 8091
tomcat:
max-threads: 10 #tomcat的最大并发值修改为10,默认是2003 接下来使用压测工具,对请求进行压力测试
下载地址https://jmeter.apache.org/
- 第一步:修改配置,并启动软件
进入bin目录,修改jmeter.properties文件中的语言支持为language=zh_CN,然后点击jmeter.bat
启动软件。

- 第二步:添加线程组

- 第三步:配置线程并发数

- 第四步:添加Http取样

- 第五步:配置取样,并启动测试
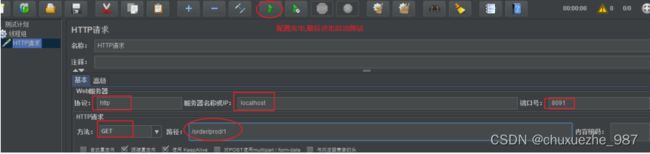
4 访问message方法观察效果
结论:
此时会发现, 由于order方法囤积了大量请求, 导致message方法的访问出现了问题,这就是服务雪
崩的雏形。
2 服务雪崩效应
在分布式系统中,由于网络原因或自身的原因,服务一般无法保证 100% 可用。如果一个服务出现了
问题,调用这个服务就会出现线程阻塞的情况,此时若有大量的请求涌入,就会出现多条线程阻塞等待,进而导致服务瘫痪。
由于服务与服务之间的依赖性,故障会传播,会对整个微服务系统造成灾难性的严重后果,这就是
服务故障的 “雪崩效应” 。

雪崩发生的原因多种多样,有不合理的容量设计,或者是高并发下某一个方法响应变慢,亦或是某台机器的资源耗尽。我们无法完全杜绝雪崩源头的发生,只有做好足够的容错,保证在一个服务发生问题,不会影响到其它服务的正常运行。也就是"雪落而不雪崩"。
3 常见容错方案
要防止雪崩的扩散,我们就要做好服务的容错,容错说白了就是保护自己不被猪队友拖垮的一些措
施, 下面介绍常见的服务容错思路和组件。
常见的容错思路
常见的容错思路有隔离、超时、限流、熔断、降级这几种,下面分别介绍一下。
(1)隔离
它是指将系统按照一定的原则划分为若干个服务模块,各个模块之间相对独立,无强依赖。当有故
障发生时,能将问题和影响隔离在某个模块内部,而不扩散风险,不波及其它模块,不影响整体的
系统服务。常见的隔离方式有:线程池隔离和信号量隔离.

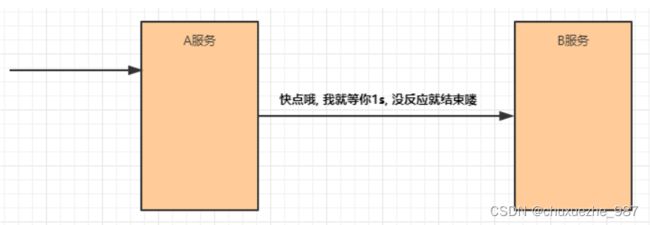
(2)超时
在上游服务调用下游服务的时候,设置一个最大响应时间,如果超过这个时间,下游未作出反应,
就断开请求,释放掉线程。
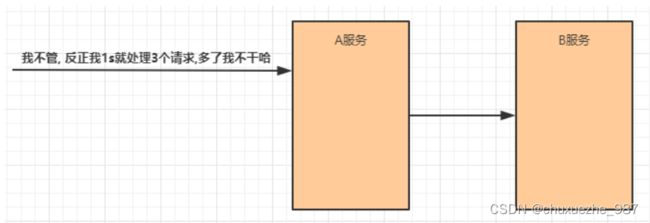
(3) 限流
限流就是限制系统的输入和输出流量已达到保护系统的目的。为了保证系统的稳固运行,一旦达到
的需要限制的阈值,就需要限制流量并采取少量措施以完成限制流量的目的。
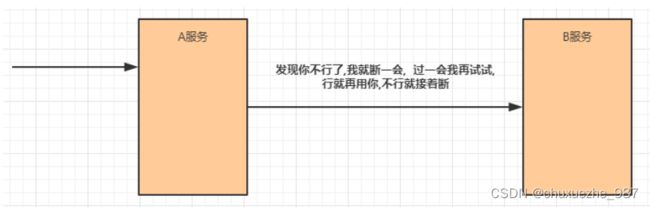
(4)熔断
在互联网系统中,当下游服务因访问压力过大而响应变慢或失败,上游服务为了保护系统整
体的可用性,可以暂时切断对下游服务的调用。这种牺牲局部,保全整体的措施就叫做熔断。
服务熔断一般有三种状态:
- 熔断关闭状态(Closed)
服务没有故障时,熔断器所处的状态,对调用方的调用不做任何限制
- 熔断开启状态(Open)
后续对该服务接口的调用不再经过网络,直接执行本地的fallback方法
- 半熔断状态(Half-Open)
尝试恢复服务调用,允许有限的流量调用该服务,并监控调用成功率。如果成功率达到预
期,则说明服务已恢复,进入熔断关闭状态;如果成功率仍旧很低,则重新进入熔断关闭状
态。
(5)降级
降级其实就是为服务提供一个托底方案,一旦服务无法正常调用,就使用托底方案。
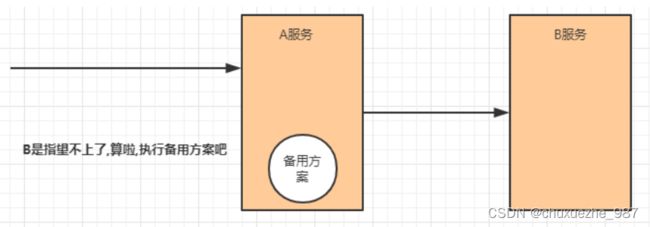
常见的容错组件
- Hystrix
Hystrix是由Netflix开源的一个延迟和容错库,用于隔离访问远程系统、服务或者第三方库,防止
级联失败,从而提升系统的可用性与容错性。
- Resilience4J
Resilicence4J一款非常轻量、简单,并且文档非常清晰、丰富的熔断工具,这也是Hystrix官方推
荐的替代产品。不仅如此,Resilicence4j还原生支持Spring Boot 1.x/2.x,而且监控也支持和
prometheus等多款主流产品进行整合。
- Sentinel
Sentinel 是阿里巴巴开源的一款断路器实现,本身在阿里内部已经被大规模采用,非常稳定。
下面是三个组件在各方面的对比:
