测开面经分享(偏Python)
某基金管理公司线下测试开发面试题总结。
预计阅读时间: 25分钟
测开题目如下
可以尝试自己先写,写完之后再去看参考解法哦 ~
1、编写一段代码,把 list 的数平方(语言不限)
ListA = [1, 3, 5, 7, 9, 11]
2、使用 Python 语言编写一个日志装饰器
3、进程、线程、协程有什么区别?
4、请画出 Selenium 框架的工作原理 (Appium 也可以)
5、落地自动化测试项目有哪几个关键节点? 请举例说明
6、请画出 Django 框架请求流程 (也就是,请求的生命周期),如果可以写出函数调用链路是怎样的?(如果未使用过 Django,可以画出你用过的框架)
7、wsgiref 作用是什么?
8、Django 有哪些中间件? 列举 5 个方法,以及中间件的应用场景?
9、请简述 WSGl/uwsgi/uwSGI 三个概念的区别是什么? 为什么有了 uWSGI 还需要 nginx?
10、请列举几种 MySQL 存储引擎,分别有什么优缺点?
11、请画出 Docker C/S 架构图
12、请使用 docker 命令操作
a) 创建一个 volume 名称为 kuma
b) 启动一个容器,名称为 yapi,后台执行,把 host 的 5000 端口映射到容器内 3000端口,并使用上面创建的 volume,挂载到/data/db 目录
同时,我也为大家准备了一份软件测试面试视频教程,就在下方,需要的可以直接去观看,也可以直接点击文末小卡片免费领取资料文档
软件测试面试视频教程观看处:
【软件测试】用300道面试题帮你上岸,每天刷一遍,让你直接入职,斩获心仪offer
解题参考如下
1、编写一段代码,把 list 的数平方(语言不限)
输入:ListA = [1, 3, 5, 7, 9, 11]
输出:[1, 9, 25, 49, 81, 121]
「java代码:」
// 方法一
import java.util.ArrayList;
import java.util.List;
public class SquareList {
public static void main(String[] args) {
List listA = new ArrayList();
listA.add(1);
listA.add(3);
listA.add(5);
listA.add(7);
listA.add(9);
listA.add(11);
List squaredList = new ArrayList();
for (int num : listA) {
squaredList.add(num * num);
}
System.out.println(squaredList);
}
}
// 方法二
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class SquareList {
public static void main(String[] args) {
List listA = Arrays.asList(1, 3, 5, 7, 9, 11);
List squaredList = listA.stream()
.map(num -> num * num)
.collect(Collectors.toList());
System.out.println(squaredList);
}
}
通过使用Java 8中引入的Stream API,可以实现更简洁的代码。在上述代码中,我们将listA转换为一个流(stream),然后使用map()操作将每个元素平方,最后通过collect()操作将结果收集到一个新的列表中。这样,我们就得到了平方后的列表并输出结果。
「go代码」
package main
import (
"fmt"
)
func main() {
listA := []int{1, 3, 5, 7, 9, 11}
squaredList := make([]int, len(listA))
for i, num := range listA {
squaredList[i] = num * num
}
fmt.Println(squaredList)
}
「python代码」
# 方法一,使用列表推导式
listA = [1, 3, 5, 7, 9, 11]
squared_list = [num**2 for num in listA]
print(squared_list) # [1, 9, 25, 49, 81, 121]
# 方法二,使用map方法
listA = [1, 3, 5, 7, 9, 11]
squared_list = list(map(lambda num: num**2, listA))
print(squared_list)
map()函数接受一个函数和一个可迭代对象作为参数,并将函数应用于可迭代对象中的每个元素
#方法三,普通for循环(这应该不是面试官想看到的,但却是最好理解的)
listA = [1, 3, 5, 7, 9, 11]
squared_list = []
for i in listA:
squared_list.append(i*i) # 写成 i**2 也是可以的
print(squared_list)
**2表示一个数的平方。
2、使用 Python 语言编写一个日志装饰器
方式一:简易版
def log_decorator(func):
def wrapper(*args, **kwargs):
print("调用函数:", func.__name__)
print("传入的参数:", args, kwargs)
result = func(*args, **kwargs)
print("函数返回结果:", result)
return result
return wrapper
@log_decorator
def add(a, b):
return a + b
result = add(3, 5)
print("最终结果:", result) # 最终结果: 8
方式一:稍微不简易版
import logging
logging.basicConfig(level=logging.INFO)
def log_decorator(func):
def wrapper(*args, **kwargs):
logger = logging.getLogger()
logger.info("调用函数: %s", func.__name__)
logger.info("传入的参数: %s %s", args, kwargs)
result = func(*args, **kwargs)
logger.info("函数返回结果: %s", result)
return result
return wrapper
@log_decorator
def add(a, b):
return a + b
result = add(3, 5)
print("最终结果:", result)
代码不做过多解释。
3、进程、线程、协程有什么区别?
进程、线程和协程是计算机中用于实现并发和并行的概念,它们之间有以下区别:
-
进程(Process):
-
进程是操作系统进行资源分配和调度的基本单位。
-
每个进程有自己独立的地址空间、堆栈和数据段,相互之间不共享内存。
-
进程之间的通信需要通过进程间通信(IPC)机制,例如管道、信号、消息队列等。
-
进程之间切换开销较大,资源占用较多。
-
进程之间是相互独立的,崩溃或异常不会影响其他进程。
-
-
线程(Thread):
-
线程是在进程内执行的独立执行流。
-
在同一进程中的线程共享资源,包括内存、文件句柄等。
-
线程之间切换开销相对较小,资源占用较少。
-
线程之间通过共享内存进行通信,但需要注意线程同步和互斥问题。
-
线程的崩溃或异常可能导致整个进程的崩溃。
-
-
协程(Coroutine):
-
协程是一种用户态的轻量级线程,也称为微线程。
-
协程的调度由程序员自己控制,可以通过yield/yield from等关键字在执行中保存和恢复上下文。
-
协程之间切换开销非常小,可以高效地执行异步操作,提高程序的并发性能。
-
协程适合处理IO密集型任务,但对于计算密集型任务,需要与多线程或多进程配合使用。
-
「什么场景适合用进程?」
计算密集型的任务(比如:大规模的数据计算和处理)
「什么场景适合用线程?」
IO密集型的任务(比如:文件读写多的,网络请求多的任务)
「什么场景适合用协程?」
IO密集型项目切要求高并发( 比如:用locust 搞压测里面就是用的协程) ,实际上真实项目中对 应高并发的业务并不会选择使用python语言。
总结来说,进程是操作系统资源分配和调度的基本单位,线程是在进程内执行的独立执行流,而协程是一种用户态的轻量级线程。它们在资源占用、切换开销以及通信方式等方面存在不同,应根据具体情况选择合适的并发实现方式。
后面我会专门写几篇进程线程协程的文章。
4、请画出 Selenium 框架的工作原理 (Appium 也可以)
「selenium工作原理」
 Selenium工作原理
Selenium工作原理
-
selenium client(python等语言编写的自动化测试脚本)初始化一个service服务,通过Webdriver启动浏览器驱动程序chromedriver.exe
-
通过RemoteWebDriver向浏览器驱动程序发送HTTP请求,浏览器驱动程序解析请求,打开浏览器,并获得sessionid,如果再次对浏览器操作需携带此id
-
打开浏览器,绑定特定的端口,把启动后的浏览器作为webdriver的remote server
-
打开浏览器后,所有的selenium的操作(访问地址,查找元素等)均通过RemoteConnection链接到remote server,然后使用execute方法调用_request方法通过urlib3向remote server发送请求
-
浏览器通过请求的内容执行对应动作
-
浏览器再把执行的动作结果通过浏览器驱动程序返回给测试脚本
「Appium工作原理」
此图高清图可以在公众号后台回复:「selenium&appium工作原理」获得
 标appium&selenium工作原理题
标appium&selenium工作原理题
5、落地自动化测试项目有哪几个关键节点? 请举例说明
这个问题非常宽泛,需要考虑的因素也很多,可以结合自己简历和工作经历进行阐述,以下为关键点参考。
1、从功能测试用例中筛选自动化测试用例
2、调研实践讨论可执行自动化测试用例
3、相关自动化方案的排期,预期,展望
3、选择自动化测试框架或自己搭建相应自动化测试框架
4、自动化脚本编写
5、持续集成与自动化构建
6、定期维护与更新
7、自动化推行(最重要)
6、请画出 Django 框架请求流程 (也就是,请求的生命周期),如果可以写出函数调用链路是怎样的?(如果未使用过 Django,可以画出你用过的框架)
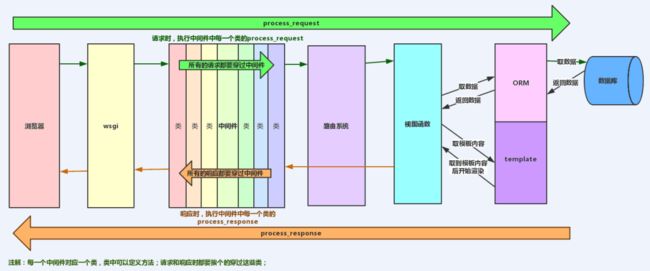
-
用户通过浏览器发送请求
-
请求到达request中间件,中间件对request请求做预处理或者直接返回response
-
若未返回response,会到达urlconf路由,找到对应视图函数
-
视图函数做相应预处理或直接返回response
-
View中的方法可以选择性的通过Models访问底层的数据
-
取到相应数据后回到django模板系统,templates通过filter或tags把数据渲染到模板上
-
返回response到浏览器展示给客户
7、wsgiref 作用是什么?
wsgiref 是 Python 标准库中的一个模块,提供了一个简单而有效的 WSGI(Web 服务器网关接口)服务器和中间件的实现。主要分为五个模块:simple_server, util, headers, handlers, validate。
wsgiref源码地址:https://pypi.python.org/pypi/wsgiref
8、Django 有哪些中间件? 列举 5 个方法,以及中间件的应用场景?
Django 提供了很多内置的中间件,用于处理请求和响应。以下是 5 个常用的中间件以及它们的应用场景:
-
SessionMiddleware:处理会话状态的中间件。它通过在请求处理过程中添加一个会话对象来支持会话管理。应用场景包括用户认证、用户状态跟踪功能。 -
AuthenticationMiddleware:处理用户身份验证的中间件。它负责在每个请求处理过程中检查用户的认证状态,并将用户的认证信息添加到请求对象中。应用场景包括用户登录、权限控制和身份验证。 -
CsrfViewMiddleware:处理跨站请求伪造(CSRF)保护的中间件。它会自动为每个 POST 请求生成 CSRF 令牌,并在提交表单时验证令牌的有效性。应用场景包括保护表单提交免受 CSRF 攻击。 -
GZipMiddleware:处理压缩响应的中间件。它在发送响应之前对内容进行 GZip 压缩,从而减小数据传输的大小。应用场景包括提高网站性能和减少带宽消耗。 -
LocaleMiddleware:处理多语言支持的中间件。它通过根据请求提供的语言首选项来设置适当的语言环境,并将其应用于请求的响应。应用场景包括多语言网站和国际化应用程序。
这些中间件提供了一系列常用的功能和处理程序,可以方便地集成到 Django 应用程序中,简化了开发人员的工作。根据具体的需求,可以根据需要启用和配置这些中间件,以实现不同的功能和处理逻辑。
9、请简述 WSGl/uwsgi/uwSGI 三个概念的区别是什么? 为什么有了 uWSGI 还需要 nginx?
WSGI
WSGI(Web Server Gateway Interface):WSGI 是一种被广泛接受和使用的 Python Web 应用程序与服务器之间的标准接口。它定义了 Web 服务器与 Web 应用程序之间的通信规则,使得服务器能够理解和与应用程序交互。WSGI 规范允许开发人员使用一种统一的方式来编写 Web 应用程序,而不用担心特定服务器的细节。
简言之,是一种描述web服务器(如nginx,uWSGI等服务器)如何与web应用程序(如用Django、Flask框架写的程序)「通信协议」。
uwsgi协议
是一个uWSGI服务器自有的协议,是一种「线路协议」而不是通信协议。它用于定义传输信息的类型(type of information),每一个uwsgi packet前4byte为传输信息类型描述,用于与nginx等代理服务器通信,它与WSGI相比是两样东西。
uwSGI
是实现了uwsgi和WSGI两种协议的「Web服务器」
为什么有了 uWSGI 还需要 nginx?
这是因为 Nginx 和 uWSGI 的角色不同。Nginx 主要作为前端服务器、反向代理和负载均衡器,它可以处理静态资源和大量并发连接,将请求转发给后端的 uWSGI 进程处理动态请求。而 uWSGI 则专注于处理 Web 应用程序的请求,它支持 WSGI 协议,负责解析并执行应用程序代码。因此,通过 Nginx 和 uWSGI 的结合,可以提高系统的性能、可靠性和安全性,并实现更好的负载均衡和更高的并发处理能力。
10、请列举几种 MySQL 存储引擎,分别有什么优缺点?
MySQL 提供了多种存储引擎,每个存储引擎都有其独特的特性和适用场景。以下是一些常见的 MySQL 存储引擎以及它们的优缺点:
-
InnoDB:
-
优点:支持事务处理和外键约束,提供高并发性能和数据完整性。具备行级锁定和多版本并发控制(MVCC)支持,适用于高并发写入和大量的读写混合场景。
-
缺点:相对于其他存储引擎,InnoDB 的存储和读取速度相对较慢。因为它支持事务和ACID特性,需要更多的磁盘空间。
-
-
MyISAM:
-
优点:具备较高的读取性能,适合于大量的只读操作和全文搜索。存储和索引数据非常紧凑,占用更少的磁盘空间。
-
缺点:不支持事务和外键约束。不具备行级锁定,只支持表级锁定,因此在并发写入场景下性能较差。容易发生表损坏,不具备故障恢复能力。
-
-
Memory(内存):
-
优点:数据完全存储在内存中,读取和写入速度非常快。适合于缓存表、临时表和高速度数据捕获等场景。
-
缺点:只能存储在内存中,断电或重启会导致数据丢失。不支持事务处理,不适合长期存储。
-
-
Archive:
-
优点:适合于归档和历史数据的存储,存储和压缩效率非常高,占用很少的磁盘空间。适合对数据进行稀疏插入和不经常更新的场景。
-
缺点:不支持索引和事务处理。只能进行追加操作,不适合常规的查询和更新操作。
-
-
NDB Cluster:
-
优点:适用于高可用性和高容量的分布式系统,支持数据分片和自动故障恢复。具备事务处理和ACID特性,适合于高并发读写和实时应用场景。
-
缺点:相对复杂,需要专门配置和管理,对硬件要求较高。不适合单机和小规模的应用。
-
这些存储引擎的选择应该根据实际需求和应用场景来决定,权衡每个存储引擎的优缺点,并根据具体场景的读写要求、数据一致性和可用性需求来确定最适合的存储引擎。
11、请画出 Docker C/S 架构图

在 Docker C/S 架构中,有以下几个关键组件:
-
Docker主机(Docker Host):它是运行 Docker 引擎的物理或虚拟机。Docker 主机负责管理容器的创建、运行和销毁,以及对容器进行资源管理和隔离。
-
Docker引擎(Docker Engine):它是 Docker 的核心组件,负责接收和处理来自 Docker 客户端的命令,执行容器的创建、运行、停止等操作。Docker 引擎由 Docker 守护进程(Docker Daemon)和 Docker REST API 组成。
-
Docker客户端(Docker Client):它是与 Docker 引擎进行通信的用户界面,可以使用命令行工具(如docker命令)或图形界面工具来与 Docker 引擎进行交互,通过向 Docker 引擎发送命令来控制容器的创建、运行和管理。
-
Docker镜像(Docker Image):它是容器的基础,用于创建容器的模板。Docker 镜像包含了一个完整的文件系统,其中包含了运行所需的所有文件和配置。可以通过从 Docker Hub 或私有镜像仓库下载现有的镜像,或者通过 Dockerfile 来构建自己的镜像。
-
Docker仓库(Docker Registry):它是用于存储和分享 Docker 镜像的中央仓库。Docker Hub 是默认的公共仓库,提供了大量的官方和社区维护的镜像供用户使用。用户也可以部署私有的 Docker 仓库来保存和管理自己的镜像。
12、请使用 docker 命令操作
a) 创建一个 volume 名称为 kuma
docker volume create kuma
b) 启动一个容器,名称为 yapi,后台执行,把 host 的 5000 端口映射到容器内 3000端口,并使用上面创建的 volume,挂载到/data/db 目录
docker run -d --name yapi -p 5000:3000 -v kuma:/data/db
需要将
这样就可以使用上述步骤创建的 volume kuma 并挂载到容器内的 /data/db 目录,同时进行端口映射,将 host 的 5000 端口映射到容器内的 3000 端口。容器名称为 yapi,并以后台模式运行。
写在最后
最后在这里分享一套软件测试的自学教程合集。对于在测试行业发展的小伙伴们来说应该会很有帮助,有需要的朋友你可以【点击文末小卡片免费领取】
除了基础入门的资源,博主也收集不少进阶自动化的资源,从理论到实战,知行合一才能真正的掌握。全套内容已经打包到网盘,内容总量接近300个G,包括基础知识、Linux必备、Shell、互联网程序原理、Mysql数据库、抓包工具专题、接口测试工具、测试进阶-Python编程、Web自动化测试、APP自动化测试、接口自动化测试、测试高级持续集成、测试架构开发测试框架、性能测试、安全测试等配套学习资源。

这些资料,对于做【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!凡事要趁早,特别是技术行业,一定要提升技术功底。
