论文阅读 The Power of Tiling for Small Object Detection
The Power of Tiling for Small Object Detection
Abstract
基于深度神经网络的技术在目标检测和分类方面表现出色。但这些网络在适应移动平台时可能会降低准确性,因为图像分辨率的增加使问题变得更加困难。在低功耗移动设备上实现实时小物体检测一直是监控应用的基本问题之一。在本研究中,我们解决了在高分辨率微型空中飞行器(MAV)图像中检测行人和车辆的问题。为此,我们利用PeleeNet,据我们所知,这是在移动GPU上效率最高的网络模型,以SSD网络的骨干和earlier layer中的38x38特征图。在展示了现有目标检测器在MAV场景下的低准确性后,我们引入了一种基于分块(tiling)的方法,该方法在训练和推断阶段均适用。所提出的技术在目标检测中限制了detail loss,同时以固定尺寸的输入送入网络。通过在Nvidia Jetson TX1和TX2上使用VisDrone2018数据集进行的深入实验,我们展示了所提出方法带来的改进。
1. Introduction
近年来,目标检测在不同应用领域得到了广泛研究,包括人脸检测、视频对象共分割、视频监控、自动驾驶汽车。卷积神经网络(CNNs)是目标检测技术背后的核心工具。在这个领域,深度学习架构的突破性和快速的应用产生了高度准确的目标检测方法,如R-CNN、Fast R-CNN 、Faster R-CNN 、RetinaNet ,这些方法后来被扩展成更快速且仍然准确的版本,如SSD 、YOLO 以及各种变体。这些方法通常在众所周知的数据集上进行训练和评估,如ImageNet 、Pascal VOC12 、COCO 。
需要注意的是,这些常见的数据集主要包括低分辨率图像(256x256),其中包含有大面积像素的大型物体。因此,这些训练好的模型对于这些类型的输入数据提供了非常成功的检测性能。然而,它们在高分辨率图像中的小物体检测任务上的准确性显著较低,这些图像是由高端摄像机生成的。摄像机和机器人技术在许多方面开创了监控应用,包括无人机、4K摄像机,并且实现了符合(D)etection、(O)bservation、(R)ecognition和(I)dentification(DORI)标准的long-range目标检测。DORI标准为不同任务的对象定义了最小像素高度。例如需要将图像高度10%的物体用于检测(在高清视频中为108像素),而在进行识别时,这个百分比增加到了20%。尽管在某些情况下符合DORI标准,相对较小的像素覆盖率和降采样影响了基于CNN的目标检测方法的能力。此外,由于内存需求和计算限制,这些技术无法处理高分辨率图像。
实时小物体检测问题主要应用于微型飞行器(MAV),其中大小、重量和功耗(SWaP)是使用高性能处理器的限制因素。MAV在一定高度观察地面,场景中的物体(行人、汽车、自行车等)的像素区域相对较小。此外,这些飞行器需要实时处理,以便在常见的监控应用中实现检测和跟踪的即时飞行控制。
在本研究中,我们提出了一种在高分辨率图像上进行小物体检测的高效解决方案,同时保持低复杂度和内存占用。为此,我们专注于微型飞行器上的行人和车辆检测,这涉及到前面讨论的问题。这些问题的解决方案依赖于三个阶段:第一步,训练数据集通过使用在原始高分辨率图像中裁剪的子集图块进行增强,同时将目标边界框相应地映射。这些 crops 将小物体映射到较大的相对区域,并在训练阶段的CNN结构的early layers中prevent misses。第二步关注CNN的部署,在这里,目标图像被分割为重叠的图块,并在每个图块上独立执行目标检测。每个图块中的object proposals被合并,以在输入图像的原始分辨率下进行最终检测。为了在满足实时要求的同时利用图块的优势,我们利用了一个高效的框架Pelee,该框架最初应用于大小为304x304的图像。第三步我们修改了Pelee中的特征分辨率,以解决小物体的问题。所有实验都在移动GPU NVIDIA Jetson TX1和TX2模块上进行。
2. Related Work
略过
3. Problem Description
对于移动设备(尤其是MAV和搭载电池的车辆)上实时部署目标检测框架的约束限制了可用网络的数量。前面提到的基于区域的方法对于及时操作不方便,而基于回归的技术则是为了在设备上进行 onboard processing 而设计的。在表1中,展示了在COCO数据集上的准确性以及在Nvidia TX2上的计算时间(每秒帧数(FPS)),其中包括各种基于回归的技术及其适用于移动设备的版本。根据表格,最近推出的Pelee不仅比所有移动检测框架(SSD+MobileNet和YOLOv3-tiny )更快,而且在与尺寸大10倍且计算能力较慢4倍的模型(如YOLOv2)相比的情况下,也提供了可比较的准确性。据我们所知,Pelee不仅是各种最先进技术中目前最佳的替代方案,还为额外的计算提供了足够的空间。

尽管Pelee在移动GPU上实现了实时性能,但由于SSD的特性,它在高分辨率图像中仍然受到检测小目标的困扰,如图1所示。在图中,展示了VisDrone2018 Video数据集中一些图像的Pelee检测(304x304)的典型结果。特别是对于较小的目标,表现出的目标检测性能较差,尤其是在黄色A-B-C-D所示的区域。

VisDrone2018 VID数据集在训练集中有100多万个边界框注释,在验证集中有11个不同类别标签(行人、人、自行车、汽车、货车、卡车、三轮车、雨篷三轮车、公共汽车、摩托车、其他)的140k个注释,非常适合我们的场景。我们将VisDrone2018中的类别分为两大类,即行人和车辆,以便进行更清晰简化的任务。在训练集中,人类和车辆类别的像素高度和宽度直方图如图2所示(将图像缩放为1920x1080)。很明显,一半的注释对应于像素高度和宽度小于50像素的对象。这个值是根据标准中讨论的阈值的一半。在VisDrone2018数据集中,小目标占了大多数,只有一半的目标满足监控阈值,而只有20%的目标满足10%图像高度的检测阈值。这在基于MAV的监视中是一个常见情况。
4. Proposed Approach
为了解决小目标检测问题,我们提出了一种tiling方法,该方法在训练和推断阶段都应用如图3所示。在图中,展示了一个典型的3x2 tiling,根据图像分辨率和目标物体纵横比,可以应用任意的tiling。将输入图像划分为重叠的tiling,使得相对于输入网络的图像,小目标的像素区域增大。这适用于任何类型的网络,另一方面,我们选择Pelee 来通过快速执行获得显著的准确率提高。
4.1. Pelee Architecture
整个PeleeNet网络由Stem Block、七个特征提取器阶段和ResBlock组成。首先,前四个特征提取器阶段由Dense Block组成,以前馈的方式将每一层连接到其他每一层。在训练过程中,输入帧被降采样到304x304分辨率。然后,降采样后的图像被送入Stem Block,以提高特征表达性能而不会增加太多的计算成本。在特征提取阶段,网络在5个尺度的特征图中(19x19、10x10、5x5、3x3和1x1)学习视觉特征示,具有不同的纵横比,然后在产生目标类别和边界框位置预测之前,将其传递到残差块(ResBlock)中。
我们的目标检测系统基于SSD 的源代码,使用Pytorch 进行训练。用于特征提取的VGG-16网络被Pelee替代。批大小设置为32。动量值为0.9,权重衰减为5e-4,γ值为0.5。初始学习率设置为0.001,然后在分别进行10K、20K、30K、40K和70K次迭代后降低10倍。训练在第120K次迭代时终止。
4.2. Tiles in network training
为了减轻小目标问题,我们降低了训练过程中因为采用图像降采样而产生的影响。通过重叠的tiles,将图像分割成较小的图像,其中tiles的大小根据训练框架中使用的图像大小进行选择。如图3所示,较低分辨率的图像(MxN)通过重叠的tiles从原始图像中裁剪出来。需要注意的是,在裁剪之前将输入图像分辨率设置为1920x1080,以固定tiles的大小。每个tiles对应于一个新的图像,其中ground truth物体的位置按照原样排列,而不改变物体的大小。通过这种方式,与完整画面相比,裁剪图像中的相对物体大小增加了。裁剪后的(MxN)图像和完整画面被用作网络训练的输入数据。需要注意的是,为了检测场景中的大物体,完整画面也被输入到网络训练中。
tiles之间的重叠区域用于保留沿tiles边界的物体,并防止由于图像分割而导致的任何遗漏。在本研究中,我们选择了连续tiles之间的25%交叠区域;子采样图像的分辨率N(宽度和高度)根据tiles数量(T)和图像大小(S)确定为:

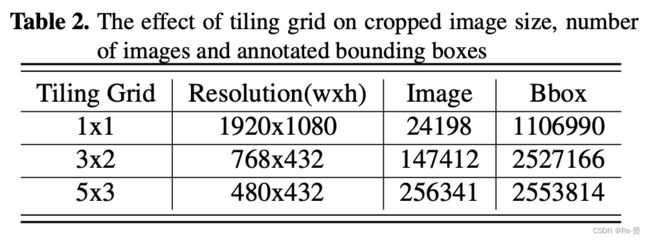
在表2中给出了对VisDrone2018数据集的裁剪图像分辨率、边界框数量和图像数量的tiling效果。由于重叠比率将网格大小增加到5x3会导致注释边界框数量增加2.5倍。将Pelee的图像分辨率与tile分辨率进行比较(304x304),降采样率大大降低,以保持小目标在网络可检测范围内。随着tile的增加,较大的物体可能无法适应tile和交叉区域,失去较大目标注释的风险也会增加。因此,在某一点上,tile的增加开始减少注释数量。图2中给出了tile扩展对目标尺寸分布的影响,蓝色表示扩展后的直方图。在提取直方图时,tile内的对象注释相对于将裁剪图像映射到完整分辨率(1920x1080)的尺度进行了放大。因此,正如在图2中观察到的,tile方法将较小的对象视为较大的对象。
4.3. Tiles during inference
与图3中给出的相同结构在目标检测期间也得到了利用。首先,输入帧被调整为1920x1080的大小,并且通过根据计算能力确定的tiles数量来裁剪输入帧生成tiles图像。由于计算性能问题,推断期间的tiles网格可以与训练阶段中的网格不同。每个tiles都被独立处理,就像原始帧一样,结果的检测框和类别概率被收集为初始结果。在这一点上,由于tiles和全帧之间的重叠,初始结果中会有重复的对象检测。根据边界框和类别分数的交集合并初始结果。如果重复检测的交集超过25%,则分数较高的一个被接受为更好的选择,另一个从检测列表中删除。在合并步骤中,与整个帧相比,tiles内的小对象通常会获得更高的分数,而对于大小与tiles区域相当的较大对象来说,情况相反。因此,小型和大型对象都会得到谨慎处理。
tiles的数量线性增加了整体检测框架的复杂性。因此,这种方法适用于轻量级和高效的网络,以满足在不增加内存使用的情况下进行实时推断。另一方面,相对于原始高分辨率帧,实际上原始图像中的相对对象尺寸可能非常小,因此小对象检测的准确性显然可以提高。即使只有少量的tiles,也可以显著提高小对象检测的性能,这在实验部分中有所呈现。
4.4. Pelee Framework Modifications
tiling方法引入了与网格数成线性关系的附加计算。为了解决小目标问题,还可以增加特征提取层的数量,以在不过多增加计算时间的情况下检测小目标。在原始的SSD结构中,使用了38x38、19x19、10x10、5x5、3x3和1x1的特征向量。带有Mobilenet的SSD没有使用38x38的特征向量,以在速度和准确性之间取得平衡。他们在预测时使用另一个2x2的特征图。这样,他们使用了一个较小的网络,以在牺牲小目标检测准确性的同时获得速度优势。原始的Pelee架构也放弃了38特征图,以平衡速度和准确性的权衡,但不像MobileNet那样使用2个特征图。在我们的框架中,我们使用38特征图对Pelee网络进行训练,以提高小目标的检测准确性。
5. Experiments && 6. Conclusion
略过