JsBridge
Bridge基本原理:
Js通知Native
1)API注入。通过webview.addJavaInterface()的方法实现
2)拦截Js的alert/confirm/prompt/console等事件。由于prompt事件在js中很少使用,所以一般是拦截该事件。这些事件在WebChromeClient都有对应的方法回调(onConsoleMessage,onJsPrompt,onJsAlert,onJsConfirm)
3)url跳转拦截,对应WebViewClient的shouldOverrideUrlLoading()方法。
第一种方法,由于webview在4.2以下的安全问题,所以有版本兼容问题。后两种方法原理本质上是一样的,都是通过对webview信息冒泡传递的拦截,通过定制协议-拦截协议-解析方法名参数-执行方法-回调。
Native通知Js
webView.loadUrl();
webView.evaluateJavascript()
webview可以通过loadUrl()的方法直接调用。在4.4以上还可以通过evaluateJava()方法获取js方法的返回值。
4.4以前,如果想获取方法的返回值,就需要通过上面的对webview信息冒泡传递拦截的方式来实现。
https://github.com/lzyzsd/JsBridge源码分析
参考:[https://my.oschina.net/JiangTun/blog/1612700
在 Js 和 WebView 交互的过程中,主要实现两个方向可以通信即可。
WebView 向 Js 传递数据是通过 WebView.loadUrl(String url) 实现的。
在 WebView 中接收 Js 传递的数据是通过 WebViewClient 中的 shouldOverrideUrlLoading(WebView view, String url) 拦截加载链接 String url 参数实现的。
重点:修改iframe的src会调用webview的shouldOverrideUrlLoading方法
js调用java
1)创建一个隐藏的messagingIframe,.更换iFrame的src,触发BridgeWebViewClient的shouldOverrideUrlLoading方法。更换src,前缀为yy://QUEUE_MESSAGE/。
2)创建sendMessageQueue数组,并为每个消息设置一个唯一的id并push到数组中
3)匹配到shouldOverrideUrlLoading,进入到BridgeWebView的flushMessageQueue方法
4)flushMessageQueue通过主要调用到了loadUrl方法
5)出发js的_fetchQueue方法,并再次更换iFrame的src协议头,触发shouldOverrideUrlLoading方法。
Retrofit2
参考:https://juejin.im/post/5c0fbcf6518825642650b875
核心原理:
通过动态代理返回具体的接口实例对象,调用接口方法时会调用到InvocationHandler的invoke方法。
然后根据每个方法的注解先解析出注解信息然后将注解信息进行封装成okhttp所需要的网络请求信息。
Okhttp3
整体流程图
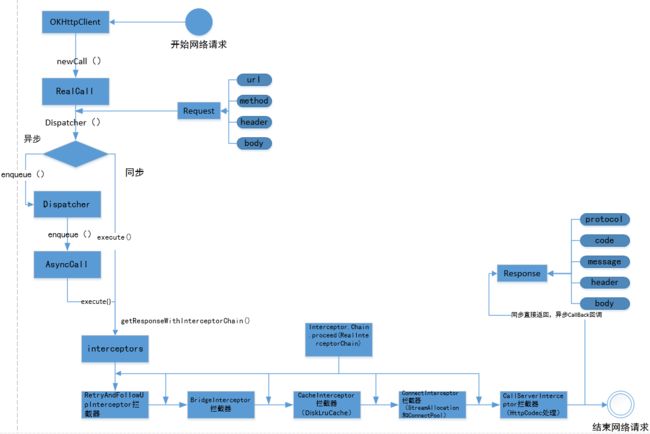
拦截器重试机制

默认拦截器
1)RetryAndFollowUpInterceptor
2)CacheInterceptor

4)CallServerInterceptor
OKHttp最终把拿到网络请求连接给到CallServerInterceptor拦截器进行网络请求和服务器通信
Response getResponseWithInterceptorChain() throws IOException {
List interceptors = new ArrayList<>();
//添加开发者应用层自定义的Interceptor
interceptors.addAll(client.interceptors());
//这个Interceptor是处理请求失败的重试,重定向
interceptors.add(retryAndFollowUpInterceptor);
//这个Interceptor工作是添加一些请求的头部或其他信息
//并对返回的Response做一些友好的处理(有一些信息你可能并不需要)
interceptors.add(new BridgeInterceptor(client.cookieJar()));
//这个Interceptor的职责是判断缓存是否存在,读取缓存,更新缓存等等
interceptors.add(new CacheInterceptor(client.internalCache()));
//这个Interceptor的职责是建立客户端和服务器的连接
interceptors.add(new ConnectInterceptor(client));
if (!forWebSocket) {
//添加开发者自定义的网络层拦截器
interceptors.addAll(client.networkInterceptors());
}
//这个Interceptor的职责是向服务器发送数据,
//并且接收服务器返回的Response
interceptors.add(new CallServerInterceptor(forWebSocket));
//一个包裹这request的chain
Interceptor.Chain chain = new RealInterceptorChain(
interceptors, null, null, null, 0, originalRequest);
//把chain传递到第一个Interceptor手中
return chain.proceed(originalRequest);
}
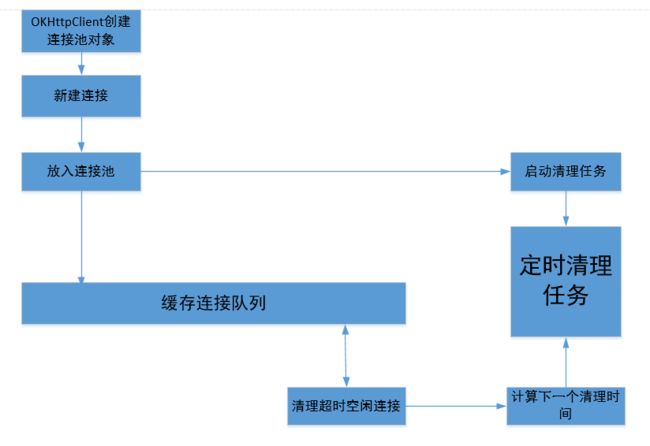
ConnectionPool
在它内部持有一个线程池和一个缓存连接的双向列表,连接中最多只能存在5个空闲连接,空闲连接最多只能存活5分钟,空闲连接到期之后定时清理。
重点
OkHttp3的最底层是Socket,而不是URLConnection,它通过Platform的Class.forName()反射获得当前Runtime使用的socket库,利用Okio生产source和sink。
private void connectSocket(int connectTimeout, int readTimeout) throws IOException {
Proxy proxy = route.proxy();
Address address = route.address();
rawSocket = proxy.type() == Proxy.Type.DIRECT || proxy.type() == Proxy.Type.HTTP
? address.socketFactory().createSocket()
: new Socket(proxy);
rawSocket.setSoTimeout(readTimeout);
...
//用Okio生产
source = Okio.buffer(Okio.source(rawSocket));
sink = Okio.buffer(Okio.sink(rawSocket));
...
}
参考:
使用Socket进行HTTP请求与报文讲解
OKHttp源码解析(九):OKHTTP连接中三个"核心"RealConnection、ConnectionPool、StreamAllocation
Okio的source是socket.inputStream,sink是socket.outputStream。
所以,真正在传输数据时,就是用Okio的sink去传socket,用source去取socket,底层其实也是socket操作。
Okhttp3的其他特性
1.返回数据阅后即焚
在OkHttp中,如果要拦截ResponseBody的数据内容(比如写日志),会发现该数据读过一次就会被情况,相当于是“阅后即焚”:
//ResponseBody源码
public final String string() throws IOException { //底层不能自己消化异常,应该向上层抛出异常
BufferedSource source = source();
try {
Charset charset = Util.bomAwareCharset(source, charset());
return source.readString(charset);
//不做catch,异常全部抛出给上层
} finally { //确保原始字节数据得到处理
Util.closeQuietly(source); //阅后即焚,这样可以迅速腾出内存空间来
}
}
如果一定要拦截出数据内容,我们就不能直接读ResponseBody中的source,需要copy一个副本才行:
BufferedSource sr = response.body().source();
sr.request(Long.MAX_VALUE);
Buffer buf = sr.buffer().clone();//copy副本读取,不能读取原文
String content = buf.readString(Charset.forName("UTF-8"));
buf.clear();
Response也提供了专门获取ResponsBody数据的函数peekBody,实现原理也是copy:
//Response源码
public ResponseBody peekBody(long byteCount) throws IOException {
BufferedSource source = body.source();
source.request(byteCount);
Buffer copy = source.buffer().clone();
...
return ResponseBody.create(body.contentType(), result.size(), result);
}
Okio
参考:
https://blog.piasy.com/2016/08/04/Understand-Okio/index.html
https://juejin.im/post/5856680c8e450a006c6474bd
Retrofit,OkHttp,Okio 进行网络 IO 的流程图
Demo
// 写入数据
String fileName="test.txt";
String path= Environment.getExternalStorageDirectory().getPath();
File file=null;
BufferedSink bufferSink=null;
try{
file=new File(path,fileName);
if (!file.exists()){
file.createNewFile();
}
bufferSink=Okio.buffer(Okio.sink(file));
bufferSink.writeString("this is some thing import \n", Charset.forName("utf-8"));
bufferSink.writeString("this is also some thing import \n", Charset.forName("utf-8"));
bufferSink.close();
}catch(Exception e){
}
//读取数据
try {
BufferedSource bufferedSource=Okio.buffer(Okio.source(file));
String str=bufferedSource.readByteString().string(Charset.forName("utf-8"));
Log.e("TAG","--->"+str);
} catch (Exception e) {
e.printStackTrace();
}
RecycleView&Listview
参考:
Android ListView 与 RecyclerView 对比浅析
缓存差异:
ListView(两级缓存):
RecyclerView(四级缓存)
1)RecyclerView从mCacheViews(屏幕外)获取缓存时,是通过匹配pos获取目标位置的缓存,这样做的好处是,当数据源数据不变的情况下,无须重新bindView,直接返回holder。
而同样是离屏缓存,ListView从mScrapViews根据pos获取相应的缓存,但是并没有直接使用,而是重新getView(即必定会重新bindView)
//AbsListView源码
//通过匹配pos从mScrapView中获取缓存
final View scrapView = mRecycler.getScrapView(position);
//无论是否成功都直接调用getView,导致必定会调用createView
final View child = mAdapter.getView(position, scrapView, this);
if (scrapView != null) {
if (child != scrapView) {
mRecycler.addScrapView(scrapView, position);
} else {
...
}
}
2)ListView中通过pos获取的是view,即pos-->view;
RecyclerView中通过pos获取的是viewholder,即pos --> (view,viewHolder,flag)引用;
从流程图中可以看出,标志flag的作用是判断view是否需要重新bindView,这也是RecyclerView实现局部刷新的一个核心
局部刷新
以RecyclerView中notifyItemRemoved(1)为例,最终会调用requestLayout(),使整个RecyclerView重新绘制,过程为:onMeasure()-->onLayout()-->onDraw()
其中,onLayout()为重点,分为三步:
dispathLayoutStep1():记录RecyclerView刷新前列表项ItemView的各种信息,如Top,Left,Bottom,Right,用于动画的相关计算;
dispathLayoutStep2():真正测量布局大小,位置,核心函数为layoutChildren();
dispathLayoutStep3():计算布局前后各个ItemView的状态,如Remove,Add,Move,Update等,如有必要执行相应的动画。
layoutChildren()流程图:
当调用notifyItemRemoved时,会对屏幕内ItemView做预处理,修改ItemView相应的pos以及flag(流程图中红色部分):
当调用fill()中RecyclerView.getViewForPosition(pos)时,RecyclerView通过对pos和flag的预处理,使得bindview只调用一次.
需要指出,ListView和RecyclerView最大的区别在于数据源改变时的缓存的处理逻辑,ListView是"一锅端",将所有的mActiveViews都移入了二级缓存mScrapViews,而RecyclerView则是更加灵活地对每个View修改标志位,区分是否重新bindView。
RecycleView源码分析
参考:RecyclerView 源码解析
RecyclerView的职责就是将Datas中的数据以一定的规则展示在它的上面,但说破天RecyclerView只是一个ViewGroup,它只认识View,不清楚Data数据的具体结构,所以两个陌生人之间想构建通话,我们很容易想到 适配器模式 ,因此,RecyclerView需要一个Adapter(适配器模式)来与Datas进行交流
如上如所示,RecyclerView表示只会和ViewHolder进行接触,而Adapter的工作就是将Data转换为RecyclerView认识的ViewHolder,因此RecyclerView就间接地认识了Datas。
事情虽然进展愉快,但RecyclerView是个很懒惰的人,尽管Adapter已经将Datas转换为RecyclerView所熟知的View,但RecyclerView并不想自己管理些子View,因此,它雇佣了一个叫做LayoutManager的大祭司来帮其完成布局(桥接模式),现在,图示变成下面这样
如上图所示,LayoutManager协助RecyclerView来完成布局。但LayoutManager这个大祭司也有弱点,就是它只知道如何将一个一个的View布局在RecyclerView上,但它并不懂得如何管理这些View,如果大祭司肆无忌惮的玩弄View的话肯定会出事情,所以,必须有个管理View的护法,它就是Recycler,LayoutManager在需要View的时候回向护法进行索取,当LayoutManager不需要View(试图滑出)的时候,就直接将废弃的View丢给Recycler,图示如下:
到了这里,有负责翻译数据的Adapter,有负责布局的LayoutManager,有负责管理View的Recycler,一切都很完美,但RecyclerView乃何等神也,它下令说当子View变动的时候姿态要优雅(动画),所以用雇佣了一个舞者ItemAnimator(观察者模式),因此,舞者也进入了这个图示:
自定义LayoutManager
参考:自定义LayoutManager实现最美应用列表
Android自定义LayoutManager第十一式之飞龙在天
效果:https://github.com/DingMouRen/LayoutManagerGroup
LayoutManager详解及使用
LinearLayoutManager继承RecycleView.LayoutManager。
LayoutManager#onLayoutChildren会调用到recycleView相应的操作view的方法。
ORMLite&GreenDao&Room
Android流行ORM框架性能对比及Room踩坑总结
Android Jetpack架构组件解析
带你领略Android Jetpack组件的魅力
ViewModel
ViewModel生命周期
参考:ViewModel相关生命周期的原理分析
sdkversion<28
从Activity的生命周期状态中触发,调用FragmentController->FragmentManager从而将设置了setRetainInstance(true)的fragment的相关fragment保存起来;这样config change时fragment不会执行到onDestroy; 对于HolderFragment而言,不会执行到其onDestory方法,ViewModelStore及其对应ViewModel均会得以保留
sdkversion>=28
ensureActivityConfiguration->relaunchActivityLocked-----binder call----------->handleRelaunchActivity (监听到config变化,走relaunch逻辑,将mChangingConfigurations置为true,这样Activity的ViewModelStore不会clear)
r.activity.mChangingConfigurations = true
总结
本问总结了ViewModel在config change时保持生命周期的相关原理;分为两种情况:
1)before androidx support activity/fragment
利用无View的HolderFragment,使用setRetainInstance(true)保证其在config change时不被销毁;这个思路值得我们借鉴
androidx support activity/fragment
2)在系统层进行了适配,无需HolderFragment接入了,其原理是config change正常执行销毁工作,只不过在再次relaunch时还原;
Gson
参考:https://blog.csdn.net/chunqiuwei/article/category/5881669
gson有2种方式将json字符串转化为成对应的Object
1)JsonParser
2)new Gson().from()
fastjson
参考:fastjson内幕
核心技术:
1、自行编写类似StringBuilder的工具类SerializeWriter。
2、使用ThreadLocal来缓存buf
这个办法能够减少对象分配和gc,从而提升性能
3、使用asm避免反射
获取java bean的属性值,需要调用反射,fastjson引入了asm的来避免反射导致的开销。fastjson内置的asm是基于objectweb asm 3.3.1改造的,只保留必要的部分,fastjson asm部分不到1000行代码,引入了asm的同时不导致大小变大太多。
4、使用一个特殊的IdentityHashMap优化性能
5、缺省启用sort field输出
6、集成jdk实现的一些优化算法
react-nantive、weex、flutter
RxJava2
RxJava2.+创建流程源码分析
RxJava2.+线程切换源码分析
Glide
参考:
Glide 架构设计艺术
基本用法:
Glide.with(this).load("xxx").circleCrop().into(ImageView(this))
Glide.with(this).load("xxx")返回RequestBuilder
其中RequestBuilder
BaseRequestOptions是用来保存配置信息的,即load()方法后面的各种操作符都是通过枚举的方式保存在BaseRequestOptions的 private Options options = new Options();对象中。其中Options的内部是通过ArrayMap来实现的。
ok,基本上load()方法后面的所有操作符基本上都是用来保存配置信息的。真正的request构建和发起其实是发生在into()方法里的。
RequestBuilder#into
private > Y into(
@NonNull Y target,
@Nullable RequestListener targetListener,
BaseRequestOptions options,
Executor callbackExecutor) {
Preconditions.checkNotNull(target);
if (!isModelSet) {
throw new IllegalArgumentException("You must call #load() before calling #into()");
}
//构建网络请求对象
Request request = buildRequest(target, targetListener, options, callbackExecutor);
Request previous = target.getRequest();
if (request.isEquivalentTo(previous)
&& !isSkipMemoryCacheWithCompletePreviousRequest(options, previous)) {
request.recycle();
// If the request is completed, beginning again will ensure the result is re-delivered,
// triggering RequestListeners and Targets. If the request is failed, beginning again will
// restart the request, giving it another chance to complete. If the request is already
// running, we can let it continue running without interruption.
if (!Preconditions.checkNotNull(previous).isRunning()) {
// Use the previous request rather than the new one to allow for optimizations like skipping
// setting placeholders, tracking and un-tracking Targets, and obtaining View dimensions
// that are done in the individual Request.
previous.begin();
}
return target;
}
requestManager.clear(target);
target.setRequest(request);
//注意这是真正发去网络请求的地方
requestManager.track(target, request);
return target;
}
RequestManager#track
synchronized void track(@NonNull Target target, @NonNull Request request) {
targetTracker.track(target);
requestTracker.runRequest(request);
}
RequestTracker#runRequest
public void runRequest(@NonNull Request request) {
requests.add(request);
if (!isPaused) {
request.begin();
} else {
request.clear();
if (Log.isLoggable(TAG, Log.VERBOSE)) {
Log.v(TAG, "Paused, delaying request");
}
pendingRequests.add(request);
}
}
request为SingleRequest
@Override
public synchronized void begin() {
assertNotCallingCallbacks();
stateVerifier.throwIfRecycled();
startTime = LogTime.getLogTime();
if (model == null) {
if (Util.isValidDimensions(overrideWidth, overrideHeight)) {
width = overrideWidth;
height = overrideHeight;
}
// Only log at more verbose log levels if the user has set a fallback drawable, because
// fallback Drawables indicate the user expects null models occasionally.
int logLevel = getFallbackDrawable() == null ? Log.WARN : Log.DEBUG;
//错误回调
onLoadFailed(new GlideException("Received null model"), logLevel);
return;
}
if (status == Status.RUNNING) {
throw new IllegalArgumentException("Cannot restart a running request");
}
// If we're restarted after we're complete (usually via something like a notifyDataSetChanged
// that starts an identical request into the same Target or View), we can simply use the
// resource and size we retrieved the last time around and skip obtaining a new size, starting a
// new load etc. This does mean that users who want to restart a load because they expect that
// the view size has changed will need to explicitly clear the View or Target before starting
// the new load.
if (status == Status.COMPLETE) {
onResourceReady(resource, DataSource.MEMORY_CACHE);
return;
}
// Restarts for requests that are neither complete nor running can be treated as new requests
// and can run again from the beginning.
status = Status.WAITING_FOR_SIZE;
if (Util.isValidDimensions(overrideWidth, overrideHeight)) {
//重点方法
onSizeReady(overrideWidth, overrideHeight);
} else {
target.getSize(this);
}
if ((status == Status.RUNNING || status == Status.WAITING_FOR_SIZE)
&& canNotifyStatusChanged()) {
target.onLoadStarted(getPlaceholderDrawable());
}
if (IS_VERBOSE_LOGGABLE) {
logV("finished run method in " + LogTime.getElapsedMillis(startTime));
}
}
从Request到Data的设计——资源加载模块设计
每个ModelLoader中包含一个对应的DataFetcher,真正的网络请求实现是DataFetcher老完成的。
从Data到Resource的设计——解码和转码模块设计
从Resource到Resource的设计——资源变换操作
从Resource到显示在Target上的设计——资源显示操作
RePlugin
参考:
Android全面插件化RePlugin流程与源码解析
ClassLoaer
1、RePluginClassLoader: 宿主App中的Loader,继承PathClassLoader,也是唯一Hook住系统的Loader
2、PluginDexClassLoader: 加载插件的Loader,继承DexClassLoader。用来做一些“更高级”的特性
v-layout
参考:
Android开源库V - Layout:淘宝、天猫都在用的UI框架,赶紧用起来吧!

最外层大的Adapter通过setAdapters方法将每个绑定helper的adapter放到mAdapters中,遍历出helper列表添加到LayoutManager中。
其中内部的每个adapter通过Pair对象跟AdapterDataObserver绑定。
重点方法:
@Override
public RecyclerView.ViewHolder onCreateViewHolder(ViewGroup parent, int viewType) {
if (mHasConsistItemType) {
Adapter adapter = mItemTypeAry.get(viewType);
if (adapter != null) {
return adapter.onCreateViewHolder(parent, viewType);
}
return null;
}
// reverse Cantor Function
Cantor.reverseCantor(viewType, cantorReverse);
int index = (int)cantorReverse[1];
int subItemType = (int)cantorReverse[0];
Adapter adapter = findAdapterByIndex(index);
if (adapter == null) {
return null;
}
return adapter.onCreateViewHolder(parent, subItemType);
}
public void onBindViewHolder(RecyclerView.ViewHolder holder, int position, ListLeakCanary
java内存相关基础:
这里以Java虚拟机为例,将运行时内存区分为不同的区域,每个区域承担着不同的功能。
方法区
用户存储已被虚拟机加载的类信息,常量,静态常量,即时编译器编译后的代码等数据。异常状态 OutOfMemoryError,其中包含常量池和用户存放编译器生成的各种字面量和符号引用。
堆
是JVM所管理的内存中最大的一块。唯一目的就是存放实例对象,几乎所有的对象实例都在这里分配。Java堆是垃圾收集器管理的主要区域,因此很多时候也被称为“GC堆”。异常状态 OutOfMemoryError。
虚拟机栈
描述的是java方法执行的内存模型,每个方法在执行时都会创建一个栈帧,用户存储局部变量表,操作数栈,动态连接,方法出口等信息。每一个方法从调用直至完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。 对这个区域定义了两种异常状态 OutOfMemoryError、StackOverflowError。
本地方法栈
虚拟机栈为虚拟机执行java方法,而本地方法栈为虚拟机使用到的Native方法服务。异常状态StackOverFlowError、OutOfMemoryError。
程序计数器
一块较小的内存,当前线程所执行的字节码的行号指示器。字节码解释器工作时,就是通过改变这个计数器的值来选取下一条需要执行的字节码指令。
内存模型
Java内存模型规定了所有的变量都存储在主内存中。每条线程中还有自己的工作内存,线程的工作内存中保存了被该线程所使用到的变量,这些变量是从主内存中拷贝而来。线程对变量的所有操作(读,写)都必须在工作内存中进行。不同线程之间也无法直接访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存来完成。
为了保证内存可见性,常常利用volatile关键子特性来保证变量的可见性(并不能保证并发时原子性)
1、强引用,只要强引用还存在,垃圾收集器永远不会回收掉被引用的对象。
2、软引用,在系统将要发生内存溢出异常之前,将会把这些对象列进回收范围进行二次回收。如果这次回收还没有足够的内存,才会抛出内存溢出异常。SoftReference表示软引用。
3、弱引用,只要有GC,无论当前内存是否足够,都会回收掉只被弱引用关联的对象。WeakReference表示弱引用。
4、虚引用,这个引用存在的唯一目的就是在这个对象被收集器回收时收到一个系统通知,被虚引用关联的对象,和其生存时间完全没关系。PhantomReference表示虚引用,需要搭配ReferenceQueue使用,检测对象回收情况。
leakCanary原理:
主要是在Activity的&onDestroy方法中,手动调用 GC,然后利用ReferenceQueue+WeakReference,来判断是否有释放不掉的引用,然后结合dump memory的hpof文件, 用HaHa分析出泄漏地方。
具体监听的原理在于 Application 的registerActivityLifecycleCallbacks方法,该方法可以对应用内所有 Activity 的生命周期做监听, LeakCanary只监听了Destroy方法。GC会造成主线程阻塞卡顿,需要在空闲时间内进行GC,根据IdleHandler,当主线程空闲时,会回调queueidle函数。
知识点:
1,用ActivityLifecycleCallbacks接口来检测Activity生命周期
2,WeakReference + ReferenceQueue 来监听对象回收情况
3,Apolication中可通过processName判断是否是任务执行进程
4,MessageQueue中加入一个IdleHandler来得到主线程空闲回调
5,LeakCanary检测只针对Activiy里的相关对象。其他类无法使用,还得用MAT原始方法
EventBus
黏性事件:发送事件之后再订阅该事件也能收到该事件,跟黏性广播类似。
RN
参考:
https://juejin.im/post/57d4e67fda2f600059f48e11
那么Java和Js之间想要能听懂对方的话,有两个必备条件:
双方的信息要能够传达到对方那里去,就是,先不管听不听的懂 ,你首先要把话传过去
信息传达前需要经过翻译,才能被接受方正确理解。
第一个条件的解决方案是通过C++来做这个传话筒,Java通过JNI来call到c++层,然后c++层再把信息传到js,反之亦然;第二个条件的解决方案就是通过在初始化的时候构造两本“词典”,约定好以后说话只说对方写好的“词典”上的单词,保证对方能听懂。
NativeModuleRegistry.Builder nativeRegistryBuilder = new NativeModuleRegistry.Builder();
JavaScriptModuleRegistry.Builder jsModulesBuilder = new JavaScriptModuleRegistry.Builder();
rn开发中遇到的坑
1)flex css属性支持不完全
2)debug比较困难,前端人员不理解native层面的报错,native人员对于js的报错也不理解。
3)原生组件Android和ios不同步,无法保证两边统一,并且有些控件Android和IOS调用不统一,需要做一层封装,方便统一调用。
优点:
不需要发版,可以热更新。但是涉及到原生功能支持的还是需要发版。只是减少发版的频率而已。
WEEX
基本上很少有公司采用,社区也不活跃。核心原理与RN类似,js层采用vue。
Flutter
参考:https://zhuanlan.zhihu.com/p/43163159
理解Platform Channel工作原理
Flutter定义了三种不同类型的Channel,它们分别是
BasicMessageChannel:用于传递字符串和半结构化的信息。
MethodChannel:用于传递方法调用(method invocation)。
EventChannel: 用于数据流(event streams)的通信。