自然语言处理NLTK(一):NLTK和语料库
对于文本的研究,对于语言主要是中文,英文的研究反而会少了很多,主要还是因为应用的问题,而现在对于海外的产品来说,英文的语言处理,会越来越显得重要,其实对英文语言处理资料会比中文的来得多,来得全,很多中文研究的方法是借鉴了英文处理的思想。
NLTK是python中研究自然语言的非常优秀的第三方库,里面集中了非常多的自然语言处理方式的算法,不需要自己去编写算法,可以让我们更多的去关系应用本身。
NLTK的安装
NLTK的安装,跟python安装第三方包并没有太多的区别。
pip install nltk
对于语料库的下载,在有较好的网络环境下可以直接使用python代码
import nltk
nltk.download()
选择所有的语料库下载:

语料库比较大,压缩文件差不多有500M,如果网络环境一般,可以单独下载,放在相应的目录下,查找目录的方法如下:
import nltk
print ntlk.data.find('*')
可以显示出来,应该把包放在哪个目录下:
Searched in:
- 'C:\\Users、\nltk_data'
- 'C:\\nltk_data'
- 'D:\\nltk_data'
- 'E:\\nltk_data'
- 'C:\\Python27\\nltk_data'
- 'C:\\Python27\\lib\\nltk_data'
- 'C:\\Users\nltk_data'
语料库
所有的语料库都存放在nltk_data\corpora下,corpora为资料库的意思,这里包含了大量的语料库,主要的如下:
古腾堡语料库
NLTK包含古腾堡项目( Project Gutenberg)电子文本档案的经过挑选的一小部分文
本。该项目大约有 25,000(现在是 36,000了) 本免费电子图书,放在 http://www.gutenberg.
org/上。资料库在:nltk_data\corpora\gutenberg下。
网络和聊天文本
虽然古腾堡项目包含成千上万的书籍,它代表既定的文学。考虑较不正式的语言也是
很重要的。 NLTK的网络文本小集合的内容包括 Firefox交流论坛, 在纽约无意听到的对话,
《加勒比海盗》的电影剧本,个人广告和葡萄酒的评论。资料库在:nltk_data\corpora\webtext下。
布朗语料库
布朗语料库是第一个百万词级的英语电子语料库的,由布朗大学于 1961年创建。这个
语料库包含500个不同来源的文本, 按照文体分类, 如: 新闻、 社论等。 表 2-1给出了各个
文体的例子(完整列表,请参阅http://icame.uib.no/brown/bcm-los.html)。资料库在:nltk_data\corpora\brown下。
路透社语料库
路透社语料库包含 10,788个新闻文档, 共计130万字。 这些文档分成90个主题, 按照
“ 训练” 和“ 测试” 分为两组。因此, fileid为“ test/14826” 的文档属于测试组。这样分割
是为了训练和测试算法的,这种算法自动检测文档的主题,资料库在:nltk_data\corpora\webtext下。
就职演说语料库
我们看到了就职演说语料库,但是把它当作一个单独的文本对待。在图 1-2
中使用的“ 词偏移”就像是一个坐标轴, 它是语料库中词的索引数, 从第一个演讲的第一个
词开始算起。然而,语料库实际上是 55个文本的集合,每个文本都是一个总统的演说。
标注文本语料库
许多文本语料库都包含语言学标注,有词性标注、命名实体、句法结构、语义角色等。
NLTK中提供了很方便的方式来访问这些语料库中的几个,还有一个包含语料库和语料样本
的数据包, 用于教学和科研的话可以免费下载。 表 2-2列出了其中一些语料库。 有关下载信
息请参阅 http://www.nltk.org/data。关于如何访问 NLTK语料库的其它例子, 请在http://www.
nltk.org/howto查阅语料库的 HOWTO。
其他语言的语料库
这里可以发现,nltk.download中存在着非常多的资料库,英文的居多,中文的语料库相对来说会少很多,这一点在进行机器对话的编程过程,就发现了这个问题,好的优质的中文资料库相当的少,而从nltk来看,语料库是基础,巧妇难为无米之炊。
文本语料库的结构
目前为止, 我们已经看到了大量的语料库结构。 图 2-3中总结了它们。 最简单的一种
没有任何结构,仅仅是一个文本集合。通常,文本会按照其可能对应的文体、来源、作者、
语言等分类。 有时, 这些类别会重叠, 尤其是在按主题分类的情况下, 因为一个文本可能与
多个主题相关。偶尔的,文本集有一个时间结构,新闻集合是最常见的例子。
NLTK语料库阅读器支持高效的访问大量语料库,并且能用于处理新的语料库。如下列出了语料库阅读器提供的函数。
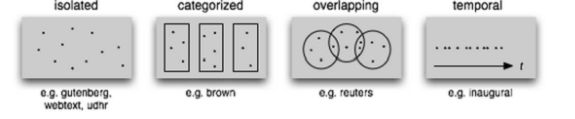
图2-3. 文本语料库的常见结构:最简单的一种语料库是一些孤立的没有什么特别的组织的
文本集合; 一些语料库按如文体( 布朗语料库) 等分类组织结构; 一些分类会重叠, 如主题
类别(路透社语料库);另外一些语料库可以表示随时间变化语言用法的改变(就职演说语
料库)。
表2-3. NLTK中定义的基本语料库函数:使用 help(nltk.corpus.reader)可以找到更多的文档,
也可以阅读http://www.nltk.org/howto上的在线语料库的 HOWTO。

具体的用法如下:
获取gutenberg项目目录下,有哪些文件
import nltk
print nltk.corpus.gutenberg.fileids()
得到如下的文件:
[u'austen-emma.txt', u'austen-persuasion.txt', u'austen-sense.txt', u'bible-kjv.txt', u'blake-poems.txt', u'bryant-stories.txt', u'burgess-busterbrown.txt', u'carroll-alice.txt', u'chesterton-ball.txt', u'chesterton-brown.txt', u'chesterton-thursday.txt', u'edgeworth-parents.txt', u'melville-moby_dick.txt', u'milton-paradise.txt', u'shakespeare-caesar.txt', u'shakespeare-hamlet.txt', u'shakespeare-macbeth.txt', u'whitman-leaves.txt']
条件频率分布
当语料文本分为几类(文体、主题、作者)时,可以计算每个类别独立的频率分布,这样就可以研究类别之间的系统性差异。——nltk.ConditionalFreqDist来实现、条件频率分布是频率分布的集合,每个频率分布有一个不同的‘条件’(通常为文本的类别)——(条件,事件)的形式。
例子:绘制特定演讲中出现[‘america’,‘citizen’]的次数随时间变化情况
#! /usr/bin/python
# -*- coding:utf-8 -*-
import nltk
from nltk.corpus import inaugural
cfd = nltk.ConditionalFreqDist((target, fileid[:4]) for fileid in inaugural.fileids() for w in inaugural.words(fileid)
for target in ['america', 'citizen'] if w.lower().startswith(target))
cfd.plot()
显示出在某一年度下,某一个词出现的次数。
