python数据读取与可视化(1)——CSV格式
CSV格式文件读取与可视化
- CSV格式文件读取与可视化
-
-
- 一 CSV
- 二 如何得到CSV
- 三 CSV文件的处理
-
- 1 导入文件
- 2 读取数据
- 3 数据的可视化
-
- 一些小问题的处理
- 一点优化
-
一 CSV
CSV文件以纯文本的形式储存数字和字母,各个数据之间一般用逗号作为分隔符。是一种通用的,相对简单的文件格式,被广泛使用。常用于在不同的程序之间传递表格数据
举个
年,制造商,型号
1997,Ford,E350
1999,Chevy,"Venture "“Extended Edition”
1999,Chevy,"Venture "“Extended Edition”
二 如何得到CSV
法一:用记事本按照csv的格式书写,保存为csv文件
法二:用Excel书写,保存时改为csv
三 CSV文件的处理
1 导入文件
将文件放置到当前项目所在的文件夹中

2 读取数据
#导入csv库
import csv
filename = "economy development.csv"
with open(filename) as f:
reader = csv.reader(f) #使用reader类
rows = next(reader)
#调用next方法,rows储存每一列的第一个
print(rows)#
result:
['地区', '经济总量', '增速']
枚举rows中的元素
for index, column_header in enumerate(rows):
print(index, column_header)
result:
0 地区
1 经济总量
2 增速
建立两个空列表储存row[0] and row[1]中的地区和经济总量
enconomic = []
place = []
for row in reader:
enconomic.append(row[1])
place.append(row[0])

3 数据的可视化
数据可视化,当然是使用matplotlib
详解传送门
一些小问题的处理
由于matplotlib不含中文字体,所以中文字体会被显示为[]
所以我们要在文件中引入中文字体
# 查看系统中的字体
from matplotlib import font_manager
a = sorted([f.name for f in font_manager.fontManager.ttflist])
for i in a:
print(i)
下面是我的一些字体

再在脚本前面加上这个即可
plt.rcParams['font.sans-serif'] = ['Songti SC']
# Songti SC 是字体名
plt.rcParams['axes.unicode_minus'] = False
完整代码如下
import matplotlib.pyplot as plt
import csv
plt.rcParams['font.sans-serif'] = ['Songti SC']
plt.rcParams['axes.unicode_minus'] = False
filename = "economy development.csv"
with open(filename) as f:
reader = csv.reader(f)
enconomic = []
place = []
for row in reader:
if row[1] != "经济总量":
# 开头如果是英文好像就没有这个困惑,不必进行判断
e = float(row[1])
enconomic.append(e)
if row[0] != "地区":
place.append(row[0])
fig = plt.figure(dpi=120, figsize=(8, 6))
plt.plot(place, enconomic)
plt.xlabel("地区", fontsize=20)
plt.ylabel("2020全年GDP/亿", fontsize=20)
plt.title("2020前11省市GDP")
plt.ylim(-10,120000)
plt.show()
结果如下
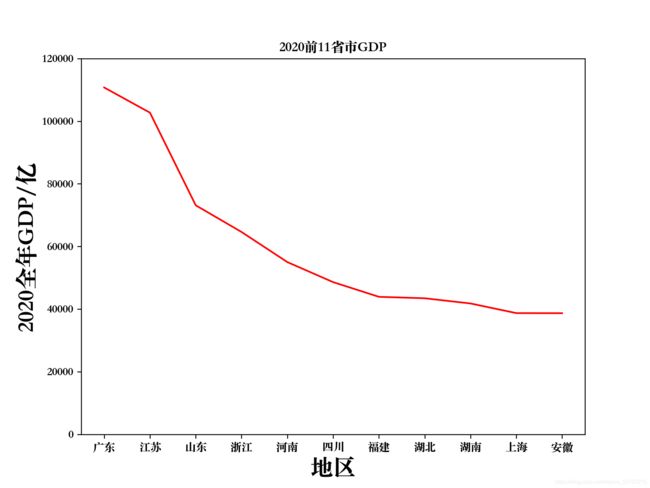
然而这种方法还是不够直观
一点优化
通过调用plt.text( )对每一点进行标注
在plot( )中的marker
plt.plot(place, enconomic, label='经济发展', linewidth=3, color='black', marker='o',
markerfacecolor='red', markersize=12)
# 对点用圆点进行标注
for a, b in zip(place, enconomic):
plt.text(a, b, b, ha='center', va='bottom', fontsize=14)
#text方法用enconomic中的值
效果如下:

欢迎大家点赞三连