Hive原理剖析
一、简介
Hive是建立在Hadoop上的数据仓库框架,提供大数据平台批处理计算能力,能够对结构化/半结构化数据进行批量分析汇总完成数据计算。提供类似SQL的Hive Query Language语言操作结构化数据,其基本原理是将HQL语言自动转换成MapReduce任务,从而完成对Hadoop集群中存储的海量数据进行查询和分析。有关Hive表的更多信息,请参阅开源社区Hive教程。
Hive主要特点如下:
- 海量结构化数据分析汇总。
- 将复杂的MapReduce编写任务简化为SQL语句。
- 灵活的数据存储格式,支持JSON,CSV,TEXTFILE,RCFILE,SEQUENCEFILE,ORC(Optimized Row Columnar)这几种存储格式。
二、Hive结构
Hive为单实例的服务进程,提供服务的原理是将HQL编译解析成相应的MapReduce或者HDFS任务,如下图所示为Hive的结构概图。
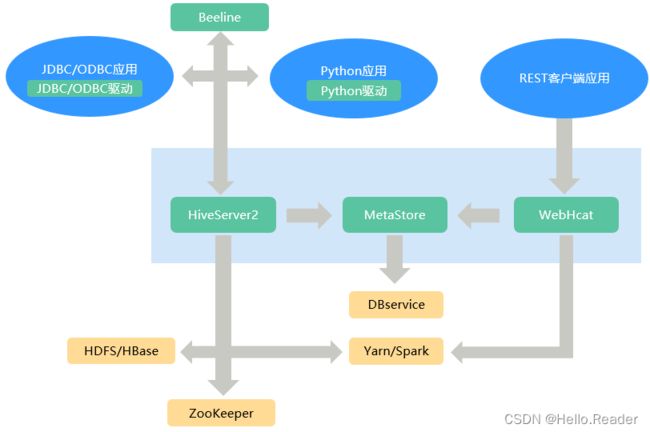
| 名称 | 说明 |
|---|---|
| HiveServer | 一个集群内可部署多个HiveServer,负荷分担。对外提供Hive数据库服务,将用户提交的HQL语句进行编译,解析成对应的Yarn任务或者HDFS操作,从而完成数据的提取、转换、分析。 |
| MetaStore | 1.一个集群内可部署多个MetaStore,负荷分担。提供Hive的元数据服务,负责Hive表的结构和属性信息读、写、维护和修改。2.提供Thrift接口,供HiveServer、Spark、WebHCat等MetaStore客户端来访问,操作元数据。 |
| WebHCat | 一个集群内可部署多个WebHCat,负荷分担。提供Rest接口,通过Rest执行Hive命令,提交MapReduce任务。 |
| Hive客户端 | 包括人机交互命令行Beeline、提供给JDBC应用的JDBC驱动、提供给Python应用的Python驱动、提供给Mapreduce的HCatalog相关JAR包。 |
| ZooKeeper集群 | ZooKeeper作为临时节点记录各HiveServer实例的IP地址列表,客户端驱动连接Zookeeper获取该列表,并根据路由机制选取对应的HiveServer实例。 |
| HDFS/HBase集群 | Hive表数据存储在HDFS集群中。 |
| MapReduce/Yarn集群 | 提供分布式计算服务:Hive的大部分数据操作依赖MapReduce,HiveServer的主要功能是将HQL语句转换成MapReduce任务,从而完成对海量数据的处理。 |
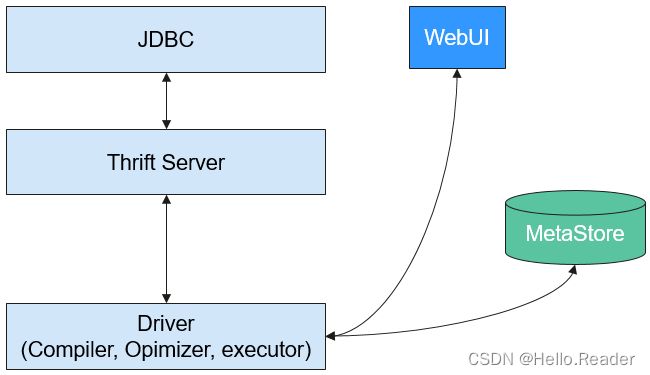
HCatalog建立在Hive Metastore之上,具有Hive的DDL能力。从另外一种意义上说,HCatalog还是Hadoop的表和存储管理层,它使用户能够通过使用不同的数据处理工具(比如Pig和MapReduce),更轻松地在网格上读写HDFS上的数据,HCatalog还能为这些数据处理工具提供读写接口,并使用Hive的命令行接口发布数据定义和元数据探索命令。此外,经过封装这些命令,WebHcat Server还对外提供了RESTful接口,如下图所示。

Hive作为一个基于HDFS和MapReduce架构的数据仓库,其主要能力是通过对HQL(Hive Query Language)编译和解析,生成并执行相应的MapReduce任务或者HDFS操作。Hive与HiveQL相关信息,请参考HiveQL 语言手册。
如下图为Hive的结构简图。
- Metastore - 对表,列和Partition等的元数据进行读写及更新操作,其下层为关系型数据库。
- Driver - 管理HiveQL执行的生命周期并贯穿Hive任务整个执行期间。
- Compiler - 编译HiveQL并将其转化为一系列相互依赖的Map/Reduce任务。
- Optimizer - 优化器,分为逻辑优化器和物理优化器,分别对HiveQL生成的执行计划和MapReduce任务进行优化。
- Executor - 按照任务的依赖关系分别执行Map/Reduce任务。
- ThriftServer - 提供thrift接口,作为JDBC的服务端,并将Hive和其他应用程序集成起来。
- Clients - 包含WebUI和JDBC接口,为用户访问提供接口。
三、Hive CBO原理介绍
CBO,全称是Cost Based Optimization,即基于代价的优化器。
其优化目标是:
在编译阶段,根据查询语句中涉及到的表和查询条件,计算出产生中间结果少的高效join顺序,从而减少查询时间和资源消耗。
Hive中实现CBO的总体过程如下:
Hive使用开源组件Apache Calcite实现CBO。首先SQL语句转化成Hive的AST,然后转成Calcite可以识别的RelNodes。Calcite将RelNode中的Join顺序调整后,再由Hive将RelNode转成AST,继续Hive的逻辑优化和物理优化过程。流程图如下图所示:
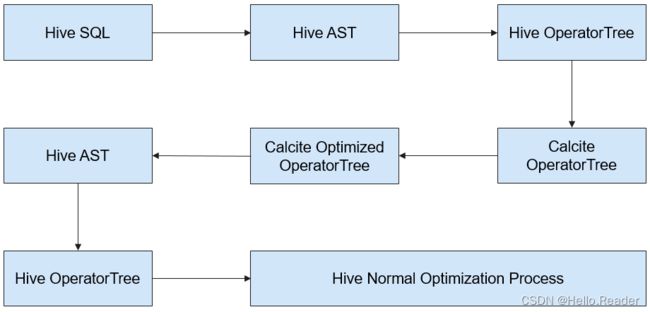
Calcite调整Join顺序的具体过程如下:
- 针对所有参与Join的表,依次选取一个表作为第一张表。
- 依据选取的第一张表,根据代价选择第二张表,第三张表。由此可以得到多个不同的执行计划。
- 计算出代价最小的一个计划,作为最终的顺序优化结果。
代价的具体计算方法:
当前版本,代价的衡量基于Join出来的数据条数:Join出来的条数越少,代价越小。Join条数的多少,取决于参与join的表的选择率。表的数据条数,取自表级别的统计信息。
过滤条件过滤后的条数,由列级别的统计信息,max,min,以及NDV(Number of Distinct Values)来估算出来。
例如存在一张表table_a,其统计信息如下:数据总条数1000000,NDV 50,查询条件如下:
Select * from table_a where colum_a='value1';
则估算查询的最终条数为1000000 * 1/50 = 20000条,选择率为2%。
以下以TPC-DS Q3为例来介绍CBO是如何调整Join顺序的。
select
dt.d_year,
item.i_brand_id brand_id,
item.i_brand brand,
sum(ss_ext_sales_price) sum_agg
from
date_dim dt,
store_sales,
item
where
dt.d_date_sk = store_sales.ss_sold_date_sk
and store_sales.ss_item_sk = item.i_item_sk
and item.i_manufact_id = 436
and dt.d_moy = 12
group by dt.d_year , item.i_brand , item.i_brand_id
order by dt.d_year , sum_agg desc , brand_id
limit 10;
语句解释:这个语句由三张表来做Inner join,其中store_sales是事实表,有约2900000000条数据,date_dim是维度表,有约73000条数据,item是维度表,有约18000条数据。每一个表上都有过滤条件,其Join关系如所下图示:

CBO应该先选择能起到最好过滤效果的表来join。
通过分析min,max,NDV,以及数据条数。CBO估算出不同维度表的选择率,详情如下表所示。
| 表名 | 原始数据条数 | 过滤后数据条数 | 选择率 |
|---|---|---|---|
| date_dim | 73000 | 6200 | 8.5% |
| item | 18000 | 19 | 0.1% |
上述表格获取到原始表的数据条数,估算出过滤后的数据条数后,计算出选择率=过滤后条数/原始条数。
从上表可以看出,item表具有较好的过滤效果,因此CBO将item表的join顺序提前。
CBO未开启时的Join示意图如下图所示:

CBO开启后的Join示意图如下图所示:
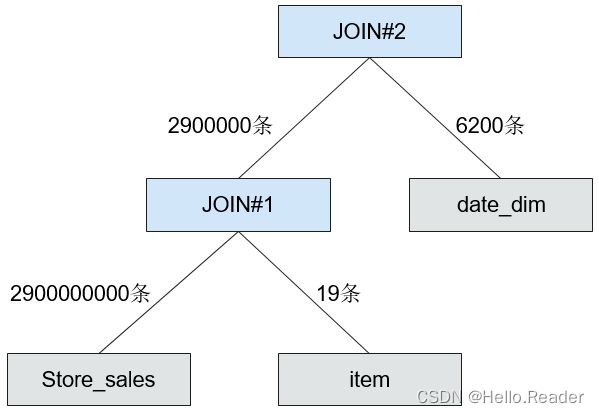
可以看出,优化后中间结果由495000000条减少到了2900000条,执行时间也大幅减少。
四、Hive与HDFS组件的关系
Hive是Apache的Hadoop项目的子项目,Hive利用HDFS作为其文件存储系统。Hive通过解析和计算处理结构化的数据,Hadoop HDFS则为Hive提供了高可靠性的底层存储支持。Hive数据库中的所有数据文件都可以存储在Hadoop HDFS文件系统上,Hive所有的数据操作也都是通过Hadoop HDFS接口进行的。
五、Hive与MapReduce组件的关系
Hive的数据计算依赖于MapReduce。MapReduce也是Apache的Hadoop项目的子项目,它是一个基于Hadoop HDFS分布式并行计算框架。Hive进行数据分析时,会将用户提交的HQL语句解析成相应的MapReduce任务并提交MapReduce执行。
六、Hive与Tez的关系
Tez是Apache的开源项目,它是一个支持有向无环图的分布式计算框架,Hive使用Tez引擎进行数据分析时,会将用户提交的HQL语句解析成相应的Tez任务并提交Tez执行。
七、Hive与DBService的关系
Hive的MetaStore(元数据服务)处理Hive的数据库、表、分区等的结构和属性信息(即Hive的元数据),这些信息需要存放在一个关系型数据库中,由MetaStore管理和处理。在产品中,Hive的元数据由DBService组件存储和维护,由Metadata组件提供元数据服务。
八、Hive与Elasticsearch的关系
Hive可以将Elasticsearch作为其扩展的文件存储系统。Hive通过集成Elasticsearch提供的Elasticsearch-Hadoop插件,建立外表,将表数据存储在Elasticsearch里,实现Hive读取和写入Elasticsearch索引数据的目的。