A Unified One-Step Solution for Aspect Sentiment Quad Prediction (2023 ACL) 文献阅读
A Unified One-Step Solution for Aspect Sentiment Quad Prediction (2023 ACL)
一种统一的一步式方面情感四元预测方法
论文地址: https://arxiv.org/pdf/2306.04152.pdf
论文代码: https://github.com/Datastory-CN/ASQP-Datasets (只有数据集没有论文代码)
个人阅读笔记,水平有限,如有问题欢迎指正交流
1. 介绍
1.1 研究目标
方面情感四元预测(ASQP)是一个具有挑战性的任务。是基于方面级别情感分析的重要子任务,因为它提供了一个完整的方面级的情感结构。
1.2 科学问题
然而,现有的ASQP数据集通常较小且密度较低,阻碍了技术进步。为了扩展容量,本文中,我们发布了两个新的ASQP数据集,它们包含以下特征:更大的尺寸、每个样本更多的字和更高的密度。
1.3 方法
有了这样的数据集,我们揭示了现有的强大的ASQP基线的缺点,因此提出了一个统一的一步解决方案ASQP,即One-ASQP,检测方面的类别,并同时确定aspect-opion-sentiment(AOS)三元组。
我们的One-ASQP具有几个独特的优势:
(1)通过将ASQP分解为两个子任务并独立地同时求解它们,可以避免基于流水线的方法中的错误传播,并克服基于生成的方法中的缓慢训练和推理;
(2)通过在基于标记对的二维矩阵中引入特定于情感的角标记模式,我们可以利用情感元素之间更深层次的相互作用并有效地解码AOS三元组;
(3)我们设计的“[NULL]”标记可以帮助我们有效地识别隐含的方面或观点。
1.4 创新点/贡献
我们的贡献有三个方面:
- 我们构建了两个新的ASQP数据集,包括更细粒度的样本,具有更高的四重密度,同时覆盖更多的领域和语言。值得注意的是,发布的zh-FoodBeverage数据集是第一个中文ASQP数据集,它为ASQP提供了在多语言环境中研究潜在技术的机会。
- 我们提出了One-ASQP同时检测方面类别和共同提取方面意见情感三元组。One-ASQP可以吸收情感元素之间更深层次的相互作用,而不会产生错误传播,并克服基于生成的方法的缓慢性能。此外,精心设计的“[NULL]”标记有助于我们有效地识别隐含的方面或观点。
- 我们进行了大量的实验,证明One-ASQP是有效的,并在某些情况下优于最先进的基线。
2. 任务案例
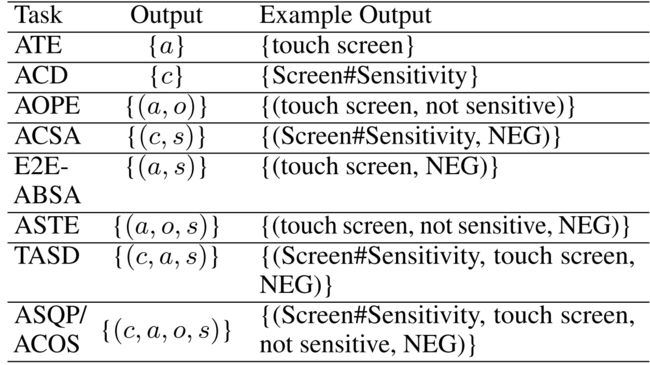
表1:针对各种ABSA任务的示例“touch screen is not sensitive”的输出。a、c、o、s和NEG的定义见第2节第1段。1.
3 数据集介绍
3.1 数据分布
我们构建了两个数据集1来扩展现有ASQP数据集的容量。

表2:ASQP任务的数据统计。#表示对应元件的数量。s、w、c、q分别代表样本、词、类别和四元组。EA、EO、IA和IO分别表示显性方面、显性意见、隐性方面和隐性意见。“-”表示不包括此项目。
3.2 数据来源
en-Phone是从2021年7月和8月多个电商平台的评论中收集的英文数据集,涵盖12个手机品牌。为了增加数据集的复杂性和四倍密度,我们提供了以下过滤步骤:(1)应用LangID工具包2过滤掉正文内容不是英文的评论;(2)滤除具有少于8个有效令牌的样本。
zh-FoodBeverage是第一个中文ASQP数据集,收集了2019-2021年食品和饮料类别下多个来源的中文评论。我们通过(1)过滤掉长度小于8且大于4000的样本来清理数据;(2)过滤掉有效汉字少于70%的样本;(3)利用分类器过滤出广告文本,所述分类器由具有90%分类准确率的营销文本训练而成。
4 模型架构
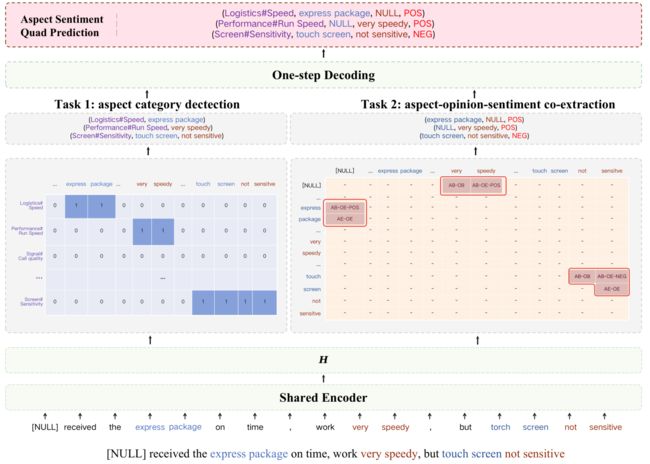
图1:One-ASQP的结构:同时解决ACD和AOSC。ACD由多类分类器实现。AOSC是由一个基于令牌对的2D矩阵与情感特定的号角标记。“[NULL]”行中的结果表明“very speedy”的意见没有任何方面。相比之下,“[NULL]”列中的结果意味着对“express package”方面没有意见。
5. 方法
5.1 ASQP制定
给定一个句子 x x x, A S Q P ASQP ASQP将预测所有方面级情感四元组 { ( c , a , o , s ) } \{(c,a,o,s)\} {(c,a,o,s)},其分别对应于方面类别、方面术语、观点术语和情感极性。方面类别 c c c属于类别集合 C C C; 方面术语 A A A和意见术语 O O O通常是 x x x中的文本跨度,而如果没有明确提及目标(隐式术语),即 a ∈ V x ∪ { ∅ } a ∈ V_x ∪\{\empty\} a∈Vx∪{∅}和 o ∈ V x ∪ { ∅ } o ∈ V_x ∪ \{\empty\} o∈Vx∪{∅},其中 V x V_x Vx表示包含 x x x的所有可能连续跨度的集合。情感极性s属于情感类之一, S = { P O S , N E U , N E G } S=\{POS,NEU,NEG\} S={POS,NEU,NEG},其分别对应于积极情感、中性情感和消极情感。
5.2 One-ASQP
我们的一个ASQP解决了两个子任务,ACD和AOSC,同时,其中ACD通过一个分类器来确定方面类别,AOSC是提取所有 ( a , o , s ) (a,o,s) (a,o,s)三元组。
给定具有 n n n个token的 x x x,我们构造输入如下:

其中引入令牌 [ N U L L ] [NULL] [NULL]用来检测隐式的方面术语或意见术语;更多详情请参见3.2.2.节。现在,通过预先训练的语言模型,两个任务(ACD,AOSC)共享一个共同的编码器来获得表示:

其中 d d d是令牌表示大小。
5.2.1 方面类别检测 (ACD)
我们应用分类器来预测类别检测的概率:

其中 W 1 ∈ R d × d W_1 ∈ R^{d×d} W1∈Rd×d, b 1 ∈ R d b_1 ∈ R^d b1∈Rd, W 2 ∈ R ∣ C ∣ × d W_2 ∈ R^{|C| ×d} W2∈R∣C∣×d.给你 ∣ C ∣ |C| ∣C∣是 C C C中的类别数。因此, C ∈ R ∣ C ∣ × ( n + 1 ) C ∈ R^{|C| \times (n+1)} C∈R∣C∣×(n+1),其中 C i j C_{ij} Cij指示第 i t h i^{th} ith牌到第 j t h j^{th} jth个类别的概率。
5.2.1 三元组提取AOSC(ASTE)
我们解决AOSC通过一个基于标记对的二维矩阵与特定的情感角标记模式,以确定方面意见术语对和他们的情感极性的位置。
标记方案
我们定义了四种类型的标记:
(1) A B _ O B AB\_OB AB_OB表示方面-观点术语对的开始位置的单元格。例如,由于**(“touch screen”, “not sensitive”) 是方面-意见对,所以2D矩阵中对应于(“touch”, “not”)** 的单元格由" A B _ O B AB\_OB AB_OB"标记。
(2) A E _ O E AE\_OE AE_OE表示方面-意见对的结束位置的单元格。因此**(“screen”, “sensitive”)的单元格由 A E _ O E AE\_OE AE_OE标记。
(3) A B _ O E _ s e n t i m e n t AB\_OE\_sentiment AB_OE_sentiment定义了一个带有情感极性的单元格,其中行**位置表示一个方面的开始,列位置表示一个观点的结束。因此,单元格由 A B _ O E _ N E G AB\_OE\_NEG AB_OE_NEG标记。由于SENTIMENT由三种类型的情感极性组成,因此在 A B _ O E − s e n t i m e n t AB\_OE-sentiment AB_OE−sentiment中存在三种情况。
(4) "-"表示除上述三种类型之外的细胞。因此,我们有五种类型的独特标签, { A B _ O B , A E _ O E , A B _ O E _ P O S , A B _ O E _ N E U , A B _ O E _ N E G } \{AB\_OB,AE\_OE,AB\_OE\_POS,AB\_OE\_NEU,AB\_OE\_NEG\} {AB_OB,AE_OE,AB_OE_POS,AB_OE_NEU,AB_OE_NEG}。
三元组解码
由于标记的2D矩阵已经标记了所有方面对的边界标记及其情感极性,因此我们可以容易地解码三元组。
首先,通过逐列扫描2D矩阵,我们可以确定方面的文本跨度,
从 A B _ O E _ s e n t i m e n t AB\_OE\_sentiment AB_OE_sentiment开始,以 A E _ O E AE\_OE AE_OE结束。类似地,通过逐行扫描2D矩阵,我们可以得到观点的文本跨度,其从 A B _ O B AB\_OB AB_OB开始并以 A B _ O E _ s e n t i m e n t AB\_OE\_sentiment AB_OE_sentiment结束。最后,可以通过 A B _ O E _ s e n t i m e n t AB\_OE\_sentiment AB_OE_sentiment容易地确定情感极性。
隐式方面/意见术语提取
检测隐式的方面或意见在 A S Q P ASQP ASQP中是至关重要的。我们在输入的开始处附加 [ N U L L ] [NULL] [NULL]标记。然后,我们的 O n e _ A S Q P One\_ASQP One_ASQP可以很容易地确定隐含方面和明确意见 ( I A & E O ) (IA\&EO) (IA&EO)和明确方面和隐含意见 ( E A & I O ) (EA\&IO) (EA&IO)的情况。
整个过程类似于上述三元组解码:当文本在 [ N U L L ] [NULL] [NULL]行跨越从 A B _ O B AB\_OB AB_OB开始到以 A B _ O E _ ∗ S E N T I M E N T AB\_OE\_^*SENTIMENT AB_OE_∗SENTIMENT结束时,我们可以获得没有方面的显式意见术语。同时,当文本跨越 [ N U L L ] [NULL] [NULL]列时,从 A B _ O E _ s e n t i m e n t AB\_OE\_sentiment AB_OE_sentiment开始并以 A E _ O E AE\_OE AE_OE结束,我们可以获得没有意见的显示方面术语。如图1所示。我们可以快速获得相应的方面意见对 ( N U L L , v e r y s p e e d y ) (NULL,very speedy) (NULL,veryspeedy) 和 " ( e x p r e s s p a c k a g e , N U L L ) " "(express package,NULL)" "(expresspackage,NULL)"。情绪极性也可以相应地通过 A B _ O E _ ∗ S E N T I M E N T AB\_OE\_^*SENTIMENT AB_OE_∗SENTIMENT来确定。虽然 I A & I O IA\&IO IA&IO的当前设置无法直接解决,但可以分两步解决。首先,我们可以使用诸如 E x t r a c t C l a s s i f y _ A C O S ExtractClassify\_ACOS ExtractClassify_ACOS。然后,我们可以分类方面类别和情感极性。然而,一个统一的解决方案与 O n e _ A S Q P One\_ASQP One_ASQP是留给未来的工作。
标签评分
给定 H H H,我们通过下式计算 ( i , j ) t h (i, j)^{th} (i,j)th单元到对应标签的概率:

其中 W a ∈ R D × d W_a ∈ R^{D×d} Wa∈RD×d和 W o ∈ R D × d W_o ∈ R^{D×d} Wo∈RD×d分别是方面token和意见token的权重矩阵, b a ∈ R D b_a ∈ R^D ba∈RD和 b o ∈ R D b_o ∈ R^D bo∈RD分别是方面token和意见token的偏差。 D D D是默认设置为400的隐藏变量大小。
5.3 训练过程
训练我们通过最小化以下损失函数来联合训练ACD和AOSC:
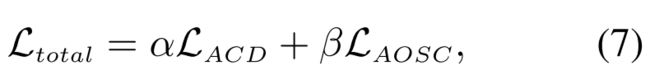
其中 α α α和 β β β是为简单起见设置为1的折衷常数。ACD损失 L A C D L_{ACD} LACD和AOSC损失 L A O S C L_{AOSC} LAOSC是两个交叉熵损耗,定义如下:

其中 C i j C_{ij} Cij是由等式(3)计算的预测类别。 y i j C ∈ { 0 , 1 } y^C_{ij} ∈ \{0,1\} yijC∈{0,1},并且当第 i i i个令牌被分配给第 j j j个类别时为1,否则为0。 P i j P_{ij} Pij是由等式(6)计算的预测标记得分。对于所有五种类型的标签,而 Y i j ∈ R 5 Y_{ij} ∈ R^5 Yij∈R5是地面实况独热编码。
在训练期间,我们实现负采样策略,以提高我们的One-ASQP在未标记四元组上的性能。我们将负采样率设置为0.4,这是(Li et al.2021年)取得了良好的成绩建议范围。具体来说,为了最小化等式(7)中的损失。我们随机抽取40%的未标记条目作为负实例,其对应于ACD中的 ‘ 0 ’ ‘0’ ‘0’和AOSC中的**‘-’**,如图1所示。(数据增强方法)
5.4 四元组解码
模型得到后,我们可以同时得到 A O S C AOSC AOSC矩阵中的 A C D ACD ACD和 A O S AOS AOS三元组的类别序列。然后,我们通过它们的公共术语在一个步骤中解码四元组。
例如,如图1所示。我们可以通过公共术语合并(Logistics#Speed,express package)和(express package,NULL,POS),“express package”,并获得方面情感四元组(Logistics#Speed,express package,NULL,POS)。(通过公共的方面术语或者意见术语对齐的方式解码方面情感四元组)
总的来说,我们的One-ASQP由两个独立的任务组成, A C D ACD ACD和 A O S C AOSC AOSC。它们的输出仅在最终解码阶段共享,并且在训练期间不像基于流水线的方法所需要的那样相互依赖。这使我们能够有效地训练模型,并在训练和测试中一致地解码结果。
6 实验结果
6.1 对比实验

表3:餐馆-ACOS和膝上型ACOS的结果。用不同的种子在5次运行中平均得分。

表4:en-Phone和zh-FoodBeverage的结果。分数是用不同种子的五次运行的平均值。

表6: 分解表现(F1分数),以描述处理隐含方面或意见的能力。E和I分别代表Explicit和Implicit,而A和O分别表示Aspect和Opinion。

表7:One-ASQP对两次损失的消融研究。