【python第三方库】playwright简要入门
参考链接: https://blog.csdn.net/lb245557472/article/details/111572119
概述
Playwright是由微软公司2020年初发布的新一代自动化测试工具,相较于目前最常用的Selenium,它仅用一个API即可自动执行Chromium、Firefox、WebKit等主流浏览器自动化操作。作为针对 Python 语言纯自动化的工具,在回归测试中可更快的实现自动化。
1. 为什么选择Playwright
1.1 Playwright的优势
(1) Selenium需要通过WebDriver操作浏览器;Playwright通过开发者工具与浏览器交互,安装简洁,不需要安装各种Driver。
(2) Playwright几乎支持所有语言,且不依赖于各种Driver,通过调用内置浏览器所以启动速度更快。
(3) Selenium基于HTTP协议(单向通讯),Playwright基于Websocket(双向通讯)可自动获取浏览器实际情况。
(4) Playwright为自动等待。
- 等待元素出现(定位元素时,自动等待30s,等待时间可以自定义,单位毫秒)
- 等待事件发生
1.2 已知局限性
(1) Playwright不支持旧版Microsoft Edge或IE11。支持新的Microsoft Edge(在Chromium上);所以对浏览器版本有硬性要求的项目不适用。
(2) 需要SSL证书进行访问的网站可能无法录制,该过程需要单独定位编写。
(3) 移动端测试是通过桌面浏览器来模拟移动设备(相当于自带模拟器),无法控制真机。
2. Playwright安装
(1)安装Playwright依赖库(Playwright支持Async\Await语法,故需要Python3.7+)
# 使用阿里源,下载速度快一点。
pip install playwright -i https://mirrors.aliyun.com/pypi/simple/
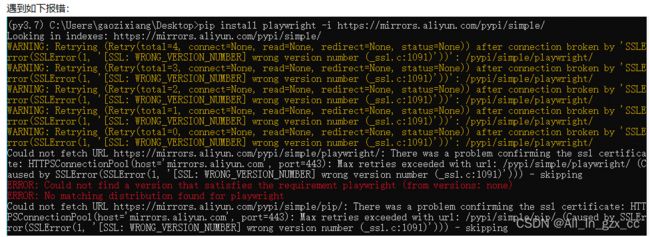
解决方法: https://www.cnblogs.com/chenyibai/p/10721656.html
(2)安装Chromium、Firefox、WebKit等浏览器的驱动文件(内置浏览器)
# 安装chromium、frefox、webkit。
python -m playwright install
代码示例
1. 打开百度搜索,截图退出
playwright提供了同步和异步的API接口,文档如下。
链接:https://playwright.dev/python/docs/intro/
page自动等待和断言 方法详解
https://www.jb51.net/article/230460.htm
1.1 同步模式
from playwright import sync_playwright
with sync_playwright() as p:
# 可以选择chromium、firefox和webkit
browser_type = p.chromium
# 运行chrome浏览器,executablePath指定本地chrome安装路径
# browser = browser_type.launch(headless=False,slowMo=50,executablePath=r"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe")
browser = browser_type.launch(headless=False)
page = browser.newPage()
page.goto('https://www.baidu.com/')
page.screenshot(path=f'example-{browser_type.name}.png')
browser.close()
1.2 异步模式
import asyncio
from playwright import async_playwright
async def main():
async with async_playwright() as p:
browser_type = p.chromium
browser = await browser_type.launch(headless=False)
page = await browser.newPage()
await page.goto('https://www.baidu.com/')
await page.screenshot(path=f'example-{browser_type.name}.png')
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
1.3 模拟手机模式
from playwright import sync_playwright
with sync_playwright() as p:
iphone_11 = p.devices['iPhone 11 Pro']
browser = p.webkit.launch(headless=False)
context = browser.newContext(
**iphone_11,
locale='zh-CN'
)
page = context.newPage()
page.goto('https://www.baidu.com/')
page.click('#logo')
page.screenshot(path='colosseum-iphone.png')
browser.close()
1.4 浏览器中运行JS
from playwright import sync_playwright
with sync_playwright() as p:
browser = p.firefox.launch(headless=False, slowMo=1000)
page = browser.newPage()
page.goto('https://www.baidu.com/')
dimensions = page.evaluate('''() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio
}
}''')
print(dimensions)
browser.close()
2. 录制 生成代码
使用Playwright无需写一行代码,我们只需手动操作浏览器,它会录制我们的操作,然后自动生成代码脚本。
codegen的用法可以使用–help查看,如果简单使用就是直接在命令后面加上url链接,如果有其他需要可以添加options。
python -m playwright codegen --help
Usage: index codegen [options] [url]
open page and generate code for user actions
Options:
-o, --output <file name> saves the generated script to a file
--target <language> language to use, one of javascript, python, python-async, csharp (default: "python")
-h, --help display help for command
Examples:
$ codegen
$ codegen --target=python
$ -b webkit codegen https://example.com
options含义:
- -o:将录制的脚本保存到一个文件
- –target:规定生成脚本的语言,有JS和Python两种,默认为Python
- -b:指定浏览器驱动
比如,我要在baidu.com搜索,用chromium驱动,将结果保存为my.py的python文件。
python -m playwright codegen --target python -o 'my.py' -b chromium https://www.baidu.com
命令行输入后会自动打开浏览器,然后可以看见在浏览器上的一举一动都会被自动翻译成代码,如下所示。
结束后自动关闭浏览器,保存生成的自动化脚本到py文件。
from playwright import sync_playwright
def run(playwright):
browser = playwright.chromium.launch(headless=False)
context = browser.newContext()
# Open new page
page = context.newPage()
page.goto("https://www.baidu.com/")
page.click("input[name=\"wd\"]")
page.fill("input[name=\"wd\"]", "jingdong")
page.click("text=\"京东\"")
# Click //a[normalize-space(.)='京东JD.COM官网 多快好省 只为品质生活']
with page.expect_navigation():
with page.expect_popup() as popup_info:
page.click("//a[normalize-space(.)='京东JD.COM官网 多快好省 只为品质生活']")
page1 = popup_info.value
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
3. 个人爬虫代码示例
百度图片输出关键字 并爬取图片
from playwright.sync_api import sync_playwright
import requests
import time
def run(playwright):
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
# Open new page
page = context.new_page()
# Go to https://www.baidu.com/
page.goto("https://image.baidu.com/")
# Click input[name="wd"]
page.click("input[name=\"word\"]")
# Fill input[name="wd"]
page.fill("input[name=\"word\"]", "美女")
# Press Enter
page.press("input[name=\"word\"]", "Enter")
# assert page.url == "https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=%E8%87%AA%E5%8A%A8%E5%8C%96%E6%B5%8B%E8%AF%95&fenlei=256&rsv_pq=88dcbfd8000550eb&rsv_t=d783NUQ8df%2BNjkvSoOoFTFDteq6CMWv5vFl0hhLwCVm30D%2Bv2VS51wdwYiU&rqlang=cn&rsv_dl=tb&rsv_enter=1&rsv_sug3=16&rsv_sug1=14&rsv_sug7=100&rsv_sug2=0&rsv_btype=i&inputT=8&rsv_sug4=5241"
for i in range(1000):
page.press("body", "PageDown")
imgitems = page.locator('li[class="imgitem"]')
for i in range(imgitems.count()):
img_url = imgitems.nth(i).get_attribute('data-objurl')
if img_url:
for j in range(2):
try:
r = requests.get(img_url, stream=True)
if r.status_code == 200:
print(img_url)
with open(f"G:/firetmp/7/{i}.jpg", 'wb') as f:
f.write(r.content)
break
except:
continue
time.sleep(1)
page.close()
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)