使用实体解析和图形神经网络进行欺诈检测
图形神经网络的表示形式(作者使用必应图像创建器生成的图像)
一、说明
对于金融、电子商务和其他相关行业来说,在线欺诈是一个日益严重的问题。为了应对这种威胁,组织使用基于机器学习和行为分析的欺诈检测机制。这些技术能够实时检测异常模式、异常行为和欺诈活动。
不幸的是,通常只考虑当前交易,例如订单,或者该过程仅基于客户配置文件中的历史数据,这些数据由客户ID标识。但是,专业欺诈者可能会使用低价值交易创建客户资料,以建立其个人资料的正面形象。此外,他们可能会同时创建多个类似的配置文件。只有在欺诈发生后,被攻击的公司才意识到这些客户资料是相互关联的。
使用实体解析,可以轻松地将不同的客户档案组合到一个 360° 客户视图中,从而可以查看所有历史交易的全貌。虽然在机器学习中使用这些数据,例如使用神经网络甚至简单的线性回归,已经为生成的模型提供了额外的价值,但真正的价值来自于观察各个交易如何相互连接。这就是图神经网络(GNN)发挥作用的地方。除了查看从事务记录中提取的特征外,它们还提供了查看从图形边缘生成的特征(事务如何相互链接)甚至只是实体图的一般布局的可能性。
二、示例数据
在我们深入研究细节之前,我有一个免责声明要在这里提出:我是开发人员和实体解析专家,而不是数据科学家或 ML 专家。虽然我认为一般方法是正确的,但我可能没有遵循最佳实践,也无法解释某些方面,例如隐藏节点的数量。使用本文作为灵感,并在GNN布局或配置方面借鉴您自己的经验。
出于本文的目的,我想重点介绍从实体图布局中获得的见解。为此,我创建了一个生成实体的小 Golang 脚本。每个实体都被标记为欺诈性或非欺诈性,由记录(订单)和边缘(这些订单的链接方式)组成。请参阅以下单个实体的示例:
{
"fraud":1,
"records":[
{
"id":0,
"totalValue":85,
"items":2
},
{
"id":1,
"totalValue":31,
"items":4
},
{
"id":2,
"totalValue":20,
"items":9
}
],
"edges":[
{
"a":1,
"b":0,
"R1":1,
"R2":1
},
{
"a":2,
"b":1,
"R1":0,
"R2":1
}
]
}每条记录有两个(潜在)特征,即总价值和购买的物品数量。但是,生成脚本完全随机化了这些值,因此在猜测欺诈标签时,它们不应提供价值。每个边还具有两个特征 R1 和 R2。例如,这些可以表示两个记录A和B是通过相似的名称和地址(R1)还是通过相似的电子邮件地址(R2)链接的。此外,我故意省略了与此示例无关的所有属性(姓名、地址、电子邮件、电话号码等),但通常事先与实体解析过程相关。由于 R1 和 R2 也是随机的,它们也不能为 GNN 提供价值。但是,根据欺诈标签,边缘以两种可能的方式布局:星形布局(欺诈=0)或随机布局(欺诈=1)。
这个想法是,非欺诈性客户更有可能提供准确匹配的相关数据,通常是相同的地址和相同的名称,这里和那里只有几个拼写错误。因此,新交易可能会被识别为重复交易。

重复数据删除的实体(图片由作者提供)
欺诈性客户可能希望使用各种名称和地址隐藏他们仍然是计算机后面的同一个人的事实。但是,实体解析工具可能仍可识别相似性(例如地理和时间相似性、电子邮件地址中的重复模式、设备 ID 等),但实体图可能看起来更复杂。
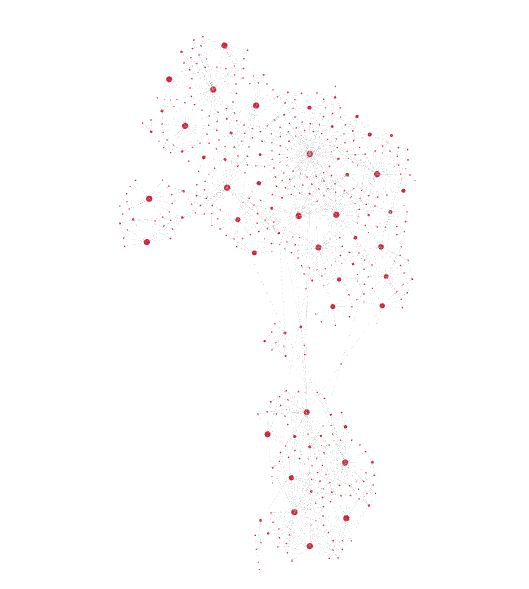
复杂,可能是欺诈实体(图片来源:作者)
为了使它不那么简单,生成脚本还具有 5% 的错误率,这意味着当实体具有类似星形的布局时,它们被标记为欺诈性,而随机布局则标记为非欺诈性。此外,在某些情况下,数据不足以确定实际布局(例如,只有一条或两条记录)。
{
"fraud":1,
"records":[
{
"id":0,
"totalValue":85,
"items":5
}
],
"edges":[
]
}实际上,您很可能会从所有三种要素(记录属性、边属性和边布局)中获得有价值的见解。下面的代码示例将考虑这一点,但生成的数据不会。
三、创建数据集
该示例使用 python(数据生成除外)和带有 pytorch 后端的 DGL。您可以在github上找到完整的jupyter笔记本,数据和生成脚本。
让我们从导入数据集开始:
import os
os.environ["DGLBACKEND"] = "pytorch"
import pandas as pd
import torch
import dgl
from dgl.data import DGLDataset
class EntitiesDataset(DGLDataset):
def __init__(self, entitiesFile):
self.entitiesFile = entitiesFile
super().__init__(name="entities")
def process(self):
entities = pd.read_json(self.entitiesFile, lines=1)
self.graphs = []
self.labels = []
for _, entity in entities.iterrows():
a = []
b = []
r1_feat = []
r2_feat = []
for edge in entity["edges"]:
a.append(edge["a"])
b.append(edge["b"])
r1_feat.append(edge["R1"])
r2_feat.append(edge["R2"])
a = torch.LongTensor(a)
b = torch.LongTensor(b)
edge_features = torch.LongTensor([r1_feat, r2_feat]).t()
node_feat = [[node["totalValue"], node["items"]] for node in entity["records"]]
node_features = torch.tensor(node_feat)
g = dgl.graph((a, b), num_nodes=len(entity["records"]))
g.edata["feat"] = edge_features
g.ndata["feat"] = node_features
g = dgl.add_self_loop(g)
self.graphs.append(g)
self.labels.append(entity["fraud"])
self.labels = torch.LongTensor(self.labels)
def __getitem__(self, i):
return self.graphs[i], self.labels[i]
def __len__(self):
return len(self.graphs)
dataset = EntitiesDataset("./entities.jsonl")
print(dataset)
print(dataset[0])这将处理实体文件,这是一个 JSON 行文件,其中每行表示一个实体。在迭代每个实体时,它会生成边特征(形状为 [e, 2]、e=边数的长张量)和节点特征(形状为 [n, 2] 的长张量,n=节点数)。然后,它继续基于 a 和 b(每个长张量具有形状 [e, 1])构建图形,并将边和图形特征分配给该图形。然后将所有生成的图形添加到数据集中。
四、模型架构
现在我们已经准备好了数据,我们需要考虑GNN的架构。这是我想出来的,但可能可以根据实际需求进行更多调整:
import torch.nn as nn
import torch.nn.functional as F
from dgl.nn import NNConv, SAGEConv
class EntityGraphModule(nn.Module):
def __init__(self, node_in_feats, edge_in_feats, h_feats, num_classes):
super(EntityGraphModule, self).__init__()
lin = nn.Linear(edge_in_feats, node_in_feats * h_feats)
edge_func = lambda e_feat: lin(e_feat)
self.conv1 = NNConv(node_in_feats, h_feats, edge_func)
self.conv2 = SAGEConv(h_feats, num_classes, "pool")
def forward(self, g, node_features, edge_features):
h = self.conv1(g, node_features, edge_features)
h = F.relu(h)
h = self.conv2(g, h)
g.ndata["h"] = h
return dgl.mean_nodes(g, "h")构造函数采用节点要素数、边要素数、隐藏节点数和标签(类)数。然后,它创建两个层:一个基于边和节点特征计算隐藏节点的 NNConv 层,然后是一个基于隐藏节点计算结果标签的 GraphSAGE 层。
五、培训和测试
快到了。接下来,我们准备用于训练和测试的数据。
from torch.utils.data.sampler import SubsetRandomSampler
from dgl.dataloading import GraphDataLoader
num_examples = len(dataset)
num_train = int(num_examples * 0.8)
train_sampler = SubsetRandomSampler(torch.arange(num_train))
test_sampler = SubsetRandomSampler(torch.arange(num_train, num_examples))
train_dataloader = GraphDataLoader(
dataset, sampler=train_sampler, batch_size=5, drop_last=False
)
test_dataloader = GraphDataLoader(
dataset, sampler=test_sampler, batch_size=5, drop_last=False
)我们使用随机抽样以 80/20 的比例进行拆分,并为每个样本创建一个数据加载器。最后一步是用我们的数据初始化模型,运行训练,然后测试结果。
h_feats = 64
learn_iterations = 50
learn_rate = 0.01
model = EntityGraphModule(
dataset.graphs[0].ndata["feat"].shape[1],
dataset.graphs[0].edata["feat"].shape[1],
h_feats,
dataset.labels.max().item() + 1
)
optimizer = torch.optim.Adam(model.parameters(), lr=learn_rate)
for _ in range(learn_iterations):
for batched_graph, labels in train_dataloader:
pred = model(batched_graph, batched_graph.ndata["feat"].float(), batched_graph.edata["feat"].float())
loss = F.cross_entropy(pred, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
num_correct = 0
num_tests = 0
for batched_graph, labels in test_dataloader:
pred = model(batched_graph, batched_graph.ndata["feat"].float(), batched_graph.edata["feat"].float())
num_correct += (pred.argmax(1) == labels).sum().item()
num_tests += len(labels)
acc = num_correct / num_tests
print("Test accuracy:", acc)我们通过提供节点和边的特征大小(在我们的例子中都是 2)、隐藏节点 (64) 和标签数量(2,因为它要么是欺诈,要么不是欺诈)来初始化模型。然后以 0.01 的学习率初始化优化器。之后,我们总共运行 50 次训练迭代。训练完成后,我们使用测试数据加载器测试结果并打印结果的准确性。
对于各种运行,我的典型准确度在 70% 到 85% 的范围内。但是,除了少数例外,降至55%左右。
六、结论
鉴于我们的示例数据集中唯一可用的信息是解释节点是如何连接的,初步结果看起来非常有希望,并表明通过真实世界的数据和更多的训练可以实现更高的准确率。
斯特凡·伯克纳
显然,在处理真实数据时,布局并不那么一致,并且没有在布局和欺诈行为之间提供明显的相关性。因此,您还应考虑边缘和节点功能。本文的关键要点应该是,实体解析为使用图形神经网络的欺诈检测提供了理想的数据,并且应被视为欺诈检测工程师工具库的一部分。