Hadoop完全分布式安装,全网最详细!
大数据系统开发
一、CentOS7系统安装
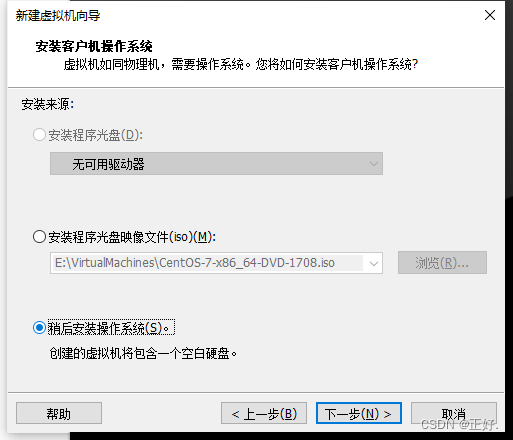
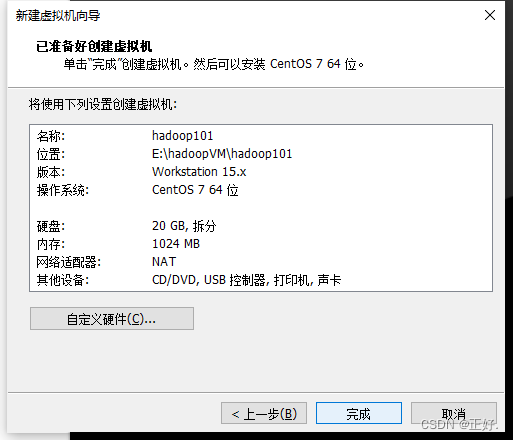
1、新建虚拟机




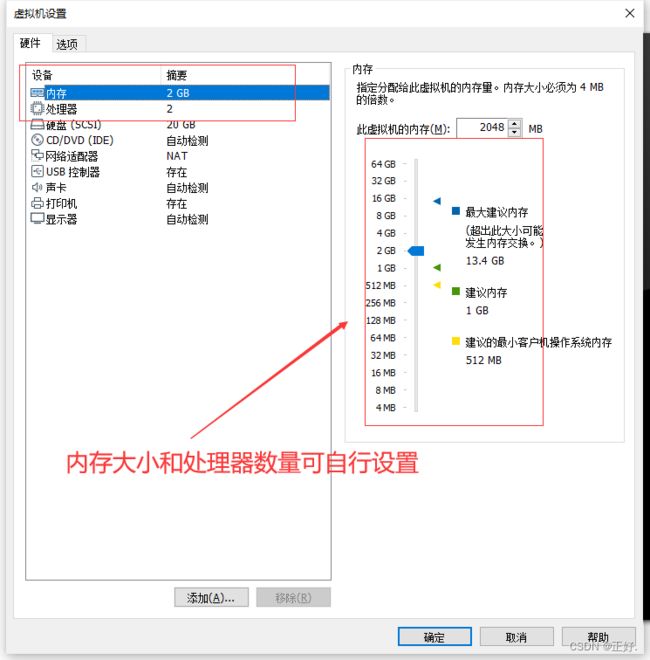
2、编辑虚拟机参数
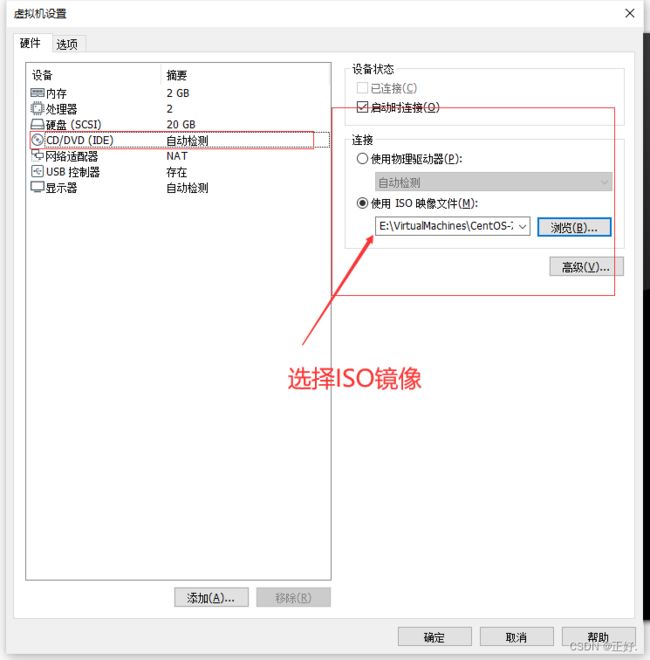
3、安装操作系统
3.1开启虚拟机

3.2选择install CentOS7
白色字体显示,通过键盘的上下键进行选择

然后回车;
3.3选择语言

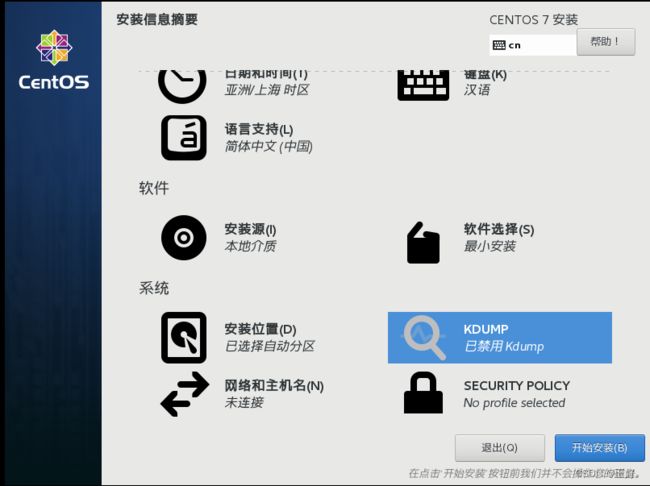
3.4套件选择;磁盘位置;KDUMP禁用
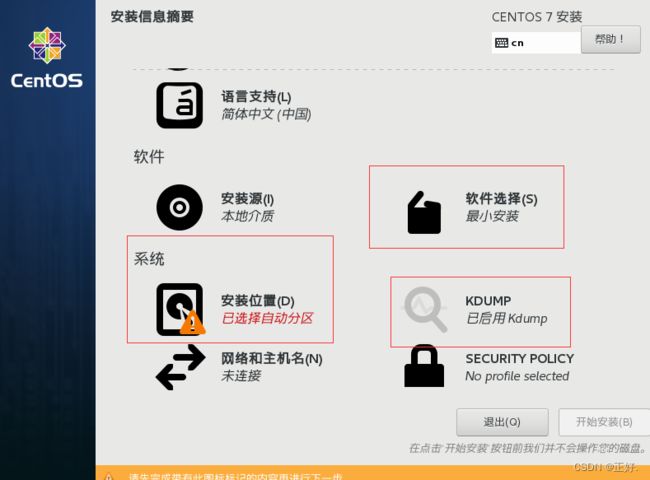
3.4.1选择最小化安装

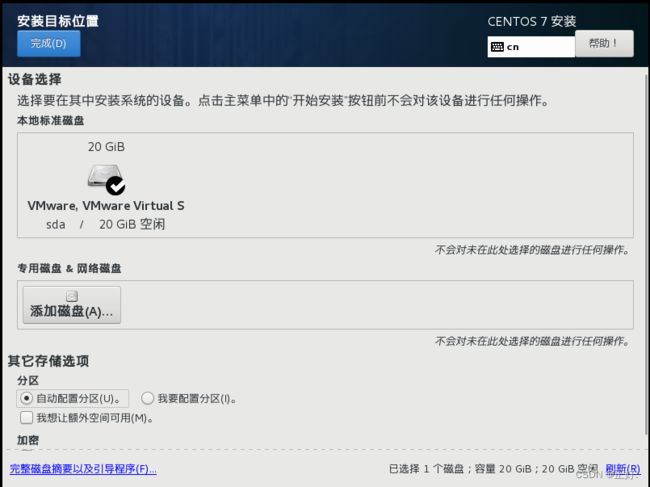
3.4.2安装目标位置
不需要任何操作,直接点完成
3.4.3KDUMP禁用

3.5开始安装
3.6设置一个root密码和创建一个账号
3.6.1设置 root密码:

3.6.2 创建一个账号:
账号密码随意设置,自己记住就行!
二 、配置CentOS 7基础环境
1、登录虚拟机

2、基础网络配置
(1)查看当前ip:ifconfig 或 ip addr
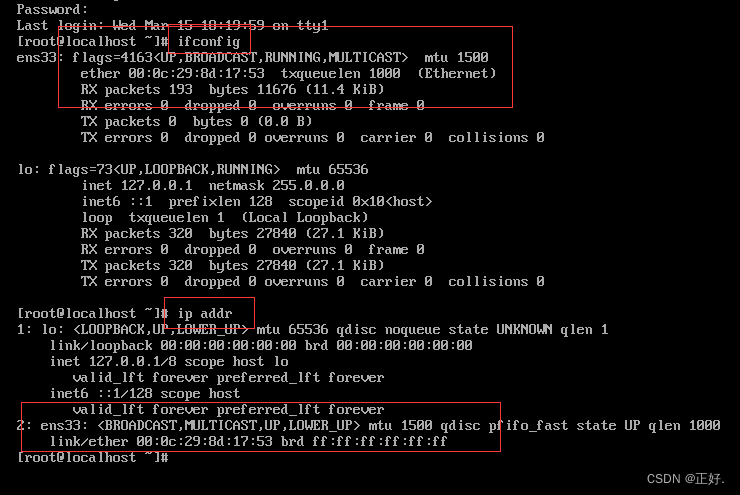
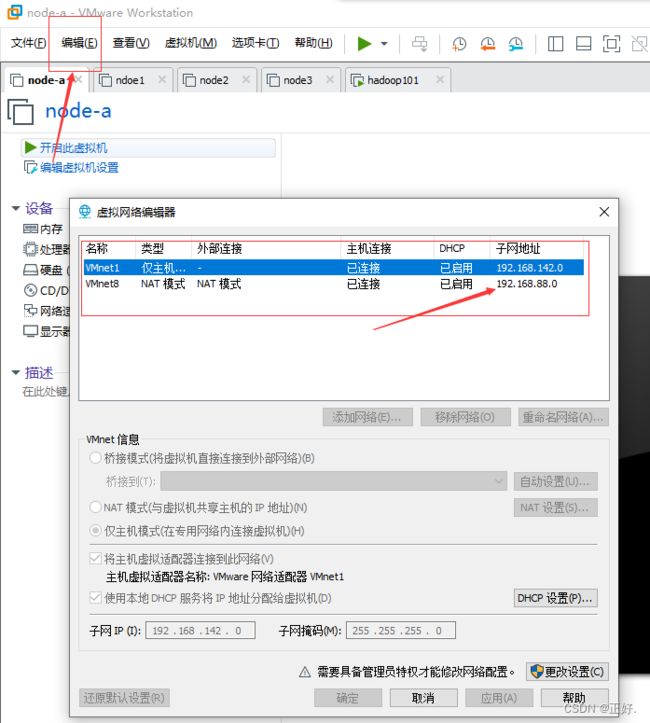
(2)查看虚拟机NAT模式网关(192.168.61.2)
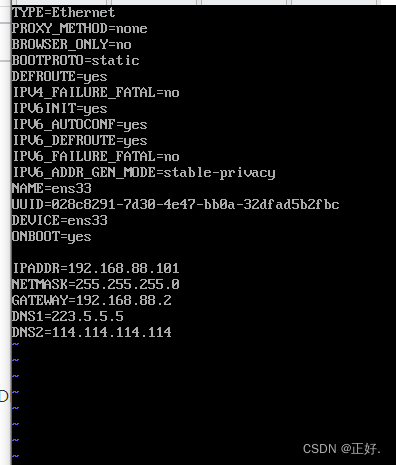
(3)配置ip信息:
vim /etc/sysconfig/network-scripts/ifcfg-ens33
# 修改BOOTPROTO=static
# 修改ONBOOT=yes
# 添加IPADDR=与上面NET模式子网地址相同,最后以为可以随意填(例如:192.168.88.101)
# 添加NETMASK=255.255.255.0
# 添加GATEWAY=子网地址,最后一位修改为2(例如:192.168.88.2)
# 添加DNS1=223.5.5.5(阿里)
# 添加NDS2=114.114.114.114(全国通用)
(4)重启网络服务
systemctl restart network
(5)再次查看网络配置
ifconfig
ens33的一些信息已经发生了改变

(6)ping 百度:
ping www.baidu.com
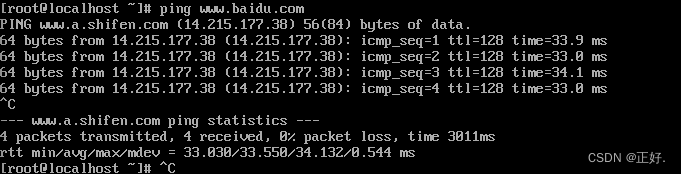
(7)重启网络管理服务器
systemctl restart NetworkManager
(8)关闭防火墙
systemctl stop firewalld
(9)禁用防火墙
systemctl disable firewalld
(10)查看防火墙状态
systemctl status firewalld
(11)禁用selinux
vi /etc/selinux/config
# SELINUX=disabled
3、客户端远程连接(xshell/finallshell)
ssh远程连接

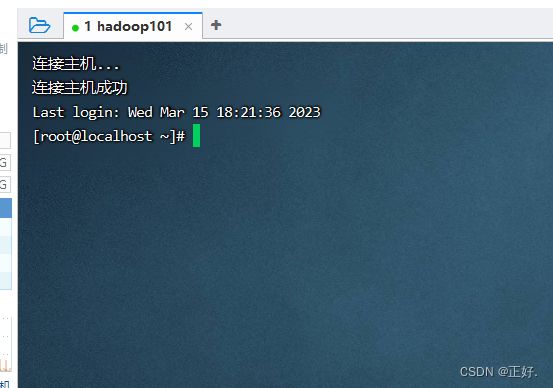
4、设置时间同步服务
(1)在线安装时间同步服务:
yum install -y ntp
(2)在线安装vim编辑工具
yum insyall -y vim
(3) 设置定时任务,要求ntp每隔1分钟与时间服务器同步一次:
crontab -e
# */1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com
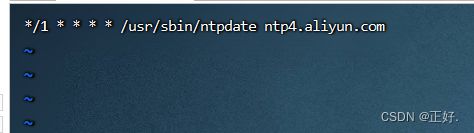
5、安装与配置JDK11
(1)新建目录:
mkdir /opt/softwares /opt/modules
(2)使用finalshell上传jdk到/opt/softwares目录

(3)解压jdk11
tar -zxvf jdk-11.0.16.1_linux-x64_bin.tar.gz -C ../modules/
(4)配置JAVA_HOME和PATH:
vim /etc/profile
JAVA_HOME=/opt/modules/jdk-11.0.16.1
export PATH=$PATH:$JAVA_HOME/bin
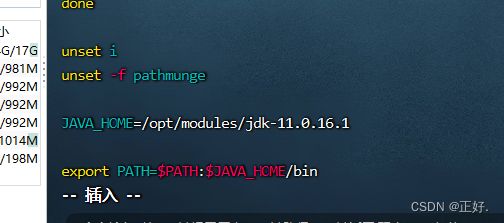
(5)刷新:
source /etc/profile
(6)测试是否配置成功:
java -version

(7)修改主机名
vim /etc/hostname
hadoop101
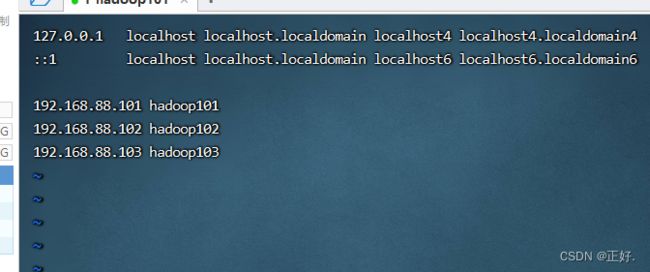
(8)修改hosts
vim /etc/hosts
192.168.88.101 hadoop101
192.168.88.102 hadoop102
192.168.88.103 hadoop103
三、克隆虚拟机
1、以hadoop101为母版,克隆hadoop102、hadoop103

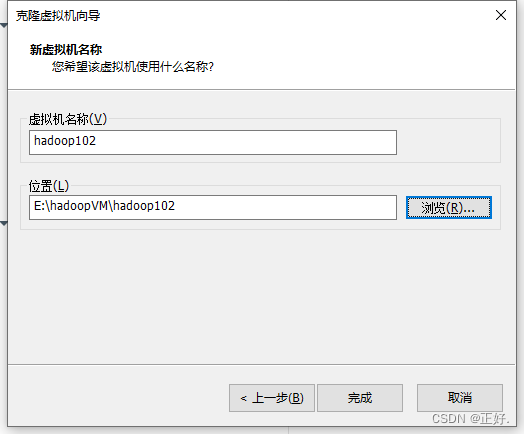
按照上述操作完成hadoop103的克隆
2、分别修改hadoop102、hadoop103的ip和主机名
# 分别修改hadoop102和hadoop103的ip
vi /etc/sysconfig/network-scripts/ifcfg-ens33
# hadoop102
IPADDR=192.168.88.102
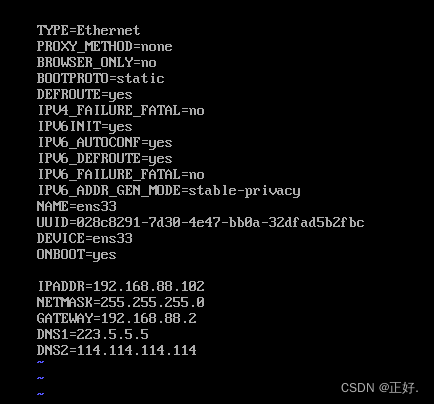
# 修改主机名
vi /etc/hostname
hadoop103按照上述操作执行
- 修改完成后需要重启hadoop101和hadoop103!
3、使用xshell连接三台机器,并测试是否互通
# 例如
ping 192.168.88.102

四、设置免密登录
1、生成密钥对
(1)依次在每台机器上执行:ssh-keygen -t rsa 生成本机秘钥
ssh-keygen -t rsa
# 四次回车
(2)依次在每台机器上执行:
ssh-copy-id hadoop101
ssh-copy-id hadoop102
ssh-copy-id hadoop103
# 将本机公钥发送给其他机器
# 按照提示执行
2、测试免密登录
(1)测试免密登录
# 例如:
ssh hadoop102
# 退出
exit

五、安装和配置Hadoop组件
1、安装Hadoop
(1)上传hadoop-3.2.4.tar.gz到/opt/softwares目录,并解压到/opt/modules
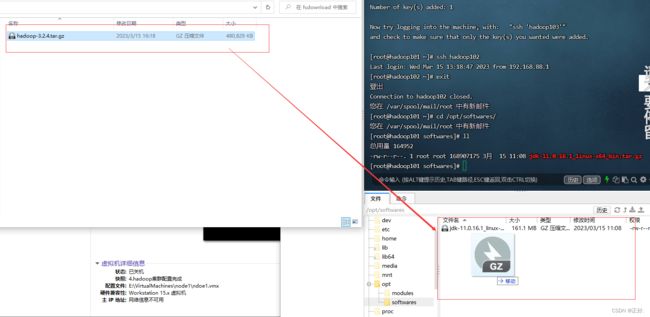
- 解压hadoop
tar -zxvf hadoop-3.2.4.tar.gz -C /opt/modules/
(2)配置/etc/profile,添加HADOOP_HOME和PATH
vim /etc/profile
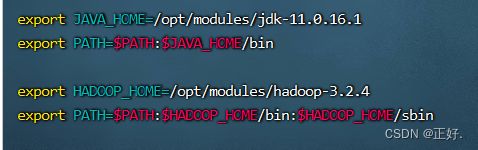
source /etc/profile
hadoop version
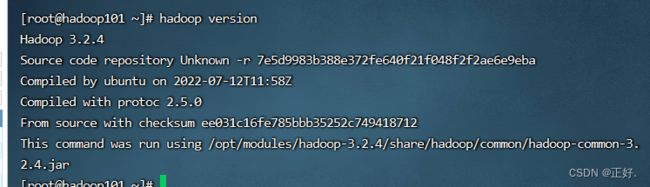
(3)进入此路径下:/opt/modules/hadoop-3.2.4/etc/hadoop
- 以下三个文件分别添加JAVA_HOME环境变量:export JAVA_HOME=XXX
- hadoop-env.sh
- mapred-env.sh
- yarn-env.sh
export JAVA_HOME=/opt/modules/jdk-11.0.16.1

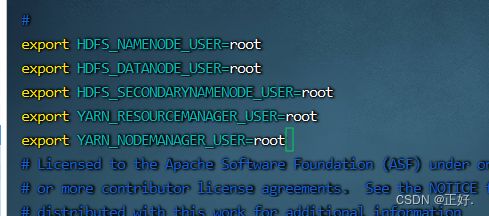
- 在hadoop-env.sh中添加以下配置:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
(4)配置HDFS
- 编辑core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop101:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>file:/opt/modules/hadoop-3.2.4/tmpvalue>
property>
configuration>

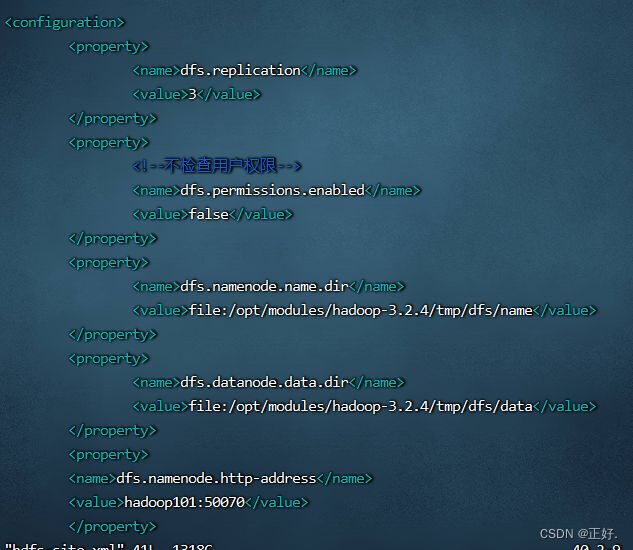
- 编辑hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.permissions.enabledname>
<value>falsevalue>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/opt/modules/hadoop-3.2.4/tmp/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/opt/modules/hadoop-3.2.4/tmp/dfs/datavalue>
property>
<property>
<name>dfs.namenode.http-addressname>
<value>hadoop101:50070value>
property>
configuration>
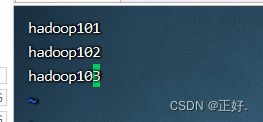
- 编辑workers文件
hadoop101
hadoop102
hadoop103
(5)配置YARN
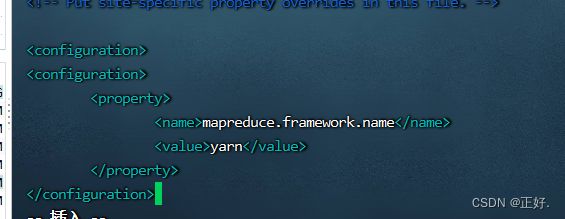
- 编辑mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
- 获取hadoop classpath值(下面会用到)
hadoop classpath
- 编辑yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>hadoop101:8032value>
property>
<property>
<name>yarn.application.classpathname>
<value>hadoop classpath返回的值value>
property>
configuration>

(6)复制hadoop101机器上配置好的hadoop到另外两台机器
- 在三台机器上依次安装rsync远程同步工具
yum install -y rsync
- 将Hadoop发送到102和103机器上
rsync -av /opt/modules/hadoop-3.2.4 root@hadoop102:/opt/modules/
rsync -av /opt/modules/hadoop-3.2.4 root@hadoop103:/opt/modules/
(7)同步另外两台机器中的hadoop环境变量
rsync -av /etc/profile root@hadoop102:/etc/profile
rsync -av /etc/profile root@hadoop103:/etc/profile

- 刷新另外两台机器的环境变量,检查hadoop version
source /etc/profile
hadoop version

(8) 在hadoop101上格式化namenode
hadoop namenode -format
(9)启动hadoop
start-all.sh
- 查看进程是否都启动成功
| 主机 | 进程 |
|---|---|
| hadoop101 | Datanode NodeManager NameNode ResourceManager |
| hadoop102 | DataNode NodeManager |
| hadoop103 | DataNode NodeManager |