C++设计模式入门
课程地址
软件设计复杂的根本原因在于需求的变化,所以软件设计的金科玉律就是复用,而复用要求我们明确代码中哪些部分是变化的,哪些部分是稳定的。设计模式的核心思想就在于将变化与稳定分隔开来,从而使得稳定的部分得以复用
面向对象设计原则
Dependence Inversion Principle
依赖倒置原则:针对接口编程,依赖于抽象而非具体实现
高层模块(稳定)不应该依赖于的低层模块(变化),二者都应该依赖于抽象
抽象(稳定)不应该依赖于实现细节(变化),实现细节(变化)应该依赖于抽象(稳定)
Open Close Principle
开闭原则:对扩展开放,对修改关闭。在程序需要进行拓展的时候,不能去修改原有的代码,实现一个热插拔的效果。所以一句话概括就是:为了使程序的扩展性好,易于维护和升级,保证类模块是可扩展的,但不可修改。想要达到这样的效果,我们需要使用接口和抽象类
Single Responsibility Principle
单一职责原则:一个类应只有一个引起他变化的原因,变化的方向隐含着类的责任。类的责任尽可能单一
Liskov Substitution Principle
李氏替换原则:子类必须能够替换他们的父类。LSP 是继承复用的基石,只有当子类可以替换掉父类,软件单位的功能不受到影响时,父类才能真正被复用,而子类也能够在父类的基础上增加新的行为。LSP是对“开-闭”原则的补充。实现“开-闭”原则的关键步骤就是抽象化。而父类与子类的继承关系就是抽象化的具体实现,所以里氏代换原则是对实现抽象化的具体步骤的规范
Interface Segregation Principle
接口隔离原则:多个隔离的接口,比使用单个接口要好。接口应该小而完备
Composite Reuse Principle
合成复用原则:优先使用合成/聚合的方式,而不是类继承
Demeter Principle
迪米特原则:一个实体应当尽量少的与其他实体之间发生相互作用,使得系统功能模块相对独立
GOF-23的分类:
总体来说设计模式分为三大类:
- 5种创建型模式:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式
- 7种结构型模式:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式
- 11种行为型模式:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式
在实际工程中,设计模式的应用并非一蹴而就的,要在代码的重构中获得模式(Refactoring to parttens)
重构的指导原则:
静态 -> 动态
早绑定 -> 晚绑定
继承 -> 组合
编译时依赖 -> 运行时依赖
紧耦合 -> 松耦合
模板方法模式
动机
在软件构建过程中,对于某一项任务,它常常有稳定的整体操作结构,但各个子步骤却有很多改变的需求,或者由于固有的原因(比如框架与应用之间的关系)而无法和任务的整体结构同时实现
如何在确定稳定的操作结构的前提下,来灵活应对各个子步骤的变化或者晚期实现需求?
实现
考虑下面的业务场景:在使用程序库开发自己的应用程序时,经常需要在程序中穿插执行程序库中的函数和自定义的函数,如下:
class Library{
public:
void step1() {
}
void step3() {
}
void step5() {
}
};
class Application {
public:
bool step2() {
}
void step4() {
}
};
int main() {
Library lib;
Application app;
lib.step1();
if (app.step2()) {
lib.step3();
}
for (int i = 0; i < 4; ++i) {
app.step4();
}
lib.step5();
return 0;
}
这正是以C语言为代表的结构化软件设计流程:

但是我们完全可以将客户程序实现的step2和step4作为父类的接口,这样就可以将main中的(模板)执行逻辑放到父类,而让客户程序继承自父类并重写接口,以实现自己的定制多态行为:
//template-method.cpp
class Library {
public:
//原来的main逻辑:稳定的template method
void run() {
step1();
if (step2()) { //虚函数,定制化
step3();
}
for (int i = 0; i < 4; ++i) {
step4(); //虚函数,定制化
}
step5();
}
virtual ~Library() {}
protected:
void step1() {
cout << "step1 in Library" << endl;
}
void step3() {
cout << "step3 in Library" << endl;
}
void step5() {
cout << "step5 in Library" << endl;
}
virtual bool step2() = 0;
virtual void step4() = 0;
};
class Application : public Library {
protected:
virtual bool step2() override {
cout << "step2 in Application" << endl;
return true;
}
virtual void step4() override {
cout << "step4 in Application" << endl;
}
};
int main() {
Library* plib = new Application();
plib->run();
delete plib;
}
这体现了面向对象的软件设计流程:将早绑定转换为晚绑定(不要调用我,让我来调用你)

总结
模板方法模式:定义一个操作中的算法的骨架(稳定),而将一些步骤延迟到子类(变化)中。模板方法模式可以在不改变(复用)一个算法结构的情况下重定义(重写)该算法的某些特定步骤(稳定中有变化)
所以设计模式的最大作用就是在变化和稳定中间寻找隔离点,从而分离它们

策略模式
动机
在软件构建过程中,某些对象使用的算法可能多种多样,经常改变,如果将这些算法都编码到对象中,将会使对象变得异常复杂;而且有时候支持不使用的算法也是一个性能负担。
如何在运行时根据需要透明地更改对象的算法?将算法与对象本身解耦,从而避免上述问题?
实现
考虑下面的业务场景:需要根据不同国家的税制选择不同的税计算方案:
enum TaxBase {
CN_Tax,
US_Tax,
DE_Tax
};
class SalesOrder {
TaxBase tax;
public:
double calculateTax() {
if (tax == CN_Tax) {
//CN****
} else if (tax == US_Tax) {
//US****
} else if (tax == DE_Tax) {
//DE***
}
}
};
如果我们想要增加一个国家,就必须要修改源代码,这违反了开闭原则,如何避免这个问题呢:采用策略模式:
//strategy.cpp
//策略基类
class TaxStrategy {
public:
virtual double Calculate(const Context& context) = 0;
virtual ~TaxStrategy(){}
};
//各个策略分别实现Calculate方法
class CNTax : public TaxStrategy {
public:
virtual double Calculate(const Context& context) override {
//CN****
}
};
class USTax : public TaxStrategy {
public:
virtual double Calculate(const Context &context) override {
//US****
}
};
class DETax : public TaxStrategy {
public:
virtual double Calculate(const Context &context) override{
//DE****
}
};
class SalesOrder {
private:
TaxStrategy* strategy;
public:
SalesOrder(StrategyFactory* strategyFactory) { //使用Strategy工厂创建strategy对象
this->strategy = strategyFactory->newStrategy(); //工厂知道构造何种子类对象
}
~SalesOrder() {
delete this->strategy;
}
double CalculateTax() {
//****
Context context;
double val = strategy->Calculate(context); //多态调用
return val;
}
};
采用上面的实现,当需要增加一个国家时,只需要增加实现这个国家的税制的类并继承自TaxStrategy,然后重写Calculate(),就完成了。
总结
策略模式:定义一系列算法,把他们一个个封装起来,并且使他们可相互替换(变化)。该模式使得算法可以独立于使用它的客户程序(稳定)而变化(扩展,子类化)
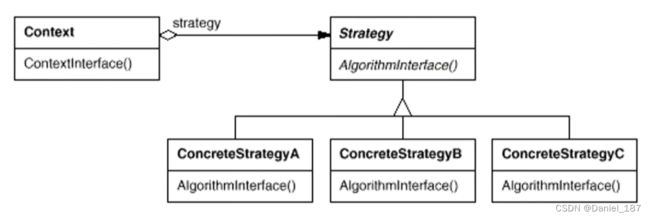
-
Strategy及其子类为组件提供了一系列可重用的算法,从而可以使得类型在运行时方便地根据需要在各个算法之间进行切换
-
Strategy模式提供了用条件判断语句以外的另一种选择,消除条件判断语句,就是在解耦合。含有许多条件判断语句的代码通常都需要Strategy模式
-
如果Strategy对象没有实例变量,那么各个上下文可以共享同一个Strategy对象,从而节省对象开销
观察者模式
动机
观察者模式是组件协作模式的一种:
在软件构建过程中,我们需要为某些对象建立一种“通知依赖关系”:一个对象(目标对象)的状态发生改变,所有的依赖对
象(观察者对象)都将得到通知。如果这样的依赖关系过于紧密,将使软件不能很好地抵御变化。
使用面向对象技术,可以将这种依赖关系弱化,并形成一种稳定的依赖关系。从而实现软件体系结构的松耦合。
实现
考虑下面的业务场景:设计一个GUI程序用于大文件的分割
class FileSplitter {
string m_filepath;
int m_filenum;
FileSplitter(const string& path, int num) : m_filepath(path), m_filenum(num) {}
void split() {
//读入大文件
//分批次向小文件中写入
for (int i = 0; i < m_filenum; ++i) {
//****
}
}
};
class MainForm : public Form {
TextBox* txtFilePath;
TextBox* txtFileNumber;
public:
void Button1_click() {
string filePath = txtFilePath->getText();
int num = atoi(txtFileNumber->getText.c_str());
FileSplitter splitter(filePath, num);
splitter.split();
}
};
现在扩展需求:需要在界面上新增一个进度条。一种实现方式如下:增加ProgressBar成员,在split时实时更新进度
class FileSplitter {
string m_filepath;
int m_filenum;
ProgressBar* m_progessBar;
FileSplitter(const string& path, int num, ProgressBar* pb) : m_filepath(path), m_filenum(num), m_progessBar(pb){}
void split() {
//读入大文件
//分批次向小文件中写入
for (int i = 0; i < m_filenum; ++i) {
//****
m_progessBar->setValue((i) / m_filenum);
}
}
};
class MainForm : public Form {
TextBox* txtFilePath;
TextBox* txtFileNumber;
ProgressBar* progessBar;
public:
void Button1_click() {
string filePath = txtFilePath->getText();
int num = atoi(txtFileNumber->getText.c_str());
FileSplitter splitter(filePath, num, progessBar);
splitter.split();
}
};
上面的实现违背了依赖倒置原则:高层的FileSplitter依赖了ProgressBar的具体实现。同时注意到如果进度通知不是以bar的形式展示,而是类似于linux上终端中的进度展示,又需要修改FileSplitter的源代码
考虑如下的改进:将具体的通知控件,修改为抽象的通知机制
class IProgress { //抽象的通知机制
public:
virtual void DoProgress(float value) = 0;
virtual ~IProgress() {};
};
class FileSplitter {
public:
string m_filepath;
int m_filenum;
//ProgressBar* m_progessBar; //具体的通知控件
IProgress* m_iprogress; //抽象的通知机制
FileSplitter(const string& path, int num, IProgress* p) : m_filepath(path), m_filenum(num), m_iprogress(p){}
void split() {
//读入大文件
//分批次向小文件中写入
for (int i = 0; i < m_filenum; ++i) {
//****
m_iprogress->DoProgress((i + 1.0) / m_filenum); //通知机制
}
}
};
class MainForm : public Form , public IProgress{ //多继承
TextBox* txtFilePath;
TextBox* txtFileNumber;
ProgressBar* progessBar;
public:
void Button1_click() {
string filePath = txtFilePath->getText();
int num = atoi(txtFileNumber->getText.c_str());
FileSplitter splitter(filePath, num, this);
splitter.split();
}
virtual void DoProgress(float value) {
progessBar->setValue(value); //这个处理方式取决于窗口类自己的重写,多态化的
}
};
现在,我们称MainForm为观察者,它继承自抽象的通知机制,以this指针的方式传入splitter,获取通知信息。但是现在只能存在一个观察者,功能受限,我们可以使用list扩展到多个观察者:
//observer.cpp
class IProgress { //抽象的通知机制
public:
virtual void DoProgress(float value) = 0;
virtual ~IProgress() {};
};
class FileSplitter {
public:
string m_filepath;
int m_filenum;
list<IProgress*> m_iprogress; //抽象的通知机制,多个观察者
FileSplitter(const string& path, int num) : m_filepath(path), m_filenum(num){}
void add_iprogress(IProgress* p) { //增加观察者
m_iprogress.push_back(p);
}
void remove_iprogress(IProgress* p) { //移除观察者
m_iprogress.remove(p);
}
void split() {
//读入大文件
//分批次向小文件中写入
for (int i = 0; i < m_filenum; ++i) {
//****
for (auto it = m_iprogress.begin(); it != m_iprogress.end(); ++it) {
(*it)->DoProgress((i + 1.0) / m_filenum); //通知所有观察者
}
}
}
};
class MainForm : public Form , public IProgress{ //多继承
TextBox* txtFilePath;
TextBox* txtFileNumber;
ProgressBar* progessBar;
public:
void Button1_click() {
string filePath = txtFilePath->getText();
int num = atoi(txtFileNumber->getText().c_str());
FileSplitter splitter(filePath, num);
splitter.add_iprogress(this); //this加入观察者,订阅通知
splitter.split();
splitter.remove_iprogress(this); //将this从观察者中移除
}
virtual void DoProgress(float value) {
progessBar->setValue(value); //这个处理方式取决于窗口自己,多态化的
}
};
int main () {
return 0;
}
总结
观察者模式:定义对象间的一种一对多(变化)的依赖关系,以便当一个对象的状态发生改变时,所有依赖于它的对象都能得到通知并自动更新
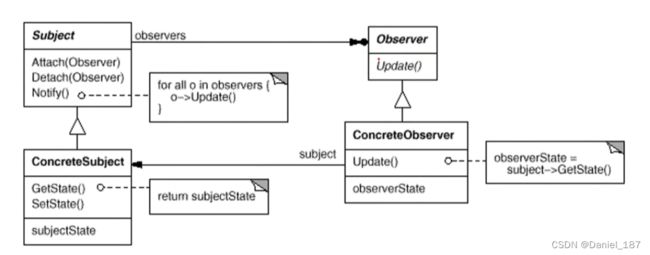
-
使用面向对象的抽象,Observer模式使得我们可以独立地改变目标与观察者,从而使二者之间的依赖关系达致松耦合
-
目标发送通知时,无需指定观察者,通知(可以携带通知信息作为参数)会自动传播
-
观察者自己决定是否需要订阅通知,目标对象对此一无所知
-
Observer模式是基于事件的UI框架中非常常用的设计模式,也是MVC模式的一个重要组成部分
装饰模式
装饰模式和下文中的桥模式都属于“单一职责模式”

动机
在某些情况下我们可能会过度地使用继承来扩展对象的功能,由于继承为类型引入的静态特质,使得这种扩展方式缺乏灵活性;并且随着子类的增多(扩展功能的增多),各种子类的组合(扩展功能的组合)会导致更多子类的膨胀
如何使“对象功能的扩展”能够根据需要来动态地实现?同时避免“扩展功能的增多”带来的子类膨胀问题?从而使得任何功能扩展变化所导致的影响将为最低?
实现
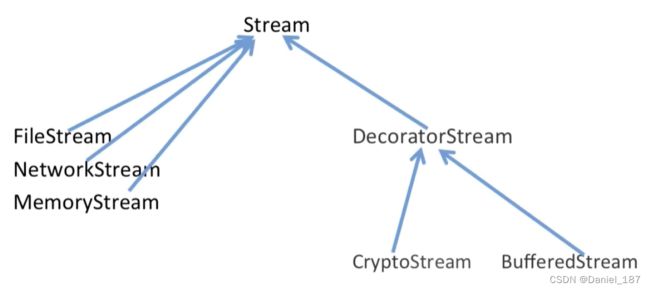
考虑下面的业务场景:定义流基类,然后创建文件流,网络流,内存流
当需要对流进行加密时,需要定义三者的加密子类型;当需要对流进行缓存时,又需要定义三者的缓存子类型;当既需要对流进行缓存又需要对流进行缓存时,又需要定义三者的缓存加密子类型
class Stream { //流基类
public:
virtual char Read(int number) = 0;
virtual void Seek(int position) = 0;
virtual void Write(char data) = 0;
virtual ~Stream(){}
};
class FileStream : public Stream { //文件流
public:
virtual char Read(int number) override {
}
virtual void Seek(int position) override {
}
virtual void Write(char data) override {
}
};
class NetworkStream : public Stream { //网络流
public:
virtual char Read(int number) override {
}
virtual void Seek(int position) override {
}
virtual void Write(char data) override {
}
};
class MemoryStream : public Stream { //内存流
public:
virtual char Read(int number) override {
}
virtual void Seek(int position) override {
}
virtual void Write(char data) override {
}
};
class CryptoFileStream : public FileStream { //扩展操作,对文件流进行加密
public:
virtual char Read(int number) override {
//额外的加密操作
FileStream::Read(number);
//额外的加密操作
}
virtual void Seek(int position) override {
//额外的加密操作
FileStream::Seek(position);
//额外的加密操作
}
virtual void Write(char data) override {
//额外的加密操作
FileStream::Write(data);
//额外的加密操作
}
};
class CryptoNetworkStream: public NetworkStream { //扩展操作,对网络流进行加密
public:
virtual char Read(int number) override {
//额外的加密操作
NetworkStream::Read(number);
//额外的加密操作
}
virtual void Seek(int position) override {
//额外的加密操作
NetworkStream::Seek(position);
//额外的加密操作
}
virtual void Write(char data) override {
//额外的加密操作
NetworkStream::Write(data);
//额外的加密操作
}
};
class CryptoMemoryStream: public MemoryStream { //扩展操作,对内存流进行加密
public:
virtual char Read(int number) override {
//额外的加密操作
MemoryStream::Read(number);
//额外的加密操作
}
virtual void Seek(int position) override {
//额外的加密操作
MemoryStream::Seek(position);
//额外的加密操作
}
virtual void Write(char data) override {
//额外的加密操作
MemoryStream::Write(data);
//额外的加密操作
}
};
//缓存并加密流
class BufferedFileStream : public FileStream {
//****
};
class BufferedNetworkStream: public NetworkStream {
//****
};
class BufferedMemoryStream : public MemoryStream {
//****
};
//即加密又缓存
class CryptoBufferedFileStream : public FileStream {
//****
};
class CryptoBufferedNetworkStream: public NetworkStream{
//****
};
class CryptoBufferedMemoryStream: public MemoryStream {
//****
};

注意到上述三者涉及到加密的代码是一样的,所以出现了代码冗余。下面考虑使用组合替代继承:
class Stream { //流基类
public:
virtual char Read(int number) = 0;
virtual void Seek(int position) = 0;
virtual void Write(char data) = 0;
virtual ~Stream(){}
};
class FileStream : public Stream { //文件流
public:
virtual char Read(int number) override {
}
virtual void Seek(int position) override {
}
virtual void Write(char data) override {
}
};
class NetworkStream : public Stream { //网络流
public:
virtual char Read(int number) override {
}
virtual void Seek(int position) override {
}
virtual void Write(char data) override {
}
};
class MemoryStream : public Stream { //内存流
public:
virtual char Read(int number) override {
}
virtual void Seek(int position) override {
}
virtual void Write(char data) override {
}
};
class CryptoStream : public Stream { //扩展操作,对流进行加密
Stream* stream;
public:
CryptoStream(Stream* stm) : stream(stm) {}
virtual char Read(int number) override {
//额外的加密操作
stream->Read(number);
//额外的加密操作
}
virtual void Seek(int position) override {
//额外的加密操作
stream->Seek(position);
//额外的加密操作
}
virtual void Write(char data) override {
//额外的加密操作
stream->Write(data);
//额外的加密操作
}
};
//缓存流
class BufferedStream : public Stream {
Stream* stream;
public:
BufferedStream(Stream* stm) : stream(stm) {}
virtual char Read(int number) override {
//额外的缓存操作
stream->Read(number);
//额外的缓存操作
}
virtual void Seek(int position) override {
//额外的缓存操作
stream->Seek(position);
//额外的缓存操作
}
virtual void Write(char data) override {
//额外的缓存操作
stream->Write(data);
//额外的缓存操作
}
};
int main() {
FileStream* fs1 = new FileStream();
CryptoStream* fs2 = new CryptoStream(fs1); //加密fs1
fs2->Read(0);
BufferedStream* fs3 = new BufferedStream(fs1); //缓存fs1
BufferedStream* fs4 = new BufferedStream(fs2); //既加密又缓存
return 0;
}
进一步地,将两个类中的Stream*提取到一个公共的“装饰类”当中:
//decorate.cpp
class Stream { //流基类
public:
virtual char Read(int number) = 0;
virtual void Seek(int position) = 0;
virtual void Write(char data) = 0;
virtual ~Stream(){}
};
class FileStream : public Stream { //文件流
public:
virtual char Read(int number) override {
}
virtual void Seek(int position) override {
}
virtual void Write(char data) override {
}
};
class NetworkStream : public Stream { //网络流
public:
virtual char Read(int number) override {
}
virtual void Seek(int position) override {
}
virtual void Write(char data) override {
}
};
class MemoryStream : public Stream { //内存流
public:
virtual char Read(int number) override {
}
virtual void Seek(int position) override {
}
virtual void Write(char data) override {
}
};
class DecoratorStream : public Stream {
protected:
Stream* stream;
DecoratorStream(Stream* stm) : stream(stm) {}
};
class CryptoStream : public DecoratorStream { //扩展操作,对流进行加密
public:
CryptoStream(Stream* stm) : DecoratorStream(stm) {}
virtual char Read(int number) override { //这里重写的是DecoratorStream的父类Stream中的虚函数
//额外的加密操作
stream->Read(number); //多态的
//额外的加密操作
}
virtual void Seek(int position) override {
//额外的加密操作
stream->Seek(position);
//额外的加密操作
}
virtual void Write(char data) override {
//额外的加密操作
stream->Write(data);
//额外的加密操作
}
};
//缓存流
class BufferedStream : public DecoratorStream{
public:
BufferedStream(Stream* stm) : DecoratorStream(stm) {}
virtual char Read(int number) override {
//额外的缓存操作
stream->Read(number);
//额外的缓存操作
}
virtual void Seek(int position) override {
//额外的缓存操作
stream->Seek(position);
//额外的缓存操作
}
virtual void Write(char data) override {
//额外的缓存操作
stream->Write(data);
//额外的缓存操作
}
};
int main() {
FileStream* fs1 = new FileStream();
CryptoStream* fs2 = new CryptoStream(fs1); //加密fs1
fs2->Read(0);
BufferedStream* fs3 = new BufferedStream(fs1); //缓存fs1
BufferedStream* fs4 = new BufferedStream(fs2); //既加密又缓存
return 0;
}
总结
装饰模式:动态(组合)地给一个对象增加一些额外的职责。就增加功能而言,Decorator模式比生成子类(继承)更为灵活(消除重复代码&减少子类个数)
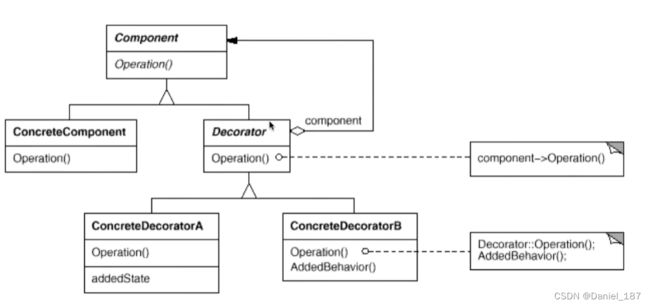
-
通过采用组合而非继承的手法,Decorator模式实现了在运行时动态扩展对象功能的能力,而且可以根据需要扩展多个功能。避免了使用继承带来的“灵活性差”和“多子类衍生问题”
-
Decorator类在接口上表现为
is a component的继承关系,即Decorator类继承了Component类所具有的接口。但在实现上又表现为has a component的组合关系,即Decorator类又使用了另外一个Component类 -
Decorator模式的目的并非解决“多子类衍生的多继承”问题,Decorator模式应用的要点在于解决主体类在多个方向上的扩展功
能”——是为“装饰”的含义
桥模式
动机
由于某些类型的固有的实现逻辑,使得它们具有两个变化的维度,乃至多个纬度的变化
如何应对这种“多维度的变化”?如何利用面向对象技术来使得类型可以轻松地沿着两个乃至多个方向变化,而不引入额外的复杂度?
实现
考虑如下业务需求:对于一个消息通知类,其某些行为依赖于具体平台的类型(如播放声音,绘制图形,键入文本,网络连接等)
class Messager {
public:
virtual void login(string username, string passwd) = 0;
virtual void sendMessage(string message) = 0;
virtual void sendPicture(Image image) = 0;
virtual void playSound() = 0;
virtual void drawShape() = 0;
virtual void writeText() = 0;
virtual void connect() = 0;
virtual ~Messager() {};
};
class PCMessagerBase : public Messager {
public:
virtual void playSound() override {
}
virtual void drawShape() override {
}
virtual void writeText() override {
}
virtual void connect() override {
}
};
class MobileMessagerBase : public Messager {
public:
virtual void playSound() override {
}
virtual void drawShape() override {
}
virtual void writeText() override {
}
virtual void connect() override {
}
};
//精简版PCMessager
class PCMessagerLite : public PCMessagerBase {
public:
virtual void login(string username, string passwd) {
PCMessagerBase::connect();
}
virtual void sendMessage(string message) {
PCMessagerBase::writeText();
}
virtual void sendPicture(Image image) {
PCMessagerBase::drawShape();
}
};
//完美版PCMessager
class PCMessagerPerfect : public PCMessagerBase {
public:
virtual void login(string username, string passwd) {
PCMessagerBase::playSound();
//****
PCMessagerBase::connect();
}
virtual void sendMessage(string message) {
PCMessagerBase::playSound();
//****
PCMessagerBase::writeText();
}
virtual void sendPicture(Image image) {
PCMessagerBase::playSound();
//****
PCMessagerBase::drawShape();
}
};
//精简版MobileMessager
class MobileMessagerLite : public MobileMessagerBase{
public:
virtual void login(string username, string passwd) {
MobileMessagerBase::login(username, passwd);
}
virtual void sendMessage(string message) {
MobileMessagerBase::writeText();
}
virtual void sendPicture(Image image) {
MobileMessagerBase::sendMessage(image);
}
};
//完美版MobileMessager
class MobileMessagerPerfect : public MobileMessagerBase{
public:
virtual void login(string username, string passwd) {
MobileMessagerBase::playSound();
//****
MobileMessagerBase::connect();
}
virtual void sendMessage(string message) {
MobileMessagerBase::playSound();
//****
MobileMessagerBase::writeText();
}
virtual void sendPicture(Image image) {
MobileMessagerBase::playSound();
//****
MobileMessagerBase::drawShape();
}
};
修改为桥模式:将依赖于具体平台实现的部分提取到一个类当中
//bridge.cpp
//依赖于平台实现
class MessagerImp {
public:
virtual void playSound() = 0;
virtual void drawShape() = 0;
virtual void writeText() = 0;
virtual void connect() = 0;
virtual ~MessagerImp() {};
};
class Messager {
protected:
MessagerImp* msg;
public:
Messager(MessagerImp* m) : msg(m) {}
virtual void login(string username, string passwd) = 0;
virtual void sendMessage(string message) = 0;
virtual void sendPicture(Image image) = 0;
virtual ~Messager() {};
};
class PCMessagerImp: public MessagerImp {
public:
virtual void playSound() override {
}
virtual void drawShape() override {
}
virtual void writeText() override {
}
virtual void connect() override {
}
};
class MobileMessagerImp: public MessagerImp {
public:
virtual void playSound() override {
}
virtual void drawShape() override {
}
virtual void writeText() override {
}
virtual void connect() override {
}
};
//精简版PCMessager
//完美版PCMessager
//精简版MobileMessager
class MobileMessagerLite : public Messager {
public:
MobileMessagerLite(MessagerImp* m) : Messager(m) {}
virtual void login(string username, string passwd) {
msg->connect();
}
virtual void sendMessage(string message) {
msg->writeText();
}
virtual void sendPicture(Image image) {
msg->drawShape();
}
};
//完美版MobileMessager
class MobileMessagerPerfect : public Messager {
public:
MobileMessagerPerfect(MessagerImp* m) : Messager(m) {}
virtual void login(string username, string passwd) {
msg->playSound();
//****
msg->connect();
}
virtual void sendMessage(string message) {
msg->playSound();
//****
msg->writeText();
}
virtual void sendPicture(Image image) {
msg->playSound();
//****
msg->drawShape();
}
};
int main() {
MessagerImp* mimp = new MobileMessagerImp();
Messager* m = new MobileMessagerPerfect(mimp);
m->login("danile", "hello");
return 0;
}
总结
桥模式:将抽象部分(业务功能)与实现部分(平台实现)分离,使得它们可以独立地变化

-
Bridge模式使用“对象间的组合关系”解耦了抽象和实现之间固有的绑定关系,使得抽象和实现可以沿着各自的维度来变化。所谓抽象和实现沿着各自纬度的变化,即“子类化”它们。
-
Bridge模式有时候类似于多继承方案,但是多继承方案往往违背单一职责原则(即一个类只有一个变化的原因),复用性比较差。 Bridge模式是比多继承方案更好的解决方法。
-
Bridge模式的应用一般在“两个非常强的变化维度”,有时一个类也有多于两个的变化维度,这时可以使用Bridge的扩展模式。
工厂方法模式
工厂方法模式属于“对象创建”模式的一种:

动机
在软件系统中,经常面临着创建对象的工作。由于需求的变化,需要创建的对象的具体类型经常变化。
如何应对这种变化?如何绕过常规的对象创建方法(new),提供一种“封装机制”来避免客户程序和这种“具体对象创建工作”的紧耦合?
实现
考虑下面的业务场景:针对不同种类的文件实现文件分割器,例如二进制文件,文本文件,图片文件等。在创建对象时如何支持未来可能加入的新的文件分割器类型?
//factory.cpp
//Splitter基类
class ISplitter {
public:
virtual void split() = 0;
virtual ~ISplitter() {};
};
//工厂基类
class SplitterFactory {
public:
virtual ISplitter* createSplitter() = 0;
virtual ~SplitterFactory() {}
};
//具体类
class BinarySplitter : public ISplitter{
public:
virtual void split() override {
}
};
class TxtSplitter : public ISplitter{
public:
virtual void split() override {
}
};
class PictureSpliter : public ISplitter{
public:
virtual void split() override {
}
};
//具体工厂
class BinarySplitterFactory : public SplitterFactory{
public:
virtual ISplitter* createSplitter() override {
return new BinarySplitter();
}
};
class TxtSplitterFactory : public SplitterFactory{
public:
virtual ISplitter* createSplitter() override {
return new TxtSplitter();
}
};
class PictureSpliterFactory : public SplitterFactory {
public:
virtual ISplitter* createSplitter() override {
return new PictureSpliter();
}
};
class MainForm {
SplitterFactory* factory;
public:
MainForm(SplitterFactory* f) : factory(f) {} //传入的子工厂类型决定了产生的子类
void Button1_click() {
//new依赖于具体的构造函数,违背的依赖倒置原则:只依赖于抽象而非依赖于具体
//ISplitter* splitter1 = new BinarySplitter();
ISplitter* splitter = factory->createSplitter(); //多态new
splitter->split();
delete splitter;
}
~MainForm(){
delete factory;
}
};
int main () {
SplitterFactory* binarySplitterFactory = new BinarySplitterFactory();
MainForm* mainForm = new MainForm(binarySplitterFactory);
mainForm->Button1_click();
}
总结
工厂模式:定义一个用于创建对象的接口,让子类决定实例化哪一个类。Factory Method使得一个类的实例化延迟到子类(目的:解耦;手段:虚函数)

-
Factory Method模式用于隔离类对象的使用者和具体类型之间的耦合关系。面对一个经常变化的具体类型,紧耦合关系(new)会导致软件的脆弱
-
Factory Method模式通过面向对象的手法,将所要创建的具体对象工作延迟到子类,从而实现一种扩展(而非更改)的策略,较好地解决了这种紧耦合关系
-
Factory Method模式解决了“单个对象”的需求变化。缺点在于要求创建方法/参数相同
抽象工厂模式
动机
在软件系统中,经常面临着“一系列相互依赖的对象”的创建工作;同时,由于需求的变化,往往存在更多系列对象的创建工作
如何应对这种变化?如何绕过常规的对象创建方法(new),提供一种“封装机制”来避免客户程序和这种“多系列具体对象创建工作”的紧耦合?
实现
考虑下面的业务情景:为了访问不同种类的数据库,需要分别为他们实现“连接,执行命令,读取数据”子类,同时注意到对于某一特定种类的数据库,上述三个操作是绑定在一起不能混叠的。我们可以使用抽象工厂模式将一系列相互依赖的对象一起创建
//数据库访问有关的基类
class IDBConnection {
public:
virtual void connectionString(string str) = 0;
};
class IDBCommand {
public:
virtual void commandText(string str) = 0;
virtual void setConnection(IDBConnection*) = 0;
};
class IDBDataReader {
public:
virtual bool read() = 0;
};
//数据库访问基类工厂
class IDBFactory {
public: //将相互关联的子操作放在一起,避免产生交叉混叠
virtual IDBConnection* createDBConnection() = 0;
virtual IDBCommand* createDBCommand() = 0;
virtual IDBDataReader* createDBDataReader() = 0;
};
//SQL Server数据库访问类
class SqlConnection : public IDBConnection {
public:
virtual void connectionString(string str) override{
cout << "Sql connection, " << str << endl;
}
};
class SqlCommand : public IDBCommand{
public:
virtual void commandText(string str) override {
cout << "Sql commandText" << str << endl;
}
virtual void setConnection(IDBConnection*) {
}
};
class SqlDataReader : public IDBDataReader {
public:
virtual bool read() override {
cout << "Sql reading" << endl;
return true;
}
};
class SqlDBFactory : public IDBFactory {
public:
//将相互关联的子操作放在一起,避免产生交叉混叠
virtual IDBConnection* createDBConnection() override {
return new SqlConnection();
}
virtual IDBCommand* createDBCommand() {
return new SqlCommand();
}
virtual IDBDataReader* createDBDataReader() {
return new SqlDataReader();
}
};
//Oracle数据库访问类
class OracleConnection : public IDBConnection {
public:
virtual void connectionString(string str) override{
}
};
class OracleCommand : public IDBCommand{
public:
virtual void commandText(string str) override {
}
virtual void setConnection(IDBConnection*) override {
}
};
class OracleDataReader : public IDBDataReader {
public:
virtual bool read() override {
return true;
}
};
class OracleDBFactory : public IDBFactory {
public:
//将相互关联(依赖)的子操作放在一起,避免产生交叉混叠
virtual IDBConnection* createDBConnection() {
return new OracleConnection();
}
virtual IDBCommand* createDBCommand() {
return new OracleCommand();
}
virtual IDBDataReader* createDBDataReader() {
return new OracleDataReader();
}
};
class EmployeeDAO {
IDBFactory* dbFactory;
public:
EmployeeDAO(IDBFactory* dbf) : dbFactory(dbf) {};
vector<EmployeeDO> getEmployees() {
IDBConnection* connection = dbFactory->createDBConnection();
connection->connectionString("...");
IDBCommand* command = dbFactory->createDBCommand();
command->commandText("...");
command->setConnection(connection);
IDBDataReader* reader = dbFactory->createDBDataReader();
while (reader->read()) {
//****
}
}
};
int main () {
IDBFactory* dbf = new SqlDBFactory();
EmployeeDAO* e = new EmployeeDAO(dbf);
e->getEmployees();
return 0;
}
总结
抽象工厂模式:提供一个接口,让该接口负责创建一系列“相关或者相互依赖的对象”,无需指定它们具体的类
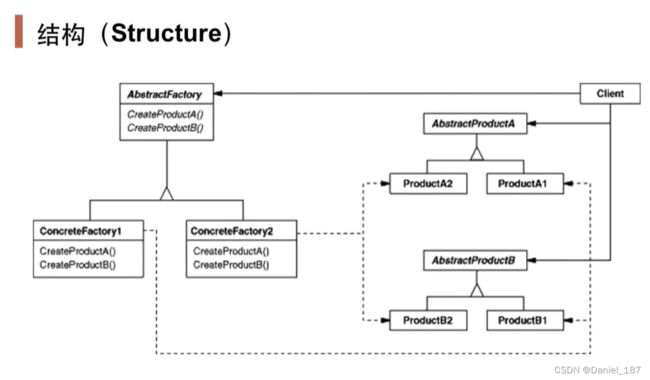
-
如果没有应对“多系列对象构建”的需求变化,则没有必要使用 AbstractFactory模式,这时候使用简单的工厂完全可以
-
“系列对象”指的是在某一特定系列下的对象之间有相互依赖或相互作用的关系。不同系列的对象之间不能相互依赖
-
Abstract Factory模式主要在于应对“新系列”的需求变动。其缺点在于难以应对“新对象”的需求变动
原型模式
动机
在软件系统中,经常面临着“某些结构复杂的对象”的创建工作;由于需求的变化,这些对象经常面临着剧烈的变化,但是它们却拥有比较稳定一致的接口
如何应对这种变化?如何向客户程序(使用这些对象的程序)隔离出“这些易变对象”,从而使得“依赖这些易变对象的客户程序”不随着需求改变而改变?
实现
修改工厂方法模式:将业务抽象基类和工厂基类合并,提供clone()接口
//prototype.cpp
//Splitter基类
class ISplitter {
public:
virtual void split() = 0;
virtual ISplitter* clone() = 0; //将不同的子类拷贝进来使用
virtual ~ISplitter() {};
};
//具体类
class BinarySplitter : public ISplitter{
public:
virtual void split() override {
}
virtual ISplitter* clone() override {
return new BinarySplitter(*this); //拷贝构造自身
}
};
class TxtSplitter : public ISplitter{
public:
virtual void split() override {
}
virtual ISplitter* clone() override {
return new TxtSplitter(*this);
}
};
class PictureSpliter : public ISplitter{
public:
virtual void split() override {
}
virtual ISplitter* clone() override {
return new PictureSpliter(*this);
}
};
class MainForm {
ISplitter* prototype;
public:
MainForm(ISplitter* p) : prototype(p) {} //传入的子工厂类型决定了产生的子类
void Button1_click() {
ISplitter* splitter = prototype->clone(); //多态clone
splitter->split();
}
};
int main () {
ISplitter* binarySplitter = new BinarySplitter();
MainForm* mainForm = new MainForm(binarySplitter);
mainForm->Button1_click();
return 0;
}
总结
原型模式:使用原型实例指定创建对象的种类,然后通过拷贝这些原型来创建新的对象
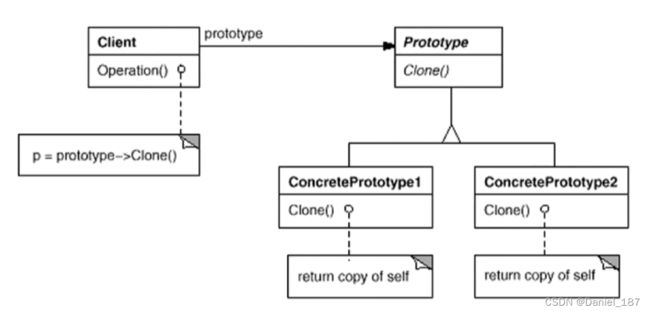
相对于工厂方法模式,原型模式一般用于复杂对象的多态化“构建”:可能随着程序的执行,对象达到了一定的状态才可用,这时就立即clone自己供客户使用。而工厂方法模式一般是new出来后立即投入使用,适用于状态比较简单的对象
-
Prototype模式同样用于隔离类对象的使用者和具体类型(易变类)之间的耦合关系,它同样要求这些“易变类”拥有“稳定的接口”
-
Prototype模式对于“如何创建易变类的实体对象”采用“原型克隆”的方法来做,它使得我们可以非常灵活地动态创建“拥有某些稳定接口”的新对象——所需工作仅仅是注册一个新类的对象(即原型),然后在任何需要的地方Clone
-
Prototype模式中的Clone方法可以利用某些框架中的序列化来实现深拷贝
构建器模式
动机
在软件系统中,有时候面临着“一个复杂对象”的创建工作,其通常由各个部分的子对象用一定的算法构成;由于需求的变化,这个复杂对象的各个部分经常面临着剧烈的变化,但是将它们组合在一起的算法却相对稳定
如何应对这种变化?如何提供一种“封装机制”来隔离出“复杂对象的各个部分”的变化,从而保持系统中的“稳定构建算法”不随着需求改变而改变?
实现
初步的构建器模式类似于模板方法模式,只不过将其思想用于对象的构造:
class House {
protected:
virtual void BuildPart1() = 0;
virtual void BuildPart2() = 0;
virtual bool BuildPart3() = 0;
virtual void BuildPart4() = 0;
virtual void BuildPart5() = 0;
public:
void Init() { //这些初始化代码不能放到构造函数,因为当前类是一个抽象类
this->BuildPart1();
for (int i = 0; i < 4; ++i) {
this->BuildPart2();
}
bool flag = this->BuildPart3();
if (flag) {
this->BuildPart4();
}
this->BuildPart5();
}
virtual ~House() {}
};
class StoneHouse : public House {
protected:
virtual void BuildPart1() override {
}
virtual void BuildPart2() override {
}
virtual bool BuildPart3() override {
}
virtual void BuildPart4() override {
}
virtual void BuildPart5() override {
}
};
int main () {
House* stoneHouse = new StoneHouse();
stoneHouse->Init();
//****
return 0;
}
上面的代码已经初步地实现了构建器模式,进一步地,可以将初始化代码拆分出来,提取出一个新的类:
//builder.cpp
class House {
public:
//some pure virtual functions
virtual ~House() {}
};
class HouseBuilder {
House* pHouse;
public:
House* getResult() {
return pHouse;
}
virtual ~HouseBuilder(){}
virtual void BuildPart1() = 0;
virtual void BuildPart2() = 0;
virtual bool BuildPart3() = 0;
virtual void BuildPart4() = 0;
virtual void BuildPart5() = 0;
};
class StoneHouseBuilder : public HouseBuilder {
protected:
virtual void BuildPart1() override {}
virtual void BuildPart2() override {}
virtual bool BuildPart3() override {}
virtual void BuildPart4() override {}
virtual void BuildPart5() override {}
};
class HouseDirector {
HouseBuilder* pHouseBuilder;
public:
//根据不同的HouseBuilder子类创建出不同的House
HouseDirector(HouseBuilder* phb) : pHouseBuilder(phb) {}
House* Construct() {
pHouseBuilder->BuildPart1();
for (int i = 0; i < 4; ++i) {
pHouseBuilder->BuildPart2();
}
bool flag = pHouseBuilder->BuildPart3();
if (flag) {
pHouseBuilder->BuildPart4();
}
pHouseBuilder->BuildPart5();
return pHouseBuilder->getResult();
}
};
class StoneHouse : public House {
};
int main () {
HouseBuilder* phb = new StoneHouseBuilder();
HouseDirector* phd = new HouseDirector(phb);
House* stoneHouse = phd->Construct();
}
总结
构建器模式:将一个复杂对象的构建与其表示相分离,使得同样的构建过程(稳定)可以创建不同的表示(变化)

-
Builder模式主要用于“分步骤构建一个复杂的对象”。在这其中分步骤是一个稳定的算法,而复杂对象的各个部分则经常变化
-
变化点在哪里,封装哪里——Builder模式主要在于应对“复杂对象各个部分”的频繁需求变动。其缺点在于难以应对“分步骤构建算法”的需求变动
-
在Builder模式中,要注意不同语言中构造器内调用虚函数的差别(C++ vs.C#)
单例模式
单例模式属于“对象性能模式”的一种:

动机
-
在软件系统中,经常有这样一些特殊的类,必须保证它们在系统中只存在一个实例,才能确保它们的逻辑正确性以及良好的效率
-
如何绕过常规的构造器,提供一种机制来保证一个类只有一个实例?
-
这应该是类设计者的责任,而不是使用者的责任
实现
class Singleton {
private:
Singleton() {} //私有化默认构造函数和拷贝构造函数
Singleton(const Singleton& s);
public:
static Singleton* getInstance();
static Singleton* m_instance; //全局的唯一实例
};
Singleton* Singleton::m_instance = nullptr;
/*示意代码:非线程安全版本
Singleton* Singleton::getInstance() {
if (m_instance == nullptr) {
m_instance = new Singleton();
}
return m_instance;
}
*/
/*线程安全版本,但锁的代价过高
Singleton* Singleton::getInstance() {
mutex lock;
if (m_instance == nullptr) {
m_instance = new Singleton();
}
return m_instance;
}
*/
//双检查锁,但由于指令执行reorder导致不安全
Singleton* Singleton::getInstance() {
if (m_instance == nullptr) {
mutex lock;
if (m_instance == nullptr) {
m_instance = new Singleton();
}
}
return m_instance;
}
//要用C++实现一个正确可用的单例模式可太难了
int main () {
Singleton* s1 = Singleton::getInstance();
return 0;
}
注意双检查锁看似是线程安全的,但实际并非如此。正常的new顺序:分配内存-执行构造函数-返回内存地址,但实际在指令层面,CPU可能打乱顺序:分配内存-返回内存地址-执行构造函数。这样,当一个线程执行完“分配内存-返回内存地址”,还没来得及调用构造函数时,轮到另一个线程执行,它发现m_instance不是null,于是返回一个没有构造完成的“对象”,导致了错误
总结
单例模式:保证一个类只有一个实例,并提供一个该实例的全局访问点
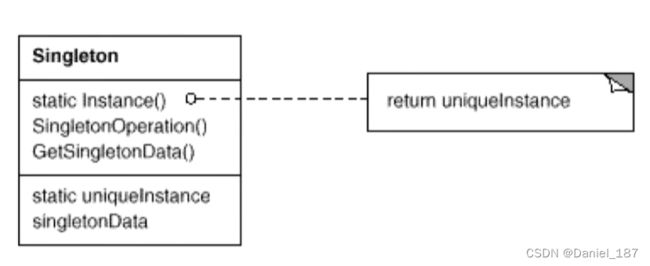
-
Singleton模式中的实例构造器可以设置为protected以允许子类派生
-
Singleton模式一般不要支持拷贝构造函数和Clone接口,因为这有可能导致多个对象实例,与Singleton模式的初衷违背
-
如何实现多线程环境下安全的Singleton?注意对双检查锁的正确实现
享元模式
享元模式属于“对象性能模式”,与单例模式一样,都是为了解决面向对象带来的成本
动机
在软件系统采用纯粹对象方案的问题在于大量细粒度的对象会很快充斥在系统中,从而带来很高的运行时代价——主要指内存需求方面的代价
如何在避免大量细粒度对象问题的同时,让外部客户程序仍然能够透明地使用面向对象的方式来进行操作?
实现
考虑下面的业务场景:实现字体对象,采用string类型的key作为其唯一标识。为了避免每次使用都创建对象,可以采用“池”的思想将创建好的对象缓存下来:
//flyweight.cpp
//字体对象
class Font {
private:
string key;
public:
Font(const string& k) {
cout << "key = " << k << " constructed" << endl;
key = k;
}
string getKey() {
return key;
}
};
//采用“池”的思想,将创建好的对象缓存下来
class FontFactory{
private:
map<string, Font*> fontPool;
public:
Font* getFont(const string& key) {
map<string, Font*>::iterator it = fontPool.find(key);
if (it != fontPool.end()) {
return it->second;
} else {
Font* font = new Font(key);
fontPool[key] = font;
return font;
}
}
void clear() {
//***
}
};
int main () {
Font* pfont = nullptr;
FontFactory* fontFactory = new FontFactory();
pfont = fontFactory->getFont("song");
cout << pfont->getKey() << endl;
pfont = fontFactory->getFont("kai");
cout << pfont->getKey() << endl;
pfont = fontFactory->getFont("song");
cout << pfont->getKey() << endl;
return 0;
}
总结
运用共享技术可有效地支持大量细粒度的对象

- 面向对象很好地解决了抽象性的问题,但是作为一个运行在机器中的程序实体,我们需要考虑对象的代价问题。Flyweight主要解决面向对象的代价问题,一般不触及面向对象的抽象性问题
- Flyweight采用对象共享的做法来降低系统中对象的个数,从而降低细粒度对象给系统带来的内存压力。在具体实现方面,要注意对象状态的处理
- 对象的数量太大从而导致对象内存开销加大——什么样的数量才算大?这需要我们仔细的根据具体应用情况进行评估,而不能凭空臆断
门面模式
门面模式属于接口隔离模式的一种,致力于在子系统的内部和外部进行解耦

如何降低系统间耦合的复杂度:
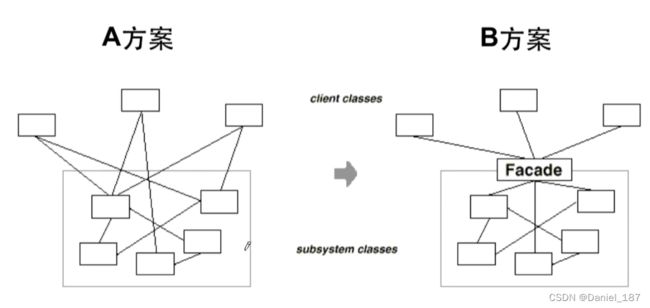
动机
上述A方案的问题在于组件的客户和组件中各种复杂的子系统有了过多的耦合,随着外部客户程序和各子系统的演化,这种过多的耦合面临很多变化的挑战。
如何简化外部客户程序和系统间的交互接口?如何将外部客户程序的演化和内部子系统的变化之间的依赖相互解耦?
总结
门面模式:为子系统中的一组接口提供一个一致(稳定)的界面,门面模式定义了一个高层接口,这个接口使得这一子系统更加容易使用(复用)
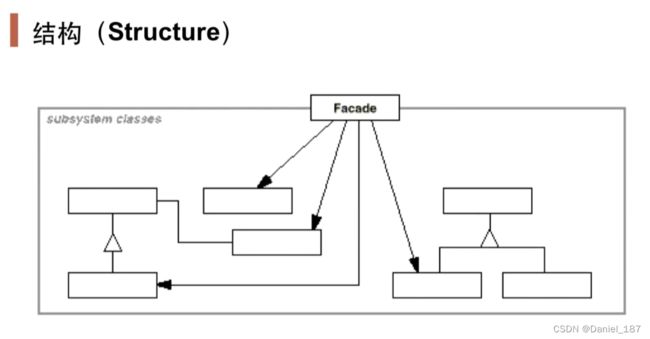
- 从客户程序的角度来看,Facade模式简化了整个组件系统的接口,对于组件内部与外部客户程序来说,达到了一种“解耦”的效果——内部子系统的任何变化不会影响到Facade接口的变化
- Facade设计模式更注重从架构的层次去看整个系统,而不是单个类的层次。Facade很多时候更是一种架构设计模式
- Facade设计模式并非一个集装箱,可以任意地放进任何多个对象。 Facade模式中组件的内部应该是“相互耦合关系比较大的一系列组件”,而不是一个简单的功能集合
代理模式
代理模式也属于接口隔离模式的一种
动机
人在面向对象系统中,有些对象由干某种原因(比如对象创建的开销很大,或者某些操作需要安全控制,或者需要进程外的访问等),直接访问会给使用者、或者系统结构带来很多麻烦
如何在不失去透明操作对象的同时来管理/控制这些对象特有的复杂性?增加一层间接层是软件开发中常见的解决方式(如字符串的COW和分布式系统)
实现
class ISubject {
public:
virtual void process() = 0;
};
class RealSubject : public ISubject {
public:
virtual void process() override {
}
};
class ClientApp {
ISubject* subject;
public:
ClientApp() {
subject = new RealSubject(); //由于某些原因,可能无法按照这种方式完成构建
}
void doTask() {
subject->process();
}
};
将RealSubject的实现改为代理类:
//proxy.cpp
class ISubject {
public:
virtual void process() = 0;
};
//Proxy的设计一般很复杂
class SubjectProxy: public ISubject {
public:
virtual void process() override {
//对RealSubject的一种间接访问
}
};
class ClientApp {
ISubject* subject;
public:
ClientApp() {
//subject = new RealSubject(); //可能无法按照这种方式完成构建
subject = new SubjectProxy();
}
void doTask() {
subject->process();
}
};
int main () {
ClientApp* clientApp = new ClientApp();
clientApp->doTask();
return 0;
}
总结
代理模式:为其他对象提供一种代理以控制(隔离,使用接口)对这个对象的访问

代理的核心思想在于增加间接层,来实现对外透明的一些feature
“增加一层间接层”是软件系统中对许多复杂问题的一种常见解决方法。在面向对象系统中,直接使用某些对象会带来很多问题,作为间接层的proxy对象便是解决这一问题的常用手段
具体proxy设计模式的实现方法、实现粒度都相差很大,有些可能对单个对象做细粒度的控制,如copy-on-write技术,有些可能对组件模块提供抽象代理层,在架构层次对对象做proxy
Proxy并不一定要求保持接口完整的一致性,只要能够实现间接控制,有时候损及一些透明性是可以接受的
适配器模式
动机
在软件系统中,由于应用环境的变化,常常需要将“一些现存的对象”放在新的环境中应用,但是新环境要求的接口是这些现存对象所不满足的
如何应对这种“迁移的变化”?如何既能利用现有对象的良好实现,同时又能满足新的应用环境所要求的接口?
适配器模式的思想类似于转换器,如电源适配器,VGA转HDMI转换器等
实现
//adapter.cpp
//目标接口
class ITarget {
public:
virtual void process() = 0;
};
//旧接口
class IAdaptee {
public:
virtual void foo(int data) = 0;
virtual int bar() = 0;
};
//旧接口的一个实现
class OldAdaptee : public IAdaptee {
public:
virtual void foo(int data) override {
}
virtual int bar() override {
return 0;
}
};
//IAdaptee --Adapter--> Itarget
class Adapter : public ITarget {
public:
Adapter(IAdaptee* pa) : padaptee(pa) {}
virtual void process() override {
//一些适配工作
int data = padaptee->bar();
padaptee->foo(data);
//一些适配工作
}
protected:
IAdaptee* padaptee;
};
int main () {
IAdaptee* pold = new OldAdaptee(); //旧接口的一个实现
ITarget* ptarget = new Adapter(pold); //对旧接口做适配工作
ptarget->process();
return 0;
}
总结
适配器模式:将一个类的接口转换成客户希望的另一个接口,适配器模式使得原本由于接口不兼容而不能在一起工作的那些类可以一起工作
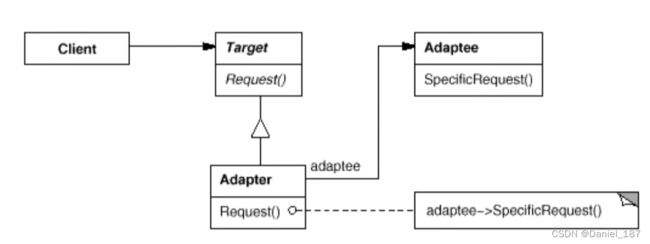
Adapter模式主要应用于“希望复用一些现存的类,但是接口又与复用环境要求不一致的情况”,在遗留代码复用、类库迁移等方面非常有用
GoF23定义了两种Adapter模式的实现结构:对象适配器和类适配器。但类适配器采用“多继承”的实现方式,一般不推荐使用。对象适配器采用“对象组合”的方式,更符合松耦合精神
Adapter模式可以实现的非常灵活,不必拘泥于GoF23中定义的两种结构。例如,完全可以将Adapter模式中的“现存对象”作为新的接口方法参数,来达到适配的目的
中介者模式
属于接口隔离模式的一种
动机
在软件构建过程中,经常会出现多个对象互相关联交互的情况,对象之间常常会维持一种复杂的引用关系,如果遇到一些需求的更改,这种直接的引用关系将面临不断的变化
在这种情况下,我们可使用一个“中介对象”来管理对象间的关联关系,避免相互交互的对象之间的紧耦合引用关系,从而更好地抵御变化
总结
用一个中介对象来封装(封装变化)一系列的对象交互。中介者使各对象不需要显式地相互引用(编译时依赖->运行时依赖),从而使其耦合松散(管理变化),而且可以独立地改变它们之间的交互

将原本杂乱的依赖关系转化为中介者模式:
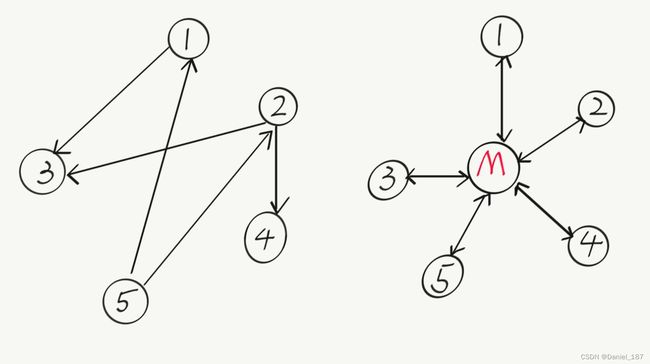
-
将多个对象间复杂的关联关系解耦,Mediator模式将多个对象间的控制逻辑进行集中管理,变“多个对象互相关联”为“多个对象和一个中介者关联”,简化了系统的维护,抵御了可能的变化
-
随着控制逻辑的复杂化,Mediator具体对象的实现可能相当复杂。这时候可以对Mediator对象进行分解处理
-
Facade模式是解耦系统间(单向)的对象关联关系;Mediator模式是解耦系统内各个对象之间(双向)的关联关系
状态模式
状态模式属于“状态变化”模式的一种
在组件构建过程中,某些对象的状态经常面临变化,如何对这些变化进行有效的管理?同时又维持高层模块的稳定?“状态变化”模式为这一问题提供了一种解决方案
典型模式
State
Memento
动机
在软件构建过程中,某些对象的状态如果改变,其行为也会随之而发生变化,比如文档处于只读状态,其支持的行为和读写状态支持的行为就可能完全不同
如何在运行时根据对象的状态来透明地更改对象的行为?而不会为对象操作和状态转化之间引入紧耦合?
实现
对于下面的网络流处理:
enum NetworkState {
Network_Open,
Network_Close,
Network_Connect,
};
class NetworkProcessor {
NetworkState state;
public:
void Operation1() {
if (state == Network_Open) {
//****
state = Network_Close;
}else if (state == Network_Close) {
//****
state = Network_Connect;
} else if (state == Network_Connect) {
//****
state = Network_Open;
}
}
void Operation2() {
if (state == Network_Open) {
//****
state = Network_Connect;
}else if (state == Network_Close) {
//****
state = Network_Open;
} else if (state == Network_Connect) {
//****
state = Network_Close;
}
}
};
类似于策略模式的思想,应用状态模式对上述代码重构:
//state.cpp
//网络状态抽象基类
class NetworkState {
public:
NetworkState* pNext;
virtual void operation1() = 0; //状态对象的行为
virtual void operation2() = 0;
virtual void operation3() = 0;
virtual ~NetworkState() {}
};
//关闭状态
class CloseState : public NetworkState {
static NetworkState* m_instance;
public:
static NetworkState* getInstance() { //单例
//lock
if (m_instance == nullptr) {
m_instance = new CloseState();
}
return m_instance;
}
void operation1() override {
//****
//状态转移
}
void operation2() override {
//****
//状态转移
}
void operation3() override {
//****
//状态转移
}
};
NetworkState* CloseState::m_instance = nullptr;
//连接状态
class ConnectState : public NetworkState {
static NetworkState* m_instance;
public:
static NetworkState* getInstance() {
if (m_instance == nullptr) {
m_instance = new ConnectState();
}
return m_instance;
}
void operation1() override {
//****
//状态转移
}
void operation2() override {
//****
//状态转移
}
void operation3() override {
//****
//状态转移
}
};
NetworkState* ConnectState::m_instance = nullptr;
//打开状态
class OpenState : public NetworkState {
static NetworkState* m_instance;
public:
static NetworkState* getInstance() { //单例
//lock
if (m_instance == nullptr) {
m_instance = new OpenState();
}
return m_instance;
}
void operation1() override {
//****
pNext = CloseState::getInstance(); //转入下一个状态:关闭
}
void operation2() override {
//****
pNext = ConnectState::getInstance(); //转入下一个状态:连接
}
void operation3() override {
//****
pNext = OpenState::getInstance(); //转入下一个状态:打开
}
};
NetworkState* OpenState::m_instance = nullptr;
class NetworkProcessor {
NetworkState* pState;
public:
NetworkProcessor(NetworkState* pState) {
this->pState = pState;
}
void operation1() {
//****
pState->operation1();
pState = pState->pNext;
//****
}
void operation2() {
//****
pState->operation2();
pState = pState->pNext;
//****
}
void operation3() {
//****
pState->operation3();
pState = pState->pNext;
//****
}
};
int main () {
NetworkState* networkState = new OpenState();
NetworkProcessor* networkProcessor = new NetworkProcessor(networkState);
networkProcessor->operation1();
return 0;
}
总结
允许一个对象在其内部状态改变时改变它的行为。从而使对象看起来似乎修改了其行为

-
State模式将所有与一个特定状态相关的行为都放入一个State的子类对象中,在对象状态切换时,切换相应的对象;但同时维持State的接口,这样实现了具体操作与状态转换之间的解耦
-
为不同的状态引入不同的对象使得状态转换变得更加明确,而且可以保证不会出现状态不一致的情况,因为转换是原子性的–即要么彻底转换过来,要么不转换
-
如果State对象没有实例变量,那么各个上下文可以共享同一个 State对象,从而节省对象开销
备忘录模式
动机
在软件构建过程中,某些对象的状态在转换过程中,可能由于某种需要,要求程序能够回溯到对象之前处于某个点时的状态。如果使用一些公有接口来让其他对象得到对象的状态,便会暴露对象的细节实现
如何实现对象状态的良好保存与恢复,但同时又不会因此而破坏对象本身的封装性?
(随着现代语言的成熟的对象序列化技术的发展,备忘录模式已经快成为历史)
实现
//momento.cpp
class Memento {
string state; //对象的状态,简化为一个字符串
public:
Memento(string s) : state(s) {}
string getState() const {
return state;
}
void setState(const string& s) {
state = s;
}
};
class Originator { //要保存的原始类
string state;
public:
Originator() {}
Memento createMomento() {
Memento m(state); //拍摄快照
return m;
}
void setMomento(const Memento& m) {
state = m.getState(); //从快照中恢复
}
};
int main () {
Originator originator;
//存储到备忘录
Memento mem = originator.createMomento();
//**originator状态改变**
//从备忘录中恢复
originator.setMomento(mem);
}
总结
在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。这样以后就可以将该对象恢复到原先保存的状态
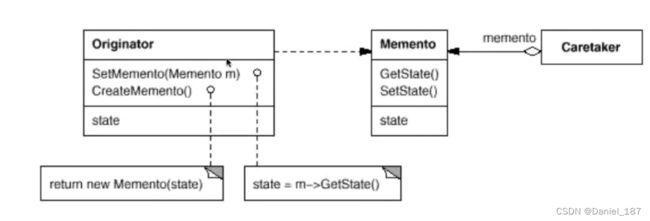
-
备忘录(Memento)存储原发器(Originator)对象的内部状态,在需要时恢复原发器状态
-
Memento模式的核心是信息隐藏,即Originator需要向外接隐藏信息,保持其封装性。但同时又需要将状态保持到外界
-
由于现代语言运行时(如C# Java等)都具有相当的对象序列化支持,因此往往采用效率较高、又较容易正确实现的序列化方案来实现Memento模式
组合模式
组合模式属于“数据结构”模式的一种

动机
软件在某些情况下,客户代码过多地依赖于对象容器复杂的内部实现结构,对象容器内部实现结构(而非抽象接口)的变化将引起客户代码的频繁变化,带来了代码的维护性变差、扩展性变差等弊端
如何将“客户代码与复杂的对象容器结构”解耦?让对象容器自己来实现自身的复杂结构,从而使得客户代码就像处理简单对象一样来处理复杂的对象容器?
实现
//节点基类:内部节点或叶子节点
class Component {
public:
virtual void process() = 0;
virtual ~Component(){}
};
//树内部节点
class Composite : public Component {
string name;
list<Component*> elements; //孩子节点
public:
Composite(const string& s) : name(s) {}
void add(Component* elem) {
elements.push_back(elem);
}
void remove(Component* elem) {
elements.remove(elem);
}
void process() override {
//process currnet node
cout << "my name is " << name << endl;
//process leaf nodes, recursively
for(auto& e : elements) {
e->process();
}
}
};
//叶子节点
class Leaf : public Component {
string name;
public:
Leaf(string s) : name(s) {}
void process() override {
cout << "my name is " << name << endl;
}
};
void invoke(Component& c) {
//****
c.process();
//***
}
int main() {
Composite root("root");
Composite n1("treeNode1");
Composite n2("treeNode2");
Composite n3("treeNode3");
Composite n4("treeNode4");
Leaf l1("leaf1");
Leaf l2("leaf2");
root.add(&n1);
n1.add(&n2);
n2.add(&l1);
root.add(&n3);
n3.add(&n4);
n4.add(&l2);
/*
* root
* / \
* n1 n3
* / \
* n2 n4
* / \
* l1 l2
*
* */
invoke(root);
return 0;
}
总结
将对象组合成树形结构以表示“部分-整体”的层次结构。组合模式使得用户对单个对象和组合对象的使用具有一致性(稳定)

-
Composite模式采用树形结构来实现普遍存在的对象容器,从而将“一对多”的关系转化为“一对一”的关系,使得客户代码可以一致地(复用)处理对象和对象容器,无需关心处理的是单个的对象,还是组合的对象容器
-
将“客户代码与复杂的对象容器结构”解耦是Composite的核心思想,解耦之后,客户代码将与纯粹的抽象接口——而非对象容器的内部实现结构发生依赖,从而更能“应对变化”
-
Composite模式在具体实现中,可以让父对象中的子对象反向追溯;如果父对象有频繁的遍历需求,可使用缓存技巧来改善效率
迭代器模式
属于“数据结构”模式的一种
动机
在软件构建过程中,集合对象内部结构常常变化各异。但对于这些集合对象,我们希望在不暴露其内部结构的同时,可以让外部客户代码透明地访问其中包含的元素;同时这种“透明遍历”也为“同一种算法在多种集合对象上进行操作”提供了可能。
使用面向对象技术将这种遍历机制抽象为“迭代器对象”为“应对变化中的集合对象”提供了一种优雅的方式
实现
//iterator.cpp
template<typename T>
class Iterator {
public:
virtual void first() = 0;
virtual void next() = 0;
virtual bool isDone() const = 0;
virtual T& current() = 0;
};
template<typename T>
class CollectionIterator : public Iterator<T> {
MyCollection<T> mc;
public:
CollectionIterator(const MyCollection<T>& c) : mc(c) {}
void first() override {
}
void next() override {
}
bool isDone() const override {
return true;
}
T& current() override {
T t;
return t;
}
};
template<typename T>
class MyCollection {
public:
Iterator<T>* getIterator() {
//....
return new CollectionIterator<T>(*this);
}
};
int main() {
MyCollection<int> mc;
Iterator<int>* iter = mc.getIterator();
for (iter->first(); !iter->isDone(); iter->next()) {
cout << iter->current() << endl;
}
return 0;
}
以上面这种面向对象的方式实现迭代器,由于虚函数的存在产生了较大的性能开销。STL的迭代器使用模板技术(编译期多态)取代了上面的方式
总结
提供一种方法顺序访问一个聚合对象中的各个元素,而又不暴露(稳定)该对象的内部表示。(隔离算法和容器)
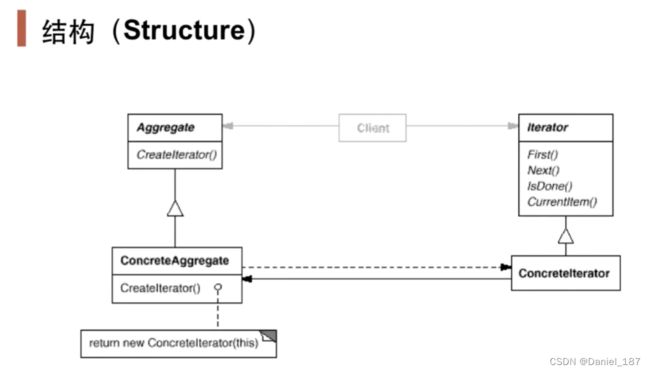
-
迭代抽象:访问一个聚合对象的内容而无需暴露它的内部表示
-
迭代多态:为遍历不同的集合结构提供一个统一的接口,从而支持同样的算法在不同的集合结构上进行操作
-
迭代器的健壮性考虑:如果在遍历的同时更改迭代器所在的集合结构,会导致问题
职责链模式
属于“数据结构”模式的一种
动机
在软件构建过程中,一个请求可能被多个对象处理,但是每个请求在运行时只能有一个接受者,如果显式指定,将必不可少地带来请求发送者与接受者的紧耦合
如何使请求的发送者不需要指定具体的接受者?让请求的接受者自己在运行时决定来处理请求,从而使两者解耦
实现
//responsibility-chain.cpp
enum class RequestType {
REQ_HANDLER1,
REQ_HANDLER2,
REQ_HANDLER3
};
class Request {
string description;
RequestType reqType;
public:
Request(const string& desc, RequestType type) : description(desc), reqType(type) {}
RequestType getReqType() const {
return reqType;
}
const string& getDescription() const {
return description;
}
};
class ChainHandler {
ChainHandler* nextChain;
void sendRequestToNextHandler(const Request& req) {
if (nextChain != nullptr) {
nextChain->handle(req);
}
}
protected:
virtual bool canHandleRequest(const Request& req) = 0;
virtual void processRequest(const Request& req) = 0;
public:
ChainHandler() {
nextChain = nullptr;
}
void setNextChain(ChainHandler* next) {
nextChain = next;
}
void handle(const Request& req) {
if (canHandleRequest(req)) {
processRequest(req);
} else {
sendRequestToNextHandler(req);
}
}
};
class Handler1 : public ChainHandler {
protected:
bool canHandleRequest(const Request& req) override {
return req.getReqType() == RequestType::REQ_HANDLER1; //判断自己能否处理该类型请求
}
void processRequest(const Request& req) override {
cout << "Handler1 is handling request:" << req.getDescription() << endl;
}
};
class Handler2 : public ChainHandler {
protected:
bool canHandleRequest(const Request& req) override {
return req.getReqType() == RequestType::REQ_HANDLER2;
}
void processRequest(const Request& req) override {
cout << "Handler2 is handling request:" << req.getDescription() << endl;
}
};
class Handler3 : public ChainHandler {
protected:
bool canHandleRequest(const Request& req) override {
return req.getReqType() == RequestType::REQ_HANDLER3;
}
void processRequest(const Request& req) override {
cout << "Handler3 is handling request:" << req.getDescription() << endl;
}
};
int main() {
Handler1 h1;
Handler2 h2;
Handler3 h3;
h1.setNextChain(&h2);
h2.setNextChain(&h3);
/*h1 --> h2 --> h3*/
Request req("I'm 3, process me", RequestType::REQ_HANDLER3);
h1.handle(req);
return 0;
}
总结
使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递请求,直到有一个对象处理它为止
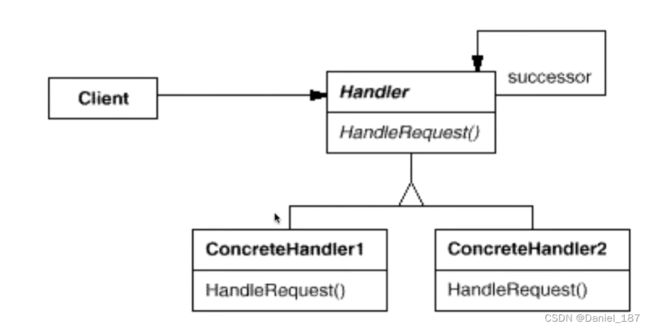
-
Chain of Responsibility模式的应用场合在于“一个请求可能有多个接受者,但是最后真正的接受者只有一个",这时候请求发送者与接受者的耦合有可能出现“变化脆弱”的症状,职责链的目的就是将二者解耦,从而更好地应对变化
-
应用了Chain of Responsibility模式后,对象的职责分派将更具灵活性。我们可以在运行时动态添加/修改请求的处理职责
-
如果请求传递到职责链的末尾仍得不到处理,应该有一个合理的缺省机制。这也是每一个接受对象的责任,而不是发出请求的对象的责任
命令模式
属于“行为变化”模式的一种

动机
在软件构建过程中,“行为请求者”与“行为实现者”通常呈现一种紧耦合”。但在某些场合——比如需要对行为进行“记录、撤销/重
(undo/redo)、事务”等处理,这种无法抵御变化的紧耦合是不合适的
在这种情况下,如何将“行为请求者”与“行为实现者”解耦:将一组行为抽象为对象,可以实现二者之间的松耦合
实现
//command.cpp
class Command {
public:
virtual void execute() = 0;
};
class ConcreteCommand1 : public Command {
string arg;
public:
ConcreteCommand1(const string& a) : arg(a) {}
void execute() override {
cout << "#1 processing "<< arg << endl;
}
};
class ConcreteCommand2 : public Command {
string arg;
public:
ConcreteCommand2(const string& a) : arg(a) {}
void execute() override {
cout << "#2 processing "<< arg << endl;
}
};
class MarcoCommand : public Command {
vector<Command*> commands;
public:
void add(Command* c) {
commands.push_back(c);
}
void execute() override {
for (auto& c : commands) {
c->execute();
}
}
};
int main() {
ConcreteCommand1 cmd1("arg ###");
ConcreteCommand2 cmd2("arg $$$");
MarcoCommand marco;
marco.add(&cmd1);
marco.add(&cmd2);
marco.execute();
return 0;
}
总结
将一个请求(行为)封装为一个对象,从而使你可用不同的请求对客户进行参数化;对请求排队或记录请求日志,以及支持可撤销的操作
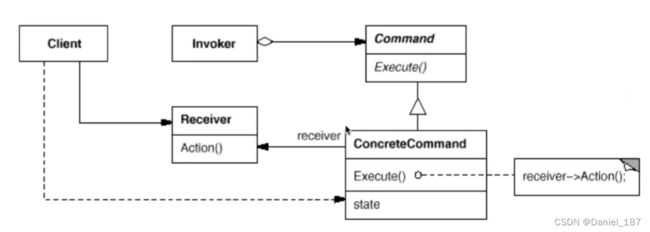
-
Command模式的根本目的在于将“行为请求者”与“行为实现者”解耦,在面向对象语言中,常见的实现手段是“将行为抽象为对象”
-
实现Command接口的具体命令对象ConcreteCommand有时候根据需要可能会保存一些额外的状态信息。通过使用Composite模式可以将多个“命令”封装为一个“复合命令”MacroCommand
-
Command模式与C++中的函数对象有些类似。但两者定义行为接口的规范有所区别:Command以面向对象中的“接口-实现”来定义行为接口规范,更严格,但有性能损失;C++函数对象以函数签名来定义行为接口规范,更灵活,性能更高
访问器模式
动机
在软件构建过程中,由于需求的改变,某些类层次结构中常常需要增加新的行为(方法),如果直接在基类中做这样的更改,将会给子类带来很繁重的变更负担,甚至破坏原有设计
如何在不更改类层次结构的前提下,在运行时根据需要透明地为类层次结构上的各个类动态添加新的操作,从而避免上述问题?
实现
//visitor.cpp
//访问器基类
class Visitor {
public:
virtual void visitElementA(ElementA&) = 0;
virtual void visitElementB(ElementB&) = 0;
virtual ~Visitor() {}
};
class Element {
public:
virtual void accept(Visitor& visitor) = 0;
virtual ~Element() {}
};
class ElementA : public Element {
public:
void accept(Visitor& visitor) override {
visitor.visitElementA(*this);
}
};
class ElementB : public Element {
public:
void accept(Visitor& visitor) override {
visitor.visitElementB(*this);
}
};
//====上面是稳定部分,下面是变化部分====
//重写一组访问器
class Visitor1 : public Visitor {
public:
void visitElementA(ElementA& element) override {
cout << "Visitor1 is processing ElementA" << endl;
}
void visitElementB(ElementB& element) override {
cout << "Visitor1 is processing ElementB" << endl;
}
};
//重写另外一组访问器
class Visitor2 : public Visitor {
public:
void visitElementA(ElementA& element) override {
cout << "Visitor2 is processing ElementA" << endl;
}
void visitElementB(ElementB& element) override {
cout << "Visitor2 is processing ElementB" << endl;
}
};
int main () {
Visitor2 visitor;
ElementB elementB;
elementB.accept(visitor);
//double dispatch
ElementA elementA;
elementA.accept(visitor);
return 0;
}
总结
表示一个作用于某对象结构中的各元素的操作。使得可以在不改变(稳定)个元素的类的前提下定义(扩展)作用于这些元素的新操作(变化)
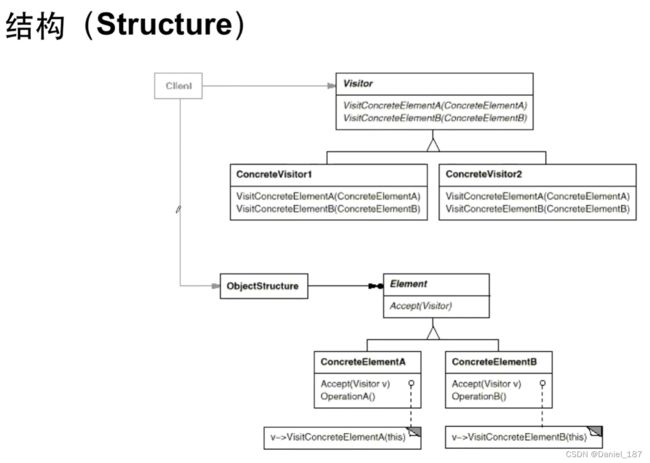
Visitor模式要求子类的种类数必须稳定不变,以便确定Visitor类中需要针对多少子类声明虚函数。这也是Visitor模式受限制的主要原因
-
Visitor模式通过所谓双重分发(doubledispatch)来实现在不更改(不添加新的操作-编译时)Element类层次结构的前提下,在运行时透明地为类层次结构上的各个类动态添加新的操作(支持变化)
-
所谓双重分发即Visitor模式中间包括了两个多态分发(注意其中的多态机制):第一个为accept方法的多态辨析;第二个为VisitElementX方法的多态辨析
-
Visitor模式的最大缺点在干扩展类层次结构(增添新的Element子类),会导致Visitor类的改变。因此Vistor模式适用于Element类层次结构稳定,而其中的操作却经常面临频繁改动
解析器模式
解析器模式属于“领域规则”模式的一种:

动机
在软件构建过程中,如果某一特定领域的问题比较复杂,类似的结构不断重复出现,如果使用普通的编程方式来实现将面临非常频繁的变化
在这种情况下,将特定领域的问题表达为某种语法规则下的句子,然后构建一个解释器来解释这样的句子,从而达到解决问题的目的
实现
//interpreter.cpp
class Expression{
public:
virtual int interpreter(map<char, int> var) = 0;
virtual ~Expression(){};
};
//变量表达式
class VarExperssion : public Expression {
char key;
public:
VarExperssion(char key) {
this->key = key;
}
int interpreter(map<char, int> var) override {
return var[key];
}
};
//符号表达式
class SymbolExpression : public Expression {
protected:
Expression* left;
Expression* right;
public:
SymbolExpression(Expression* left, Expression* right) : left(left), right(right) {}
};
class AddExpression : public SymbolExpression {
public:
AddExpression(Expression* l, Expression* r) : SymbolExpression(l, r) {}
int interpreter(map<char, int> var) override {
return left->interpreter(var) + right->interpreter(var);
}
};
class SubExpression : public SymbolExpression {
public:
SubExpression(Expression* l, Expression* r) : SymbolExpression(l, r) {}
int interpreter(map<char, int> var) override {
return left->interpreter(var) - right->interpreter(var);
}
};
Expression* analyse(string exp) {
stack<Expression*> expstk;
Expression* left = nullptr;
Expression* right = nullptr;
for (int i = 0; i < exp.size(); ++i) {
switch (exp[i]) {
case '+':
left = expstk.top();
right = new VarExperssion(exp[++i]);
expstk.push(new AddExpression(left, right));
break;
case '-':
left = expstk.top();
right = new VarExperssion(exp[++i]);
expstk.push(new SubExpression(left, right));
break;
default:
expstk.push(new VarExperssion(exp[i]));
}
}
return expstk.top();
}
void release(Expression* expression) {
//...
}
int main () {
string expStr = "a+b-c+d";
map<char, int> var;
var['a'] = 5;
var['b'] = 2;
var['c'] = 1;
var['d'] = 6;
Expression* expression = analyse(expStr);
int result = expression->interpreter(var); //interpret from root recursively
cout << result << endl;
release(expression);
return 0;
}
总结
给定一个语言,定义它的文法的一种表示,并定义一种解释器,这个解释器使用该表示来解释语语言中的句子

-
Interpreter模式的应用场合是Interpreter模式应用中的难点,只有满足“业务规则频繁变化,且类似的结构不断重复出现,并且容易抽象为语法规则的问题”才适合使用Interpreter模式
-
使用Interpreter模式来表示文法规则,从而可以使用面向对象技巧来方便地“扩展”文法
-
Interpreter模式比较适合简单的文法表示,对于复杂的文法表示, Interperter模式会产生比较大的类层次结构,需要求助于语法分析生成器这样的标准工具
设计模式总结
一个目标:管理变化,提高复用
两个手段:分解&抽象
八大原则:
- 依赖倒置原则
- 开放封闭原则
- 单一职责原则
- 李氏替换原则
- 接口隔离原则
- 对象组合优于类继承
- 封装变化点
- 面向接口编程
重构技法:
静态 -> 动态
早绑定 -> 晚绑定
继承 -> 组合
编译时依赖 -> 运行时依赖
紧耦合 -> 松耦合
模式分类:

松耦合的基础:指针指向多态对象
经验之谈:
- 不要为模式而模式
- 关注抽象类&接口
- 理清变化点和稳定点
- 审视依赖关系
- 要有Framework和Application的区隔思维
- 良好的设计是演化的结果