k8s等运维(四)
一、共享存储
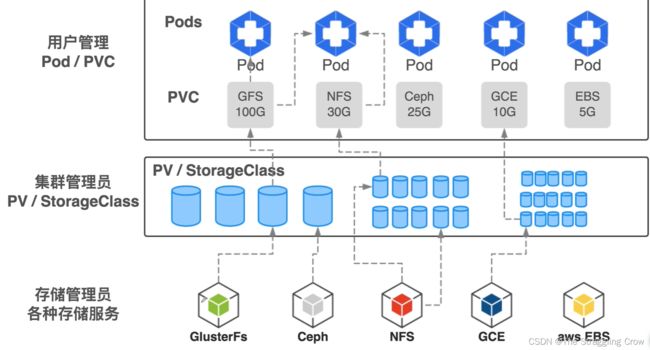
1、pv 持久化数据卷:远程共享存储—运维来管理
accessModes:
- ReadWriteOnce # 只有一个pod可以读写这个pv,改成ReadWriteMany就很多Pod都能
2、pvc 开发人员负责管理
描述了pod对共享存储的需求或者期望
3、kubectl create pv和pvc后,pv和pvc要建立好绑定关系,才能使用起来
pv要满足pvc的需求,想存储大小啊,读写权限啊
把pvc的资源描述对象里把pv添加进去,就是绑定在一起了
pod就可以像使用volumes一样使用pvc了
volumes:
persistentVolumeClaim:
claimName: nfs
pod里面包含了pvc的名字,pvc里面描述了pv的需求,pv描述了具体的后端的地址,如何访问啊,都有哪些参数啊,
pod所有的volume都会对应本地的一个目录,把本地目录挂载到nfs server 上pv指定的位置
docker run -v 命令将目录映射到容器里面,这样就实现了共享存储

4、StorageClass 自动管理pv
如果有很多pod需要共享存储,每建一个就要让运维给我们创建一个pv,不用了还要回收,麻烦死了,所以StorageClass出现了
让k8s 根据StorageClass 这个模板自动创建pv
yaml关键词 provisioner:
创建pv都是k8s 自己搞定的
综述,就是docker run -v 挂远程存储啦
5、实践共享存储ClusterFS
需要三台虚拟机,并且每个虚拟机有两个磁盘,其中一块裸磁盘,供ClusterFS完全接管
在每一个work节点装上clusterfs的客户端
yum install -y glusterfs glusterfs-fuse
在master节点上的apiserver和每个节点的kubelet要加上 allow-privileged=true
ps -ef|grep apiserver|grep allow-pri
vi /etc/systemd/system/kubelet.service
1)在三台虚机上配置好ClusterFs,也就是上图最底层,存储服务的提供者,给三台加tag 才能确保部署在了正确位置
2)初始化磁盘,让ClusterFs管理起来,用heketi工具来做
3)结果就是运行两个pod副本,在一个副本里写如文件,在另一个也能看到
二、有状态应用守护者
1、deployment 不能胜任所有的编排工作
只能胜任 无状态,pod无差别, 没有顺序性
2、StatefulSet 抽象了两种有状态场景,就是解决了两个问题
1)多个pod之间的顺序性,需要按一定的顺序启动,实例之间互相访问,互相通信的情况
注意下yaml下的serviceName:service的名字 表示告诉statefulset用哪个headless service 去保证每个pod的解析
这样弄下来,每个pod都有具体的编号,就有了顺序性
2)持久存储区分,就是每个pod私有存储空间(当然在有共享存储的前提下,没有,本来就是隔离的)
**volumeClaimTemplates:**创建pvc的模板,下面写上路径,这个路径就是私有存储
kubectl get pvc
pod删了,重建,存储依旧有
将statefulset删掉,pod不在了,pvc 和 pv 还在,需要自己手动处理
三、KubernetesAPI
就是yaml文件里的内容,官网有具体介绍
还可以用resfulAPI 搞,操作apiserver,github上提供了各种语言的client
里面有很多examples,什么logs,WebSockets等等
最后搞出来就是容器管理平台工具,不就是kubesphere嘛?
为了不太熟悉k8s的同学更简单地使用复杂的东西
四、日志
k8s中的日志处理
1、将日志打到远端,Kafka or es,最后汇总到日志服务器
2、阿里的LogPilot在每个节点上做agent(没有对pod和服务侵入,占用资源也少),采集日志,发给es做存储,Kibana做展示
LogPilot专门针对docker的。
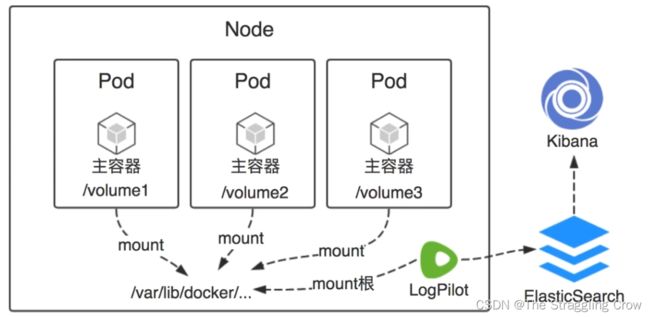
3、LogPilot 是容器日志采集工具,发送到后端,比如es,kafka ,redis等等
4、环境搭建ES,LogPilot,Kibana这些都是通过yaml文件
es 9200 http端口是与外部通信用的,9300 tcp是es之间通信用的
es的三个副本分别放在了三个节点上,用到了statefulset
LogPilot 部署用 DaemonSet,保证每个节点上都有一个实例来搜集日志
volumeMounts: mountPath: /var/run/docker.sock 这样就可以获取docker 信息,日志存储位置,docker 事件,通过挂载目录形式,拿到权限
需要在被采集的yaml设置env和volumeMounts,在里面填上要采集目录的位置
五、监控报警
1、监控的目的
及时发现已经出现的问题,提前预警可能发生的问题
2、监控什么
系统基础指标,cpu 内存 网络 IO load负载,否则主机出问题,服务不能幸免
服务基础信息,cpu、内存占用情况,内存是否溢出,占用的网络带宽,磁盘IO,监听的端口在不在
服务个性化信息,有些服务提供特定的端口,比如web服务,请求的排队情况呀,每秒的请求次数,错误次数,请求的处理时间啊
日志,根据日志的异常数,和异常发生的频率来做预警
3、如何监控?
数据采集,每隔多长时间采集一次
数据存储,时间序列数据库来存储
定义报警规则,一旦触发条件,就报警
配置报警方式,邮件,短信,企业钉钉
4、常见的工具
Zabbix — 主要是系统基础信息的监控
5、Kubernetes的监控
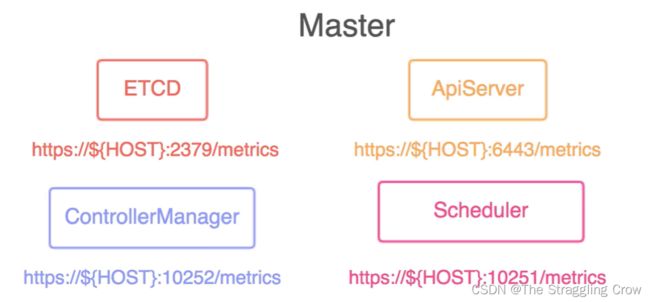
每个节点,容器的基础指标,k8s集群组件的监控,比如ApiServer,controllerManager,etcd
6、Prometheus
它是一系列服务的组合,系统和服务的监控报警平台
1)特征
由metric 名称和 kv 标识的多维数据模型
每一条名字和kv组合都是一条单独的时间序列
metric名称{ kv标识 }

灵活的查询语言(PromQL),比如 http_response_total{method=“GET”} 将metric是 h…t method是GET的都给查询出来
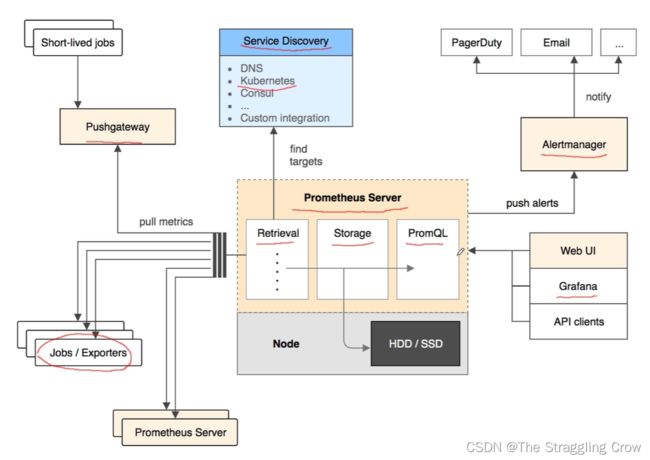
2) 架构
就是 Prometheus Server 从各个地方pull数据,即为 Retrieval,数据保存在Storage ,通过PromQL查询
Jobs / Exporters 暴露指标,让Retrieval 来抓取的
Pushgateway 用push 的方式将数据推送到网关, 比如一些定时任务和一次性执行任务
Service Discovery 是 Prometheus 支持的服务发现
够报警条件,就将消息push 给 Alertmanager
3) Prometheus 常见的数据类型
Counter 累积增大,不会减小,比如请求的次数,异常发生的次数
Gauge可大可小,内存的变化,磁盘的变化,
Histogram && Summary 统计和分析样本的分布情况, 我们会使用量化指标的平均值,cpu的平均使用率,页面的平均响应时间,但是有时候个别请求远远超出平均水平,这样平均水平就不能体现出问题,为了分析这种情况,分时间段,比如0-100ms,请求有几个;100-500ms呢,通过这种方式就能快速找到系统慢的原因,即为这项数据类型的作用
Histogram 类型于直方图,就是之前定义好区间
Summary 分位数,排序后,第几个的样本的值是多少
4)数据是如何采集来的
通过ds的方式将NodeExporter运行在每个worker 上。抓取节点的信息,内置http服务,供 Prometheus pull 数据

针对 docker容器指标
每个kubelet内置 cAdvisor,采集容器的信息,cpu,内存,网络文件系统等,也会启动http服务,供 Promethues pull 数据

针对K8s组件的监控
5)部署
手动部署—不好用
Helm – k8s里面的文件包管理工具,类似centos里的 yum
Prometheus Operator – 用了跟Prometheus 更贴近的技术方案
Helm + Prometheus Operator
Helm简介
helm是一个二进制文件
一个包就是一个Chart( 本质上就是一个目录, 一般会打成 tar.gz)
码云上有详细安装步骤
HELM客户端,一个二进制文件,
Chart Files就是一个目录,里面存放了各种 yaml文件
STORAGE 本质就是一个软件包服务器,供用户下载
TILLER Helm命令的服务端,接收helm的请求,根据对应的chart来生成k8s部署的配置文件,提交给k8s来创建应用。就是一个桥梁作用
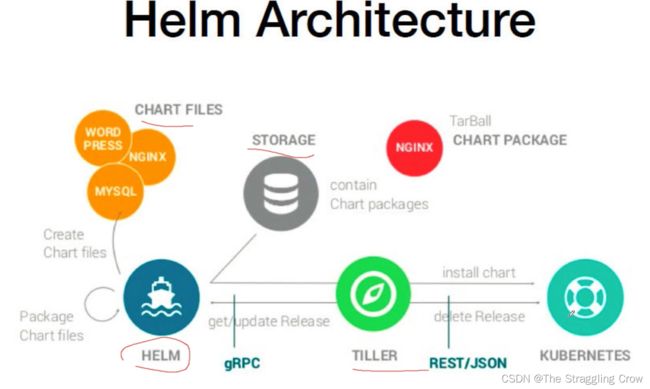
Operator
很多资源pod,deployment,ds,service,他们都是k8s 预先定义好的,k8s 自己的控制器去管理他们
控制器的本质就是一个代码循环,不断去看预期状态与真实状态之间的差别,并努力使他们保持一致
比如一个deployment,我们定义的实例数是3,现在只有一个实例,控制器就会发现差别,然后再启动两个实例
Operator就是利用自定义资源类型CRD + 自定义控制器,实现了它操作者的能力,所以Operator也能胜任statefulset的工作,并且它是针对特定性服务的。
CRD怎么搞,自己查
部署Prometheus只需要 helm install
问题解决
kubectl describe 你有问题的pod, 看看哪个镜像下载不到
也可以到对应的worker节点看下系统日志
journalctl -f
find .|grep xxx.yaml| xargs grep “要找的镜像名”
换成中国源
查看情况
kubectl get ds -n 命名空间
kubectl get svc -n 命名空间
kubectl statefulset ds -n 命名空间
服务配好后,配ingress,里面加上服务名和域名,然后配host,就能通过域名访问了
endpoint,就是从哪个地址,获取Prometheus 想要的指标
六、ServiceMesh
就是服务网格,一个概念,不是产品,代表作 Istio 针对微服务
Istio的架构和原理
核心就是代理,一个pod有一个网络代理,pod的共享网络机制,让这个代理完全接管网络,让服务的进出流量都通过代理,有了代理,还需要一个对这些代理统一管理的组件,
架构大致分为两块,数据层(一系列的代理组成,控制所有的网络通信和策略)和控制层(有很多模块,管理流量的,管理路由策略的,搜集监测数据的,负责通信安全的)

Proxy是用c++写的Envoy以sidecar的方式部署在每个pod中,istio比作互联网公司,那么Envoy 就是一线员工,所有的事都是由他们干的
控制层的Pilot 就是Envoy 的领导,告诉它怎么来干活,给它提供情报,信息,集群都有谁,都在哪,告诉它多长时间算超时,应该重试几次等等
Galley负责验证配置的,校验各种配置是不是正确。
Citadel 安全服务,权限控制
Istio解决的问题
1)故障排查
这个请求在哪失败的?A 有调用 B 嘛?
为什么用户的请求/页面 hung住了?
为什么系统这么慢?哪个组件最慢?
2)应用容错性
客户端没有设置 timeout 导致应用卡住
没有重试机制,某个服务偶尔出现的异常导致用户页面错误
某些节点异常(如load过高),导致应用响应变长
3)应用升级发布
新版本一次性升级,一旦出错影响范围很大
无法进行 A/B 测试,根据用户属性访问不通版本
服务版本的依赖关系处理不当导致的服务不可用
4)系统安全
服务都是HTTP的而非 HTTPS
没有流量限制,任何人都可以对服务发起攻击
在k8s部署istio,去git上提供的那里找详细文档
BookInfo 为了演示Istio的应用,该应用是由四个单独的微服务构成。就是在线书店
把sidecar注入到每个服务中,每个服务都会有一个proxy, 这些服务都全部加入到网格中了。
可以通过修改yaml让指定给用户哪个应用版本,再比如指定用户登录后看到一个版本,退出登录看到另一个版本,就是具有配置路由功能
Istio完全控制了网络,所以可以模拟tcp,http的故障,比如网络延迟
流量转移,将流量从一个版本转移到另一版本
熔断就是跳闸,以减缓内部的压力,在内部恢复正常后,我们再给它恢复正常
流量镜像,也叫影子流量,一般用于测试环境,把一部分生产流量拿过来给新服务,新版本,看看有没有什么问题
可观测性
Istio命名空间里在部署上Prometheus
分布式追踪:做链路分析,利用 Envoy 的分布式追踪功能,用于追踪到问题,Jaeger 提供UI
网格可视化,用kiali, 提供UI,让我们可以去看网格和 Istio 的配置
七、Docker or Containerd
用docker需要加垫片才能和k8s通信,但是containerd就不用。
containerd 一个工业标准的容器运行时,管理了容器的整个生命周期
部署containerd,去github 下载 cni.tar.gz
ctr 也能像docker那样 pull push image,也能开启容器,删除容器,也有命名空间,docker底层就是它
【有很多bash命令的时候,直接写到sh里,一口气解决】
如果一台电脑同时安装了 docker和containerd,他们的存储目录不一样,镜像不共享。
但是他们俩的镜像是通用的,docker 的image,crt也能从镜像仓库拉下来用
docker 运行一个容器,用crt也能看到,只是命名空间不同
crictl用的命名空间是k8s.io,比crt 命令更简洁,k8s相关的操作就用它
【可以设置别名 alias docker=crictl 因为他们的命令后接的几乎一样】不同的是crictl还有一些关于pod的相关功能
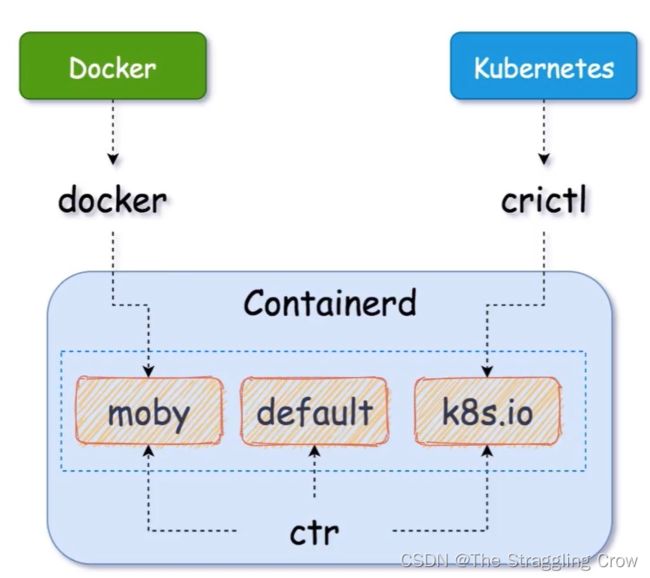
containerd有三个命名空间,moby,default,k8s.io
ctr 是containerd 的客户端工具,能操作所有namespace
docker 底层是使用了 containerd 的 moby 命名空间,仅限于容器。image是docker自己的,因为存储目录不同,是物理隔离的
crictl 是 k8s 专用的命令 它用了 containerd 的 k8s.io 命名空间 去处理它的容器和镜像
八、CoreDNS
就是dns呀,不用ip访问了,域名就可以
NodeLocal DNSCache通过 daemon-set 形式运行在每个工作节点,作为节点pod的 dns 缓存,提升dns性能