机器学习能够基于数据发现一般化规律的优势日益突显,我们看到有越来越多的开发者关注如何训练出更快速、更准确的机器学习模型,而分布式训练 (Distributed Training) 则能够大幅加速这一进程。
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |
|---|
关于在亚马逊云科技上进行分布式训练的话题,在各种场合和论坛我们讨论了很多。随着 PyTorch 这一开源机器学习框架被越来越多的开发者在生产环境中使用,我们也将围绕它展开话题。本文我们将分别探讨在 PyTorch 上的两种分布式训练:数据分布式训练,以及模型分布式训练。
首先我们来看看当今机器学习模型训练的演进趋势中,开发者对模型训练结果的两种迫切需求:
- 更快速
- 更准确
更快速的数据分布式训练
对于机器学习模型训练来说,将庞大的训练数据有效拆分,有助于加快训练速度。
常见的数据分布式训练方式有两种:
基于参数服务器的数据分布式训练

(异步)参数服务器 (Parameter Server) : 如 TensorFlow Parameter Server Strategy
对于参数服务器 (Parameter Server) 来说,计算节点被分成两种:
- Workers:保留一部分的训练数据,并且执行计算;
- Servers:共同维持全局共享的模型参数。
而 Workers 只和 Servers 有通信,Workers 相互之间没有通信。
参数服务器方式的优点开发者都很熟悉就不赘述了,而参数服务器的一个主要问题是它们对可用网络带宽的利用不够理想,Servers 常常成为通信瓶颈。
由于梯度在反向传递期间按顺序可用,因此在任何给定的时刻,从不同服务器发送和接收的数据量都存在不平衡。有些服务器正在接收和发送更多的数据,有些很少甚至没有。随着参数服务器数量的增加,这个问题变得更加严重。
基于 Ring ALL-Reduce 的数据分布式训练

(同步)Ring All-Reduce: 如 Horovod 和 PyTorch DDP
Ring All-Reduce 的网络连接是一个环形,这样就不需要单独的 GPU 做 Server。6 个 GPU 独立做计算,用各自的数据计算出各自的随机梯度,然后拿 6 个随机梯度的相加之和来更新模型参数。为了求 6 个随机梯度之和,我们需要做 All-Reduce。在全部的 GPU 都完成计算之后,通过 Ring All-Reduce 转 2 圈(第 1 圈加和,第 2 圈广播这个加和),每个 GPU 就有了 6 个梯度的相加之和。注意算法必须是同步算法,因为 All-Reduce 需要同步(即等待所有的 GPU 计算出它们的梯度)。
Ring All-Reduce 的主要问题是:
- 通过 Ring All-Reduce 转圈传递信息时,例如:G0 传递给 G1 时,其它 GPU 都在闲置状态;因此,这种步进时间越长,GPU 闲置时间就越长;而 GPU 越多这种通信代价就越大;
- All-Reduce 的资源会占用宝贵的 GPU 资源,所以会在扩展的时候,面临效率挑战。
实例:Amazon SageMaker 数据并行的分布式方法
那么如何尽可能消除上述弊端?我们通过亚马逊云科技在 Amazon SageMaker 上的数据并行实例来演示如何解决这一问题。
SageMaker 从头开始构建新的 All-Reduce 算法,以充分利用亚马逊云科技网络和实例拓扑,利用 EC2 实例之间的节点到节点通信。

这样做的优势在于:
- 引入了一种名为平衡融合缓冲区的新技术,以充分利用带宽。GPU 中的缓冲区将梯度保持到阈值大小,然后复制到 CPU 内存,分片成 N 个部分,然后将第 i 个部分发送到第 i 个服务器。平衡服务器发送和接收的数据,有效利用带宽。
- 可以有效地将 All-Reduce 从 GPU 转移到 CPU。
我们能够重叠向后传递和 All-Reduce,从而缩短步进时间,释放 GPU 资源用于计算。
在这里分享关键的 PyTorch 代码步骤:
- 更新训练脚本
与非分布式训练不同的是,在这里我们输入 mdistributed.dataparallel.torch.torch_smdbp 的模型:
# Import SMDataParallel PyTorch Modules
import smdistributed.dataparallel.torch.torch_smddp- 提交训练任务
在这里指定一个开关,打开数据并行即可。这样可以非常方便地调试,而不用在底层配置上花费时间。
# Training using SMDataParallel Distributed Training Framework
distribution={"smdistributed":
{"dataparallel":
{"enabled": True
}
}
},
debugger_hook_config=False,您可以在 GitHub 上查看完整代码示例:
Amazon Sagemaker Examples
- https://github.com/aws/amazon-sagemaker-examples/blob/main/training/distributed_training/pytorch/data_parallel/mnist/code/train_pytorch_smdataparallel_mnist.py?trk=cndc-detail
- https://github.com/aws/amazon-sagemaker-examples/blob/main/training/distributed_training/pytorch/data_parallel/mnist/pytorch_smdataparallel_mnist_demo.ipynb?trk=cndc-detail
更准确的模型分布式训练
众所周知,模型越大,那么预测结果的准确度越高。
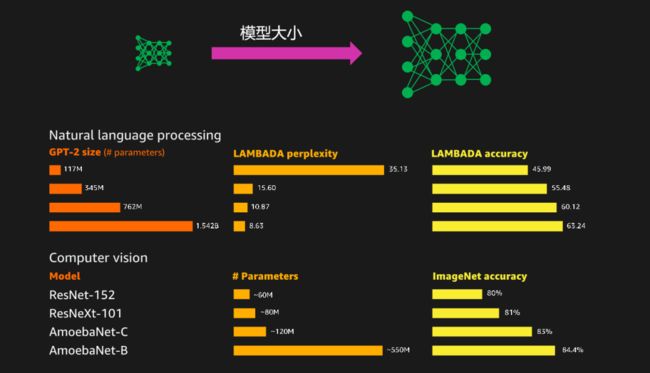
那么在面对庞大模型的时候如何进行模型并行?我们推荐开发者使用以下方式:
自动模型拆分
主要的优化策略基于内存使用和计算负载,从而更好地实现大模型的兼容。
平衡内存使用:平衡每台设备上存储的可训练参数和激活次数的总数。
平衡计算负载:平衡每台设备中执行的操作次数。
流水线执行计划
Amazon Sagemaker PyTorch SDK 中可以选择两种方式实现:
- 简单流水线:需要等前项全部计算完之后才能进行后项的计算。

- 交错流水线:通过更高效利用 GPU 来实现更好的性能,包括模型并行等方式。

Amazon SageMaker 分布式模型并行库的核心功能是流水线执行 (Pipeline Execution Schedule) ,它决定了模型训练期间跨设备进行计算和数据处理的顺序。流水线是一种通过让 GPU 在不同的数据样本上同时进行计算,从而在模型并行度中实现真正的并行化技术,并克服顺序计算造成的性能损失。
流水线基于将一个小批次拆分为微批次,然后逐个输入到训练管道中,并遵循库运行时定义的执行计划。微批次是给定训练微型批次的较小子集。管道调度决定了在每个时隙由哪个设备执行哪个微批次。例如,根据流水线计划和模型分区,GPU i 可能会在微批处理 b 上执行(向前或向后)计算,而 GPU i+1 对微批处理 b+1 执行计算,从而使两个 GPU 同时处于活动状态。
该库提供了两种不同的流水线计划,简单式和交错式,可以使用 SageMaker Python SDK 中的工作流参数进行配置。在大多数情况下,交错流水线可以通过更高效地利用 GPU 来实现更好的性能。
更多相关信息可参考:
https://docs.aws.amazon.com/zh_cn/sagemaker/latest/dg/model-p...
PyTorch 模型并行的分布式训练的关键步骤如下(以PyTorch SageMaker Distributed Model Parallel GPT2 代码为例):

- 更新训练脚本
a. Import 模型并行模块
b. 带入参数的模型并行的初始化 smp.int (smp_config)
- 提交训练任务
a. 消息传递接口 (MPI) 是编程并行计算机程序的基本通信协议,这里可描述每台机器上的 GPU 数量等参数
b. 激活模型分布式训练框架和相关配置等
实例:Amazon SageMaker 分布式训练
训练医疗计算机视觉 (CV) 模型需要可扩展的计算和存储基础架构。下图案例向您展示如何将医疗语义分割训练工作负载从 90 小时减少到 4 小时。
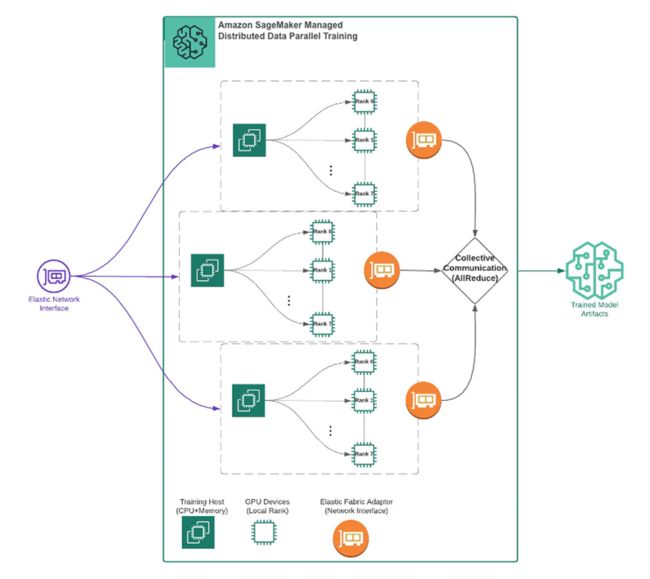
图片来源:官方博客《使用 Amazon SageMaker 训练大规模医疗计算机视觉模型》
解决方案中使用了 Amazon SageMaker 处理进行分布式数据处理,使用 SageMaker 分布式训练库来加快模型训练。数据 I/O、转换和网络架构是使用 PyTorch 和面向人工智能的医疗开放网络 (MONAI) 库构建的。
在下篇文章中,我们将继续关注无服务器推理,请持续关注 Build On Cloud 微信公众号。
往期推荐

作者
黄浩文
亚马逊云科技资深开发者布道师,专注于 AI/ML、Data Science 等。拥有 20 多年电信、移动互联网以及云计算等行业架构设计、技术及创业管理等丰富经验,曾就职于 Microsoft、Sun Microsystems、中国电信等企业,专注为游戏、电商、媒体和广告等企业客户提供 AI/ML、数据分析和企业数字化转型等解决方案咨询服务。
文章来源:https://dev.amazoncloud.cn/column/article/63e32dd06b109935d3b...