MIT 6.824 lab1 mapreduce
经过一段时间的了解这个MIT 6.824,真的深深感觉,见识越多,就越知道自己有多菜。我登入6.824网站,可以看到别人一周的安排是怎样的,一周之内学会go语言,并完成lab 1,其中lab 1 又有五个部分。而我呢,我大概花了一周才了解了go语言,又看了一周才了解mapreduce,然后才开始做lab1,不得不说里面的introduction,Read,lab全是英文,真的超烦人,有时候写程序写着也会忘记go怎么用的,甚至和java,c++混淆了,说真的,这一个月真的搞这个东西搞到自闭,搞到脑袋都要炸了。
不过呢还是得承认这个过程还是挺不错的,知道了自己和别人的差距,做出来的过程中成就感还是有的哈哈哈。挺喜欢这种感觉。
如果想要学习的话可以去MIT 6.824学习。
一:MapReduce简介
首先就是理一理mapreduce了,其实是map and reduce,这是一个编程模型,一般笼统的分为map函数和reduce函数。
原理:通过输入key–value有map函数生成中间的key–value,并作为reduce的输入由reduce生成最终的value。
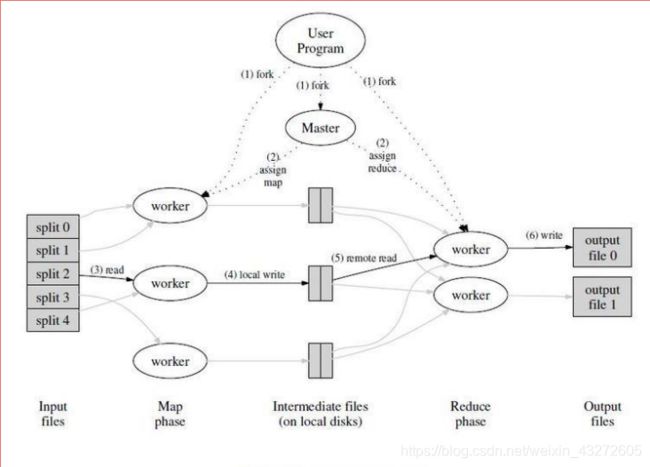
看看上面这个图片梳理一下大概的过程了。
1:首先就是用户是吧,根据具体的场景,选取具体的mapreduce编程模型。
2:mapreduce库里面的某些程序将输入文件分成M个数据片,如上图左边的split0,1,2,3…有的用户程序会在集群中创建大量副本,备用。
3:有个特殊的程序master程序,还有就是worker程序。master程序分配M个map任务和R个reduce任务,将他们分给空闲的worker程序
4:分配的map任务的worker程序读取相应的输入数据,解析出key-value,然后传递给map函数,map函数生成相应的中间文件key-value,这时一个key对应的是集合value,这些文件会缓存在该worker程序的内存中,尽量减少网络传输,和某些程序故障时,数据丢失。
5:缓存的中间文件key-value被分成R个区域,然后写入到本地磁盘上,他们的存储位置会被传回master,master将存储位置传给reduce。
6:当reduce接收到这些位置时,使用RPC从map worker所在的位置上读取这些中间文件作为输入文件,同时reduce需要对key进行排序。
7:reduce的worker程序遍历这些输入文件,传给reduce函数,并输出所需要的文件。
8:所有map,reduce任务完成,master唤醒用户程序,这个时候对Mapreduce的调用才会返回。
这时候虽然完成了,一般还有R个输出文件吧,它们其实也可以作为其他的分布式输入文件,在进行mapreduce的。
其实吧,在map过程中,都还有一定的优化过程:
~会有一个排序的过程
~会将同样的key配到一起,一般情况下是
~还有个过程就是常说的combine过程,实质就是一个本地reduce,将整合的KeyValue值reduce,比如上面的变成了
上面的我都只是以wordcount为例。
但是这真的知识个大概过程,具体的需求要设计对应的程序,刚刚也说了,mapreduce只是个编程模型而已,并没有明确怎么做。另外还有一些容错机制,mapreduce技巧,性能等各方面的原因都要考虑,其中很多东西非常复杂。
在看lab1的代码时,我们还是先看看rpc吧。

这是我写的一个简单的rpc目录结构。
ser_file:服务注册文件
在这里插入代码片package math
import "errors"
type Args struct{
A,B float32
}
type Result struct {
Value float32
}
type CountService struct{
fe float32
}
func (s *CountService) add(args *Args,result Result) error{
result.Value=args.A+args.B
return nil
}
func (s *CountService) Divide(args *Args, result *Result) error {
if args.B == 0 {
return errors.New("除数不能为零!")
}
result.Value = args.A / args.B
return nil
}
service:服务端文件
package serve
import (
"fmt"
"net"
"net/rpc"
"../math"
)
func main(){
var ms=new (math.CountService)//实例化服务对象
rpc.Register(ms)//注册服务
fmt.Print("服务启动了")
var address,_=net.ResolveTCPAddr("tcp","127.0.0.1:8000")
listener,err:=net.ListenTCP("tcp",address)
if err!=nil{
fmt.Print("start error!")
}
for{
conn,err:=listener.Accept()
if err!=nil{
continue
}
fmt.Print("accept a ")
rpc.ServeConn(conn)//让这个rpc绑定这个tcp链接上
}
}
客户端调用文件:
package clients
import (
“fmt”
“net/rpc”
)
func main(){
var clien,err=rpc.Dial("tcp",127,0,0,1:8000)//链接服务器
if err!=nil{
fmt.Print("连接失败")
}
var args=Args{40,3}
var result=Result{}
fmt.Print("sstart")
err=clien.Call("CountService.Add",args,&result)
if err!=nil{
fmt.Print("error",err)
}
fmt.Print("error")
}
这里需要注意:**定义的服务文件里面,方法一定要严格按照
func (t T) MethodName(argType T1, replyType T2) error
的样式写,t一般没有多大用处,argType是传进来的参数,replyType是传进来的参数地址,学c的话也知道,它可以寻找该地址并修改里面的值,从而达到一种传回给原函数的效果,就像一个返回值一样。
我这里是在自己机器上调用,所以地址端口都是自己的,大家可以用不同的机器去用,只要客户端和服务端对应的端口相对应就行。但是我一直没搞清楚,有时候需要关闭防火墙。
这就是一个简单的远程rpc调用了。
现在正是来看lab1。
我们先来看
master
package mapreduce
//
// Please do not modify this file.
//
import (
"fmt"
"net"
"sync"
)
//这个结构体主要是记录master需要的实时信息
type Master struct {
sync.Mutex//
address string//master地址
doneChannel chan bool//信道,用来通信
// 被mutex保护着
newCond *sync.Cond // 注册worker的信号
workers []string // 每个worker的地址
jobName string // 作业名称1
files []string // 输入文件名称切片
nReduce int // reduce任务数量
shutdown chan struct{}//关闭服务的信道结构体
l net.Listener//监听
stats []int
}
//这个Register是供给woerker注册的,此时只是将worker的地址传过来,加入到workers的切片中,一定要和启动rpc的Register区别
func (mr *Master) Register(args *RegisterArgs, _ *struct{}) error {//提供给worker注册链接
mr.Lock()
defer mr.Unlock()
debug("Register: worker %s\n", args.Worker)
mr.workers = append(mr.workers, args.Worker)
// tell forwardRegistrations() that there's a new workers[] entry.
mr.newCond.Broadcast()
return nil
}
// 这个newMaster无非就是实例化一个master,并初始化它的信息
func newMaster(master string) (mr *Master) {
mr = new(Master)
mr.address = master
mr.shutdown = make(chan struct{})
mr.newCond = sync.NewCond(mr)
mr.doneChannel = make(chan bool)
return
}
//顺序执行任务,不用分发任务,这个是顺序执行的,与分布式想区别
func Sequential(jobName string, files []string, nreduce int,
mapF func(string, string) []KeyValue,
reduceF func(string, []string) string,
) (mr *Master) {
mr = newMaster("master")
go mr.run(jobName, files, nreduce, func(phase jobPhase) {
switch phase {
case mapPhase:
for i, f := range mr.files {
doMap(mr.jobName, i, f, mr.nReduce, mapF)
}
case reducePhase:
for i := 0; i < mr.nReduce; i++ {
doReduce(mr.jobName, i, mergeName(mr.jobName, i), len(mr.files), reduceF)
}
}
}, func() {
mr.stats = []int{len(files) + nreduce}
})
return
}
//这个forwardRegistrations方法就是当从分布式里面传过来的,主要是把新的worker实时告诉schedule(分发tasks),以便schedule实时的分发任务
func (mr *Master) forwardRegistrations(ch chan string) {//刷新worker,传给分发任务的schedule.go
i := 0
for {
mr.Lock()
if len(mr.workers) > i {
// there's a worker that we haven't told schedule() about.
w := mr.workers[i]
go func() { ch <- w }() // send without holding the lock.
i = i + 1
} else {
// wait for Register() to add an entry to workers[]
// in response to an RPC from a new worker.
mr.newCond.Wait()
}
mr.Unlock()
}
}
**//分布式任务,这个就与之前的Sequential方法相区别了,分布式的分发执行tasks**
func Distributed(jobName string, files []string, nreduce int, master string) (mr *Master) {
mr = newMaster(master)//为一个master初始化
mr.startRPCServer()//启动master一个RPC服务器,等待worker
go mr.run(jobName, files, nreduce,
func(phase jobPhase) {
ch := make(chan string)//提供给forwardRegistrations一个通信ch,同时也给了schedule.go,互相通知当前所有worker
go mr.forwardRegistrations(ch)//为master增加一个worker,并通知给schedule
schedule(mr.jobName, mr.files, mr.nReduce, phase, ch)//执行分发任务
},
func() {
mr.stats = mr.killWorkers()
mr.stopRPCServer()
})
return
}
func (mr *Master) run(jobName string, files []string, nreduce int,
schedule func(phase jobPhase),
finish func(),
) {
mr.jobName = jobName
mr.files = files
mr.nReduce = nreduce
fmt.Printf("%s: Starting Map/Reduce task %s\n", mr.address, mr.jobName)
schedule(mapPhase)//这两个schedule不是直接的schedule.go里面的schedule,而是自己传进来的函数参数,真正的用法在func Distributed
schedule(reducePhase)
finish()
mr.merge()//综合reduce输出
fmt.Printf("%s: Map/Reduce task completed\n", mr.address)
mr.doneChannel <- true
}
// Wait blocks until the currently scheduled work has completed.
// This happens when all tasks have scheduled and completed, the final output
// have been computed, and all workers have been shut down.
func (mr *Master) Wait() {
<-mr.doneChannel
}
//当所有的分发任务完成后,执行这个方法
func (mr *Master) killWorkers() []int {
mr.Lock()
defer mr.Unlock()
ntasks := make([]int, 0, len(mr.workers))
for _, w := range mr.workers {
debug("Master: shutdown worker %s\n", w)
var reply ShutdownReply
ok := call(w, "Worker.Shutdown", new(struct{}), &reply)
if ok == false {
fmt.Printf("Master: RPC %s shutdown error\n", w)
} else {
ntasks = append(ntasks, reply.Ntasks)
}
}
return ntasks
}
这个就是master,是主要的mapreduce开始的地方,我也是根据mapreduce原理从这里读起来的。其中包括的common_rpc.go我就不列举了,到时候我传到github上面看详细的,或者大家自己去下源码也可以。
下面来看看schedule怎么工作的,这也是part3我们需要完成的
schedule
package mapreduce
import (
"fmt"
"sync"
)
func schedule(jobName string, mapFiles []string, nReduce int, phase jobPhase, registerChan chan string) {//我写这里的时候已经把这个需要的参数传进来了
//jobName:是当前工作的名字
//mapFiles:传入文件的切片
//nReduce:reduce的数量
//phase:工作类型,判断是map任务还是reduce任务
//registerChan:信道,与master分布式的forward啥的实时通信有多少worker
var ntasks int//任务数量
var n_other int //如果phase是map,那就记录reduce数量,反过来一样
switch phase {//如下实现
case mapPhase:
ntasks = len(mapFiles)
n_other = nReduce
case reducePhase:
ntasks = nReduce
n_other = len(mapFiles)
}
fmt.Printf("Schedule: %v %v tasks (%d I/Os)\n", ntasks, phase, n_other)
taskArgsList :=make([]DoTaskArgs, ntasks)//先创建一个任务切片,这个DoTaskArgs是common_rpc.go里面的,包含了任务各种信息的结构体
for i:=0;i以上就是master到schudule分发任务过程。
common_map.go
package mapreduce
import (
"encoding/json"
"io/ioutil"
"log"
"os"
"hash/fnv"
)
func doMap(
jobName string, // the name of the MapReduce job
mapTask int, // which map task this is
inFile string,
nReduce int, // the number of reduce task that will be run ("R" in the paper)
mapF func(filename string, contents string) []KeyValue,
) {
dat,errinput:=ioutil.ReadFile(inFile)//返回的dat是一字节数组[]byte
if errinput !=nil{//读取不成功,errinput如果返回nil则是读取成功
log.Fatal(errinput)
}
outFiles:=make([]*os.File,nReduce)//创建输出中间文件切片,最大容量为nReduce
encoders:=make([]*json.Encoder,nReduce)
for i:=range outFiles{
var erroutput error
filename:=reduceName(jobName,mapTask,i)//设置中间输出文件的filename=jobname+mapTaskNumber+nReduce_number
outFiles[i],erroutput = os.Create(filename)//创建文件
if erroutput!=nil{//如果创建成功返回nil,否则返回错误
log.Fatal(erroutput)
}
encoders[i]=json.NewEncoder(outFiles[i])//转换数据格式
}
mapRes:=mapF(inFile,string(dat))//在test_test.go中的函数,返回的是dat文件分割单词后的键值对
for _,kv:=range mapRes{//遍历keyvalue键值对,由kv接收
index:=int(ihash(kv.Key))%nReduce
encoders[index].Encode(&kv)
}
for _,file:=range outFiles{
file.Close()
}
}
func ihash(s string) int {
h := fnv.New32a()
h.Write([]byte(s))
return int(h.Sum32() & 0x7fffffff)
}
common_reduce.go
package mapreduce
import (
"encoding/json"
"fmt"
"log"
"os"
"sort"
)
func doReduce(
jobName string, // the name of the whole MapReduce job
reduceTask int, // which reduce task this is
outFile string, // write the output here
nMap int, // the number of map tasks that were run ("M" in the paper)
reduceF func(key string, values []string) string,
) {
KeyValues:=make(map[string][]string)
i:=0
for i以上就是我在MIT lab1中实现的主要部分,通过这个过程,总算了解了mapreduce基本原理,当然因为初学go的关系,很多东西不了解,所以需要自己独立写一个mapreduce的框架还是有难度的。
但是,这么久了,才弄出来一个这样的东西,真是很菜。。。
不过这个过程我真的觉得对大数据,分布式有很兴趣