浅析Redis(1)
一.Redis的含义
Redis可以用来作数据库,缓存,流引擎,消息队列。redis只有在分布式系统中才能充分的发挥作用,如果是单机程序,直接通过变量来存储数据是更优的选择。那我们知道进程之间是有隔离性的,那么redis中的数据是如何共享的呢?reids是基于网络,把自己内存中的变量给别的进程,甚至别的主机的进程使用
Mysql和redis的区别:
Mysql最大的问题在于,访问速度比较慢,redis是把数据存储在内存当中的,访问速度比较快,但是redis的劣势是:内存空间有限.
二.单机架构和分布式
单机架构:
只有一台服务器,负责所有的工作

服务器处理客户端的请求,是要消耗资源的
按理来说:现在计算机硬件,发展速度很快,但是一台主机上的性能是有限的,一台主机也可以支持非常高的并发但是如果业务持续增长,一台主机难以应付,就需要引入更多的主机,引入更多的硬件资源,
应用数据分离架构
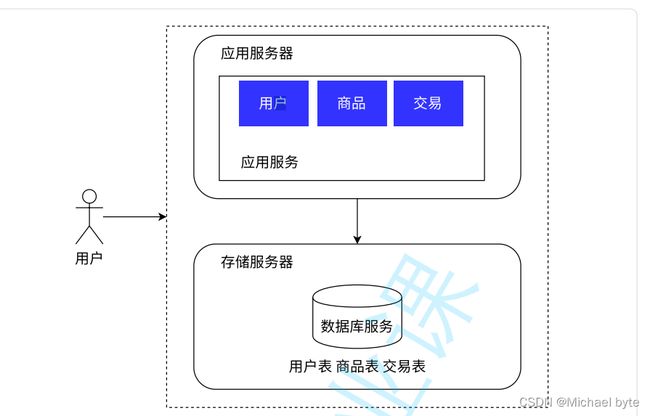
引入更多的服务器节点:
\
负载均衡:用户请求合理的分配到每个服务器
例如有2w个请求,,每个应用服务器平均分摊1w个请求。
如果说我们的请求数量如果继续增多,我们的负载均衡器也会承担不了,那么我们会引入更多的负载均衡器。
增加应用服务器,能够处理更多的请求数量,但是随之存储服务器,要承担的请求数量也就更多了。
数据库提高处理请求的能力的方式
1.读写分离
我们知道数据库的操作,读操作会比较频繁,而写和修改操作相对比较小一些。我们用一个主数据库负责数据的查询操作,而从数据库负责写操作。
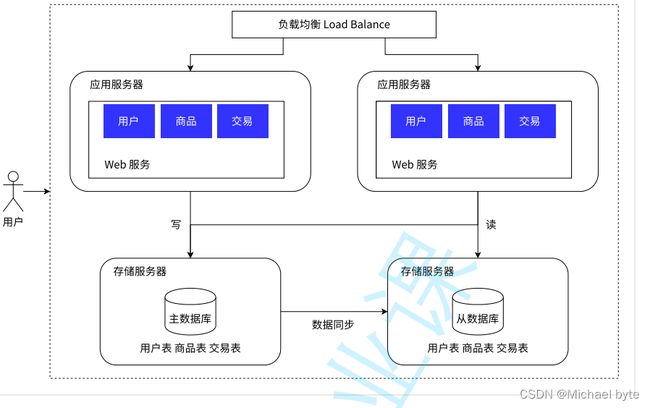
2.引入缓存
我们将一些经常访问的数据放入缓存中,读取缓存中的数据的速度要远远大于读取硬盘中数据的速度。

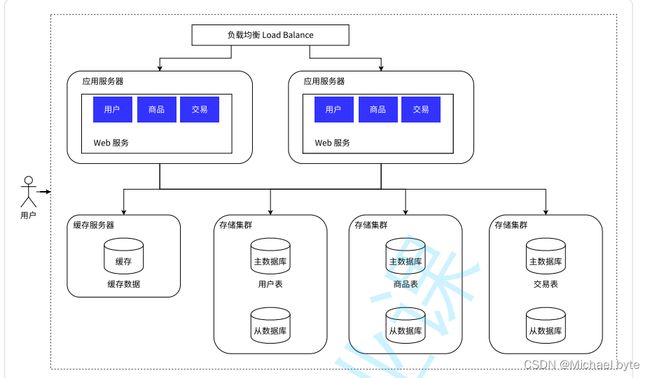
针对数据库进一步拆分,分库分表,本来一个数据库服务器,每个数据库服务器存储一个或者一部分数据库,如果某个表特别大,大到一台主机存不上,也可以针对表进行拆分。
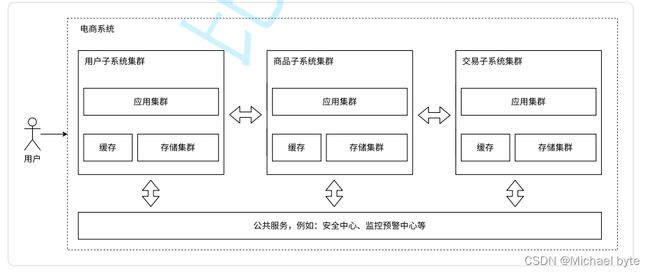
微服务数据架构:
一个应用服务器,一个服务器有很多业务,方便于代码的维护,把这样一个复杂的服务器,拆分成更多的,功能更单一,但是更小的服务器(微服务),引入微服务,根本原因是解决人的问题,当应用服务器更复杂,势必需要更多的人来维护,人一多,就不好管理,需要划分组织结构,分成多个组,进行分工。
引入微服务缺点:(1)系统的性能下降
(2)系统复杂度程度提高,可用性收到影响
微服务的优势:(1)解决了人的问题
(2)使用微服务,方便于功能的复用
(3)可以给不同的服务进行不同的部署
分布式系统小结:
1.单机架构(应用程序+数据库服务器)在一台服务器上
2.数据库和应用分离
应用程序和数据库服务器,分别放在不同主机上部署
3.引入负载均衡:应用服务器->集群
通过负载均衡器,把请求均匀发布在集群中的每个应用服务器
4.引入读写分离,数据库主从结构
一个数据库结点作为主节点,其他N个数据库节点作为从节点,主节点负责写数据,从节点负责读数据。
5.引入缓存,冷热数据分离
进一步的提升了服务器针对请求的处理能力
6.引入分库分表
数据库能进一步扩展存储能力
7.引入微服务
从业务进一步拆分应用服务器,从业务功能的角度,把应用服务器,拆分成更多的功能单一,简单,更小的服务器。
三.Redis特性:
Redis是一个内存中存储数据的中间件,用于作为数据库,用于作为数据库缓存,在分布式系统中起到重要的作用,它有一些特性:
(1)在内存中存储数据
(2)Redis可以通过简单的交互命令进行操作,也可以通过一些脚本的方式,批量执行一些操作
(3)Redis在原有的功能基础上再进行拓展,Redis提供了一组API,通过redis支持更多的数据结构以及支持更多的命令。
(4)Redis把数据存储在内存中,内存中的数据易失的,Redis也会把数据存储在硬盘上,相当于在内存中的数据备份了一部分)Redis重启了,会在重启的时候加载硬盘中的数据,使Redis中的内存恢复到重启前的状态。
(5)Redis作为一个分布式系统中的中间件,能够支持集群,一个Redis能够存储的数据是有限的,引入多个多个主机,部署多个Redis节点,每个Redis存储数据的一部分
(6)Redis支持主从结构,从节点相当于主节点的备份,一旦主节点挂了,从结点会变成主节点
为啥Redis快?
1.Redis数据在内存中,要比存储在硬盘中,要快很多
2.Redis核心功能都是比较简单的操作内存的数据结构
3.Redis使用了IO多路复用的方式
4.Redis使用的是单线程方式,减少了不必要的竞争的开销
另外谈到redis的快,只是和mysql相比,如果和内存中的操作变量相比,就没有优势了,甚至更慢
比如应用程序要存储购物的一些信息,那么用hashmap来存,要比用redis来存,要更加快速,但是用hashmap来存,如果服务器一旦重启,数据就会丢失。因此到底用那种场景来存,要看具体的应用场景。
四.Redis的应用
1.redis作为数据库,相较于Mysql,redis查询数据的速度更快
2.redis作为缓存,把热点数据存储在redis中
3.redis作为消息队列。对于分布式系统来说,服务器和消费者之间有时也是需要使用到消费者和生产者模型的。
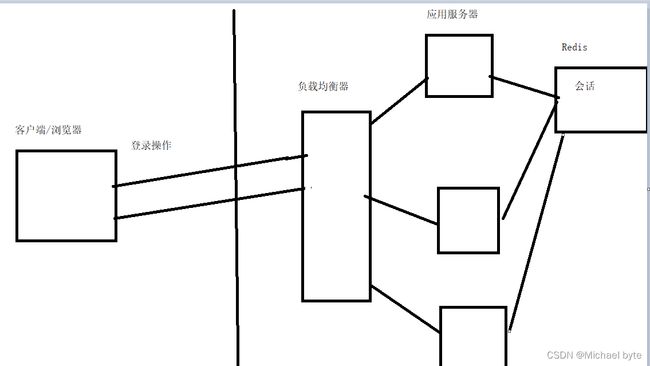
4.redis作为会话

想象这样一个场景,一个用户登录我们的服务器,服务这里随机产生了一个session,并将用户信息存储到了服务器上,但当用户再次去访问的时候,可能会访问另外一个服务器,因为另外一个服务器没有用户信息,这时候就需要重新登录了,那如何解决这个问题吗?
(1)设计特定的算法,让负载均衡器,把同一个用户的请求,始终打到同一个服务器上
(2)把会话数据单独放在一台机器上存储
下面是第二种方法图:
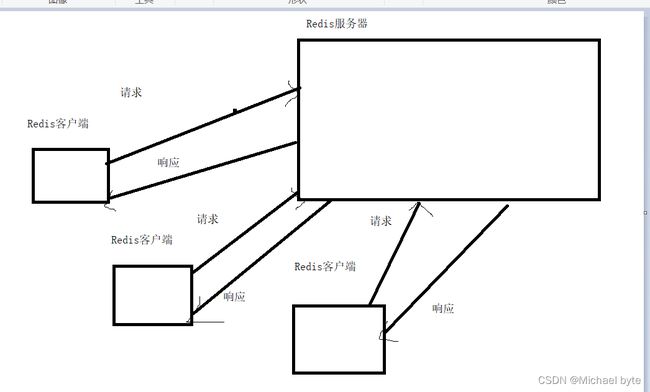
Redis客户端
Redis是一个客户端-服务器结构的程序
Redis客户端的形态
(1)自带的命令行客户端
![]()
(2)图形化界面客户端
五.Redis中的常用命令(redis是按照键值对的方式进行存储的)
1.set key value 把 key 和value存储进去
2.get 根据key来获取value,如果key不存在会返回nil
3.keys的模糊匹配
(1)?匹配任意一个字符
keys h?llo

(2)*匹配0个或者多个字符

(3)[....,....,....,]匹配某些指定的字符
[a,b]只能匹配到a,b,在此场景下,所有的key第二个字母必须是a,b

(4)[.....-....]匹配某个范围内的字符
[a-c]表示所有的只能匹配a-c这个范围内的字符,包含两侧边界

(5)[^.....]排除某些字符

另外要注意keys的命令时间复杂度是o(n),所以,在生产环境上,一般都会禁止使用keys命令,尤其是keys*,生产环境上的key可能会非常多,redis是一个单线程服务器,如果执行keys*时间非常长,就使redis服务器被阻塞了,无法给其他客户端提供服务
4.exists[key1,key2.....]判定key是否存在
返回值:key的个数,时间复杂度o1
![]()
5.del[key1,key2,.....]删除一个或多个key

6.expire作用给key设置过期时间
设置的时间单位是秒
pexpire 设置的时间单位是毫秒
给存在的key设置,会返回1,表示设置成功,给不存在的key设置,会返回0,表示设置失败
key存活的时间超出指定的过期时间,就会被自动删除,很多业务场景,是有时间限制的,例如手机验证码,5分钟内有效,点外卖,优惠券,在指定的时间内有效。还有基于redis的分布式锁,为了避免不能正确解锁的情况,通常都会在加锁的时候设置一下过期时间
![]()
7.ttl查看key的过期时间还剩多少

8.type 返回key的类型
9.incr 针对value+1
![]()
incrby 针对value+n
![]()
decr 针对value-1
![]()
decrby 针对value-n
![]()
incrbyfloat 针对value+/-小数
![]()
10.append追加字符
![]()


这里注意当value值为中文时,我们通过getkey方式得到的不是中文,如果 想要得到中文,我们可
以在连接客户端的时候通过redis-cli --raw设置一下
![]()
11.getrange key start end 得到指定范围内的value,注意区间是前闭后闭。
如果end是负数,则表示倒数的概念,如-1,表示倒数第1个
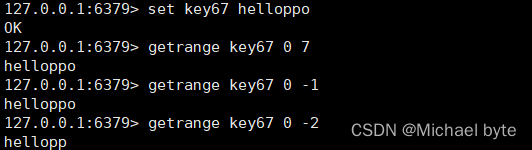
12.setrange key offset(偏移量) value从第几个字节开始替换

13.strlen 获取到字符串的长度,单位是字节

六.Redis中的过期策略
一个Redis中可能同时存在很多key,这些key中会存在一些过期的,那这些过期的key是如何进行处理的呢?
1.定期删除:每隔一段时间,每次抽取一部分,去验证它的过期时间
2.惰性删除:当去访问到key的时候,如果key已经过期了,对其进行删除操作
七.Redis的数据类型
Redis支持10个数据类型,其中String,List,Set,Hash,Sorted set,是常用的几种数据类型
上述常见的几种数据类型,其底层的数据结构,并不一定是我们看到的表面那样
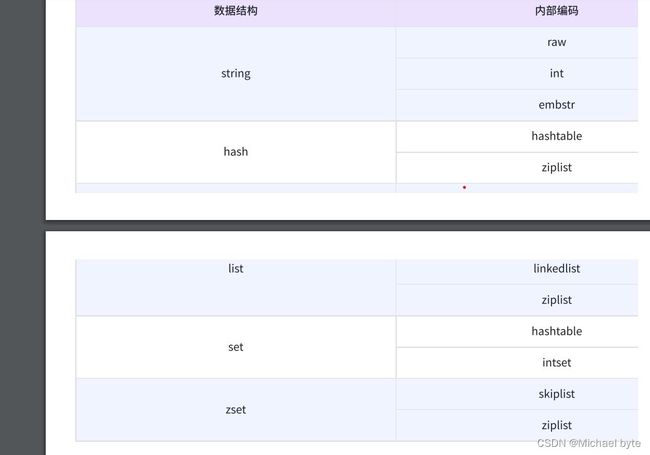
Redis底层在实现上述数据结构的时候,会进行特定的优化,来达到节省空间/时间的效果。
object encoding key 查看key对应的value的实际编码方式
Redis单线程模型:
(1)Redis只使用一个线程,处理所有的命令请求,这并不意味着一个redis服务器内部只有一个线程,其实也有多个线程在处理网络IO,一个线程在处理命令请求。
(2)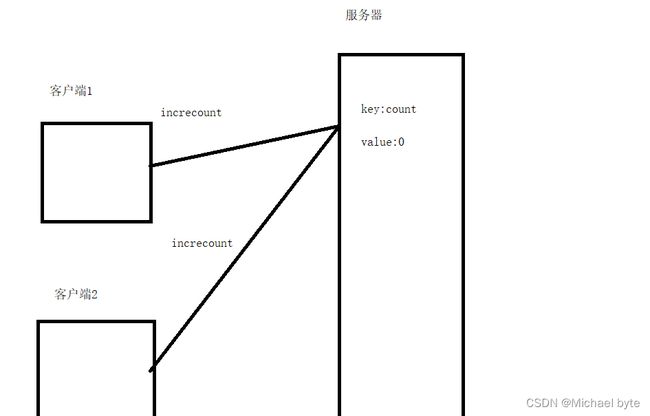
当两个客户端发送要对count++请求的时候,我们明白在多线程情况下,会出现线程安全问题,但是redis我们知道它是单线程来处理命令请求的,也就是说多个请求同时到达redis服务器,也是要现在队列中排队,再等待Redis服务器一个一个取出里面的命令再执行,redis服务器都是串行/顺序执行这些命令的。弊端:redis必须要小心,某个操作占用时间较长,会阻塞其他命令的执行。
Redis是单线程模型,为啥效率高?
1.redis直接从内存中读取数据,数据库则是从硬盘中读取数据
2.redis核心功能比数据库核心功能更简单,数据库对于数据的插入和删除查询,都有复杂的功能支持,也就导致了更多的开销,比如针对插入和删除,会存在外键、unique等限制。
3.单线程模型:避免了不必要的线程竞争开销
4.处理网络IO的时候,使用了epoll这样的IO多路复用机制。很多情况下,客户端和服务器交互不是很频繁,我们可以让一个线程处理多个客户端的请求。
String类型:
String类型内部编码方式
1.int 用来表示较小的整数
2.embstrbbb 压缩字符串,用来表示比较短的字符串
3.raw 普通字符串,用于表示较长的字符串
object encoding key 查看编码方式
![]()
![]()


String类型的应用:
(1)redis作为缓存
(2)用于计数系统
(3)Session会话
Hash类型
redis本身已经是一个键值对了,value又是一个键值对
常用命令:
1.hset(设置多个键值对)
hset key filed value filed value.....
![]()
2.hexists key field 判断filed是否存在
![]()
3.hdel key field1,field2,field3 删除多个field
![]()
4.hkeys key 获取多个field

5.hvald key 获取所有的value

6.hgetall key 获取所有的field value

7.hmget相较于hget能同时获取多个field

8.hsetnx key field value 只有field存在时才能设置成功
9.hincrby key field n
10.hincrbyfloat key field n 加减小数

11.hlen key获取value的个数
![]()
12.hstrlen key field获取某个field的value大小,单位是字节
![]()
13.hget key field获取某个filed的value值
![]()
Hash内部的编码方式:
(1)ziplist压缩列表,可以节省内存空间,压缩的本质是针对数据进行重新编码,重新编码之后,就会缩小体积,但是ziplist进行读写速度比较慢,因此只适应元素个数比较少的一些情况
(2)hashtable
适用场景:(1)如果哈希表中的元素个数比较少,使用ziplist表示,元素个数比较多,使用hashtable来表示
(2)每个value的值长度都比较短,使用ziplist表示,如果value值长度太大,也会转换成hashtable.
Hash类型的应用:
(1)作为缓存:
String类型也是可以作为缓存使用的,但是要存储结构化的数据,使用hash类型会更方便

像上面这个例子:如果使用String(json)的格式来表示student,如果想修改某个field,需要把json读取出来,解析成对象,修改field,再重写成json字符串,再写回去,如果使用hash的方式来表示student,就可以使用field表示对象的每个属性(数据表的每个列)此时也就更加的方便修改/获取某个属性的值了,使用hash的方式,读写field更直观高效,但是也浪费了空间,需要控制hash在ziplist和hashtable两种内部编码的转换,会造成内存的巨大消耗。