什么是tensorflow
什么是tensorflow
tenroflow是Google开源软件库,为机器学习工程中的问题提供了一整套解决方案。类比于Spark/Flink是大数据工程问题的解决方案。
该软件库把机器学习中的通用功能封装成了库,并提供了简易的API,使得在构建机器学习系统时不再需要做那些纷繁复杂的数学、工程工作,能把主要精力放在模型和业务上。这就像现在使用编程语言进行编程时,不再需要知道计算机硬件的细节,不用知道CPU的指令集。从这个意义上说,tensorflow让机器学习工程从汇编语言时代,上升到了高级语言时代。使得机器学习这种曾经只存在于实验室由高级专业人才能把玩的高端技术变成了幼儿园小朋友手里的玩具。
什么是机器学习?
机器学习工程中又遇到了哪些问题?机器学习是实现人工智能的一种方式。什么是人工智能?什么是智能?
什么是智能?
目前还没有统一的定义。但是可以肯定的是人具有最高的智能。其他生命也有不同程度的智能。一只猫,一只蚂蚁,一只蚊子我们都认为它们有不同程度的智能。人工智能是人能制造出一种机器,这个机器能像生命智能一样工作。如可以听说读写,可以走路开车,可以辨认图片。就拿辨认图片来说,如辨认图片中的动物是不是一只猫。这个过程可以简化为三步, 看图片,大脑进行思考判断,回答是或者否。这个过程被抽象为一个数据的函数$y=f_w(x)$。x是输入的图片,y是判断的结果(是、否), f是大脑思考,w是大脑中的一些状态。所以智能就是这里的f和w。如何得到f和w就是人工智能中最重要的问题。计算机的发展给人工智能带来希望。f可以是运行在计算机上的程序,w是这个程序的参数。x,y是程序的输入和输出,由于需要计算机处理,所以x,y必须数字化。
- 传统人工智能:人为编写规则构成f
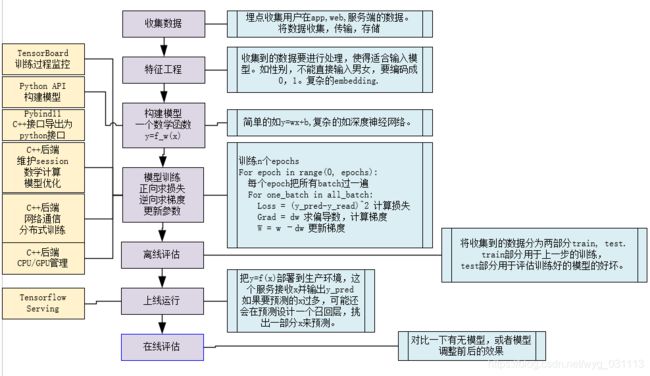
最明显的就是游戏中AI的实现。由人工编写了复杂的规则,如当敌人距离自己w1米时该干什么,当自己的血量 通用的 f 被发现在:记得傅里叶变换吗?记得小波分析吗?从最简单函数无限叠加来近似一个函数。神经网络就是这样一个通用的 f (实际上需要人为构建层数,每层神经元数,各种卷积,循环神经网络就是这么构造出来的) 如果我们有大量的x,y,还有自己构建的 f 能否由机器自己学习出w? 机器学习就是建立在这种指导思想之上。首先我们构建一个函数f, 他的参数是w. y_pred=f_w(x) y_real是真实值。 loss=(y_pred-y_real)^2。loss, f_w都是人为构建的。比如loss,我们想用它表示真实值和预测值之间的差距,刚好方差能满足我们的需求,当然也有其他函数能满足,人为挑选即可。 同样,f_w也是我们人为挑选的函数,参数w初始值可以是随机值。 只要loss可导,那么我们就可以用梯度下降法来调整参数w去逼近loss的最小值。至于为什么要用梯度下降法也是人为选择的。在这里数学是我们的工具箱。我们要找到一个函数能与现实相符合。 如今不需要你懂高深的物理数学知识,只要能构建神经网络,有数据,就能训练出模型。这让懂程序懂神经网络的人能对其他行业进行降维打击。因为不需要人去学习那些专业性很强的知识,让机器去学习,学出来还比专业人员还厉害。甚至能训练出通用人工智能,可能在各个方面超过人,特殊专业又比人强。 收集用户的数据,如用户点击,评论,浏览的内容,用户的性别年龄等等。又如图像识别中要收集大量的图片。 数据收集部分收集的数据可能不能直接输入模型,需要一定的处理,对于类别特征,如性别,爱好等等,需要以数字编码,对于数值特征 ,如年龄,收入,可以直接用,但是 这是一个寻找一个适合的函数的过程,简单如y=wx+b, 复杂如深度神经网络。深度神经网络有个特点,能表示任意函数,它也能表示y=kx+b.所以自从深度神经网络出现后人们就不用再费尽心机构造合适的数学模型了。想想曾经的天气预报模型,人为构建无数个偏微分方程,还得懂各种大气,流体等物理学知识。而现在,一个万金油深度神经网络加大数据加持就能搞。成为大数据,败也大数据。没有大数据,显然没法用神经网络了。 既然f_w已经确定,剩下的就是要编程实现整个训练过程了,无非是一些数学计算,涉及矩阵运算,微分计算,损失函数计算,梯度计算,参数更新。只要我们一一实现即可。 特征工程中的数据要成训练集train和测试集test. 训练过程只使用train,训练完成后在test上计算loss,正确率等等指标评估模型,当然评估方式还有很多。 将训练好的模型部署成服务端集群,等待线上求参入参数x,计算出y_pred返回。 使用A/B测试等等再线评估方法对模型进行评估。然后再回头去调优模型。 以上就是机器学习在工程应用中需要做的事儿,当然可以不使用任何框架,从0开始编程实现,从一个矩阵计算,向量乘法来实现,如果这么做,那么工程量浩大。经过多年的发展,这些通用的基本功能已经被前人封装成可以重用的库。我们不需要从0开始。 tensorflow就是为解决上述问题而实现的一整套库。
如果我们有两条数据(x1,y1),(x2,y2), loss = (y_pred1-y_real1)^2 + (y_pred2-y_real2)^2。 如果有n条数据,n特别大,如有几个亿,那么loss函数将十分巨大,计算还是求导都十分困难。因此,把n条数据分为大小为m的batch, 每个batch有m条数据,共batch_num = n/m个batch。 每次求导,更新参数,只用一个batch,这样计算量会小很多。 同时把所有batch过一遍称为一个epoch, 经过几个epoch,loss可能不再减小,稳定到一个固定值附近,这种情况就叫模型已经收敛。训练结束。 训练结束后,需要对模型进行评估,这就需要在训练前,把一部分数据拿出来,不参与训练,此时就可以在这部分拿出来的数据上用模型进行预测,并计算loss, 或者预测准确率,就能知道模型的效果。当然,这只是简单的模型离线评估,离线评估有很多其他方法。除此之外,模型上线后还可以进行如A/B测试这样的线上评估。 后边就是如此往复,改进模型,训练,评估。
机器学习中的工程问题
在一个基于机器学习的系统中有很多工程工作需要做。主要是为了服务于y=f_w(x), loss=(y_pred-y_real)^2这两个函数。首先得有大量的(x,y),其次要构建一个合适的f和loss。
最后还要用计算机程序实现f,loss,梯度的计算和参数w的更新。 那么剩下的离线评估,上线,在线评估就水到渠成了。
一般会做归一化处理,以免数值差距较大的特征影响模型效果。经过这一步,x,y将被处理成两个向量如x=[0.1, 0, 0.234, ...] y = 0. 这样的n个(x,y)叫做训练样本,可以直接给y=f_w(x)作为输入了。
训练中把特征工程中的数据分成一个个小的batch,进行迭代,直到模型收敛,即损失Loss达到最小值。训练过程可能是个漫长的过程,我们想时刻监控当前的训练状态,如当前的loss,训练的进度等等,这还需要一套可视化的监控系统。