代码大模型神仙打架,WizardCoder发布新模型,超越最新GPT-4以外所有闭/开源模型
来源 | 机器之心
作者 | 杜伟、梓文
这几天,代码大模型领域又热闹了起来!
先是 Meta 开源代码专用大模型Code Llama,且免费商用。效果也非常好,Code Llama 在 HumanEval 和 MBPP 代码数据集上的一次生成通过率(pass@1)轻松超越 GPT-3.5,其中「Unnatural」版本的 pass@1 逼近了原始 GPT-4(OpenAI 在今年 3 月 GPT-4 技术报告中的数据)。
大模型研究测试传送门
GPT-4传送门(免墙,可直接测试,遇浏览器警告点高级/继续访问即可):
Hello, GPT4!

Code Llama 发布仅一天,来自Phind组织的研究人员用微调的 Code Llama-34B 在 HumanEval 评估中击败了 GPT-4。他们的两个模型 Phind-CodeLlama-34B-v1 以及 Phind-CodeLlama-34B-Python-v1 在 HumanEval 分别实现 67.6% 和 69.5% 的 pass@1,显然都超越了原始 GPT-4 的 67%。

不过,仅仅又过了一天,Phind 微调版 Code Llama 又迎来了一个强劲的对手。这次是 WizardLM 团队的编程专用大模型 WizardCoder。
该团队推出了基于 Code Llama 的最新版本模型 WizardCoder 34B,它利用 Evol-Instruct 进行微调而成。
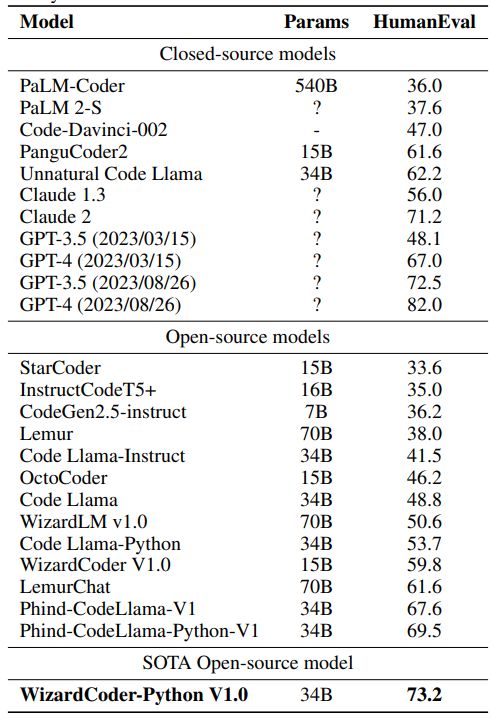
结果显示,它在 HumanEval 上的 pass@1 达到了惊人的 73.2%,超越了原始 GPT-4、ChatGPT-3.5 以及 Claude 2、Bard。此外,WizardCoder 13B 和 7B 版本也将很快到来。
此次具体版本是 WizardCoder-Python-34B-V1.0,下图是与主流闭源和开源模型的 HumanEval pass@1 比较。除了最新 API 的 GPT-4(该团队测试后得到的结果是 82.0%),该模型超越了所有闭源和开源模型,包括最新 API 的 ChatGPT(72.5%)和原始 GPT-4(67%)。
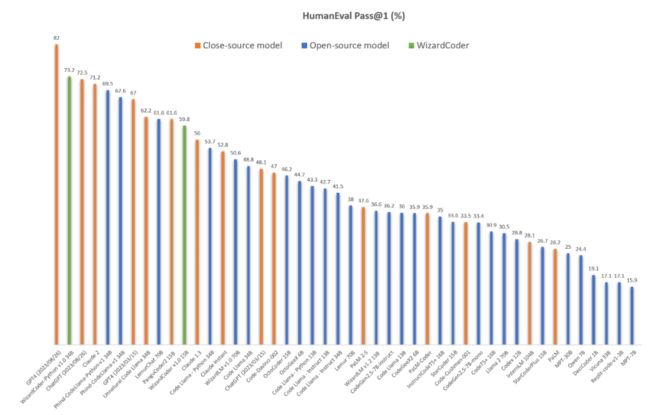
因此,WizardCoder-Python-34B-V1.0 成为了最新的 SOTA 开源代码大模型。
WizardLM 团队还表示,WizardCoder-Python-34B-V1.0 的性能百分之百是可以复现的。
![]()
想要体验 WizardCoder-Python-34B-V1.0 的小伙伴可以尝试以下 demo。
有人表示,在试了 demo 后发现,提供准确代码之前似乎有 COT(思维链)在起作用,这非常棒。
还有人表示,WizardCoder-Python-34B-V1.0 要比 GPT-4 犯的错更少。
不过运行 WizardCoder-Python-34B-V1.0 需要 32GB 以上的 mac。
WizardLM 团队会带来更多惊喜
WizardCoder 在成为代码家族一员已经不是新鲜事,但是 WizardLM 团队每次都会给大家带来不一样的惊喜。
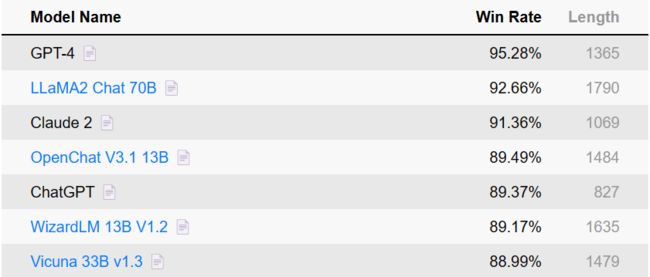
斯坦福发布的大语言模型排行榜 AlpacaEval 是一种基于 LLM 的全自动评估基准,且更加快速和可靠。很多著名的模型如 GPT-4、ChatGPT 等都在其上刷榜单。在这其中,WizardLM 13B V1.2 依旧在第六位。
WizardLM 是由 Can Xu 等人在 2023 年 4 月提出的一个能够根据复杂指令生成文本的大型语言模型。它使用了一个名为 Evol-Instruct 的算法来生成和改写指令数据,从而提高了指令的复杂度和多样性。 WizardLM 共有三个版本:7B、13B 和 30B。
WizardLM 推出的指令微调代码大模型 ——WizardCoder,更是打破了闭源模型的垄断地位,在 HumanEval 和 HumanEval + 上优于 Anthropic 的 Claude 和 Google 的 Bard。
更值得一提的是,WizardCoder 还大幅度地提升了开源模型的 SOTA 水平,创造了惊人的进步,提高了 22.3% 的性能,成为了开源领域的新晋「领头羊」。
以下为 WizardLM 团队在 GitHub 上发布的诸多模型,这些模型是该团队不断创新、改进的足迹。
WizardLM 团队在 WizardLM 与 WizardCoder 之后,还在今年八月中旬公布了 WizardMath。该团队还发推文表示,自己一直在致力于解决各个学科复杂的问题。

那么未来 WizardLM 团队还会带给我们怎样的惊喜,让我们拭目以待。
