对于论文Semi-Supervised Classification with Graph Convolutional Networks,小白的学习理解
参考笔记:论文笔记:Semi-Supervised Classification with Graph Convolutional Networks_hongbin_xu的博客-CSDN博客
论文笔记:SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS_semi supervised classification_饮冰l的博客-CSDN博客
拉普拉斯矩阵与正则化_拉普拉斯正则化_solicucu的博客-CSDN博客
图卷积网络 GCN Graph Convolutional Network(谱域GCN)的理解和详细推导_详细给出图卷积网络推导过程_不务正业的土豆的博客-CSDN博客
如果看了这篇文章你还不懂傅里叶变换,那就过来掐死我吧 - 知乎
前言
卷积神经网络:灵感来源于人类的大脑,在识别一个物体时,首先识别边缘,再识别形状,最后确定物体的类型。卷积神经网络利用大脑识别的特点,建立多层神经网络,较低层识别物体的特征,若干底层特征组成更高一层特征,最终通过多层特征组合来进行分类。
典型的卷积神经网络CNN由卷积层、池化层和全连接层组成。卷积层用来提取特征,池化层用来降维和降低过拟合,全连接层用来输出最后的结果。研究的对象通常是有规则的空间结构,比如有序的语句,对于猫狗的分类。这些特征都可以用矩阵来表示。对于具有平移不变性的图片,一个小窗口移动到任意位置都不影响内部结构,可以使用CNN来提取特征。而RNN通常用于NLP这种序列信息。但是生活中还具备很多没有规则的空间结构数据,比如分子结构等,可以认为是无限维的数据,不具有平移不变性,这些不规则的空间结构难以用固定的卷积核来表示特征。每一个节点都是独一无二的,会让CNN,RNN失效.而GCN设计了一套从图数据中提取特征的办法,本质是个特征提取器。论文(Semi-Supervised Classification with Graph Convolutional Networks)使用谱图理论,利用拉普拉斯矩阵的特征值和特征向量来研究图的性质。
半监督学习是指样本集只有部分数据含有标签 ,通过已有标签的数据推断出没有标签数据的分类。给定一个数据集,可以映射成一个图,数据集中每个数据对应一个结点,由于一个图可以对应一个矩阵,这使得我们可以基于矩阵来进行半监督学习算法的分析。但是这有两个问题,一是假设有n个样本,复杂度就是n^2,这使得如此大规模的数据很难处理。二是构图过程只能使用样本集,再加入新的样本需要对原图进行重构并重新标记。
该论文的目标是解决半监督学习的问题。本文使用神经网络f(X,A)对图结构进行编码,对带有标签的节点在监督目标上进行训练。
1 介绍
我们考虑在图中对节点进行分类的问题,其中标签只适用于一小部分节点。这个问题被定为半监督学习,其中标签信息通过某种形式基于图的显示正则化在图上平滑。例如公式(1),在损失函数中使用拉普拉斯正则化项:

 表示图中有标签的监督损失
表示图中有标签的监督损失- f(.)表示类似神经网络的可微函数
- λ 是个权重因子
- X是节点特征向量
 的矩阵
的矩阵 - A表示图的邻接矩阵
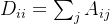 表示A的度矩阵,是个对角矩阵
表示A的度矩阵,是个对角矩阵- ∆=D-A表示无向图的非归一化图拉普拉斯算子
这有两个好处,我们为图神经网络引入了一个简单且行为良好的前向传播公式,并展示了它是如何从谱图卷积的一阶近似中被激发。其次,我们演示了这种形式的基于图的神经网络模型如何用于图中节点的半监督分类。缺点是依赖于假设:相连接的节点可能共享相同的标签。这个假设可能会限制建模的能力,因为图边不一定需要编码节点相似性,而是可能包含附加信息。
2 图上的快速近似卷积
这节考虑多层图卷积网络(GCN):
- A是图的邻接矩阵
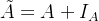 ,是A加上自环
,是A加上自环-
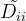 是
是 的度矩阵
的度矩阵 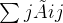 ,是一个对角矩阵
,是一个对角矩阵  是用于特定层可训练的权重矩阵
是用于特定层可训练的权重矩阵- σ(.)是激活函数,例如ReLU(.)=max(0,.)
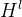 ∈
∈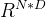 是l层的激活矩阵可以认为是第l-1层的输出,且
是l层的激活矩阵可以认为是第l-1层的输出,且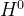 =X
=X
下面将证明这种前向传播形式可以通过图上的局部谱滤波器的一阶近似来激发。
2.1 谱图卷积
我们考虑图上的谱卷积。对于一个输入信号x∈![]() ,在傅里叶领域中取参数θ∈
,在傅里叶领域中取参数θ∈![]() ,设置一个过滤器
,设置一个过滤器![]()
![]()
- U是图的标准化拉普拉斯的特征向量矩阵
- 拉普拉斯矩阵:
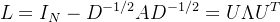
- Λ特征值是对角矩阵,
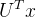 就是图上的傅里叶变换
就是图上的傅里叶变换 - 可以将
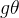 理解成为L的特征值函数,即
理解成为L的特征值函数,即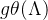
计算公式(3)成本很昂贵,复杂度是O( ),此外,计算L的特征分解代价很高。为了避免这个问题,
),此外,计算L的特征分解代价很高。为了避免这个问题,![]() 可以使用切比雪夫多项式
可以使用切比雪夫多项式![]() 的截断展开式很好的近似到k阶。
的截断展开式很好的近似到k阶。

-
 ,
,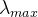 代表拉普拉斯矩阵L最大的特征值
代表拉普拉斯矩阵L最大的特征值 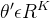 是一个切比雪夫系数
是一个切比雪夫系数- 切比雪夫多项式定义:
回到信号x和滤波器![]() 卷积的定义,可得:
卷积的定义,可得:
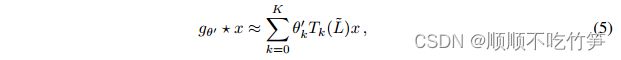
-

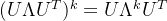
- k是拉普拉斯函数的k阶多项式,它只依赖于距离中心点步长最大为k步的节点
2.2 分层线性模型
可以通过叠加公式(5)来构建基于图卷积的神经网络。当K=1,即为拉普拉斯L上的线性函数。论文提到,通过这种形式的GCN,可以缓解具有非常宽节点度分布的图的局部邻域结构的过拟合问题。可以通过堆叠多个这样的层来提取特征。
在GCN的这个线性公式(K=1)中,进一步假设![]() .可以预测到神经网络参数能在训练过程中适应这种变化。在这些近似下,公式(5)化简为:
.可以预测到神经网络参数能在训练过程中适应这种变化。在这些近似下,公式(5)化简为:

证明过程:
拉普拉斯矩阵L=D(度矩阵)-A(邻接矩阵)
拉普拉斯矩阵正则化证明:![]()
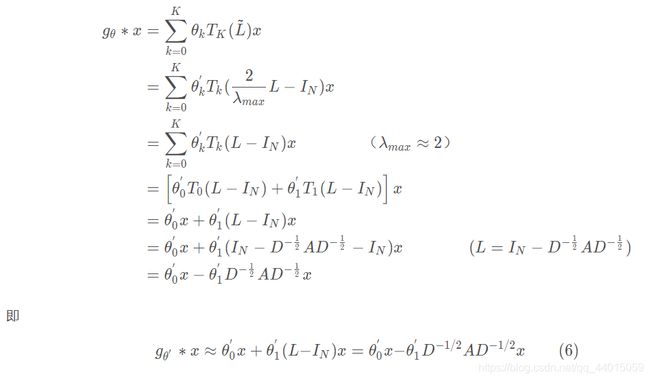
- 这里有两个过滤器参数
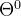 和
和 ,可以在整个图上共享。
,可以在整个图上共享。 - k是卷积层的数量
- 进一步限制参数的数量有助于减少过拟合

此时![]() 特征值范围是[0,2],当神经网络使用该公式可能造成数值不稳定和梯度爆炸/消失。为了解决这个问题,引入了以下归一化技巧。
特征值范围是[0,2],当神经网络使用该公式可能造成数值不稳定和梯度爆炸/消失。为了解决这个问题,引入了以下归一化技巧。
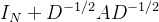 ->
->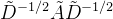 (即加上图中自环)
(即加上图中自环)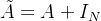
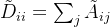
在加上激活函数σ(.),可以得到![]() ,也就是公式2.
,也就是公式2.
可以将这个定义推广到信号![]() ,它有C个输入通道(即每个节点有一个C维特征向量)和F和滤波器或特征映射,如下图所示
,它有C个输入通道(即每个节点有一个C维特征向量)和F和滤波器或特征映射,如下图所示
![]()
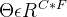 是滤波器参数矩阵
是滤波器参数矩阵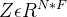 是卷积后输出的信号矩阵
是卷积后输出的信号矩阵
3 半监督节点分类
前面介绍了在图上有效的传播信息的模型f(X,A),现在回到半监督节点分类问题。通过调节模型f(.)使得在邻接矩阵包含了一些X中不存在的信息的情况下更有用,例如引用网络中文档之间的引用链接或知识图中的关系。如图是整体模型用于半监督学习的多层GCN:
3.1 样例
下列例子中考虑在一个对称邻接矩阵A的图上使用两层GCN进行半监督节点分类。我们首先计算![]() ,前向传播模型采用:
,前向传播模型采用:
![]()

左图用于半监督学习的多层网络GCN的示意图,在输入层有C个输入,若干个隐藏层和F个输出特征。右图是在Cora数据集上训练的双层GCN的隐藏层可视化结果,颜色表示文档分类。
在这里,我们定义![]() 属于输入层到隐藏层的参数,
属于输入层到隐藏层的参数,![]() 属于隐藏层到输出层的参数。softmax激活函数定义为
属于隐藏层到输出层的参数。softmax激活函数定义为![]() ,按行应用。用交叉熵误差来评估所有有标签数据。
,按行应用。用交叉熵误差来评估所有有标签数据。

其中Yl是带有标签节点的集合。神经网络对W0和W1采用梯度下降法进行训练。使用dropout引入训练过程的随机性。
4 总结
利用切比雪夫公式作k阶近似拟合滤波器,依赖于周围步长最长为k的节点,进一步考虑周围节点对其影响,即取K=1,![]() ,并进一步优化,取
,并进一步优化,取![]() ,为了防止梯度爆炸做了改进,得到最终定义。
,为了防止梯度爆炸做了改进,得到最终定义。