Understanding Black-box Predictions via Influence Functions阅读笔记
Understanding Black-box Predictions via Influence Functions阅读笔记
- 1.案例1----理解模型行为
- 2.案例2----生成对抗训练样本
- 3.案例3----调试域不匹配
- 4.案例4----修正错误标注
- 参考
1.案例1----理解模型行为
通过告诉我们对一个给定的预测“负责”的训练点,影响函数揭示了关于模型如何依赖训练数据和从训练数据中推断的见解。在本节中,我们将展示两个模型可以做出相同的正确预测,但以完全不同的方式实现。
在一个从ImageNet中提取的狗和鱼图像分类数据集(每个类有900张图片)上,作者比较了当时最先进的Inception v3网络(除顶层模型参数外其他参数全部冻结)和带有RBF内核的SVM模型。
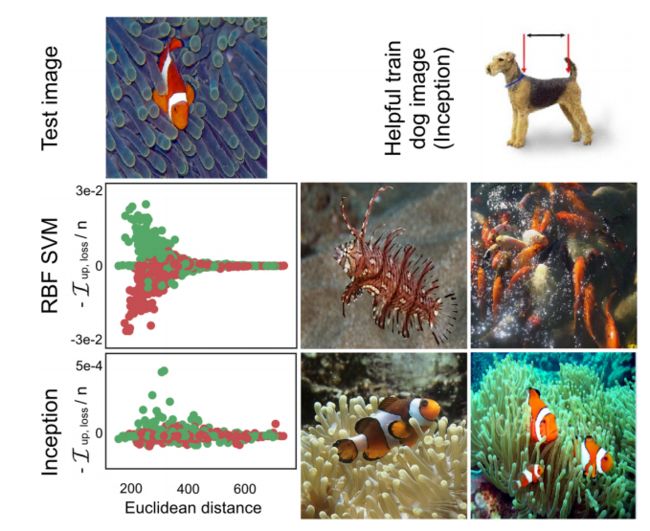
作者选择了一个测试图像(上图Test image),两个模型都预测到了正确的结果。SVM中的损失与原始像素距离的变化成反比,训练图像远离测试图像几乎没有影响;Inception影响与像素空间距离的相关性要小得多(上图左下两幅子图,其中横坐标代表训练样本和测试图像的欧氏距离,纵坐标代表去掉该训练样本模型的参数改变)。上图下右4幅子图分别展示了两个网络对Test image预测正确最有帮助的两幅子图,可以看出Inception网络选择了小丑鱼的独特特征,而SVM匹配的训练图像的表面特征。
此外,在SVM中,靠近Test image的鱼的训练图像(绿色点)大多是有用,而狗的训练图像(红色)大多是有害的。相比之下,在Inception网络中,鱼和狗的训练图像可能对正确地将Test image分类为鱼有益或有害;事实上,在Inception网络中,第五个最有帮助的训练图像是一只狗,它看起来与测试鱼非常不同(上图顶部)。
2.案例2----生成对抗训练样本
本节中,作者证明,在少量点上放置大量干扰的模型可能很容易受到训练输入扰动的影响,在现实世界的ML系统中造成了严重的安全风险,因为攻击者可以影响训练数据。最近的工作已经从真实的测试图像上产生了在视觉上无法区分的对抗性测试图像,但完全欺骗了一个分类器。我们证明了影响函数可以用于制作类似的视觉上难以区分的对抗性训练图像,并可以在单独的测试图像上改变模型的预测。
关键的思想是, I p e r t , l o s s ( z , z t e s t ) \mathcal{I}_{pert,loss}(z,z_{test}) Ipert,loss(z,ztest)告诉我们如何修改训练点 z z z,以最多地增加在 z t e s t z_{test} ztest上的损失。
作者在与案例1相同的inception网络上对第5.1节中的狗和鱼进行了实验,测试了这些对抗性的训练扰动,选择这对动物可以在类之间形成鲜明的对比。最初,该模型正确分类了591/600张测试图像。对于这591个测试图像中的每一个,我们试图从1800个训练图像中找到一个对单个训练图像的视觉上难以区分的扰动(即,相同的8位表示),这将改变模型的预测。我们能够在591张测试图像中的335张(57%)上做到这一点。如果我们对每个测试图像干扰2张训练图像,我们可以改变591张测试图像中77%的预测;如果我们干扰10张训练图像,我们可以改变591张图像中的590个预测结果。以上结果来自于分别攻击每个测试图像,即我们使用不同的训练集来攻击每个测试图像。
接下来,我们尝试通过增加多个测试图像的平均测试损失来同时攻击它们,并发现单个训练图像的扰动也可以同时改变多个测试预测结果(下图所示)。例如,图5中的图像包含狗和鱼,并且非常模糊;因此,这是模型最不自信的训练例子(置信度为77%,而图片下方子图的置信度最少为90%)。

上图作者瞄准了一组30张测试图像,以第一作者的狗为主角,呈现各种姿势和背景。通过最大化这30张图像的平均损失,我们发现特定的训练图像(如上所述)有一个难以察觉的变化,它可以改变16张测试图像的预测结果。
3.案例3----调试域不匹配
领域不匹配——如果训练分布与测试分布不匹配——可能会导致具有高训练精度的模型在测试数据上表现不佳。作者表明,影响函数可以识别出最容易导致错误的训练样本,帮助模型开发人员识别域不匹配。
作为一个案例研究,我们预测了患者是否会再次入院。领域不匹配在生物医学数据中很常见;例如,不同的医院可以为非常不同的人群提供服务,而针对一个人群训练的再入院模型可能在另一个人群中表现不佳。我们使用逻辑回归来预测了来自美国100家+医院的20K名糖尿病患者的平衡训练数据集的再入院情况,每个人由127个特征代表。
该数据集中的24名10岁以下儿童中有3名被重新入院。为了导致结构域不匹配,我们过滤掉了20名未再次入院的儿童,只剩下4名再次入院的儿童中的3名。这就导致了该模型错误地对测试集中的许多子代进行了分类。我们的目标是确定训练集中的4名儿童是否对这些错误“负责”。
随机选择一个模型分类错误的样本 z t e s t z_{test} ztest,我们对每个训练点 z i z_i zi计算 − I u p , l o s s ( z i , z t e s t ) −\mathcal{I}_{up,loss}(z_i,z_{test}) −Iup,loss(zi,ztest)。这清楚地突出了这4名训练集中的儿童,每个儿童的影响力是其他最有影响力的训练样本的30-40倍。训练集中的1名未再次入院的儿童有非常积极的影响,而其他3名儿童有非常消极的影响。计算这4个孩子的 I p e r t , l o s s \mathcal{I}_{pert,loss} Ipert,loss 显示,“儿童”指标变量的变化是迄今为止对 I u p , l o s s \mathcal{I}_{up,loss} Iup,loss 的影响是最大的。
4.案例4----修正错误标注
现实世界中的标签经常是有噪声的,尤其是如果是众包的话,甚至可能会被过度破坏。即使人类专家能够识别出错误标记的样本,但在许多应用程序中,也不可能手动检查所有的训练数据。我们表明,影响函数可以帮助人类专家优先考虑他们的注意力,允许他们只检查实际重要的例子。
其关键思想是标记对模型产生影响最大的训练样本。因为我们没有访问测试集,我们用 I u p , l o s s ( z i , z i ) \mathcal{I}_{up,loss}(z_i,z_i) Iup,loss(zi,zi) 测量 z i z_i zi 的影响,这近似于如果我们从训练集中删除 z i z_i zi 对 z i z_i zi 产生的误差。
我们的案例研究是电子邮件垃圾邮件分类,它依赖于用户提供的标签,也容易受到敌对攻击。作者随机改变了10%的训练数据的标签,然后手动模拟检查一部分训练数据,如果它们被改变了,就会纠正它们。使用影响函数对训练点进行优先级检查,使我们可以在不检查太多点的情况下修复数据集(下图,蓝色),性能优于训练损失最高的检查点的基线(下图,绿色)或随机(下图,红色)。没有任何方法可以访问测试数据。
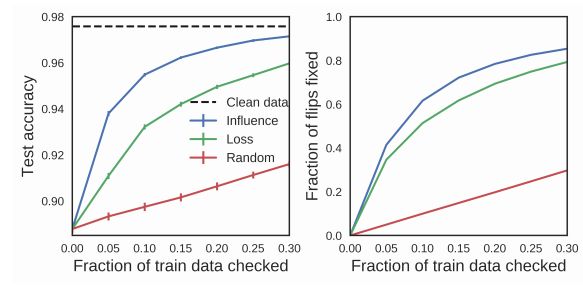
上图显示:测试精度(左)和检测到的翻转数据的比例(右)如何随着检查的训练数据的比例而变化,使用不同的算法来选择点进行检查。
参考
[1] 论文地址
[2] 论文代码
[3] Understanding Black-box Predictions via Influence Functions–PENG LIU
[4] 知乎—[ICML] Understanding Black-box Predictions via Influence Functions