深度学习的低秩优化:在紧凑架构和快速训练之间取得平衡(上)
论文出处:[2303.13635] Low Rank Optimization for Efficient Deep Learning: Making A Balance between Compact Architecture and Fast Training (arxiv.org)
由于篇幅有限,本篇博客仅引出问题的背景、各种张量分解方法及其分解FC/Conv层的方法,欢迎各位讨论!
高度的计算复杂度和存储成本使得深度学习难以在资源受限的设备上使用,并且不环保,功耗高。本文专注于高效深度学习技术的低秩张量优化方法。在空间域,深度神经网络通过对网络参数进行低秩逼近( low rank approximation )进行压缩,以更少的网络参数直接降低了存储需求。在时域中,网络参数可以在几个子空间中进行训练,从而实现快速收敛的高效训练。这两种类型可以通过低秩优化联系起来,发现时域和空间域的冗余是同源的,为了加快神经网络的训练速度,需要在空间效率和时间效率之间取得平衡。
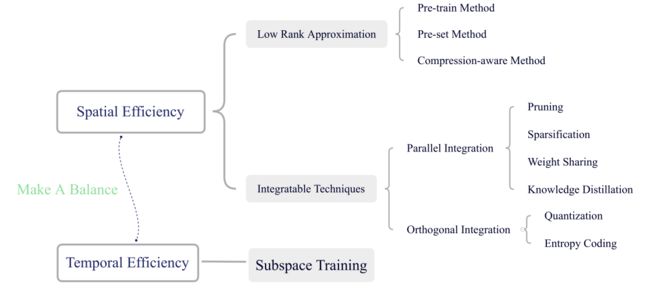
文章目录
-
- 一、问题背景
- 二、模型压缩的低秩优化
-
- (一) 网络压缩的各种张量分解方法
-
- 1) Singular Value Decomposition
- 2) CP Decomposition
- 3) Tucker Decomposition
- 4) Block Term Decomposition
- 5) Hierarchical Tucker Decomposition
- 6) Tensor Train Decomposition
- 7) Tensor Ring Decomposition
- 8) Generalized Kronecker P.roduct Decomposition
- 9) Semi-tensor Product-based Tensor Decomposition
- (二) 低秩逼近的优化方法
-
- 1)预训练方法
- 2)预设方法
- 3)压缩感知方法
- (三) 有效的稀疏度度量
- 三、与其他压缩技术相结合
- 四、子空间训练的低秩优化
一、问题背景
-
深度学习主要有两个挑战:高复杂性和慢收敛性。
-
高复杂性意味着深度神经网络中有数百万个参数,大量参数和输入之间的计算非常麻烦,这强调了对高效算法的压缩和加速的需求,尤其是资源有限的设备(如手机、物联网设备)。此外,由于更深或更宽的结构可以带来更好的性能,深度神经网络逐渐以其过度参数化为特征,过度参数化意味着DNN中冗余过多,导致过拟合。
-
传统的BP算法收敛速度慢,训练时间长。同时,收敛速度对学习率的设置和初始化权值的方式也很敏感。
-
-
降低深度神经网络的高复杂性分为两类:减少参数量,减少数据表示的平均位宽。
-
减少参数量的方法:low rank approximation(本文的重点), pruning, weight-sharing, sparsity, knowledge distillation
-
减少数据表示的平均位宽:Quantization 与 entropy coding
-
-
模型压缩的低秩优化分为三大类:预训练方法、预设置方法和压缩感知方法( 区别在于训练的方式 )
-
预训练方法直接对预训练模型进行分解,得到压缩格式的热初始化,然后对压缩模型进行再训练,恢复性能。
-
预设置方法在没有预训练的情况下,从头开始训练一个预先设置为紧凑格式的网络。
-
与上述两种方法不同的是,压缩感知方法通过逐步使网络具有低秩结构,明确地考虑了训练过程中的压缩。
虽然关于低秩优化的讨论也可以在[2302.09019] Tensor Networks Meet Neural Networks: A Survey and Future Perspectives (arxiv.org)中找到,但本文进一步研究了如何将其与其他压缩技术相结合以追求更低的复杂度,并推荐将有效秩作为低秩优化中使用的最有效度量。
-
-
加快深度神经网络的收敛速度:子空间训练
-
一阶优化方法存在一些固有的缺陷,如理论和经验收敛速度慢。
-
二阶方法可以很好地处理这类问题,但由于计算量大不适用预DNN。将参数投影到由多个自变量表示的微小子空间上是解决这一问题的有效方法,它只有少数变量需要优化。
-
二、模型压缩的低秩优化
量化、剪枝和低秩逼近等压缩方法可以在不显著降低精度的前提下降低DNN的复杂度。其中,由于张量分解具有坚实的理论基础,低秩近似被广泛采用。
(一) 网络压缩的各种张量分解方法
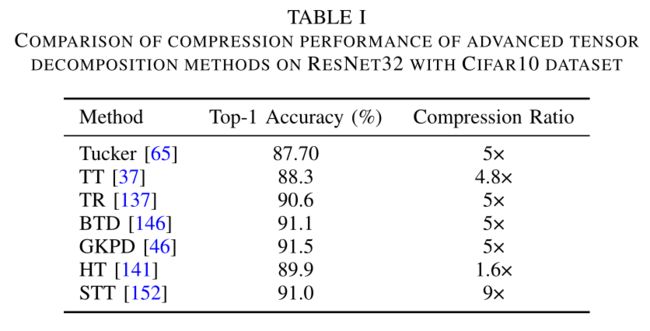
低秩近似可以在精度损失较小的情况下为递归神经网络提供超高的压缩比。然而,当涉及到卷积神经网络(CNN)时,压缩性能并不像RNN那样令人满意。将4D卷积核重构为矩阵,并利用奇异值分解(SVD)将矩阵分解为两个因子的操作,会导致结构信息失真。因此,更有效的张量分解引起了人们的兴趣。应用CP分解将卷积层分解为四个连续的卷积层,显著加快了CNN的速度。Tucker分解利用通道冗余将四维核分解为一个四维紧核和两个矩阵。在这三种经典分解的基础上,出现了许多其他灵活的方法,包括HT, TT , TR, BTD, GKPD,基于半张量积(STP)的张量分解等,这些方法显著提高了DNN的压缩性能。表1给出了使用Cifar10数据集压缩ResNet32的常用张量分解方法的性能。
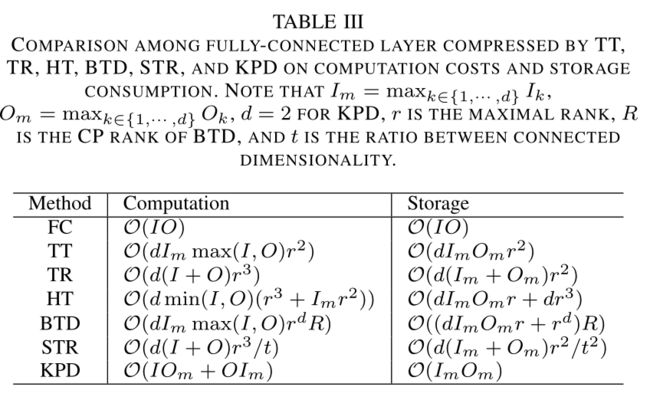
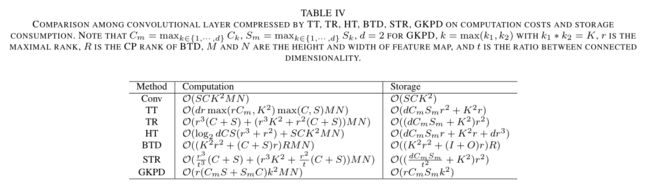
不同方法的时空复杂度,针对FC层,对比如表3所示。表4为Conv层。
对于张量的基础表示、运算就不在这里展开了,推荐一些学习资料:
浅谈张量分解(二):张量分解的数学基础 (zhihu.com)
张量基础| 张量的秩与秩一张量 - 知乎 (zhihu.com)
( Xinyu Chen - 知乎 (zhihu.com)
Tensor Computation for Data Analysis | SpringerLink
下面介绍一下本文提到的9种分解方式:
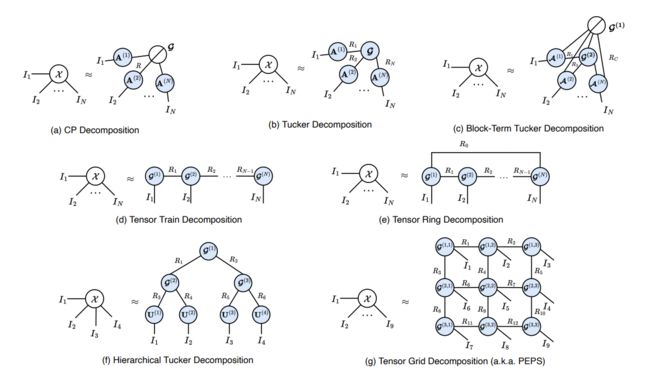
1) Singular Value Decomposition
对于给定矩阵 X ∈ R N × N X∈R^{N×N} X∈RN×N,其SVD可以写成:
X = U d i a g ( s ) V T X = U diag(s)V^T X=Udiag(s)VT
设R为矩阵的秩, R ≤ m i n ( M , N ) R≤min{(M, N)} R≤min(M,N)。注意, U ∈ R M × N U∈R^{M×N} U∈RM×N和 V ∈ R N × R V∈R^{N×R} V∈RN×R分别满足 U U T = I UU^T = I UUT=I和 V V T = I VV^T = I VVT=I。而 s ∈ R R s∈\Bbb{R}^R s∈RR的元素依次递减,即 s 1 ≥ s 2 ≥ . . . ≥ s R s_1≥s_2≥...≥s_R s1≥s2≥...≥sR。
由于FC层的权值格式是自然矩阵,因此可以直接利用奇异值分解。利用奇异值分解(SVD),可以将FC层近似为两个连续的层。第一层和第二层的权重可以分别表示为 B = d i a g ( s ) V T B = diag(\sqrt{s} )V^T B=diag(s)VT和 A = U d i a g ( s ) A = Udiag(\sqrt{s}) A=Udiag(s)。对于Conv层,首先要将4D核重构为2D矩阵。通过利用不同类型的冗余,有两种分解方案,一种是将W重塑为 S − b y − C H W S-by-CHW S−by−CHW矩阵,即信道分解,另一种是空间分解,得到 S H − b y − C W SH-by-CW SH−by−CW矩阵。然后,计算重构矩阵的SVD。与压缩FC层的过程类似,可以使用由因子 B B B和 A A A重塑的张量表示的两个Conv层来替换原始层。
然而,这两种方法都只能利用一种冗余。此外,输入通道之间也存在冗余。可以通过张量分解同时利用各种冗余,帮助我们获得更高的压缩比。
2) CP Decomposition
SVD将一个矩阵分解为秩一矩阵的和,而CP分解将一个张量分解为秩一张量(rank-one tensors)的和。对于n阶张量 X ∈ R I 1 × I 2 × ⋅ ⋅ ⋅ × I N \mathcal{X}∈R^{I_1×I_2×···×I_N} X∈RI1×I2×⋅⋅⋅×IN, CP分解可表示为:
X = ⟦ λ ; A ( 1 ) , A ( 2 ) , ⋯ , A N ⟧ = ∑ r = 1 R λ r a r ( 1 ) ∘ a r ( 2 ) ∘ ⋯ ∘ a r ( N ) . \mathcal{X}=\llbracket \lambda ; \mathbf{A}^{(1)}, \mathbf{A}^{(2)}, \cdots, \mathbf{A}^{N} \rrbracket=\sum_{r=1}^{R} \lambda_{r} \mathbf{a}_{r}^{(1)} \circ \mathbf{a}_{r}^{(2)} \circ \cdots \circ \mathbf{a}_{r}^{(N)} . X=[[λ;A(1),A(2),⋯,AN]]=r=1∑Rλrar(1)∘ar(2)∘⋯∘ar(N).
每个 a r ( n ) \mathbf{a}_{r}^{(n)} ar(n)表示 A ( n ) A^{(n)} A(n)的第 r r r列, λ ∈ R R λ∈\Bbb{R}^R λ∈RR表示 r r r个分量的显著性。张量 X \mathcal{X} X的秩用 R R R表示,定义为秩1张量的最小个数。
在使用CP压缩FC层时,首先需要将权值矩阵W张成一个2d阶张量 W ∈ R O 1 × O 2 ⋅ ⋅ × O d × I 1 × I 2 × ⋅ ⋅ ⋅ × I d \mathcal{W}∈R^{O_1×O_2··×O_d×I_1×I_2×···×I_d} W∈RO1×O2⋅⋅×Od×I1×I2×⋅⋅⋅×Id。同时,输入向量 x ∈ R I x∈R^I x∈RI应表示为一个 d d d阶张量 x ∈ R I 1 × I 2 × ⋅ ⋅ ⋅ × I d x∈R^{I_1×I_2×···×I_d} x∈RI1×I2×⋅⋅⋅×Id。对于卷积核,通过直接对4-D核张量执行CP,层将由四个连续的卷积层近似,其权重分别由四个因子矩阵表示。
3) Tucker Decomposition
Tucker分解可以看作是主成分分析(PCA)的一种高阶推广。它表示一个n阶张量和一个n阶核心张量沿着每个模态乘以一个基矩阵。因此,对于 X ∈ R I 1 × I 2 × ⋅ ⋅ ⋅ × I N \mathcal{X}∈R^{I_1×I_2×···×I_N} X∈RI1×I2×⋅⋅⋅×IN,有:
X = G × 1 A ( 1 ) × 2 A ( 2 ) × 3 ⋯ × N A ( N ) \mathcal{X}=\mathcal{G} \times_{1} \mathbf{A}^{(1)} \times_{2} \mathbf{A}^{(2)} \times_{3} \cdots \times_{N} \mathbf{A}^{(N)} X=G×1A(1)×2A(2)×3⋯×NA(N)
其中 G ∈ R R 1 × R 2 × ⋯ × R N \mathcal{G} \in \mathbb{R}^{R_{1} \times R_{2} \times \cdots \times R_{N}} G∈RR1×R2×⋯×RN称为核心张量。其中," × n \times{ }_{n} ×n “表示 n n n模积,即张量与模态为 n n n的矩阵相乘。在元素上,” $\times{ }_{n} $”可以表示为:
( G × 1 A ( 1 ) ) i 1 , r 2 , ⋯ , r N = ∑ r 1 = 1 R 1 G r 1 , r 2 , ⋯ , r N A i 1 , r 1 ( 1 ) \left(\mathcal{G} \times{ }_{1} \mathbf{A}^{(1)}\right)_{i_{1}, r_{2}, \cdots, r_{N}}=\sum^{R_{1}}_{r_1 = 1} \mathcal{G}_{r_{1}, r_{2}, \cdots, r_{N}} \mathbf{A}_{i_{1}, r_{1}}^{(1)} (G×1A(1))i1,r2,⋯,rN=r1=1∑R1Gr1,r2,⋯,rNAi1,r1(1)
因子矩阵 A ( n ) ∈ R I n × R n A(n)∈R^{I_n×R_n} A(n)∈RIn×Rn的列可以看作是第n个模态的主成分。核心张量 G \mathcal{G} G可以看作是 X \mathcal{X} X的压缩版本,或者是低维子空间中的系数。在这种情况下,我们可以说 X \mathcal{X} X是一个 r a n k − ( R 1 , R 2 , ⋅ ⋅ ⋅ , R N ) rank-(R_1, R_2,···,R_N) rank−(R1,R2,⋅⋅⋅,RN)张量
在压缩FC层的情况下,与CP类似,通过直接对二阶张量进行Tucker分解对权重和输入进行相同的紧凑化。对于Conv层,由于内核的空间大小太小,我们可以只使用Tucker2利用滤波器之间和输入通道之间的冗余,生成1×1卷积、H × W卷积和1×1卷积。
4) Block Term Decomposition
块项分解(Block Term Decomposition, BTD)在中作为一种更强大的张量分解被引入,它结合了CP分解和Tucker分解。因此,BTD比原始的CP和Tucker分解具有更强的鲁棒性。CP近似于一个张量的秩一张量的和,而BTD是一个低秩Tucker格式的张量的和。或者,通过将每个模态中的因子矩阵串联起来,将每个子张量的所有核心张量排列成一个块对角核心张量,BTD可以视为Tucker的一个实例。因此,考虑一个n阶张量 X ∈ R I 1 × I 2 × ⋅ ⋅ ⋅ × I d \mathcal{X} ∈R^{I_1×I_2×···×I_d} X∈RI1×I2×⋅⋅⋅×Id,其BTD可以表示为:
X = ∑ n = 1 N G n × 1 A n ( 1 ) × 2 A n ( 2 ) × 3 ⋯ × d A n ( d ) \mathcal{X}=\sum^N_{n=1}\mathcal{G}_n \times_{1} \mathbf{A}^{(1)}_n \times_{2} \mathbf{A}^{(2)}_n \times_{3} \cdots \times_{d} \mathbf{A}^{(d)}_n X=n=1∑NGn×1An(1)×2An(2)×3⋯×dAn(d)
上式中,N表示CP秩,即块项个数, G ∈ R R 1 × R 2 × ⋯ × R d \mathcal{G} \in \mathbb{R}^{R_{1} \times R_{2} \times \cdots \times R_{d}} G∈RR1×R2×⋯×Rd是第N个多线性秩块项的核心张量,其秩为 ( R 1 , R 2 , ⋅ ⋅ ⋅ , R d ) (R_1, R_2,···,R_d) (R1,R2,⋅⋅⋅,Rd)。
当BTD应用于压缩FC层时,生成的紧凑层称为块项层(Block Term layer, BTL)。在BTL中,输入张量 X ∈ R I 1 × I 2 × ⋅ ⋅ ⋅ × I d \mathcal{X} ∈R^{I_1×I_2×···×I_d} X∈RI1×I2×⋅⋅⋅×Id从原始输入向量 X ∈ R I X∈R^I X∈RI张量化,原始权矩阵W被重塑为 W ∈ R O 1 × I 1 × O 2 × I 2 ⋅ ⋅ × O d × I d W∈R^{O_1×I_1×O_2×I_2··×O_d×I_d} W∈RO1×I1×O2×I2⋅⋅×Od×Id
然后,我们可以通过BTD用因子张量{ A n ( d ) ∈ R O d × I d × R d A^{(d)}_n∈R^{Od×Id×Rd} An(d)∈ROd×Id×Rd} n = 1 d {}^d_{n=1} n=1d分解W。通过在 B T D ( W ) BTD(\mathcal{W} ) BTD(W)和 X \mathcal{X} X之间进行张量收缩算子,得到输出张量 Y ∈ R O 1 × O 2 × ⋅ ⋅ ⋅ × O d \mathcal{Y} ∈R^{O_1×O_2×···×O_d} Y∈RO1×O2×⋅⋅⋅×Od,可以将其矢量化作为最终的输出向量。
对于Conv层,文献声称通过将4D核重构为矩阵 W ∈ R S × C H W W∈R^{S×CHW} W∈RS×CHW,可以将该层转化为BTL。具体来说,矩阵应进一步重构为 1 × H × 1 × W × S 1 × C 1 × S 2 × C 2 × ⋅ ⋅ ⋅ × S d × C d 1 × H × 1 × W × S_1 × C_1 × S_2 × C_2 ×···× S_d × C_d 1×H×1×W×S1×C1×S2×C2×⋅⋅⋅×Sd×Cd。
5) Hierarchical Tucker Decomposition
分层Tucker分解(HT)是Tucker分解的一种分层变体,它迭代地表示一个高阶张量和两个低阶子张量以及利用Tucker分解得到的传递矩阵。对于张量 X ∈ R I 1 × I 2 × ⋅ ⋅ ⋅ × I N \mathcal{X} ∈R^{I_1×I_2×···×I_N} X∈RI1×I2×⋅⋅⋅×IN,我们可以简单地将索引集{1,2,···,N}划分为两个子集,即 T = { t 1 , t 2 , ⋅ ⋅ , t k } , S = { s 1 , s 2 , ⋅ ⋅ , s N − k } T = \{t_1, t_2,··,t_k\}, S = \{s_1, s_2,··,s_{N−k}\} T={t1,t2,⋅⋅,tk},S={s1,s2,⋅⋅,sN−k}
设 U 12 ⋅ ⋅ ⋅ N ∈ R I t 1 I t 2 ⋅ ⋅ ⋅ I t k I s 1 I s 2 ⋅ ⋅ ⋅ I s N − k × 1 U_{12···N}∈R^{I_{t_1} I_{t_2}···I_{t_k}I_{s_1} I_{s_2}···I_{s_{N-k}} ×1} U12⋅⋅⋅N∈RIt1It2⋅⋅⋅ItkIs1Is2⋅⋅⋅IsN−k×1表示由X重构的矩阵,截断的矩阵 U t ∈ R I t 1 I t 2 ⋅ ⋅ ⋅ I t k × R t U_t∈R^{I_{t_1} I_{t_2}···I_{t_k} ×R_t} Ut∈RIt1It2⋅⋅⋅Itk×Rt, U s ∈ R I s 1 I s 2 ⋅ ⋅ ⋅ I s N − k × R s U_s∈R^{I_{s_1} I_{s_2}···I_{s_{N-k}} ×R_s} Us∈RIs1Is2⋅⋅⋅IsN−k×Rs表示两个子空间对应的列基矩阵。然后,我们可以:
U 12 ⋅ ⋅ ⋅ N = ( U t ⊗ U s ) B 12 ⋅ ⋅ ⋅ N , U_{12···N} = (U_t ⊗ U_s)B_{12···N} , U12⋅⋅⋅N=(Ut⊗Us)B12⋅⋅⋅N,
其中 B 12 ⋅ ⋅ N ∈ R R t R s × 1 B_{12··N}∈R^{R_tR_s×1} B12⋅⋅N∈RRtRs×1被称为转移矩阵,“⊗”表示两个矩阵之间的Kronecker乘积。随后,将集合 T \mathbb{T} T划分为两个子集 L = { l 1 , l 2 , ⋅ ⋅ ⋅ , l q } \mathbb{L}=\{l_1,l_2,···,l_q\} L={l1,l2,⋅⋅⋅,lq}和 V = { v 1 , v 2 , ⋅ ⋅ ⋅ , v k − q } \mathbb {V}=\{v_1,v_2,···,v_{k−q}\} V={v1,v2,⋅⋅⋅,vk−q}。我们可以将 U l ∈ R I l 1 I l 2 ⋅ ⋅ I l q × R l U^l∈\mathbb{R}^{I_{l_1} I_{l_2}··I_{l_q}×R_l} Ul∈RIl1Il2⋅⋅Ilq×Rl, U v ∈ R I v 1 I v 2 ⋅ ⋅ I v q × R v U^v∈\mathbb{R}^{I_{v_1} I_{v_2}··I_{v_q}×R_v} Uv∈RIv1Iv2⋅⋅Ivq×Rv, U t ∈ R I t 1 I t 2 ⋅ ⋅ I t q × R t U^t ∈\mathbb{R} ^{I_{t_1} I_{t_2}··I_{t_q}×R_t} Ut∈RIt1It2⋅⋅Itq×Rt的 U t U_t Ut表示为:
U t = ( U l ⊗ U v ) B t U_{t} = (U_l ⊗ U_v)B_{t} Ut=(Ul⊗Uv)Bt
类似的因子分解过程同时适用于 U s U_s Us。通过重复这个过程直到索引集不能被划分,我们最终可以获得目标张量的树状HT格式。
通过HT实现FC层压缩,则需要将权重矩阵变换为 W ∈ R ( I 1 ⋅ O 1 ) × ( I 2 ⋅ O 2 ) × ⋅ ⋅ × ( I d ⋅ O d ) \mathcal W∈\mathbb{R}^{\left(I_1·O_1 \right )×\left(I_2·O_2\right)×··×\left(I_d·O_d\right)} W∈R(I1⋅O1)×(I2⋅O2)×⋅⋅×(Id⋅Od),并将输入数据张量化为 X ∈ R I 1 × I 2 × ⋅ ⋅ ⋅ × I d \mathcal{X} ∈R^{I_1×I_2×···×I_d} X∈RI1×I2×⋅⋅⋅×Id。为了降低计算复杂度,采用了图中所示的链式计算。然而,由于没有将卷积和收缩相关联的定律,因此必须从HT格式中恢复Conv层的内核。顺便说一下,为了保持平衡,4D核应该张量化为 W ∈ R ( H ⋅ W ) × ( C 1 ⋅ S 1 ) × ( C 2 ⋅ S 2 ) × ⋅ ⋅ × ( C d ⋅ S d ) \mathcal W∈R^{\left(H·W \right )×\left(C_1·S_1 \right )×\left(C_2·S_2 \right )×··×\left(C_d·S_d \right )} W∈R(H⋅W)×(C1⋅S1)×(C2⋅S2)×⋅⋅×(Cd⋅Sd)。
6) Tensor Train Decomposition
张量序列(TT)是HT的一个特例,它是退化的HT格式。TT将高阶张量分解为三阶或二阶张量的集合。这些核心张量是通过收缩算子连接起来的。假设我们有一个N阶张量, X ∈ R I 1 × I 2 × ⋅ ⋅ × I N \mathcal X∈R^{I_1×I_2×··×I_N} X∈RI1×I2×⋅⋅×IN,在元素上,我们可以将其分解为TT格式:
X i 1 , i 2 , ⋅ ⋅ ⋅ , i N = ∑ r 1 , r 2 , ⋅ ⋅ ⋅ , r N G i 1 , r 1 1 G r 1 , i 2 , r 2 2 ⋅ ⋅ ⋅ G r N − 1 , i N N \mathcal X_{i_1,i_2,··· ,i_N} =\sum _{r_1,r_2,··· ,r_N} \mathcal G^1_{i_1,r_1}\mathcal G^2_{r_1,i_2,r_2} · · · \mathcal G^N_{r_{N-1},i_{N}} Xi1,i2,⋅⋅⋅,iN=r1,r2,⋅⋅⋅,rN∑Gi1,r11Gr1,i2,r22⋅⋅⋅GrN−1,iNN
其中 { G n ∈ R R n − 1 × I n × R n } n = 1 N \{\mathcal G_n∈\mathbb{R}^{R_{n−1}×I_n×R_n}\}^N_{n=1} {Gn∈RRn−1×In×Rn}n=1N与 R 0 = 1 R_0=1 R0=1和 R n = 1 R_n=1 Rn=1的集合称为TT核。秩 { R n } n = 0 N \{Rn \}^N_{n=0} {Rn}n=0N的集合称为TT秩。
TT用于压缩FC层,其中权重矩阵被重塑为高阶张量, W ∈ R ( I 1 ⋅ O 1 ) × ( I 2 ⋅ O 2 ) × ⋅ ⋅ × ( I d ⋅ O d ) \mathcal W∈\mathbb{R}^{\left(I_1·O_1 \right )×\left(I_2·O_2\right)×··×\left(I_d·O_d\right)} W∈R(I1⋅O1)×(I2⋅O2)×⋅⋅×(Id⋅Od)。在以TT格式表示 W \mathcal W W之后,得到的TT核 { G n ∈ R R n − 1 × I n × O n × R n } n = 1 N \{\mathcal G_n∈\mathbb{R}^{R_{n−1}×I_n×O_n×R_n}\}^N_{n=1} {Gn∈RRn−1×In×On×Rn}n=1N可以与张量化输入直接收缩。[141]中提出,TT比HT更有效地压缩Conv层,而HT更适合于压缩权重矩阵更倾向于重塑为平衡张量的FC层。
[37]中介绍了在Conv层上使用TT,其中4D核张量应重塑为 ( H ⋅ W ) × ( C 1 ⋅ S 1 ) × ( C 2 ⋅ S 2 ) × ⋅ ⋅ ⋅ × ( C d ⋅ S d ) (H·W)×(C_1·S_1)×(C_2·S_2)×···×(C_d·S_d) (H⋅W)×(C1⋅S1)×(C2⋅S2)×⋅⋅⋅×(Cd⋅Sd)的大小,并且输入特征图重塑为 X ∈ R H × W × C 1 × ⋅ ⋅ ⋅ × C d X∈\mathbb R^{H×W×C_1×···×C_d} X∈RH×W×C1×⋅⋅⋅×Cd。在前馈阶段,张量化的输入X将与每个TT核心逐一收缩。尽管TT可以显著节省存储成本,但计算复杂度可能高于原始的Conv层。因此,[149]中提出了HODEC(高阶分解卷积),以同时降低计算和存储成本,从而将每个TT核心进一步分解为两个三阶张量。
7) Tensor Ring Decomposition
由于边缘TT核的不统一(即 R 0 = 1 R_0=1 R0=1和 R n = 1 R_n=1 Rn=1),如何排列张量的维数以找到最优的TT格式仍然是一个悬而未决的问题。为了解决这个问题,张量环(TR)分解提出了在核上进行循环多线性乘积的分解。考虑一个给定的张量, X ∈ R I 1 × I 2 × ⋅ ⋅ × I N \mathcal X∈R^{I_1×I_2×··×I_N} X∈RI1×I2×⋅⋅×IN,在元素上,我们可以将其TR表示公式化为:
X i 1 , i 2 , ⋅ ⋅ ⋅ , i N = ∑ r 1 , r 2 , ⋅ ⋅ ⋅ , r N G r 1 , i 1 , r 2 1 G r 2 , i 2 , r 3 2 ⋅ ⋅ ⋅ G r N , i N , r 1 N = t r ( ∑ r 2 , ⋅ ⋅ ⋅ , r N G : , i 1 , r 2 1 G r 2 , i 2 , r 3 2 ⋅ ⋅ ⋅ G r N , i N , : N ) \mathcal X_{i_1,i_2,··· ,i_N} =\sum _{r_1,r_2,··· ,r_N} \mathcal G^1_{r_1,i_1,r_2}\mathcal G^2_{r_2,i_2,r_3} · · · \mathcal G^N_{r_{N},i_{N},r_1} = tr( \sum _{r_2,··· ,r_N} \mathcal G^1_{:,i_1,r_2}\mathcal G^2_{r_2,i_2,r_3} · · · \mathcal G^N_{r_{N},i_{N},:} ) Xi1,i2,⋅⋅⋅,iN=r1,r2,⋅⋅⋅,rN∑Gr1,i1,r21Gr2,i2,r32⋅⋅⋅GrN,iN,r1N=tr(r2,⋅⋅⋅,rN∑G:,i1,r21Gr2,i2,r32⋅⋅⋅GrN,iN,:N)
其中所有核 { G n ∈ R R n × I n × R n + 1 } n = 1 N \{\mathcal G_n∈\mathbb{R}^{R_{n}×I_n×R_{n+1}}\}^N_{n=1} {Gn∈RRn×In×Rn+1}n=1N且 R N + 1 = R 1 R_{N+1}=R_1 RN+1=R1称为TR核。这种形式相当于 R 1 R_1 R1 TT形式的总和。得益于通过使用迹操作(trace operation)获得的循环多线性乘积,TR等效地对待所有核心,并变得比TT更强大和通用。
此外,由于循环策略,TR修正了TT中梯度的变化性。因此,TR也适用于压缩FC层。在[137]中,TR首次被用于压缩DNN。具体来说,FC层的权重矩阵应该被重塑为大小为 I 1 × ⋅ ⋅ × I d × O 1 × ⋅ × O 2 I_1×··×I_d×O_1×·×O_2 I1×⋅⋅×Id×O1×⋅×O2的2阶张量,然后将张量表示为TR格式。对于前馈过程,首先将前d个核和后d个核合并,分别得到 F 1 ∈ R R 1 × I 1 × ⋅ ⋅ × I d × R d + 1 \mathcal F_1∈ \mathbb R^{R_1×I_1×··×I_d×R_{d+1}} F1∈RR1×I1×⋅⋅×Id×Rd+1和 F 2 ∈ R R d + 1 × O 1 × ⋅ ⋅ × O d × R 1 \mathcal F_2∈ \mathbb R^{R_{d+1}×O_1×··×O_d×R_{1}} F2∈RRd+1×O1×⋅⋅×Od×R1。然后,我们可以计算输入 X ∈ R I 1 × I 2 × ⋅ ⋅ × I d \mathcal X∈R^{I_1×I_2×··×I_d} X∈RI1×I2×⋅⋅×Id和 F 1 \mathcal F_1 F1之间的收缩,得到一个可以用 F 2 \mathcal F_2 F2收缩的矩阵。最终输出张量的大小为 O 1 × O 2 × ⋅ ⋅ × O d O_1×O_2×··×O_d O1×O2×⋅⋅×Od。对于Conv层,如果将核张量保持在4阶并保持空间信息,则其TR格式可以公式化为:
K s , c , h , w = ∑ r 1 = 1 R 1 ∑ r 2 = 1 R 2 ∑ r 3 = 1 R 3 U r 1 , s , r 2 V r 2 , c , r 3 Q r 3 , h , w , r 1 K_{s,c,h,w} = \sum^{R_1}_{r_1=1}\sum^{R_2}_{r_2=1}\sum^{R_3}_{r_3=1}\mathcal U_{r_1,s,r_2}\mathcal V_{r_2,c,r_3}\mathcal Q_{r_3,h,w,r_1} Ks,c,h,w=r1=1∑R1r2=1∑R2r3=1∑R3Ur1,s,r2Vr2,c,r3Qr3,h,w,r1
因此,原始层可以由三个连续层表示,其权重张量分别为 V 、 Q 和 U \mathcal V、\mathcal Q和\mathcal U V、Q和U。如果需要更高的压缩比,我们可以进一步将 U \mathcal U U和 V \mathcal V V分别视为从 d d d个核心张量合并而来的张量,从而增加合并的计算负担。
8) Generalized Kronecker P.roduct Decomposition
Kronecker乘积分解(KPD)可以将矩阵分解为由Kronecker积互连的两个较小的因子矩阵,这在应用于压缩RNNs时非常有效。为了进一步压缩Conv层,它被生成为广义Kronecker积分解(GKPD),它通过两个因子张量之间的多维Kronecker乘积的和来表示张量。形式上, A ∈ R J 1 × J 2 × ⋅ ⋅ × J N A∈R^{J_1×J_2×··×J_N} A∈RJ1×J2×⋅⋅×JN和 B ∈ R K 1 × K 2 × ⋅ ⋅ ⋅ × K N B∈R^{K_1×K_2×···×K_N} B∈RK1×K2×⋅⋅⋅×KN之间的多维Kronecker乘积公式化为:
( A ⊗ B ) i 1 , i 2 , ⋅ ⋅ ⋅ , i N = A j 1 , j 2 , ⋅ ⋅ ⋅ , j N B k 1 , k 2 , ⋅ ⋅ ⋅ , k N (A⊗B)_{i_1,i_2,··· ,i_N} = \mathcal A_{j_1,j_2,··· ,j_N} B_{k_1,k_2,··· ,k_N} (A⊗B)i1,i2,⋅⋅⋅,iN=Aj1,j2,⋅⋅⋅,jNBk1,k2,⋅⋅⋅,kN
其中 j n = b i n / K n c j_n=bi_n/K_nc jn=bin/Knc并且 k n = i n m o d K n k_n=i_nmodK_n kn=inmodKn。基于此,对于给定的N阶张量 X ∈ R J 1 K 1 × J 2 K 2 × ⋅ ⋅ ⋅ × J N K N \mathcal X∈R^{J_1K_1×J_2K_2×···×J_NK_N} X∈RJ1K1×J2K2×⋅⋅⋅×JNKN,GKPD可以表示为:
X = ∑ r = 1 R A r ⊗ B r \mathcal X= \sum^R_{r=1} \mathcal A_r ⊗\mathcal B_r X=r=1∑RAr⊗Br
其中R被称为Kronecker秩。为了在给定 R R R的GKPD中找到最佳逼近,我们可以将这个优化问题转化为找到矩阵的最佳秩- R R R逼近, S V D SVD SVD可以通过小心地将 X \mathcal X X重新排列成矩阵,并将 A \mathcal A A和 B \mathcal B B重新排列成向量来方便地求解。
为了实现使用GKPD对Conv层进行解压缩,4D内核表示为:
W s , c , h , w = ∑ r = 1 R ( A r ) s 1 , c 1 , h 1 , w 1 ⊗ ( B r ) s 2 , c 2 , h 2 , w 2 W_{s,c,h,w} = \sum^R_{r=1}(\mathcal A_r)_{s_1,c_1,h_1,w_1} ⊗ (\mathcal B_r)_{s_2,c_2,h_2,w_2} Ws,c,h,w=∑r=1R(Ar)s1,c1,h1,w1⊗(Br)s2,c2,h2,w2
其中 S 1 S 2 = S , C 1 C 2 = C , H 1 H 2 = H , W 1 W 2 = W S_1S_2=S,C_1C_2=C,H_1H_2=H,W_1W_2=W S1S2=S,C1C2=C,H1H2=H,W1W2=W。每个 A r ⊗ B r A_r⊗B_r Ar⊗Br和输入之间的2D卷积可以转换为深度等于 C 2 C_2 C2的3D卷积,然后是多个2D卷积。此外, R R R Kronecker乘积组可以看作是分别计算上述两个步骤的 R R R个平行通道。分析表明,较大的 S 1 S_1 S1和 C 2 C_2 C2有助于获得更多的FLOP减少。
9) Semi-tensor Product-based Tensor Decomposition
半张量积(STP)是传统矩阵积的一代,它将二维匹配矩阵的计算扩展到二维任意矩阵的计算。由于张量收缩是基于传统的矩阵乘积,我们可以将STP进一步替换为张量收缩,这将导致更通用、更灵活的张量分解方法。在[152]中提出,基于半张量乘积的张量分解旨在通过用STP代替张量收缩中的传统矩阵乘积来增强Tucker分解、TT分解和TR分解的灵活性,这表明了比原始方法高得多的效率。考虑一个特殊情况,其中列的数量 X ∈ R M × N P X∈\mathbb R^{M×N P} X∈RM×NP与 W ∈ R P × Q W∈\mathbb R^{P×Q} W∈RP×Q中的行的数量成比例,STP可以表示为:
![]()
或者,元素表示为:
Y m , g ( n , q ) = ∑ p = 1 P X m , g ( n , p ) W p , q Y_{m,g(n,q) }=\sum^P_{p=1}X_{m,g(n,p)}W_{p,q} Ym,g(n,q)=p=1∑PXm,g(n,p)Wp,q
注意, Y ∈ R M × N Q Y∈\mathbb R^{M×N Q} Y∈RM×NQ, g ( N , Q ) = ( Q − 1 ) N + n 和 g ( N , p ) = ( p − 1 ) N + n g(N,Q)=(Q−1)N+n和g(N,p)=(p−1)N+n g(N,Q)=(Q−1)N+n和g(N,p)=(p−1)N+n是重索引函数。
因此,以基于STP的Tucker分解为例,即STTu,可以公式化为:
![]()
其中 G ∈ R R 1 × R 2 × ⋅ ⋅ × R N , A ( n ) ∈ R I n / t × R n / t \mathcal G∈\mathbb R^{R_1×R_2×··×R_N},A^{(n)}∈\mathbb R^{I_n/t × R_n/t} G∈RR1×R2×⋅⋅×RN,A(n)∈RIn/t×Rn/t。与普通Tucker相比,参数的数量从 ( ∏ n = 0 N R n + ∑ n = 1 N I n R n ) (\prod^ N_{ n=0}R_n+ \sum^N_{n=1}I_nR_n) (∏n=0NRn+∑n=1NInRn)减少到 ( ∏ n = 0 N R n + ∑ n = 1 N I n R n / t 2 ) (\prod^ N_{ n=0}R_n+ \sum^N_{n=1}{I_nR_n}/t^2) (∏n=0NRn+∑n=1NInRn/t2)。
(二) 低秩逼近的优化方法
我们已经介绍了各种张量分解方法,但如何在不显著降低精度的情况下将这些方法应用于DNN是一个有待讨论的优化问题。由于张量秩越低,我们将获得越高的压缩比,我们希望每一层DNN都可以通过非常低秩的张量分解来分解。然而,随着秩的降低,近似误差增加,导致精度的急剧损失。因此,在精度和压缩比之间存在折衷,这是一个广泛研究的问题。主要有三种低秩优化方法来实现良好的折衷:预训练方法、预设方法和压缩感知方法。
限于篇幅,未完待续。