HDFS小文件问题及解决方案(Hadoop Archive,Sequence File和CombineFileInputFormat)
目录
一、前言概述
二、Hadoop Archive方案(HAR)
第一步:创建归档文件
第二步:查看归档文件内容
第三步:解压归档文件
三、Sequence Files方案
四、CombineFileInputFormat方案
一、前言概述
小文件是指文件size小于HDFS上block大小的文件。这样的文件会给Hadoop的扩展性和性能带来严重问题。
首先,在HDFS中,任何block,文件或者目录在内存中均以对象的形式存储,每个对象约占150byte,如果有1000 0000个小文件,每个文件占用一个block,则namenode大约需要2G空间。如果存储1亿个文件,则namenode需要20G空间。这样namenode内存容量严重制约了集群的扩展。
其次,访问大量小文件速度远远小于访问几个大文件。HDFS最初是为流式访问大文件开发的,如果访问大量小文件,需要不断的从一个datanode跳到另一个datanode,严重影响性能。
最后,处理大量小文件速度远远小于处理同等大小的大文件的速度。每一个小文件要占用一个slot,而task启动将耗费大量时间甚至大部分时间都耗费在启动task和释放task上。
hadoop自带的解决小文件问题的方案(以工具的形式提供),包括Hadoop Archive,Sequence file和CombineFileInputFormat;
二、Hadoop Archive方案(HAR)

Hadoop Archive或者HAR,是一个高效地将小文件放入HDFS块中的文件存档工具,它能够将多个小文件打包成一个HAR文件,这样在减少namenode内存使用的同时,仍然允许对文件进行透明的访问。
案例实操:
第一步:创建归档文件
(注意:归档文件一定要保证yarn集群启动,本质启动mr程序,所以需要启动yarn )
把某个目录 /small_files 下的所有小文件存档成 /big_files/myhar.har :
hadoop archive -archiveName myhar.har -p /small_files /big_files [hadoop@weekend110 datas]$ hdfs dfs -ls /small_files
20/08/06 03:40:07 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 10 items
-rw-r--r-- 1 hadoop supergroup 80 2020-08-06 03:30 /small_files/t1.txt
-rw-r--r-- 1 hadoop supergroup 88 2020-08-06 03:30 /small_files/t10.txt
-rw-r--r-- 1 hadoop supergroup 632 2020-08-06 03:30 /small_files/t2.txt
-rw-r--r-- 1 hadoop supergroup 1509 2020-08-06 03:30 /small_files/t3.txt
-rw-r--r-- 1 hadoop supergroup 38 2020-08-06 03:30 /small_files/t4.txt
-rw-r--r-- 1 hadoop supergroup 98 2020-08-06 03:30 /small_files/t5.txt
-rw-r--r-- 1 hadoop supergroup 69 2020-08-06 03:30 /small_files/t6.txt
-rw-r--r-- 1 hadoop supergroup 62 2020-08-06 03:30 /small_files/t7.txt
-rw-r--r-- 1 hadoop supergroup 88 2020-08-06 03:30 /small_files/t8.txt
-rw-r--r-- 1 hadoop supergroup 93 2020-08-06 03:30 /small_files/t9.txt
[hadoop@weekend110 datas]$ hdfs dfs -mkdir /big_files
[hadoop@weekend110 datas]$ hadoop archive -archiveName myhar.har -p /small_files /big_files
20/08/06 03:35:30 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
20/08/06 03:35:31 INFO client.RMProxy: Connecting to ResourceManager at weekend110/192.168.2.100:8032
20/08/06 03:35:33 INFO client.RMProxy: Connecting to ResourceManager at weekend110/192.168.2.100:8032
20/08/06 03:35:33 INFO client.RMProxy: Connecting to ResourceManager at weekend110/192.168.2.100:8032
20/08/06 03:35:34 INFO mapreduce.JobSubmitter: number of splits:1
20/08/06 03:35:35 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1596678262767_0001
20/08/06 03:35:36 INFO impl.YarnClientImpl: Submitted application application_1596678262767_0001
20/08/06 03:35:36 INFO mapreduce.Job: The url to track the job: http://weekend110:8088/proxy/application_1596678262767_0001/
20/08/06 03:35:36 INFO mapreduce.Job: Running job: job_1596678262767_0001
20/08/06 03:35:56 INFO mapreduce.Job: Job job_1596678262767_0001 running in uber mode : false
20/08/06 03:35:56 INFO mapreduce.Job: map 0% reduce 0%
20/08/06 03:36:09 INFO mapreduce.Job: map 100% reduce 0%
20/08/06 03:36:18 INFO mapreduce.Job: map 100% reduce 100%
20/08/06 03:36:18 INFO mapreduce.Job: Job job_1596678262767_0001 completed successfully
20/08/06 03:36:18 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=859
FILE: Number of bytes written=233827
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=3568
HDFS: Number of bytes written=3567
HDFS: Number of read operations=33
HDFS: Number of large read operations=0
HDFS: Number of write operations=7
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=10429
Total time spent by all reduces in occupied slots (ms)=6181
Total time spent by all map tasks (ms)=10429
Total time spent by all reduce tasks (ms)=6181
Total vcore-seconds taken by all map tasks=10429
Total vcore-seconds taken by all reduce tasks=6181
Total megabyte-seconds taken by all map tasks=10679296
Total megabyte-seconds taken by all reduce tasks=6329344
Map-Reduce Framework
Map input records=11
Map output records=11
Map output bytes=831
Map output materialized bytes=859
Input split bytes=118
Combine input records=0
Combine output records=0
Reduce input groups=11
Reduce shuffle bytes=859
Reduce input records=11
Reduce output records=0
Spilled Records=22
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=754
CPU time spent (ms)=5080
Physical memory (bytes) snapshot=436662272
Virtual memory (bytes) snapshot=4185804800
Total committed heap usage (bytes)=289406976
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=693
File Output Format Counters
Bytes Written=0
当然,也可以指定HAR的大小(使用-Dhar.block.size)。
第二步:查看归档文件内容
HAR是在Hadoop file system之上的一个文件系统,因此所有fs shell命令对HAR文件均可用,只不过是文件路径格式不一样,HAR的访问路径可以是以下两种格式:
har://scheme-hostname:port/archivepath/fileinarchive
har:///archivepath/fileinarchive(本节点)
另外,也可以这样查看归档文件内容 :
hdfs dfs -lsr /big_files/myhar.har
hdfs dfs -lsr har:///big_files/myhar.har输出:
[hadoop@weekend110 datas]$ hdfs dfs -lsr /big_files/myhar.har
lsr: DEPRECATED: Please use 'ls -R' instead.
20/08/06 03:37:49 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
-rw-r--r-- 1 hadoop supergroup 0 2020-08-06 03:36 /big_files/myhar.har/_SUCCESS
-rw-r--r-- 5 hadoop supergroup 787 2020-08-06 03:36 /big_files/myhar.har/_index
-rw-r--r-- 5 hadoop supergroup 23 2020-08-06 03:36 /big_files/myhar.har/_masterindex
-rw-r--r-- 1 hadoop supergroup 2757 2020-08-06 03:36 /big_files/myhar.har/part-0
[hadoop@weekend110 datas]$ hdfs dfs -lsr har:///big_files/myhar.har
lsr: DEPRECATED: Please use 'ls -R' instead.
20/08/06 03:38:22 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
20/08/06 03:38:23 WARN hdfs.DFSClient: DFSInputStream has been closed already
-rw-r--r-- 1 hadoop supergroup 80 2020-08-06 03:30 har:///big_files/myhar.har/t1.txt
-rw-r--r-- 1 hadoop supergroup 88 2020-08-06 03:30 har:///big_files/myhar.har/t10.txt
-rw-r--r-- 1 hadoop supergroup 632 2020-08-06 03:30 har:///big_files/myhar.har/t2.txt
-rw-r--r-- 1 hadoop supergroup 1509 2020-08-06 03:30 har:///big_files/myhar.har/t3.txt
-rw-r--r-- 1 hadoop supergroup 38 2020-08-06 03:30 har:///big_files/myhar.har/t4.txt
-rw-r--r-- 1 hadoop supergroup 98 2020-08-06 03:30 har:///big_files/myhar.har/t5.txt
-rw-r--r-- 1 hadoop supergroup 69 2020-08-06 03:30 har:///big_files/myhar.har/t6.txt
-rw-r--r-- 1 hadoop supergroup 62 2020-08-06 03:30 har:///big_files/myhar.har/t7.txt
-rw-r--r-- 1 hadoop supergroup 88 2020-08-06 03:30 har:///big_files/myhar.har/t8.txt
-rw-r--r-- 1 hadoop supergroup 93 2020-08-06 03:30 har:///big_files/myhar.har/t9.txt使用HAR时需要两点:
第一,对小文件进行存档后,原文件并不会自动被删除,需要用户自己删除;
第二,创建HAR文件的过程实际上是在运行一个mapreduce作业,因而需要有一个hadoop集群运行此命令。
此外,HAR还有一些缺陷:
第一,一旦创建,Archives便不可改变。要增加或移除里面的文件,必须重新创建归档文件;
第二,要归档的文件名中不能有空格,否则会抛出异常,可以将空格用其他符号替换(使用-Dhar.space.replacement.enable=true 和-Dhar.space.replacement参数)。
第三步:解压归档文件
hdfs dfs -mkdir /big_files/har
hdfs dfs -cp har:///big_files/myhar.har/* /big_files/har[hadoop@weekend110 datas]$ hdfs dfs -mkdir /big_files/har
20/08/06 03:41:46 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@weekend110 datas]$ hdfs dfs -cp har:///big_files/myhar.har/* /big_files/har
20/08/06 03:42:28 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
20/08/06 03:42:30 WARN hdfs.DFSClient: DFSInputStream has been closed already
20/08/06 03:42:30 WARN hdfs.DFSClient: DFSInputStream has been closed already
20/08/06 03:42:30 WARN hdfs.DFSClient: DFSInputStream has been closed already
20/08/06 03:42:30 WARN hdfs.DFSClient: DFSInputStream has been closed already
20/08/06 03:42:30 WARN hdfs.DFSClient: DFSInputStream has been closed already
20/08/06 03:42:30 WARN hdfs.DFSClient: DFSInputStream has been closed already
20/08/06 03:42:31 WARN hdfs.DFSClient: DFSInputStream has been closed already
20/08/06 03:42:31 WARN hdfs.DFSClient: DFSInputStream has been closed already
20/08/06 03:42:31 WARN hdfs.DFSClient: DFSInputStream has been closed already
20/08/06 03:42:31 WARN hdfs.DFSClient: DFSInputStream has been closed already
20/08/06 03:42:31 WARN hdfs.DFSClient: DFSInputStream has been closed already
[hadoop@weekend110 datas]$ hdfs dfs -ls /big_files/har
20/08/06 03:43:03 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 10 items
-rw-r--r-- 1 hadoop supergroup 80 2020-08-06 03:42 /big_files/har/t1.txt
-rw-r--r-- 1 hadoop supergroup 88 2020-08-06 03:42 /big_files/har/t10.txt
-rw-r--r-- 1 hadoop supergroup 632 2020-08-06 03:42 /big_files/har/t2.txt
-rw-r--r-- 1 hadoop supergroup 1509 2020-08-06 03:42 /big_files/har/t3.txt
-rw-r--r-- 1 hadoop supergroup 38 2020-08-06 03:42 /big_files/har/t4.txt
-rw-r--r-- 1 hadoop supergroup 98 2020-08-06 03:42 /big_files/har/t5.txt
-rw-r--r-- 1 hadoop supergroup 69 2020-08-06 03:42 /big_files/har/t6.txt
-rw-r--r-- 1 hadoop supergroup 62 2020-08-06 03:42 /big_files/har/t7.txt
-rw-r--r-- 1 hadoop supergroup 88 2020-08-06 03:42 /big_files/har/t8.txt
-rw-r--r-- 1 hadoop supergroup 93 2020-08-06 03:42 /big_files/har/t9.txt三、Sequence Files方案
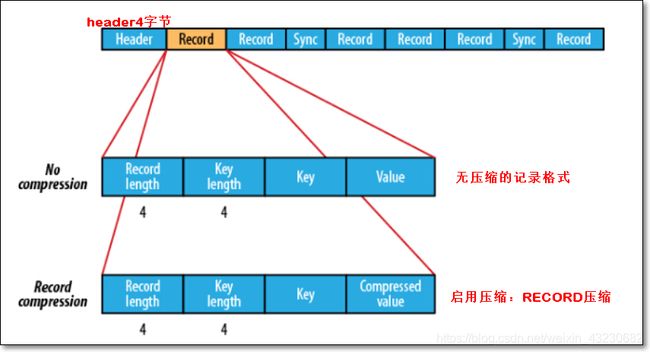
SequenceFile文件,主要由一条条record记录组成;
具体结构(如上图):
- 一个SequenceFile首先有一个4字节的header(文件版本号)
- 接着是若干record记录
- 每个record是键值对形式的;键值类型是可序列化类型,如IntWritable、Text
- 记录间会随机的插入一些同步点sync marker,用于方便定位到记录边界
SequenceFile文件可以作为小文件的存储容器;
- 每条record保存一个小文件的内容
- 小文件名作为当前record的键;
- 小文件的内容作为当前record的值;
- 如10000个100KB的小文件,可以编写程序将这些文件放到一个SequenceFile文件。
一个SequenceFile是可分割的,所以MapReduce可将文件切分成块,每一块独立操作。
不像HAR,SequenceFile支持压缩。记录的结构取决于是否启动压缩
支持两类压缩:
- 不压缩NONE,如上图
- 压缩RECORD,如上图
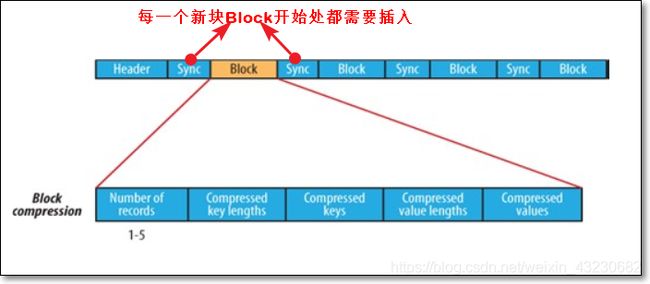
- 压缩BLOCK,如下图,①一次性压缩多条记录;②每一个新块Block开始处都需要插入同步点
在大多数情况下,以block(注意:指的是SequenceFile中的block)为单位进行压缩是最好的选择
因为一个block包含多条记录,利用record间的相似性进行压缩,压缩效率更高
把已有的数据转存为SequenceFile比较慢。比起先写小文件,再将小文件写入SequenceFile,一个更好的选择是直接将数据写入一个SequenceFile文件,省去小文件作为中间媒介.
案例实操:
向SequenceFile写入数据
package com.xsluo.hadoop.sequencefile;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import java.io.IOException;
import java.net.URI;
public class SequenceFileWriteNewVersion {
//模拟数据源;数组中一个元素表示一个文件的内容
private static final String[] DATA = {
"The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.",
"It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.",
"Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer",
"o delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.",
"Hadoop Common: The common utilities that support the other Hadoop modules."
};
public static void main(String[] args) throws IOException {
//输出路径:要生成的SequenceFile文件名
String uri = "hdfs://192.168.2.100:9000/writeSequenceFile";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
//向HDFS上的此SequenceFile文件写数据
Path path = new Path(uri);
//因为SequenceFile每个record是键值对的
//指定key类型
IntWritable key = new IntWritable(); //key数字 -> int -> IntWritable
//指定value类型
Text value = new Text();//value -> String -> Text
//创建向SequenceFile文件写入数据时的一些选项
//要写入的SequenceFile的路径
SequenceFile.Writer.Option pathOption = SequenceFile.Writer.file(path);
//record的key类型选项
SequenceFile.Writer.Option keyOption = SequenceFile.Writer.keyClass(IntWritable.class);
//record的value类型选项
SequenceFile.Writer.Option valueOption = SequenceFile.Writer.valueClass(Text.class);
//SequenceFile压缩方式:NONE | RECORD | BLOCK三选一
//方案一:RECORD、不指定压缩算法
// SequenceFile.Writer.Option compressOption = SequenceFile.Writer.compression(SequenceFile.CompressionType.RECORD);
// SequenceFile.Writer writer = SequenceFile.createWriter(conf, pathOption, keyOption, valueOption, compressOption);
//方案二:BLOCK、不指定压缩算法
// SequenceFile.Writer.Option compressOption = SequenceFile.Writer.compression(SequenceFile.CompressionType.BLOCK);
// SequenceFile.Writer writer = SequenceFile.createWriter(conf, pathOption, keyOption, valueOption, compressOption);
//方案三:使用BLOCK、压缩算法BZip2Codec;压缩耗时间
//再加压缩算法
BZip2Codec codec = new BZip2Codec();
codec.setConf(conf);
SequenceFile.Writer.Option compressAlgorithm = SequenceFile.Writer.compression(SequenceFile.CompressionType.RECORD, codec);
//创建写数据的Writer实例
SequenceFile.Writer writer = SequenceFile.createWriter(conf, pathOption, keyOption, valueOption, compressAlgorithm);
for (int i = 0; i < 100000; i++) {
//分别设置key、value值
key.set(100000 - i);
value.set(DATA[i % DATA.length]); //%取模 3 % 3 = 0;
System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key, value);
//在SequenceFile末尾追加内容
writer.append(key, value);
}
//关闭流
IOUtils.closeStream(writer);
}
}
命令查看SequenceFile内容
hadoop fs -text /writeSequenceFile读取SequenceFile文件
package com.xsluo.hadoop.sequencefile;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.util.ReflectionUtils;
import java.io.IOException;
public class SequenceFileReadNewVersion {
public static void main(String[] args) throws IOException {
//要读的SequenceFile
String uri = "hdfs://192.168.2.100:9000/writeSequenceFile";
Configuration conf = new Configuration();
Path path = new Path(uri);
//Reader对象
SequenceFile.Reader reader = null;
try {
//读取SequenceFile的Reader的路径选项
SequenceFile.Reader.Option pathOption = SequenceFile.Reader.file(path);
//实例化Reader对象
reader = new SequenceFile.Reader(conf, pathOption);
//根据反射,求出key类型对象
Writable key = (Writable)
ReflectionUtils.newInstance(reader.getKeyClass(), conf);
//根据反射,求出value类型对象
Writable value = (Writable)
ReflectionUtils.newInstance(reader.getValueClass(), conf);
long position = reader.getPosition();
System.out.println(position);
while (reader.next(key, value)) {
String syncSeen = reader.syncSeen() ? "*" : "";
System.out.printf("[%s%s]\t%s\t%s\n", position, syncSeen, key, value);
//移动到下一个record开头的位置
position = reader.getPosition(); // beginning of next record
}
} finally {
IOUtils.closeStream(reader);
}
}
}
四、CombineFileInputFormat方案
CombineFileInputFormat是一种新的inputformat,用于将多个文件合并成一个单独的split,另外,它会考虑数据的存储位置。
我们仅仅需实现三个类:
CompressedCombineFileInputFormat
CompressedCombineFileRecordReader
CompressedCombineFileWritable
具体实现可以参考:https://www.cnblogs.com/jhcelue/p/7249593.html