Scala的特质trait与java的interface接口的区别,以及Scala特质的自身类型和依赖注入
1. Scala的特质trait与java接口的区别
Scala中的特质(trait)和Java中的接口(interface)在概念和使用上有一些区别:
-
默认实现:在Java中,接口只能定义方法的签名,而没有默认实现。而在Scala的特质中,除了可以定义方法签名外,还可以定义方法的具体实现。这样,在混入(mix in)特质的类中,可以直接使用特质中定义的方法的默认实现。
-
多重继承:在Java中,类只能单继承,但是可以实现多个接口。而在Scala中,一个类可以混入多个特质,实现了多重继承的效果。这使得Scala的特质更加灵活,并且可以解决多继承带来的冲突问题。
-
字段的定义:特质和接口都可以定义字段,但在Scala特质中,字段可以包含具体的初始值。而在Java接口中,字段只能是常量(即静态final字段)。
-
构造函数:特质和接口都不能直接定义构造函数。在Java中,接口不能有构造函数,而在Scala中,特质也不能有显式的构造函数。不过,特质可以定义具有参数的抽象方法,相当于定义了一个需要传递参数的构造函数。
-
特质的线性化:Scala中的特质具有线性化(linearization)的特性,这意味着特质中的方法调用将按照线性化顺序进行解析。这种特性使得特质更加灵活和可控。
总的来说,Scala中的特质比Java中的接口功能更加强大,更加灵活。特质可以包含方法的默认实现,支持多重继承,可以定义字段和具有参数的抽象方法。特质的线性化特性也使得方法解析更加可控。这些特性使得Scala中的特质在实现代码复用和组件设计时更加灵活和方便。
2. Scala特质的定义与特质混入和特质叠加规则
2.1 Scala特质的定义与特质混入
Scala 语言中,采用特质 trait(特征)来代替接口的概念,也就是说,多个类具有相同的特质(特征)时,就可以将这个特质(特征)独立出来,采用关键字 trait 声明。
Scala 中的 trait 中即可以有抽象属性和方法,也可以有具体的属性和方法,一个类可以混入(mixin)多个特质。这种感觉类似于 Java 中的抽象类。
Scala 引入 trait 特征,第一可以替代 Java 的接口,第二个也是对单继承机制的一种补充。
- 基本语法:
trait 特质名 {
trait 主体
}
- 例子:
trait PersonTrait {
// 声明属性
var name:String = _
// 声明方法
def eat():Unit={
}
// 抽象属性
var age:Int
// 抽象方法,讲语言的特征,因语言不确定,定义为抽象方法
def speakLanguage():Unit
}
- 类继承某种特征:
类继承特质基本语法:
个类具有某种特质(特征),就意味着这个类满足了这个特质(特征)的所有要素,所以在使用时,也采用了extends 关键字,如果有多个特质或存在父类,那么需要采用with关键字连接。
1)基本语法:
没有父类:class 类名 extends 特质 1 with 特质 2 with 特质 3 …
有父类:class 类名 extends 父类 with 特质 1 with 特质 2 with 特质 3…
2)说明:
(1) 类和特质的关系:使用继承的关系。
(2) 当一个类去继承特质时,第一个连接词是 extends,后面是with。
(3) 如果一个类在同时继承特质和父类时,应当把父类写在 extends 后。
3)案例实操:
(1) 特质可以同时拥有抽象方法和具体方法
(2) 一个类可以混入(mixin)多个特质
(3) 所有的 Java 接口都可以当做Scala 特质使用
(4) 动态混入:可灵活的扩展类的功能- (4.1)动态混入:创建对象时混入 trait,而无需使类混入该 trait。
- (4.2)如果混入的 trait 中有未实现的方法,则需要实现。
4. 特质叠加 规则
由于一个类可以混入(mixin)多个 trait,且 trait 中可以有具体的属性和方法,若混入的特质中具有相同的方法(方法名,参数列表,返回值均相同),必然会出现继承冲突问题。
-
冲突分为以下两种:
-
第一种,一个类(Sub)混入的两个 trait(TraitA,TraitB)中具有相同的具体方法,且两个 trait 之间没有任何关系,解决这类冲突问题,直接在类(Sub)中重写冲突方法。
-
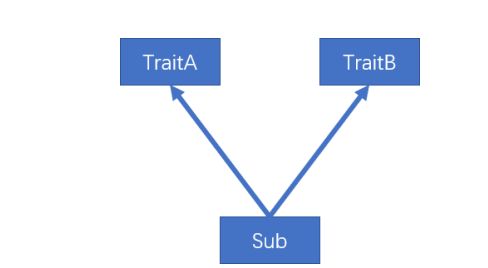
-
第二种,一个类(Sub)混入的两个 trait(TraitA,TraitB)中具有相同的具体方法,且两个 trait 继承自相同的 trait(TraitC),及所谓的“钻石问题”,解决这类冲突问题,Scala采用了特质叠加的策略。
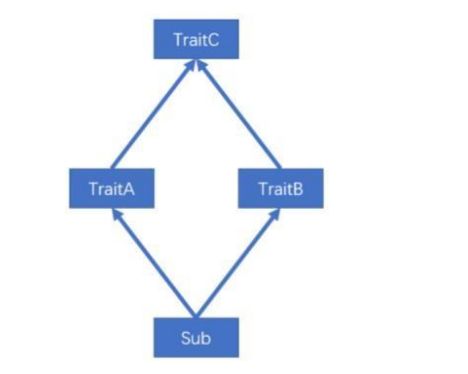
所谓的特质叠加,就是将混入的多个 trait 中的冲突方法叠加起来。 -
例子:
trait Ball {
def describe(): String = {
"ball"
}
}
trait Color extends Ball {
override def describe(): String = {
"blue-" + super.describe()
}
}
trait Category extends Ball {
override def describe(): String = {
"foot-" + super.describe()
}
}
class MyBall extends Category with Color {
override def describe(): String = {
"my ball is a " + super.describe()
}
}
object TestTrait {
def main(args: Array[String]): Unit = {
println(new MyBall().describe())
}
}
- 运行结果:

4.1 特质叠加执行顺序
思考:上述案例中的 super.describe()调用的是父 trait 中的方法吗?
当一个类混入多个特质的时候,scala 会对所有的特质及其父特质按照一定的顺序进行排序,而此案例中的 super.describe()调用的实际上是排好序后的下一个特质中的 describe()方法。排序规则如下:

结论:
(1) 案例中的 super,不是表示其父特质对象,而是表示上述叠加顺序中的下一个特质,即,MyClass 中的 super 指代 Color,Color 中的 super 指代Category,Category 中的super指代Ball。
(2) 如果想要调用某个指定的混入特质中的方法,可以增加约束: super[],例如:
super[Category].describe()。
4.2 Scala的特质叠加规则总结
Scala中的特质可以被混入(mix in)到类中,从而为类添加新的功能。当一个类混入多个特质时,会遵循一定的叠加规则。
以下是Scala特质的叠加规则:
-
线性叠加:Scala中的特质都形成了继承层次结构,因此在叠加特质时采用线性叠加的方式,也就是将所有特质按照其继承关系进行线性化,然后将所有的成员组合成一个新的整体。
-
方法冲突:如果特质之间存在同名的方法,则会发生冲突。此时,编译器会检查这些冲突的方法是否具有相同的方法签名和返回类型。如果是,则该方法只会被引入一次;如果不是,则需要在类中覆盖该方法并提供具体的实现。
-
调用顺序:在具体实例中调用混入的特质方法时,方法的调用顺序与线性化顺序相同,即从最右边的特质开始向左依次调用,直到调用到最左端的特质。
-
初始化顺序:当混入的特质具有构造函数时,初始化顺序也要按照线性化顺序进行。首先执行最右边特质的构造函数,然后依次向左执行每个特质的构造函数。
-
super调用:在具体实例中调用混入的特质方法时,可以使用super关键字来调用相同方法签名的父特质的实现。这种调用方式也需要遵循线性化顺序。
总的来说,Scala中的特质的叠加规则相对比较复杂,主要包括线性叠加、方法冲突、调用顺序、初始化顺序和super调用。这些规则使得混入特质的类具有更加灵活的功能,同时也增加了代码设计和维护的复杂性。因此,在实际开发中应该谨慎使用特质,并注意规避可能出现的问题。
5. Scala特质的自身类型和依赖注入
Scala中的特质(trait)是一种将方法和字段组合在一起的机制,类似于Java中的接口。特质可以被类混入(mixed in),从而为类提供额外的功能,实现了多重继承的效果。
特质类型(self type)是一种限定特质在哪些类型的类中可以混入的方式。通过在特质定义时指定一个特定类型作为 self type,只有混入了该特定类型的类才能混入该特质。这样可以确保特质只能被特定类型的类使用,增加了代码的正确性和安全性。
依赖注入(Dependency Injection,简称DI)是一种设计模式,用于解耦组件之间的依赖关系。在Scala中,可以使用特质类型和依赖注入来实现组件的解耦。
通过将依赖的组件作为特质的 self type,然后在需要使用该组件的地方将其混入到类中,可以实现依赖注入的效果。这样可以方便地替换依赖的实现,提高代码的可测试性和可维护性。
例如,假设我们有一个需要日志功能的类 UserService:
trait Logger {
def log(message: String): Unit
}
class UserService {
this: Logger => // 将Logger作为self type
def register(username: String, password: String): Unit = {
// 注册逻辑
log(s"User '$username' registered.")
}
}
现在我们可以定义一个实现了 Logger 的类,并将其混入 UserService:
class ConsoleLogger extends Logger {
def log(message: String): Unit = println(message)
}
val userService = new UserService with ConsoleLogger
userService.register("user123", "password")
通过依赖注入的方式,我们可以方便地替换日志实现,例如使用文件日志或数据库日志,而不需要修改 UserService 的代码。
总结来说,Scala中的特质类型和依赖注入是一种强大的机制,可以实现代码的解耦和组件的灵活替换。这种设计模式可以提高代码的可测试性、可维护性和可扩展性。
5.1 特质自身类型案例一
- 特质自身类型:自身类型可实现依赖注入的功能。
- 例子:
// 用户类
class User(val name: String, val password: String){}
trait UserDao {
//这里对User类进行了注入
_: User =>
// 向数据库插入数据
def insert(): Unit = {
println(s"insert into db: ${this.name}")
}
}
// 定义注册用户类
class RegisterUser(name: String, password: String) extends User(name, password) with UserDao
//测试
object Test_TraitSelfType {
def main(args: Array[String]): Unit = {
val user = new RegisterUser("alice", "123456")
user.insert()
}
}
这里的_下划线表示通配符,代指当前的UserDao 特质。
5.2 特质自身类型案例二
/**
* 依赖注入是指 依赖对象的创建,由第三方完成,而不是被依赖对象,我们将这种控制关系的转移,称为依赖注入或者控制反转。
* scala通过自身类型的限定实现依赖注入
*/
trait Logger { def log(msg: String) }
trait Auth {
//自身类型命名为auth,并且限定为Auth实例化时必须携带Logger
auth: Logger =>
def act(msg: String): Unit = {
log(msg) //自身类型限定后,可以使用携带类中的方法
}
}
object DI extends Auth with Logger {
override def log(msg: String) = println(msg)
}
object Dependency_Injection {
def main(args: Array[String]): Unit = {
DI.act("I hope you will like it")
}
}
5.3 特质和抽象类的区别
1.优先使用特质。一个类扩展多个特质是很方便的,但却只能扩展一个抽象类。
2.如果你需要构造函数参数,使用抽象类。因为抽象类可以定义带参数的构造函数,而特质不行(有无参构造)。